Q-Learning 简介
在 本课程的第一章中,学习了强化学习 (RL)、RL 过程以及解决 RL 问题的不同方法。今天,将 深入研究其中一种强化学习方法:基于价值的方法 ,并研究第一个 RL 算法: Q-Learning。
本单元分为 2 个部分:
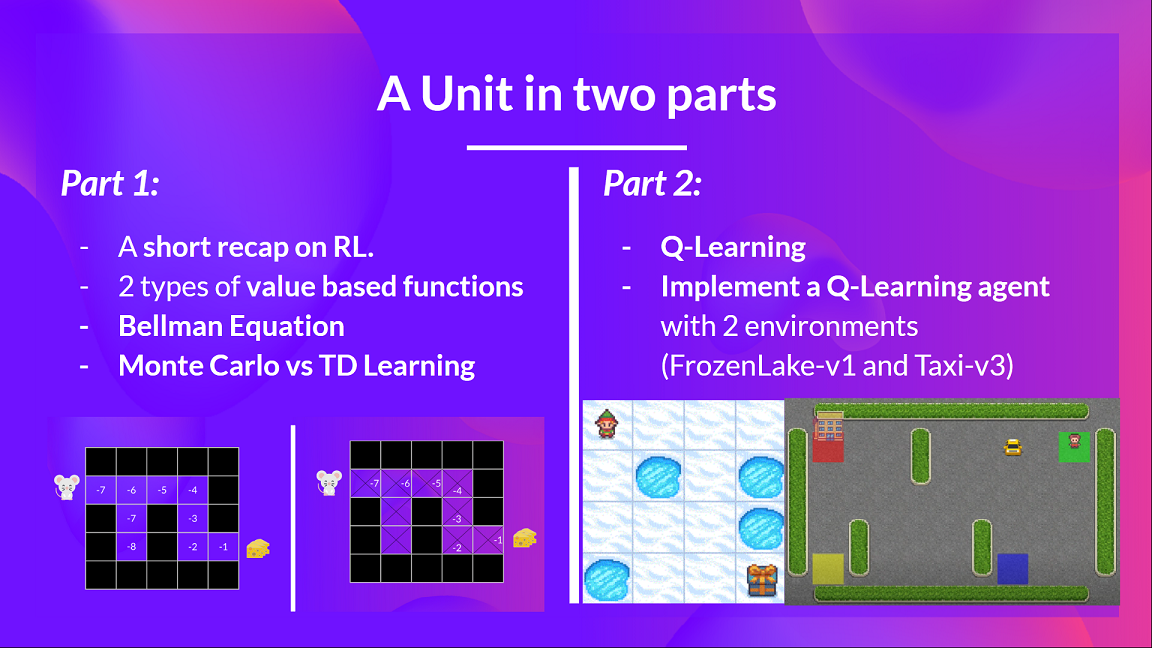
在第一部分,将学习基于值的方法以及蒙特卡洛和时间差分学习之间的区别。
在第二部分, 将研究第一个 RL 算法:Q-Learning,并实现第一个 RL 智能体。
如果你想学习深度 Q 学习(第 3 单元):这是第一个能够玩 Atari 游戏并 在其中一些游戏上击败人类水平的深度 RL 算法. 学好本单元很有必要。
什么是强化学习?简短回顾
在 RL 中,我们构建了一个可以 做出明智决策的智能体。例如,一个学习玩电子游戏的智能体。 或者是一个交易智能体, 通过对购买哪些股票和何时出售做出明智的决策来学习最大化其利益。
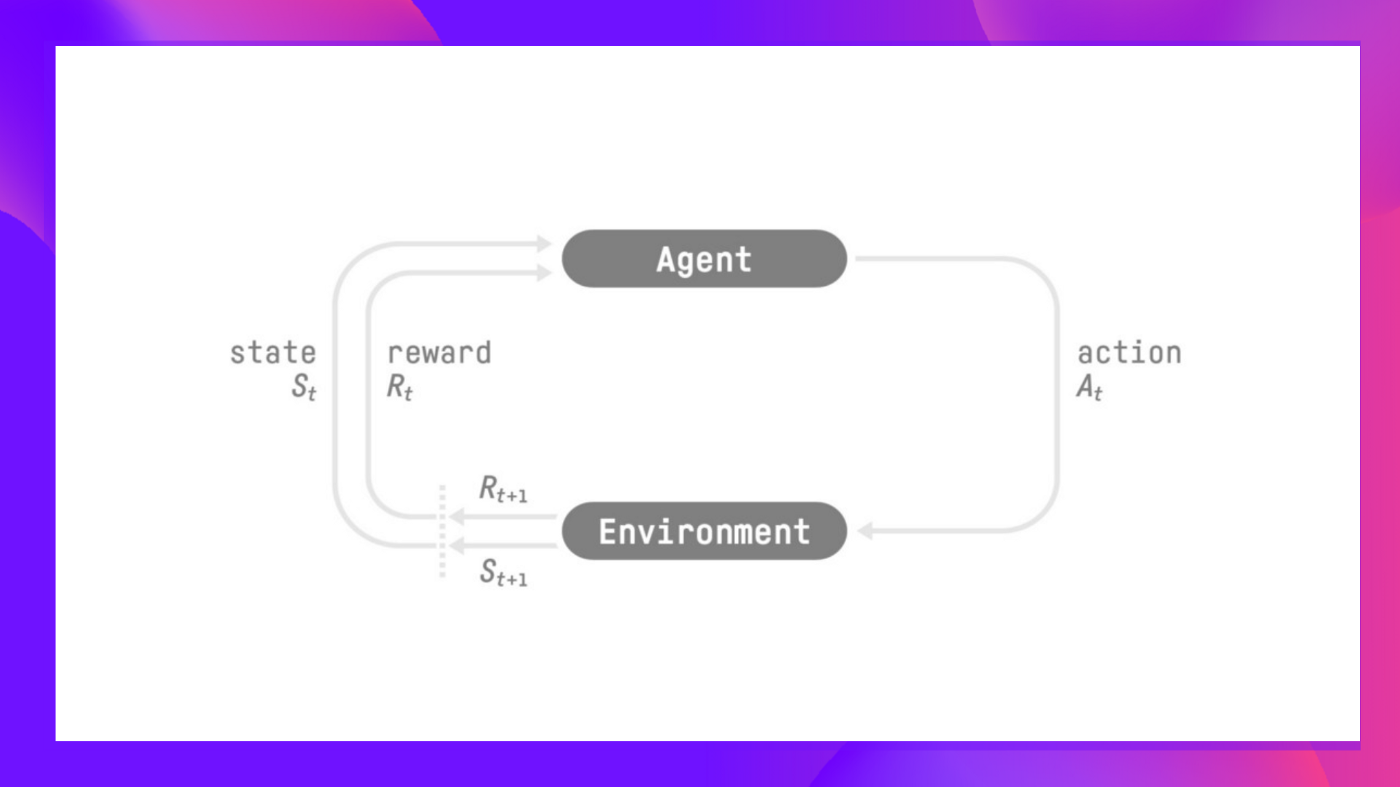
为了做出明智的决策,智能体将 通过反复试验与环境交互 并接收奖励(正面或负面) 作为反馈,从而从环境中学习。
它的目标 是最大化其期望累积奖励 (奖励假设)。
智能体的决策过程称为策略 π: 给定 一个状态,策略将输出一个动作或动作的概率分布。也就是说,给定对环境的观察,策略将提供智能体应采取的动作(或每个动作的概率)。

我们的目标是找到最优策略 π*,也就是导致最佳期望累积奖励的策略。
为了找到这个最优策略(从而解决 RL 问题),有 两种主要的 RL 方法:
- 基于策略的方法: 直接训练策略函数 以学习在给定状态下要采取的动作。
- 基于价值的方法: 训练一个价值函数来学习 哪个状态更有价值 ,并使用这个价值函数来采取导致最优价值的动作。

