强化学习前沿
恭喜您完成前面的课程!你现在在深度强化学习方面有了扎实的背景。但本课程只是您深度强化学习之旅的开始,还有很多小节需要探索。在这个可选单元中,我们为您提供资源来探索强化学习中的多个概念和研究主题。
基于模型的强化学习 (MBRL)
基于模型的强化学习与无模型对应的区别仅在于学习动态模型,但这对决策的制定方式具有重大的下游影响。
动力学模型通常模拟环境转换动力学,$s_{t+1} = \mathbb{f}_{\theta}(s_t, a_t)$,但是可以在此框架中使用逆向动力学模型(从状态到动作的映射)或奖励模型(预测奖励)之类的东西。
简单定义
- 有一个智能体反复尝试解决问题,积累状态和动作数据。
- 有了这些数据,智能体创建了一个结构化的学习工具,一个动态模型,来推理这个世界。
- 使用动态模型,智能体通过预测未来来决定如何行动。
- 通过这些行动,智能体收集更多数据,改进所述模型,并有望改进未来的行动。
学术定义
基于模型的强化学习 (MBRL) 遵循智能体在环境中交互的框架,学习所述环境的模型,然后利用模型进行控制(做出决策)。
具体来说,智能体在由转换函数控制的马尔可夫决策过程 (MDP) 中运行 $s_{t+1} = \mathbb{f}{\theta}(s_t, a_t)$ , 返回在每一步的奖励 $r(s_t, a_t)$. 通过收集的数据, $D : = s, a_{i}, s_{i+1}, r_{i}$ 智能体训练学习了一个模型, $s_{t+1} = f_{\theta}(s_t, a_t)$最小化 transitions 负对数似然。
我们使用学习的动力学模型采用基于样本的模型预测控制 (MPC),该模型在有限的、递归预测的范围内优化预期奖励,τ,从一组从均匀分布中采样的动作 $U_{(a)}$, (see paper or paper or paper)。
延伸阅读
有关 MBRL 的更多信息,我们建议您查看以下资源:
$$L(\theta)=\mathbb{E}{q{\theta}(\mathbf{z})}(l(\theta, \mathbf{z}))=\int l(\theta, \mathbf{z}) q_{\theta}(\mathbf{z}) \mathrm{d} \mathbf{z}$$
离线与在线强化学习
深度强化学习 (RL) 是构建决策智能体的框架。这些智能体旨在通过反复试验与环境交互并接收奖励作为独特的反馈来学习最佳行为(策略) 。
智能体人的目标是最大化其累积奖励,称为回报。因为RL基于奖励假设:所有目标都可以描述为期望累积奖励的最大化。
深度强化学习智能体通过批量经验进行学习。问题是,他们如何收集它?:
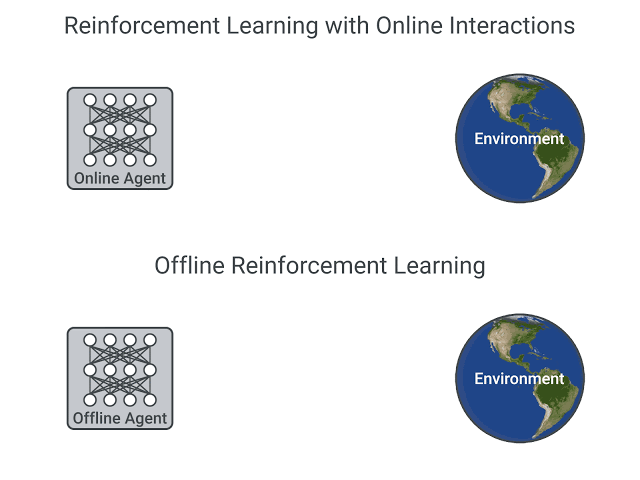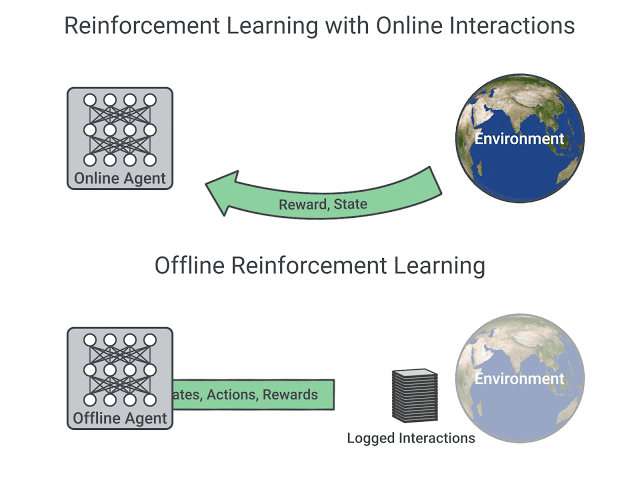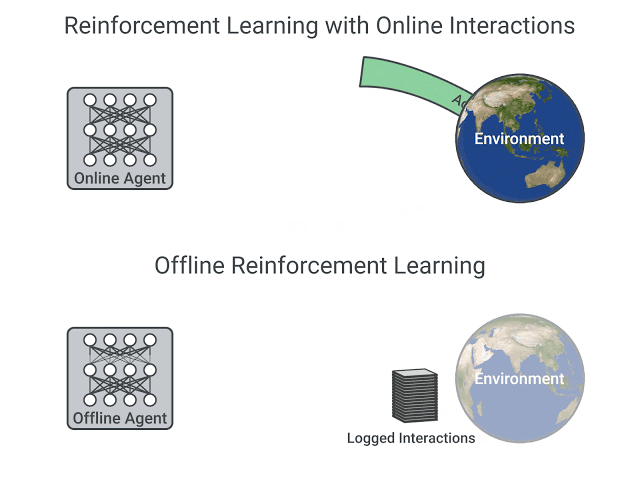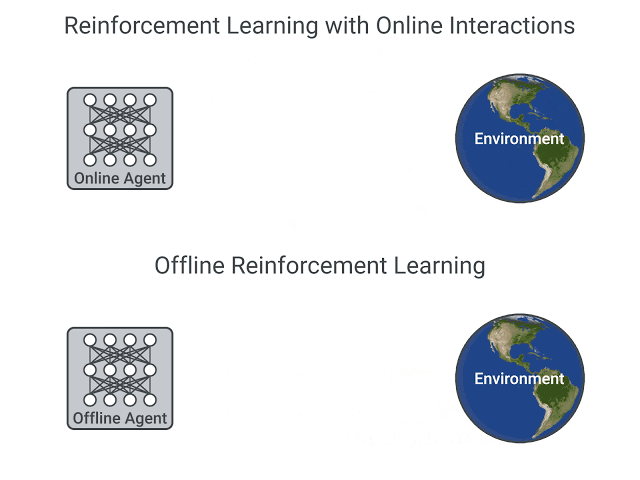
