VDN (合作模式下多智能体学习的价值分解网络)
背景
多智能体强化学习的传统解决方案有两种:
- 集中式:通过将各个智能体的状态空间与动作空间组合为联合状态空间与联合动作空间进行集中式训练,将多智能体训练视为单智能体训练
- 独立式:每个智能体使用单智能体的方法独立训练, 不做通信,也不做配合.
这两种方法各自具有缺陷:
- 集中式的方法在训练两个智能体时往往会产生”lazy agent”的问题,即只有一个智能体活跃,而另一个变得很懒。这是因为当一个智能体学到有效的策略后,另一个智能体会因为不想干扰已经学好的智能体的策略导致整个团队的收益降低,从而不愿意学习。
- 独立式的方法在训练时很困难,在许多简单环境中都没有效果。因为每个智能体面对的环境是动态的(另一个智能体的行为成为了环境中的动态部分),而且每个智能体可能会收到由其他智能体执行且自己观察不到的动作所产生的假的奖励信号。
为了解决现有两类方法的缺陷,VDN中提出提出了值函数分解的方法,通过 learning 的方式将团队整体奖励中分解为每个智能体自己的奖励。一种通过反向传播将团队的奖励信号分解到各个智能体上的方式。
Q函数值分解
如果想要使用基于价值的强化学习模型(value-based),就需要对系统的联合动作-价值函数(joint action-value function,联合Q函数)建模。假设系统中有d个智能体,则联合Q函数可以表示为 $Q((h1,h2,…,hd),(a1,a2,…,ad))$,其中hi表示智能体的局部信息,ai表示动作。可以看出,如果使用一般的方法建模,Q函数的输出维度是dn,n是动作空间的维度。
Value-Decomposition Networks(VDN)的基本假设是,系统的联合Q函数可以近似为多个单智能体的Q函数的和:$Q\left(\left(h^{1}, h^{2}, \ldots, h^{d}\right),\left(a^{1}, a^{2}, \ldots, a^{d}\right)\right) \approx \sum_{i=1}^{d} \tilde{Q}_{i}\left(h^{i}, a^{i}\right)$
其中Qi之间是独立的,只取决于局部观策和动作hi,ai。这样可以保证,最大化每个单智能体的 $Q̃_i$函数得到动作,与通过最大化联合Q函数得到的结果是一样的,即
$$\begin{array}{c}{\max_{a} Q=\max_{a} \sum_{i=1}^{d} \tilde{Q}{i}=\sum^{d} \max_{a_{i} } \tilde{Q}{i} } \ {\operatorname{argmax} Q=\left(\operatorname{argmax}{a } \tilde{Q}_{i}\right)}\end{array}$$
我们可以通过全局的奖励函数,间接地训练每个单智能体的Q函数。并且只要对每个智能体选择最大化$Q̃_i$的动作,就能使得全局Q值最大。
其网络结构如下图所示:

先看上图中的图1,画的是两个独立的智能体,因为对每个智能体来说,观测都是部分可观测的,所以Q函数是被定义成基于观测历史数据所得到的$Q\left(h_{t}, a_{t}\right)$,实际操作的时候直接用RNN来做就可以。
图2说的就是联合动作值函数由各个智能体的值函数累加得到的:$Q\left(\left(h^{1}, h^{2}, \ldots, h^{d}\right),\left(a^{1}, a^{2}, \ldots, a^{d}\right)\right) \approx \sum_{i=1}^{d} \tilde{Q}_{i}\left(h^{i}, a^{i}\right)$
其中d表示d 个智能体,$\tilde{Q}{i}$由每个智能体的局部观测信息得到,$ \tilde{Q} $是通过联合奖励信号反向传播到各个智能体的 $\tilde{Q}_{i} $上进行更新的。这样各个智能体通过贪婪策略选取动作的话,也就会使得联合动作值函数最大。
总结来说:值分解网络旨在学习一个联合动作值函数 $$Q_{t o t}(\tau, \mathbf{u})$$,其中 $ \tau \in \mathbf{T} \equiv \mathcal{T}$ 是一个联合动作-观测的历史轨迹,u是一个联合动作。它是由每个智能体a 独立计算其值函数 $Q_{a}\left(\tau^{a}, u^{a} ; \theta^{a}\right)$,之后累加求和得到的。其关系如下所示:$$Q_{t o t}(\tau, \mathbf{u})=\sum_{i=1}^{n} Q_{i}\left(\tau^{i}, u^{i} ; \theta^{i}\right)$$
严格意义上说 $Q_{a}$称作值函数可能不太准确,因为并没有理论依据表明一定存在一个reward函数,使得该 $Q~i $ 满足贝尔曼方程。
参数共享
使用以下的技巧,VDN能够得到更好的效果:
- 使用DRQN作为Q函数。DRQN是一个用来处理POMDP(部分可观马尔可夫决策过程)的一个算法,其采用LSTM替换DQN卷基层后的一个全连接层,来达到能够记忆历史状态的作用,因此可以在部分可观的情况下提高算法性能。经试验证明,使用LSTM作为Q函数网络的输出层在PODMP环境下有更强的鲁棒性和泛化能力。
- 参数共享(weight sharing)和角色信息(role information)。即所有的单智能体使用同一个Q函数网络,同时在输入中加入一个one-hot 向量来区别不同角色的智能体。
- 智能体间的通信(information channels)。本文试验了两种通信方式,一种是在输入时就包括了其他智能体的信息(low level),另一种是结合Q网络的高层隐藏变量(high level)再分别输出。
实验
实验对比了不同训练方式(集中训练分步执行、集中式、独立式)和不同通信方式(VDN,VDN+low level,VDN+high level的网络结构)的效果。不同网络结构中在low level做通信的结构学习速度比在high level通信更快。集中训练分步执行效果好于传统方式。三种通信方式结构如下图所示:
- 值分解的独立的智能体网络结构可以参考下图所示:

- 如果在此基础上在加上底层的通信的话可以表示为如下形式(其实就是将各个智能体的观测给到所有的智能体):
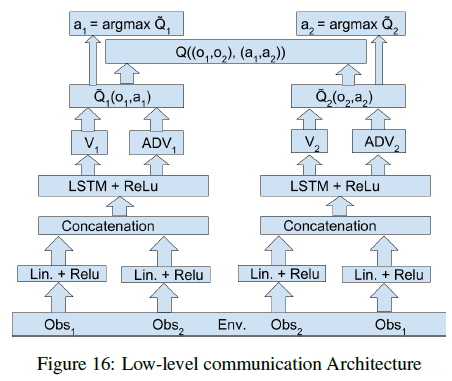
- 如果是在高层做通信的话可以得到如下形式:

- 如果是在底层加上高层上都做通信的话可以得到如下形式:

- 如果是集中式的结构的话,可以表示为如下形式:

缺点
- 多智能体实验环境简单
- 对于一些比较大规模的多智能体优化问题,它的学习能力将会大打折扣。其根本限制在于缺少值函数分解有效性的理论支持。
- VDN可行的原因可以总结为一个公式:$\operatorname{argmax}{a} Q=\left(\operatorname{argmax} } \tilde{Q}_{i}\right)$。VDN中联合函数的表达形式(求和)满足这个条件,但求和这种方式表现力有限,并不能涵盖更加复杂的组合情况,比如非线性组合。
优点
VDN算法结构简洁,设计了中心化计算系统的Q函数,去中心化的单智能体Qi函数。同时每个智能体
这种结构使得在训练的时候可以利用全局信息, 能够在一定程度上保证整体Q函数的最优性。通过它分解得到的 $Q_i $可以让智能体,根据自己的局部观测选择贪婪动作,从而执行分布式策略。
VDN的端到端训练和参数共享使得算法收敛速度非常快,针对一些简单的任务,该算法可以说既快速又有效。