A2C
在第 4单元中,我们学习了第一个基于策略的算法,Reinforce。在基于策略的方法中,我们的目标是直接优化策略而不使用价值函数。更准确地说,Reinforce 是Policy-Based Methods子类的一部分,称为Policy-Gradient methods。该子类通过使用 Gradient Ascent 估计最优策略的权重直接优化策略。
我们看到 Reinforce 效果还不错。然而,因为使用蒙特卡洛抽样来估计回报(用一整个 Eposide 来计算回报),在策略梯度估计上方差非常大。
策略梯度估计是回报增长最快的方向。也就是,如何更新我们的策略权重,使得带来良好回报的动作更有可能被采纳。然而,蒙特卡洛采样带来的高方差会导致训练速度变慢,因为我们需要大量样本来减轻这一问题。
今天我们将研究Actor-Critic 方法,这是一种混合的架构,结合了基于价值和基于策略的方法,通过减少方差来帮助稳定训练:
- Actor:控制智能体行为方式(基于策略的方法)
- Critic:衡量**所采取动作的好坏 **(基于价值的方法)
我们将研究其中一种称为 Advantage Actor Critic (A2C) 的混合方法,并动手从零开始实现这一算法。
Reinforce 算法的方差问题
在 Reinforce 中,我们希望增加轨迹中动作的概率与回报的高低成正比。

- 如果回报高,将推高(状态,动作)组合的概率。
- 否则,如果回报很低,则降低(状态,动作)组合的概率。
回报 $R(\tau)$是使用蒙特卡洛采样计算的。我们收集智能体和环境交互的轨迹并计算折扣回报,并使用回报分数来增加或减少在该轨迹中采取的每个动作的概率。如果回报高,所有动作都将通过增加采取动作的可能性来“加强”。$R(\tau) = R_{t+1} + \gamma R_{t+2} + \gamma^2R_{t+3} + ... $
这种方法的优点是: 这种方法的估计是无偏的。因为我们没有估计回报,只是通过采样获得的真实回报来计算。
但是由于环境的随机性和策略的随机性,不同轨迹可能导致不同的回报, 因此带来的方差很高。因此,相同的起始状态可能导致截然不同的回报。正因为如此,从同一状态开始的回报在不同的Eposide中可能会有很大差异。
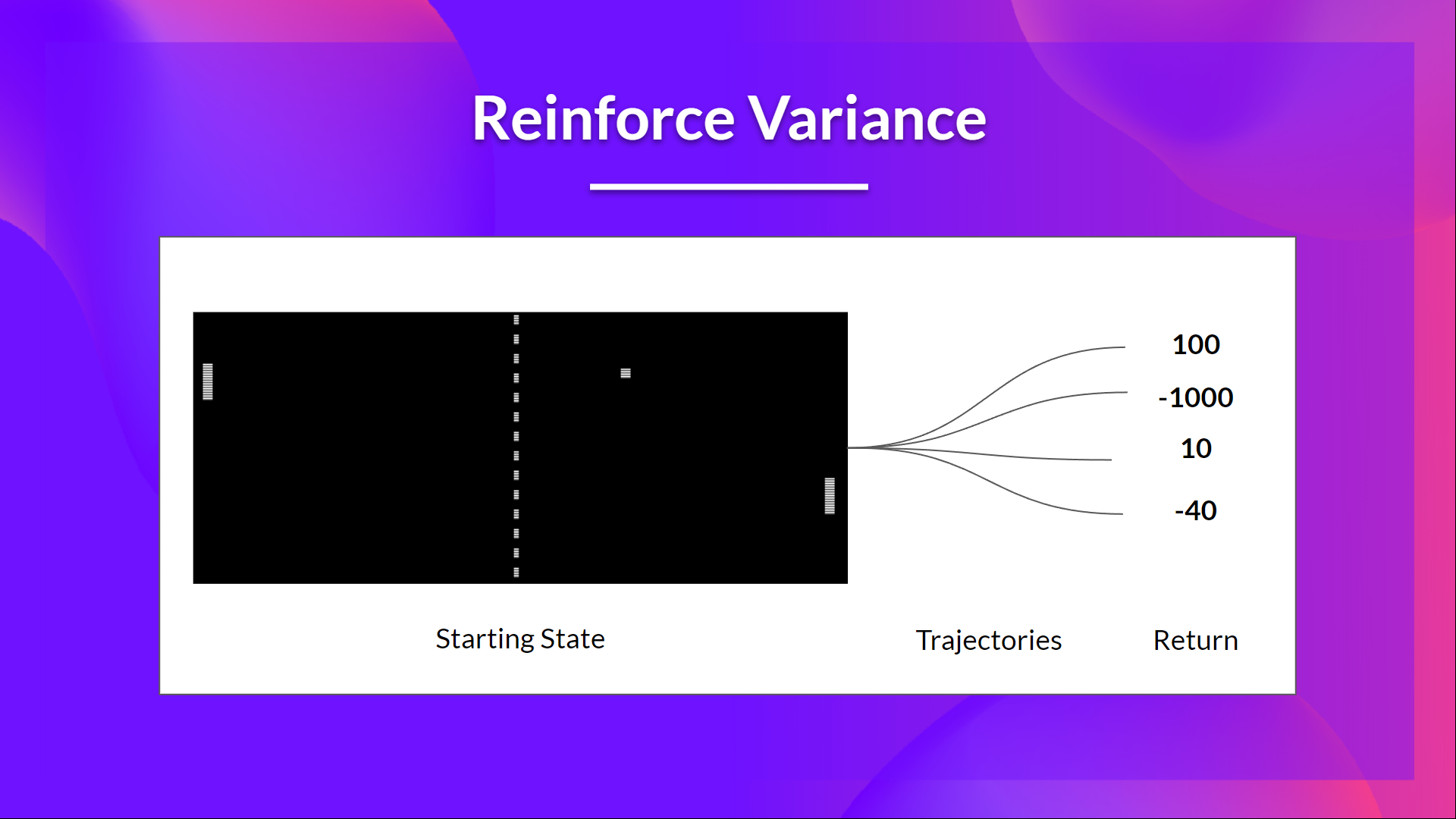
解决方案是通过使用大量轨迹来减轻方差 ,希望在任何一个轨迹中引入的方差都将总体减少,并提供一个“真实”的回报估计。
然而,增加Batch_size会显着降低采样效率。所以我们需要找到额外的机制来减少方差。
如果你想更深入地研究深度强化学习中的方差和偏差平衡问题,可以查看这两篇文章:
Actor Critic (AC)
使用 Actor-Critic 方法减少方差
减少 Reinforce 算法的方差并更快更好地训练智能体的解决方案是结合基于策略和基于价值的方法:Actor-Critic 方法。
要了解 Actor-Critic,请想象您玩电子游戏。你可以和一个朋友一起玩,他会给你一些反馈。你是Actor,你的朋友是Critic。

一开始你不知道怎么玩,所以你随机尝试一些动作。Critic 观察您的行为并提供反馈。
从这些反馈中学习, 您将更新您的策略并更好地玩这个游戏。
另一方面,您的朋友(Critic)也会更新他们提供反馈的方式,以便下次可以做得更好。
这就是 Actor-Critic 背后的想法。我们学习了两个函数逼近:
- 控制我们的智能体行为方式的策略函数:$\pi_{\theta}(s,a)$
- 通过衡量所采取的动作好坏的来协助策略更新的价值函数:$\hat{q}_{w}(s,a)$
Actor-Critic过程
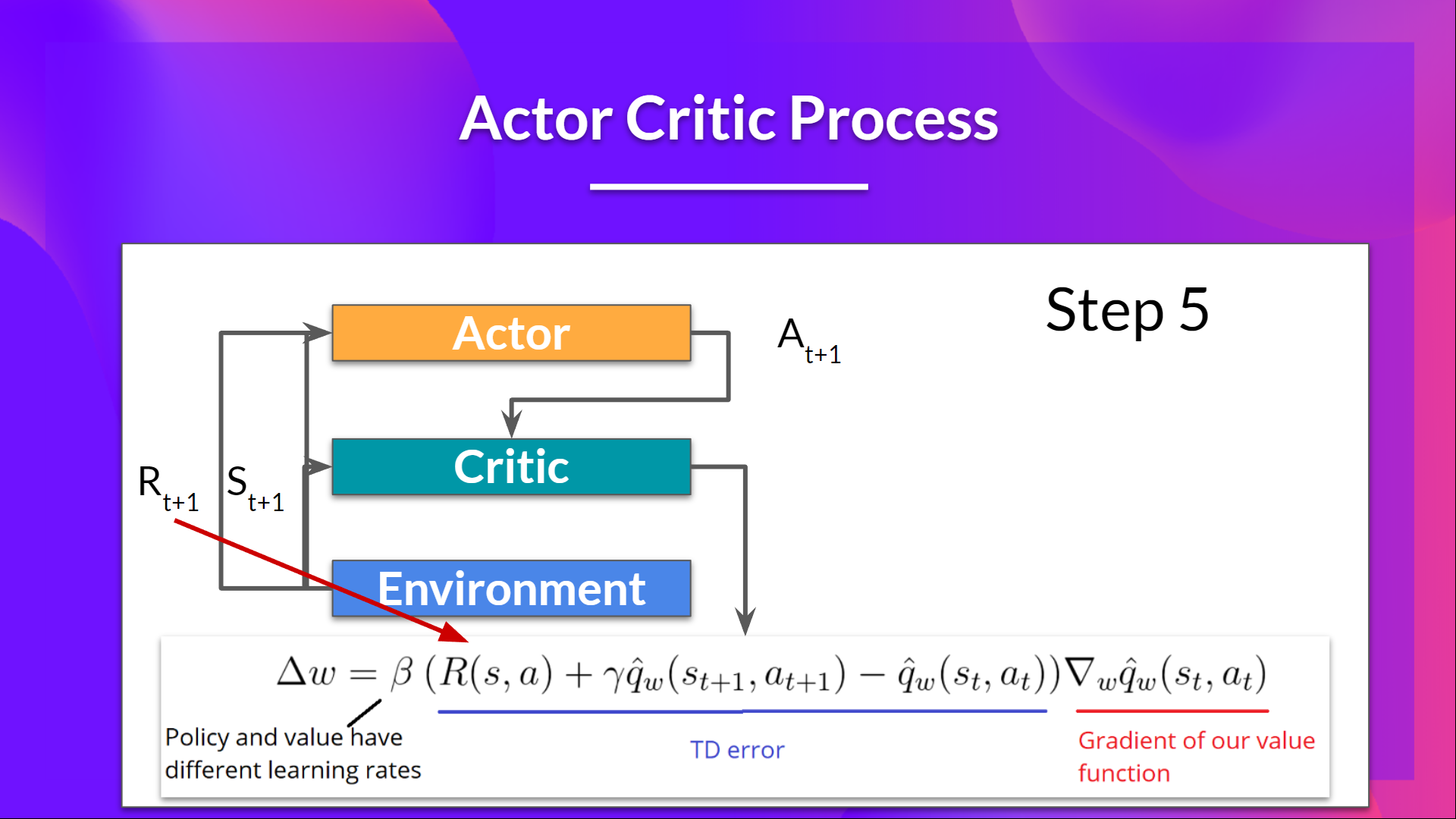
现在我们已经从大局层面理解了Actor Critic,接下来让我们更深入地了解 Actor 和 Critic 在训练过程中是如何进行改进和优化的。
正如我们所见,Actor-Critic 方法有两个函数近似(两个神经网络):
- Actor,由 theta 参数化的策略函数:$\pi_{\theta}(s,a)$
- Critic,由 w 参数化的价值函数:$\hat{q}_{w}(s,a)$
让我们看看训练过程,了解 Actor 和 Critic 是如何被优化的:
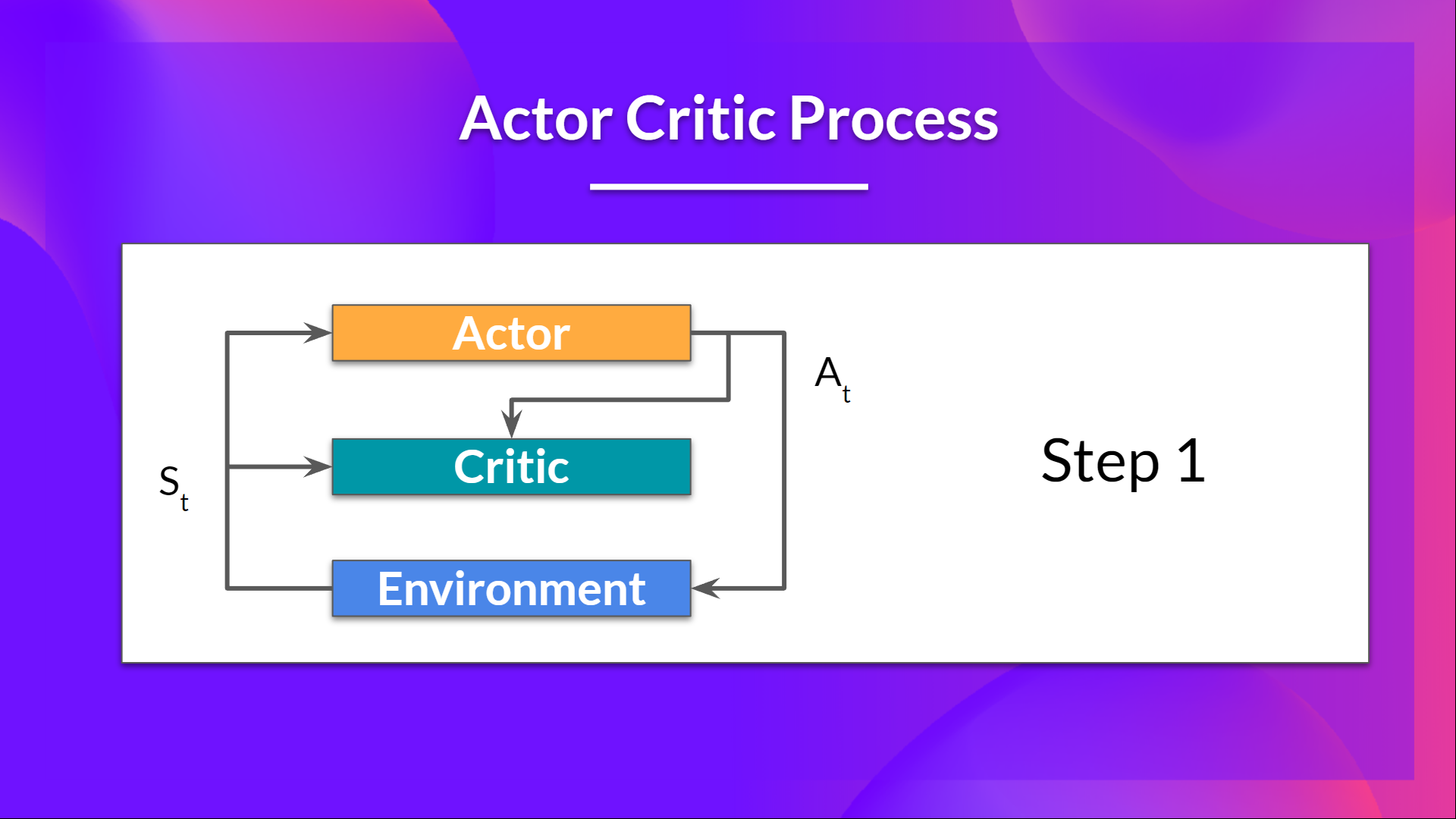
- 在每个时间步 t,我们得到当前的来自环境状态 $S_t$ ,并将其作为输入传递给我们的 Actor 和 Critic。
- 我们的策略获取状态 $S_t$ 并输出一个动作 $A_t$.
