近端策略优化 (PPO)
在上一个单元中,我们了解了 Advantage Actor Critic (A2C),这是一种混合架构,结合了基于价值和基于策略的方法,通过减少方差来帮助稳定训练:
- 控制 Agent行为方式的 Actor(演员) (基于策略的方法)。
- 衡量 所采取动作好坏的 Critic (评论家) (基于价值的方法)。
今天我们将学习近端策略优化 (PPO),这是一种通过避免过多的策略更新来提高Agent训练稳定性的架构。为此,我们使用一个比率来指示我们当前和旧策略之间的差异,并将该比率裁剪到特定范围内 $[1 - \epsilon, 1 + \epsilon]$.这样做可以保证 Agent 策略更新不会太大,训练更稳定。
PPO 背后的直觉
近端策略优化 (PPO) 的想法是,我们希望通过限制在每个训练时期对策略所做的更改来提高策略的训练稳定性: 我们希望避免策略有太大更新。
有两个原因:
- 根据经验,我们知道训练期间较小的策略更新 更有可能收敛到最佳解决方案。
- 策略更新步子太大可能会导致“跌落悬崖”(得到一个糟糕的策略) 并且恢复时间很长,甚至没有恢复的可能。

RL 的修改版本——近端策略优化 (PPO),由 Jonathan Hui 解释:https://jonathan-hui.medium.com/rl-proximal-policy-optimization-ppo-explained-77f014ec3f12
所以对于 PPO,我们保守地更新策略。为此,我们需要使用当前策略与先前策略之间的比率计算来衡量当前策略与先前策略相比发生了多大变化。我们将这个比率限制在 $[1 - \epsilon, 1 + \epsilon]$范围内,这意味着我们 移除了当前策略与旧策略相去甚远的策略(这即是近端策略术语的含义)。
引入 Clipped 代理目标函数
回顾:策略目标函数
让我们回忆在 Reinforce 中优化的目标:

想法是,通过对该函数采取梯度上升步骤(相当于对该函数的负值进行梯度下降),将 推动Agent采取导致更高奖励的动作并避免有害动作。
但是,问题来自步长:
- 太小, 训练过程太慢
- 太高,训练中有太多的可变性
对于 PPO,其想法是使用称为 Clipped surrogate objective function 来约束Agent策略更新,该目标函数将使用裁剪将策略更改限制在一个小范围内。
这个新函数设计的目的 旨在避免破坏性的大的权重更新 :

让我们研究每个部分以了解其工作原理。
比率函数

这个比率是这样计算的:

这是当前的策略在 $s_t$ 下采取动作$a_t$的概率除以以前的策略的概率。
正如我们所见,$r_t(θ)$ 表示当前策略和旧策略之间的概率比:
- 如果 $r_t(\theta) > 1$ , 则状态 $s_t$ 的动作$a_t$在当前策略中比旧策略更有可能。
- 如果 $r_t(θ)$ 介于 0 和 1 之间, 当前策略比旧策略更不可能采取动作。
所以这个概率比是估计旧策略和当前策略之间差异的一种简单方法。
Clipped Surrogate Objective 函数的未裁剪部分

这个比率可以代替我们在策略目标函数中使用的对数概率。这为我们提供了新目标函数的左侧部分:将比率乘以优势。

近端策略优化算法
然而,在没有约束的情况下,如果在我们当前的策略中采取的动作比在我们以前的策略中更有可能采取动作, 这将导致重大的策略梯度步长 ,因此导致 过度的策略更新。
Clipped Surrogate Objective 函数的 Clipped Part

