游戏 AI-斗地主-DouZero
1. 概览
斗地主是一个非常具有挑战性的领域,涉及竞争、合作、不完全信息、大型状态空间,特别是可能的动作集合庞大,合法动作在每个回合之间变化显著。
现代强化学习算法主要关注简单和小动作空间,因此无法在斗地主中表现良好。本文提出了一种概念简单且有效的斗地主 AI 系统,称为 DouZero。DouZero 使用神经网络、动作编码以及并行化 Actor 增强了传统蒙特卡洛方法。DouZero从零开始训练,在具有 4 个 GPU 的单机上,训练几天就超越了所有现有的斗地主AI程序,并在Botzone排行榜上的344个AI代理中排名第一。
1.1 背景
强化学习的目标是针对一个特定的任务去学习一个策略来最大化奖励。放在斗地主的环境下,任务是学打斗地主,策略是指出牌策略(先不考虑叫牌),奖励是输赢(先不考虑炸弹加倍)。那么什么是策略呢?这里我们引入强化学习中的两个概念,状态和动作。状态是指一个策略在某一时刻所能看到所有信息。在斗地主中,状态包括玩家当前的手牌、过去的出牌历史、地主的三张牌等等(注意,这里不包括其他玩家的手牌)。动作是指在某一个状态下做出的一个行为。在斗地主中,动作指玩家打出的牌型,例如单张、对子、三带一、炸弹等等。那么策略其实就是一个由状态到动作的一个函数映射,也就是我们优化的目标。它可以是简单的规则,也可以是深度神经网络。我们接下来引入状态转移的概念。在斗地主中,状态是会改变的。例如当玩家出了一张牌后,它的手牌会少一张并且出牌历史记录里会多了一张牌,这个过程我们称为状态转移。在强化学习中,我们假设下一个状态是由前一个状态和在上一个状态做的动作决定的,这也被称为马尔可夫决策过程。
根据以上定义,我们重新描述一下用强化学习学打斗地主这个任务。我们希望为每个位置(地主、地主上家和地主下家)分别学出一个策略来达到以下效果:当每个位置用其学到的策略来打牌时,经过多次状态转换直到一局游戏的结束最终得到的奖励(可以是输赢,也可以考虑炸弹算得分)的期望值达到最大。当然这个描述中奖励还有一些瑕疵,因为输赢不仅取决于策略好不好,还取决于对手强不强。
强化学习的原理在于不断试错。例如在斗地主中,一开始我们并不能直接知道哪个动作是好的,但是当我们打完一局游戏后,我们可以根据输赢获取正反馈或者负反馈。对于正反馈,强化学习算法会基于某种机制来增大未来在相同或者类似的状态做当前动作的概率。相反,对于负反馈,算法会减小未来在相同或者类似的状态做当前动作的概率。经过一次试错后,策略根据反馈进行了更新;在下一次试错中,算法会用新的策略去打牌产生新的数据。经过很多次迭代,算法最终学到一个比较强的策略。
1.2 难点
1.2.1 合作与竞争并存
斗地主中有三个角色,包括一个地主和两个农民。农民之间需要相互配合来共同对抗地主。这种多智能体的设定对强化学习来说是很难的。
- 比如,地主最后得到的奖励(输赢)取决于两个农民策略的强度。如果两个农民很强,地主就很难赢:如果两个农民都很弱,地主的策略即便很弱也很容易赢。
- 对农民来说就更加复杂了,农民得到的奖励不仅关系到地主强不强,还取决于队友给不给力(毕竟遇到猪队友很难赢)。
在这样一种奖励不明确的情况下,训练强化学习是很难的。扑克游戏中表现优异的 CFR 算法及其变种在复杂的三人设置中并不健全。
1.2.2 庞大而复杂的动作空间
斗地主中有复杂的牌型组合,比如单牌、对子、顺子、三带一等,一共有上万种(斗地主具有 27472 个可能的动作)可能的组合,在很大动作空间下训练强化学习是很难的。与德州扑克不同的是,斗地主中的动作很难进行抽象,这导致搜索的计算量十分昂贵,使用强化学习算法效率低。
1.2.3 非完美信息
围棋是完全信息游戏,斗地主是非完美信息游戏,每个玩家看到的信息是不对称的。具体来说,斗地主中的玩家不能看到其他玩家手牌,而围棋中双方玩家都能看到所有的棋子。如此,智能体只能靠「猜」来做决策,增加了很多变数,导致AlphaZero中的算法MCTS不能直接用得上。当然并不是说斗地主比围棋难,它们都很难,区别在于难的点不一样。围棋难在庞大的状态空间和很深的决策树,而斗地主难在合作与竞争并存的设定、巨大的动作空间和非完美信息。
1.3 现有解决方法
现有的斗地主解决方法:
- Counterfactual Regret Minimization (CFR) 不适合这种三人棋牌游戏。
- DQN 算法, DQN 由于动作空间变大会使得高估问题变得严重。
- A3C 等策略梯度算法, 输出一般与动作数量相同维度, 不能利用斗地主的动作特征, 所以不能像 DQN 那样处理没见过的动作. 因此,A3C 和 DQN 在对战简单的规则智能体时,只有 20% 的胜率。
- Combination Q-Network (CQN) 把动作分解为拆牌选择和最终动作选择两部分. 但是分解依赖人类先验, 而且很慢.
- DeltaDou 第一个与顶级人类玩家相比,达到人类水平性能的人工智能程序。 通过贝叶斯方法推断隐藏信息+MCTS, 并基于其他参与者的策略网络采样动作的算法。 为了抽象动作空间, DeltaDou 基于启发式规则预训练一个 kicker 网络, 但是 kicker 网络在算法里分量太重, 当它选了一个坏的动作将拆掉其他牌型,并直接导致输掉游戏. 另外, 算法计算代价也很大.