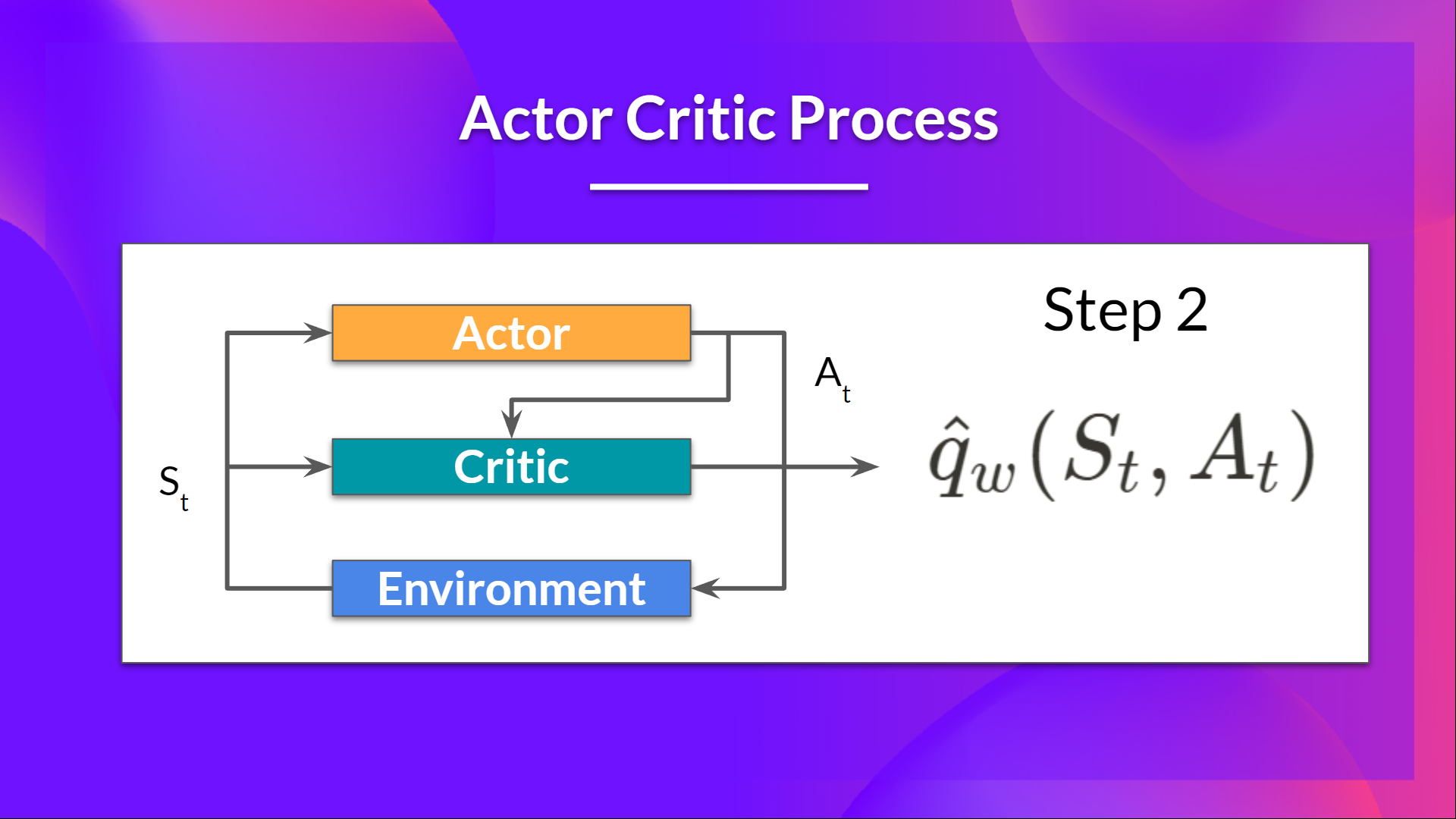
- Critic 也将该动作作为输入,并使用$S_t$ 和 $A_t$,计算在该状态下采取该动作的值:Q 值。
- 环境执行动作 $A_t$ 并输出一个新的状态 $S_{t+1}$ 和奖励 $R_{t+1}$.
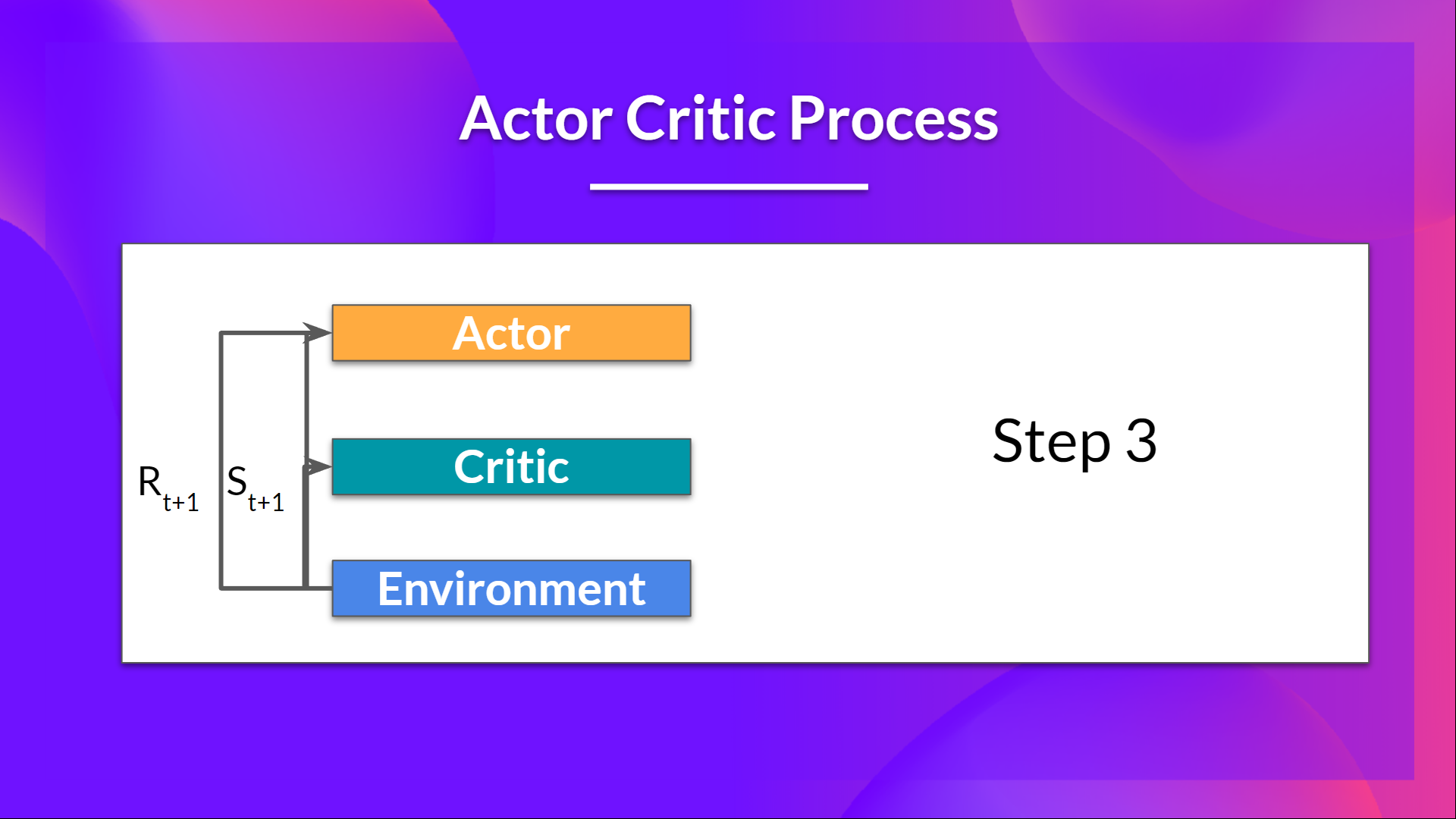
- Actor 使用 Q 值更新其策略参数。

- 更新完参数的 Actor,在给定新状态 $S_{t+1}$下产生了下一步要采取的动作 $A_{t+1}$ 。
- 然后 Critic 更新它的价值函数的参数。
Advantage ActorCritic (A2C)
我们可以通过使用 Advantage function 作为 Critic 而不是 Action value function 来 进一步稳定学习。
这个想法是 Advantage 函数计算在一个状态下采取该动作与该状态的平均值的相对优势。它通过从状态动作对中减去状态的平均值:

换句话说,这个函数计算的是如果我们在那个状态下采取这个动作,我们得到的额外奖励与我们在那个状态下得到的平均奖励相比的优势。
而额外的奖励则是超出该状态预期值的。
- 如果 A(s,a) > 0:我们的梯度被推向那个方向。
- 如果 A(s,a) < 0(我们的动作价值比那个状态的平均值要差),我们的梯度被推向相反的方向。
实现这个优势函数的问题在于它需要两个价值函数 $Q(s,a)$ 和 $V(s)$. 幸运的是, 我们可以使用 TD 误差作为优势函数的良好估计量。

既然您已经研究了Advantage Actor Critic(A2C)背后的理论,接下来我们将使用Pytorch 从头实现这一算法。
补充阅读
Bias-variance tradeoff in Reinforcement Learning
如果你想更深入地研究深度强化学习中的方差和偏差权衡问题,你可以查看这两篇文章:
- Making Sense of the Bias / Variance Trade-off in (Deep) Reinforcement Learning
- Bias-variance Tradeoff in Reinforcement Learning
Advantage Functions
- [Advantage Functions, SpinningUp RL](https://spinningup.openai.com/en/latest/spinningup/rl_intro.html?highlight=advantage functio#advantage-functions)