自动化虚拟网络防御仿真环境
| 仿真环境 | 作者 | 简介 | 本地部署(Linux) | 仿真程度 |
|---|---|---|---|---|
CSLE | 瑞典皇家理工学院 | 使用定量方法(例如最优控制、计算博弈论、强化学习、优化、进化方法和因果推理)开发自动化安全策略的研究平台。 | No | 高,最接近真实环境 |
| Yawning Titan | 英国国防科学技术实验室 (DSTL) | Yawning-Titan 是一组抽象的、基于图形的网络安全模拟环境,支持基于 OpenAI Gym 的自主网络操作智能体的训练。Yawning-Titan 专注于提供快速模拟,以支持对抗概率红方智能体的防御性自主智能体的开发。 | yes | 较简单 |
| CyberBattleSim | 微软 | 网络拓扑和一组预定义的漏洞定义了进行模拟的环境。攻击者利用现有漏洞,通过横向移动在网络中进化,目标是通过利用计算机节点中植入的参数化漏洞来获取网络的所有权。防御者试图遏制攻击者并将其从网络中驱逐。 CyberBattleSim 为其模拟提供了 OpenAI Gym 接口,以促进强化学习算法的实验。 | yes | 较高 |
| CyBorg | 澳大利亚国防部 | 用于训练和开发安全人员和自主智能体的网络安全研究环境。包含用于模拟(使用基于云的虚拟机)和模拟网络环境的通用接口。 | yes | 高 |
| NetworkAttackSimulator | Jonathon.schwartz@anu.edu.au | 用于针对模拟网络测试 AI 渗透测试智能体的环境。 | yes | 简单 |
NASim 仿真环境
介绍
网络攻击模拟器 (NASim) 是一个模拟计算机网络,具有漏洞、扫描和漏洞利用,旨在用作 AI 智能体的测试环境和应用于网络渗透测试的规划技术。它是一个模拟器,因此没有复制攻击真实系统的所有细节,而是旨在捕捉一些网络渗透测试的更显著特征,如状态和动作空间的规模变化、部分可观察性和多样化的网络拓扑。
环境是基于 gymnasium 建模的
Github:https://github.com/Jjschwartz/NetworkAttackSimulator
安装
依赖项
该框架经过测试,可以在 Python 3.7 或更高版本下运行。
所需的依赖项:
- Python >= 3.7
- Gym >= 0.17
- NumPy >= 1.18
- PyYaml >= 5.3
对于渲染:
- NetworkX >= 2.4
- prettytable >= 0.7.2
- Matplotlib >= 3.1.3
运行安装
pip install nasim启动 NASim 环境
与 NASim 的交互主要通过类 NASimEnv 完成,该类处理所选scenario定义的模拟网络环境。
有两种方法可以启动新环境:
- (i)直接通过 nasim 库,
- (ii)使用gymnasium 库的gym.make()函数。
在本教程中,我们将介绍第一种方法。对于第二种方法,请查看使用 OpenAI gym 启动 NASim。
环境设置
NASimEnv类的初始化需要一个scenario定义和三个可选参数。
scenario定义了网络属性和渗透测试人员的特定信息(例如可用的漏洞等)。
三个可选参数控制环境模式:
fully_obs: 环境的可观察性模式,如果为True,则使用完全可观察模式,否则是部分可观察(默认=False)flat_actions: 如果为真,则使用平面动作空间,否则将使用参数化动作空间(默认=True)。flat_obs: 如果为真,则使用1D观察空间,否则使用2D观察空间(默认=True)
如果使用完全可观察模式 ( fully_obs=True),则每一步之后都会观察到网络和攻击的整个状态。这是“简单”模式,不能反映渗透测试的现实,但它对于入门和健全性检查算法和环境很有用。当使用部分可观察模式 ( fully_obs=False) 时,Agent在开始时不知道网络上每个主机的位置、配置和值,并且只接收与每一步执行的操作直接相关的特征的观察结果。这是“困难”模式,更准确地反映了渗透测试的现实。
环境是否完全或部分可观察对动作和观察空间的大小和形状或Agent与环境的交互方式没有影响。
使用flat_actions=True意味着我们的操作空间由 N 个离散操作组成,其中 N 基于网络中的主机数量以及可用的漏洞和扫描数量。对于我们的示例,有 3 个主机、1 个漏洞和 3 个扫描(操作系统、服务和子网),总共有 3 (1 + 3) = 12 个操作。如果flat_actions=False 每个操作都是一个向量,向量的每个元素都指定了操作的一个参数。
使用 flat_obs=True 意味着返回的观测值将是一个一维向量。否则,flat_obs=False观测值将是一个二维矩阵。
从 scenario 加载环境
NASim 环境可以通过三种方式从scenario构建:创建现有scenario、从 YAML 文件加载以及从参数生成。
基于现有scenario创建
这是加载新环境的最简单方法,与OpenAI Gym 方式非常吻合。加载现有scenario非常简单:
import nasim
env = nasim.make_benchmark("tiny")还可以使用种子参数传入随机种子,这将在使用生成的scenario时产生影响。
从 YAML 文件加载scenario
如果希望加载 YAML 文件中定义的现有或自定义scenario,这也非常简单:
import nasim
env = nasim.load("path/to/scenario.yaml")生成 scenario
加载新环境的最后一种方法是使用 NASim scenario生成器来生成它。有相当多的参数可用于控制生成什么scenario,但两个关键参数是网络中的主机数量和正在运行的服务数量(除非另有说明,否则它们还控制漏洞的数量)。
要生成一个包含 5 个主机并运行 3 个服务的新环境:
import nasim
env = nasim.generate(5, 3)如果您想要传递一些其他参数(例如可能的操作系统数量),可以将其作为关键字参数传递:
env = nasim.generate(5, 3, num_os=3)使用 OpenAI gym 启动 NASim
启动时,NASim 将每个基准测试 scenario注册为Gymnasium 环境,从而允许使用 加载 NASim 基准测试环境 gymnasium.make()。
所有基准测试 scenario都可以使用 gymnasium.make() 加载。
import gymnasium as gym
env = gym.make("nasim:TinyPO-v0")
# to specify render mode
env = gym.make("nasim:TinyPO-v0", render_mode="human")与 NASim 环境交互
启动环境
首先是简单地加载环境:
import nasim
# load my environment in the desired way (make_benchmark, load, generate)
env = nasim.make_benchmark("tiny")
# or using gym
import gymnasium as gym
env = gym.make("nasim:Tiny-PO-v0")这里我们使用默认的环境参数:fully_obs=False、flat_actions=True和flat_obs=True。
可以从环境属性中检索操作的数量,action_space如下所示:
# When flat_actions=True
num_actions = env.action_space.n
# When flat_actions=False
nvec_actions = env.action_space.nvec可以从环境属性中检索观测的形状,observation_space如下所示:
obs_shape = env.observation_space.shapeEnv.reset()
要重置环境并获取初步观察结果,请使用以下reset()函数:
o, info = env.reset()返回值info包含可选的辅助信息。
Env.step()
可以使用函数在环境中采取一个步骤step(action)。该函数返回一个元组,分别对应于观察、奖励、完成、达到步骤限制、辅助信息:
action = # integer in range [0, env.action_space.n]
o, r, done, step_limit_reached, info = env.step(action)如果done=True,则目标已达到,情节结束。或者,如果当前 scenario有步骤限制,step_limit_reached=True那么步骤限制已达到。在这两种情况下,建议停止或重置环境,否则无法保证会发生什么(尤其是第一种情况)。
Env.render()
您可以使用该render()函数来获取环境状态的可读可视化效果。要正确使用渲染,请确保将其传递render_mode="human"给环境初始化函数:
import nasim
# load my environment in the desired way (make_benchmark, load, generate)
env = nasim.make_benchmark("tiny", render_mode="human")
# or using gym
import gymnasium as gym
env = gym.make("nasim:Tiny-PO-v0", render_mode="human")
env.reset()
# render the environment
# (if render_mode="human" is not passed during initialization this will do nothing)
env.render()Agent示例
目录中提供了一些示例Agentnasim/agents。以下是一个假设Agent与环境交互的简单示例:
import nasim
env = nasim.make_benchmark("tiny")
agent = AnAgent(...)
o, info = env.reset()
total_reward = 0
done = False
step_limit_reached = False
while not done and not step_limit_reached:
a = agent.choose_action(o)
o, r, done, step_limit_reached, info = env.step(a)
total_reward += r
print("Done")
print("Total reward =", total_reward)理解 Scenarios
NASim 中的 Scenarios 定义了创建网络环境所需的所有属性。每个 scenario定义可分为两个部分:网络配置和渗透测试器。
网络配置
网络配置由以下属性定义:
- subnets:网络中子网的数量和大小。
- topology:网络中不同子网如何连接
- host configurations:网络中每台主机的地址、操作系统、服务、进程和防火墙
- firewall:阻止子网之间的通信
请注意,对于主机配置,我们通常只对渗透测试人员可以利用的服务和进程感兴趣,因此我们通常会忽略任何不易受攻击的服务和进程,以减少问题规模。
渗透测试器
渗透测试器的定义如下:
- exploits:渗透测试人员可以利用的漏洞集
- privescs:渗透测试人员可用的一组权限提升操作
- scan costs:执行每种类型扫描(服务、操作系统、进程和子网)的成本
- sensitive hosts:网络上的目标主机及其价值
示例 scenario
为了说明这些属性,我们展示了一个示例 scenario,其中渗透测试人员的目的是获得敏感子网中的服务器和用户子网中一台主机的 root 访问权限。
下图显示了我们的示例网络的布局。
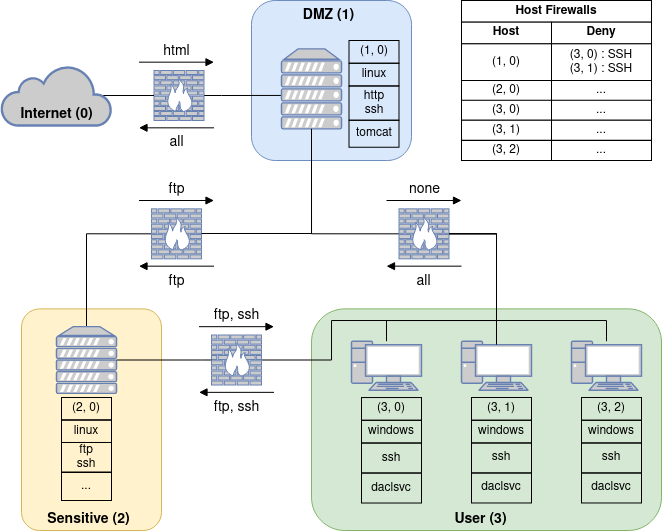
从图中我们可以看出这个网络有以下性质:
- subnets:三个子网:具有单个服务器的 DMZ、具有单个服务器的敏感子网和具有三个用户机器的用户子网。
- topology:只有 DMZ 连接到互联网,而网络中的所有子网都互连。
- host configurations:每个主机旁边显示每个主机上运行的地址、操作系统、服务和进程(例如,DMZ 子网中的服务器的地址为 (1, 0),具有 Linux 操作系统,正在运行 http 和 ssh 服务以及 tomcat 进程)。主机防火墙设置显示在图右上角的表格中。这里只有主机(1, 0)配置了防火墙,阻止来自主机(3, 0)和(3, 1)的任何 SSH 连接。
- firewall:防火墙上方和下方的箭头表示子网之间以及 DMZ 子网与互联网之间各个方向可以通信的服务(例如,互联网可以与 DMZ 中的主机上运行的 http 服务进行通信,而防火墙不会阻止从 DMZ 到互联网的通信)。
接下来我们需要定义渗透测试器,我们根据想要模拟的 scenario来指定。
exploits
漏洞利用:在这种情况下,渗透测试人员可以使用三种漏洞利用
- ssh_exploit:利用 windows 机器上运行的 ssh 服务,成本为 2,成功概率为 0.6,成功后可获得用户级访问权限。
- ftp_exploit:利用在 Linux 机器上运行的 ftp 服务,成本为 1,成功概率为 0.9,如果成功则可获得 root 级别访问权限。
- http_exploit:利用任何操作系统上运行的 http 服务,成本为 3,成功概率为 1.0,如果成功则可获得用户级访问。
privescs
privescs:在这种情况下,渗透测试人员可以执行两项权限提升操作
- pe_tomcat:利用 Linux 机器上运行的 tomcat 进程获取 root 访问权限。成本为 1,成功概率为 1.0。
- pe_daclsvc:利用 Windows 机器上运行的 daclsvc 进程获取 root 访问权限。成本为 1,成功概率为 1.0。
scan costs
扫描成本:这里我们需要指定每种扫描类型的成本
- 服务扫描:1
- 操作系统扫描:2
- 进程扫描:1
- 子网扫描:1
sensitive hosts
敏感主机:这里有两个目标主机
- (2, 0),1000:在敏感子网上运行的服务器,其值为 1000。
- (3, 2),1000:用户子网上运行的最后一个主机,其值为 1000。
这样,我们的 scenario就完全定义了,我们拥有运行攻击模拟所需的一切。
创建自定义 scenario
使用 NASim,可以使用有效 YAML 文件中定义的自定义 scenario。在本教程中,我们将介绍如何创建和运行您自己的自定义 scenario。
使用 YAML 定义自定义 scenario
在我们开始编写新的自定义 YAML scenario之前,值得看一些示例。NASim 附带了许多基准 YAML scenario,可以在目录中找到nasim/scenarios/benchmark, 或在 github 上查看。在本教程中,我们将使用该tiny.yaml scenario作为示例。
NASim 中的自定义 scenario需要定义组件:网络和渗透测试器。
定义网络
该网络由以下部分定义:
- 子网:网络中每个子网的大小
- 拓扑:定义哪些子网相互连接的邻接矩阵
- os:网络上可用的操作系统的名称
- services:网络上可用服务的名称
- 进程:网络上可用进程的名称
- hosts:网络上的主机及其配置的字典
- 防火墙:子网防火墙的定义
子网
此属性定义网络上的子网数量以及每个子网的大小。它简单地定义为一个有序的整数列表。列表中第一个子网的地址为1,第二个子网为2,依此类推。地址0为“互联网”子网保留(请参阅下面的拓扑部分)。例如,tiny网络包含 3 个子网,大小均为 1:
subnets: [1, 1, 1]
# or alternatively
subnets:
- 1
- 1
- 1拓扑
拓扑结构由邻接矩阵定义,其中一行和一列表示网络中的每个子网,另外还有一行和一列表示“互联网”子网,即与网络外部的连接。第一行和第一列为“互联网”子网保留。子网之间的连接用 表示,1而非连接用 表示0。请注意,我们假设连接是对称的,并且子网与自身相连。
对于tiny网络,子网1是公共子网,因此连接到互联网,由1第 1 行第 2 列和第 2 行第 1 列中的 表示。子网1还与子网2和3相连,由相关单元格中的 表示1,同时子网2和3是私有的,不直接连接到互联网,由0值表示。
topology: [[ 1, 1, 0, 0],
[ 1, 1, 1, 1],
[ 0, 1, 1, 1],
[ 0, 1, 1, 1]]操作系统、服务、进程
与我们定义子网列表的方式类似,操作系统、服务和进程由一个简单的列表定义。每个列表中任何项目的名称都可以是任何名称,但请注意,它们将用于验证主机配置、漏洞利用等,因此只需根据需要与这些值匹配即可。
os:
- linux
services:
- ssh
processes:
- tomcat继续我们的示例,该tiny scenario包括一个操作系统:linux,一个服务:ssh和一个进程:tomcat:
主机配置
主机配置部分是从主机地址到其配置的映射,其中地址是一个元组,配置必须包括主机操作系统、运行的服务、运行的进程和可选的主机防火墙设置。(subnet number, host number)
定义主机时需要注意以下几点:
- 每个子网定义的主机数量需要与每个子网的大小相匹配
- 子网内的主机地址必须从 开始
0并从那里开始计数(即,子网1中的三个主机的地址为、和)(1, 0)``(1, 1)``(1, 2)- 任何操作系统、服务和进程的名称都必须与YAML 文件的os、services和processes部分中提供的值匹配。
- 每个主机必须有一个操作系统和至少一个正在运行的服务。主机可以没有正在运行的进程(可以使用空列表来表示
[])。
主机防火墙被定义为从主机地址到拒绝来自该主机的服务列表的映射。主机地址必须是网络中主机的有效地址,并且任何服务也必须与服务部分中定义的服务相匹配。最后,如果主机地址不是防火墙的一部分,则假定在主机级别允许来自该主机的所有流量(子网防火墙仍可能阻止该流量)。
主机值是Agent在入侵主机时将收到的可选值。与sensitive_hosts部分不同,此值可以是负数,也可以是零和正数。这使得可以设置额外的主机特定奖励或惩罚,例如为网络上的“蜜罐”主机设置负奖励。需要注意以下几点:
- 主机值是可选的,默认为 0。
- 对于任何敏感主机,该值要么未指定,要么必须与文件的sensitive_hosts部分中指定的值匹配。
- 与敏感主机相同,Agent只有在破坏主机时才会收到价值作为奖励。
这是该 scenario的示例主机配置部分tiny,其中主机防火墙仅为主机定义,并且主机的值为(注意,在这种情况下我们可以不指定值以获得相同的结果,我们在此处将其作为示例):(1, 0)``(1, 0)``0
host_configurations:
(1, 0):
os: linux
services: [ssh]
processes: [tomcat]
# which services to deny between individual hosts
firewall:
(3, 0): [ssh]
value: 0
(2, 0):
os: linux
services: [ssh]
processes: [tomcat]
firewall:
(1, 0): [ssh]
(3, 0):
os: linux
services: [ssh]
processes: [tomcat]防火墙
定义网络的最后一部分是防火墙,它被定义为从三元组到允许的服务列表的映射。定义防火墙时需要注意以下几点:(subnet number, subnet number)
- 防火墙规则只能在拓扑邻接矩阵中连接的子网之间定义。
- 每条规则定义单向允许哪些服务,从元组中的第一个子网到元组中的第二个子网(即(源子网,目标子网))
- 空列表意味着从源到目的地的所有流量都将被阻止
tiny这是允许所有子网之间进行 SSH 流量(子网 1 到 0 和子网 1 到 2 除外)的 scenario的防火墙定义。
# two rows for each connection between subnets as defined by topology
# one for each direction of connection
# lists which services to allow
firewall:
(0, 1): [ssh]
(1, 0): []
(1, 2): []
(2, 1): [ssh]
(1, 3): [ssh]
(3, 1): [ssh]
(2, 3): [ssh]
(3, 2): [ssh]至此,我们已经涵盖了定义 scenario网络所需的一切。接下来是定义渗透测试器。
定义渗透测试人员
渗透测试器由以下部分定义:
- sensitive_hosts:包含敏感/目标主机地址及其值的字典
- 功绩:功绩词典
- privilege_escalation:特权升级操作词典
- os_scan_cost:使用操作系统扫描的成本
- service_scan_cost:使用服务扫描的成本
- process_scan_cost:使用进程扫描的成本
- subnet_scan_cost:使用子网扫描的成本
- step_limit:渗透测试人员在单次测试中可以执行的最大操作数
敏感主机
此部分指定网络中目标主机的地址和值。当渗透测试人员获得这些主机的 root 访问权限时,他们将收到指定的值作为奖励。sensitive_hosts 部分是一个字典,其中的条目是地址、值对。其中地址是一个元组,值是一个非负浮点数或整数。(subnet number, host number)
在此tiny scenario中,渗透测试人员的目标是获取主机和的 root 访问权限,这两个主机的值均为 100:(2, 0)``(3, 0)
sensitive_hosts:
(2, 0): 100
(3, 0): 100漏洞
漏洞利用部分是一本将漏洞利用名称映射到漏洞利用定义的字典。每个 scenario至少需要一个漏洞利用。漏洞利用定义是一本必须包含以下条目的字典:
service
:漏洞所针对的服务的名称。
- 请注意,该值必须与网络定义的服务部分中定义的服务名称匹配。
os
:漏洞所针对的操作系统的名称,或
none漏洞是否适用于所有操作系统。
- 如果值不是,则必须与网络定义的操作系统
none部分中定义的操作系统的名称匹配prob:在满足所有先决条件的情况下,漏洞利用成功的概率(即目标主机被发现且可访问,并且主机正在运行目标服务和操作系统)
cost:执行操作的成本。这应该是非负整数或浮点数,可以以任何方式表示操作的成本(财务、时间、产生的流量等)
access:漏洞利用成功后,渗透测试人员将获得对目标主机的访问权限。该权限可以是user或root。
漏洞的名称可以是任何您想要的名称,只要它们是不可变的、可哈希的(即字符串、整数、元组)并且是唯一的。
示例tiny scenario只有一个漏洞e_ssh,该漏洞针对的是 Linux 主机上运行的 SSH 服务,成本为 1,并导致用户级别访问:
exploits:
e_ssh:
service: ssh
os: linux
prob: 0.8
cost: 1
access: user权限提升
与漏洞利用部分类似,特权升级部分是一本将特权升级操作名称映射到其定义的字典。特权升级操作定义是一本字典,必须包含以下条目:
process
:操作所针对的进程的名称。
- 该值必须与网络定义的进程部分中定义的进程的名称匹配。
os
:操作所针对的操作系统的名称,或
none漏洞是否适用于所有操作系统。
- 如果值不是,则它必须与网络定义的os
none部分中定义的 OS 的名称匹配。prob:在满足所有先决条件的情况下,操作成功的概率(即渗透测试人员可以访问目标主机,并且主机正在运行目标进程和操作系统)
cost:执行操作的成本。这应该是非负整数或浮点数,可以以任何方式表示操作的成本(财务、时间、产生的流量等)
access:操作成功后,渗透测试人员将获得对目标主机的访问权限。可以是user或root。
与漏洞利用类似,每个特权漏洞利用操作的名称可以是任何您想要的名称,只要它们是不可变的、可散列的(即字符串、整数、元组)并且是唯一的。
笔记
scenario不需要定义任何特权升级操作。在这种情况下,将特权升级部分定义为空:。privilege_escalation: {}
但请注意,您需要确保仅通过使用漏洞就可以获得敏感主机的 root 访问权限,否则渗透测试人员将永远无法达到目标。
示例tiny scenario有一个单一的权限提升操作pe_tomcat,该操作针对在 Linux 主机上运行的 tomcat 进程,成本为 1,并导致 root 级别访问:
privilege_escalation:
pe_tomcat:
process: tomcat
os: linux
prob: 1.0
cost: 1
access: root扫描费用
每次扫描都必须有一个相关的非负成本。此成本可以代表任何您希望的值,并且将计入Agent每次执行扫描时收到的奖励中。
扫描成本很容易定义,只需要一个非负浮点数或整数值。您必须指定所有扫描的成本。在这里,在示例tiny scenario中,我们为所有扫描定义成本为 1:
service_scan_cost: 1
os_scan_cost: 1
subnet_scan_cost: 1
process_scan_cost: 1步数限制
步骤限制定义了渗透测试人员在单个 scenario中达到目标的最大步骤数(即操作数)。在模拟过程中,一旦达到步骤限制,则认为该 scenario已完成,Agent未能达到目标。
定义步长限制很容易,因为它只需要一个正整数值。例如,这里我们为以下 scenario定义步长限制为 1000 tiny:
step_limit: 1000这样我们就有了定义自定义 scenario所需的一切。
运行自定义 YAML scenario
NASimEnv要从自定义 YAML scenario文件创建,我们使用以下nasim.load()函数:
import nasim
env = nasim.load('path/to/custom/scenario.yaml`)加载函数还采用一些附加参数来控制环境的观察模式和观察和动作空间,请参阅NASimEnv 加载参考以获取参考和环境设置以获取解释。
如果您的文件格式存在任何问题,您在尝试加载文件时应该会收到一些有用的错误消息。成功加载环境后,您可以正常与其交互(有关更多详细信息,请参阅与 NASim 环境交互)。
scenario生成说明
生成 scenario涉及许多设计决策,这些决策在很大程度上决定了要生成的网络的形式。本文档旨在解释使用 scenario生成器类生成 scenario的一些技术细节。
scenario生成器主要基于先前的研究,具体来说:
- Sarraute, Carlos, Olivier Buffet, and Jörg Hoffmann. “POMDPs make better hackers: Accounting for uncertainty in penetration testing.” Twenty-Sixth AAAI Conference on Artificial Intelligence. 2012.
- Speicher, Patrick, et al. “Towards Automated Network Mitigation Analysis (extended).” arXiv preprint arXiv:1705.05088 (2017).
网络拓扑结构
描述即将发布。在此之前,我们建议阅读上面链接的论文,尤其是 Speicher 等人 (2017) 的附录。
相关配置
生成 scenario时, scenariouniform=False将与主机配置相关联。这意味着,它运行的操作系统和服务不是从可用的操作系统和服务中随机均匀地选择,而是随机选择,并且会提高由较早生成配置的其他主机运行的操作系统和服务的概率。
具体来说,网络中每台主机的配置分布都是使用嵌套狄利克雷过程生成的,因此整个网络主机将具有相关的配置(即某些服务/配置在网络主机之间更为常见)。可以使用三个参数来控制相关性:alpha_H、alpha_V和lambda_V。
alpha_H并alpha_V控制相关程度,值越低,相关程度越大。
lambda_V控制每个主机运行的服务的平均数量,值越高意味着平均主机的服务越多(因此越容易受到攻击)。
所有三个参数都必须有一个正值,默认值为alpha_H=2.0、alpha_V=2.0和lambda_V=1.0,这往往会生成具有相当相关配置的网络,其中主机平均只有一个漏洞。
生成的漏洞概率
每个漏洞的成功概率根据参数的值确定exploit_probs,如下所示:
exploit_probs=None- 从区间 (0, 1) 上的均匀分布随机生成的概率。exploit_probs=float- 每个漏洞的概率设置为浮点值,该值必须是一个有效的概率。exploit_probs=list[float]- 每个漏洞的概率设置为列表中相应的浮点值。这要求列表的长度与参数指定的漏洞数量相匹配num_exploits。exploit_probs="mixed"- 概率从基于2017 年CVSS十大漏洞攻击复杂度分布的集合分布中选择。具体而言,漏洞利用概率从 [0.3, 0.6, 0.9] 中选择,分别对应高、中、低攻击复杂度,概率为 [0.2, 0.4, 0.4]。
对于确定性漏洞设置exploit_probs=1.0。
防火墙
防火墙限制不同子网中的主机之间可以通信的服务。这主要是通过在每个子网之间随机选择要阻止的服务来实现的,但会有一些限制。
首先,用户区内子网间不存在防火墙,因此所有服务都允许不同用户子网上的主机间进行通信。
其次,阻止的服务数量由参数控制restrictiveness。这控制了区域之间(即互联网、DMZ、敏感和用户区域之间)阻止的服务数量。
第三,为了确保目标能够实现,每个区域之间将允许至少一个运行在每个子网上的服务的流量。这可能意味着将允许比限制性参数更多的服务。
解释
模拟与现实差距考虑
NASim 是一个相当简化的网络渗透测试模拟器。它的主要目标是在一个易于使用且快速的模拟器中捕捉网络渗透测试的一些关键特性,以便在更真实的环境中测试这些算法之前,可以用它来快速测试和原型设计算法。也就是说,NASim 中的 scenario与现实世界之间存在一些差距。
在本文档中,我们想列出一些在尝试将算法扩展到 NASim 之外时需要考虑的事项。这绝不是一个详尽的清单,但希望能为您下一步的思考提供一些参考,并解释 NASim 中做出的一些设计决策。
处理部分可观察性
NASim 做出的一大假设是,渗透测试Agent可以访问网络中每个主机的网络地址,即使在部分可观察模式下也是如此。此信息在其操作列表中提供给Agent。在现实世界中,根据 scenario的不同,此假设可能无效,而渗透测试人员面临的部分挑战是能够在网络中导航时发现新主机。
NASim 使用已知网络地址实现的主要原因是,这样可以固定动作空间大小,从而更容易与典型的深度强化学习算法(即具有固定大小输入和输出层的神经网络)一起使用。
研究挑战之一是开发能够处理随着渗透测试人员发现更多网络地址而变化的动作空间的算法,或者更现实的情况是,渗透测试人员的动作空间是多维的,包括分别选择地址和利用/扫描/等。实际上,NASim 中内置了一些对此的支持,即 nasim.envs.action.ParameterisedActionSpace 动作空间(参见Actions),但即使使用该动作空间,也会向渗透测试人员提供一些有关网络大小的信息。
目前还没有计划更新 NASim 以支持无信息动作空间。这部分是由于时间原因,但也是为了保持 NASim 的简单和稳定,因为现在有很多更好、更现实的环境正在开发中(例如CybORG)。
处理变化的动作空间的一种方法是使用自回归动作,就像AlphaStar所做的那样。
CSLE 仿真环境
什么是 CSLE?
CSLE 是一个用于评估和开发强化学习代理以解决网络安全控制问题的框架。CSLE 中的网络仿真、模拟和学习等所有内容都经过共同设计,旨在提供一个环境,使人们能够训练和评估强化学习代理以完成实际的网络安全任务。
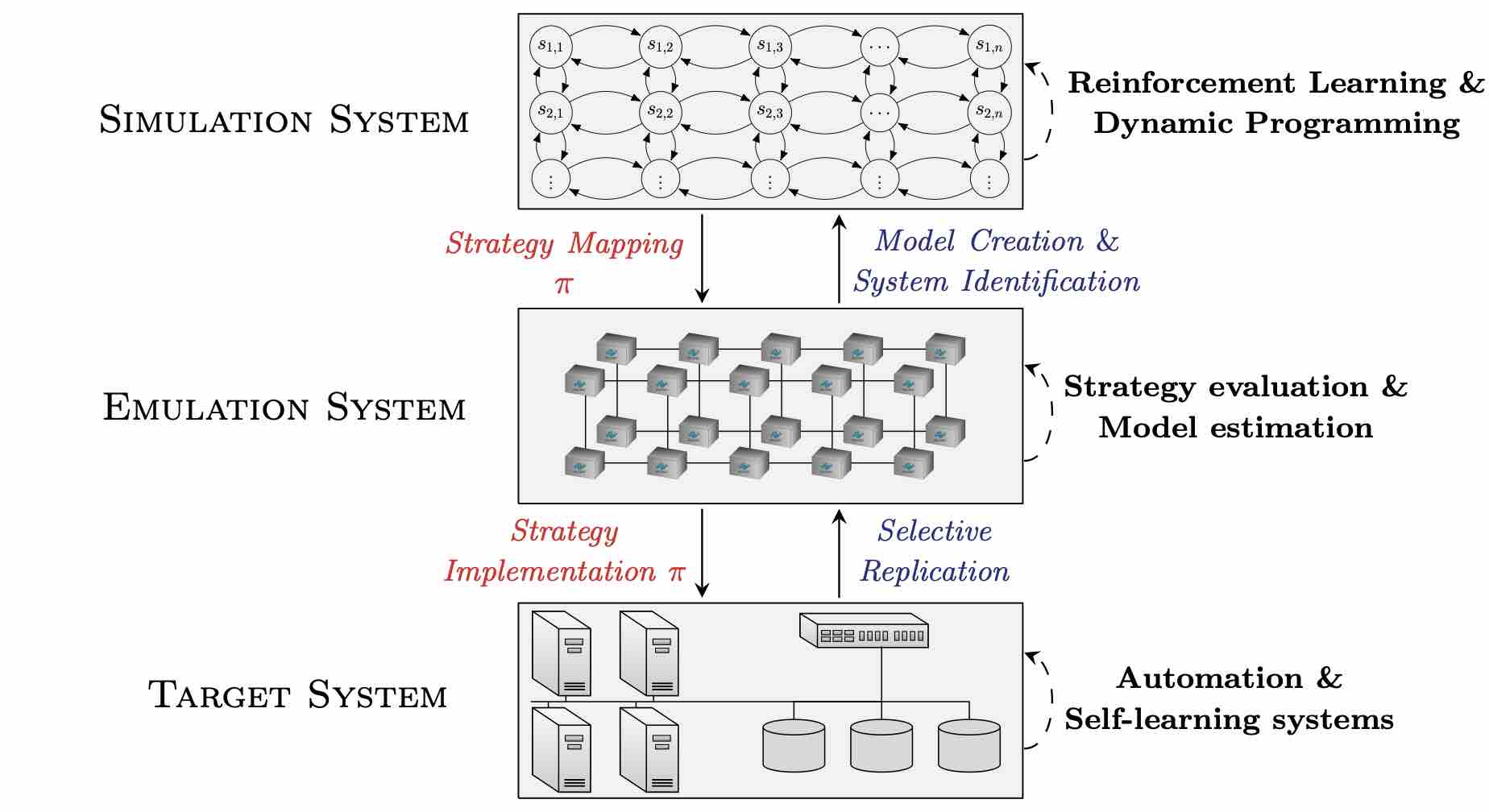
图 1:CSLE 中用于自动查找有效安全策略的方法。
该方法包括两个系统:仿真系统和模拟系统。仿真系统与目标基础设施的功能非常接近,用于运行攻击场景和防御者响应。此类运行会产生系统测量值和日志,据此估算基础设施统计数据,然后用于实例化马尔可夫决策过程 (MDP)。
模拟系统用于模拟实例化的MDP,并通过强化学习来学习安全策略。从模拟系统中提取学习到的策略,并在仿真系统中进行评估。
该方法有三个好处:
(i)仿真系统提供了一个评估策略的真实环境;
(ii)仿真系统允许评估策略而不影响目标基础设施上的操作工作流程;
(iii)模拟系统能够高效、快速地学习策略。
管理系统
管理系统是 CLSE 的核心组件,管理框架的整体执行。它是一个分布式系统,由通过 IP 网络连接的 N>=1 个物理服务器组成。其中一个服务器被指定为“领导者”,其他服务器为“工作者”。管理系统可用于实时监控模拟、启动或停止服务、监控强化学习工作负载、访问模拟组件的终端以及检查安全策略。
仿真系统
仿真系统允许模拟大规模 IT 基础设施和网络流量,即客户端流量、网络攻击和自动防御。它在运行由 Docker 容器和虚拟链接提供的虚拟化层的机器集群上执行。它使用网络命名空间和 Linux 内核中的 NetEm 模块在容器上实现网络隔离和流量整形。使用 cgroups 强制执行容器的资源限制,例如 CPU 和内存限制。
模拟系统
CSLE 的模拟系统允许运行强化学习和优化算法来学习安全策略。正式地,我们将攻击者和防御者之间的互动建模为马尔可夫博弈。然后,我们使用自我游戏模拟,其中自主代理进行互动并根据以前玩过的游戏的经验不断更新其策略。要自动更新游戏中的策略,可以使用多种方法,包括计算博弈论、动态规划、进化算法和强化学习。
为什么选择 CSLE?
网络攻击的普遍性和不断演变的性质越来越受到社会关注, 安全流程和功能的自动化已被视为应对这一威胁的重要组成部分。实现这种自动化的一种有前途的方法是强化学习,它已被证明可有效找到多个领域(例如机器人和工业自动化)中控制问题的近乎最优的解决方案。
虽然这方面研究已经取得了令人鼓舞的成果,但关键挑战仍然存在。其中最主要的是缩小强化学习代理的评估环境与真实系统中场景之间的差距。迄今为止获得的大多数结果仅限于模拟环境,目前尚不清楚它们如何推广到实际的 IT 基础设施。先前研究的另一个局限性是缺乏通用的基准和工具集。
CSLE 的开发正是为了解决上述限制。通过使用高保真仿真,它缩小了评估环境与真实系统之间的差距,并且由于是开源的,它为进一步的研究提供了基础。
最近,人们开始努力构建与 CSLE 类似的框架(见 调查)。最值得注意的是 微软的 CyberBattleSim 、澳大利亚国防部的CyBorg 、英国国防科学技术实验室 (DSTL) 的 Yawning Titan 以及美国国家安全局 (NSA) 开发的FARLAND 。其中一些框架仅包含模拟组件,而另一些则同时包含模拟和仿真组件。与这些框架相比,CSLE 是完全开源的,既包含模拟组件又包含仿真组件,并且已经展示了在特定用例上学习近乎最佳的防御者策略的能力。
CyberBattleSim 仿真环境
Github: https://github.com/microsoft/CyberBattleSim.git
CyberBattleSim 是什么
CyberBattleSim是一款微软365 Defender团队开源的人工智能攻防对抗模拟工具,来源于微软的一个实验性研究项目。该项目专注于对网络攻击入侵后横向移动阶段进行威胁建模,用于研究在模拟抽象企业网络环境中运行的自动化智能体的交互。
网络拓扑和一组预定义的漏洞定义了进行模拟的环境。攻击者利用现有漏洞,通过横向移动在网络中进化,目标是通过利用计算机节点中植入的参数化漏洞来获取网络的所有权。防御者试图遏制攻击者并将其从网络中驱逐。 CyberBattleSim 为其模拟提供了 OpenAI Gym 接口,以促进强化学习算法的实验。
为什么要有模拟环境?
CyberBattleSim 仿真运行时环境提供高保真度和控制,框架中使用的是参数化的虚拟环境,模拟环境性能要求低,更轻量,速度快,抽象,并且可控性更强,适用于强化学习实验。优点如下:
- 抽象级别高,只需要建模系统重要的方面;例如应用程序级网络通信与数据包级网络模拟,忽略了低层的信息(例如,文件系统、注册表)。
- 灵活性:定义一个新的机器是很容易的,不需要考虑底层的驱动等,可以限制动作空间为可以管理且相关的子集。
- 可有效捕获全局状态,从而简化调试和诊断。
- 轻量级:在单台机器/进程的内存中运行。
CyberBattleSim的仿真固然简单,但是简单是具有优势的。高度抽象的性质使得无法直接应用于现实系统,从而防止了潜在的恶意训练的自动化智能体使用。同时,可以使我们更专注于特定的安全性方面,例如研究和快速实验最新的机器学习和AI算法。
当前的内网渗透实现方式侧重于横向移动,希望理解网络拓扑和配置并施加影响。基于这一目标,没有必要对实际的网络流量进行建模。
该项目主要采用了免模型学习(Model-Free),虽然在效率上不如有模型学习(Model-Based)(缺点是如果模型跟实际场景不一致,那么在实际使用场景下会表现的不好),但是这种方式更加容易实现,也容易在真实场景下调整到很好的状态。所以免模型学习方法更受欢迎,得到更加广泛的开发和测试。
CyberBattleSim 的工作原理
将强化学习应用于安全
让我们通过一个Demo示例来介绍如何使用 RL 术语进行模拟。我们的网络环境由有向注释图给出,其中节点代表计算机,边代表其他节点的知识或节点之间发生的通信。
在强化学习背景下思考软件安全问题:攻击者或防御者可以被视为在计算机网络提供的环境中进化的智能体。他们的动作是可用的网络和计算机命令。攻击者的目标通常是从网络中窃取机密信息。防御者的目标是驱逐攻击者或通过执行其他类型的操作来减轻他们对系统的行为。

图 1. 将强化学习概念映射到安全领域
CyberBattleSim中的强化学习建模:
- 环境:状态就是网络,单个智能体,部分可观测(智能体无法观测到所有的结点和边),静态的,确定性的,离散的,post-breach
- 行动空间(智能体可以逐步探索网络):本地攻击,远程攻击,认证连接
- 观测空间:发现结点,获取结点,发现凭证,特权提升,可用攻击
- 奖励:基于结点的内在价值,如SQL server比测试机器重要
计算机网络系统比视频游戏复杂得多。虽然视频游戏通常一次允许执行少量操作,但与计算机和网络系统交互时,可以执行大量操作。例如,与棋盘游戏中有限的位置列表不同,网络系统的状态可能非常庞大,并且不易可靠地检索。
CyberBattleSim 示例
CyberBattleSim 专注于对网络攻击的后入侵横向移动阶段进行威胁建模。该环境由计算机节点网络组成。它由固定的网络拓扑和一组预定义的漏洞参数化,智能体可以利用这些漏洞在网络中横向移动。模拟攻击者的目标是通过利用这些植入的漏洞来控制网络的某些部分。当模拟攻击者在网络中移动时,防御者智能体会监视网络活动以检测攻击者的存在并遏制攻击。
为了说明这一点,下图描绘了一个网络的简单示例,其中机器运行不同的操作系统、软件。每台机器都有一组属性、价值,并且都存在预先分配的漏洞。蓝色边缘代表节点之间运行的流量,并由通信协议标记。

图 2. 计算机网络模拟中横向移动的直观表示
该项目中的环境(environment)定义:
- 网络中结点的属性:如Windows,Linux,ApacheWebSite,MySql,nginx/1.10.3,SQLServer等。
- 开放的ports:如HTTPS,SSH,RDP,PING,GIT等。
- 本地漏洞包括:CredScanBashHistory,CredScan-HomeDirectory,CredScan-HomeDirectory等。
- 远程漏洞包括:ScanPageContent,ScanPageSource,NavigateWebDirectoryFurther,NavigateWebDirectory等。
- 防火墙配置为:允许进出的服务为RDP,SSH,HTTPS,HTTP,其他服务默认不允许。
- 定义了部分奖励与惩罚:发现新结点奖励,发现结点属性奖励,发现新凭证奖励,试图连接未打开端口的处罚,重复使用相同漏洞的惩罚等。