2. DMC 算法
DouZero使用的强化学习算法非常简单。有多简单呢?我们数学课上学过「用频率估计概率」。当我们要知道某个事件发生的概率时,我们可以通过重复采样,根据事件发生的频率来估计概率。这种方法有个更高端的名字,叫做「蒙特卡罗方法」。蒙特卡罗方法很容易和强化学习联系起来,因为强化学习也是通过不断重复采样来做估计。几十年前在还没有深度学习的时候就有学者想到了这一点。
具体怎么做呢?首先,我们介绍价值的概念:价值是指当前情况下预期的奖励是多少;在这里,我们主要考虑 Q 价值,指的是在某个状态去做某个动作预期的价值是多少。那么我们知道 Q值有什么用呢? Q 值可以用来做决策:在某个状态下,我们可以自然而然地选择Q值最大的动作,因为它预期能带来的奖励最大。在强化学习中,我们一般用 Q(s,a) 来表示在状态 s 和动作 a下的 Q 值。在非深度学习的时代, Q 一般都是离散的,用表格实现。
我们怎么样用「蒙特卡罗方法」学习出 Q 表格呢?我们可以用重复采样的方法去迭代更新 Q 表格中的值,直到收敛。首先,我们初始化 Q 表格中的值(比如0)和一个随机的的策略 π( π(s)会对于当前状态 s 输出一个动作)。然后,我们迭代执行以下步骤(以斗地主为例):
2.1 Monte-Carlo 方法
蒙特卡洛方法(Monte-Carlo)是一种基于平均样本收益的强化学习方法。为了优化策略 π,可以通过迭代执行下列步骤,使用 every-visit MC 方法来估计 Q 值 Q(s,a) 表:
- 使用当前策略 π 生成一个 episode, 得到奖励 r;
- 对于每个在 episode 中的 s,a 对,使用所有关于s,a 的样本的平均收益计算、更新 Q(s,a)
- 对于 episode 中的每个 s,更新策略 π(s)←argmax Q(s,a)。
上面的过程在重复做两件事:第一,用当前的策略去采样;第二,用采样的数据去估计 Q 值。步骤 2 中的平均收益通常使用累计折扣奖励进行计算。与依赖于自举(bootstrapping)的 Q 学习不同,MC 方法直接近似目标 Q 值。步骤1 中使用 epsilon-greedy 方法来平衡探索与利用。上述过程可以自然地与深度神经网络进行结合,即 Deep Monte Carlo (DMC)。具体地,使用神经网络代替 Q 值表,并用均方误差(MSE)进行网络参数更新。
虽然 MC 方法被批评不能处理不完整的事件,并且由于高方差而被认为效率低下,但 DMC 非常适合斗地主。首先,斗地主是一个情节性的任务,所以不需要处理不完整的情节。其次,DMC 可以很容易地并行化,有效地每秒生成多个样本,以缓解高方差问题。
为什么不能直接使用 DQN?
- Deep Q-Learning 是一种自举的方法,它使用下一步的 Q 值来更新当前步的 Q 值。与 DMC 相似的是,它们都是对 Q 值的近似方法,但就斗地主而言,DMC 更为合适。
- 首先,DQN 由于使用了自举,本身具有高估问题,而在更大的动作空间中,高估问题就更加严重了。虽然现在已经有缓解高估问题的技巧,如 Double DQN 和 经验回放,但在斗地主中实验证明,DQN 不稳定。反观 MC 方法,并不使用自举,直接对真实的 Q 值进行近似。
- 第二,斗地主是一个长视野、奖励稀疏的博弈场景。这可能会延缓 Q-Learning 的收敛速度。不同于 DQN,蒙特卡罗收敛不受节目长度的影响,因为它直接接近真实的目标 Q 值。
- 第三,在斗地主问题中,DQN 的实施并不容易,因为动作空间庞大,并且会发生变化。具体来说,DQN 在每次 max 操作时,由于需要迭代所有合法动作,会产生极高的计算成本。此外,不同状态下的合法动作是不同的,因此在批处理操作时也很不方便。
MC 方法可能会受到高方差带来的影响,这意味着需要进行更多采样让其收敛,这很容易通过并行化进行加速采样。
Deep Monte-Carlo
标准的蒙特卡罗算法只能处理离散的情况,但斗地主的状态和动作空间都非常大,普通的蒙特卡罗算法不能直接用。这里我们给它做些加强来应对斗地主:
- 把Q 表格换成神经网络,称作Q 网络。
- 用Mean-Square-Error(MSE) 的损失来更新Q 网络。
- 我们对斗地主中的动作也进行编码(后面会详细介绍)。
- 我们在采样中引入 ϵ−greedy 机制来鼓励探索。
- 我们用多个进程来采样,提高效率。
因为我们引入了深度神经网络。我们把这个方法称为深度蒙特卡罗(Deep Monte-Carlo)。这个方法也可以看作是只包含价值网络的 AlphaZero(去掉搜索和策略网络;当然这个价值是 Q 价值,而AlphaZero里是状态的价值)。这个方法有几个优点:
- 实现简单,效率高。简单并行处理后产生数据很快。
- 超参数很少,避免调参的麻烦。
- 因为没有用 bootstrapping,所以不会有偏差的烦恼。
- 通用性很强。
这个方法可能的缺点就是方差很大。但因为算法本身简单,采样速度快,所以可以通过采集大量的样本来降低方法。在实际中(斗地主游戏),这种组合效果很好。
2.2 DouZero System
接下来,我们介绍DouZero是怎么实现基于深度蒙特卡罗算法来打斗地主,主要包括牌型编码、神经网络和多演员(actor)的并行训练。
卡片表示和神经网络架构
我们用one-hot 编码将牌型编码成 4 x 15 矩阵, 其中15表示非重复牌的种类(3到A加上大小王),4表示最多每种有四张牌。我们用0/1的矩阵来编码,例子如下:(图 2)。
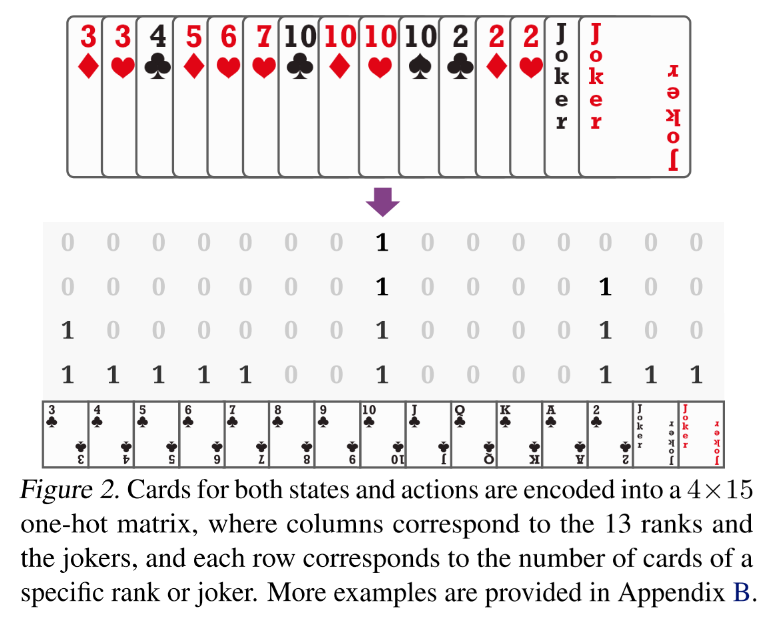
由于在斗地主中花色是不相关的, 这里我们忽略了花色。[有人可能会说花色也有用(当考虑地主三张牌的时候),但这毕竟是很少数的情况,我们暂不考虑。]
这种编码方式是非常通用,我们可以用它去编码一种特定的牌型(例如单张、对子、三带一等),也可以编码手牌、其他玩家的手牌等。有了这种编码方式,我们接下来介绍神经网络,如下图所示:
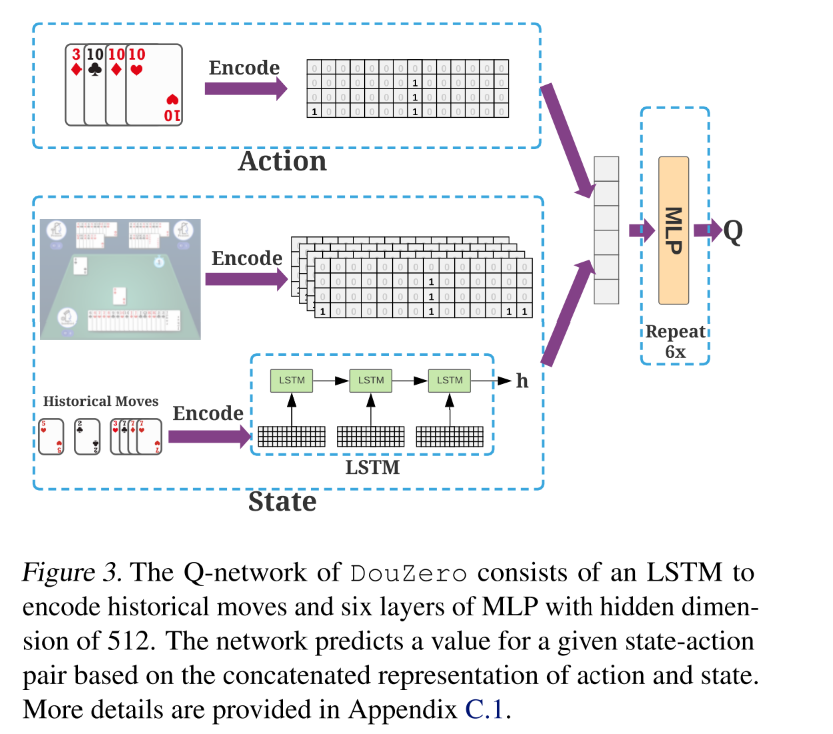
图 3 显示了 Q 网络的架构。网络的输入是状态和动作,输出是 Q值。动作就是简单地用上面的方式进行编码。对于状态,状态包括两部分:一部分是当前能看到的信息,包括手牌、其他玩家出的牌、上家的牌等特征矩阵以及其他玩家手牌数量和炸弹数量的0/1编码;另一部分是历史出牌信息。
我们使用LSTM来对历史移动进行编码,输出与其他状态/动作特征连接。最后,我们使用隐藏大小为 512 的六层 MLP 来生成 Q 值。
状态包括手牌, 对手手牌(即场上剩余的牌), 最近的对手出牌, 剩余牌的数量, 炸弹数量.
- 把牌型编码成 4 * 15 的 card matrix, 然后 flatten 成向量,并去掉最后六维, 因为大小王最多各只有一张, 最后的 card 编码为 1*54 的向量.
- 用 17 one-hot 向量表示农民手牌的数量.
- 用 20 的 one-hot 向量表示地主手牌数量.
- 用 15 维向量表示当前状态下炸弹数量.
- 历史动作, 使用最近的 15 个动作, 并把每 3 个拼到一起, 即历史动作为 5 x 3 x 54 = 5 x 162 的矩阵. 然后将其 feed 进 LSTM, 用最后一个隐状态表示其编码. 如果历史不足 15 个, 那就使用 0 矩阵表示缺失的动作.
并行化 Actor
为了加快采样速度,我们采用多演员(actor)机制去模拟产生数据。每个演员进程的算法实现细节如下:
我们将 Landlord 表示为 L,将 Landlord 之前移动的玩家表示为 U,将 Landlord 之后移动的玩家表示为 D。我们通过多个Actor进程和一个Learner进程来并行化DMC ,分别总结在算法 1 和算法 2 中。Learner 为这三个位置维护三个全局 Q 网络,并使用 MSE 损失更新网络,以根据Actor进程提供的数据近似目标值。每个Actor维护三个局部 Q 网络,这些网络定期与全局Q 网络同步。Actor 将重复从游戏引擎中采样轨迹,并计算每个状态-动作对的累积奖励。Learner 和Actor的通信是通过三个共享缓冲区实现的。每个缓冲区被划分为多个条目,其中每个条目由多个数据实例组成。
算法1: Douzero 的 Actor 过程
1: 输入:共享缓冲区 BL、BU 和 BD,每个缓冲区有 B 个条目,每个条目大小为 S,探索超参数 $\epsilon$,折扣因子 $\gamma$
2: 初始化本地 Q 网络 $Q_L, Q_U$ 和 $Q_D$,以及本地缓冲区 $\mathcal{D}_L, \mathcal{D}_U$ 和 $\mathcal{D}_D$
3: 对于迭代 = 1,2,... 执行
4: 与学习进程同步 $Q_L, Q_U$ 和 $Q_D$
5: 对于 t=1,2,...,T 执行 D 生成一局游戏
$$a_t \leftarrow \begin{cases} \arg\max_a Q(s_t, a) & \text{with prob } \epsilon \ \text{random action} & \text{with prob } (1-\epsilon) \end{cases}$$
8: 执行 $a_t$,观察 $s_{t+1}$ 和奖励 $r_t$
9: 将 ${s_t, a_t, r_t}$ 存储到 $\mathcal{D}_L, \mathcal{D}_U$ 或 $\mathcal{D}_D$ 中
10: 结束循环
11: 对于 $t=T-1,~T-2,\ldots,1$ 执行 $\triangleright$ 获取累积奖励
12: $\quad r_t \leftarrow r_t + \gamma r_{t+1}$ 并更新 $\mathcal{D}_L, \mathcal{D}_U$ 或 $\mathcal{D}_D$ 中的 $r_t$
13: 结束循环
14: 对于 $p \in {L,U,D}$ 执行 $\triangleright$ 多线程优化
15: 如果 $\mathcal{D}_p$ 的长度 $\geq L$ 则
16: 请求并等待 $\mathcal{B}_p$ 中的一个空条目
17: 将 $\mathcal{D}_p$ 中的 ${s_t, a_t, r_t}$ 大小为 L 移动到 $\mathcal{B}_p$
18: 结束如果
19: 结束循环
20:结束循环
这段伪代码描述了一个多进程的强化学习算法,用于训练斗地主中的AI代理。每个进程代表一个玩家位置(地主L、上游U、下游D),并使用本地Q网络和缓冲区来生成游戏数据,然后与全局共享缓冲区同步,以便进行学习和优化。探索参数 $\epsilon$ 控制AI在采取最优动作和随机动作之间的行为。折扣因子 $\gamma$ 用于计算累积奖励,以训练网络。
算法 2: DouZero的学习者进程
1: 输入:共享缓冲区 BL、BU 和 BD,每个缓冲区有 B 个条目,每个条目大小为 S,批量大小 M,学习率 $\psi$。
2: 初始化全局 Q 网络 $Q_g^L$、$Q_g^U$ 和 $Q_g^D$。
3: 对于迭代 = 1,2,... 直到收敛为止执行以下步骤:
4: 对于 p ∈ {L,U,D} 执行以下步骤,D 表示多线程优化:
5: 如果 Bp 中满条目的数量 ≥ M 则:
6: 从 Bp 中采样一个包含 M × S 个实例的批量 {st, at, rt},并释放这些条目。
7: $\quad$ 使用 MSE 损失和学习率 $\psi$ 更新 $Q_p^g$。
8: 结束如果。
9: 结束循环。
10: 结束循环。
这段伪代码描述了DouZero系统中学习者进程的算法流程,其中包括从共享缓冲区中采样数据并更新全局Q网络。这个过程会重复进行,直到算法收敛。
3. Douzero 实验结果
本文设计的实验需要解决以下问题:
- DouZero 与现有的斗地主程序算法,如基于规则的,基于 RL 的,基于 MCTS 的方法对比,有什么优势?
