Multi-Agent Env: PettingzZoo
概述
PetingZoo 是一个多智能体环境库,具有通用、优雅的 Python API。PetingZoo 开发目的是加速多智能体强化学习 ("MARL) 的研究,通过使工作更加可互换、可访问和可重现,类似于用于单智能体强化学习的OpenAI 的 Gym 库。PetingZoo 的 API 在继承 Gym 的许多特征的同时,在 MARL API 中是独一无二的,因为它基于新颖的 AEC 游戏模型。我们认为,通过对流行MARL环境中主要问题的案例研究,流行的博弈模型是MARL中常用的博弈概念模型差,因此可以促进难以检测的混淆错误,AEC博弈模型解决了这些问题。
背景
在 PettingZoo 之前,许多单个用途的 MARL API 几乎完全继承了他们在 MARL 文献中最突出的游戏数学模型的设计——部分可观察的随机游戏( Partially Observable Stochastic Games ("POSGs") )和广泛的形式游戏Extensive Form Games ((“EFG”))。在开发过程中,我们发现这些常见的游戏模型在概念上对于代码中实现的多智能体游戏来说并不清楚,并且不能形成干净处理所有类型的多智能体环境的 API 的基础。
为了解决这个问题,我们引入了一种新的游戏形式模型,即( Agent Environment Cycle ("AEC") )智能体环境循环游戏,作为 PettingZoo API 的基础。我们认为该模型更适合代码中实现的游戏的概念拟合。并且唯一地适用于一般的MARL API。然后,我们证明了任何 AEC 游戏都可以用标准的 POSG 模型表示,并且任何 POSG 都可以用 AEC 游戏表示。为了说明AEC博弈模型的重要性,本文进一步涵盖了流行的MARL实现中有意义的bug的两个案例研究。在这两种情况下,这些错误都会长时间被忽视。两者都源于使用令人困惑的游戏模型,并且通过使用基于 AEC 游戏的 API 是不可能的。
但是当前大多数单智能体环境库存在一些问题。
- 基于POSG(partially observable stochastic game)的环境库,例如Gym,所有的智能体一起行动、一起观察、一起得到奖励。但是这种库对回合制游戏支持不好,且无法更改智能体的数量。这类库由于难以处理智能体回合顺序、智能体死亡和创建这类数量上的变化,难以扩展到超过两个智能体的范畴。
- 基于扩展式博弈(EFG)的环境库,由于模型复杂、当前应用面不广。当前基于EFG的库只有OpenSpiel API3,这个库的局限性在于无法处理连续动作。且EFG游戏结束时才有奖励,而强化学习通常需要频繁的奖励。
因此,为了解决上述问题,PettingZoo引入了AEG(Agent Environment Cycle games)作为PettingZoo API的基础。在AEG模型中,智能体依次看到他们的观察结果、采取行动,从其他智能体发出奖励,并选择下一个要采取行动的智能体。这实际上是POSG模型的一个顺序步进形式。
相关工作
首先简要介绍Gym的API。该 API 是单智能体强化学习中事实上的标准,主要用作后续多智能体 API 的基础,稍后将进行比较。
import gym
env = gym.make('CartPole-v0')
observation = env.reset()
for _ in range(1000):
action = policy(observation)
observation, reward, done, info = env.step(action)Figure 1: An example of the basic usage of Gym
Gym API 是一个相当简单的 Python API,它借鉴了 RL 的 POMDP 概念化。API 的简单性和概念清晰度使其具有高度影响力,它自然地伴随着流行的 POMDP 模型,该模型用作强化学习的普遍心理和数学模型 [Brockman et al., 2016]。这使得任何对于RL 框架稍有理解人都更容易能完全理解 Gym 的 API。
