蒙特卡洛树搜索 (MCTS)
蒙特卡洛方法
蒙特卡罗方法(英语:Monte Carlo method),也称统计模拟方法,是1940年代中期由于科学技术的发展和电子计算机的发明,而提出的一种以概率统计理论为指导的数值计算方法。是指使用随机数(或更常见的伪随机数)来解决很多计算问题的方法。
20世纪40年代,在科学家冯·诺伊曼、斯塔尼斯拉夫·乌拉姆和尼古拉斯·梅特罗波利斯于洛斯阿拉莫斯国家实验室为核武器计划工作时,发明了蒙特卡罗方法。因为乌拉姆的叔叔经常在摩纳哥的蒙特卡洛赌场输钱得名,而蒙特卡罗方法正是以概率为基础的方法。
蒙特卡罗方法可以粗略地分成两类:一类是所求解的问题本身具有内在的随机性,借助计算机的运算能力可以直接模拟这种随机的过程。例如在核物理研究中,分析中子在反应堆中的传输过程。中子与原子核作用受到量子力学规律的制约,人们只能知道它们相互作用发生的概率,却无法准确获得中子与原子核作用时的位置以及裂变产生的新中子的行进速率和方向。科学家依据其概率进行随机抽样得到裂变位置、速度和方向,这样模拟大量中子的行为后,经过统计就能获得中子传输的范围,作为反应堆设计的依据。
另一种类型是所求解问题可以转化为某种随机分布的特征数,比如随机事件出现的概率,或者随机变量的期望值。通过随机抽样的方法,以随机事件出现的频率估计其概率,或者以抽样的数字特征估算随机变量的数字特征,并将其作为问题的解。这种方法多用于求解复杂的多维积分问题。
蒙特卡洛树搜索:概览
蒙特卡洛树搜索 (Monte Carlo Tree Search) 是一种决策算法,其基本思想是搜索由树形结构表示的组合空间。它搜索状态空间并构建构建有关特定状态下可用决策的统计证据,最终寻找最优决策。
形式上,蒙特卡洛树搜索(MCTS)可直接应用于可以通过马尔可夫决策过程(MDP)。MDP 建模的问题,这是一种离散时间随机控制过程。对MCTS的某些修改使其能够应用于部分可观察MDPs(POMDPs)。
MDP是一个被建模为元组 ($S$, $A_s$, $Pa$, $Ra$) 的过程,其中:
- $S$ 是环境中可能存在的状态集(状态空间), 初始状态$S_{0}$。
- $A_{s}$ 表示可用于在状态 S中执行的一组动作。
- $Pa(s, s')$ 在状态 $S$中执行动作 $a$ 将导致状态$S'$的概率建模的状态转移函数。
- $R_{a}(s)$ 是通过动作 $a$ 到达状态 $s$ 的即时奖励(回报)。
MCTS基本特征:
- 每个状态的价值$V{s}$通过 随机模拟(random simulation)来近似。
- ExpectiMax 搜索树是增量式地构建的。
- 当一些预定义的计算预算用完时(例如:超出时间限制或扩展的结点数),搜索将终止。 因此,它是一种任意时间算法,因为它可以随时终止并且仍然给出一个答案。
- 算法将返回表现最好的行动。
蒙特卡洛树搜索:框架
基本的蒙特卡洛树搜索框架很简单,使用模拟来构建一个 MDP 树。 评估状态存储在一个搜索树中。评估状态集合是通过迭代以下四个步骤 增量式 地构建的,该过程主要分为四步:选择(Selection),拓展(Expansion),模拟(Simulation),反向传播(Backpropagation)。
- 选择:在树中选择一个 未完全扩展 的单结点。选择总是从根节点开始,在每个水平,根据树选择策略选择下一个节点。当访问叶节点时,此阶段终止,并且下一个节点要么未在内存中表示,要么到达游戏的终端状态。
- 扩展:通过从该节点应用一个可用的行动(由 MDP 定义)来扩展该结点。除非选择达到终端状态,否则扩展将至少一个新子节点添加到内存中表示的树中。
- 模拟:从一个新结点中,对 MDP 进行一个完整的随机模拟,使其达到终止状态并获取收益。这是算法的“蒙特卡罗”部分。因此,这种做法假设搜索树是有限的,但是也存在无限大的树的版本,我们可以只在其中执行一段时间,然后估计结果。
- 反向传播:最后,将游戏中智能体的 收益/价值 从最后一个访问的节点 反向传播 到根结点的路径上的所有节点,使用期望价值更新途中经过的每个祖先结点的价值,统计数据更新。
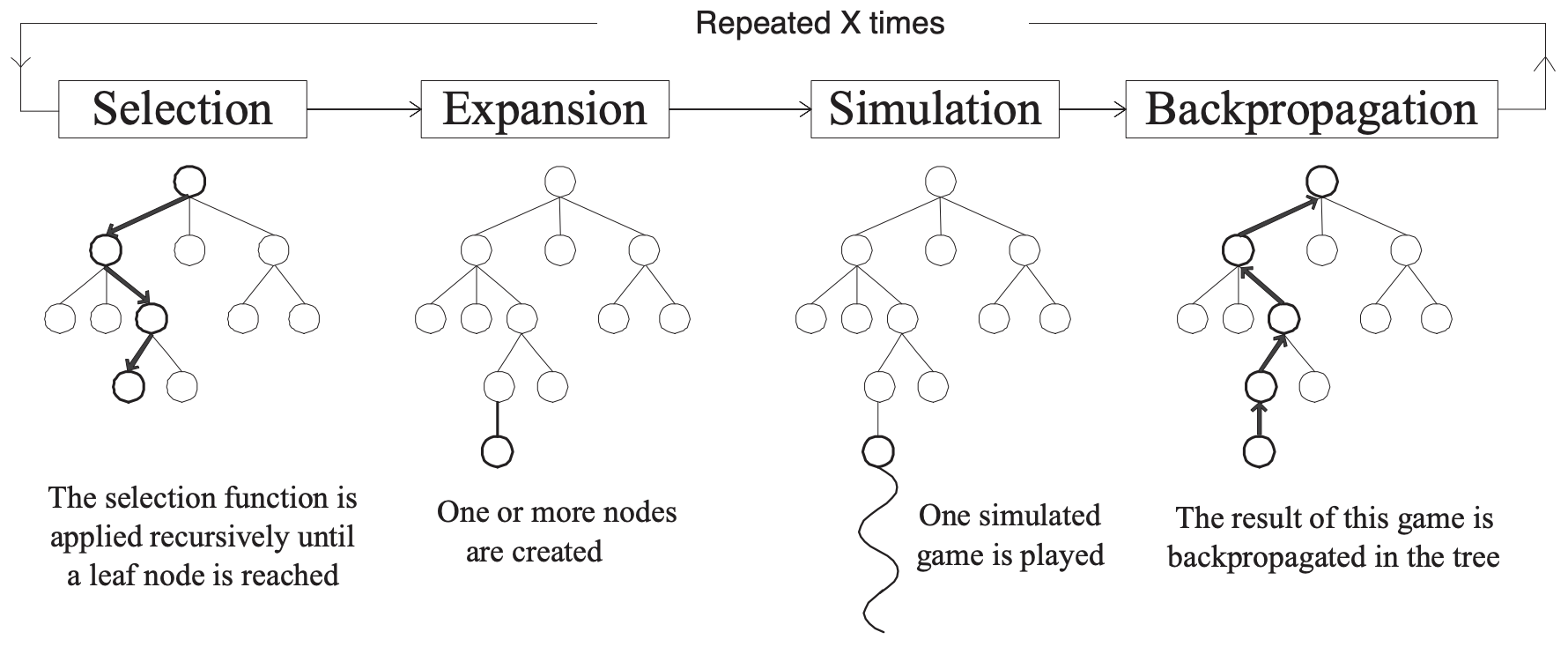
来源: Monte-Carlo Tree Search: A New Framework for Game AI. by Chaslot et al. In AIIDE. 2008. https://www.aaai.org/Papers/AIIDE/2008/AIIDE08-036.pdf
蒙特卡洛树搜索:流程
1. 基础知识
介绍 MCTS 的具体搜索算法之前,先介绍一下 MCTS 的基础知识。
1.1 节点
在棋类问题中,MCTS 使用一个节点来表示一个游戏状态,换句话说,每一个节点都对应着井字棋中的一种情况。假设现在井字棋的棋盘上只有中间一个棋子,图中用 ○ 画出,我们用一个节点表示这个游戏状态,这个节点就是下图中的根节点。这时,下一步棋有 8 种下法,所以对应的,这个根节点就有 8 个子节点。
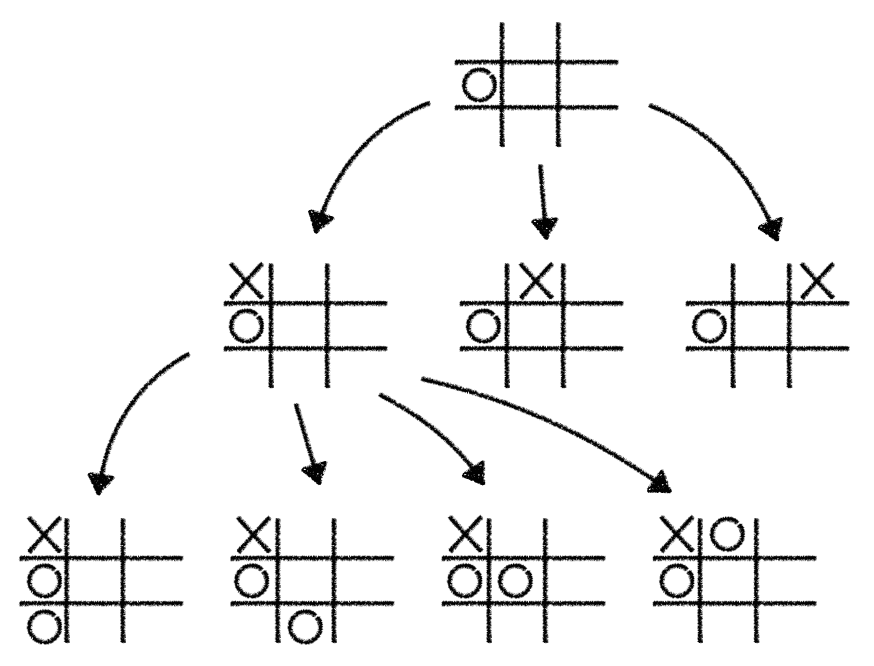
下完一步后,游戏还没有结束,棋盘上还可以继续下棋,继续按照刚才的方法,一个节点表示一个游戏状态,这些子节点又有子节点,所有的井字棋游戏状态都可以被这样表示,于是它们就构成了一个树。对于围棋或者其他更复杂的棋类也是一样,只不过这个树会更大、更复杂。蒙特卡洛树搜索就是要在这样一个树中搜索出下一步在哪个位置下棋最有可能获胜,即根节点的哪个子节点获胜概率最高。
1.2 节点的两个属性
在蒙特卡洛树搜索中,我们将节点记作 $v$ ,在搜索过程中需要记录节点的访问次数和累计奖励,它们的表示符号如下:
- $N(v)$:节点 $v$ 的访问次数,节点在搜索过程中被访问多少次,该值就是多少。
- $Q(v)$:节点 $v$ 的累计奖励,即节点在反向传播过程中获得的所有奖励(reward)求和。
所谓的奖励(reward)是一个数值,游戏结束时若获胜,奖励为 1,若失败,奖励为 -1。
2. 搜索过程
下面介绍 MCTS 的具体搜索算法。
给定当前游戏状态,如何获得下一步的最佳下法呢?对于井字棋来说,当然可以在整个决策树中遍历所有可能性,直接找出最优策略。但若换成围棋等复杂的棋类,遍历的方法是显然不可行的,这时就需要在决策树中有选择地访问节点,并根据现有的有限信息做出最优决策。
在介绍下面的搜索过程之前,我们首先要知道:蒙特卡洛树搜索搜的是什么?换句话说,假如我们先把 MCTS 看成一个黑盒子,那么它的输入和输出分别是什么?
输入:一个游戏状态
输出:下一步下棋的位置
也就是说,给 MCTS 一个棋局,它就告诉你下一步该怎么走。知道了输入输出分别是什么后,我们再来看看从输入到输出这中间,MCTS 到底做了什么。总的来说,MCTS 按顺序重复执行以下四个步骤:选择,拓展,模拟,反向传播。
2.1. 选择(Selection)
根据上文所述,对于围棋等可能性非常多的问题,遍历的方法不可行,因此 MCTS 有选择地访问节点,这就是选择阶段。
从根节点(就是输入)出发,根据一定的策略,向下选择一个节点进行访问,若被选择的节点未被访问过,则执行扩展;若被选择的节点已被访问,则访问该节点,并继续向下选择节点进行访问,直到遇见未被访问的节点,或遇见终止节点(游戏结束)。
选择的策略由多项式置信算法公式(Polynomial Upper Confidence Tree, PUCT)确定, 这个算法具体会根据式 (1) 给每个子结点计算一个分数,我们会不断选择分数最高的结点,直到到达一个叶结点。 $$ U(s, a)=Q(s, a)+c_{\text {puct } } P(s, a) \frac{\sqrt{\sum_b N(s, b)} }{N(s, a)+1} $$ 其中,加入父结点的状态为 $s$ ,经过父结点的动作 $a$ ,到达一个子结点,那么 这个子结点的分数由这个子结点的价值函数 $Q(s, a)$ 、这个子结点的先验概率 $P(s, a)$ 、这个子结点被采样到的个数 $N(s, a)$ 和父结点的所有采样个数的和的平方根 $\sqrt{\sum_b N(s, b)}$ 共同决 定,式 (1) 中, $c_{\text {puct } }$ 是一个常数, 用于权衡探索 (Exploration) 与利用 (Exploitation)。
我们知道,一个结点的价值函数代表了这个结点末来有可能收到的奖励的值,所以式(1)的
- 第一项代表某个结点的价值,这个价值越大,表示探索这个结点越有可能获取大的奖励;
- 第二项如果不考虑先验概率(这个概率由深度学习网络产生),那么这个值就和子结点被采样到的次数成反比,如果一个结点很少被采样到,那么第二项的访问次数的比值就会很大,从而就会 增加 $U(s, a)$ 的值,让这个结点更容易被采样到。
因此, $U(s, a)$ 的第一项和第二项分别代表智能体的利用和探索的部分。 而 $c_{\text {puct } }$系数控制了这两个部分之间的平衡,我们可以根据具体的问题来调节这个值的大小,让蒙特卡洛树搜索偏向于探索更好的结点或者探索尽可能多的结点。$c_{\text {puct } }$ 越大,就越偏向于探索;$c_{\text {puct } }$ 越小,就越偏向于利用。
2.2 扩展(Expansion)
MCTS 在搜索的过程中是有选择地访问节点,并把所有访问过的节点构建成一个树。扩展就是把选择步骤中遇到的未访问节点添加到树中,然后对该节点执行模拟。
在不断迭代选择了一个叶结点之后,需要考虑的问题是查看叶结点是否可以展开并添加子结点。
因为叶结点代表的是当前博弈(也就是棋盘)的一个状态,这个状态下所有可行的步骤都是由强化学习环境决定的。
也就是说,如果当前叶结点不是最终结点,那么可以根据当前的强化学习环境 (棋盘状态) 获取当前玩家所有可能的动作状态,并且根据这些状态建立子结点。
在子结点的建立过程中,我们需要考虑一个函数 $(v, p(s, a))=f(s)$ ,其中 $s$ 是棋盘当前状态的特征, $v$ 是当前局势的价值函数, $p(s, a)$ 对应的是在状态 $s$ 情况下,采取动作 $a$ 的先验概率。
这样,根据先验概率的值就能新建叶结点用于接下来的搜索。在AlphaGoZero和AlphaZero算法中, $(v, p(s, a))=f(s)$ 函数由一个深度学习模型决定,这个模型的输入是棋盘状态的特征对应的张量,输出当前局势的价值 $v$ 和所有子结点的先验概率 $p(s, a)$ 。
蒙特卡洛树搜索算法的目的之一就是训练这个深度学习模型,让模型能够根据当前的棋盘状态准确地估计价值和先验概率。
2.3 模拟 (Simulation)
模拟是一个粗略获取信息的过程。从被扩展的节点开始,对游戏进行模拟,也就是在棋盘上随机下棋,直到游戏结束或到达终止状态。若此时游戏胜利,则奖励 (Reward) 记为 1;若游戏失败,奖励记为 0。
2.4 反向传播 (Backpropagation)
反向传播是将在模拟中得到的奖励回溯更新的过程。为什么叫反向传播呢?回顾MCTS的第一步动作选择,我们从根节点向下一步一步地选择节点进行访问,得到了一条从根节点到叶子节点的路径, 路径的叶结点更新以后,需要考虑叶结点的扩展对于父结点的影响。现在从叶结点出发,反向回溯对应的决策路径,更新对应的价值函数。这里的价值函数使用的是所有到达过的叶结点的价值的平均值,如式 (2) 所 示。
将处于终止状态获得的奖励记作 $R$,对当前节点,及其路径上的所有节点 $v$ ,都执行以下操作。即,更新访问次数,对奖励进行累加。 $$ N(s_t, a_t)=N(s_t, a_t)+1 \ Q(s_t, a_t)=Q(s_t, a_t)+R \ Q(s_t, a_t)=\frac{1}{N(s_t, a_t)} \sum_{s^{\prime} \mid s, a \rightarrow s^{\prime} } V\left(s^{\prime}\right) $$ 假如最终到达的叶子结点的价值函数的值是 $V\left(s^{\prime}\right)$ ,如果叶子结点不是最終结点,那么这个值由前面提到的函数 $(v, p(s, a))=f(s)$ 估计得到,如果叶子结点是最终结点,那么这个值由最后的胜负状态决定,如果是平局,则这个值为 0 ;如果获胜一方是当前结点的玩家,则这个值 为 $+1$ ,反之则为 $-1$ 。在更新价值函数的同时,我们也需要更新回溯路径上每个结点的访问次 数 $N(s, a)$ ,让这个值加一。
3. 搜索结束
蒙特卡洛树搜索算法何时终结?一般设置以下两个终止条件。
- 设置最大根节点搜索次数,达到该次数后结束搜索。
- 设置最大搜索时间,超过时间后结束搜索。
4. 决策(选择最佳节点)
搜索结束后,如何选择下一步下棋的位置呢?
不是选择 $Q$ 最大的节点,也不是选择平均奖励最大的节点,而是选择访问次数最多的节点。这样,就得到了当前游戏状态(根节点)下的一个选择。或者,也可以将访问次数归一化,作为下一步的概率。
如果下一步还要进行决策,则又要将下一步的状态作为根节点,重新执行 MCTS,并选择访问次数最多的节点作为下一步的策略。(上一步的搜索结果可以保留).
在蒙特卡洛树搜索算法中,“选择→扩展和求值→模拟→回溯”这个过程要重复执行多次,直到到达一个指定的次数。
在这种情况下,我们相当于积界了很多对练的数据,同时获取了根结点所有可能的子结点的访问次数,这个访问次数代表不同结点的重要性。
一般来说,访问次数越高,代表当前结点的价值越高,越应该被选择。
根据这个原理,我们就可以估算出根结点的所有子结点的概率 $\pi=\alpha(a \mid s)$ ,这个概率的计算方法如式 (3) 所示,其中 $T$ 是温度系数,对应的访问次数越高,则代表结点的价值越高, 越容易被选择。而温度系数越高,则意味着访问次数多的结点和访问次数少的结点的概率差距越大。当温度趋向于zero的时候,访问次数最高的结点概率趋向于 1 ,其他结点的概率趋向于 0 。 有了这个概率的值,蒙特卡洛树搜索算法就可以根据这个值进行采样,把当前的根结点推进到 下一个子结点,这就是决策的过程,在决策后可以继续进行“选择→扩展和求值→回溯" 这个循环。
为了增加算法的随机性,AlphaGoZero和AlphaZero的原始文献中给这个概率增加了一个服从狄利克雷分布的噪声,如式 (4) 所示,其中 $\epsilon 、 \alpha$ 是可以调节的超参数。 $$ \begin{gathered} \pi(a \mid s)=\frac{N(s, a)^{\frac{1}{T} } }{\sum_b N(s, b)^{\frac{1}{T} } } \ \pi^{\prime}(a \mid s)=(1-\epsilon) \pi(a \mid s)+\epsilon \operatorname{Dirichlet}(\alpha) \end{gathered} $$
5. 总结
总结一下,蒙特卡洛树搜索算法包含了一系列的决策过程,每个决策过程都会包含多个“选择 $\rightarrow$ 扩展和求值→回溯" 循环,并且在循环结束的时候计算选择对应的动作概率进行决策,随机采样让根结点向前移动。
在决策到达终点,也就是得到对弈的结果之后,整条决策路径会被保存下来,同时,根据最后博弈的结果会给每个结点赋予一个具体的价值 $z$ ,根据结点当前的决策玩家是不是最后的赢家来决定 (如果是,则 $z=+1$ ,若不是,则 $z=-1$ ,平局 $z=0$ )。
蒙特卡洛树搜索:算法


整个算法过程是这样的。一开始,我们会找到根节点 S0,代表目前的游戏的一个状态,那么接下来判断它是否是叶节点,如果它不是叶节点,是一个中间节点的话,我们就计算出该结点下面的所有子结点的 UCB 值并且找到 UCB 值最大的子结点,然后将这个 UCB 最大值的子结点当作当前节点进行下一步迭代,继续判断当前结点是否是叶节点,若它还不是叶节点,我们就在这个结点下面计算它的所有子节点的 UCB 值并找出最大的结点当作当前结点继续进行迭代,直到找出一个结点是叶节点,我们就判断该节点的 n(探索的次数) 是否为 0,如果它的探索次数为 0,那么就代表该结点是没有被探索过的,那么我们就进行 ROLLOUT,如果不是 0,我们就枚举出当前结点所有的动作,并添加到树中,这一步相当于是 Node Expansion,然后我们将第一个新结点作为当前结点,然后进行 ROLLOUT。
输入:
- 输入游戏环境的 MDP 信息
- 初始状态 $s_0$
- 时间限制 $T$
每个结点存储:
- 该结点对应状态的 $V_s$(该状态价值的一个估计)
- 该状态被访问的次数
- 一个指向其父结点的指针
SELECT(root)
- 选择最大化 UCB 值的结点。
$$ UCB1(s_i)= \overline V_i + c \sqrt{\dfrac{\ln N(s)}{N(s,a)} } $$
- Vi:该结点下的平均 Value 大小
- C:常数,通常可以取 2,相当于是加号两边式子的一个权重
- N:总探索次数,就是对所有的结点一共 explore 了多少次
- ni:当前结点的探索次数
EXPAND(expand_node)
根据已选择的结点,随机选择一个适用于该状态且之前在该状态下未被选择的行动。
扩展该行动的所有可能的结果结点。
检查生成的结点是否已在树中。如果不在,则将这些结点添加到树中。
注意: $P_a(s'|s)$是随机的,因此可能需要多次访问才能生成所有后继结点。
SIMULATE(child)
- 对 MDP 执行随机模拟,直到达到终止状态。即,在每个选择点,从 MDP 中随机选择一个行动,并使用转移概率 $P_a(s'|s)$为每个行动选择一个结果。
- Reward 是在这个完整模拟中获得的回报。
下面用一段伪代码来表示模拟的过程
def Rollout(S_i): # S_i:当前状态
loop forever: # 无限循环
if S_i a terimal state: # 如果当前状态是个终止状态,比如说你赢了或者他赢了
return value(S_i) # 返回对 S_i 这个状态的价值,比如说你赢了,这个价值可能就会相对比较高
# 假设还没到终止状态
A_i = random(available_action(S_i)) # 随机选取当前状态下能够采取的一个动作
S_i = simulate(A_i, S_i) # 通过当前状态 S_i 与随机选取的动作 A_i 来计算出下一步的状态并赋值给 S_i这一过程实际上就是蒙特卡洛过程。
BACKUP(expand_node, reward)
来自模拟的回报会从扩展的结点递归地反向传播到其祖先。在第三步中我们计算出了 value 之后,我们需要返回这个 value,那么对于它所有的父节点,它们的探索次数全部 +1,它们的 value 也会进行一个累加。
注意一定不要忘记 折扣因子。
对于每个状态 $s$,从该结点获取所有行动的期望价值:
$$ V(s):=\max \limits_{a\in A(s)}\sum_{s'\in \textit{children} }P_a(s'\mid s)[r(s,a,s')+\gamma V(s')] $$
蒙特卡洛树搜索:执行
一旦我们用尽了计算时间,我们选择能够使期望回报最大化的行动,简单来说,就是我们的模拟中具有最高 Q 值的行动: $$ \mathop{\operatorname{arg,max} }\limits_{a} Q(s_0,a) $$ 也就是: $$ \mathop{\operatorname{arg,max} }\limits_{a} \sum_{s'\in A(s_0)}P_a(s'\mid s_0)[r(s_0,a,s')+\gamma V(s')] $$ 我们执行该动作,然后等待观察该动作对应的哪种结果会发生。一旦我们观察到结果,我们将其称为 $s'$,我们将重新开始这整个过程,唯一变化是此时 $s_0 := s'$。
但是, 很重要的一点是,我们可以 保留 来自状态$s$的子树,因为我们已经从该状态进行了模拟。我们丢弃树中的其余部分(除了所选择的行动之外的其他所有 $s_0$的子树),并从$s'$开始增量式地构建 MCTS。
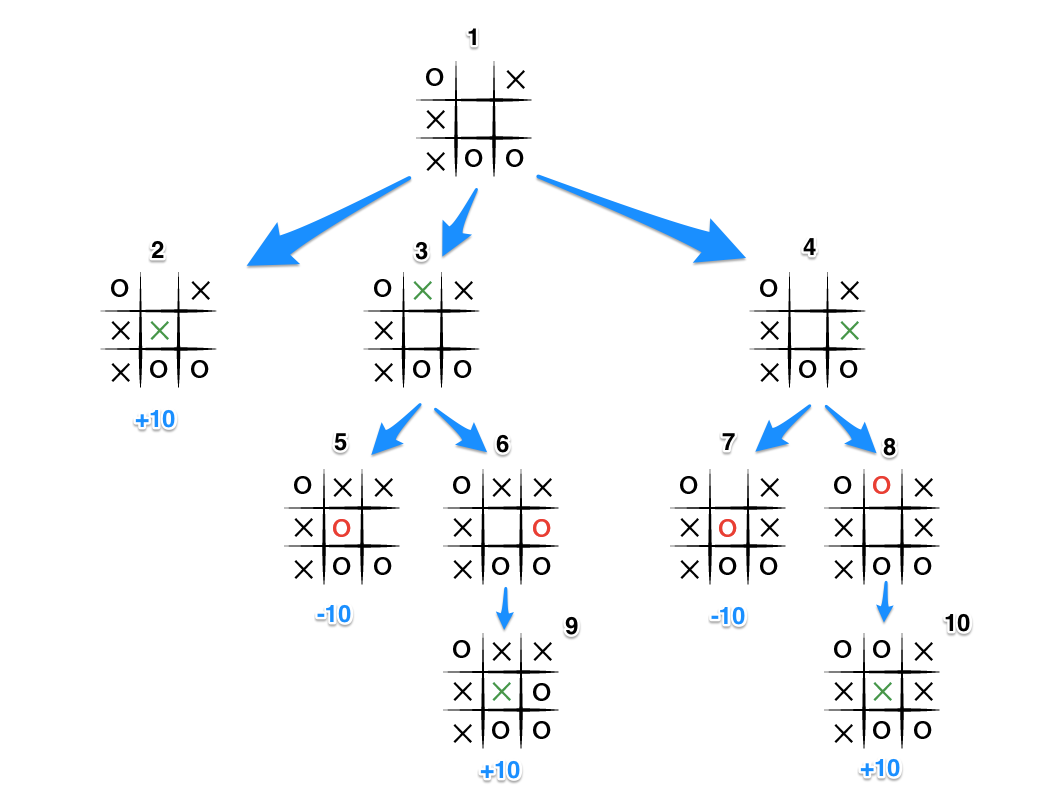
两个玩家的游戏
在两个玩家的游戏中,如 井字棋,象棋,围棋等,该如何应用MCTS 算法呢? 正如 stackoverflow 上的答复 指出,我们需要将树的每一层看做是玩家1或者玩家2的走棋。如下图所示:
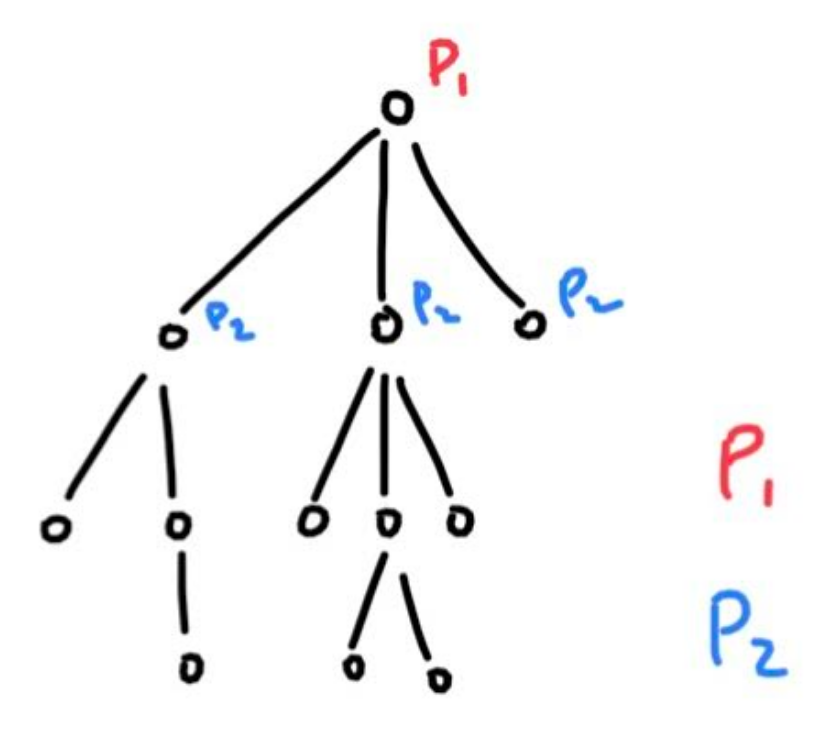
我们将根节点设置为玩家 1 的节点,它选择从那里采取的动作,无论采取什么动作都会将我们带到树的下一层,球在玩家 2 的球场上,并且不断重复。 那么当我们到达终端节点时,该如何修改我们的反向传播? 让我们看看下面的图片来理解。
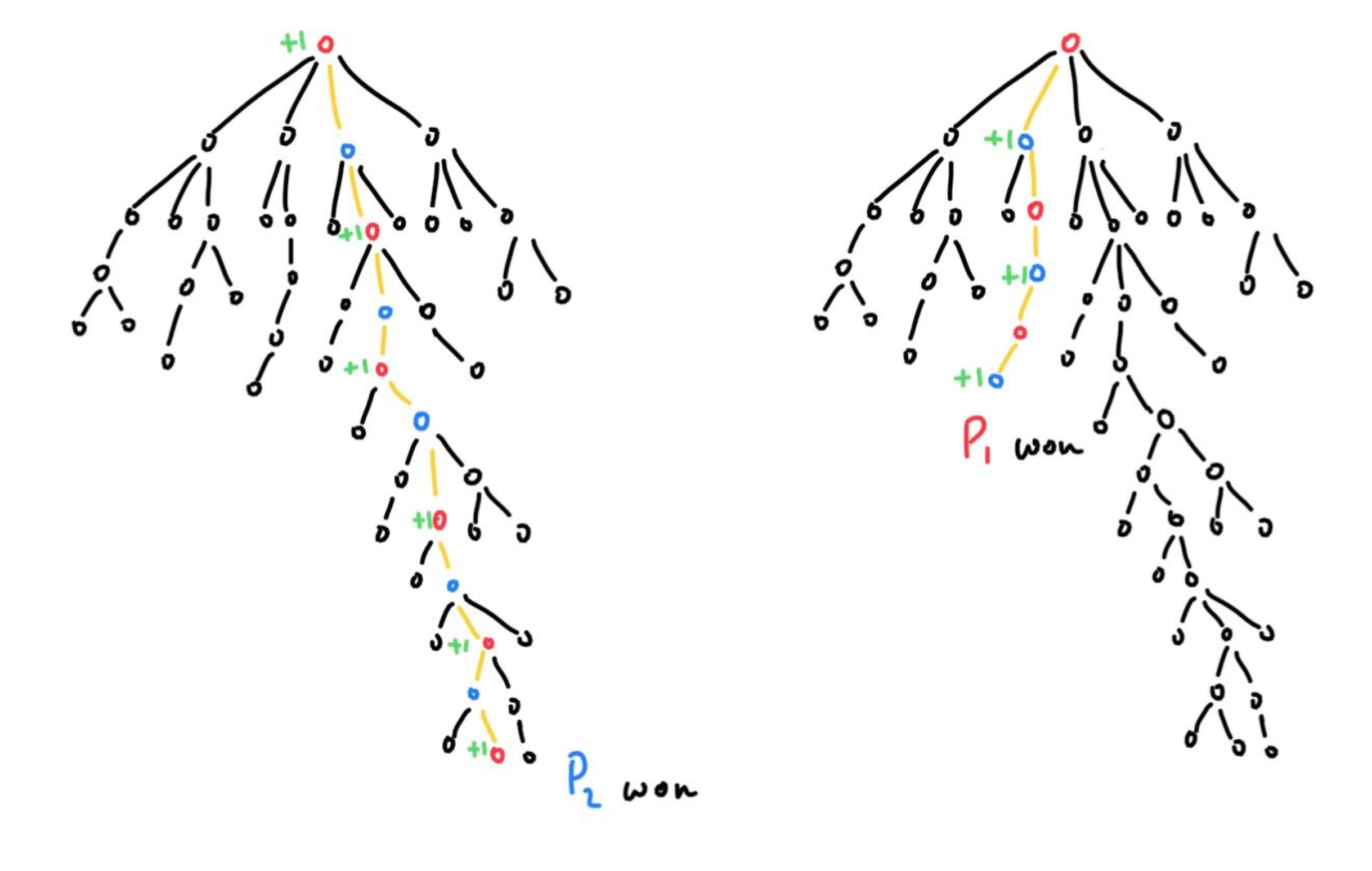
我们所要做的就是交替增加那些胜利的节点。 如果玩家 1 获胜,则从获胜路径中的第二个节点开始,每个其他节点的获胜得分将递增。 如果玩家 2 获胜,则相同,只是起始节点是根节点。
代码实现
1. 节点类 TreeNode
class TreeNode(object):
"""A node in the MCTS tree. Each node keeps track of its own value Q,
prior probability P, and its visit-count-adjusted prior score u.
"""
def __init__(self, parent, prior_p):
self._parent = parent
self._children = {} # a map from action to TreeNode
self._n_visits = 0
self._Q = 0
self._u = 0
self._P = prior_p
def expand(self, action_priors):
"""Expand tree by creating new children.
action_priors: a list of tuples of actions and their prior probability
according to the policy function.
"""
for action, prob in action_priors:
if action not in self._children:
self._children[action] = TreeNode(self, prob)
def select(self, c_puct):
"""Select action among children that gives maximum action value Q
plus bonus u(P).
Return: A tuple of (action, next_node)
"""
return max(self._children.items(),
key=lambda act_node: act_node[1].get_value(c_puct))
def update(self, leaf_value):
"""Update node values from leaf evaluation.
leaf_value: the value of subtree evaluation from the current player's
perspective.
"""
# Count visit.
self._n_visits += 1
# Update Q, a running average of values for all visits.
self._Q += 1.0*(leaf_value - self._Q) / self._n_visits
def update_recursive(self, leaf_value):
"""Like a call to update(), but applied recursively for all ancestors.
"""
# If it is not root, this node's parent should be updated first.
if self._parent:
self._parent.update_recursive(-leaf_value)
self.update(leaf_value)
def get_value(self, c_puct):
"""Calculate and return the value for this node.
It is a combination of leaf evaluations Q, and this node's prior
adjusted for its visit count, u.
c_puct: a number in (0, inf) controlling the relative impact of
value Q, and prior probability P, on this node's score.
"""
self._u = (c_puct * self._P *
np.sqrt(self._parent._n_visits) / (1 + self._n_visits))
return self._Q + self._u
def is_leaf(self):
"""Check if leaf node (i.e. no nodes below this have been expanded).
"""
return self._children == {}
def is_root(self):
return self._parent is NoneTreeNode 类里初始化了一些数值,主要是 父节点,子节点,访问节点的次数,Q值和u值,还有先验概率,还定义了一些函数:
select()的功能: 选择 在子节中选择具有 (Q+u)最大的节点,c_puct是需要我们定义的值.expand()的功能:扩展 输入action_priors 是一个包括的所有合法动作的列表(list),表示在当前局面我可以在哪些地方落子。此函数为当前节点扩展了子节点。update_recursive()的功能:回溯 从该节点开始,自上而下地 更新 所有的父节点。
可以看到,我们定义了一个TreeNode类来描述对应的博弈树的结点,除了价值函数等计算中需要用到的信息,还定义了父结点的信息和子结点的信息,其中父结点是一个TreeNode的实例,子结点的信息是一个字典,字典的键是执行的动作,值是动作对应的结点。
有了这些信息之后,我们就可以计算前面介绍的PUCT分数,这个分数的值由式(1)决定,通过score方法计算得到。
在得到PUCT分数之后,算法就可以根据这个分数来选择分数最高的子结点,对应的方法是select。
除了select方法,TreeNode类还定义了expand方法,这个方法输入所有的动作actions和动作对应的先验概率priors,根据这些值来对叶子结点进行扩展,另外还有backup方法,这个方法获得当前结点的价值估计,并且递归地对到达这个结点的路径上的其他结点进行访问次数和价值函数的更新。
为了判断结点的性质,我们还需要有两个方法is_root和is_leaf,分别代表当前的结点是否是根结点和是否是叶子结点。
以上是MCTS中的三个流程(一二四),我们发现还少了一个最重要的第三步:模拟,模拟的步骤写在了 MCTS类中。
2. MCTS算法
class MCTS(object):
"""A simple implementation of Monte Carlo Tree Search."""
def __init__(self, policy_value_fn, c_puct=5, n_playout=10000):
"""
policy_value_fn: a function that takes in a board state and outputs
a list of (action, probability) tuples and also a score in [-1, 1]
(i.e. the expected value of the end game score from the current
player's perspective) for the current player.
c_puct: a number in (0, inf) that controls how quickly exploration
converges to the maximum-value policy. A higher value means
relying on the prior more.
"""
self._root = TreeNode(None, 1.0)
self._policy = policy_value_fn
self._c_puct = c_puct
self._n_playout = n_playout
def _playout(self, state):
"""Run a single playout from the root to the leaf, getting a value at
the leaf and propagating it back through its parents.
State is modified in-place, so a copy must be provided.
"""
node = self._root
while(1):
if node.is_leaf():
break
# Greedily select next move.
action, node = node.select(self._c_puct)
state.do_move(action)
action_probs, _ = self._policy(state)
# Check for end of game
end, winner = state.game_end()
if not end:
node.expand(action_probs)
# Evaluate the leaf node by random rollout
leaf_value = self._evaluate_rollout(state)
# Update value and visit count of nodes in this traversal.
node.update_recursive(-leaf_value)
def _evaluate_rollout(self, state, limit=1000):
"""Use the rollout policy to play until the end of the game,
returning +1 if the current player wins, -1 if the opponent wins,
and 0 if it is a tie.
"""
player = state.get_current_player()
for i in range(limit):
end, winner = state.game_end()
if end:
break
action_probs = rollout_policy_fn(state)
max_action = max(action_probs, key=itemgetter(1))[0]
state.do_move(max_action)
else:
# If no break from the loop, issue a warning.
print("WARNING: rollout reached move limit")
if winner == -1: # tie
return 0
else:
return 1 if winner == player else -1
def get_move(self, state):
"""Runs all playouts sequentially and returns the most visited action.
state: the current game state
Return: the selected action
"""
for n in range(self._n_playout):
state_copy = copy.deepcopy(state)
self._playout(state_copy)
return max(self._root._children.items(),
key=lambda act_node: act_node[1]._n_visits)[0]
def update_with_move(self, last_move):
"""Step forward in the tree, keeping everything we already know
about the subtree.