因此,我们需要通过惩罚导致比率偏离 1 的变化来约束此目标函数(在本文中,比率只能在 0.8 到 1.2 之间变化)。
通过裁剪比率,我们确保不会有太大的策略更新,因为当前策略不能与旧策略相差太大。
为此,我们有两个解决方案:
- TRPO(Trust Region Policy Optimization) 在目标函数之外使用KL散度约束来约束策略更新。但是这种方法 实现起来比较复杂并且需要更多的计算时间。
- PPO clip probability ratio直接在目标函数中用它的 Clipped surrogate objective function。
这个裁剪部分是PPO 的一个实现版本,其中 rt(theta) 被裁剪在 $[1 - \epsilon, 1 + \epsilon]$.
使用 Clipped Surrogate Objective 函数,我们有两个概率比,一个未被裁剪,一个被裁剪在(介于 $[1 - \epsilon, 1 + \epsilon]$ 的范围内, $ \epsilon $ 是一个超参数,可以帮助我们定义这个裁剪范围(在论文中 $\epsilon = 0.2$ ).
然后,我们采用裁剪目标和非裁剪目标中的最小值, 因此最终目标是未裁剪目标的下限(悲观边界)。
取 clipped 和 non-clipped objective 中的最小值意味着我们将根据比率和优势情况选择 clipped 或 non-clipped objective。
可视化Clipped Surrogate Objective
不用担心。如果现在处理起来似乎很复杂,这是正常的。但我们将看到这个 Clipped Surrogate Objective Function 是什么样子的,这将帮助您更好地想象正在发生的事情。
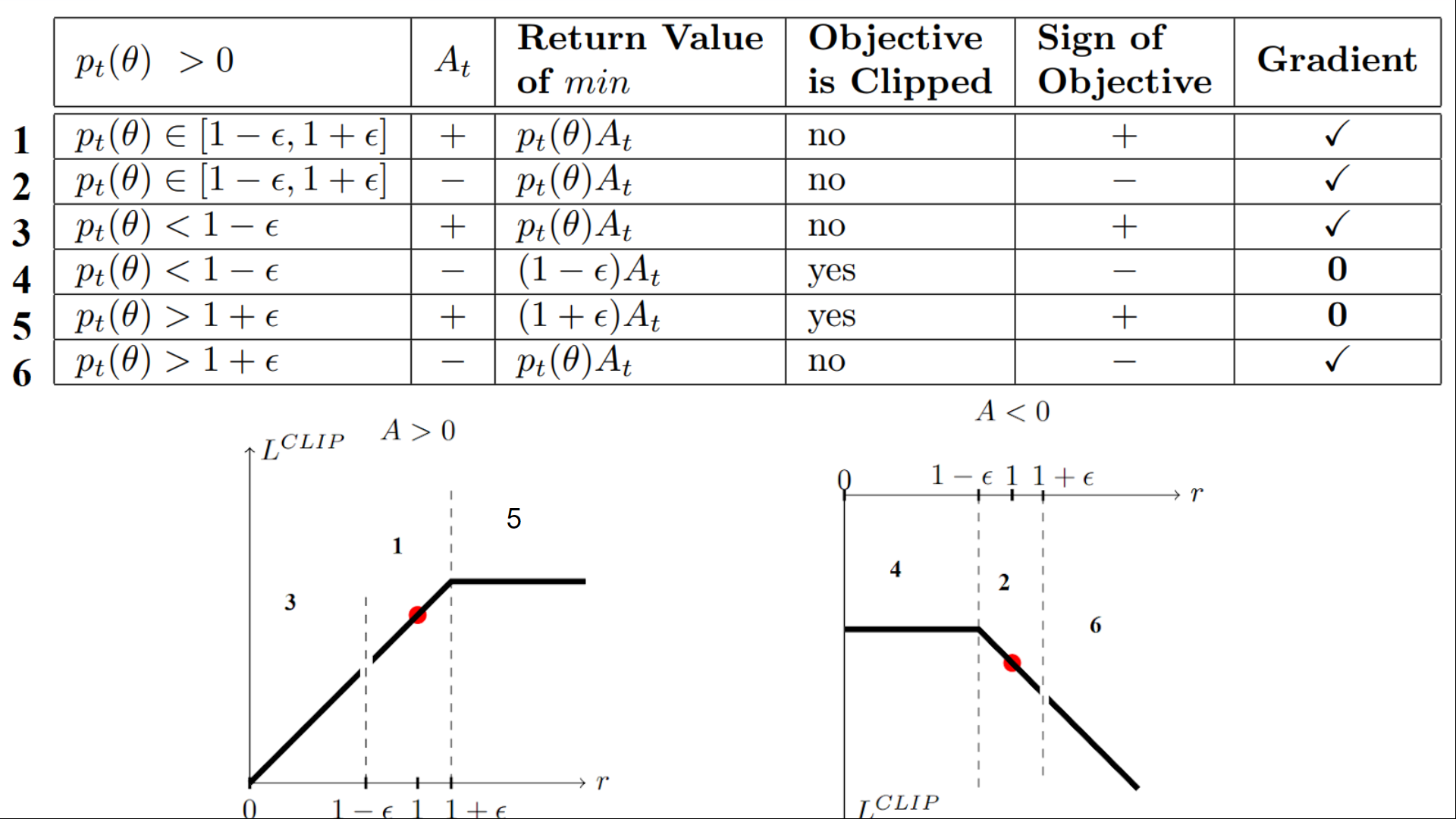
我们有六种不同的情况。首先请记住,我们采用的是经过裁剪和未裁剪的目标之间的最小值。
情况 1 和 2:比率介于范围之间
在情况 1 和 2 中,剪裁不适用,因为比率在范围之间 $[1 - \epsilon, 1 + \epsilon]$