假设智能体代表攻击者。入侵后假设意味着一个节点最初感染了攻击者的代码(我们称攻击者拥有该节点)。模拟攻击者的目标 是通过发现并取得网络中节点的所有权来最大化累积奖励。环境是 部分可观察的:智能体无法提前看到网络图的所有节点和边。相反,攻击者采取行动,从其当前拥有的节点开始逐步探索网络。有 三种类型的操作,为智能体提供了开发和探索能力的混合:执行本地攻击、执行远程攻击和连接到其他节点。操作由底层操作应发生的源节点参数化,并且仅允许在智能体拥有的节点上执行。奖励 是 一个浮点数,表示节点的内在值(例如,SQL 服务器的价值大于测试机器)。
在图示的示例中,模拟攻击者从模拟的 Windows 7 节点(左侧,橙色箭头指向)入侵网络。它利用 SMB 文件共享协议中的漏洞横向移动到 Windows 8 节点,然后使用一些缓存的凭据登录另一台 Windows 7 计算机。然后,它利用 IIS 远程漏洞来控制 IIS 服务器,最后使用泄露的连接字符串访问 SQL DB。
该环境模拟了支持多个平台的异构计算机网络,并有助于展示如何使用最新的操作系统并使这些系统保持最新状态,从而使组织能够利用 Windows 10 等平台中最新的强化和保护技术。模拟 Gym 环境通过网络布局的定义、支持的漏洞列表以及漏洞所在的节点进行参数化。模拟不支持机器代码执行,因此实际上不会发生任何安全漏洞。我们改为使用定义以下内容的先决条件抽象地对漏洞进行建模:漏洞活跃的节点、成功利用的概率以及结果和副作用的高级定义。节点具有预先分配的命名属性,先决条件通过布尔公式表示。
防御 智能体主要通过预测攻击成功的可能性的基础之上实现了识别、减缓攻击的行为。主要通过重装镜像(re-image)的方式抵御攻击,通过计算攻击者的步骤数和持续性的奖励分数来衡量当前攻击策略的优劣性。通过返回的数据字段内容来确认各种攻击的成功性。(防御遍历所有节点,如果发现该节点可能存在漏洞(定义了一个概率函数计算可能性),先使该节点不可用,再通过重装镜像的方式抵御攻击)。
支持的漏洞和攻击类型
模拟环境由网络定义参数化,网络定义由底层网络图本身以及支持的漏洞及其所在节点的描述组成。由于模拟不运行任何代码,因此无法实际实现漏洞和利用。相反,我们通过定义以下内容对每个漏洞进行抽象建模: 确定漏洞在给定节点上是否处于活动状态的前提条件;攻击者成功利用它的概率;以及成功利用的副作用。每个节点都有一组分配的命名属性。然后,前置条件被表示为可能的节点属性(或标志)集上的布尔表达式。
漏洞结果
每个漏洞都有一个预定义的结果,其中可能包括:
- 一组泄露的凭据;
- 对网络中另一个节点的引用被泄露;
- 泄露节点信息(节点属性);
- 节点的所有权;
- 节点上的权限升级。
远程漏洞的示例包括:
- 公开凭据的 SharePoint 站点
ssh(但不一定是远程计算机的 ID)暴露; - 授予计算机访问权限的ssh 漏洞;
- 在提交历史记录中泄露凭据的 GitHub 项目;
- SharePoint 站点的文件包含存储帐户的 SAS Token;
本地漏洞示例:
- 从系统缓存中提取身份验证Token或凭据;
- 升级到SYSTEM权限;
- 升级至管理员权限。
漏洞可以在节点级别就地定义,也可以全局定义并由前置条件布尔表达式激活。
基准:衡量进展
我们提供了一个基本的随机防御者,它根据预定义的成功概率检测和缓解正在进行的攻击。为了比较智能体的性能,主要关注两个指标:为实现其目标而采取的模拟步骤数,以及跨训练时期模拟步骤的累积奖励。通过步骤梳理与累计的分数,评估最先进的强化学习算法,以研究自主智能体如何与它们交互并从中学习。
安全问题建模
Gym 环境的可参数化特性允许对各种安全问题进行建模。以一个Demo示例为例,在下图所示的计算机系统上玩的“夺旗”游戏。

例如,下面的代码片段受到夺旗挑战的启发,其中攻击者的目标是夺取网络中有价值的节点和资源的所有权。我们在toy_ctf.py的 Python 代码中正式定义了这个网络。以下是代码片段,展示了我们如何定义节点Website及其属性、防火墙配置和植入的漏洞:
nodes = {
"Website": m.NodeInfo(
services=[
m.ListeningService("HTTPS"),
m.ListeningService("SSH", allowedCredentials=[
"ReusedMySqlCred-web"])],
firewall=m.FirewallConfiguration(
incoming=default_allow_rules,
outgoing=default_allow_rules
+ [
m.FirewallRule("su", m.RulePermission.ALLOW),
m.FirewallRule("sudo", m.RulePermission.ALLOW)]),
value=100,
properties=["MySql", "Ubuntu", "nginx/1.10.3"],
owned_string="FLAG: Login using insecure SSH user/password",
vulnerabilities=dict(
ScanPageContent=m.VulnerabilityInfo(
description="Website page content shows a link to GitHub repo",
type=m.VulnerabilityType.REMOTE,
outcome=m.LeakedNodesId(["GitHubProject"]),
reward_string="page content has a link to a Github project",
cost=1.0
),
ScanPageSource=m.VulnerabilityInfo(
description="Website page source contains refrence to"
"browseable relative web directory",
type=m.VulnerabilityType.REMOTE,
outcome=m.LeakedNodesId(["Website.Directory"]),
reward_string="Viewing the web page source reveals a URL to"
"a .txt file and directory on the website",
cost=1.0
),
...