部分可观察的随机博弈和 RLlib
Multi-agent 强化学习没有一个通用的心理和数学模型,如单智能体强化学习中的 POMDP 模型。最流行的模型之一是部分可观察的随机游戏(“POSG”)。该模型与多智能体 MDP [Boutilier, 1996]、Dec-POMDP [Bernstein et al., 2002] 和随机(“马尔可夫”)游戏 [Shapley, 1953])非常相似。在 POSG 中,所有智能体一起执行动作,一起观察,并一起获得奖励。
这种同步进行的模型自然地转化为类似 Gym 的 API,其中动作、观察、奖励等是智能体各个值的列表或字典。这种设计选择已经成为扑克等严格基于回合的游戏之外的MARL的标准。
图 2 显示了RLlib 中的多智能体 API 的一个例子,其中动作、观察和奖励的智能体关键字典被传递到 Gym API 的简单扩展中。
from ray.rllib.examples.env.multi_agent import MultiAgentCartPole
env = MultiAgentCartPole()
observation = env.reset()
for _ in range(1000):
actions = policies(agents, observation)
observation, rewards, dones, infos = env.step(actions)Figure 2: An example of the basic usage of RLlib
该模型使将单个智能体 RL 方法应用于多智能体设置更容易。然而,这个模型有两个直接的问题:
- 支持像国际象棋这样的严格基于回合的游戏需要不断地为非动作智能体传递虚拟动作(或使用类似的技巧)
- 难以处理智能体回合顺序、智能体死亡和创建这类数量上的变化,难以扩展到超过两个智能体的范畴。
OpenSpiel和 Extensive Form Games
在基于严格回合的游戏的情况下,POSG模型不太适合(例如国际象棋),MARL研究人员通常将游戏数学建模为Extensive Form Games (“EFG”)。EFG 将游戏表示为树,明确地将每个可能的动作序列表示为树中叶路径的根。通过添加“自然”玩家(有时也称为“机会”)来捕获游戏(或 MARL 环境)的随机方面,该玩家根据某个给定的概率分布采取行动。对于EFGs的完整定义,我们建议读者参考Osborne和Rubinstein[1994]或附录C.2。OpenSpiel [Lanctot et al., 2019],这是一个大型经典棋盘和卡片游戏集合的主要库,用于MARL,其API如图3所示。
import pyspiel import numpy as np
game = pyspiel.load_game("kuhn_poker")
state = game.new_initial_state()
while not state.is_terminal():
if state.is_chance_node():
# Step the stochastic environment.action_list,
prob_list = zip(*state.chance_outcomes())
state.apply_action(np.random.choice(action_list,
p=prob_list))
else:
# sample an action for the agent
legal_actions = state.legal_actions()
observations = state.observation_tensor()
action = policies(state.current_agent(), legal_actions, observations)
state.apply_action(action)
