MuZero 直觉
MuZero是令人振奋的一大步,该算法摆脱了对游戏规则或环境动力学的知识依赖,可以自行学习环境模型并进行规划。即使如此,MuZero仍能够实现AlphaZero的全部功能——这显示出其在许多实际问题的应用可能性!
It's all just statistics
MuZero是一种机器学习算法,自然首先要了解它是如何使用神经网络的。它从 AlphaGo 和 AlphaZero 继承了策略网络和价值网络:
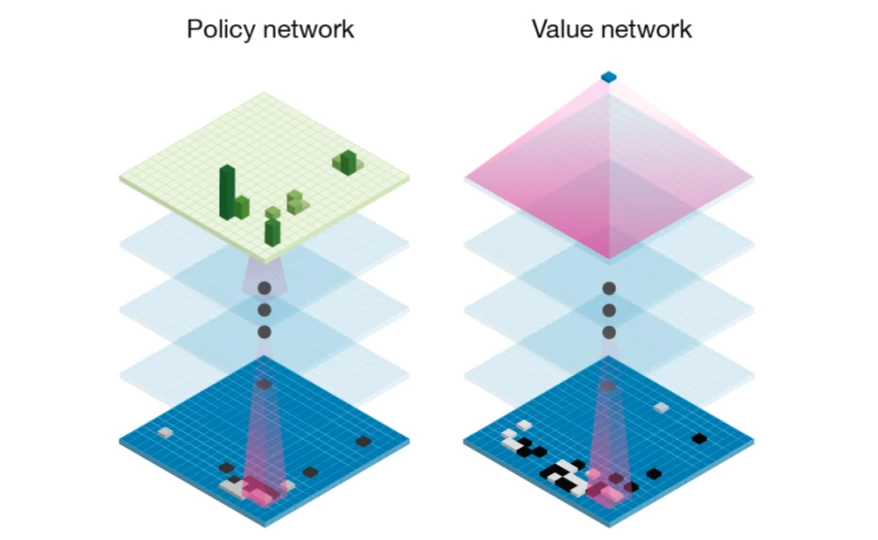
policy 和 value 都有非常直观的含义:
- 策略,$p(s, a)$, 是在状态 $s$ 时所有可能动作$a$的概率分布, 据此可以估计最优的动作。类比人类玩家,该策略相当于快速浏览游戏时拟采取的可能动作。
- 价值 $v(s)$ 估计从当前状态$s$获胜的概率:即通过对所有的未来可能性进行加权平均,确定当前玩家的获胜概率。
这两个网络任何一个都非常强大:只根据策略网络,能够轻易预测每一步的动作,最终得到良好结果;只依赖值网络,始终选择值最高的动作。但是,将这两个估计结合起来可以得到更好的结果。
取胜之路
与之前的AlphaGo和AlphaZero类似, MuZero使用蒙特卡洛树搜索2(简称 MCTS)来聚合神经网络预测并选择要应用于环境的动作。
MCTS 是一个迭代的、最佳优先的树搜索过程。最佳优先意味着搜索树的扩展由搜索树中的值估计指导。与广度优先(将整棵树扩展到固定深度再进行更深搜索)或深度优先(连续扩展每条可能的路径直到游戏结束后再尝试下一条)等经典方法相比,最佳优先搜索可以利用启发式估计(例如神经网络)即使在非常大的搜索空间中也能找到有前途的解决方案。
MCTS具有三个主要阶段:模拟,扩展和反向传播。通过重复执行这些阶段,MCTS根据节点可能的动作序列逐步构建搜索树。在该树中,每个节点表示未来状态,而节点间的边缘表示从一个状态到下一个状态的动作。
在我们深入细节之前,让我介绍一下这种搜索树的示意图,包括MuZero做出的神经网络预测:
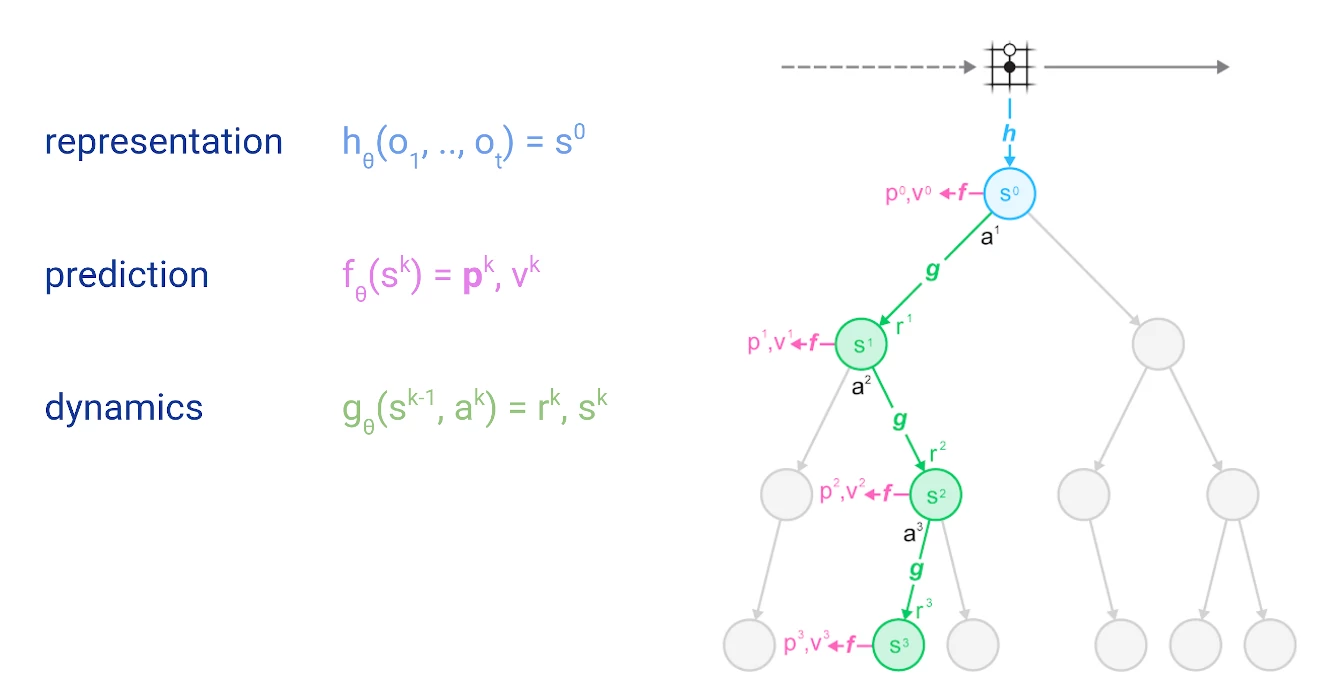
圆圈代表树的节点,对应于环境中的状态。线代表动作,从一个状态到下一个状态. 根节点为当前环境状态,即围棋面板状态。后续章节我们会详细介绍预测和动力学函数。
模拟 总是从树的根部(图中顶部的浅蓝色圆圈)开始,即环境或游戏中的当前位置。在每个节点(状态$s$), 它使用评分函数 $U(s,a)$ 比较不同的动作$a$, 并选择了最优动作。MuZero中使用的评分函数将先前的估计$p(s,a)$与价值估计 $v(s,a)$结合起来,即:
$U(s,a) =v(s,a) + c* p(s,a) $
其中 $C$ 是一个缩放因子,随着值估计准确性的增加,减少先验的影响。
每次选择一个动作时,我们都会增加其相关的访问次数$n(s,a)$, 用于 UCB 比例因子$c$并用于以后的动作选择。
模拟沿着树向下进行,直到到达尚未展开的叶子;此时神经网络用于评估节点。评估结果(先验和价值估计)存储在节点中。
Expansion:一旦节点达到估计量值后,将其标记为“扩展”,意味着可以将子级添加到节点,以便进行更深入的搜索。在MuZero中,扩展阈值为1,即每个节点在首次评估后都会立即扩展。在进行更深入的搜索之前,较高的扩展阈值可用于收集更可靠的统计信息。
反向传播:最后,将神经网络的值估计传播回搜索树,每个节点都在其下保存所有值估计的连续均值,这使得UCB公式可以随着时间的推移做出越来越准确的决策,从而确保MCTS收敛到最优动作。
中间奖励
细心的读者可能已经注意到,上图中还包含了一个量r的预测. 某些领域,例如棋盘游戏,仅在一集完全结束时提供反馈(例如输赢结果);它们可以完全通过价值估计来建模。但在另外一些情况下,会存在频繁的反馈,即每次从一种状态转换到另一种状态后,都会得到回报r。
只需要对 UCB 公式稍作修改,就可以通过神经网络预测直接对该奖励建模,并将其用于搜索:
$$ U(s, a)=r(s, a)+\gamma \cdot v\left(s^{\prime}\right)+c \cdot p(s, a) $$
其中r(s,a)是从状态$s$转换时通过选择行动$a$观察到的奖励, γ是一个折扣因子,描述了我们对未来奖励的关心程度。
由于总体奖励可以时任意量级的,因此在将其与先验奖励组合之前,我们将奖励/值估计归一化为区间[0,1]:
$$ U(s, a)=\frac{r(s, a)+\gamma \cdot v\left(s^{\prime}\right)-q_{\min } }{q_{\max }-q_{\min } }+c \cdot p(s, a) $$ 其中,q_min和q_max分别是整个搜索树中观察到的最小和最大r(s,a)+γ⋅v(s')估计。
Episode Generation
可以重复应用上述 MCTS 过程来玩整个剧集:
- 在当前环境状态$s_t$下运行搜索。
- 根据搜索的统计 $\pi_t$选择一个动作$a_{t+1}$。
- 根据该动作更新环境,进入到下一个状态$s_{t+1}$并观察奖励$u_{t+1}$.
- 重复上述过程直到环境终止。
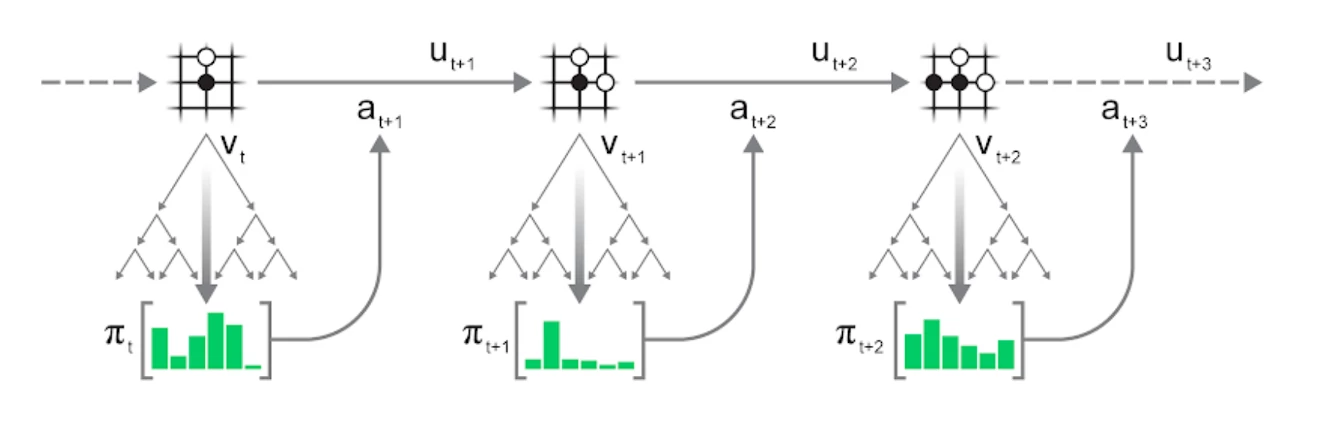
动作的选择可以是贪心的——访问次数最多的动作, 也可以是探索性的:通过一定的温度t控制探索程度,并对与访问次数n(s,a)成比例的动作a进行采样:
$$p(a)=\left(\frac{n(s, a)}{\sum_b n(s, b)}\right)^{1 / t}$$
当t = 0时,等效贪婪采样;当t = inf时,等效均匀采样。
Training
现在我们知道如何运行 MCTS 来选择动作、与环境交互和生成episodes,我们可以转向训练MuZero模型。
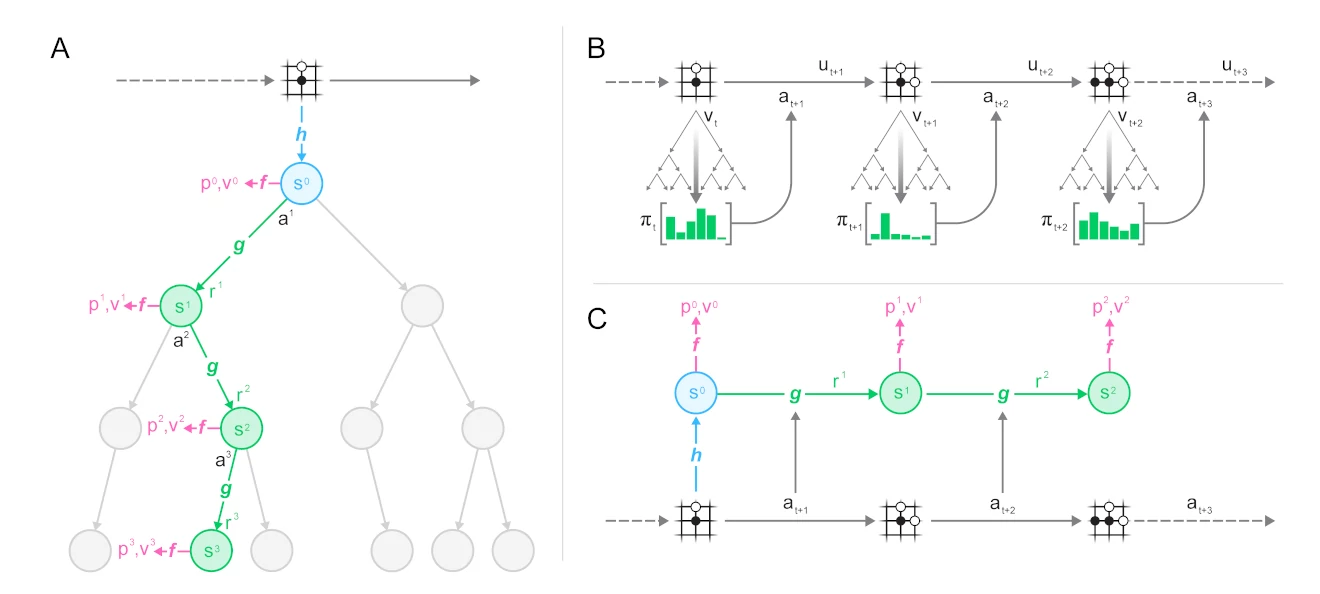
首先,从数据集中采样一条轨迹和一个位置,然后根据该轨迹运行MuZero模型:
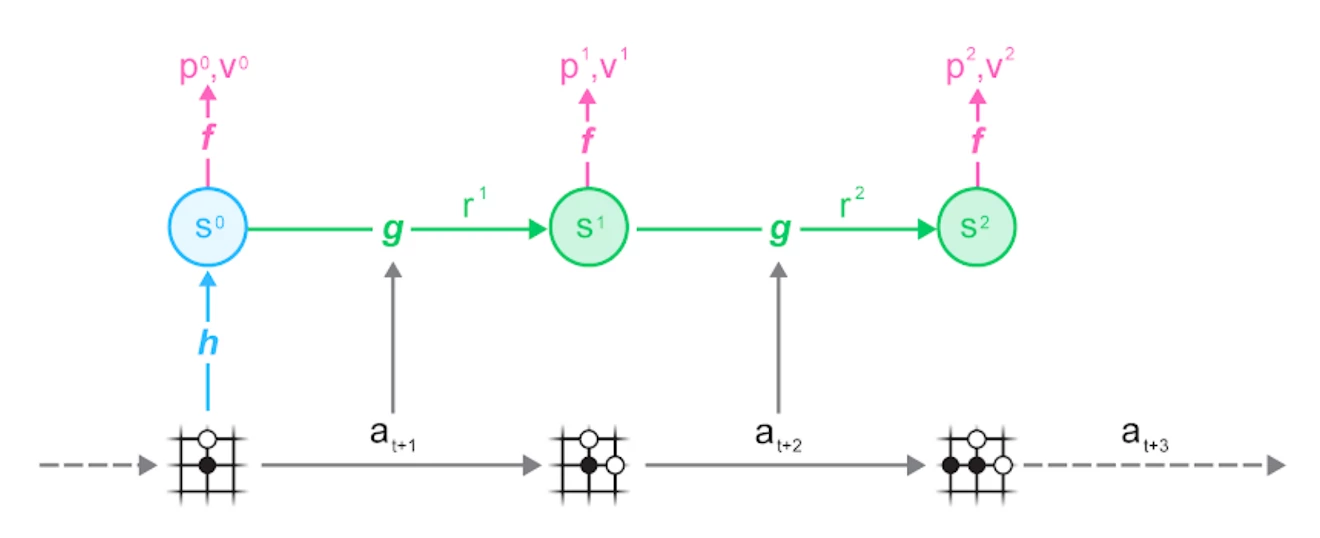
您可以看到运行中的MuZero算法的三个部分:
- representation 函数 $h$, 使用神经网络从一组观察结果(棋盘)映射到隐藏状态$s$
- dynamics 函数 $g$ ,将状态 $s_t$ 采取的动作$a_{t+1} 映射到 $$s_{t+1}$. 同时估算在此过程的奖励$r_t$。这样模型就能够不断向前扩展;
- prediction 函数 $f$ , 基于状态 $s_t$ 对策略$p_t$和值函数$v_t$进行估计. 应用UCB公式并将其汇入MCTS过程。
根据轨迹选择用于网络输入的观测值和动作。相应地,策略、值和奖励的预测目标是在生成存储的轨迹。
从下图可以看到过程生成(B)与训练(C)之间的一致性:
具体问言,MuZero估计量的训练损失为:
- 策略:MCTS访问统计信息与预测函数的策略logit之间的交叉熵;
- 值:N个奖励的折扣和+搜索值/目标网络估计值与预测函数的值之间的交叉熵或均方误差;
- 奖励:轨迹观测奖励与动态函数估计之间的交叉熵。
重分析
在了解了MuZero的核心思想后,接下来我们将介绍重分析技术,这将显著提高模型对大量数据的搜索效率。
在一般训练过程中,通过与环境的相互作用,我们会生成许多轨迹,并将其存储在重播缓冲区用于训练。那么,我们可以从该数据中获得更多信息吗?
 很难。由于需要与环境交互,我们无法更改存储数据的状态、动作或奖励。在《黑客帝国》中可能做到,但在现实世界中则不可能。
很难。由于需要与环境交互,我们无法更改存储数据的状态、动作或奖励。在《黑客帝国》中可能做到,但在现实世界中则不可能。
幸运的是,我们并不需要这样。只要使用更新的、改进标签的现有输入,就足以继续学习。考虑到MuZero模型和MCTS,我们做出如下改进:
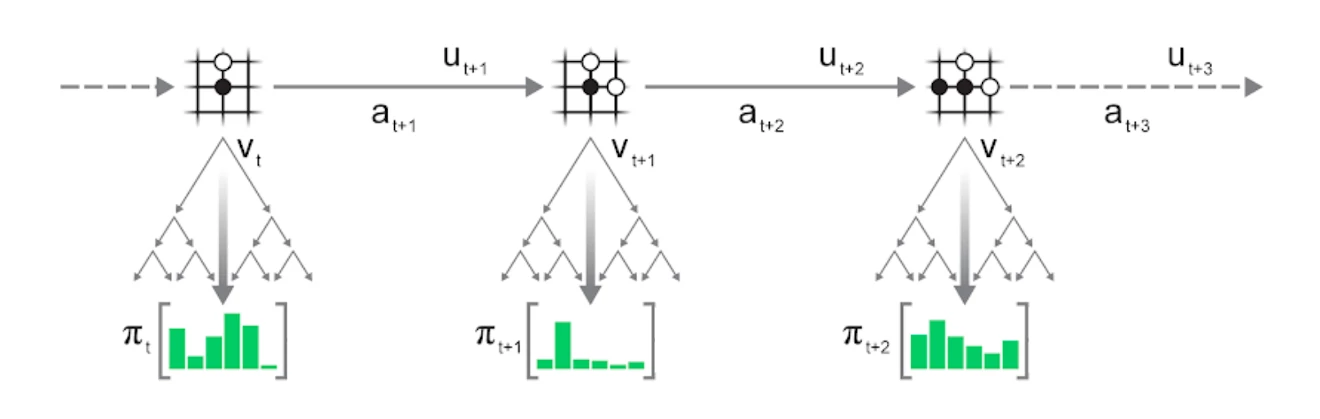
保持轨迹(观测、动作和奖励)不变,重新运行MCTS,就可以生成新的搜索统计信息,从而提供策略和值预测的新目标。
我们知道,在与环境直接交互过程中,使用改进网络进行搜索会获得更好的统计信息。与之相似,在已有轨迹上使用改进网络重新搜索也会获得更好的统计信息,从而可以使用相同的轨迹数据重复改进。
重分析适用于MuZero训练,一般训练循环如下:
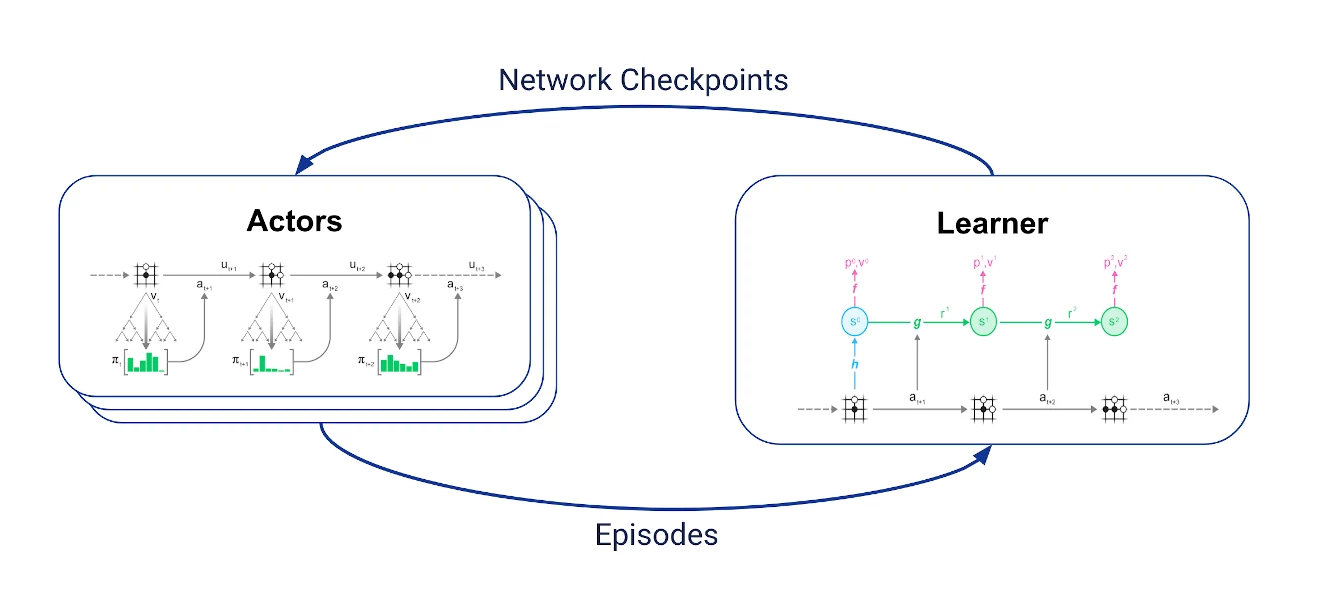 设置两组异步通信任务:
设置两组异步通信任务:
- 一个学习者接收最新轨迹,将最新轨迹保存在重播缓冲区,并根据这些轨迹进行上述训练;
- 多个行动者定期从学习者那里获取最新的网络检查点,并使用MCTS中的网络选择动作,与环境进行交互生成轨迹。
为实现重分析,引入两个新任务:
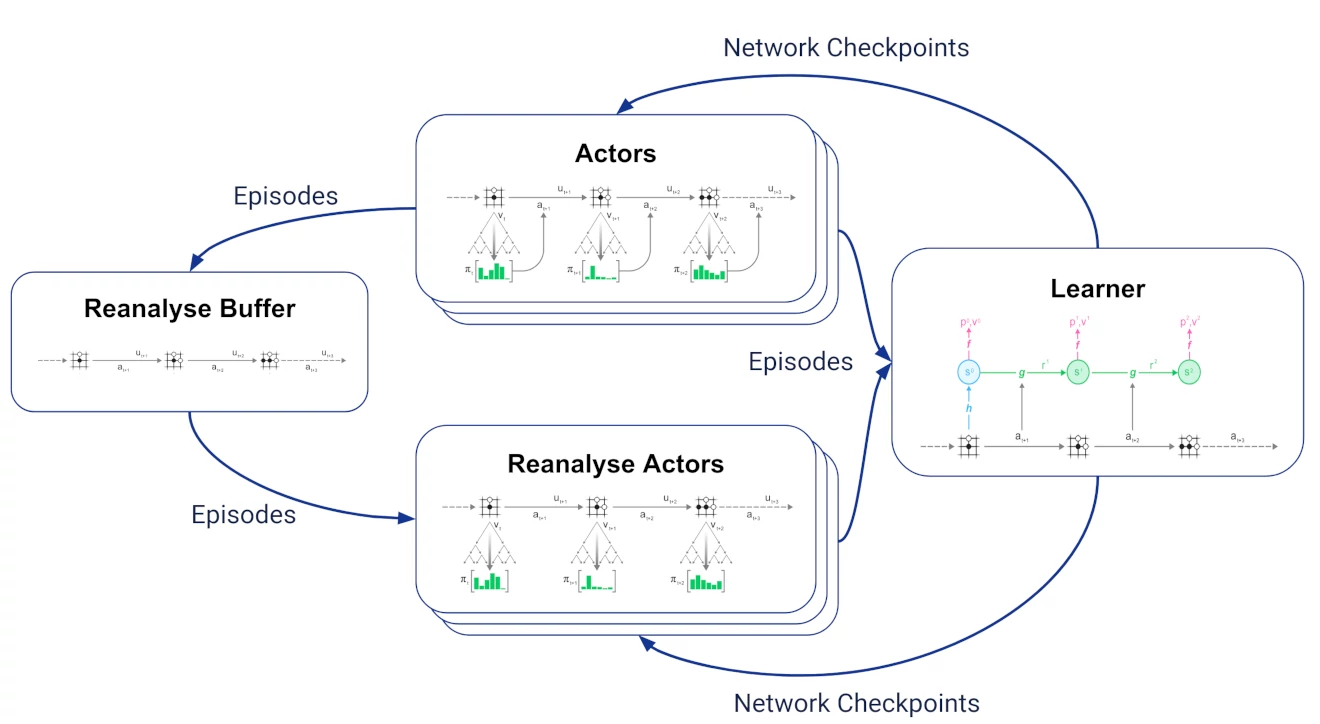
- 一个重新分析缓冲区,它接收参与者生成的所有轨迹并保留最新的轨迹。
- 多个再分析参与者 从再分析缓冲区中对存储的轨迹进行采样,使用来自学习器的最新网络检查点重新运行 MCTS,并将生成的轨迹和更新的搜索统计信息发送给学习器。
由于学习者无法区分新轨迹和重分析的轨迹,这使得新轨迹与重分析轨迹的比例更改变得简单。
MuZero命名含
MuZero的命名基于AlphaZero,其中Zero表示是在没有模仿人类数据的情况下进行训练的,Mu取代Alpha表示使用学习模型进行规划。
更研究一些,Mu还有其他丰富的含义:
- [夢](https://jisho.org/search/夢 %23kanji),日语中读作mu,表示“梦”的意思, 就像MuZero通过学习的模型来想象未来状况一样;
- 希腊字母μ(发音为mu)也可以表示学习的模型;
- [無](https://jisho.org/search/無 %23kanji), 日语发音为mu,表示“无、没有”,这强调从头学习的概念:不仅无需模仿人类数据,甚至不需提供规则。
结语
希望本文对MuZero的介绍对你有所启发!
如果想了解更多细节,可以阅读原文,还可以查看我在NeurIPS的poster以及在ICAPS上发表的关于MuZero的演讲。
最后,分享给你一些其他研究人员的文章,博客和GitHub项目:
- A Simple Alpha(Go) Zero Tutorial
- MuZero General implementation
- How To Build Your Own MuZero AI Using Python