)
),
...图 4.描述模拟环境实例的代码
我们提供了一个 Jupyter 笔记本,以便在此示例中以交互方式扮演攻击者:
CyberBattleSim 实例过程
通过 Gym 界面,我们可以轻松实例化自动化智能体,并观察它们在此类环境中的演变情况。下面的屏幕截图显示了在此模拟中运行随机智能体的结果- 即在模拟的每个步骤中随机选择要执行的操作的智能体。

图 5. 与模拟交互的随机智能体
Jupyter 笔记本中的上图显示了累积奖励函数如何随着模拟步长(左)和探索的网络图(右)而增长,其中受感染的节点以红色标记。在这次运行中,大约需要 500 步才能达到此状态。日志显示许多尝试的操作都失败了,一些是因为防火墙规则阻止了流量,一些是因为使用了错误的凭据。在现实世界中,这种不稳定的行为应该会迅速触发警报,而防御性 XDR 系统(如 Microsoft 365 Defender)和 SIEM/SOAR 系统(如 Azure Sentinel)会迅速做出反应并驱逐恶意行为者。
这种Demo示例为攻击者提供了一种最佳策略,只需大约 20 次操作即可完全控制网络。人类玩家平均需要大约 50 次操作才能在第一次尝试中赢得这场游戏。由于网络是静态的,经过反复玩,人类可以记住正确的奖励动作顺序,并可以快速确定最佳解决方案。
项目中强化学习算法比较
使用多种算法在环境中获得的结果CyberBattleChain10:分别为Tabular Q-learning, Credential lookups, DQL(deep Q-learning), Exploiting DQL。
为了进行基准测试,我们创建了一个大小可变的简单Demo环境,并尝试了各种强化算法。下图总结了结果,其中 Y 轴是在多次重复的Epiosode(X 轴)中采取的完全控制网络的行动数量(越低越好)。如图所示,其中X轴是在多个episode,(Y轴)中为获得网络的完全所有权而采取的迭代数量(越低越好)。某些算法(如Exploiting DQL)随着episode增加可以逐渐改进并达很高水平,而有些算法在50 episode后仍在苦苦挣扎!

累积奖励图提供了另一种比较方式,其中智能体每次感染一个节点都会获得奖励。深色线表示中位数,而阴影表示一个标准差。这再次表明某些智能体(红色、蓝色和绿色)的表现明显优于其他智能体(橙色)。

CyberBattleSim 评估
项目的优势
- 借助OpenAI工具包,可以为复杂的计算机系统构建高度抽象的模拟,可视化的图像表达,使用户可以容易看到这些智能体的进化行为,通过步骤梳理与累计的分数,可以对当前的场景有个较好的展示,并评估出最合适的强化学习算法(其中经过实验得到的结果为Exploiting DQL算法最优
- CyberBattleSim的仿真固然简单,但是简单是具有优势的。高度抽象的性质使得无法直接应用于现实系统,从而防止了潜在的恶意训练的自动化智能体使用。同时,这种简单可以更专注于特定的安全性方面,例如研究和快速试验最新的机器学习和AI算法。项目目前专注于横向移动技术,目的是了解网络拓扑和配置如何影响这些技术。考虑到这样的目标,微软认为没有必要对实际的网络流量进行建模,但这是该项目实际应用的重大限制。
- 该项目相比于其他强化学习自动化渗透项目:如DEEPEXPLOIT框架,AutoPentest-DRL框架,这两个框架都使用了强化学习,nmap扫描,Metasploit攻击,但是他们并没有有效利用强化学习,主要原因在于他们的action只是根据各种漏洞对应相应的payload获取shell,该模式更像是监督学习,因为没有环境观察与反馈。CyberBattleSim项目有它自己的优势,虽然该项目并没有实现真实攻击,但是该项目完整地诠释了强化学习的步骤(包含观察环境与反馈),如果能开发出合适的工具使用,那么就可以实现更高效,准确度更高的渗透。
项目存在的问题
CyberBattleSim 除了提供智能体之外还可以通过Gym的基础提供参数化构建的虚拟网络环境、漏洞类型、漏洞出现的节点等。所以该项目其实只是一个强化学习的自动化攻击框架,并没有进行实际的攻击,网络中的所有节点,漏洞,漏洞类型等都是使用各种参数自定义的。
该项目的攻击方式包括本地攻击,远程攻击和连接其他节点,每种攻击只举了几个例子,然而实际过程中远远不止于此,需要学习训练就会是一个很耗时的过程。且该项目采用免模型学习(虽然该方法会更适用于当前网络环境),实际渗透中因为攻击方式众多,需要训练的时间也会更长,具体学习渗透的时间犹未可知。
CyberBattleSim项目提供的只是自动化攻击内网渗透项目当中必不可少的沙盒,只是一个用户产生虚拟攻防场景数据的工具,距离真实的项目还有很长的路要走,现有的强化学习最好的例子只存在于游戏(2016年:AlphaGo Master 击败李世石,使用强化学习的 AlphaGo Zero 仅花了40天时间;2019年4月13日:OpenAI 在《Dota2》的比赛中战胜了人类世界冠军),对于复杂的自动化攻击并不一定能胜任。
项目的发展
该项目更适合比较强化学习算法在内网渗透的优劣,因为该项目高度虚拟化,不考虑底层网络的信息,要使该项目成为一个真实的内网渗透工具是一个极大挑战。如下列出可能对该项目有所贡献的改进:
- 实现一个类似端口扫描操作(非确定性)的nmap,用来收集信息,而且该步骤不仅仅是渗透的开始工作,在渗透过程中也需要更新信息。
- 与现有的攻击工具结合或者开发更适合强化学习模型的攻击工具,用来真实的攻击。
- 奖励的定义也是强化学习中重要的一项内容,可以通过通用漏洞评分系统(CVSS)的组成部分所确定的漏洞得分来定义。
总结
本文针对自动化内网渗透这一方向对微软的开源项目CyberBattleSim做了介绍,通过对其内部原理和源码的分析,笔者指出了该项目的优势,存在的问题及其发展前景。该项目只是自动化攻击内网渗透项目中必不可少的沙盒,自动化渗透还有很长的路要走。
相关论文
NASimEmu: Network Attack Simulator & Emulator for Training Agents Generalizing to Novel Scenarios
Incorporating Deception into CyberBattleSim for Autonomous Defense
A Multiagent CyberBattleSim for RL Cyber Operation Agents
Developing Optimal Causal Cyber-Defence Agents via Cyber Security Simulation
CybORG: A Gym for the Development of Autonomous Cyber Agents
ACD-G: Enhancing Autonomous Cyber Defense Agent Generalization Through Graph Embedded Network Representation
Research on active defense decision-making method for cloud boundary networks based on reinforcement learning of intelligent agent
Network Environment Design for Autonomous Cyberdefense
Network Attack Simulation Model
节点数配置实验
Test on CyberBattleSim
| Network | Node size | Time (100 Steps) |
|---|---|---|
| Chain Network | 10 | 21.501863956451416 |
| Chain Network | 100 | 23.260196924209595 |
| Chain Network | 1000 | 2290.061856031418 |
| Chain Network | 10000 | numpy.core._exceptions._ArrayMemoryError: Unable to allocate 2.91 TiB for an array with shape (10000, 10000, 8, 1000) and data type int32 |