"""
if last_move in self._root._children:
self._root = self._root._children[last_move]
self._root._parent = None
else:
self._root = TreeNode(None, 1.0)
def __str__(self):
return "MCTS"MCTS类的初始输入参数:
- policy_value_fn:当前采用的策略函数,输入是当前棋盘的状态,输出 (action, prob)元祖和score[-1,1]。
- c_puct:控制探索和回报的比例,值越大表示越依赖之前的先验概率。
- n_playout:MCTS的执行次数,值越大,消耗的时间越多,效果也越好。
- 还定义了一个根节点 self._root = TreeNode(None, 1.0) 父节点:None,先验概率:1.0
_playout(self, state):
此函数有一个输入参数:state, 它表示当前的状态。 这个函数的功能就是模拟。它根据当前的状态进行游戏,用贪心算法一条路走到黑,直到叶子节点,再判断游戏结束与否。如果游戏没有结束,则扩展节点,否则回溯更新叶子节点和所有祖先的值。
get_move_probs(self, state, temp):
之前所有的代码都是为这个函数做铺垫。它的功能是从当前状态开始获得所有可行行动以及它们的概率。也就是说它能根据棋盘的状态,结合之前介绍的代码,告诉你它计算的结果,在棋盘的各个位置落子的胜率是多少。有了它,我们就能让计算机学会下棋。
update_with_move(self, last_move):
自我对弈时,每走一步之后更新MCTS的子树。 与玩家对弈时,每一个回合都要重置子树。
3. MCTS的玩家
接下来构建一个MCTS的玩家
class MCTSPlayer(object):
"""AI player based on MCTS"""
def __init__(self, c_puct=5, n_playout=2000):
self.mcts = MCTS(policy_value_fn, c_puct, n_playout)
def set_player_ind(self, p):
self.player = p
def reset_player(self):
self.mcts.update_with_move(-1)
def get_action(self, board):
sensible_moves = board.availables
if len(sensible_moves) > 0:
move = self.mcts.get_move(board)
self.mcts.update_with_move(-1)
return move
else:
print("WARNING: the board is full")
def __str__(self):
return "MCTS {}".format(self.player)MCTSPlayer类的主要功能在函数get_action(self, board, temp=1e-3, return_prob=0)里实现。自我对弈的时候会有一定的探索几率用来训练。与人类下棋是总是选择最优策略用来检测训练成果。
优势
与传统的树搜索方法相比,MCTS 具有许多优势。
启发式
MCTS 不需要任何关于给定领域的战略或战术知识来做出合理的决定。该算法可以在除了合法移动和结束条件之外的游戏知识的情况下有效运行;这意味着一个单一的 MCTS 实现可以在稍作修改的情况下重复用于许多游戏,并使 MCTS 成为一般游戏的潜在福音。
非对称
MCTS 执行适应搜索空间拓扑的非对称树生长。该算法更频繁地访问更有趣的节点,并将其搜索时间集中在树的更相关部分。

这使得 MCTS 适用于分支因子较大的游戏,例如 19x19 的围棋。如此大的组合空间通常会导致标准的基于深度或广度的搜索方法出现问题,但 MCTS 的自适应特性意味着它将(最终)找到那些看起来最优的移动并将其搜索工作集中在那里。
Anytime
可以随时停止算法以返回当前最佳估计值。到目前为止构建的搜索树可能会被丢弃或保留以供将来重用。
优雅
该算法易于实现(请参阅代码)。
缺点
MCTS 有一些缺点,但它们可能是主要的。
复杂度高
即使是中等复杂度的游戏,MCTS 算法的基本形式也无法在合理的时间内找到合理的着法。这主要是由于组合移动空间的巨大规模以及关键节点可能没有被访问足够多次以提供可靠估计的事实。
速度
MCTS 搜索可能需要多次迭代才能收敛到一个好的解决方案,这对于难以优化的更通用的应用程序来说可能是一个问题。例如,最好的围棋实施可能需要数百万次的比赛,并结合领域特定的优化和增强功能,才能做出专家级的举动,而最好的 GGP 实施可能每秒只能进行数十次(独立于领域的)比赛,以应对更复杂的游戏。对于合理的移动时间,此类 GGP 可能几乎没有时间访问每个合法移动,并且不太可能进行重大搜索。
幸运的是,可以使用多种技术显着提高算法的性能。
改进
迄今为止,已经提出了数十项 MCTS 增强功能。这些通常可以描述为领域知识或领域独特性。
领域知识
特定于当前游戏的领域知识可以在树中被利用来过滤掉不可信的动作,或者在模拟中产生更类似于人类对手之间发生的比赛的大量比赛。这意味着播出结果将比随机模拟更真实,并且节点将需要更少的迭代来产生真实的奖励值。
领域知识可以产生显着的改进,但代价是速度和通用性的丧失。
域独立
域独立增强适用于所有问题域。这些通常应用于树中(例如 AMAF),尽管有些再次应用于模拟(例如更喜欢在播出期间获胜的动作)。域独立增强不将实现绑定到特定域,保持通用性,因此是该领域大多数当前工作的重点。
Context
1928 年: John von Neumann 的极小极大定理为对抗树搜索方法铺平了道路,这些方法几乎从一开始就构成了计算机科学和人工智能决策的基础。
1940 年代:蒙特卡洛 (MC) 方法被形式化为一种通过使用随机抽样来处理不适合树搜索的不太明确的问题的方法。
2006 年: Rémi Coulomb 和其他研究人员将这两个想法结合起来,提供了一种在计算机围棋中进行移动规划的新方法,现在称为 MCTS。Kocsis 和 Szepesvári 将这种方法形式化为 UCT 算法。
这种优雅的算法没有早点被发现,这似乎很了不起!