在线和离线设置中, 强化学习的比较,图片来自这篇文章
- 在我们在本课程中学到的在线强化学习中,智能体直接收集数据:它通过与环境交互来收集一批经验。然后,它会立即(或通过一些重播缓冲区)使用此经验来从中学习(更新其策略)。
但这意味着要么直接在现实世界中训练智能体,要么使用模拟器。如果没有,则需要构建它,这可能非常复杂(如何在环境中反映现实世界的复杂现实?)、昂贵且不安全(如果模拟器存在缺陷,可能会提供竞争优势,智能体商将利用它们)。
- 另一方面,在离线强化学习中,智能体只使用从其他智能体或人类演示中收集的数据。它不与环境相互作用。
过程如下:
- 使用一个或多个策略和/或人工交互创建数据集。
- 在此数据集上运行离线 RL以学习策略
这种方法有一个缺点:反事实查询问题。如果我们的智能体人决定做一些我们没有数据的事情,我们该怎么办?例如,在十字路口右转,但我们没有这个轨迹。
关于这个主题有一些解决方案,但是如果你想了解更多关于离线强化学习的信息,你可以观看这个视频
Further reading
For more information, we recommend you check out the following resources:
- Offline Reinforcement Learning, Talk by Sergei Levine
- Offline Reinforcement Learning: Tutorial, Review, and Perspectives on Open Problems
人类反馈强化学习 (RLHF)
人类反馈强化学习 (RLHF) 是一种将人类数据标签集成到基于 RL 的优化过程中的方法。它的动机是对人类偏好建模的挑战。
对于许多问题,即使你可以尝试写下一个理想的方程式,人们的偏好也会有所不同。
基于测量数据更新模型是尝试和缓解这些固有的人类 ML 问题的途径。
开始学习 RLHF
开始学习 RLHF:
- 阅读介绍:从人类反馈 (RLHF) 中阐释强化学习。
- 观看我们几周前录制的现场直播,Nathan 介绍了从人类反馈中强化学习 (RLHF) 的基础知识,以及如何使用这项技术来启用最先进的 ML 工具,例如 ChatGPT。大部分谈话是对相互关联的 ML 模型的概述。它涵盖了自然语言处理和强化学习的基础知识,以及如何在大型语言模型上使用 RLHF。然后我们以 RLHF 中的开放性问题作为结束。
- 阅读关于此主题的其他博客,例如Closed-API vs Open-source continues: RLHF, ChatGPT, data moats。
补充阅读
请注意,这是从上面的 Illustrating RLHF 博客文章中复制的。以下是迄今为止关于 RLHF 最流行的论文列表。该领域最近随着 DeepRL 的出现(2017 年左右)而得到普及,并已发展成为对许多大型科技公司的 LLM 应用的更广泛研究。以下是一些早于 LM 焦点的关于 RLHF 的论文:
- TAMER:Training an Agent Manually via Evaluative Reinforcement(Knox 和 Stone 2008):提出了一个学习的智能体,其中人类提供迭代采取的行动的分数以学习奖励模型。
- Interactive Learning from Policy-Dependent Human Feedback (MacGlashan et al. 2017):提出了一种演员-评论家算法 COACH,其中人类反馈(正面和负面)用于调整优势函数。
- Deep Reinforcement Learning from Human Preferences (Christiano et al. 2017):RLHF 应用于 Atari 轨迹之间的偏好。
- Deep TAMER: Interactive Agent Shaping in High-Dimensional State Spaces (Warnell et al. 2018):扩展了 TAMER 框架,其中使用深度神经网络对奖励预测进行建模。
以下是越来越多的论文的快照,这些论文显示了 RLHF 对 LM 的性能:
- Fine-Tuning Language Models from Human Preferences(Zieglar 等人,2019 年):一篇研究奖励学习对四项特定任务影响的早期论文。
- Learning to summarize with human feedback (Stiennon et al., 2020):RLHF 应用于文本摘要任务。此外,递归总结带有人类反馈的书籍(OpenAI 对齐团队 2021),继续总结书籍的工作。
- WebGPT:带人工反馈的浏览器辅助问答(OpenAI,2021 年):使用 RLHF 训练智能体来浏览网络。
- InstructGPT:训练语言模型遵循人类反馈的指令(OpenAI Alignment Team 2022):RLHF applied to a general language model [关于 InstructGPT 的博客文章]。
- GopherCite: Teaching language models to support answers with verified quotes (Menick et al. 2022):使用 RLHF 训练 LM 以返回带有特定引用的答案。
- Sparrow:通过有针对性的人类判断改进对话智能体的对齐(Glaese 等人 2022):使用 RLHF 微调对话智能体
- ChatGPT:优化对话语言模型(OpenAI 2022):使用 RLHF 训练 LM 以适合用作通用聊天机器人。