在本章中, 将深入探讨基于价值的方法。
两种基于值的方法
在基于值的方法中, 我们学习了一个将状态映射到处于该状态的期望值的价值函数。

状态的价值是智能体从该状态开始然后按照策略行动时 可以获得的期望折扣回报。
但是,按照策略行动意味着什么?毕竟,没有基于价值的方法的策略,因为训练的是价值函数而不是策略。
请记住, RL 智能体的目标是拥有最优策略 π。
为了找到它,有两种不同的方法:
- 基于策略的方法: 直接训练策略 以选择在给定状态下要采取的动作(或在该状态下的动作的概率分布)。在这种情况下, 没有价值函数。
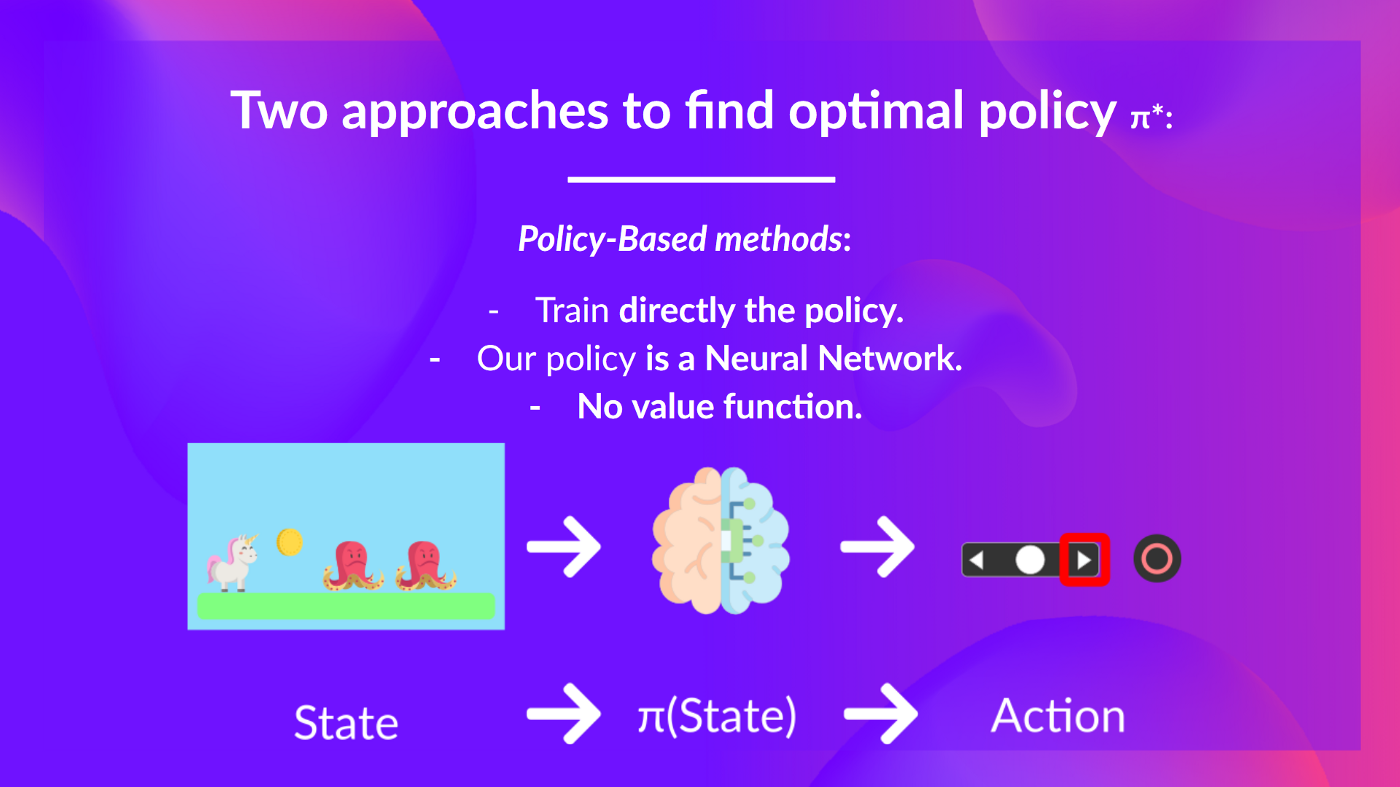
该策略将状态作为输入并输出在该状态下要采取的动作(确定性策略:一种在给定状态下输出一个动作的策略,与输出动作概率分布的随机策略相反)。
- 基于值的方法: 间接地,通过训练 输出状态值或状态-动作对的值函数。根据这个价值函数,我们的策略将采取导致值最大的动作。
但是,因为我们没有训练好策略函数, 需要指定它的行为。 例如,如果想要一个策略,在给定价值函数的情况下,将采取总是导致最大回报的动作, 这样,我们就创建一个贪婪策略。
 给定一个状态,动作值函数(训练的)输出该状态下每个动作的值,然后根据贪婪策略选择具有最大状态-动作对值的动作。
给定一个状态,动作值函数(训练的)输出该状态下每个动作的值,然后根据贪婪策略选择具有最大状态-动作对值的动作。
因此,无论您使用什么方法来解决问题, 您都会有一个 policy,但在您不训练它的基于值的方法的情况下,您的 policy 只是您指定的一个简单函数 (例如贪婪策略)该策略使用价值函数给出的值来选择其操作。
所以区别在于:
- 在基于策略的情况下, 通过直接训练策略来找到最优策略。
- 在基于价值的情况下, 找到最佳价值函数会间接获得最佳策略。

事实上,大多数时候,在基于价值的方法中,您将使用 Epsilon-Greedy 策略 来处理探索/利用平衡;在本单元的第二部分讨论 Q-Learning 时,再讨论它。
因此,有两种类型的基于值的函数:
状态值函数
在策略 π 下表示状态值函数,如下所示:
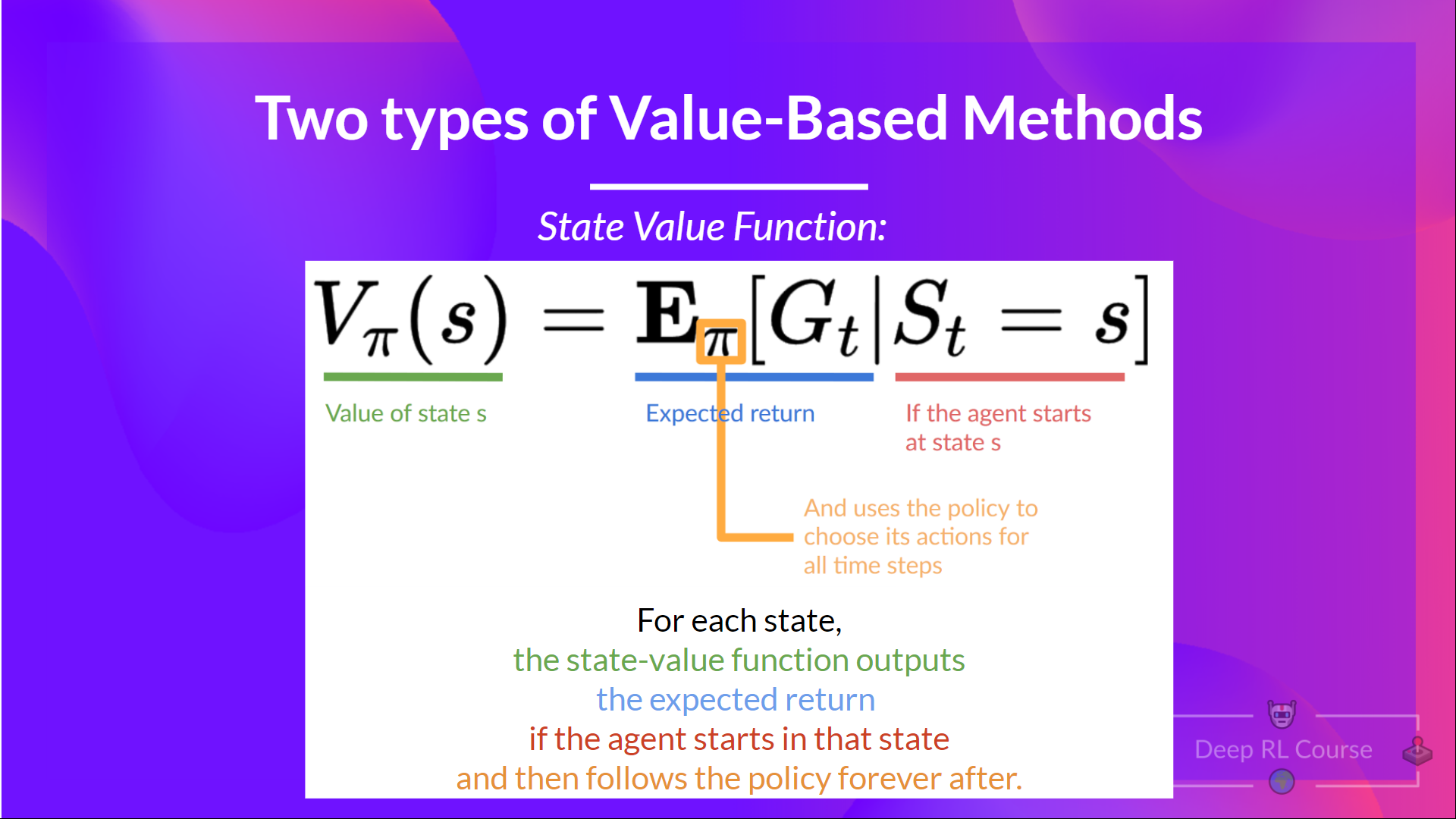
对于每个状态,如果智能体 从该状态开始,状态值函数会输出期望回报, 然后永远遵循该策略(如果您愿意,可以用于所有未来的时间步长)。
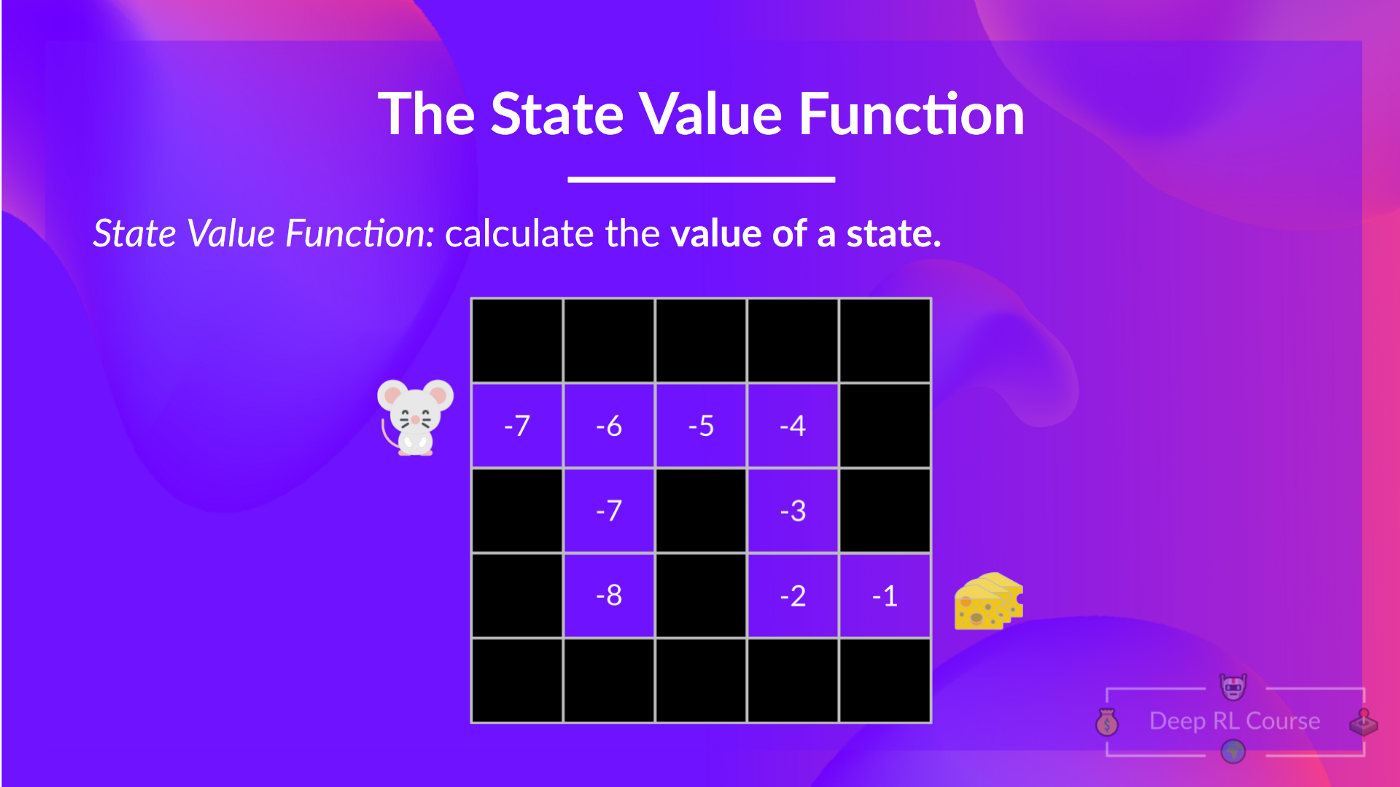 如果取值为 -7 的状态:它是从该状态开始并根据我们的策略(贪婪策略) 采取动作的期望回报。
如果取值为 -7 的状态:它是从该状态开始并根据我们的策略(贪婪策略) 采取动作的期望回报。
动作价值函数
在动作价值函数中,对于每个状态和动作对,动作价值函数 输出如果智能体在该状态下开始并采取动作的期望回报 ,然后永远遵循该策略。
在策略 π 下,在状态 s 中采取动作的价值是:


区别在于:
- 在状态价值函数中,计算 **状态的值 $ S_t $ **,
- 在动作-价值函数中,计算 状态-动作对的值 $(S_t, A_t)$ , 即在该状态下采取该动作的价值。
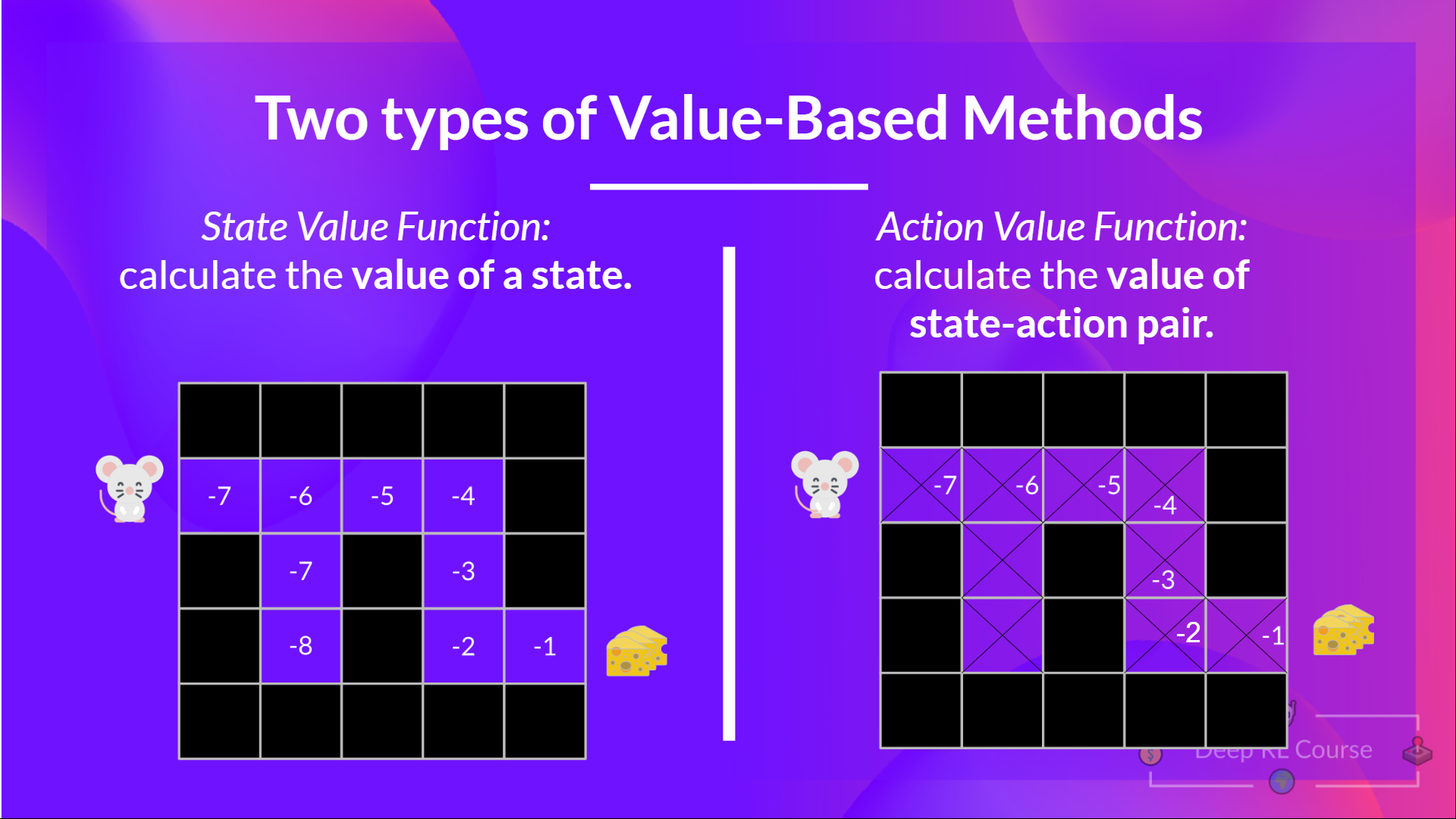 注意:动作价值函数的例子,这里没有填写所有的状态-动作对
注意:动作价值函数的例子,这里没有填写所有的状态-动作对
在任何一种情况下,无论选择什么价值函数(状态-价值函数 或 动作-价值函数), 价值都是期望回报。意味着 要计算状态或状态-动作对的每个值,需要将智能体从该状态开始可以获得的所有奖励相加。
这是一个乏味的过程,贝尔曼方程可以帮助简化这一问题。
贝尔曼方程:简化价值估计
贝尔曼方程 简化了状态价值或状态-动作价值的计算。

根据目前学到的知识,如果计算 $V(S_t)$(状态的值),需要从该状态开始计算回报,然后永远遵循该策略。 (在以下示例中定义的策略是贪婪策略,为简化起见,不对奖励打折扣)。
所以要计算$V(S_t) $,需要做期望奖励的总和。因此:
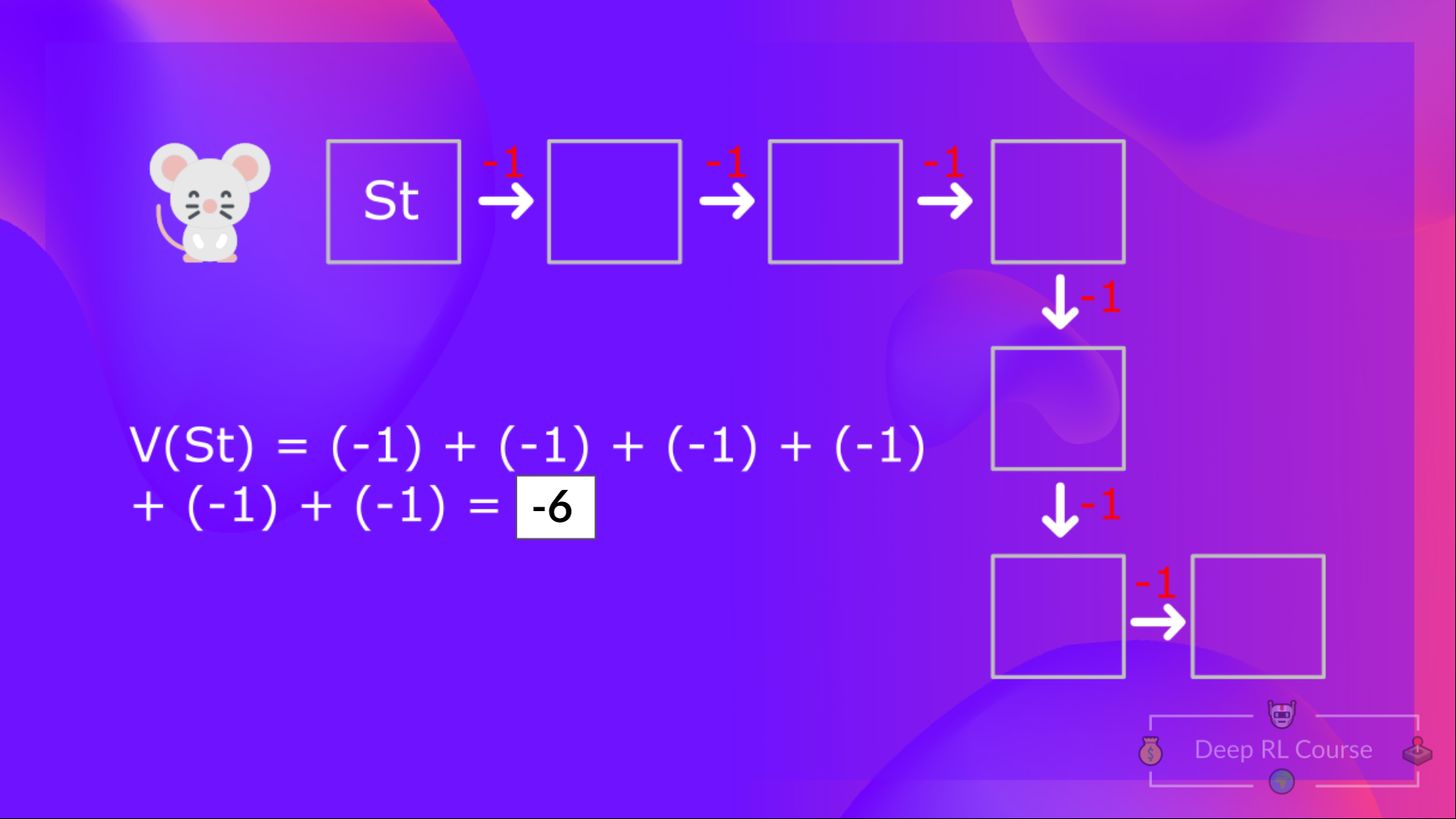 计算状态 1 的值:如果智能体从该状态开始,然后在所有时间步中遵循贪婪策略(采取导致最佳状态值的动作),则奖励的总和。
计算状态 1 的值:如果智能体从该状态开始,然后在所有时间步中遵循贪婪策略(采取导致最佳状态值的动作),则奖励的总和。
然后,计算 $V(S_{t+1})$,需要计算从 $S_{t+1}$ 状态开始的回报.
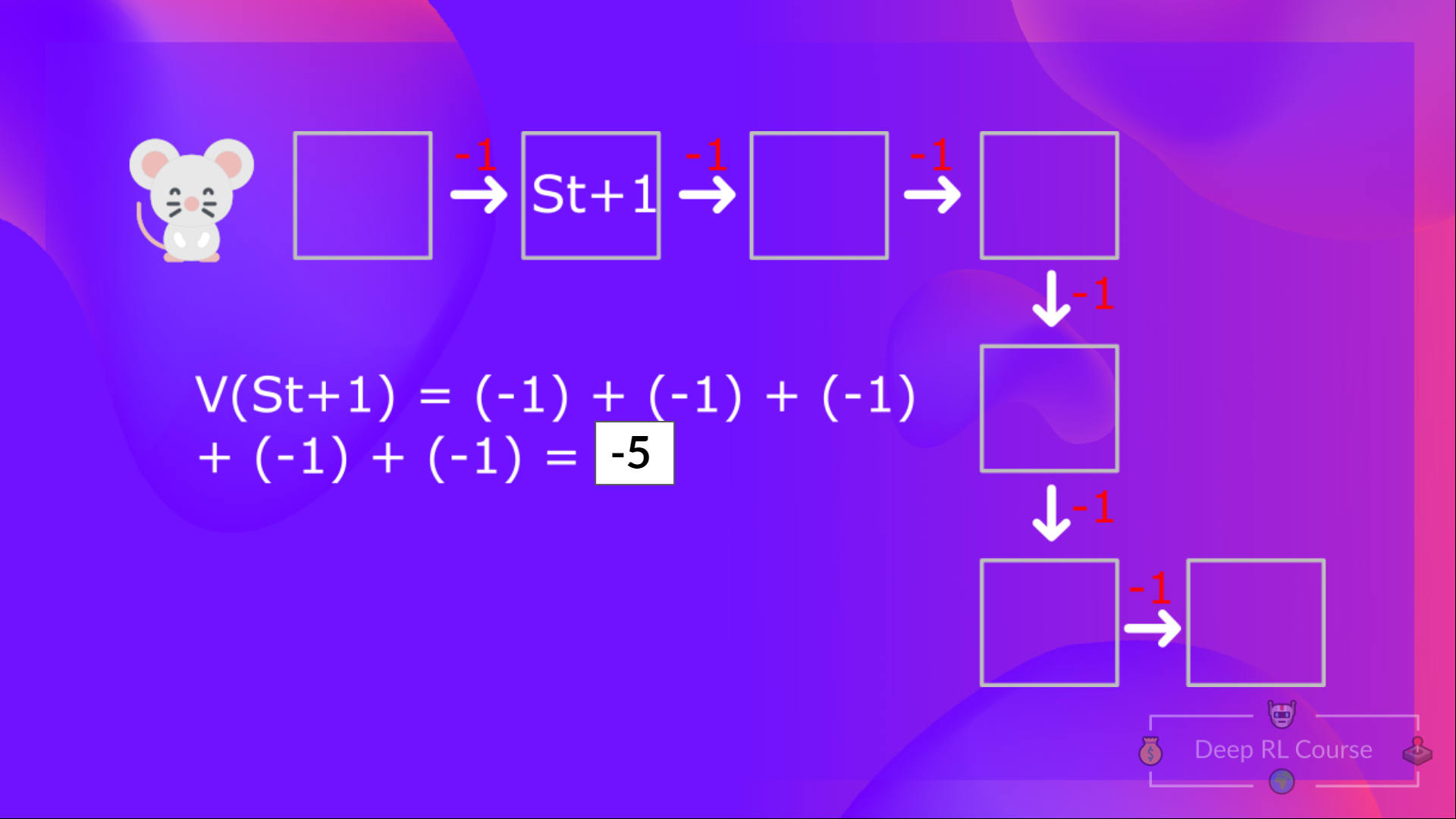 计算状态 2 的值:奖励的总和 如果智能体在该状态下开始,然后遵循所有时间步的策略。
计算状态 2 的值:奖励的总和 如果智能体在该状态下开始,然后遵循所有时间步的策略。
所以你可能已经注意到,我们正在重复计算不同状态的值,如果你需要为每个状态值或状态-动作价值做这件事,那将是一个相当乏味的过程。
可以使用贝尔曼方程,而不是计算每个状态或每个状态-动作对的期望回报 。
贝尔曼方程是一个递归方程,它的工作原理如下:可以将任何状态的值视为:
**即时奖励 $R_{t+1}$ + 紧随其后的状态的折扣值 ( gamma * $V(S_{t+1})$). **
 为了简单起见,这里我们不打折扣,所以 gamma = 1。
为了简单起见,这里我们不打折扣,所以 gamma = 1。
回到示例中,状态 1 的值 = 如果从该状态开始,期望的累积回报。
计算状态 1 的值: 如果智能体从状态 1 开始, 然后在 所有时间步都遵循策略,则奖励的总和。
这相当于 $V(S_{t})$ = 立即奖励 $R_{t+1}$ + 下一个状态的折扣值 gamma * $V(S_{t+1})$
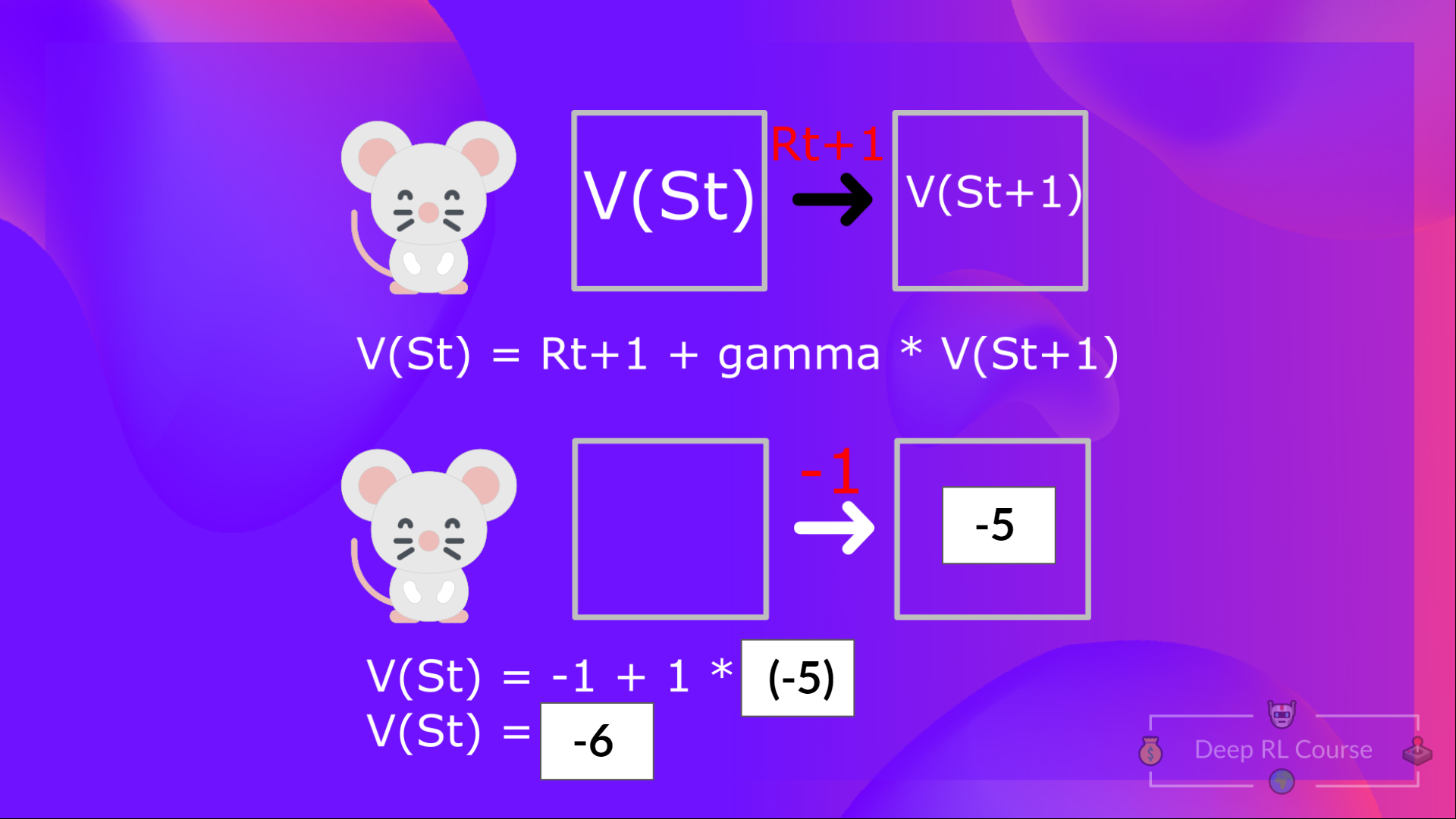
为简单起见,这里不打折扣,所以 gamma = 1。
- 价值 $V(S_{t+1})$= 立即奖励 $R_{t+2}$ + 下一个状态的折扣值 gamma * $V(S_{t+2})$。
回顾一下,贝尔曼方程的想法是,不是将每个值计算为期望收益的总和, 相当于 立即奖励的总和 + 随后状态的折现值。
蒙特卡洛与时间差分学习
在深入 Q-Learning 之前,需要谈论的最后一件事是两种学习方式。RL 智能体 通过与其环境交互来学习。 这个想法是, 使用获得的经验,给定它获得的奖励,更新其价值或策略。
蒙特卡洛和时间差分学习是 关于如何训练的价值函数或策略函数的两种不同方法。 他们都 使用经验来解决 RL 问题。蒙特卡洛 在学习之前使用了一整段经验。 Temporal Difference 仅使用一个步骤 $(S_t, A_t, R_{t+1}, S_{t+1})$ 来学习。下面使用基于值的方法示例来解释它们 。
蒙特卡洛:在 Episode 结束时学习
蒙特卡洛等到 Episode 结束,计算 $G_t$(return) 并将其用于更新目标 $V(S_t)$.
因此, 在更新价值函数之前,需要一个完整的交互经验记录。

举个例子:
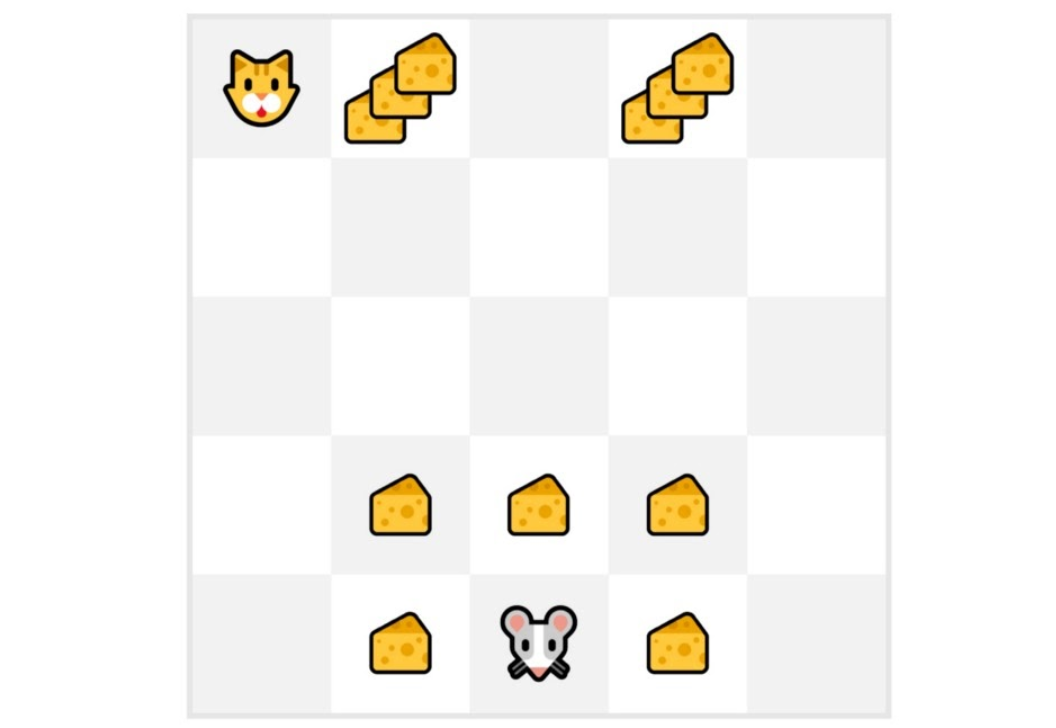
- 同一个起点开始Episode。
- 智能体使用策略采取动作。例如,使用 Epsilon Greedy 策略,这是一种在探索(随机动作)和利用之间交替的策略。
- 得到 奖励和下一个状态。
- 如果猫吃掉了老鼠或者老鼠移动了 > 10 步,就会终止这一局。
- 在这一局的结尾, 得到一个{状态、动作、奖励和下一个状态}的列表
- 智能体将汇总奖励 $G_t$。
- 然后会基于下面的公式更新 $V(s_t)$

- 进一步用这些新知识开始新游戏
通过运行越来越多的次数 , 智能体将学会玩得越来越好。

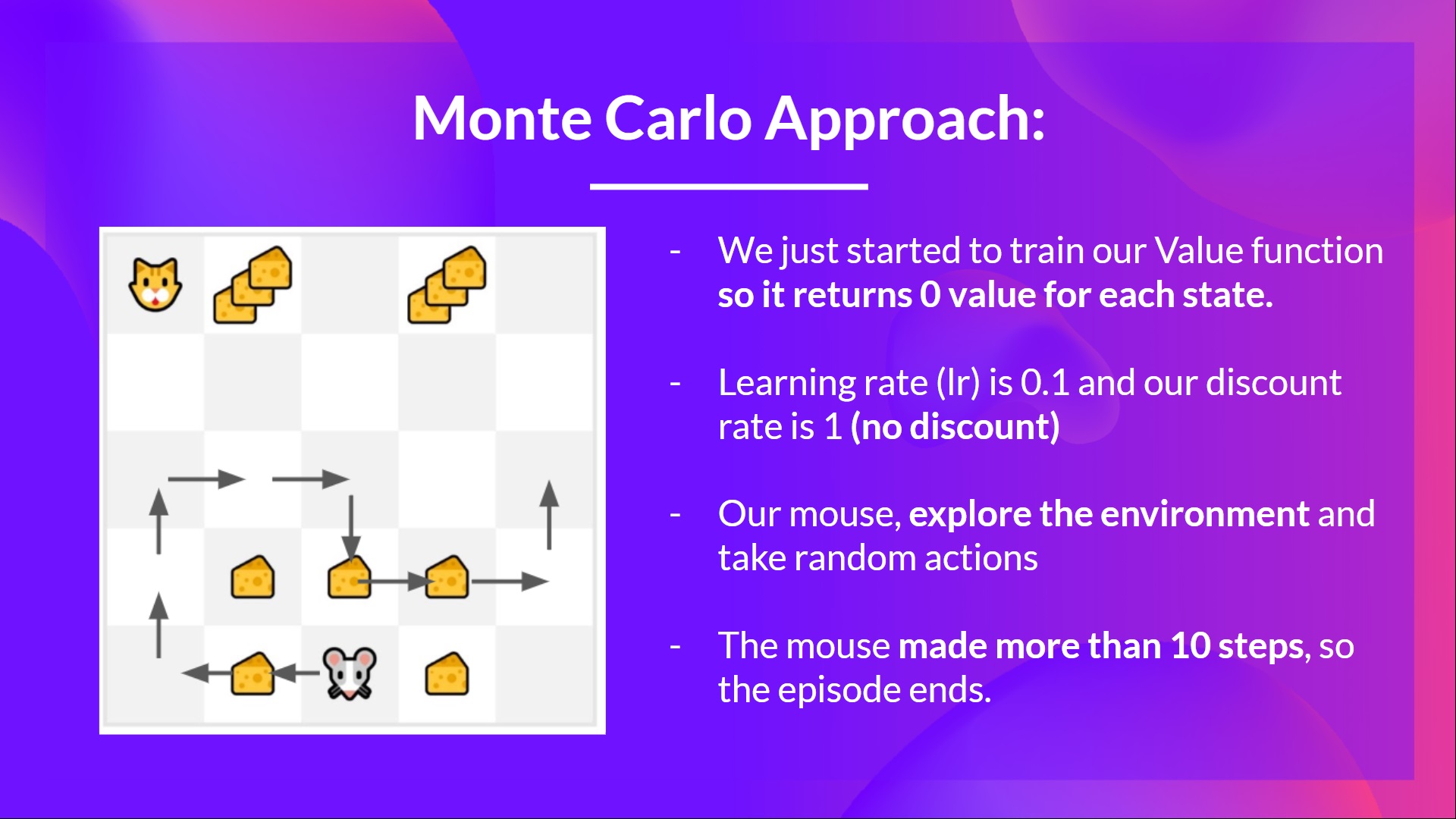
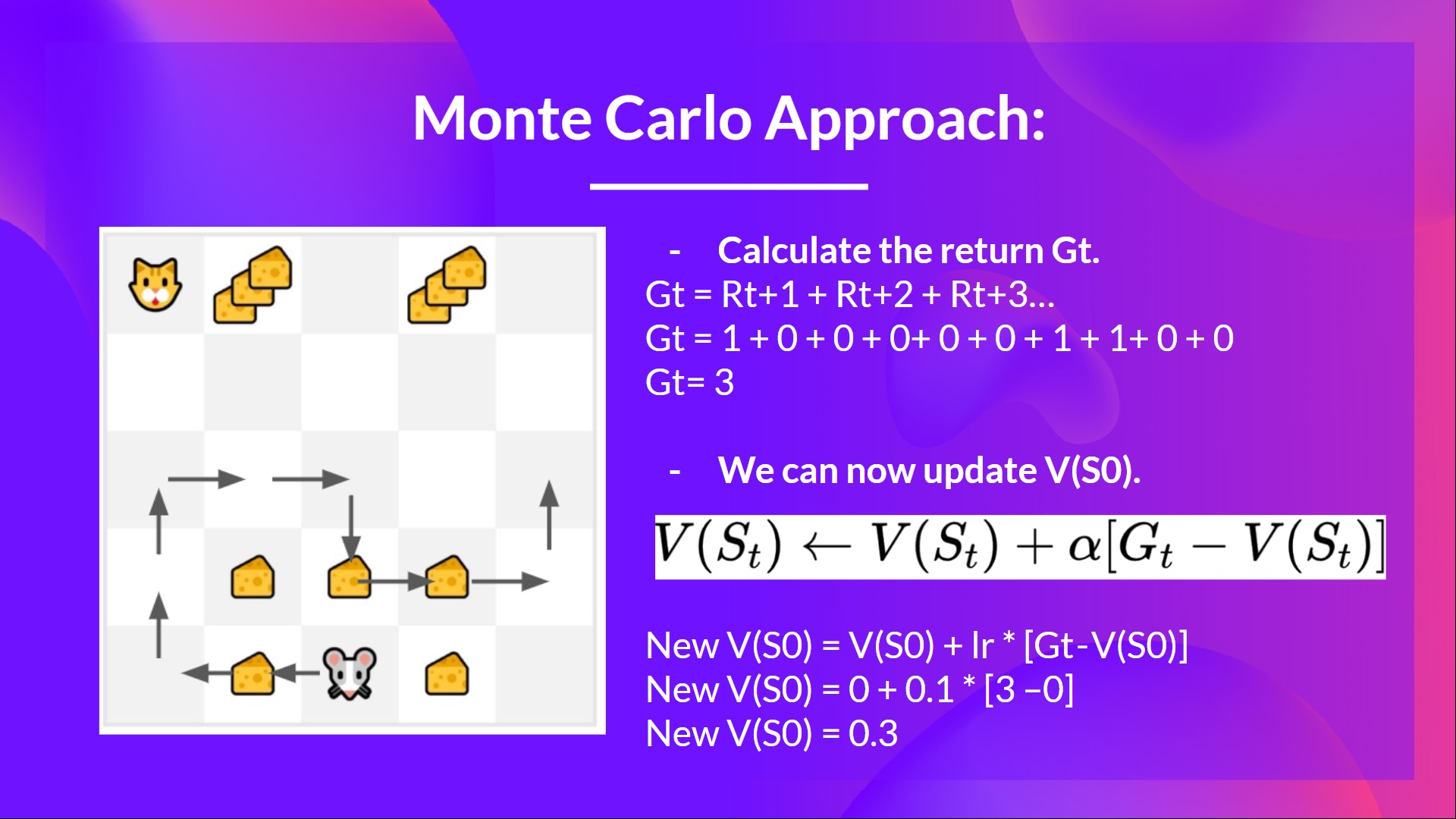
例如,如果使用 Monte Carlo 训练状态价值函数:
- 将每个状态初始化 0 值
- 学习率 (lr) 为 0.1,折扣率为 1(无折扣)
- 老鼠 探索环境并采取随机动作
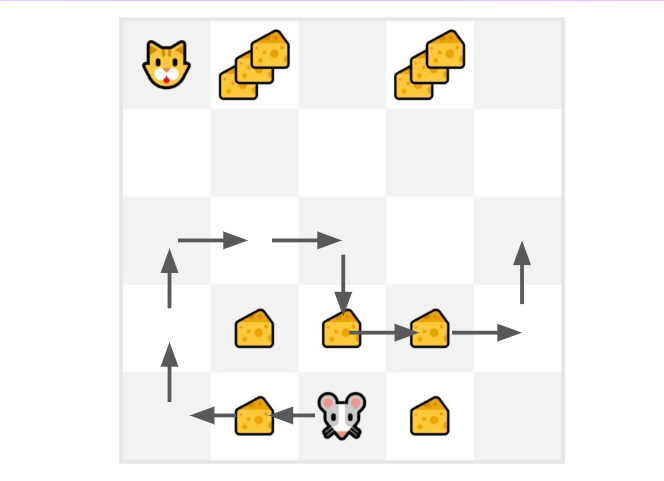
- 老鼠走了十多步,这一局就结束了。
- 得到一个 { state、action、rewards、next_state } 的列表, 需要计算 return $G{t}$
- $G_t = R_{t+1} + R_{t+2} + R_{t+3} ...$
- $G_t = R_{t+1} + R_{t+2} + R_{t+3}…$(为简单起见,不打折奖励)。
- $G_t = 1 + 0 + 0 + 0+ 0 + 0 + 1 + 1 + 0 + 0$
- $G_t= 3$
- 现在可以更新$V(S_0)$:

- 新的 $V(S_0) = V(S_0) + lr * [G_t — V(S_0)]$
- 新的 $V(S_0) = 0 + 0.1 * [3 – 0]Ⅴ ( S0)=0+0 . 1*[ 3 - 0 ]$
- 新的 $V(S_0) = 0.3$
时间差分学习:每一步都在学习
- 时间差分算法只等待一个交互(一步)$S_{t+1}$
- 形成一个TD目标, 并使用 $R_{t+1}$ 和 gamma * $V(S_{t+1}) $更新 $V(S_t)$ .
TD的想法是在每一步更新 $ V(S_t)$ 。但是因为没有使用整个Episode,所以没有$G_t$(期望收益)。相反,我们可以通过添加 $R_{t+1}$以及下一个状态的折扣值来估计G_t 。
这称为 bootstrapping。之所以这样称呼,是因为 TD 的更新部分基于现有的估计 $V(S_{t+1})$ 而不是一个完整的样本 $G_t$.

此方法称为 TD(0) 或 单步 TD 算法(在每个单个步骤后更新值函数)。

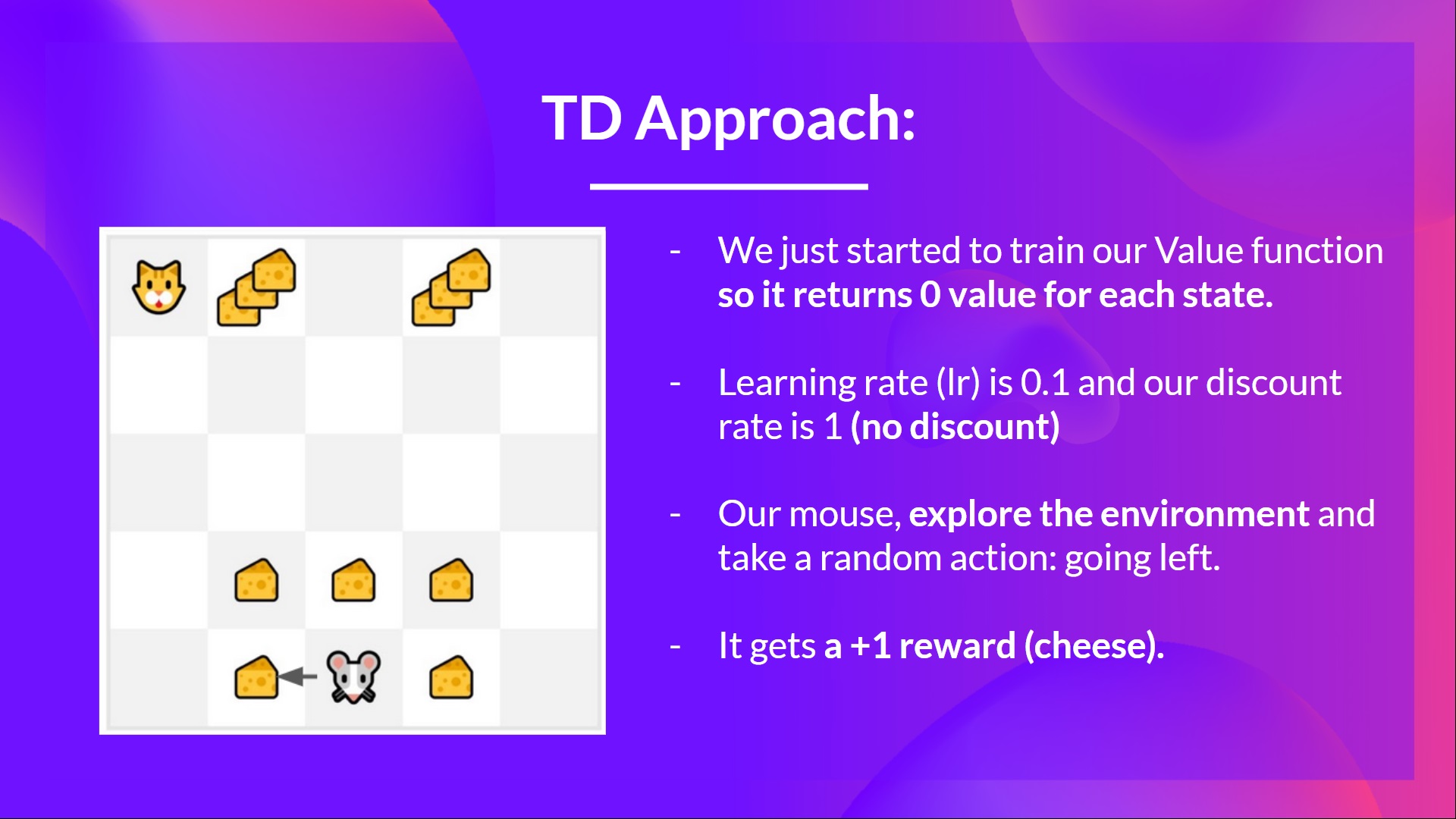
举同样的例子,

- 刚刚开始训练 Value 函数,对每个状态初始化 0 值。
- 学习率 (lr) 是 0.1,折扣率是 1(没有折扣)。
- 老鼠探索环境并采取随机动作: 向左移动
- 它得到了奖励 $R_{t+1} = 1 $ 因为 它吃一块奶酪
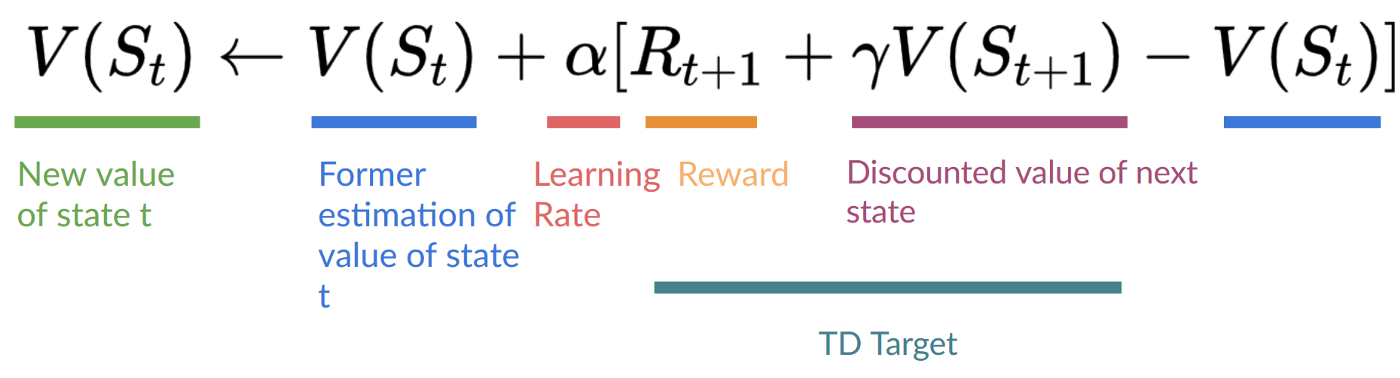
现在可以更新 $V(S_0)$:
新的 $V(S_0) = V(S_0) + lr * [R_1 + gamma * V(S_1) - V(S_0)]$
新的 $V(S_0) = 0 + 0.1 * [1 + 1 * 0–0]$
新的 $V(S_0) = 0.1$
所以刚刚更新了状态 0 的价值函数。
现在 继续使用更新的价值函数与这个环境进行交互。

总结一下:
- 使用蒙特卡洛,我们从一个完整的 episode 更新价值函数,因此 使用这一episode的实际准确折扣回报。
- 通过 TD learning,我们从一步更新价值函数,因此我们用一个称为TD目标的估计收益来代替我们没有的G_t。
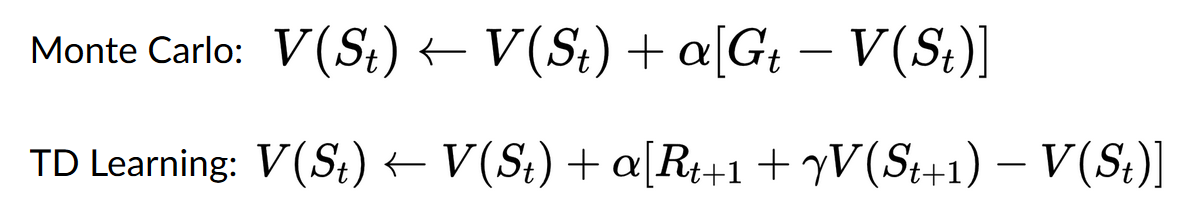
所以现在,在深入 Q-Learning 之前,总结一下刚刚学到的内容:
有两种基于价值的函数:
- 状态值函数:如果 智能体从给定状态开始并在之后永远按照策略执行动作,输出期望回报。
- Action-Value 函数:如果智能体在给定状态下开始, 在该状态下采取给定动作, 然后永远按照策略动作,则输出期望回报,
- 在基于价值的方法中, 手动定义策略, 因为我们不训练它,训练一个价值函数。这个想法是,如果有一个最优的价值函数, 就会有一个最优的策略。
有两种方法可以学习价值函数的策略:
- 使用 蒙特卡洛方法,从一个完整的episode更新价值函数,因此 使用这一episode的实际准确折扣报。
- 使用 TD 学习方法, 从一个步骤更新价值函数,因此我们用一个称为TD目标的估计收益来代替我们没有的Gt。

什么是 Q-Learning?
Q-Learning 是一种 基于 off-policy 价值的方法,它使用 TD 方法来训练其动作价值函数:
- Off-policy:我们将在本单元末尾讨论。
- 基于价值的方法:通过训练价值或动作价值函数来间接找到最优策略,这些价值或动作价值函数将告诉我们 每个状态或每个状态动作对的价值。
- 使用 TD 方法: 在每个步骤而不是在Episode结束时更新其动作值函数。
Q-Learning 是我们用来训练 Q-function 的算法,Q-function是一种 动作价值函数 ,它确定处于特定状态并在该状态下采取特定动作的价值。
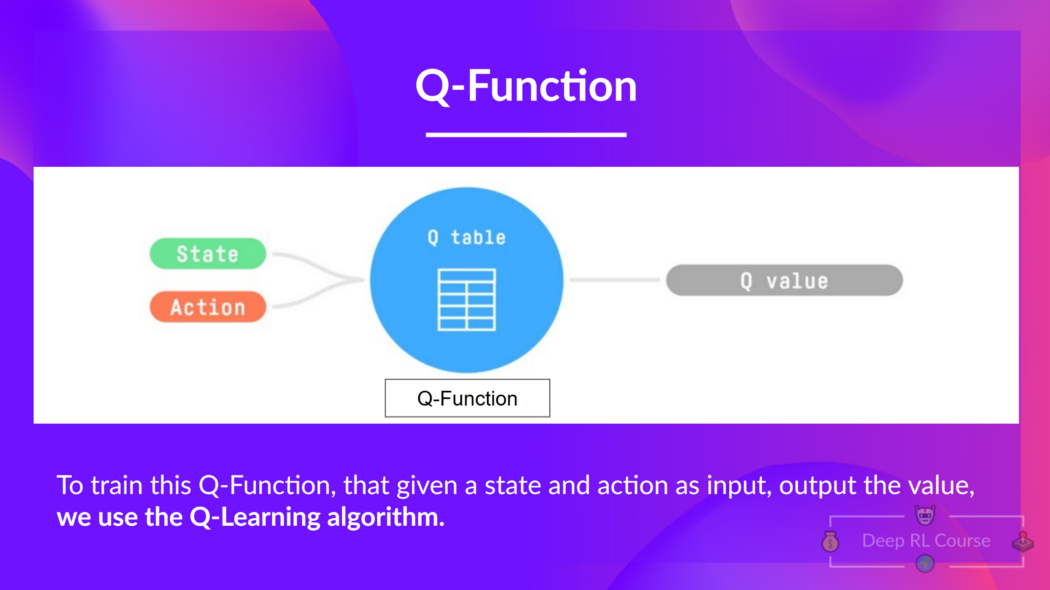
给定状态和动作,我们的 Q 函数输出状态动作值(也称为 Q 值)
Q 来自该状态下该动作的“质量”(价值)。
让我们回顾一下价值和奖励之间的区别:
- 状态或状态-动作对的值是我们的智能体从该状态(或状态-动作对)开始并根据其策略采取行动时获得的预期累积奖励。
- 奖励是我在某种状态下执行动作后从环境中得到的反馈。
在内部,Q 函数有 一个 Q 表,该表中每个单元格对应一个状态-动作对值。 将此 Q 表视为 Q 函数的内存或备忘单。
来看一个迷宫的例子。

Q表被初始化。这就是为什么所有值都 = 0 的原因。此表 包含每个状态的四个状态-动作值。

这里我们看到 初始状态和向上的state-action值为0:

因此,Q-function 包含一个 具有每个状态动作对值的 Q-table。 给定状态和动作, 我们的 Q 函数将在其 Q 表中搜索以输出值。
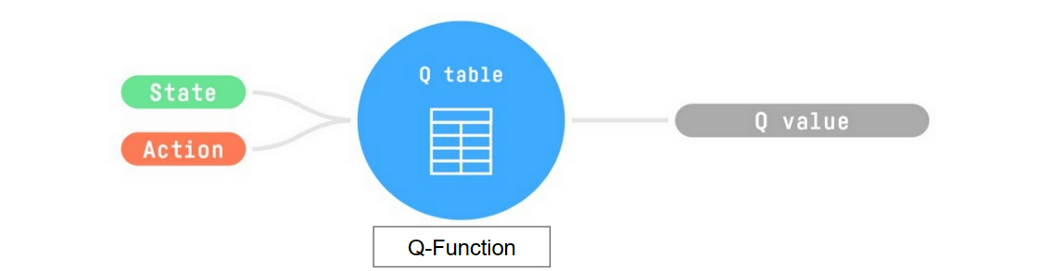
回顾一下, Q-Learning 是 RL 算法:
- 训练一个Q 函数(一个动作值函数),它在内部是一个 包含所有状态动作对值的 Q 表。
- 给定状态和动作,我们的 Q 函数 将在其 Q 表中搜索相应的值。
- 训练完成后, 我们有一个最优 Q 函数,这意味着我们有最优 Q 表。
- 如果我们 有一个最优 Q 函数,我们 就有一个最优策略 ,因为我们 知道每个状态采取什么是最好的行动。

但是,一开始, 我们的 Q 表是无用的,因为它为每个状态-动作对提供了任意值 (大多数时候,我们将 Q 表初始化为 0)。当智能体探索环境并更新 Q 表时,它将为我们提供越来越好的最优策略近似值。
 我们在这里看到,通过训练,我们的 Q 表更好,因为有了它,我们可以知道每个状态-动作对的值。
我们在这里看到,通过训练,我们的 Q 表更好,因为有了它,我们可以知道每个状态-动作对的值。
现在我们了解了 Q-Learning、Q-function 和 Q-table 是什么, 让我们更深入地研究 Q-Learning 算法。
Q-Learning 算法
这是 Q-Learning 伪代码;让我们研究每个部分,并在实现它之前通过一个简单的例子看看它是如何工作的。

第 1 步:我们初始化 Q 表

我们需要为每个状态动作对初始化 Q 表。 大多数时候,我们使用 0 值进行初始化。
第 2 步:使用 epsilon-greedy 策略选择动作
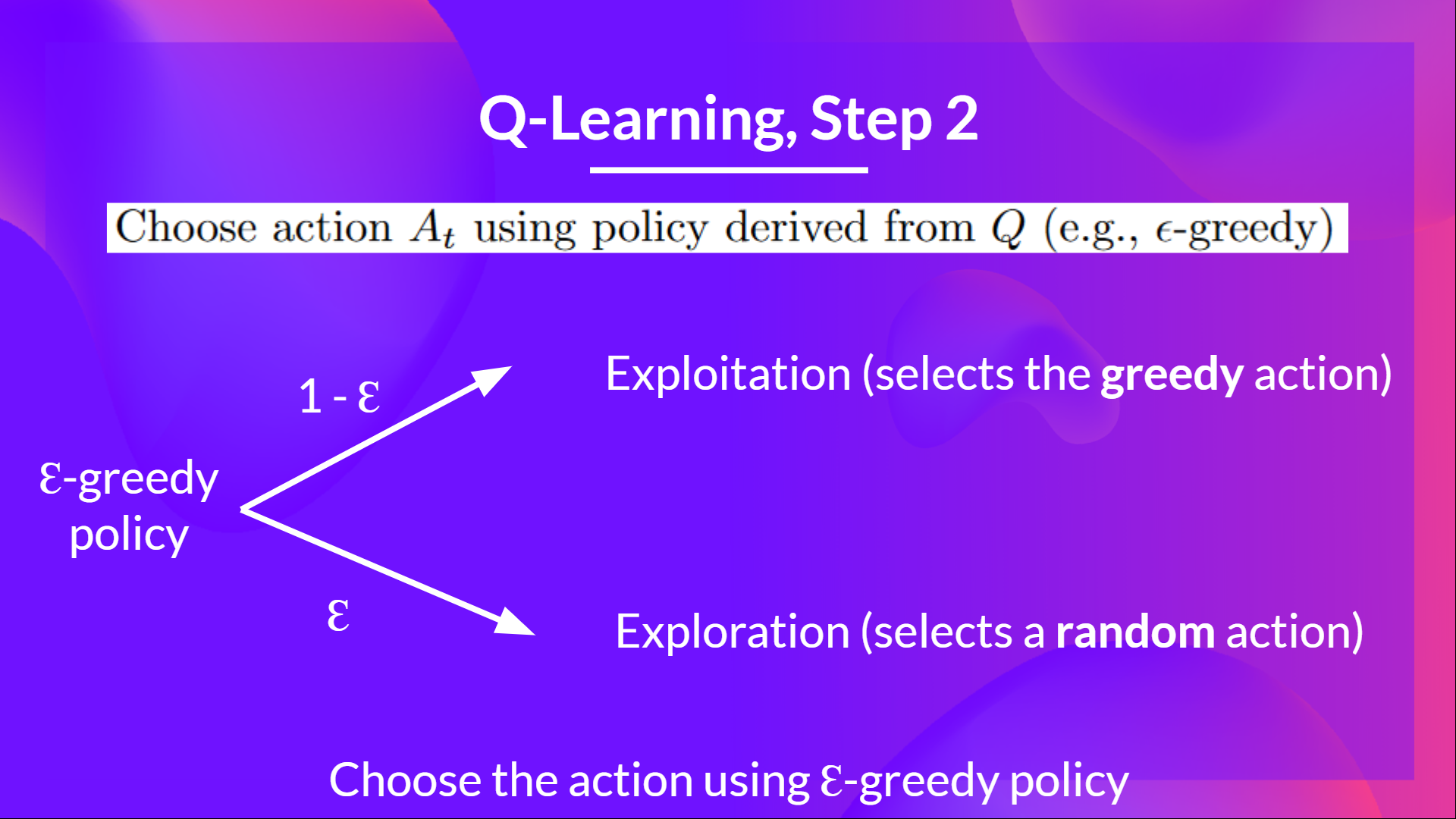
Epsilon 贪婪策略是一种处理探索/开发权衡的策略。
这个想法是我们定义初始 epsilon, $ɛ = 1.0$:
- 以1 - ε 的概率:我们进行 开发 (也就是我们的智能体选择具有最高状态-动作对值的动作)。
- ε 的概率: 我们进行探索 (尝试随机动作)。
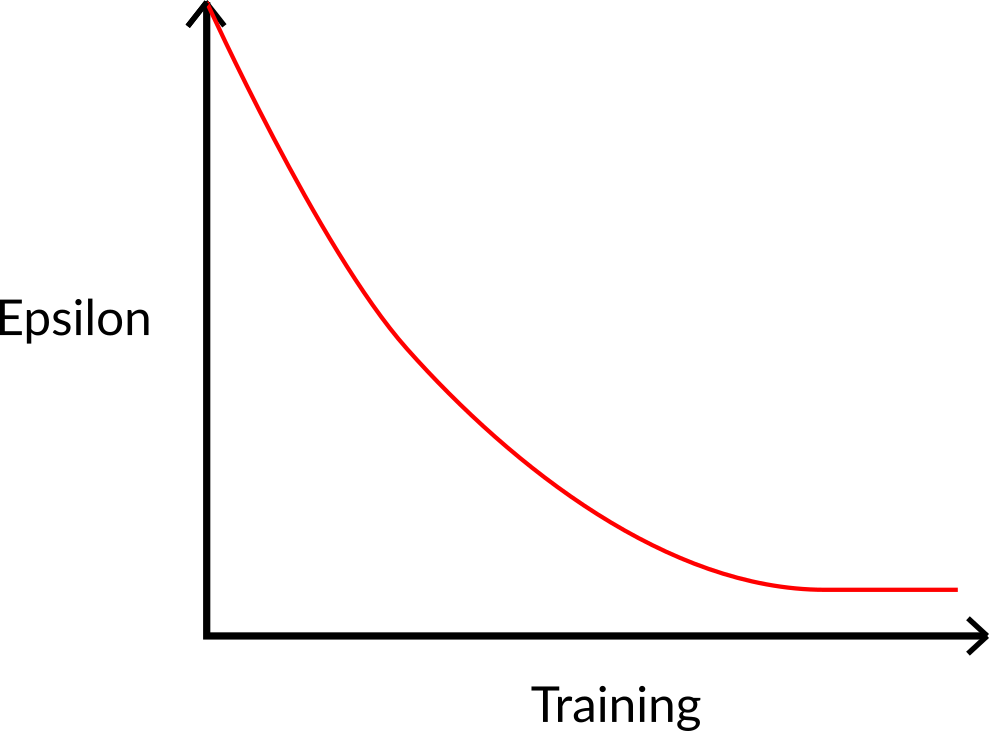
刚开始训练的时候,做探索的概率会很大,因为ε很大,所以大部分时间,我们都会探索。 但是随着训练的进行,我们的 Q 表的估计越来越好,我们逐渐降低 epsilon 值 ,因为我们需要越来越少的探索和更多的开发。
第三步:执行动作 $A_t$,得到奖励 $R_{t+1}$和下一个状态 $S_{t+1}$

第 4 步:更新 $Q(S_t, A_t)$
在 TD 学习中,我们会在交互的一个步骤后更新我们的策略或价值函数(取决于我们选择的 RL 方法) 。
为了产生我们的 TD 目标, 我们使用了即时奖励 $R_{t+1}$ 加上下一个状态最佳状态-动作对的折扣值 (我们称之为bootstrap)。
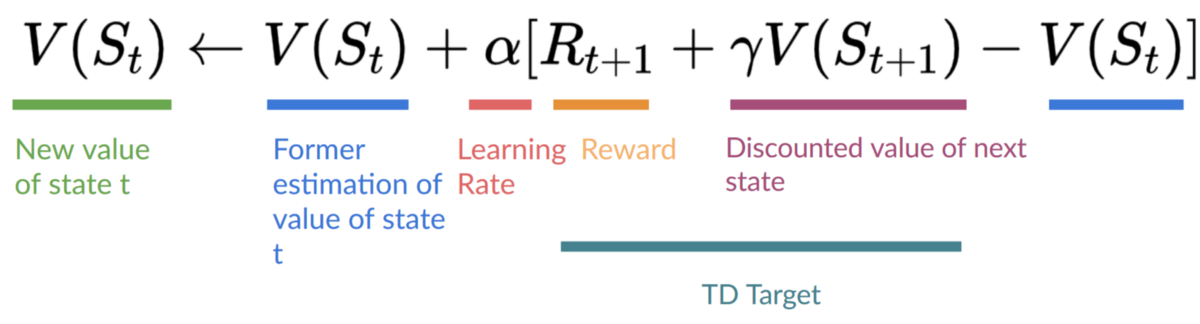
因此,我们的 $Q(S_t, A_t)$ 更新公式是这样的:
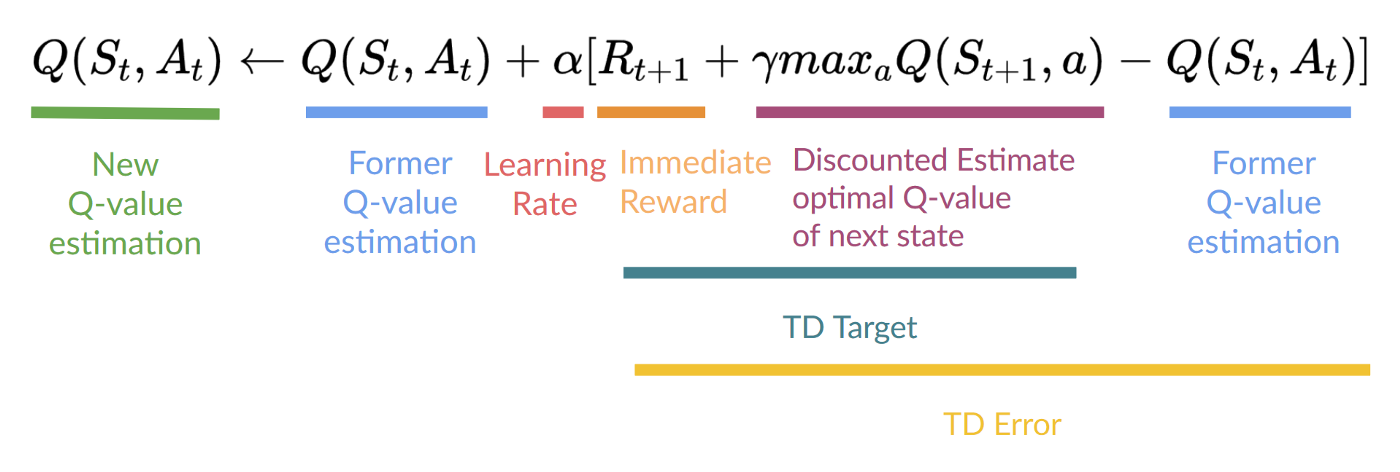
这意味着如要更新我们的 $Q(S_t, A_t)$ :
- 我们需要 $S_t, A_t, R_{t+1}, S_{t+1}$.
- 为了更新给定 状态-动作对 的 Q 值,我们使用 TD 目标。
我们如何形成TD目标?
- 我们在采取行动后获得奖励 $R_{t+1}$.
- 为了获得最佳的下一状态动作对值,我们使用贪心策略来选择下一个最佳动作。请注意,这不是 epsilon-greedy 策略,贪心策略总是会采取具有最高状态动作值的动作。
然后当这个 Q 值的更新完成时,我们从一个新的状态开始并 再次使用 epsilon-greedy 策略选择我们的动作。
这就是为什么我们说 Q Learning 是一种 off-policy 算法。
Off-policy vs On-policy
- Off-policy:使用 不同的策略来执行(推理)和更新(训练)。
例如,对于 Q-Learning,epsilon-greedy policy(行为策略)不同于 用于选择最佳下一状态动作值以更新我们的 Q 值(更新策略)的贪婪策略。执行动作使用的是 $ɛ - greedy$ 策略,而在训练过程中使用的是贪婪策略。
- On-policy: 使用 相同的策略来执行和更新。
例如,对于另一种基于值的算法 Sarsa,epsilon- greedy 策略选择下一个状态-动作对,而不是贪婪策略。

补充阅读
Monte Carlo and TD Learning
To dive deeper on Monte Carlo and Temporal Difference Learning:
- Why do temporal difference (TD) methods have lower variance than Monte Carlo methods?
- When are Monte Carlo methods preferred over temporal difference ones?