rewards = state.rewards()图 3:OpenSpiel 的基本用法示例
EFG 模型采用博弈论分析和树搜索等方法已成功用于解决涉及心智理论的问题。然而,对于一般MARL问题的应用,EFG模型出现了三个直接的问题:
- 与POSG相比,模型和相应的API非常复杂,不适合初学者以Gym的方式学习——例如,这个环境API比Gym的API或RLLib的POSG API要复杂得多。此外,由于EFG模型的复杂性,强化学习研究人员很难普遍地将其用作游戏的心理模型,就像他们使用POSG或POMDP模型一样。
- EFG游戏结束时才有奖励,而强化学习通常需要频繁的奖励。
- OpenSpiel API 无法处理连续动作(RL 中常见且重要的情况),尽管这是 EFG 模型固有的选择。
还值得注意的是,一些简单的严格回合的游戏是用单智能体Gym API建模的,环境交替控制智能体[Ha, 2020]。由于难以处理智能体顺序(例如 Uno)、智能体死亡和智能体创建的变化,这种方法无法合理地扩展到两个智能体之外。
PetingZoo
受到将 POSG 和 EFG 模型应用于 MARL API 的问题激发,我们开发了智能体环境循环(“AEC”)游戏。在这个模型中,智能体依次查看他们的观察、采取行动、从其他智能体发出奖励,并选择下一个要采取行动的智能体。这实际上是 POSG 模型的顺序Step形式。
PettingZoo 设计
按顺序建模多智能体环境有很多好处:
- 更清楚地将奖励归因于不同的来源,允许各种学习改进。
- 防止开发人员添加混淆和易于引入的竞争条件。
- 紧密地模拟了计算机游戏如何在代码中执行。
- 允许在RL所需的每个步骤之后奖励,是EFG模型通常不具备的。
- 对于初学者足够简单。
- 更改智能体死亡或创建的数量更容易,学习代码不需要考虑到不断变化的列表大小。
PettingZoo的设计还考虑了以下原则:
- 尽可能重用Gym的设计,并且使API成为标准化
- 具有大量智能体的环境
- 具有智能体死亡和创建的环境
- 不同的智能体可以选择参与每个episode
- 学习方法需要访问低级别特征学习方法
PettingZoo API
如图 6 所示,与 Gym API 的强相似性(图 1)——每个智能体向Step函数提供动作,并接收观察、奖励、完成、信息作为返回值。观察空间和状态空间也使用与 Gym 完全相同的空间对象。渲染和接近的方法也与 Gym 的功能相同,显示了当前视觉帧,表示每当调用时到屏幕的环境。reset 方法与 Gym 具有相同的功能——它在播放后将环境重置为起始配置。PetingZoo 真的只有与常规 Gym API 有两个偏差—— the last 和 agent_iter 方法和相应的迭代逻辑。
from pettingzoo.butterfly import pistonball_v0
env = pistonball_v0.env()
env.reset()
for agent in env.agent_iter(1000):
env.render()
observation, reward, done, info = env.last()
action = policy(observation, agent)
env.step(action)
env.close()Figure 6: An example of the basic usage of Pettingzoo
常用的方法有:
agent_iter(max_iter=2**63)返回一个迭代器,该迭代器产生环境的当前智能体。当环境中的所有智能体完成或max_iter(步骤已执行)时,它终止。last(observe=True)返回当前能够采取行动的智能体的observation, reward, done, info。返回的奖励是智能体自上次行动以来收到的累积奖励。如果observe设置为 False,则不会计算观测值,并且将返回 None 来代替它。请注意,完成单个智能体并不意味着环境已完成。reset()重置环境, 并设置它以供第一次调用时使用。只有在调用此函数后,agents 对象才会变得可用。step(action)接受并执行环境中智能体的操作,自动将控制权切换到下一个智能体。agent_selection显示当前选择的智能体。