- Scaling Laws for Reward Model Overoptimization (Gao et al. 2022):研究学习偏好模型在 RLHF 中的缩放特性。
- Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback(Anthropic,2022):使用 RLHF 训练 LM 助手的详细文档。
- Red Teaming Language Models to Reduce Harms: Methods, Scaling Behaviors, and Lessons Learned(Ganguli 等人,2022 年):详细记录了“发现、衡量和尝试减少 [语言模型] 潜在有害输出”的努力。
- Dynamic Planning in Open-Ended Dialogue using Reinforcement Learning(Cohen 等人,2022 年):使用 RL 来增强开放式对话智能体的会话技能。
- Is Reinforcement Learning (Not) for Natural Language Processing?: Benchmarks, Baselines, and Building Blocks for Natural Language Policy Optimization(Ramamurthy 和 Ammanabrolu 等人,2022 年):讨论 RLHF 中开源工具的设计空间并提出新算法NLPO(自然语言策略优化)作为 PPO 的替代方案。
Decision Transformers
Decision Transformer 模型由 Chen L. 等人的“Decision Transformer:Reinforcement Learning via Sequence Modeling” 提出。它将强化学习抽象为条件序列建模问题。
主要思想是,我们不是使用 RL 方法训练策略,例如拟合值函数,它会告诉我们采取什么行动来最大化回报(累积奖励),我们使用序列建模算法(Transformer),给定一个期望的回报、过去的状态和行动,将产生未来的行动来实现这个期望的回报。它是一个自回归模型,以期望回报、过去状态和行动为条件,以生成实现期望回报的未来行动。
这是强化学习范式的彻底转变,因为我们使用生成轨迹建模(对状态、动作和奖励序列的联合分布建模)来取代传统的 RL 算法。这意味着在 Decision Transformers 中,我们不会最大化回报,而是生成一系列未来的行动来实现预期的回报。
🤗 Transformers 团队将离线强化学习方法 Decision Transformer 和 Hugging Face Hub 集成到库中。
了解 Decision Transformers
要了解有关 Decision Transformers 的更多信息,您应该阅读我们写的关于它的博文 Introducing Decision Transformers on Hugging Face
