MADDPG算法
论文链接:Counterfactual Multi-Agent Policy Gradients, AAAI 2017
代码链接:https://github.com/oxwhirl/pymarl
引言
传统RL算法面临的一个主要问题是由于每个智能体都是在不断学习改进其策略,因此从每一个智能体的角度看,环境是一个动态不稳定的,这不符合传统RL收敛条件。并且在一定程度上,无法通过仅仅改变智能体自身的策略来适应动态不稳定的环境。由于环境的不稳定,将无法直接使用之前的经验回放等DQN的关键技巧。policy gradient算法会由于智能体数量的变多使得本就有的方差大的问题加剧。
MADDPG算法具有以下三点特征:
- 通过学习得到的最优策略,在应用时只利用局部信息就能给出最优动作。
- 不需要知道环境的动力学模型以及特殊的通信需求。
- 该算法不仅能用于合作环境,也能用于竞争环境。
MADDPG算法具有以下三点技巧:
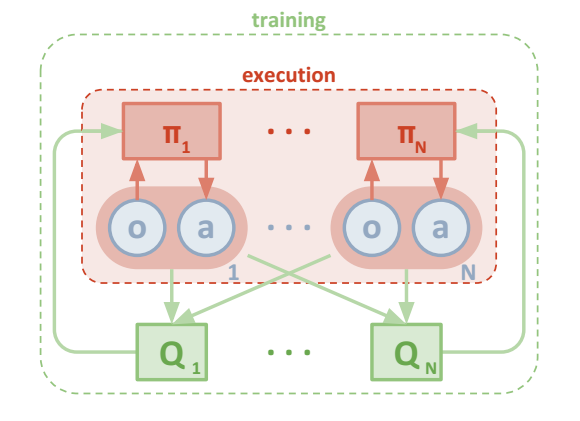
- 集中式训练,分布式执行
训练时采用集中式训练critic与actor,在训练阶段每个智能体的 Critic 网络会将所有智能体的观察及动作作为输入,而在执行阶段每个智能体的 Actor 网络仅将当前智能体的观察作为输入。
改进了经验回放记录的数据。为了能够适用于动态环境,每一条信息由 $$(x,x', a_q,\cdots,a_n,r_1,\cdots,r_n)$$ 组成, $$x=(o_1,\cdots,o_n) $$ 表示每个智能体的观测。
利用策略集合效果优化(policy ensemble)
对每个智能体学习多个策略,改进时利用所有策略的整体效果进行优化。以提高算法的稳定性以及鲁棒性。
其实MADDPG本质上还是一个DPG算法,针对每个智能体训练一个需要全局信息的Critic以及一个需要局部信息的Actor,并且允许每个智能体有自己的奖励函数(reward function),因此可以用于合作任务或对抗任务。并且由于脱胎于DPG算法,因此动作空间可以是连续的。
背景知识
DQN
DQN的思想就是设计一个 $Q(s,a|\theta) $ 不断逼近真实的 $Q(s,a) $ 函数。其中主要用到了两个技巧:
- 经验回放。2. 目标网络。
该技巧主要用来打破数据之间联系,因为神经网络对数据的假设是独立同分布,而MDP过程的数据前后有关联。打破数据的联系可以更好地拟合 $Q(s,a)$ 函数。其代价函数为:
$$L(\theta) = E_{s,a,r,s'}[(Q(s,a|\theta)-y)^2],\qquad \rm $$ where. $$ \ y=r+\gamma max_{a'}\overline Q(s',a'|\overline \theta) $$
其中 $Q(s',a'|\overline \theta)$ 表示目标网络,其参数更新与 $\theta$ 不同步(滞后)。
SPG(stochastic policy gradient)
SPG算法不采用拟合Q函数的方式,而是直接优化累积回报来获得使回报最大的策略。假定参数化的策略为 $\pi_\theta(a|s)$ ,累积回报为 $J(\theta)=E_{s\sim \rho^{\pi},a\sim \pi_\theta}[\sum_{t=0}^{\infty}\gamma^t r_t] $。为了使 $J(\theta)$ 最大化,直接对策略参数求导得到策略更新梯度:
$$\nabla_{\theta} J(\theta)=E_{s\sim \rho^{\pi},a\sim \pi_\theta}[\nabla_{\theta}\log\pi_\theta(a|s)Q^\pi(s,a)] $$
AC算法也可以由此推出,如果按照DQN的方法拟合一个 $Q(s,a|\theta) $函数,则这个参数化的 $Q(s,a|\theta)$ 函数被称为Critic,$\pi_\theta(a|s)$ 被称为Actor。
DPG
上述两种算法都是针对随机策略,$\pi_\theta(a|s) $ 是一个在状态 s 对于各个动作 a 的条件概率分布。DPG针对确定性策略, $\mu_\theta(s):S\to A$ 是一个状态空间到动作空间的映射。其思想与SPG相同,得到策略梯度公式为
$$ \nabla_{\theta} J(\theta)=E_{s\sim \beta}[\nabla_{\theta}\mu_\theta(s)\nabla_a Q^\mu(s,a)|{a=\mu\theta(s)}] $$
DPG可以是使用AC的方法来估计一个Q函数,DDPG就是借用了DQN经验回放与目标网络的技巧.
研究痛点
- 在多智能体问题中直接使用 DQN 算法时:
Independent Q-learning: 每个智能体都在随着训练而改变策略,导致整个环境的不稳定性。因此智能体存到replay buffer的经验都不能用。
(1)对于每个智能体来说其身处的马尔可夫环境是非平稳的,而这会影响 Q 学习算法的收敛性。
(2)另外 DQN 的经验回放技术的使用也将受到限制,因为当任意的 $πi′≠πi $时有可能出现 $P(s' | s,a,\pi_1,...,\pi_N) \neq P(s' | s,a,\pi'_1,...,\pi'_N),$此时经验便不再有效,这也是由于马尔可夫环境的非平稳所导致的。
- 策略梯度方法本来就面临高方差的问题,
- (1)而在多智能体环境中采用策略梯度方法将大大加剧其高方差的问题,因为此时每个智能体的 reward 不仅仅取决于当前智能体的动作,也取决于其他智能体的动作。
- (2)另外我们对策略梯度的采样估计方向也可能将随着智能体数量的增加而愈发不准确,具体如下。

MADDPG
多智能体Actor Critic
MADDPG采用集中式的学习,分布式的应用。因此我们允许使用一些额外的信息(全局信息)进行学习,只要在应用的时候使用局部信息进行决策就行。这点就是Q-learning的一个不足之处,Q-learning在学习与应用时必须采用相同的信息。所以这里MADDPG对传统的AC算法进行了一个改进,Critic扩展为可以利用其他智能体的策略进行学习,这点的进一步改进就是每个智能体对其他智能体的策略进行一个函数逼近。
环境的设置有较强的通用性:(1)每个智能体在实际执行时只使用local observation; (2)不对环境建模;(3)不对智能体间的通信做显式建模。然而,既然在实际中不知道其他agent的信息,但是其他的agent的信息能够很好的帮助学习,很自然就会想:我们就在训练的时候使用这些信息,实际运用的时候的不用这些信息,那很自然就可以学习出一个更好的agent了。更进一步,我们想要在offline的时候利用更多的信息学习出一个拥有比较好policy的agent,但是为了能够在实际的设置中使用,这个agent的policy的输入与输出在训练与实际使用的时候应该一样,所以无法直接把额外的信息直接结合在policy的输入中。那么有一种想法就是这些额外的信息既然无法直接用,那么就拿来做更准确的梯度的估计,那么很直观的想法就是用Actor Critic结构。
每一个智能体使用自己独立的actor,通过自己观测状态o,输出确定的动作a,同时训练数据也只使用自己产生的训练数据,每一个agent同时也对应一个critic,但是该critic同时接收所有actor产生的数据,本文将其当做中心化的critic。这种中心化critic和普通的中心化critic不同的是,本文的critic存在N个(每个agent一个)。
我们用 $\theta=[\theta_1,\cdots,\theta_n] $表示n个智能体策略的参数, $\pi=[\pi_1,\cdot,\pi_n]$ 表示n个智能体的策略。针对第i个智能体的累积期望奖励 $J(\theta_i)=E_{s\sim \rho^{\pi},a_i\sim \pi_{\theta_i} }[\sum_{t=0}^{\infty}\gamma^t r_{i,t}] $,针对随机策略,求策略梯度为:
$$\nabla_{\theta_i}J(\theta_i)=E_{s\sim \rho^\pi,a_i\sim \pi_i}[\nabla_{\theta_i}\log\pi_i(a_i|o_i)Q_i^{\pi}(x,a_1,\cdots,a_n)] $$
其中 $o_i $表示第i个智能体的观测,$x=[o_1,\cdots,o_n]$ 表示观测向量,即状态。 $Q_i^{\pi}(x,a_1,\cdots,a_n) $ 表示第i个智能体集中式的状态-动作函数。由于是每个智能体独立学习自己的 $Q_i^\pi $函数,因此每个智能体可以有不同的奖励函数(reward function),因此可以完成合作或竞争任务。
上述为随机策略梯度算法,下面我们拓展到确定性策略 $\mu_{\theta_i} $,梯度公式为
$$\nabla_{\theta_{i} } J\left(\boldsymbol{\mu}{i}\right) = \mathbb{E}{\mathbf{x}, a \sim \mathcal{D} }\left[\left.\nabla_{\theta_{i} } \boldsymbol{\mu}{i}\left(a | o_{i}\right) \nabla_{a_{i} } Q_{i}^{\boldsymbol{\mu} }\left(\mathbf{x}, a_{1}, \ldots, a_{N}\right)\right|{a=\boldsymbol{\mu}{i} }\left(o\right)\right]$$
由以上两个梯度公式可以看出该算法与SPG与DPG十分类似,就像是将单体直接扩展到多智能体。但其实 $Q_i^\mu$是一个非常厉害的技巧,针对每个智能体建立值函数,极大的解决了传统RL算法在Multi-agent领域的不足。D是一个经验存储(experience replay buffer),元素组成为 $(x,x',a_1,\cdots,a_n,r_1,\cdots,r_n)$ 。集中式的critic的更新方法借鉴了DQN中TD与目标网络思想
$$L(\theta_i)=E_{x,a,r,x'}[(Q_i^\mu(x,a_1,\cdots,a_n)-y)^2],\qquad \rm{where}\ y=r_i+\gamma \overline Q_i^{\mu'}(x',a_1',\cdots,a_n')|_{a_j'=\mu_j'(o_j)}\qquad (1) $$
$Q_i^{\mu'}$ 表示目标网络,$\mu'=[\mu_1',\cdots,\mu_n']$ 为目标策略具有滞后更新的参数 $\theta_j'$ 。其他智能体的策略可以采用拟合逼近的方式得到,而不需要通信交互。
如上可以看出critic借用了全局信息学习,actor只是用了局部观测信息。MADDPG的一个启发就是,如果我们知道所有的智能体的动作,那么环境就是稳定的,就算策略在不断更新环境也是恒定的,因为模型动力学是稳定的 $$P(s'|s,a_1,\cdots,a_n,\pi_1,\cdots,\pi_n)=P(s'|s,a_1,\cdots,a_n)=P(s'|s,a_1,\cdots,a_n,\pi_1',\cdots,\pi_n')$$ 。
Actor Critic的策略梯度公式为:$$\nabla_{\theta_{i} } J\left(\theta_{i}\right)=E_{s \sim p^{u}, a_{i} \sim \pi_{i} }\left[\nabla_{\theta_{i} } \log \pi_{i}\left(a_{i} | o_{i}\right) Q_{i}^{\pi}\left(o_{i}, a_{i}\right)\right]$$
推广到多智能体设置下,Actor Critic的策略梯度公式则为:
$$ \nabla_{\theta_{i} } J\left(\theta_{i}\right)=\mathbb{E}{s \sim p^{\mu}, a \sim \pi_{i} }\left[\nabla_{\theta_{i} } \log \pi_{i}\left(a_{i} | o_{i}\right) Q_{i}^{\pi}\left(\mathrm{x}, a_{1}, \ldots, a_{N}\right)\right] $$
推广到MADDPG下,即输出确定性动作,则策略梯度公式为:
$$ \nabla_{\theta_{i} } J\left(\boldsymbol{\mu}{i}\right) = \mathbb{E}{\mathbf{x}, a \sim \mathcal{D} }\left[\left.\nabla_{\theta_{i} } \boldsymbol{\mu}{i}\left(a | o_{i}\right) \nabla_{a_{i} } Q_{i}^{\boldsymbol{\mu} }\left(\mathbf{x}, a_{1}, \ldots, a_{N}\right)\right|{a=\boldsymbol{\mu}{i} }\left(o\right)\right] $$
其中$i$为agent,$\boldsymbol{\mu}$为策略。Critic的更新为:
$$ \mathcal{L}\left(\theta_{i}\right)=\mathbb{E}{\mathbf{x}, a, r, \mathbf{x}^{\prime} }\left[\left(Q^{\mu}\left(\mathbf{x}, a_{1}, \ldots, a_{N}\right)-y\right)^{2}\right], \quad y=r_{i}+\left.\gamma Q_{i}^{\mu^{\prime} }\left(\mathbf{x}^{\prime}, a_{1}^{\prime}, \ldots, a_{N}^{\prime}\right)\right|{a^{\prime}=\boldsymbol{\mu}{j}^{\prime}\left(o\right)} $$
其中$\boldsymbol{\mu'}$为target network策略。
估计其他智能体策略
知道其他agent的策略这个假设过于强,所以这里提出弱化该假设的方法:知道对手的action,不知道对手的policy。然后通过别人的observation和action来估计出别人的policy。所以可以采用极大似然估计来估计policy,另外加上一个entropy增加policy的不确定性:
$$ \mathcal{L}\left(\phi_{i}^{j}\right)=-\mathbb{E}{o, a_{j} }\left[\log \hat{\boldsymbol{\mu} }{i}^{j}\left(a | o_{j}\right)+\lambda H\left(\hat{\boldsymbol{\mu} }_{i}^{j}\right)\right] $$
使用这个估计出的别人的策略来更新Critic:
$$ \hat{y}=r_{i}+\gamma Q_{i}^{\boldsymbol{\mu}^{\prime} }\left(\mathbf{x}^{\prime}, \hat{\boldsymbol{\mu} }{i}^{\prime 1}\left(o\right), \ldots, \boldsymbol{\mu}{i}^{\prime}\left(o\right), \ldots, \hat{\boldsymbol{\mu} }{i}^{\prime N}\left(o\right)\right) $$
策略集合优化(policies ensemble)
很多时候agent使用的策略只对当前的其他agent使用的策略有效,一旦其他agent稍微变化效果就变差,所以在这里我们对每个agent都训练$k$个不同的策略,然后在每次训练的时候就在这个策略集中随机挑选一个,那么这样就有可能能够学出$k$个不同的策略,但是在实际运用中,我们只使用一个policy,所以我们可以利用这$k$个策略来做权衡,学习出一个总的策略。
这个技巧也是本文的一个亮点。多智能体强化学习一个顽固的问题是由于每个智能体的策略都在更新迭代导致环境针对一个特定的智能体是动态不稳定的。这种情况在竞争任务下尤其严重,经常会出现一个智能体针对其竞争对手过拟合出一个强策略。但是这个强策略是非常脆弱的,也是我们希望得到的,因为随着竞争对手策略的更新改变,这个强策略很难去适应新的对手策略。
对于每个sub policy单独采用MADDPG学习:
$$ J_{e}\left(\boldsymbol{\mu}{i}\right)=\mathbb{E}{k \sim \operatorname{unif}(1, K), s \sim p^{\mu}, a \sim \boldsymbol{\mu}{i}^{(k)} }\left[R(s, a)\right] $$
因此策略梯度公式变为:
$$ \nabla_{\theta_{i}^{(k)} } J_{e}\left(\boldsymbol{\mu}{i}\right)=\frac{1}{K} \mathbb{E}{\mathbf{x}, a \sim \mathcal{D}{i}^{(k)} } \left[\left.\nabla{\theta_{i}^{(k)} } \boldsymbol{\mu}{i}^{(k)}\left(a | o_{i}\right) \nabla_{a_{i} } Q^{\boldsymbol{\mu}{i} }\left(\mathbf{x}, a, \ldots, a_{N}\right)\right|{a=\boldsymbol{\mu}{i}^{(k)} }\left(o\right)\right] $$
MADDPG算法流程如图:

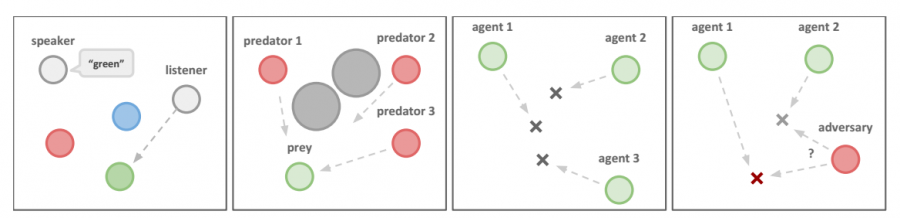
实验内容
在多个环境上打败了DDPG、DQN等Independent learning方法。
缺点
- 每一个Critic需要观测到所有的agent的状态和动作,对于大量不确定agent的场景,不是特别实用
- 当agent数量特别多的时候,状态空间太过于巨大
- 每一个agent都对应了一个actor和一个critic,数量多的时候,存在大量的模型。
优点
- 对于集中训练分步执行的方法是一种完善
- 是多智能体环境下的开创性工作。