其他特性
PettingZoo 将游戏建模为智能体环境循环(AEC) 游戏,因此可以支持多智能体 RL 可以考虑的任何游戏。因此,我们的 API 包含您可能不需要但在您需要时非常重要的较低级别的函数和属性。不过,它们的功能用于实现上面的高级函数,因此包含它们只是代码分解的问题。
agents:所有当前智能体的名称列表,通常为整数。这些可能会随着环境的进展而改变(即可以添加或删除智能体)。
num_agents:智能体列表的长度。agent_selection与当前选择的智能体相对应的环境属性,可以对其采取操作。observation_space(agent)检索特定智能体的观察空间的函数。对于特定的智能体 ID,此空间不应更改。action_space(agent)检索特定智能体的操作空间的函数。对于特定的智能体 ID,此空间不应更改。terminations:调用时每个当前智能体的终止状态的字典,按名称键入。last()访问该属性。请注意,可以在此字典中添加或删除智能体。返回的字典如下所示:
terminations = {0:[first agent's termination state], 1:[second agent's termination state] ... n-1:[nth agent's termination state]}truncations:调用时每个当前智能体的截断状态的字典,按名称键入。last()访问该属性。请注意,可以在此字典中添加或删除智能体。返回的字典如下所示:
truncations = {0:[first agent's truncation state], 1:[second agent's truncation state] ... n-1:[nth agent's truncation state]}infos:每个当前智能体的信息字典,按名称键入。每个智能体的信息也是一个字典。请注意,可以在此属性中添加或删除智能体。last()访问该属性。返回的字典如下所示:
infos = {0:[first agent's info], 1:[second agent's info] ... n-1:[nth agent's info]}observe(agent):返回智能体当前可以进行的观察。last()调用这个函数。rewards:当时呼叫的每个当前智能体的奖励的字典,按名称键入。奖励上一步后产生的瞬时奖励。请注意,可以在此属性中添加或删除智能体。last()不直接访问此属性,而是将返回的奖励存储在内部变量中。奖励结构如下:
{0:[first agent's reward], 1:[second agent's reward] ... n-1:[nth agent's reward]}
seed(seed=None)`:重新播种环境。必须在之后和之前`reset()`调用。`seed()``step()render():使用初始化时指定的渲染模式从环境返回渲染帧。在渲染模式为 的情况下'rgb_array',返回一个 numpy 数组,而 with'ansi'返回打印的字符串。无需使用render()模式调用human。close():关闭渲染窗口。
AEC API
默认情况下,PettingZoo 将游戏建模为智能体环境循环(AEC) 环境。这使得 PettingZoo 能够代表多智能体 RL 可以考虑的任何类型的游戏。
关于 AEC
Agent环境循环(AEC) 模型被设计为MARL 的类似Gym的 API,支持所有可能的用例和环境类型。
在 AEC 环境中,智能体按顺序采取行动,在采取行动之前接收更新的观察结果和奖励。环境在每个智能体执行完一步后更新,使其成为表示连续游戏(例如国际象棋)的自然方式。AEC 模型足够灵活,可以处理多智能体 RL 可以考虑的任何类型的游戏。