训练您的第一个决策转换器
现在您已经了解了 Decision Transformers 的工作原理,这要归功于Introducing Decision Transformers on Hugging Face。您已准备好学习从头开始训练您的第一个 Offline Decision Transformer 模型以进行半猎豹奔跑。
从这里开始教程 👉 https://huggingface.co/blog/train-decision-transformers
Further reading
For more information, we recommend you check out the following resources:
强化学习中的语言模型
LM 为智能体编码有用的知识
语言模型(LM) 在处理文本时可以表现出令人印象深刻的能力,例如问答甚至逐步推理。此外,他们对大量文本语料库的训练使他们能够对各种知识进行编码,包括关于我们世界物理规则的抽象知识(例如,可以对物体做什么,旋转物体时会发生什么……)。
最近研究的一个自然问题是,在尝试解决日常任务时,此类知识能否使机器人等智能体受益。虽然这些工作显示出有趣的结果,但所提出的智能体缺乏任何学习方法。这种限制会阻止这些智能体适应环境(例如修复错误的知识)或学习新技能。
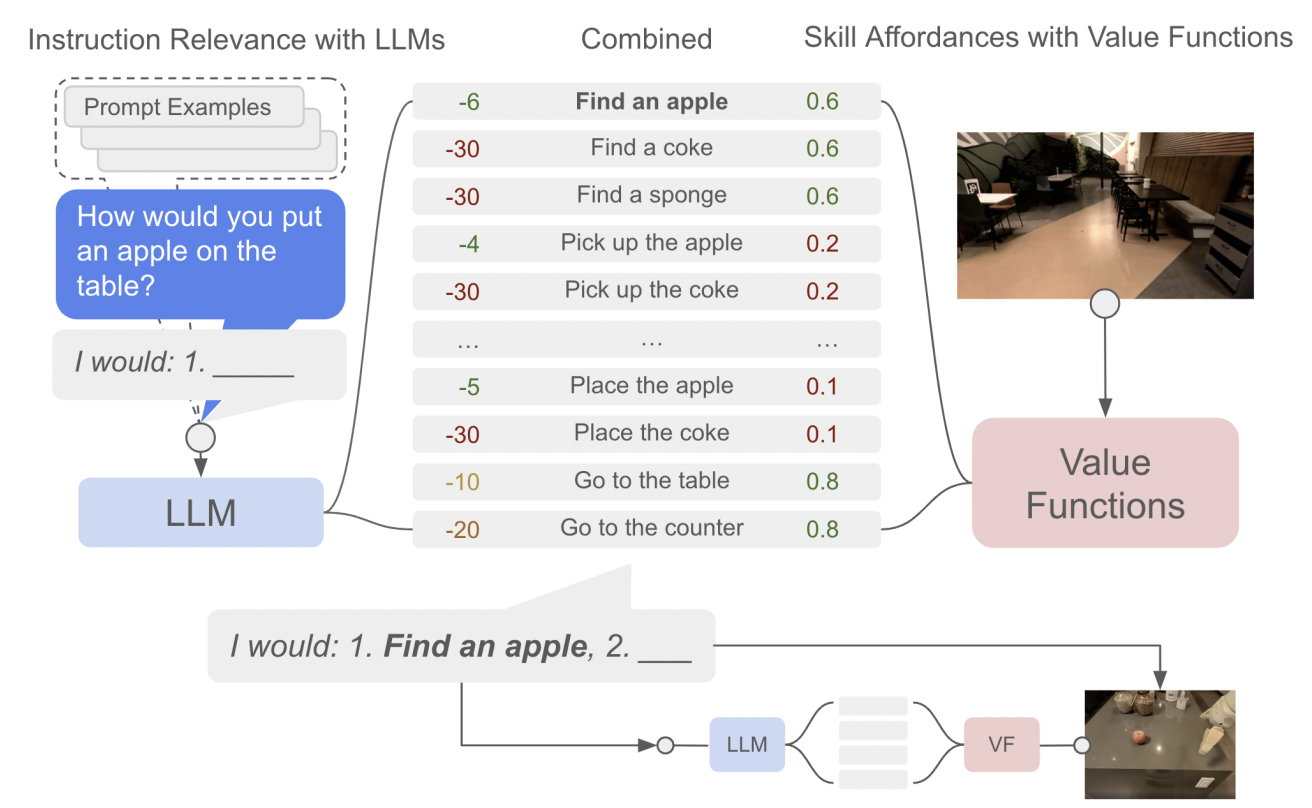 资料来源:
资料来源:LM 和 RL
因此,可以带来关于世界的知识的 LM 和可以通过与环境交互来调整和纠正这些知识的 RL 之间存在潜在的协同作用。从 RL 的角度来看,它特别有趣,因为 RL 领域主要依赖于Tabula-rasa设置,其中所有内容都是由智能体从头开始学习的,从而导致:
- 样本效率低下
- 人眼中的意外行为
作为第一次尝试,论文“Grounding Large Language Models with Online Reinforcement Learning”解决了使用 PPO 使 LM 适应或对齐文本环境的问题。他们表明,LM 中编码的知识可以快速适应环境(为样本效率 RL 智能体开辟道路),而且这种知识允许 LM 在对齐后更好地泛化到新任务。
“Guiding Pretraining in Reinforcement Learning with Large Language Models”中研究的另一个方向是保持 LM 冻结,但利用其知识来指导 RL 智能体的探索。这种方法允许 RL 智能体被引导到对人类有意义和看似有用的行为,而不需要在训练过程中有人在循环中。
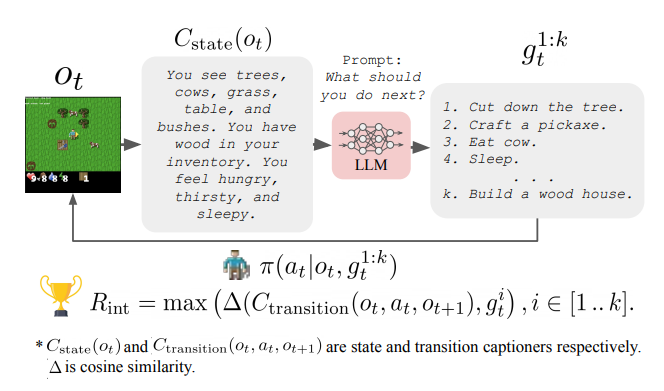 资料来源:
资料来源:一些限制使这些工作仍然非常初步,例如需要在将智能体的观察结果提供给 LM 之前将其转换为文本,以及与非常大的 LM 交互的计算成本。
Further reading