- DouZero 如果考虑上抢地主阶段,会如何表现?
- DouZero 的训练效率如何?
- DouZero 与 boostrapping 和 actor-critic 方法相比表现如何?
- DouZero 所学到的策略与人类专家的知识是否一致?
- DouZero 与现有方法相比,推理时的计算效率高吗?
- DouZero 中,两个农民是否能够学会相互合作?
在扑克中,常见的用于衡量策略的指标是可利用度。然而,在斗地主中,由于具有三个玩家,同时有很大的状态、动作空间,因此计算可利用度是十分棘手的。为了评估算法性能,作者让算法之间进行对战。具体来说,对于两种竞争算法的 A 和 B 和给定的牌型,它们将首先分别作为地主和农民的位置。对局结束后,双方交换位置,并且牌型不变。
对比方法:
- DeltaDou:一个强大的人工智能程序,它使用贝叶斯方法来推断隐藏的信息,并使用 MCTS 搜索动作。本文使用了作者提供的代码和预训练过的模型。该模型经过了两个月的训练,显示出与顶级人类玩家表现相当。
- CQN:组合 Q-Learning 是一个基于手牌分解和 DQN 的程序。本文使用了开源代码和作者提供的预训练模型。
- SL:监督学习基线。作者在内部收集了来自联盟最高级别的玩家的 226,230 场人类专家比赛。然后我们使用与 DouZero 相同的状态重构符号和神经结构,从这些数据中生成 49,990,075 个样本来训练监督代理。
- Rule-Based Programs: 作者收集了一些基于开放的启发式的程序,包括 RHCP,一个名为 RHCP-v25 的改进版本,以及 RLCard 包中的规则模型(Zha等人,2019a)。
评估指标:
- WP (Winning Percentage):胜率,以 A 获胜的比赛次数除以总比赛次数
- WP (Winning Percentage, 胜率): A 赢的次数除以总游戏数. 用最后的+/-1 作为奖励, 训练出的 AI 对于出炸更激进.
- ADP (Average Difference in Points, 平均得分差): 每局游戏 A 和 B 的平均得分差. 基础点是 1, 每一个炸加倍. 直接以 ADP 作为奖励, 训练出的 AI 对出炸更保守.
3.1 与现有方法的表现对比
首先,DouZero 策略在所有基于规则的策略和监督学习中占主导地位,证明了在斗地主中采用强化学习的有效性。
其次,DouZero 的性能明显优于 CQN。回想一下,CQN 同样用动作分解和 DQN 来训练 Q 网络。DouZero 的优势表明DMC 是这确实是在斗地主中训练 Q 网络的有效方法。
第三,DouZero 的性能表现比目前最强的斗地主 AI 要更优秀。我们注意到斗地主有很高的方差,也就是说,赢得一个游戏依赖于初始手牌的强度,这是高度依赖于运气。因此,WP为 0.586,ADP为 0.258,表明比有明显的改善。
3.2 抢地主阶段比较
作者使用人类专家数据训练一个具有监督学习的抢地主网络。将排名前三的算法,即 DouZero、DeltaDou 和 SL,放入了一个斗地主游戏的三个位置。在每个游戏中,随机选择第一个投标人,并使用预先训练的投标网络模拟抢地主阶段。该网络同时用于三个玩家上。带了抢地主阶段的 DouZero 仍具有很强的优势。
3.1 DouZero 的训练效率
使用 SL 和 DeltaDou 作为对手来绘制 WP 和 ADP w.r.t.的曲线的训练天数。
首先,DouZero 在 WP 和 ADP 方面,在一天和两天的训练中分别优于 SL。注意到 DouZero 和 SL 使用完全相同的神经结构进行训练。因此,我们将 DouZero 的优越性归因于自博弈强化学习。虽 然SL 的性能也很好,但它依赖于大量数据,数据不灵活,可能会限制其性能。
第二,DouZero 训练在 3 天和 10 天的训练时间内,在 WP 和 ADP 方面分别优于 DeltaDou。我们注意到 DeltaDou 是通过启发式上的监督学习初始化的,并且训练时间超过两个月。而 DouZero 从零开始,只需要几天的训练就能打败 DeltaDou。这表明,没有搜索的无模型强化学习在斗地主中确实是有效的。
3.4 与 SARSA 和 Actor-Critic 方法的表现对比
作者实现了两种 DouZero 的变体。首先,用时间差异(TD)目标代替 DMC 目标。这就导致了 SARSA 的一个深度神经网络版本。其次,实现了一个具有动作特征的 actor-critic 变体。具体来说,我们使用 Q 网络作为具有行动特征的 critic,并使用训练策略作为具有动作掩码的 actor 来消除非法行为。
首先,没有观察到使用 TD 学习的明显好处。观察到,DMC 在训练时间和样本效率方面的学习速度略快于 SARSA。可能的原因是 TD学习在稀疏的奖励设置中并没有多大帮助。
第二,观察到 actor-critic 的性能比较差。这就说明向 critic 添加动作特性可能不足以解决复杂的动作空间问题。
3.5 在专家数据上对 DouZero 分析
作者在整个训练过程中计算了 DouZero 对人类数据的准确性。
首先,在早期阶段,即训练的前五天,准确性不断提高。这表明,智能体通过自博弈,可能已经学会了一些与人类专业知识相一致的策略。
其次,经过五天的训练,准确度急剧下降。注意到,针对 SL 的 ADP 在5天后仍在改善。这表明,这些智能体可能已经发现了一些人类无法轻易发现的新颖的、更强的策略,这再次验证了自我游戏强化学习的有效性。
3.6 推断时间的比较
可以观察到 DouZero 比 DeltaDou、CQN、RHCP 和 RHCP-v2 快几个数量级。这是意料之中的,因为 DeltaDou 需要执行大量的蒙特卡罗模拟,而 CQN、RHCP 和 RHCP-v2 需要昂贵的手牌分解计算。然而,DouZero 在每一步中只执行神经网络的一次正向传递。DouZero 的有效推理使我们每秒生成大量样本用于强化学习。它还可以在实际应用程序中部署模型 .
4. 斗地主游戏介绍
A. 斗地主介绍
作为中国最受欢迎的卡牌游戏,斗地主吸引了数亿玩家,每年都会举办许多比赛。斗地主以其易学难精而闻名,需要精心策划和战略思考。斗地主由三名玩家进行。在每局游戏中,玩家首先竞标地主位置。竞标阶段后,一名玩家将成为地主,另外两名玩家将成为农民。两名农民作为一队与地主对抗。游戏的目标是成为第一个没有牌的玩家。除了巨大的状态/动作空间和不完全信息外,两名农民还需要合作以击败地主。因此,通常针对小型游戏且仅设计用于两名玩家的扑克游戏算法在斗地主中不适用。以下,我们首先概述斗地主的游戏规则,然后分析斗地主的状态/动作空间。熟悉该游戏的读者可以跳过A.1节。不熟悉斗地主的读者也可以参考Wikipedia 以获取更多介绍。
A.1. 规则
斗地主使用一副卡牌进行游戏,包括两个王。在斗地主中,花色是不相关的。牌的等级由大到小依次为:大王、小王、2、A、K、Q、J、10、9、8、7、6、5、4、3。每局游戏有三个阶段,如下所述。
- 发牌:一副54张的牌将被发给三名玩家。每个玩家将得到17张牌,最后剩下的三张牌将面朝下放在牌堆上。这三张牌将在竞标阶段后发给地主。
- 竞标:三名玩家将分析自己的牌,不向其他玩家展示。玩家将根据自己的手牌强度决定是否竞标地主。竞标规则有许多版本。在本文中,我们考虑大多数在线斗地主应用中采用的版本。首个竞标者将被随机选择。首个竞标者随后决定是否出价。如果首个竞标者不出价,其他玩家将轮流成为竞标者,直到有人出价。如果没有人出价,将为玩家重新发牌。如果有人选择出价,其他玩家将决定她是否接受出价或者她想要出更高的价。每个玩家只有一次出更高价的机会。最后一个出价或出更高价的玩家将成为地主。一旦地主确定,地主将得到牌堆上的三张牌。其他两名玩家将作为农民与地主对抗。
- 出牌:在这个阶段,玩家将从地主开始轮流出牌。第一个玩家可以选择任意类别的牌,如下一段详细说明。然后下一个玩家必须出相同类别的更高级别的牌。如果下一个玩家手上没有更高级别的牌或者她不想跟进这一类别,也可以选择“PASS”。如果所有其他玩家都选择“PASS”,那么首先出牌类别的玩家可以自由地出其他类别的牌。玩家将轮流出牌,直到一名玩家没有牌为止。如果地主没有牌了,地主获胜。如果农民中的任何一个没有牌了,农民队获胜。两名农民需要合作以增加获胜的可能性。即使手牌很差,一名农民仍然可以通过帮助另一名农民获胜来赢得游戏。
斗地主的一个挑战是丰富的牌型,包括各种牌的组合。对于一些牌型,玩家可以选择一张踢牌,这可以是手中的任何一张牌。人们通常会选择一张无用的牌作为踢牌,以便更容易地出完手中的牌。因此,玩家需要仔细规划如何出牌以赢得游戏。斗地主中的牌型如下所示。请注意,炸弹和火箭可以超越其他所有牌型。
单牌:任何一张单牌。
对子:两张等级相同的牌。
三张:三张等级相同的牌。
三张带单牌:三张等级相同的牌,加上一张作为踢牌的单牌。
三张带对子:三张等级相同的牌,加上一对作为踢牌的对子。
顺子:至少五张连续的单牌。
连对:至少三对连续的对子。
飞机:至少两个连续的三张,每个三张带有一个不同的单牌作为踢牌。
四带二:四张相同的牌,加上两对作为踢牌的对子。
炸弹:四张相同的牌。
火箭:红桃和黑桃的王。
A.2 斗地主的状态和动作空间
根据 RLCard(Zha et al., 2019a)的估计,斗地主的信息集数量高达10^83, 每个信息集的平均大小高达10^23。 虽然信息集的数量比无限制德州扑克(10^126)少, 但每个信息集的平均大小远大于无限制德州扑克(10^4)。
与德州扑克游戏不同,斗地主的状态空间不容易抽象化。具体来说,斗地主中的每一张牌都对获胜至关重要。例如,历史行动中2的数量至关重要,因为玩家需要决定他们的牌是否会被其他玩家的2压制。因此,状态表示中的微小差异可能会显著影响策略。尽管斗地主的状态空间大小没有无限制德州扑克那么大,但学习有效策略非常具有挑战性,因为代理需要准确区分不同的状态。DouZero通过提取表示并使用深度神经网络自动学习策略来解决这个问题。
斗地主由于牌的组合而导致动作空间爆炸。我们在表3中总结了动作空间。斗地主的动作空间大小为27,472,远大于麻将(10^2)的大小。它也比无限制德州扑克复杂得多,后者的动作空间可以轻易抽象化。具体来说,在斗地主中,每张牌都很重要。例如,对于三带一的动作类型,错误选择踢牌可能直接导致失败,因为它可能会破坏一个链条。因此,动作空间难以抽象化。这对强化学习提出了挑战,因为大多数算法只在小动作空间上表现良好。与之前使用启发式抽象动作空间的工作(Jiang et al., 2019)不同,DouZero采用蒙特卡洛方法来解决这个问题,这允许灵活探索动作空间,以潜在地发现更好的走法。
| 动作类型 | 动作数量 |
|---|---|
| 单牌 (Solo) | 15 |
| 对子 (Pair) | 13 |
| 三张 (Trio) | 13 |
| 三带一 (Trio with Solo) | 182 |
| 三带二 (Trio with Pair) | 156 |
| 顺子 (Chain of Solo) | 36 |
| 连对 (Chain of Pair) | 52 |
| 飞机 (Chain of Trio) | 45 |
| 飞机带单牌 (Plane with Solo) | 21,822 |
| 飞机带对子 (Plane with Pair) | 2,939 |
| 四带一 (Quad with Solo) | 1,326 |
| 四带二 (Quad with Pair) | 858 |
| 炸弹 (Bomb) | 13 |
| 火箭 (Rocket) | 1 |
| 过 (Pass) | 1 |
| 总计 | 27,472 |
我们遵循RLCard(Zha et al., 2019a)提供的内容。这些数据展示了斗地主中可能的动作类型和每种类型中不同动作的数量,从而构成了斗地主复杂的动作空间。例如,单牌动作有15种,对应于除去大小王之外的15 种不同的牌面值;而飞机带单牌的动作数量则远远大于其他类型,因为它涉及到多种不同的牌的组合方式。这个动作空间的规模和复杂性是斗地主AI需要解决的主要挑战之一。
C. 特征表示和神经网络架构的附加细节
C.1. 动作和状态表示
神经网络的输入是状态和动作的连接表示。对于每个15×4的卡牌矩阵,我们首先将矩阵展平为一个大小为60的一维向量。然后我们移除六个始终为零的条目,因为只有一个黑色或红色的王牌。换句话说,每个卡牌矩阵被转换成一个大小为54的独热向量。除了卡牌矩阵,我们进一步使用独热向量来表示其他两名玩家当前的手牌。例如,对于农民,我们使用一个大小为17的向量,其中每个条目对应当前状态下手牌的数量。对于地主,向量的大小是20,因为地主手中最多可以有20张牌。类似地,我们使用一个15维向量来表示当前状态下的炸弹数量。对于历史移动,我们考虑最近的15次移动,并将每三个连续移动的表示连接起来;也就是说,历史移动被编码成一个5×162的矩阵。历史移动被输入到一个LSTM中,我们使用最后一个单元的隐藏表示来代表历史移动。如果历史上的移动少于15次,我们使用零矩阵来表示缺失的移动。我们分别在表4和表5中总结了地主和每个农民的编码特征。
| 特征 | 尺寸 | |
|---|---|---|
| 动作 | 动作的卡牌矩阵 | 54 |
| 状态 | 手牌的卡牌矩阵 | 54 |
| 状态 | 其他两名玩家手牌的联合卡牌矩阵 | 54 |
| 状态 | 最近一次移动的卡牌矩阵 | 54 |
| 状态 | 第一农民打出的卡牌矩阵 | 54 |
| 状态 | 第二农民打出的卡牌矩阵 | 54 |
| 状态 | 表示第一农民剩余手牌数量的独热向量 | 17 |
| 状态 | 表示第二农民剩余手牌数量的独热向量 | 17 |
| 状态 | 表示当前状态下炸弹数量的独热向量 | 15 |
| 状态 | 最近15次移动的连接矩阵 | 5×162 |
| 特征 | 尺寸 | |
|---|---|---|
| 动作 | 动作的卡牌矩阵 | 54 |
| 状态 | 手牌的卡牌矩阵 | 54 |
| 状态 | 其他两名玩家手牌的联合卡牌矩阵 | 54 |
| 状态 | 最近一次移动的卡牌矩阵 | 54 |
| 状态 | 地主执行的最近一次移动的卡牌矩阵 | 54 |
| 状态 | 另一农民执行的最近一次移动的卡牌矩阵 | 54 |
| 状态 | 地主打出的卡牌矩阵 | 54 |
| 状态 | 另一农民打出的卡牌矩阵 | 54 |
| 状态 | 表示地主剩余手牌数量的独热向量 | 20 |
| 状态 | 表示另一农民剩余手牌数量的独热向量 | 17 |
| 状态 | 表示当前状态下炸弹数量的独热向量 | 15 |
| 状态 | 最近15次移动的连接矩阵 | 5×162 |
这些表格详细描述了斗地主中地主和农民的特征表示,包括他们各自的手牌、其他玩家的手牌、最近的动作以及历史移动等信息。这些特征被用来作为神经网络的输入,以帮助模型更好地理解和预测游戏的状态和最佳动作。
C.2. 监督学习的数据处理和神经架构
为了使用监督学习训练代理,我们从一个流行的斗地主游戏手机应用中内部收集用户数据。应用中的用户分属不同的联赛,这些联赛代表了用户的实力。我们通过只保留最高联赛玩家生成的数据来过滤原始数据,以确保数据的质量。过滤后,我们获得了226,230场人类专家的比赛。我们将每一步骤视为一个实例,并使用监督损失来训练网络。
这个问题可以被制定为一个分类问题,我们的目标是基于给定的状态预测动作,总共有27,472个类别。然而,我们发现在实践中大多数动作是不合法的,而且遍历所有类别的成本很高。受到Q网络设计的启发,我们将问题转化为二元分类任务,如图12所示。具体来说,我们使用与DouZero相同的神经架构,并在输出上添加了Sigmoid函数。然后我们使用二元交叉熵损失来训练网络。我们随机抽取10%的数据用于验证,并使用其余数据进行训练。我们将用户数据转化为正例,并基于未被选择的合法移动生成负例。最终,训练数据包括49,990,075个实例。我们进一步发现数据是不平衡的,负例的数量远大于正例。因此,我们采用了基于正例和负例分布的加权交叉熵损失。我们发现在实践中,加权损失可以提高性能。我们将批量大小设置为8096,并训练20个周期。预测是通过选择导致最高分数的动作来进行的。我们输出在验证数据上准确度最高的模型。我们分别为三个位置做三次这个过程。我们在图13中绘制了验证准确度与周期数量的关系。网络可以在所有位置上达到大约84%的准确度。
C.3. 叫牌网络的神经网络架构和训练细节
叫牌阶段的目标是基于手牌的强弱来决定一个玩家是否应该成为地主。这个决策比出牌要简单得多,因为代理只需要考虑手牌和其他玩家的决策,我们只需要做出二元预测,即我们是否叫牌。在叫牌阶段开始时,一个随机选择的玩家将决定是否叫牌。然后其他两名玩家也会选择是否叫牌。如果只有一名玩家叫牌,那么那名玩家将成为地主。假设有两名或更多玩家叫牌,首先叫牌的玩家将有优先权决定她是否想成为地主。我们提取了128个特征来表示手牌和玩家的移动,如表6所总结。对于网络架构,我们使用了一个(512, 256, 128, 64, 32, 16)的多层感知机(MLP)。像监督学习的出牌代理一样,我们在输出上添加了Sigmoid函数,并使用二元交叉熵损失来训练网络。我们在图14中绘制了验证准确度与周期数量的关系。网络可以达到83.1%的准确度。
| 特征 | 尺寸 |
|---|---|
| 手牌的卡牌矩阵 | 54 |
| 表示等级3到A的单牌的向量 | 12 |
| 表示等级3到2的对子的向量 | 13 |
| 表示等级3到2的三张的向量 | 13 |
| 表示等级3到2的炸弹和火箭的向量 | 14 |
| 2号牌和王牌的数量 | 10 |
| 编码历史叫牌动作的向量 | 12 |
| 总计 | 128 |
这些特征被用来在叫牌阶段为神经网络提供输入,帮助模型决定是否叫牌。每个特征都针对玩家的手牌进行了详细的编码,包括不同牌型的计数和历史叫牌行为。这些信息对于AI决定是否叫牌至关重要。
在扑克中,常见的用于衡量策略的指标是可利用度。然而,在斗地主中,由于具有三个玩家,同时有很大的状态、动作空间,因此计算可利用度是十分棘手的。为了评估算法性能,作者让算法之间进行对战。具体来说,对于两种竞争算法的 A 和 B 和给定的牌型,它们将首先分别作为地主和农民的位置。对局结束后,双方交换位置,并且牌型不变。
5. 研究背景简介
5.1 简介
游戏常常作为人工智能的基准,因为它们是许多现实世界问题的抽象。在完美信息游戏中已经取得了显著的成就。例如,AlphaGo(Silver et al., 2016)、AlphaZero(Silver et al., 2018)和MuZero(Schrittwieser et al., 2020)在围棋游戏中确立了最先进的性能。最近的研究已经发展到更具挑战性的不完美信息游戏,在这个环境中,代理与其他代理在部分可观察的环境中竞争或合作。
从两玩家游戏,如简单的Leduc Hold’em 和限注/无限制德州扑克(Zinkevich et al., 2008; Heinrich & Silver, 2016; Moravcˇ´ık et al., 2017; Brown & Sandholm, 2018),到多玩家游戏,如多玩家德州扑克(Brown & Sandholm, 2019b)、星际争霸(Vinyals et al., 2019)、DOTA(Berner et al., 2019)、Hanabi(Lerer et al., 2020)、麻将(Li et al., 2020a)、王者荣耀(Ye et al., 2020b;a)和 No-Press Diplomacy(Gray et al., 2020),已经取得了令人鼓舞的进展。
这项工作的目标是构建斗地主(又称为打庄家)的AI程序,这是中国最受欢迎的卡牌游戏,每天有数亿活跃玩家。斗地主有两个有趣的特性,给AI系统带来了巨大的挑战。首先,斗地主中的玩家需要在一个有限通信的部分可观察环境中与他人竞争和合作。具体来说,两个农民玩家将组成一个团队与地主玩家对抗。流行的扑克游戏算法,如反事实遗憾最小化(CFR)(Zinkevich et al., 2008)及其变体,在这种复杂的三玩家设置中通常不健全。其次,斗地主有大量的信息集,平均大小非常大,并且由于牌的组合,动作空间非常复杂且庞大,最多有10^4种可能的动作(Zha et al., 2019a)。与德州扑克不同,斗地主的动作不容易抽象化,这使得搜索计算成本高昂,常用的强化学习算法效果不佳。深度Q学习(DQN)(Mnih et al., 2015)在非常大的动作空间中存在高估问题(Zahavy et al., 2018);策略梯度方法,如A3C(Mnih et al., 2016),不能利用斗地主中的动作特征,因此不能像DQN那样自然地泛化到未见过的动作(Dulac-Arnold et al., 2015)。不足为奇的是,先前的研究表明DQN和A3C在斗地主中无法取得令人满意的进展。在(You et al., 2019)中,即使经过二十天的训练,DQN和A3C对抗简单基于规则的代理的胜率还不到20%;(Zha et al., 2019a)中的DQN仅略好于随机均匀抽样合法动作的代理。
在构建斗地主人工智能(AI)的研究中,已经尝试了多种方法。其中,组合Q网络(CQN)通过将动作分解为两个阶段来减少动作空间,但这种方法依赖于人类的启发式规则,并且在实际应用中表现并不理想,即使经过长时间的训练也无法击败简单的启发式规则。DeltaDou 是第一个达到人类水平的斗地主AI,它采用贝叶斯方法来推断隐藏信息,并通过采样对手的动作来进行决策。然而,DeltaDou 依赖于基于启发式规则预训练的踢球网络,这在斗地主中是一个重要的角色,且不容易抽象化。此外,DeltaDou 的训练过程非常耗时,需要两个多月的时间。
DouZero 是一个更为简单而有效的斗地主AI系统,它不依赖于人类知识的抽象,而是通过深度神经网络、动作编码和并行Actor来增强传统的蒙特卡洛方法。DouZero 在仅配备48个内核和4个1080Ti GPU的单台服务器上从零开始训练,很快就超越了CQN和启发式规则,成为了最强大的斗地主人工智能系统。DouZero 的成功证明了经典的蒙特卡洛方法在大型和复杂的纸牌游戏中的强大性能,并且它的训练过程相对经济,不需要昂贵的计算资源。
最近的研究还提出了通过引入对手建模和教练引导学习来改进DouZero,这些技术进一步提升了AI的性能,并加快了训练过程。这些研究表明,通过结合深度学习和蒙特卡洛方法,可以有效地处理斗地主中的大规模状态和动作空间,同时减少对人类启发式规则的依赖。这些进展为未来在解决多智能体学习、稀疏奖励、复杂动作空间和不完全信息方面的研究提供了新的方向。
在这项工作中,我们介绍了DouZero,这是一个概念上简单但有效的斗地主人工智能系统,它不依赖于状态/动作空间的抽象或任何人类知识。DouZero通过深度神经网络、动作编码和并行Actor增强了传统的蒙特卡洛方法(Sutton & Barto, 2018)。DouZero具有两个理想属性:
- 与DQN不同,它不易受到高估偏差的影响。
- 通过将动作编码到卡片矩阵中,它可以自然地泛化在整个训练过程中不经常看到的动作。
这两个属性对于处理斗地主庞大而复杂的动作空间至关重要。与许多树搜索算法不同,DouZero基于采样,这使我们能够使用复杂的神经架构,并在相同的计算资源下每秒生成更多的数据。与之前许多依赖于特定领域抽象的扑克AI研究不同,DouZero不需要任何领域知识或底层动态知识。在只有48个核心和四个1080Ti GPU的单台服务器上从零开始训练,DouZero在半天内超越了CQN和启发式规则,在两天内击败了我们内部的监督学习代理,并在十天内超过了DeltaDou。广泛的评估表明,DouZero是迄今为止最强大的斗地主人工智能系统。
通过构建DouZero系统,我们展示了经典的蒙特卡洛方法可以在大规模和复杂的卡牌游戏中提供强大的结果,这些游戏需要在巨大的状态和动作空间中进行竞争和合作的推理。我们注意到,一些研究也发现蒙特卡洛方法可以实现竞争性能(Mania et al., 2018; Zha et al., 2021a)并在稀疏奖励设置中提供帮助(Guo et al., 2018; Zha et al., 2021b)。与这些专注于简单和小规模环境的研究不同,我们证明了蒙特卡洛方法在大规模卡牌游戏上的强劲表现。我们希望这一见解能够促进未来在解决多智能体学习、稀疏奖励、复杂动作空间和不完全信息方面的研究,我们已经发布了我们的环境和训练代码。与许多需要数千个CPU进行训练的扑克AI系统不同,例如DeepStack(Moravčík et al., 2017)和Libratus(Brown & Sandholm, 2018),DouZero实现了一个合理的实验流程,它只需要在单个GPU服务器上进行几天的训练,这对大多数研究实验室来说是负担得起的。我们希望它能激励该领域的未来研究,并作为一个强有力的基线。
5.2 斗地主背景
斗地主是一种流行的三人卡牌游戏,易于学习但难以精通。它在中国吸引了数以亿计的玩家,每年都会举办许多比赛。这是一种脱手型游戏,玩家的目标是在其他玩家之前清空手中的所有牌。两个农民玩家组成一队对抗另一个地主玩家。如果农民中的任何一个玩家首先没有牌了,农民队就赢了。每一局游戏都有一个叫牌阶段,玩家根据手牌的强弱叫地主,以及一个出牌阶段,玩家轮流出牌。
我们在附录A中提供了详细介绍。
斗地主仍然是多智能体强化学习一个未解决的基准(Zha et al., 2019a; Terry et al., 2020)。
两个有趣的特性使得斗地主特别难以解决。首先,农民需要合作对抗地主。例如,图10显示了一个典型情况,底部的农民可以选择打出一张小单牌来帮助右侧的农民获胜。其次,由于牌的组合,斗地主有一个复杂且庞大的动作空间。有27,472种可能的组合,不同的组合子集对于不同的手牌是合法的。图1展示了一个手牌示例,它有391种合法组合,包括单张、对子、三张、炸弹、飞机、四带二等。动作空间不容易抽象化,因为不当出牌可能会破坏其他牌型并直接导致输掉游戏。因此,构建斗地主AI具有挑战性,因为斗地主中的玩家需要在巨大的动作空间中进行竞争和合作的推理。
5.3 深度蒙特卡洛方法
在这一部分,我们重新审视蒙特卡洛(MC)方法,并介绍深度蒙特卡洛(DMC),它通过深度神经网络对MC进行泛化,用于函数逼近。然后我们讨论并比较DMC与策略梯度方法(例如A3C)和DQN,这些方法在斗地主中被证明是失败的(You et al., 2019; Zha et al., 2019a)。
5.3.1 蒙特卡洛方法与深度神经网络
蒙特卡洛(MC)方法是传统的基于平均样本回报的强化学习算法(Sutton & Barto, 2018)。MC方法专为情景任务设计,其中经历可以被划分为情景,并且所有情景最终都会结束。为了优化策略π,可以使用每次访问MC来估计Q表Q(s, a),通过迭代执行以下程序:
- 使用π生成一个情景。
- 对于情景中出现的每个s, a,计算并更新Q(s, a),使用所有关于s, a的样本的平均回报。
- 对于情景中的每个s,π(s) ← arg max_a Q(s, a)。
第2步中的平均回报通常是通过折扣累积奖励获得的。与依赖自举的Q学习不同,MC方法直接近似目标Q值。在第1步中,我们可以使用epsilon-greedy来平衡探索和利用。上述程序可以自然地与深度神经网络结合,从而产生深度蒙特卡洛(DMC)。具体来说,我们可以用神经网络替换Q表,并使用均方误差(MSE)在第2步更新Q网络。
虽然MC方法被批评为无法处理不完整的情景,并且由于高方差而被认为效率低下(Sutton & Barto, 2018),但DMC非常适合斗地主。首先,斗地主是一个情景任务,所以我们不需要处理不完整的情景。其次,DMC可以很容易地并行化,以每秒高效生成许多样本,从而缓解高方差问题。
5.3.2 与策略梯度方法的比较
策略梯度方法,如REINFORCE(Williams, 1992)、A3C(Mnih et al., 2016)、PPO(Schulman et al., 2017)和IMPALA(Espeholt et al., 2018),在强化学习中非常流行。它们的目标是直接使用梯度下降对策略进行建模和优化。在策略梯度方法中,我们通常使用类似分类器的函数逼近器,其中输出随动作数量线性缩放。尽管策略梯度方法在大型动作空间中表现良好,但它们无法利用动作特征来推理以前未见过的动作(Dulac-Arnold et al., 2015)。在实践中,斗地主中的动作可以自然地编码成卡片矩阵,这对于推理至关重要。例如,如果智能体因为选择了一个很好的踢球者而获得了动作3KKK的奖励,那么它也可以将这些知识推广到将来未见过的动作,例如3JJJ。这一属性对于处理非常大的动作空间和加速学习至关重要,因为许多动作在模拟数据中并不常见。
深度蒙特卡洛(DMC)能够通过将动作特征作为输入,自然地利用这些特征来泛化到未见过的动作。虽然当动作规模较大时,它可能具有较高的执行复杂性,但在斗地主的大多数状态下,只有一部分动作是合法的,因此我们不需要遍历所有动作。因此,DMC总体上是斗地主的一个高效算法。虽然有可能将动作特征引入到演员-评论家框架中(例如,通过使用Q网络作为评论家),但类似分类器的演员仍然会受到大型动作空间的影响。我们的初步实验证实,这种策略并不是很有效(见图7)。
5.3.3 与深度Q学习的比较
最受欢迎的基于价值的算法是深度Q学习(DQN)(Mnih et al., 2015),它是一种自举方法,根据下一步的Q值更新当前的Q值。尽管DMC和DQN都近似Q值,但在斗地主中DMC有几个优势。
首先,DQN在近似最大动作值时引起的高估偏差在使用函数逼近时难以控制(Thrun & Schwartz, 1993; Hasselt, 2010),并且在非常大的动作空间中变得更加明显(Zahavy et al., 2018)。虽然一些技术,如双Q学习(van Hasselt et al., 2016)和经验回放(Lin, 1992),可能会缓解这个问题,我们发现在实践中DQN非常不稳定,经常在斗地主中发散。而蒙特卡洛估计由于不使用自举直接近似真实值,所以不易受到偏差的影响(Sutton & Barto, 2018)。
其次,斗地主是一个具有长远视野和稀疏奖励的任务,即代理需要经历一连串的状态而没有反馈,只有在游戏结束时才会产生非零奖励。这可能会减慢Q学习的收敛速度,因为估计当前状态的Q值需要等到下一个状态的价值接近其真实值(Szepesvari, 2009; Beleznay et al., 1999)。与DQN不同,蒙特卡洛估计的收敛不受情景长度的影响,因为它直接近似真实的目标值。
第三,由于动作空间大且变化多端,在斗地主中有效实现DQN是不方便的。具体来说,DQN在每次更新步骤中的最大操作将导致高计算成本,因为它需要遍历所有合法动作在一个成本很高的深度Q网络上。此外,不同状态下的合法动作不同,这使得批量学习变得不方便。因此,我们发现DQN在实际时间上太慢了。虽然蒙特卡洛方法可能会受到高方差的影响(Sutton & Barto, 2018),这意味着它可能需要更多的样本来收敛,但它可以轻易地并行化,每秒生成数千个样本来缓解高方差问题并加速训练。我们发现DMC的高方差被其提供的可扩展性大大抵消了,DMC在实际时间上非常高效。