深度强化学习简介
欢迎来到人工智能中最引人入胜的话题:深度强化学习。
深度强化学习是一种让机器通过尝试和学习来掌握如何做出最好决策的方法。简单来说,它教会机器通过实践来学习和提高。
自 2013 年 Deep Q-Learning 论文以来,已经看到了很多突破。从击败世界上最优秀的 Dota2 玩家的OpenAI 5 到 Dexterity 项目 , 我们处在深度强化学习研究的激动人心的时刻。

本文是深度强化学习课程的第一个单元,这是一门从入门到精通的免费课程,您将在其中学习使用著名的深度 RL 库(如 Stable Baselines3、RL Baselines3 Zoo 和 RLlib)的理论和实践。
在深入探索深度强化学习智能体的世界之前,理解本章介绍的基础知识点是至关重要的。目标是建立一个坚实的理论和实践基础。
什么是强化学习?
要了解强化学习,让我们从大局出发来看。
要了解强化学习(Reinforcement Learning,RL), 首先要从宏观角度入手。
强化学习背后的想法是,智能体(agent)将通过与环境交互(通过反复试验和试错)并接收奖励(积极或消极)作为执动作的反馈来从环境中学习,并在与环境的交互中不断习得自然经验。
例如,想象一下把一个小男孩放在一个他从未玩过的电子游戏前,给他一个控制器,让他一个呆着自己玩。

小男孩会通过按下游戏手柄的右键(动作)与电子游戏(环境)互动。当他获得一枚金币并因此获得+1的奖励时。他就会明白这是一个积极的反馈,这样,他便知道在这款游戏中要努力获取金币。
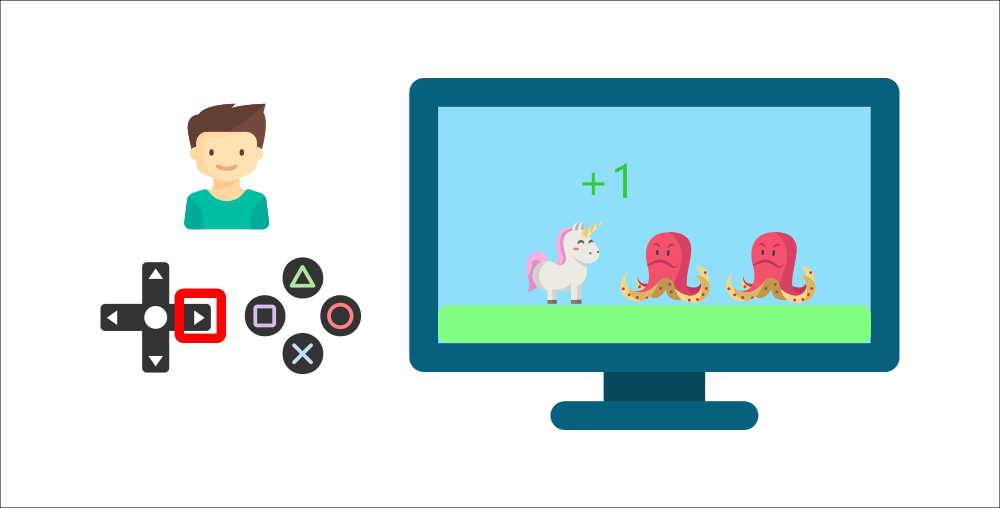
但随后,他再次按下右键(动作),碰到了敌人,他死了,得到 -1 的奖励。
然而,当他再次按下右键时,因为撞到了一个敌人, 所以游戏角色死亡了,这是一个 -1 的奖励,如图1-5所示。
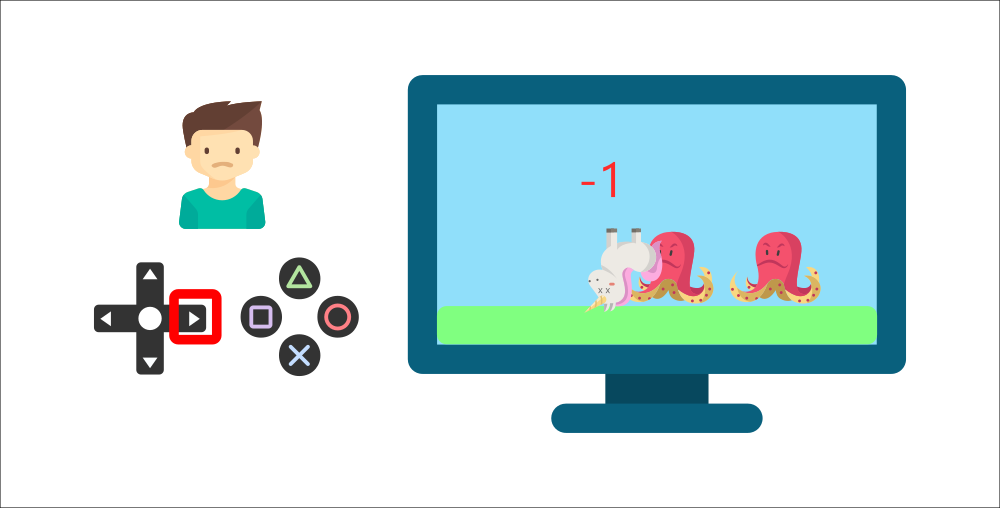
通过试错与环境互动,你的弟弟明白了他需要在这个环境中获得硬币,但要避开敌人。
通过不断的试验和与环境的交互,小男孩逐渐明白:在这个游戏环境中,角色需要在获取金币的同时避免敌人的攻击。所以即使在没有外部指导的情况下,小男孩也会变得越来越擅长这款游戏。这正是人类和动物通过交互进行学习的方式,而强化学习也就是一种从动作交互中学习的方法。
正式的定义
我们现在采取一个正式的定义:
强化学习是一种解决控制任务(也被成为决策任务)的框架,在其过程中可以构建智能体,这些智能体能够与环境进行试错交互,并接收奖励(积极或消极奖励)作为唯一的反馈,不断地从环境中学习。
⇒ 但是强化学习是如何工作的?
强化学习框架
强化学习过程
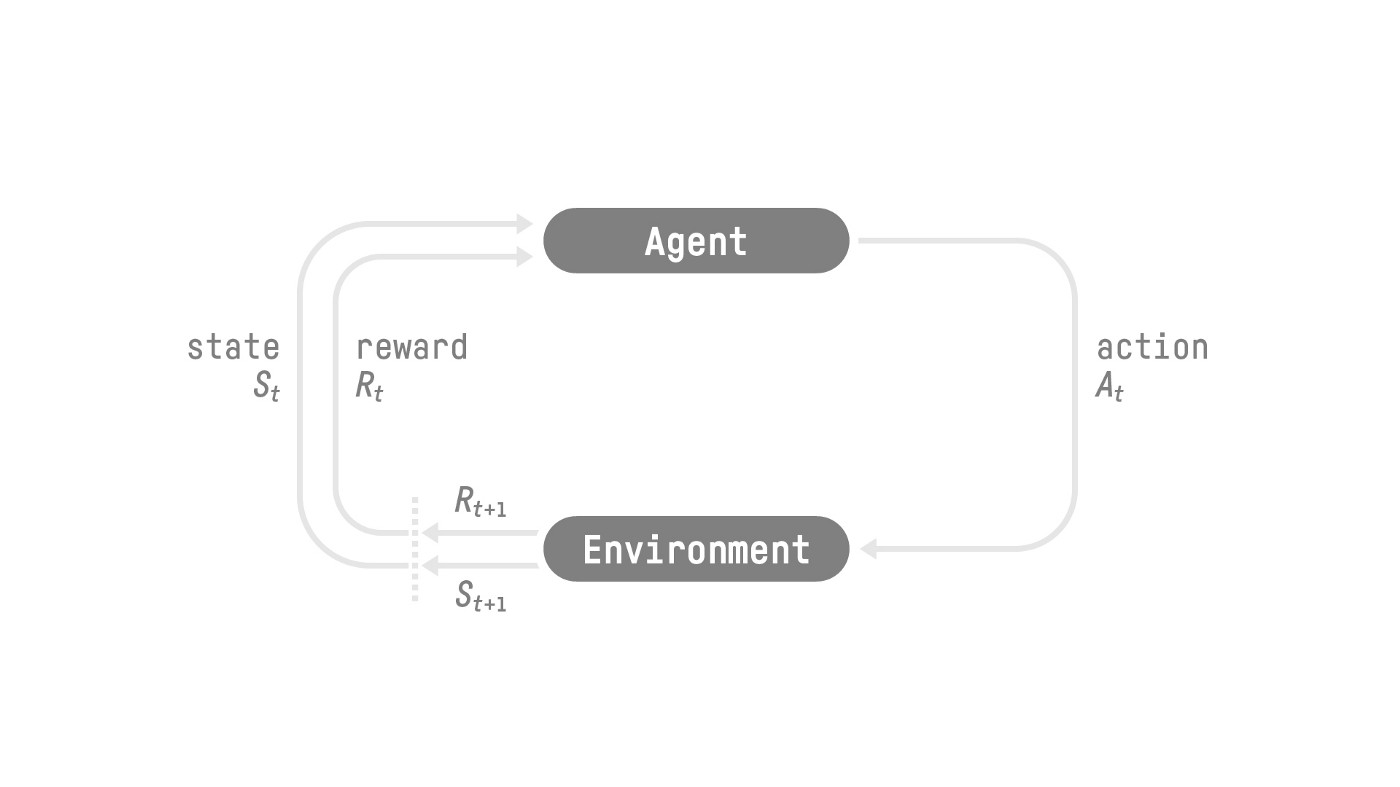
资料来源:Reinforcement Learning: An Introduction, Richard Sutton and Andrew G. Barto
为了更好地理解强化学习过程,想象一下智能体学习玩游戏的过程,如图1-6所示。
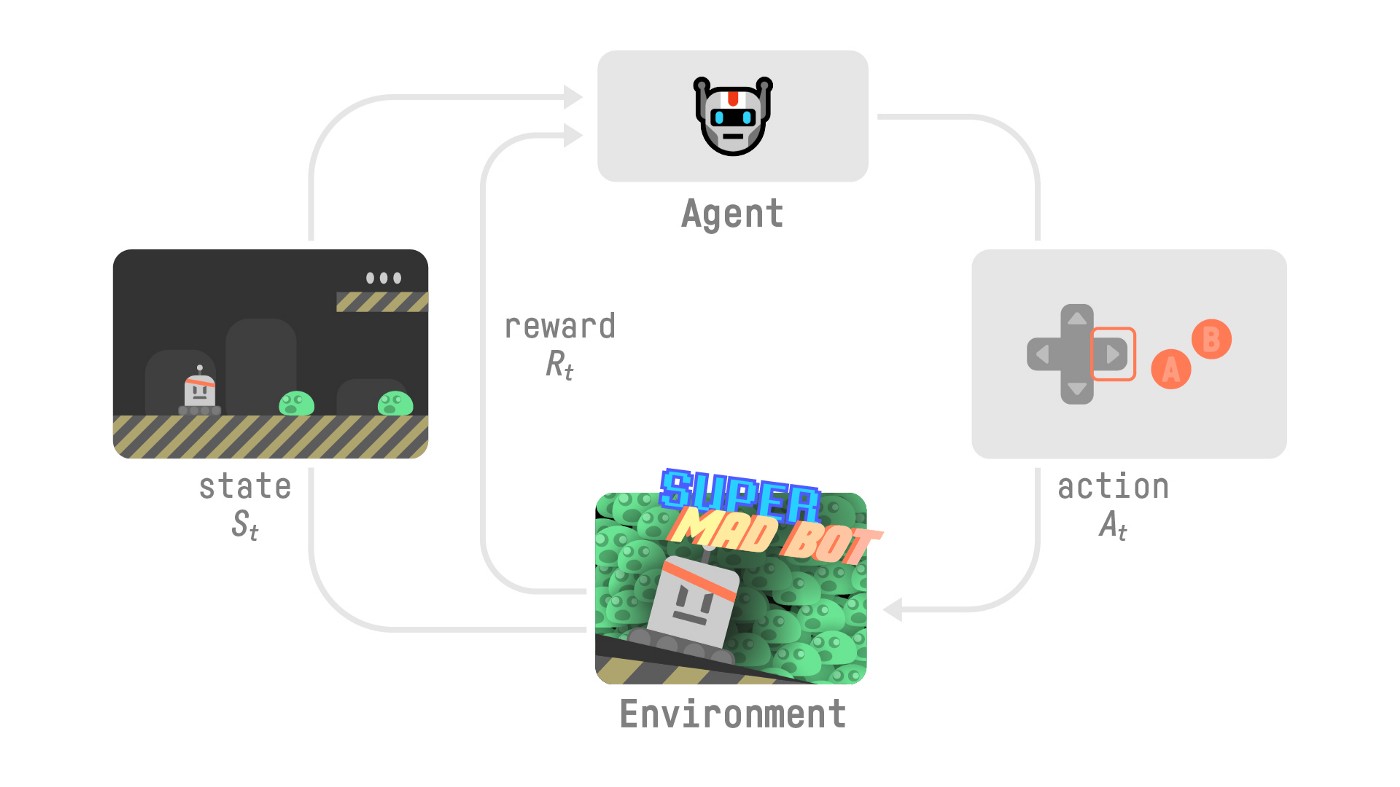
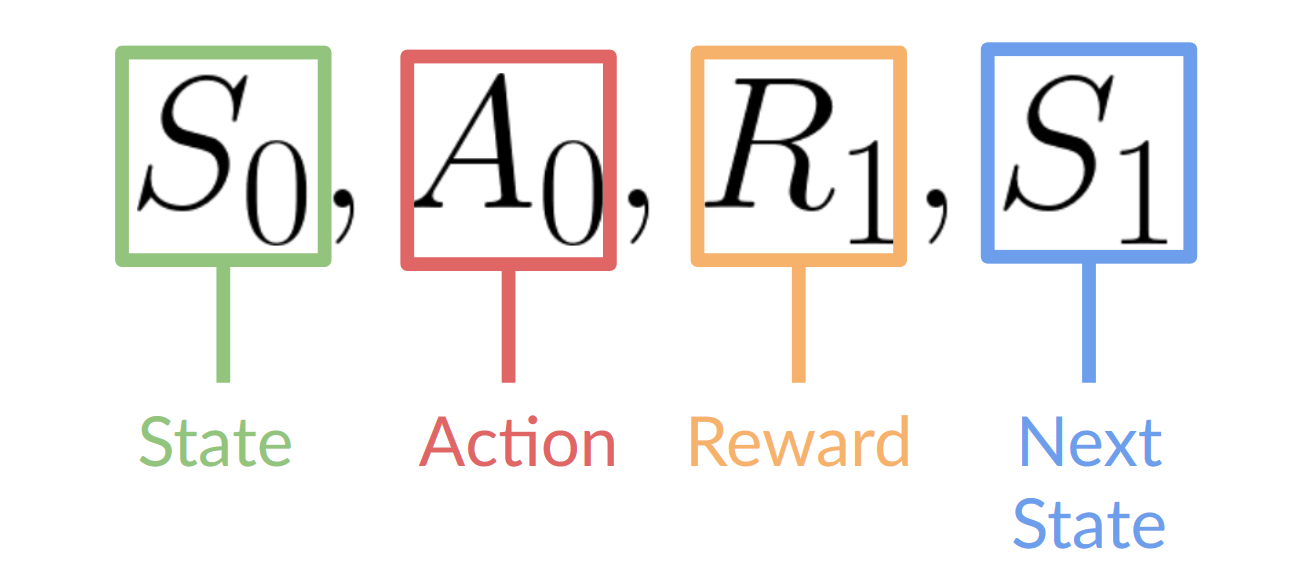
- 智能体接收来自环境的状态 $S_0$ —— 游戏的第一帧(环境)。
- 基于状态$S_0$, 智能体采取动作$A_0$ — — 智能体将向右移动。
- 环境进入新状态$S_1$—— 游戏进入下一帧。
- 环境给予给智能体一些奖励$R_1$——完成任务(正奖励+1)。
强化学习过程会循环输出一系列状态、动作、奖励和下一个状态,如图1-7所示。
智能体的目标是最大化其累积奖励, 即最大化期望回报。
奖励假设:强化学习的中心思想
⇒ 为什么智能体的目标是期望收益最大化?
因为强化学习是基于奖励假设的,即所有目标都可以描述为期望回报(期望累积奖励)的最大化。
因此,在强化学习中,为了找到最优的行动方案,核心目标是学习如何选择动作以最大化期望累积奖励。
马尔可夫性质
强化学习过程也被称为马尔可夫决策过程(Markov Decision Process,MDP)。
在本书的后续章节中,将深入探讨马尔可夫性质。不过,如果想现在就掌握一些核心要点,可以参考并尝试理解以下简明易懂的解释:马尔可夫性质意味着,智能体在决策时只需考虑当前状态,而无需回顾所有过去的状态和动作。这就像玩棋类游戏,通常只需要根据眼前的棋盘局势来计划下一步,而不必回溯先前每一步的走棋。
观测/状态空间
观测,或者说状态,是智能体从环境中获得的信息。以视频游戏为例,这个观测可以是一帧画面(即屏幕截图);而在涉及交易的情境下,这个观测可能是某支股票的价值等数据。
观测 和 状态之间有区别 :
- 状态 s:是在完全可观测的环境中对世界状态的完整描述(没有隐藏信息)。

在国际象棋游戏中,由于可以访问整个棋盘的信息,因此从环境中接收状态,如图1-8所示。换句话说,环境是可以被完全观测到的。
- • 观测o:在部分可观测的环境中对状态的部分描述。

在游戏《超级马里奥》中,处于一个部分可观测的环境。由于只看到了关卡的一部分,所以接收的是一个观测,如图1-9所示。
在本章中,虽然用“状态”一词同时指代状态和观测,但在具体实现过程中,会明确区分这两者。
回顾一下:

动作空间
动作空间是环境中所有可能动作的集合。动作可以来自离散或连续空间:
- 离散空间:可能动作的数量是有限的。
在《超级玛丽》中,只有跳跃,蹲着,左移,右移四个动作。
- 连续空间: 可能采取动作的数量是无限的。

如图1-12所示自动驾驶汽车智能体有无数种可能的动作,例如左转20°、21.1°、21.2°、鸣喇叭、右转20°……;
回顾一下:

这些信息在将来选择强化学习算法时非常重要。
奖励和折扣
奖励是强化学习的基础,因为它是智能体所能接收到的唯一反馈,只有通过对奖励的判断,智能体才能知道它所采取的动作是否“正确”。
每个时间步的累积奖励可以写成如图1-14所示的形式。
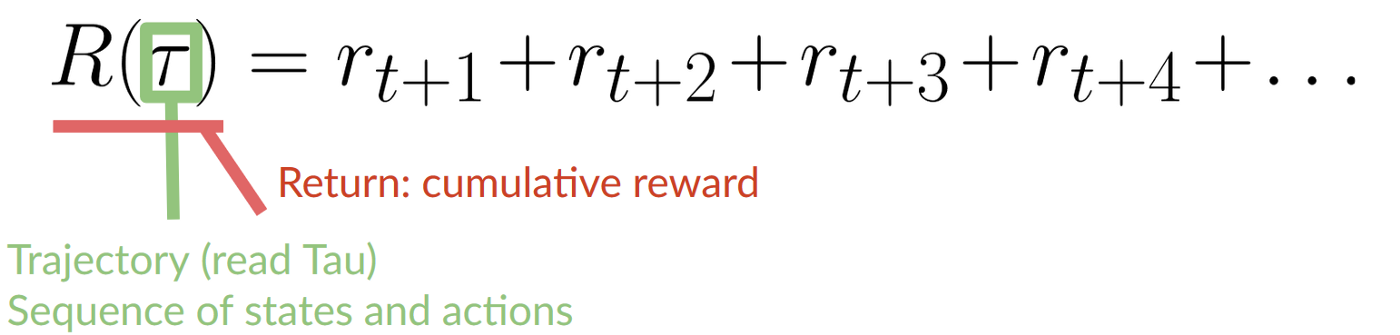
累积奖励等于该序列所有奖励的总和。
这就等同于1-15所示的公式。
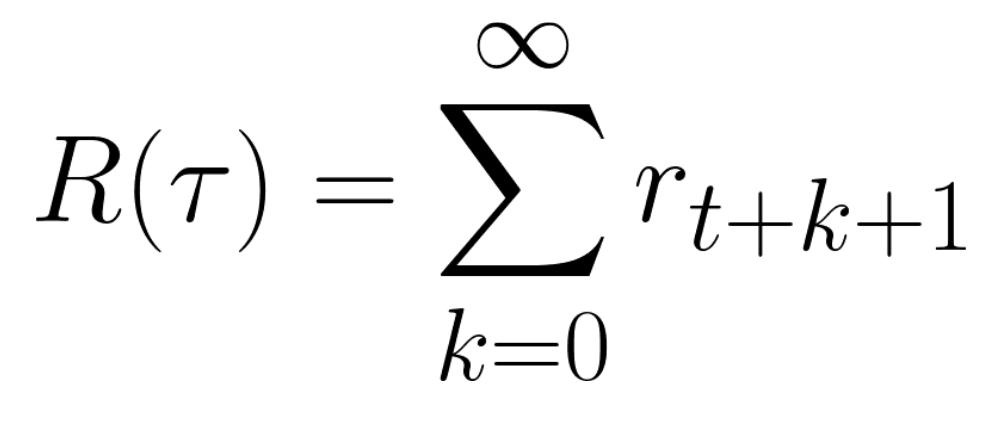
但在实际应用中,不能只是简单地累加奖励。这是因为游戏初期出现的奖励更可能发生,因此相对于长期的未来奖励,它们具有更强的可预测性。
假设智能体是一只小老鼠,每一步可以移动一个方块,而对手是一只猫(它也可以移动),如图1-16所示。老鼠的目标是在被猫吃掉之前吃到最多的奶酪。

正如在图中所看到的,吃掉老鼠附近的奶酪的可能性比吃靠近猫的奶酪的可能性更大(小老鼠离猫越近,它就越危险)。
因此,尽管猫周围的奖励可能更大(奶酪更丰富),但由于无法确定是否能成功获取这些奖励,因此相应的折扣率也会更高。
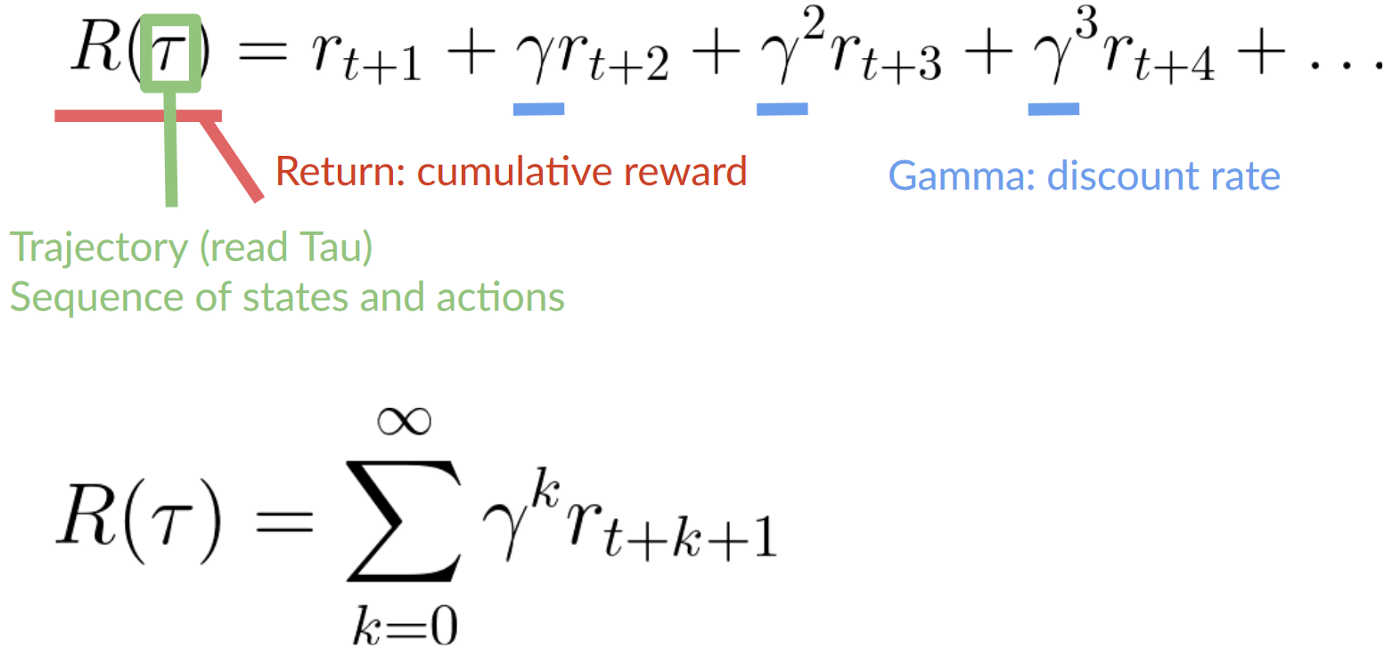
为了折扣奖励,需要这样做:
- 定义一个称为 gamma 的折扣率,它必须介于 0 和 1 之间, 大多数时候介于0.99 和 0.95之间。
- gamma越大,折扣越小。这意味着智能体更关心长期回报。
- gamma 越小,折扣越大。这意味着智能体更关心短期奖励(最近的奶酪)。
- 然后,每个奖励将通过 gamma 时间步数的指数来打折扣。随着时间步数的增加,猫离老鼠越来越近,因此未来奖励发生的可能性越来越小。
折扣期望累积奖励如图1-17中的公式所示。
任务类型
任务是一个强化学习问题的实例,目前有两种类型的任务:回合制任务和持续性任务。
回合制任务
在回合制任务中,每个回合都有一个明确的起点和终点(即终止状态)。这样的回合由一系列的元素组成:状态、采取的动作、获得的奖励,以及随之而来的新状态。
例如在游戏《超级马里奥》中,新的回合从马里奥的启动开始,到被击倒或到达关卡终点时结束。
持续性任务
持续性任务是指那些永无止境、没有终止状态的任务。在这种任务中,智能体需要学会如何选择最佳行动,并且必须持续与环境进行交互。
以进行自动化股票交易的智能体为例,如图1-19所展示,这种任务没有明确的起点和终点。这样的智能体会持续运行,直至人工决定将其停止。
探索/利用 平衡
在深入探索强化学习的各种解决方法前,有一个关键问题需先行讨论,即探索与利用之间的权衡:
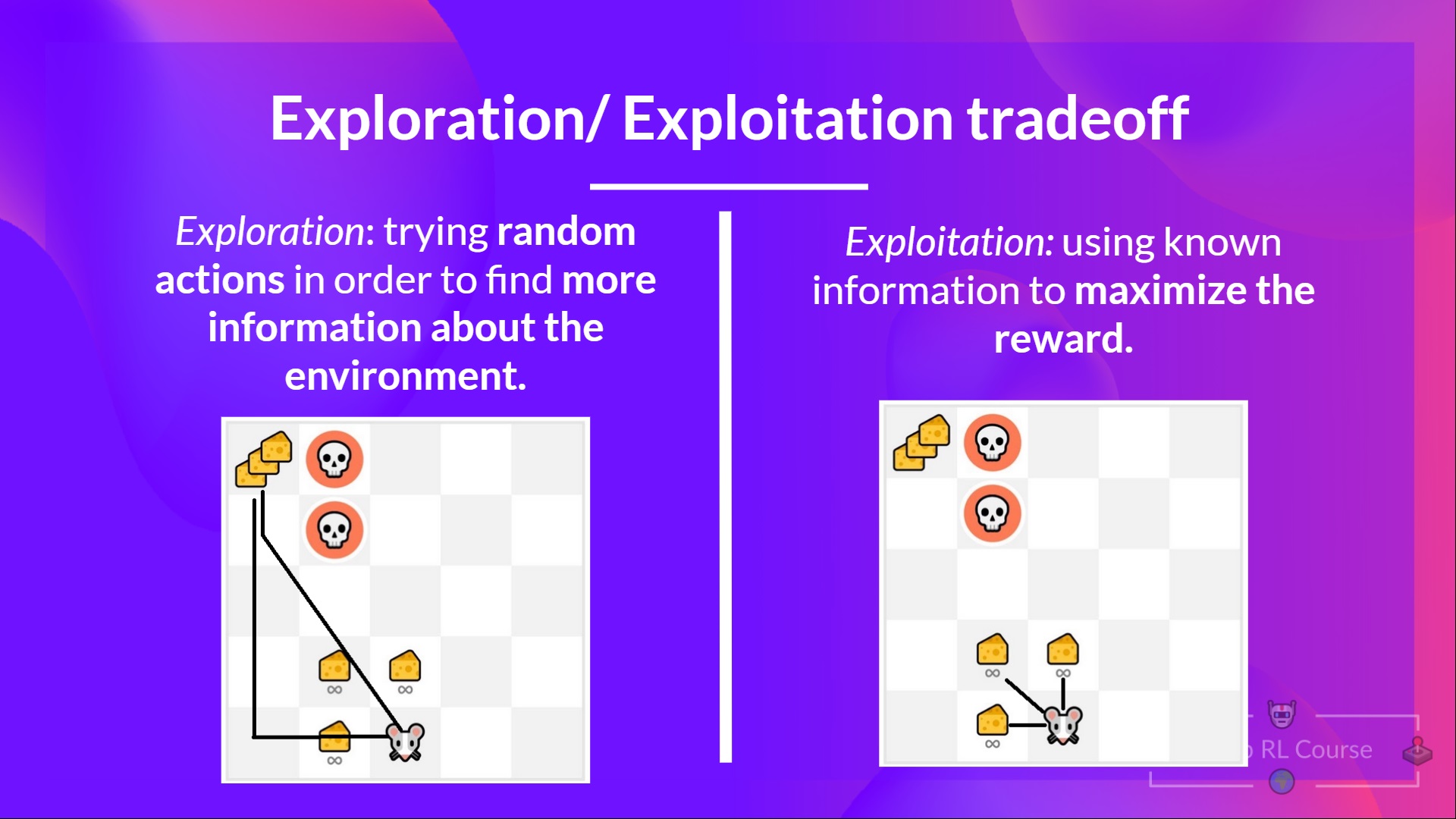
• 探索指的是智能体通过尝试不同的随机动作来探查环境,目的是获取关于该环境的更多信息。
• 利用指的是智能体使用已经获得的信息来最大化其获得的奖励。
记住,强化学习智能体的目标是最大化期望累积奖励。然而,这可能会陷入一个常见的陷阱。
下面举个例子,如图1-21所示。
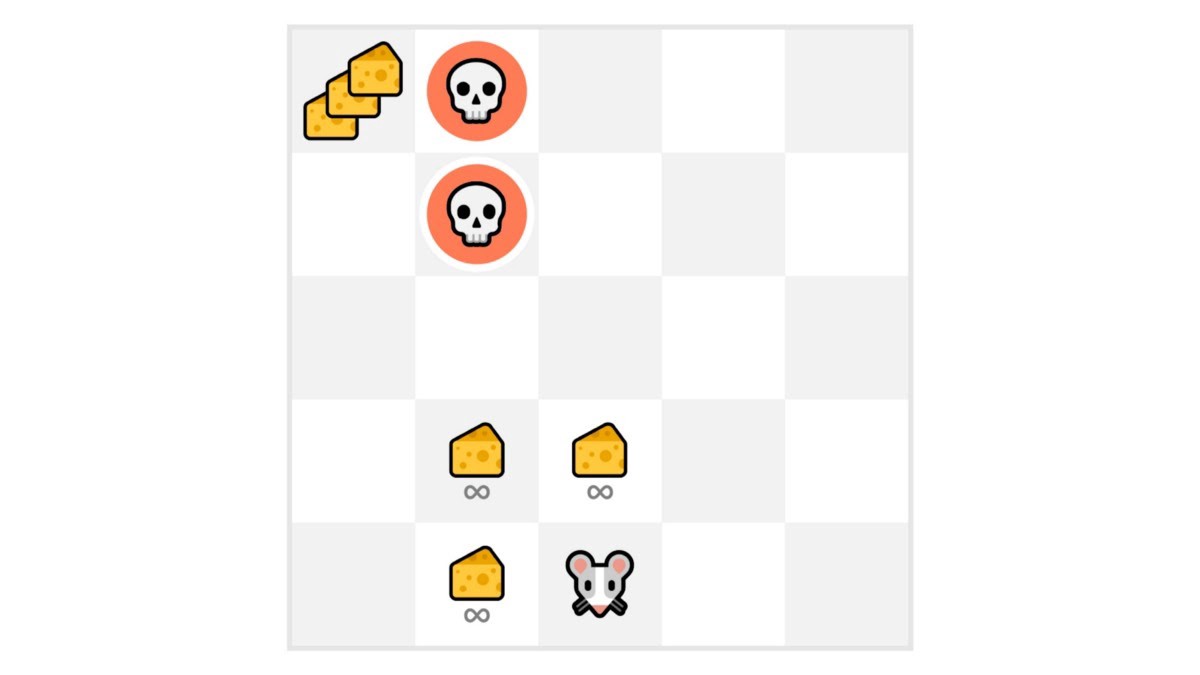
在这个游戏中,小老鼠可以拥有无限数量的小奶酪(每个+1)。但是在迷宫的顶端,有一个大奶酪(+1000)。这时如果只专注于利用,那么智能体将永远无法取得巨量奶酪。相反,小老鼠只会利用最近的奖励来源,即使这个来源很小(利用)。但如果智能体进行一点点探索,那么它就可能发现大奖励(大奶酪)。
这种在探索新策略和利用已有知识之间寻求平衡的过程,正是前文提到的‘探索/利用权衡’。有效处理这种权衡,需要制定合适的规则和策略。在本书后续章节中,将详细探讨如何有效地实现这种平衡,包括不同的方法和策略。
如果还是一头雾水,可以考虑现实中的问题,比如挑选餐厅,如图1-22所示。
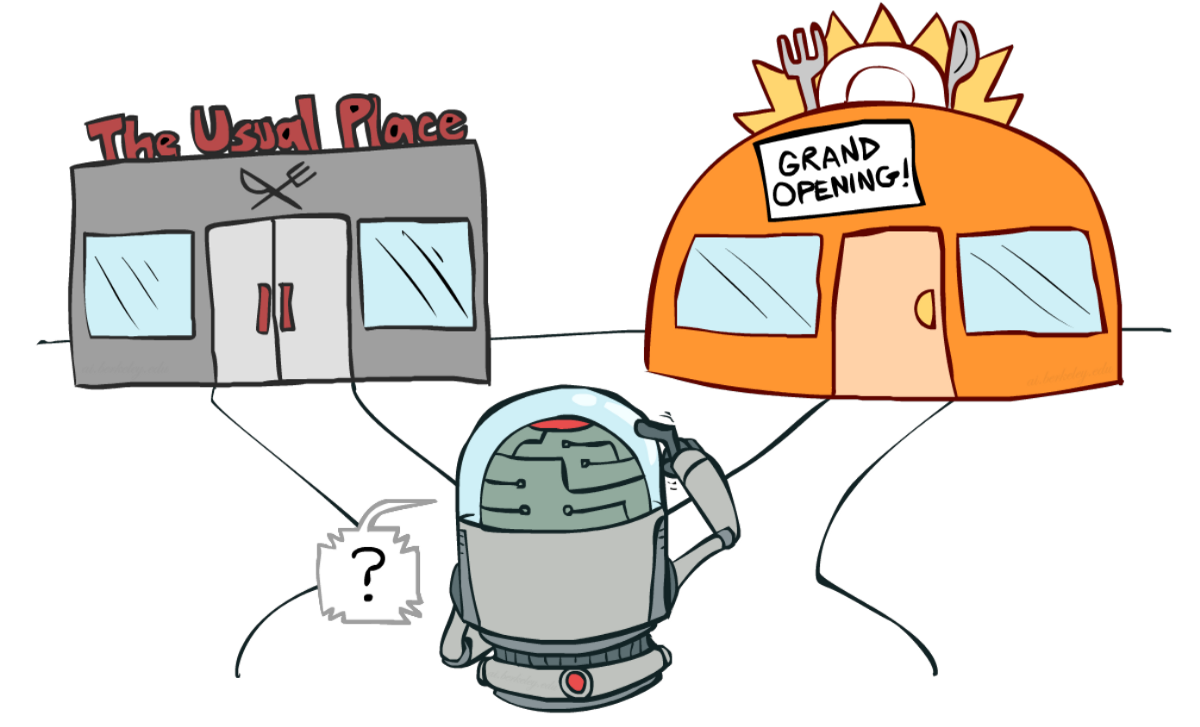
资料来源 伯克利人工智能课程
- 利用:每天都去同一家认为不错的餐厅,但是同时也冒着错过另一家更好的餐厅的风险。
- 探索:尝试以前从未去过的餐厅,有可能会有糟糕的体验,但也可能获得美妙的体验。
回顾一下:
解决 RL 问题的两种主要方法
现在已经学习了强化学习框架,那怎么解决强化学习问题呢?换句话说,怎么构建一个强化学习智能体,让其能够选择最大化期望累计奖励的动作呢?
策略 π:智能体的大脑
策略π是智能体的大脑,它是一个函数,能够在给定状态下决定采取什么动作。因此,它定义了智能体在特定时间应采取的动作,如图1-24所示。
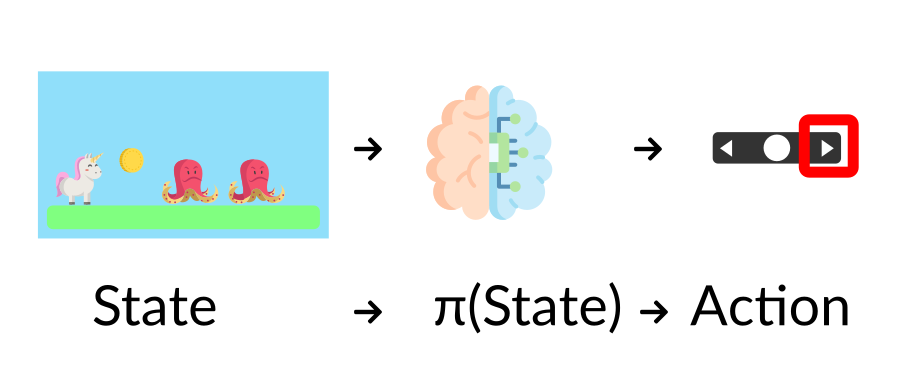
这个策略是想要学习的函数,目标是找到最优策略 π, 当智能体根据这个策略行动时返回最大期望回报。可以通过训练找到这个策略 π* 。
有两种方法可以训练智能体来找到这个最优策略 π:
- 直接型,通过教授智能体学习采取哪个动作,并给出当前状态,这就是*基于策略方法*;
- 间接型,通过教授智能体学习哪个状态更有价值,并且采取动作向更有价值的状态行进,这就是*基于价值的方法*。
基于策略的方法
基于策略的强化学习方法的目标是直接学习出一个策略函数。该策略函数将每个状态分别映射到对应的最适合的动作,即它定义了在特定状态下各种可能动作的概率分布。如图1-25所示,这种确定性策略为智能体在每一步骤中的行动提供了直接的指引。
目前有两类策略:
- 确定型策略,即给定一个状态,策略返回同样的动作,表达式如图1-26所示;
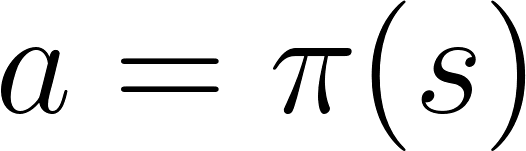
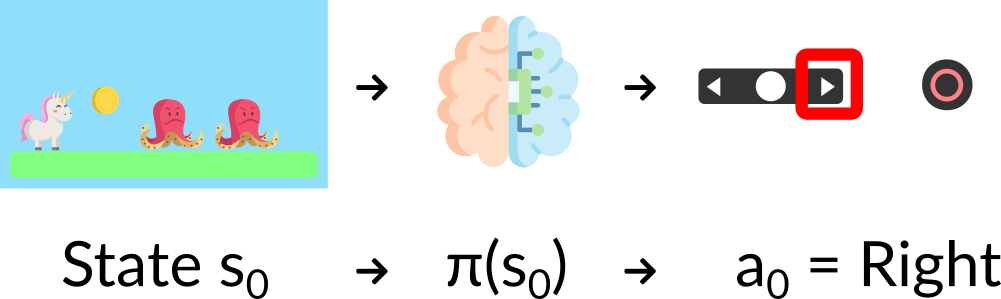
- 随机策略,即结果是一个动作的概率分布,表达式如图1-28所示,策略(动作|状态)=给定当前状态下动作集合的概率分布;

此时,给定一个初始状态,随机策略将输出该状态下可能动作的概率分布,如图1-29所示。
回顾一下:

基于价值的方法
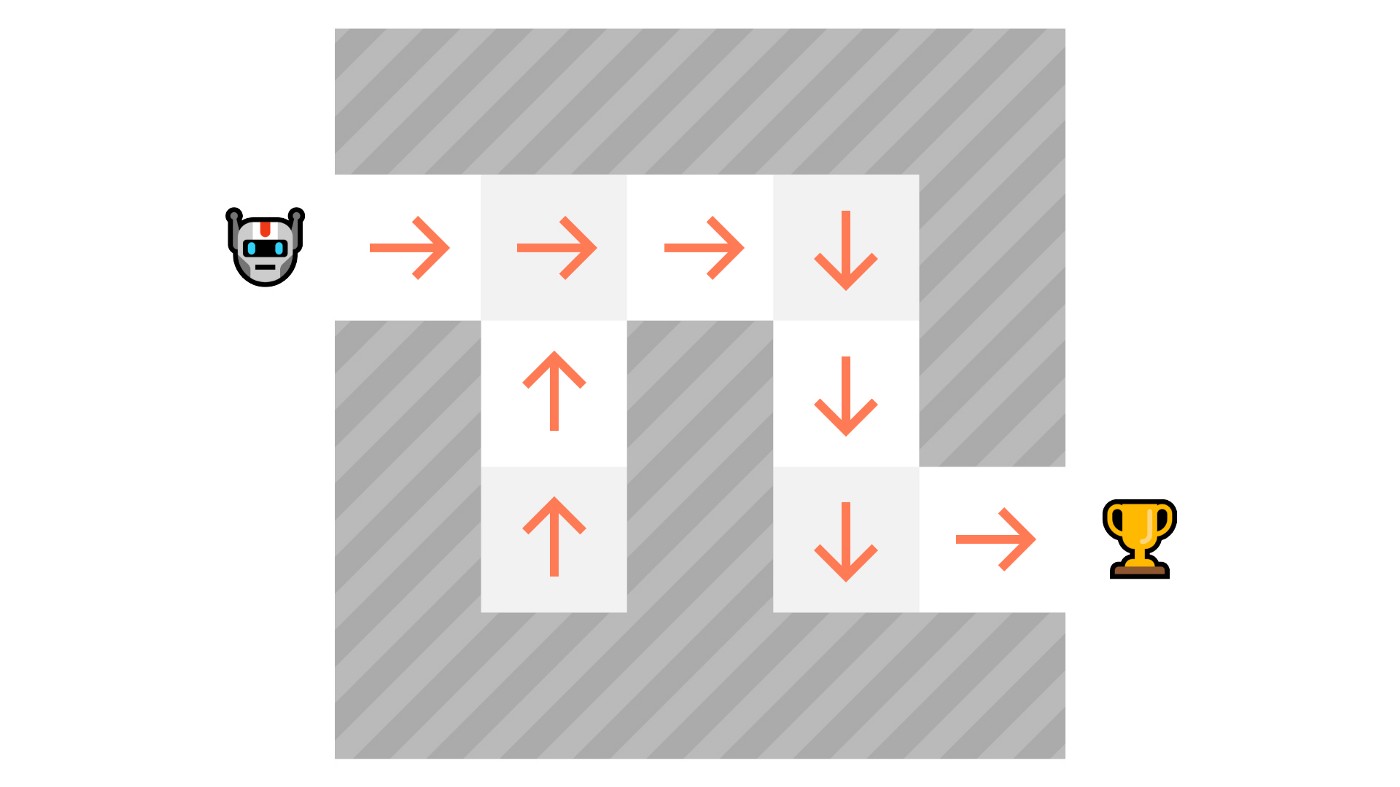
基于策略的强化学习方法,核心是训练一个策略函数;而基于价值的强化学习方法,核心是学习一个价值函数。这个价值函数的作用是把一个状态映射到对应的期望价值上。
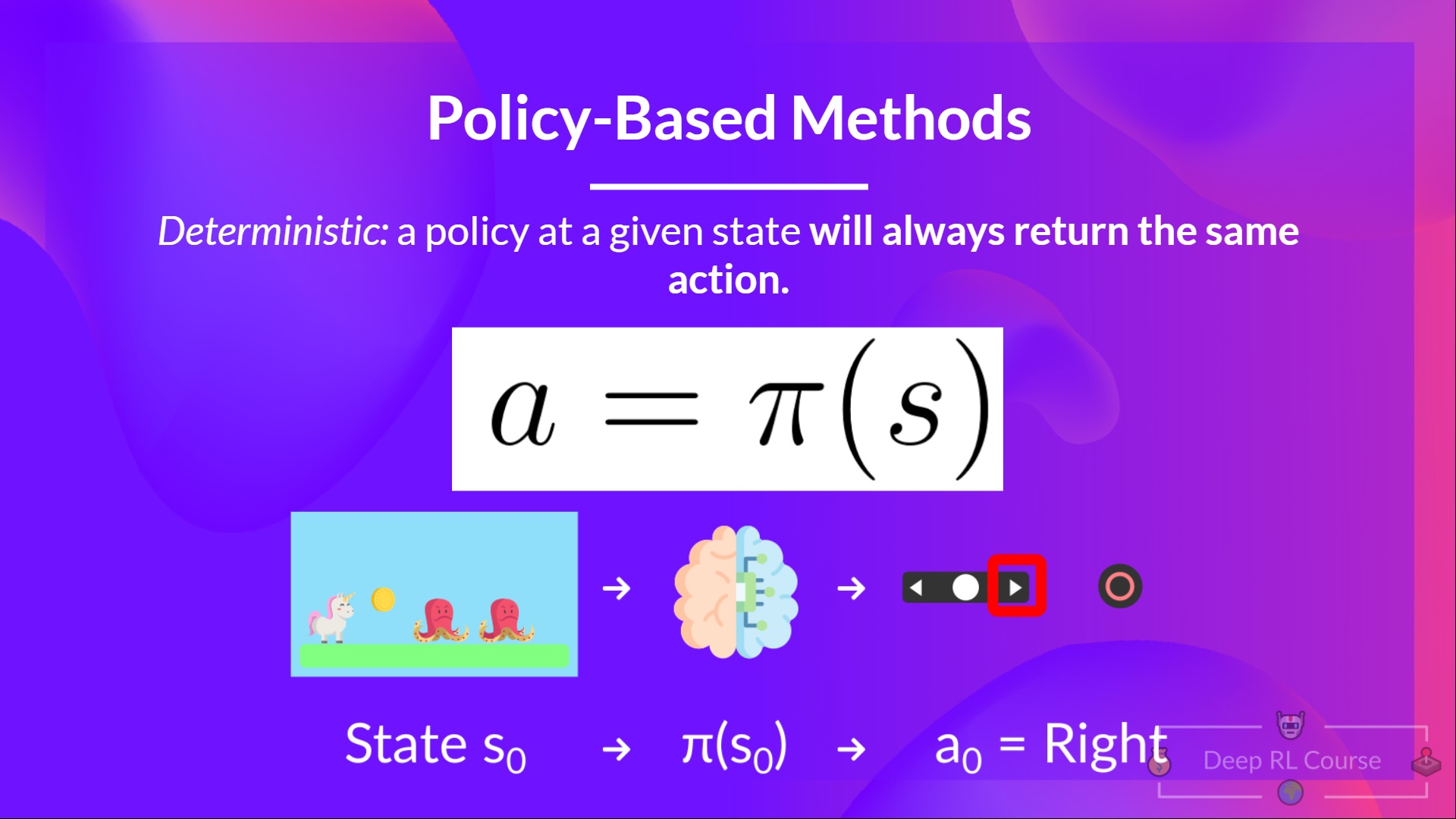
一个状态的价值,是指智能体从该状态开始,依照特定策略进行行动时,所能获得的期望折扣回报。换言之,根据策略执行动作表明,在那个特定的状态下,策略认为该状态具有较高的价值,正如图1-32所展示的那样。
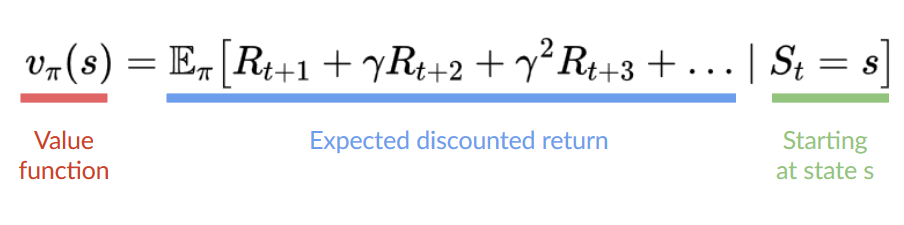
如图1-32所示,价值函数定义了每个可能状态的价值

由于有了价值函数,策略在每一步会选择由价值函数定义的最大值状态:-7、-6,随后是-5,依此类推,以实现目标。
回顾一下:


强化学习中的“深度”
迄今为止的讨论主要集中在强化学习本身。但是,何为深度强化学习?这个称谓源于深度神经网络在强化学习中的应用。它是通过利用深度神经网络来解决强化学习中的问题,从而赋予了这个领域“深度”的特征。
例如,在下一个章节中,将学习两种基于价值的算法:Q-learning(经典强化学习)和深度Q-learning。
两种算法不同之处在于,在第一种方法中,使用传统算法创建一个Q表格(Q-table),以帮助找到每个状态可采取的动作,在第二种方法中,将使用神经网络(近似Q值),如图1-36所示。
如果您不熟悉深度学习,您应该观看fastai Practical Deep Learning for Coders(free)
本章小结
总结一下,本章介绍了很多东西。
强化学习是一种从动作中学习的计算方法。这里构建了一个从环境中学习的智能体通过试错与它交互并接收奖励(积极或消极)作为反馈。
任何RL智能体的目标都是最大化其期望累积奖励(也称为期望回报),因为RL基于奖励假设,即所有目标都可以描述为最大化期望累积奖励。
RL过程是一个循环,该循环输出一个状态、动作、奖励和下一个状态的序列。
为了计算期望累积奖励(期望回报),这里对奖励进行折扣:较早出现的奖励(在游戏开始时)更有可能发生,因为它们比长期的未来奖励更可预测。
要解决强化学习(RL)问题,需找到最优策略。该策略相当于智能体的‘大脑’,指导在给定状态下应采取的动作。最优策略旨在提供最大化期望回报的动作选择。
有两种方法可以找到最佳策略:
直接训练策略:基于策略的方法。
训练一个价值函数来告诉智能体在每个状态下将获得的期望回报,并使用这个函数来定义策略:基于价值的方法。
最后,谈到深度强化学习,因为引入了深度神经网络来估计要采取的动作(基于策略)或估计状态的价值(基于价值)因此得名“深度”。
在下一章中,我们将学习 Q-Learning 并深入研究基于价值的方法。
补充阅读
Deep Reinforcement Learning
- Reinforcement Learning: An Introduction, Richard Sutton and Andrew G. Barto Chapter 1, 2 and 3
- Foundations of Deep RL Series, L1 MDPs, Exact Solution Methods, Max-ent RL by Pieter Abbeel
- Spinning Up RL by OpenAI Part 1: Key concepts of RL