在情况 1 中,我们有一个正的优势(A>0):该动作优于该状态下所有动作的平均值。因此,我们应该鼓励我们当前的策略,以增加在该 $s_t$ 采取该动作的可能性。
由于比率介于区间之间, 我们可以增加Agent策略在该状态下采取该动作的可能性。
在情况 2 中,我们有一个负面优势(A<0):动作比该状态下所有动作的平均值差。因此,我们应该阻止我们当前的策略在该 $s_t$ 采取该动作。
由于比率在区间之间, 我们可以降低Agent策略在该状态下采取该动作的可能性。
情况 3 和 4:比率低于范围
如果概率比低于 $1 - \epsilon $,在该状态下采取该动作的可能性远低于旧策略。
如果与情况 3 一样,优势估计为正 (A>0),那么您希望增加在该状态下采取该动作的概率。
但是,如果像情况 4 那样,优势估计为负,我们不想进一步降低在该状态下采取该动作的可能性。因此,梯度 = 0(因为我们在一条直线上),所以我们不更新权重。
情况 5 和 6:比率超出范围
如果概率比高于 $[1 + \epsilon] $,在当前策略中在该状态下采取该操作的概率远高于前一个策略。
如果像情况 5 那样,优势是正的,我们就不想太贪心了。与以前的策略相比,我们已经有更高的可能性在该状态下采取该动作。因此,梯度 = 0(因为我们在一条直线上),所以我们不更新权重。
如果像情况 6 那样,优势是负面的,我们希望降低在该状态下采取该动作的可能性。
因此,回顾一下,我们只会用未裁剪的目标部分更新策略。当最小值是被裁剪的目标部分时,我们不会更新Agent策略权重,因为梯度将等于 0。
因此,只有在以下情况下,我们才会更新Agent策略:
Agent比例在范围内 $[1 - \epsilon, 1 + \epsilon]$
Agent比率在范围之外,但优势导致越来越接近范围
- 低于比率但优势 > 0
高于比率但优势<0
你可能想知道,为什么当最小值是裁剪比率时,梯度为 0。当裁剪比率时,这种情况下的导数将不是 $r_t(\theta) * A_t $但其中任何一个$(1 - \epsilon)* A_t $或 $(1 + \epsilon)* A_t $ 的导数都为 0。
总而言之,由于这个被裁剪的替代目标, 我们限制了当前策略与旧策略的差异范围。 因为我们消除了概率比移出区间的动机,因为裁剪对梯度有影响。如果比率 $>1 + ε $ 或 $<1 - \epsilon $ 梯度将等于 0。
PPO Actor-Critic 风格的最终 Clipped Surrogate Objective Loss 看起来像这样,它是 Clipped Surrogate Objective 函数、Value Loss Function 和 Entropy bonus 的组合:
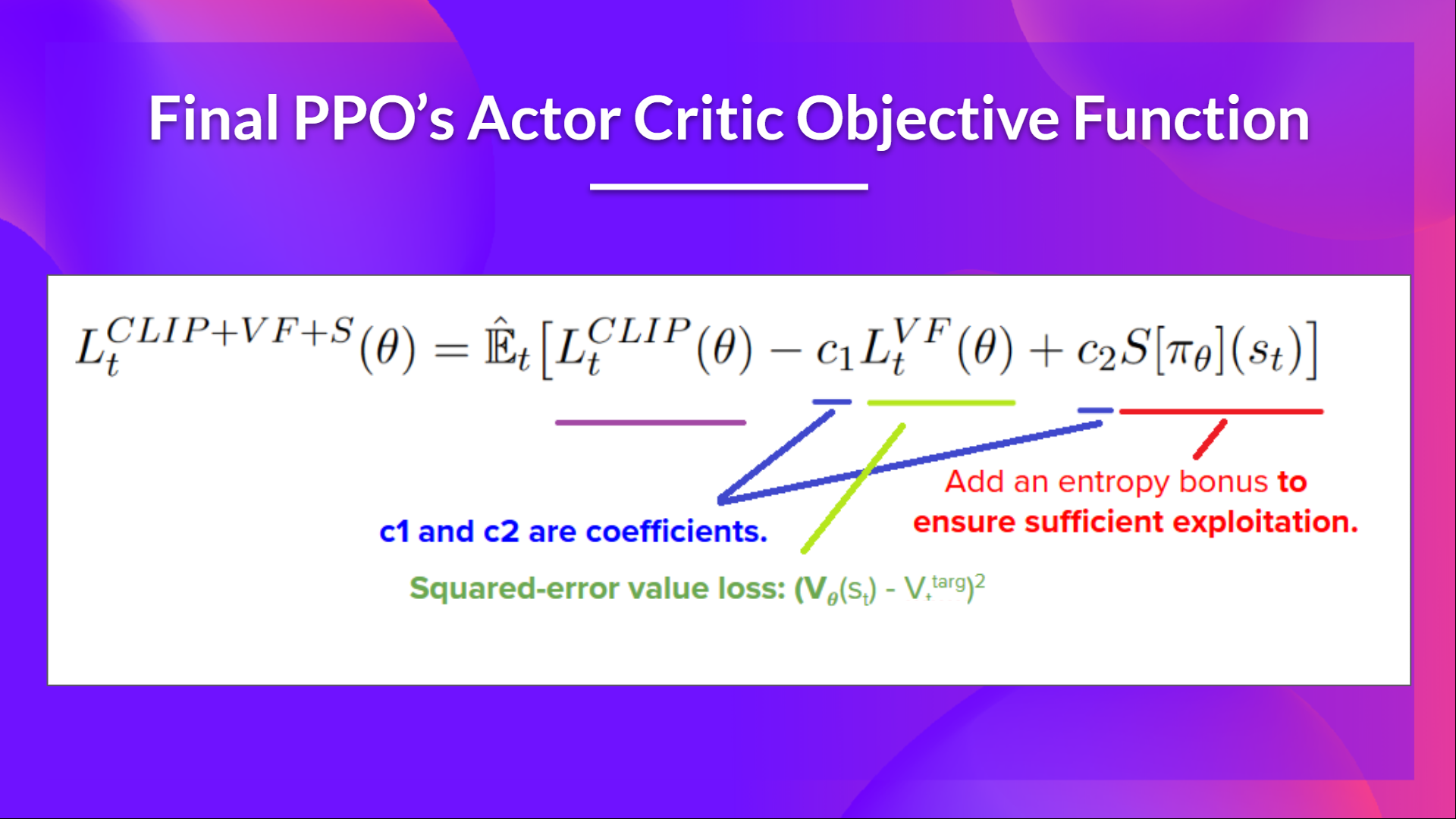
那是相当复杂的。花点时间通过查看表格和图表来了解这些情况。你必须明白为什么这是有道理的。如果您想深入了解,最好的资源是Daniel Bick 撰写的文章 Towards Delivering a Coherent Self-Contained Explanation of Proximal Policy Optimization,尤其是第 3.4 部分。
补充阅读
如果您想深入了解,这些是可选读物。
PPO Explained
- Towards Delivering a Coherent Self-Contained Explanation of Proximal Policy Optimization by Daniel Bick
- What is the way to understand Proximal Policy Optimization Algorithm in RL?
- Foundations of Deep RL Series, L4 TRPO and PPO by Pieter Abbeel
- OpenAI PPO Blogpost
- Spinning Up RL PPO
- Paper Proximal Policy Optimization Algorithms
PPO Implementation details
- The 37 Implementation Details of Proximal Policy Optimization
- Part 1 of 3 — Proximal Policy Optimization Implementation: 11 Core Implementation Details