For more information we recommend you check out the following resources:
- Google Research, 2022 & beyond: Robotics
- Pre-Trained Language Models for Interactive Decision-Making
- Grounding Large Language Models with Online Reinforcement Learning
- Guiding Pretraining in Reinforcement Learning with Large Language Models
强化学习的(自动)课程学习
虽然本课程中看到的大多数 RL 方法在实践中都运行良好,但在某些情况下单独使用它们会失败。例如,情况是:
- 学习的任务是艰巨的,需要逐步掌握技能(例如,当一个人想让一个双足智能体学会穿越困难的障碍时,它必须先学会站立,然后走路,然后可能跳跃……)
- 环境有变化(影响难度),人们希望其智能体对它们具有鲁棒性
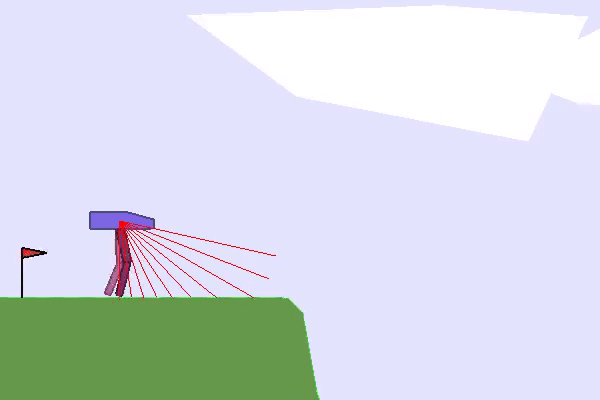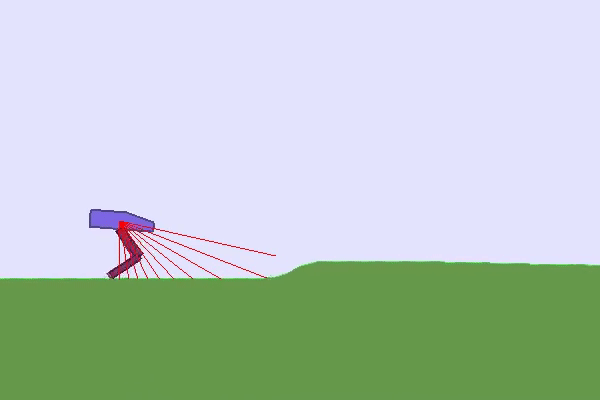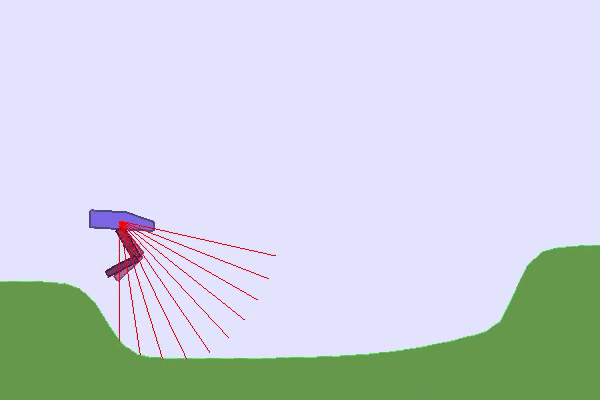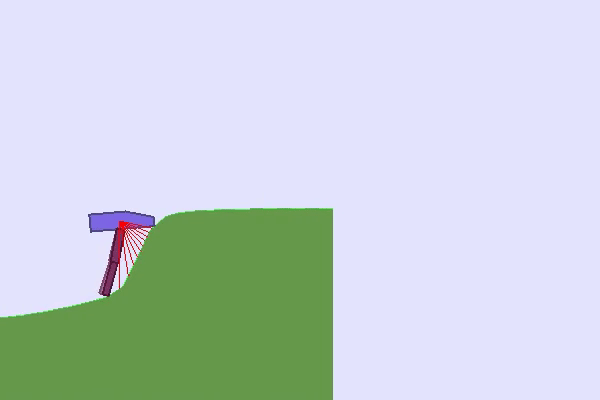

在这种情况下,似乎需要向我们的 RL 智能体提出不同的任务并组织它们,以允许智能体逐步获得技能。这种方法称为课程学习,通常意味着手工设计的课程(或按特定顺序组织的一组任务)。在实践中,例如可以控制环境的生成、初始状态,或使用自我对弈来控制向 RL 智能体提出的对手级别。
由于设计这样的课程并不总是微不足道的,自动课程学习 (ACL) 领域建议设计学习创建此类和组织任务的方法,以最大限度地提高 RL 智能体的性能。波特拉斯等人。建议将ACL定义为:
...一系列机制,通过学习将学习情况的选择调整为 RL 智能体的能力,从而自动调整训练数据的分布。
例如,OpenAI 使用域随机化(他们在环境中应用随机变化)让机器人手解魔方。

最后,您可以通过控制环境变化甚至绘制地形来发挥在TeachMyAgent基准测试中训练的智能体的稳健性👇
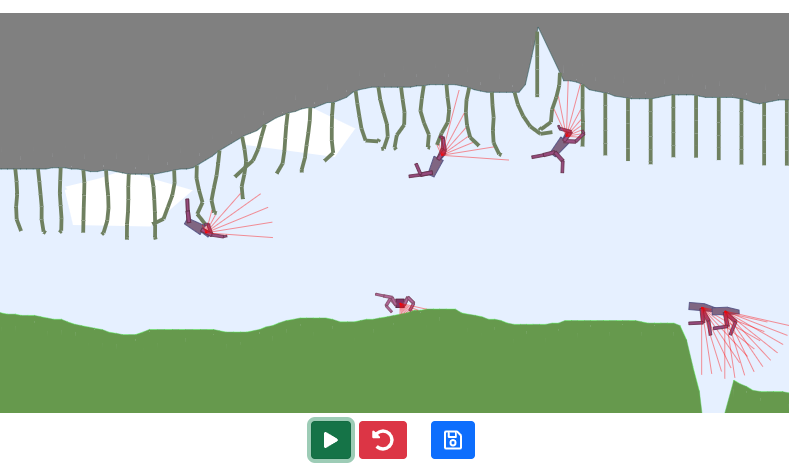 https://huggingface.co/spaces/flowers-team/Interactive_DeepRL_Demo
https://huggingface.co/spaces/flowers-team/Interactive_DeepRL_Demo
Further reading
For more information, we recommend you check out the following resources: