多智能体强化学习
多智能体强化学习 (MARL) 简介
截至目前,我们学习了在单智能体系统中训练智能体,在该系统中,我们的智能体在环境中是单独的:它不与其他智能体合作或协作。
但是,作为人类,我们生活在一个多主体的世界中。我们的智慧来自于与其他智能体的互动。因此,我们的目标是创建可以与其他人和其他智能体交互的智能体。
因此,我们必须研究如何在多智能体系统中训练深度强化学习智能体,以构建能够适应、协作或竞争的强大智能体。所以今天,我们将学习多智能体强化学习 (MARL) 的基础知识。
从单智能体到多智能体
当我们进行多智能体强化学习 (MARL) 时,有多个智能体在一个公共环境中共享和交互。
例如,您可以想象一个仓库,多个机器人需要在其中导航以装卸包裹。
 [图片来自 upklyak](https://www.freepik.com/free-vector/robots-warehouse-interior-automated-machines_32117680.htm#query=warehouse robot&position=17&from_view=keyword)
[图片来自 upklyak](https://www.freepik.com/free-vector/robots-warehouse-interior-automated-machines_32117680.htm#query=warehouse robot&position=17&from_view=keyword)
或者有几辆自动驾驶汽车的道路。
 [图片来自 jcomp](https://www.freepik.com/free-vector/autonomous-smart-car-automatic-wireless-sensor-driving-road-around-car-autonomous-smart-car-goes-scans- roads-observe-distance-automatic-braking-system_26413332.htm#query=self driving cars highway&position=34&from_view=search&track=ais)
[图片来自 jcomp](https://www.freepik.com/free-vector/autonomous-smart-car-automatic-wireless-sensor-driving-road-around-car-autonomous-smart-car-goes-scans- roads-observe-distance-automatic-braking-system_26413332.htm#query=self driving cars highway&position=34&from_view=search&track=ais)
在这些示例中,我们有多个智能体在环境中并与其他智能体交互。这意味着定义一个多智能体系统。但首先,让我们了解不同类型的多智能体环境。
不同类型的多智能体环境
鉴于在多智能体系统中,智能体与其他智能体交互,我们可以有不同类型的环境:
- 合作环境:智能体需要最大化共同利益的环境。
例如,在仓库中,机器人必须协作以尽可能高效(尽可能快)装卸包裹。
- 竞争/对抗环境:在这种情况下,智能体希望通过最小化对手利益来最大化其自身利益。
例如,在网球比赛中,每个智能体都想打败另一个智能体。
- 混合对抗和合作:就像在 SoccerTwos 环境中,两个智能体是团队的一部分(蓝色或紫色):他们需要相互合作并击败对手球队。
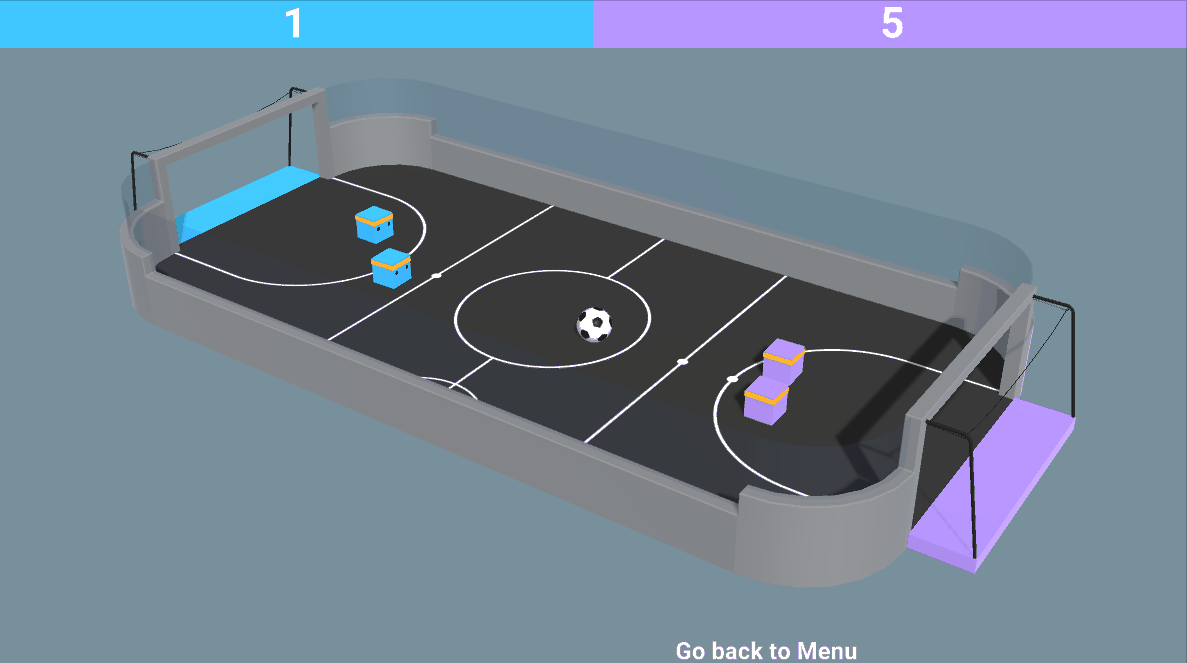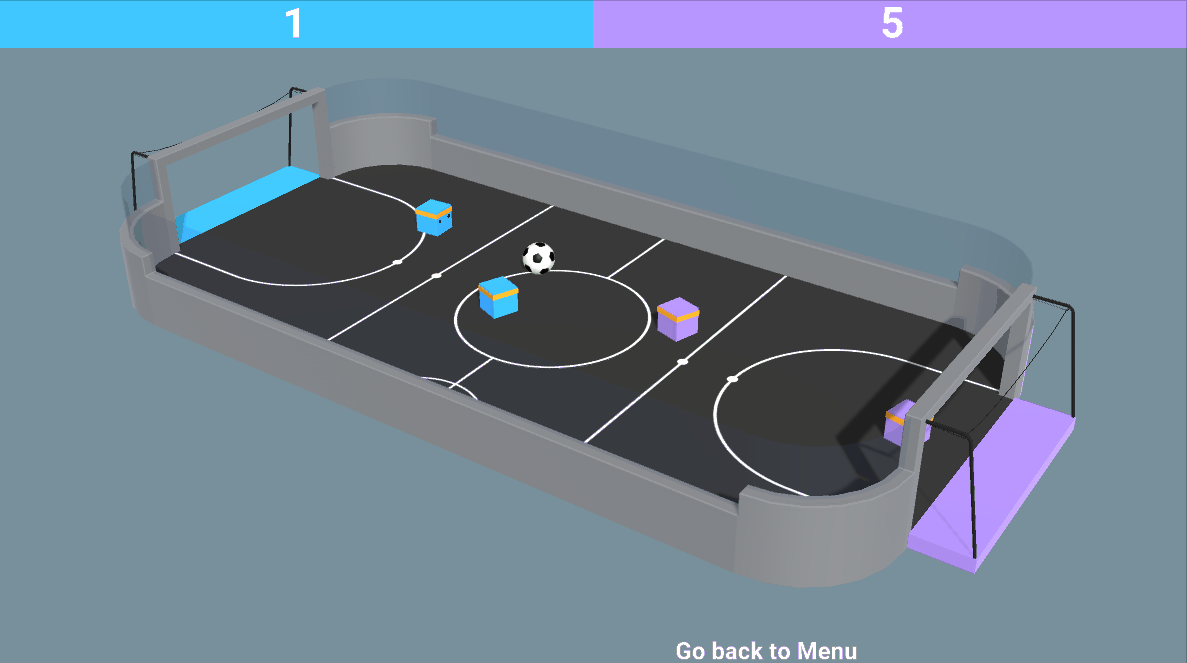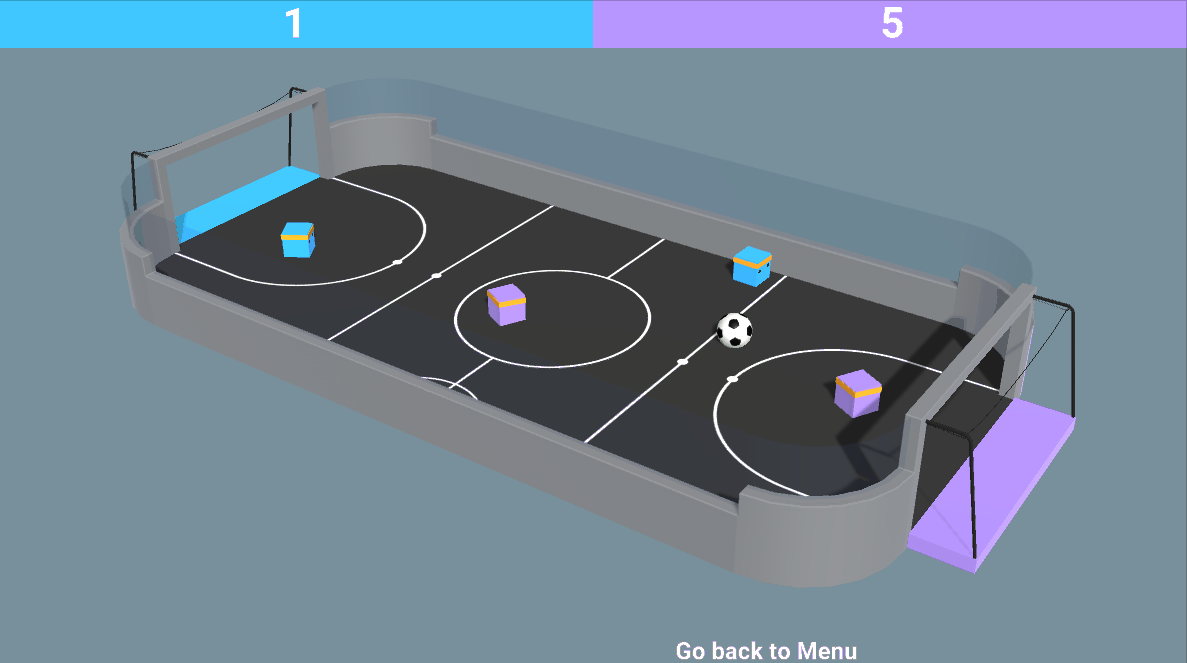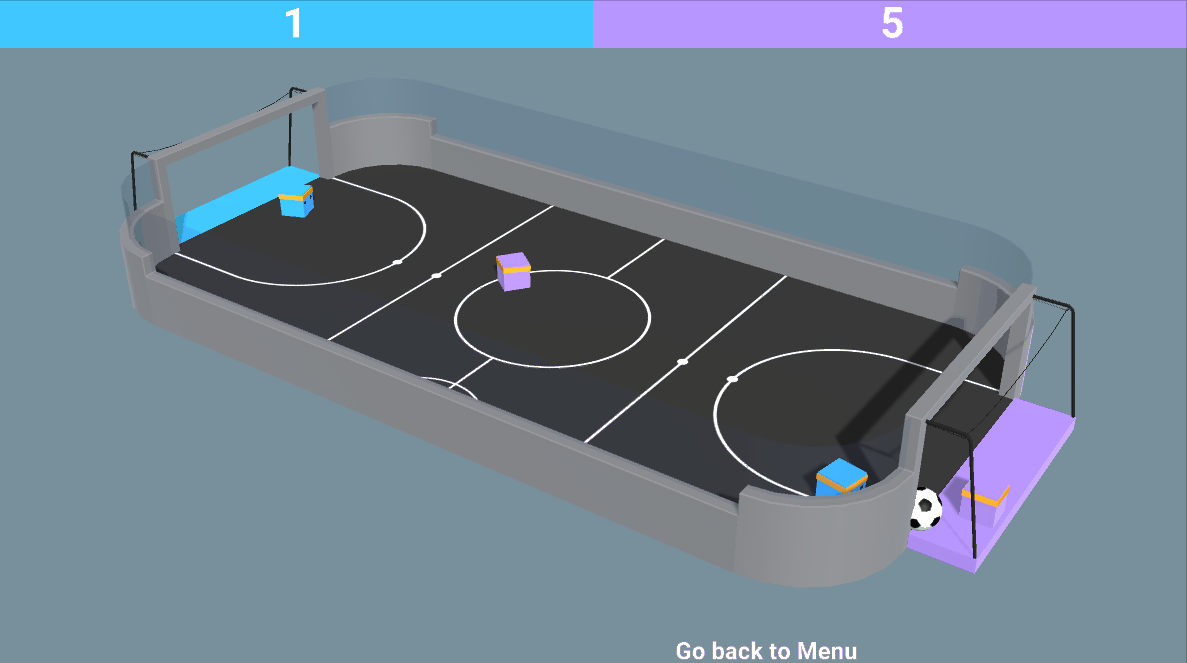 环境是由
环境是由所以现在我们可能想知道:如何设计这些多智能体系统?换句话说,我们如何在多智能体环境中训练智能体?
设计多智能体系统
在本节中,将观看由Brian Douglas制作的对多智能体的出色介绍。
在此视频中,Brian 谈到了如何设计多智能体系统。他特地拿了一个吸尘器的多智能体设置,问他们如何相互协作?
我们有两种解决方案来设计这个多智能体强化学习系统 (MARL)。
分散系统
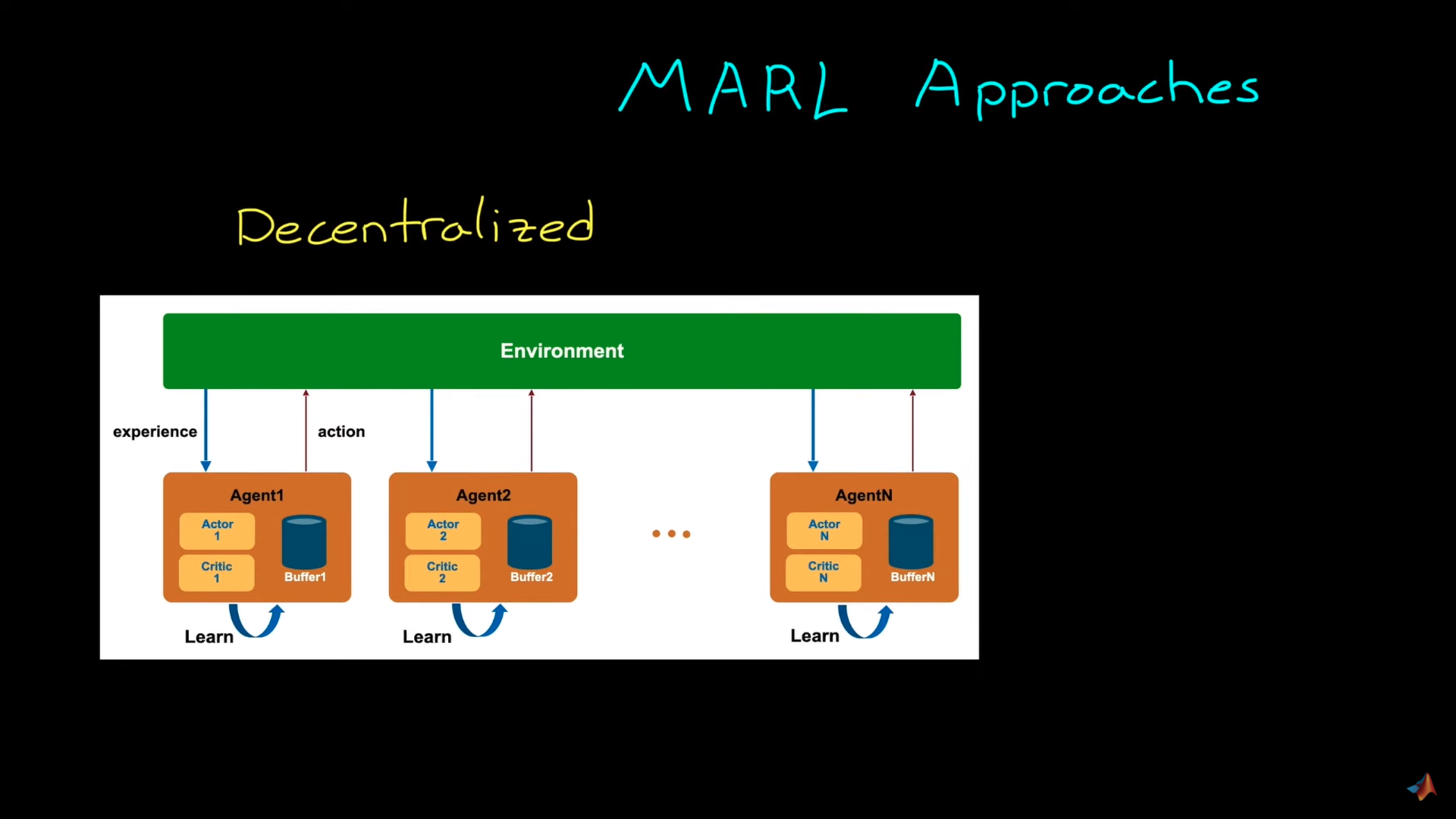 资料来源:多智能体强化学习简介
资料来源:多智能体强化学习简介
在去中心化学习中,每个智能体都是独立于其他智能体进行训练的。在给出的示例中,每个吸尘器都学会了尽可能多地清洁地方,而无需关心其他吸尘器(智能体)在做什么。
好处是,由于智能体之间不共享信息,因此可以像训练单个智能体一样设计和训练这些多智能体。
这里的想法是我们训练的智能体将考虑其他智能体作为环境动力学的一部分。而不是作为智能体。
然而,这种技术的最大缺点是它会使环境变得不稳定,因为潜在的马尔可夫决策过程会随着时间的推移而变化,因为其他智能体也在环境中进行交互。这对于许多无法在非平稳环境下达到全局最优的强化学习算法来说是有问题的。
集中方式
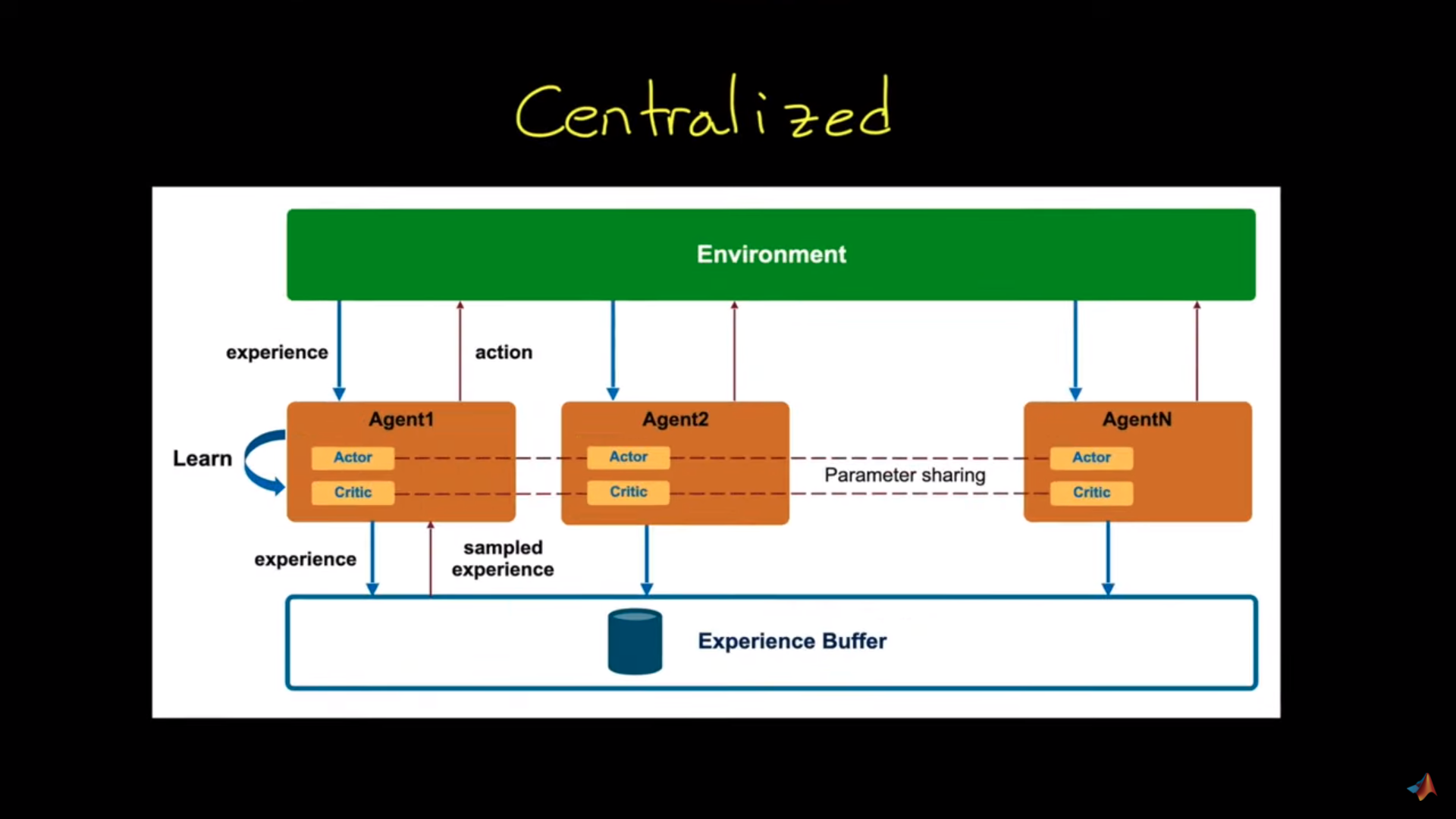 资料来源:多智能体强化学习简介
资料来源:多智能体强化学习简介
在这个架构中,我们有一个收集智能体经验的 High -Level 的程序 :经验缓冲区。我们将利用这些经验来学习共同的策略。
例如,在真空吸尘器中,观察将是:
- 吸尘器的覆盖图。
- 所有吸尘器的位置。
我们利用这些集体经验来训练策略,该策略将以最有利的方式整体移动所有三个机器人。所以每个机器人都在从共同的经验中学习。我们有一个固定的环境,因为所有智能体都被视为一个更大的实体,并且他们知道其他智能体策略的变化(因为它与他们的策略相同)。
回顾一下:
- 在去中心化方法中,我们独立对待所有智能体而不考虑其他智能体的存在。
- 在这种情况下,所有智能体都将其他智能体视为环境的一部分。
- 这是一个非平稳的环境条件,所以不保证收敛。
- 在集中式方法中:
- 一个单一的策略是从所有的智能体那里学到的。
- 将环境的当前状态和策略输出的联合行动作为输入。
- 奖励是全局的。
Self-Play
Self-Play:在对抗性游戏中训练有竞争力的智能体的经典技术
现在我们研究了多智能体的基础知识,准备好进行更深入的研究。如简介中所述,我们将在 SoccerTwos 的对抗游戏中训练智能体,这是一种 2vs2 游戏。
什么是 Self-Play ?
在对抗游戏中正确训练智能体可能非常复杂。
一方面,我们需要找到如何让训练有素的对手与你的训练智能体对战。另一方面,即使你有一个训练有素的对手,这也不是一个好的解决方案,因为当对手太强大时你的智能体将如何改进它的策略?
想想一个刚开始学足球的孩子。与一个非常优秀的足球运动员比赛将毫无用处,因为赢球或至少时不时拿到球太难了。所以孩子会不断地输,而没有时间去学习一个好的策略。
最好的解决方案是让对手与智能体处于同一级别,并随着智能体升级自己的级别而升级其级别。因为如果对手太强,我们什么也学不到;如果它太弱,那么我们就会过度学习对抗更强大对手的无用行为。
这种解决方案称为self-play。在Self-Play中,智能体使用自己(其策略)的之前副本作为对手。这样,智能体将与同级别的智能体对战(具有挑战性但不是太多),有机会逐渐改进其策略,然后在它变得更好时更新它的对手。这是一种引导对手并逐渐增加对手复杂性的方法。
这与人类在竞争中学习的方式相同:
- 一开始,我们与水平相近的对手进行训练
- 然后我们从中学习,当我们掌握了一些技巧之后,我们就可以和更强的对手走得更远。
我们对自博弈做同样的事情:
- 我们以这种方式将智能体的副本作为对手,这个对手处于相似的水平。
- 我们从中学习,当我们获得一些技能时,我们用最新的训练策略副本更新我们的对手。
自博弈背后的理论并不新鲜。50 年代 Arthur Samuel 的跳棋玩家系统和 1955 年 Gerald Tesauro 的 TD-Gammon 已经使用了它。如果您想了解更多关于自我对弈的历史,请查看 Andrew Cohen 的这篇博客文章
在 MLAgents 中自我对弈
Self-Play 已集成到 MLAgents 库中,并由多个超参数进行管理。但文档中解释的主要焦点是最终策略的技能水平和通用性与学习稳定性之间的权衡。
针对一组缓慢变化或不变的低多样性对手进行训练会导致更稳定的训练。但如果变化太慢,就会有过拟合的风险。
然后我们需要控制:
- 多久更换一次对手, 通过参数
swap_steps和team_change - 保存的对手数量, 使用参数
window。 更大的window值意味着智能体的对手池将包含更大的行为多样性,因为它将包含来自训练运行早期的策略。 - 与当前自己对战在池中采样的对手的概率
play_against_latest_model_ratio。较大的值play_against_latest_model_ratio表示智能体将更频繁地与当前对手对战。 - 保存新对手之前的训练步骤数, 使用参数
save_steps。较大的值save_steps将产生一组涵盖更广泛的技能水平和可能的游戏风格的对手,因为该策略接受了更多的训练。
要获得有关这些超参数的更多详细信息,您需要查看文档的这一部分
评估智能体的 ELO 分数
什么是 ELO 分数?
在对抗性游戏中,跟踪累积奖励并不总是跟踪学习进度的有意义指标:因为该指标仅取决于对手的技能。
相反,我们使用ELO 评级系统(以 Arpad Elo 命名)计算零和游戏中来自给定人群的 2 名玩家之间的相对技能水平。
在零和游戏中:一个智能体赢,另一个智能体输。它是一种数学表示,在这种情况下,每个参与者的效用收益或损失与其他参与者的效用收益或损失完全平衡。我们谈论零和游戏,因为效用之和等于零。
此 ELO(从特定分数开始:通常为 1200)最初可能会降低,但应在训练期间逐渐增加。
Elo 系统是根据与其他玩家的失败和平局推断出来的。这意味着球员的评分取决于对手的评分和对他们的得分结果。
Elo 定义了 Elo 分数,即零和游戏中玩家的相对技能。我们说相对,因为这取决于对手的表现。
中心思想是将球员的表现视为服从正态分布的随机变量。
2 名球员之间的评分差异可作为比赛结果的预测指标。如果玩家赢了,但赢的概率很高,那么它只会从对手那里赢几分,因为这意味着它比它强得多。
每场比赛结束后:
获胜的玩家从失败的玩家那里获得积分。
点数
由 2 位玩家评分的差异决定(因此是相对的)。
- 如果评分较高的玩家获胜→评分较低的玩家将获得很少的积分。
- 如果评分较低的玩家获胜→将从评分较高的玩家那里获得很多积分。
- 如果是平局 → 评分较低的玩家从评分较高的玩家那里获得几分。
因此,如果 A 和 B 的评级为 Ra 和 Rb,则预期分数为:

然后,在游戏结束时,我们需要更新玩家的实际 Elo 分数。我们使用与玩家表现出色或表现不佳的数量成比例的线性调整。
我们还定义了每场比赛的最大调整评级:K -Factor。
- K = 16 为主人。
- 对于较弱的玩家,K=32。
如果玩家 A 有 Ea 分但获得了 Sa 分,则使用以下公式更新玩家的评分:

例子
我们举个例子:
玩家A的评分为2600
玩家 B 的评分为 2300
- 我们首先计算期望分数:
$$ \begin{aligned} & E_A=\frac{1}{1+10^{(2300-2600) / 400} }=0.849 \ & E_B=\frac{1}{1+10^{(2600-2300) / 400} }=0.151 \end{aligned} $$
- 如果组织者确定 $\mathrm{K}=16$ 并且$\mathrm{A}$ 获胜,, 则新的评分将是:
$$ \begin{aligned} & E L O_A=2600+16 *(1-0.849)=2602 \ & E L O_B=2300+16 *(0-0.151)=2298 \end{aligned} $$
- 如果组织者确定 $K=16$ 并且 $B$获胜,则新的评分将是:
$$ \begin{aligned} & E L O_A=2600+16 *(0-0.849)=2586 \ & E L O_B=2300+16 *(1-0.151)=2314 \end{aligned} $$
优点
使用 ELO 分数有多个优点:
- 积分总是平衡的(当出现意想不到的结果时交换更多的积分,但总和总是相同的)。
- 这是一个自我修正的系统,因为如果一个玩家赢了一个弱玩家,你只会赢得几分。
- 如果适用于团队游戏:我们计算每个团队的平均值并将其用于 Elo。
缺点
- ELO不考虑团队中每个人的个人贡献。
- 评级通缩:良好的评级需要随着时间的推移获得相同评级的技能。
- 无法比较历史评级。
补充读物
An introduction to multi-agents
- Multi-agent reinforcement learning: An overview
- Multiagent Reinforcement Learning, Marc Lanctot
- Example of a multi-agent environment
- A list of different multi-agent environments
- Multi-Agent Reinforcement Learning: Independent vs. Cooperative Agents
- Dealing with Non-Stationarity in Multi-Agent Deep Reinforcement Learning