每个智能体步骤后底层环境都会更新。智能体在开始时会收到更新的观察结果和奖励。每一步之后环境都会更新,这是表示连续游戏(例如国际象棋)的自然方式,
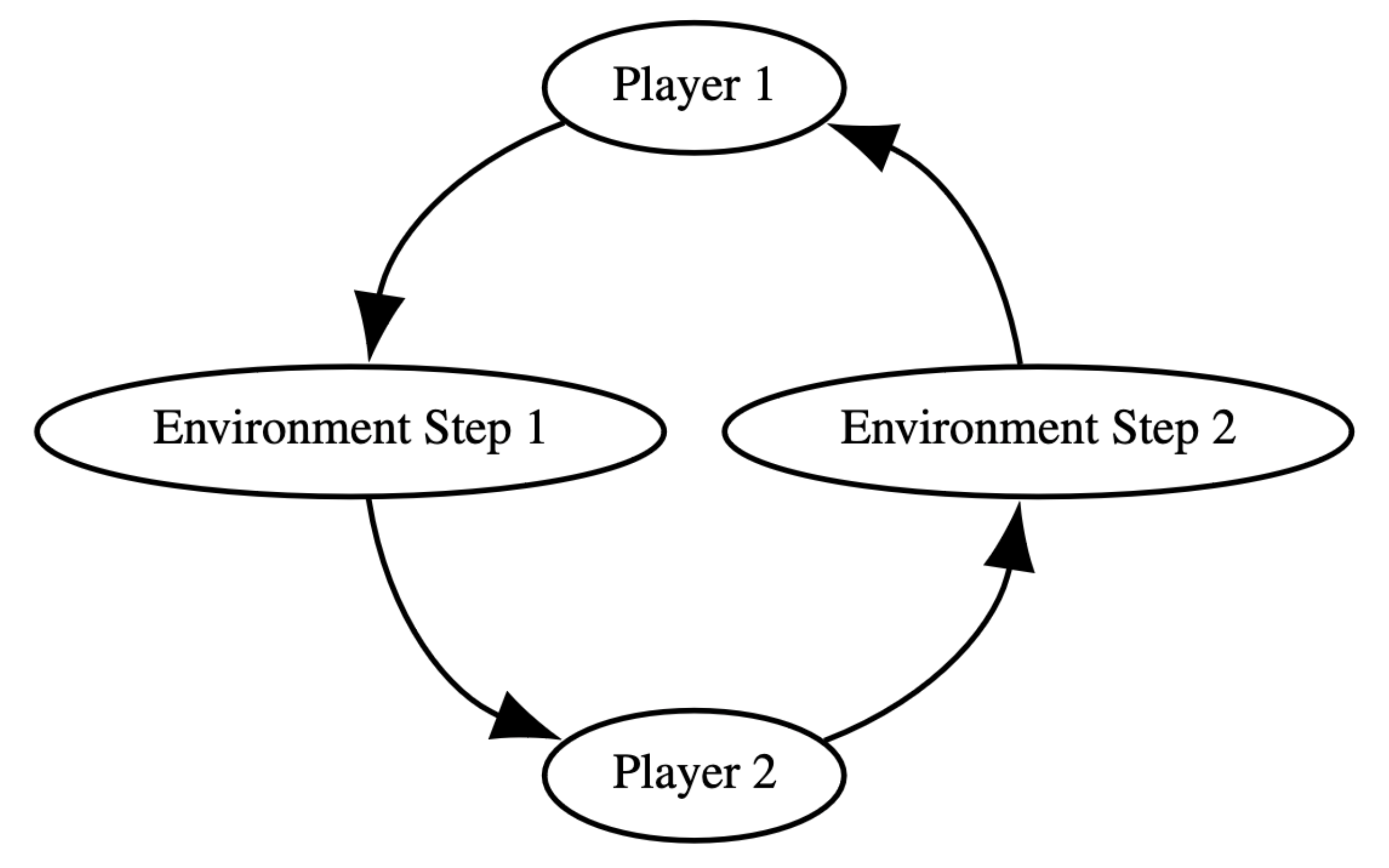
这与我们的Parallel API中表示的部分可观察随机博弈(POSG) 模型形成鲜明对比,在该模型中,智能体同时行动,并且只能在周期结束时接收观察和奖励。这使得表示顺序博弈变得困难,并导致竞争条件——智能体选择采取互斥的行动。这会导致环境行为根据智能体顺序的内部解析而有所不同,如果环境没有捕获和处理单个竞争条件(例如,通过打破平局),则会导致难以检测的错误。
AEC 模型类似于DeepMind 的OpenSpiel中使用的扩展形式游戏(EFG) 模型。EFG 将顺序游戏表示为树,明确地将每个可能的动作序列表示为树中从根到叶的路径。EFG 的局限性在于,正式定义是特定于博弈论的,并且只允许在游戏结束时进行奖励,而在 RL 中,学习通常需要频繁的奖励。
通过添加代表环境的玩家(例如 OpenSpiel 中的机会节点),可以将 EFG 扩展为代表随机游戏,该玩家根据给定的概率分布采取行动。然而,这需要用户在与环境交互时手动采样和应用机会节点操作,从而为用户错误和潜在的随机播种问题留下空间。
相比之下,AEC 环境在每个智能体步骤之后在内部处理环境动态,从而产生更简单的环境心智模型,并允许任意和不断变化的环境动态(与静态机会分布相反)。AEC 模型也更类似于计算机游戏在代码中的实现方式,并且可以被认为类似于游戏编程中的游戏循环。
用法
AEC 环境可以进行如下交互:
from pettingzoo.classic import rps_v2
env = rps_v2.env(render_mode="human")
env.reset(seed=42)
for agent in env.agent_iter():
observation, reward, termination, truncation, info = env.last()
if termination or truncation:
action = None
else:
action = env.action_space(agent).sample() # this is where you would insert your policy
env.step(action)
env.close()动作掩码
AEC 环境通常包括操作掩码,以便标记智能体的有效/无效操作。
要使用动作掩码对操作进行采样:
from pettingzoo.classic import chess_v6
env = chess_v6.env(render_mode="human")
env.reset(seed=42)
for agent in env.agent_iter():
observation, reward, termination, truncation, info = env.last()
if termination or truncation:
action = None
else:
# invalid action masking is optional and environment-dependent
if "action_mask" in info:
mask = info["action_mask"]
elif isinstance(observation, dict) and "action_mask" in observation:
mask = observation["action_mask"]
else:
mask = None
action = env.action_space(agent).sample(mask) # this is where you would insert your policy
env.step(action)
env.close()注意:动作掩码是可选的,可以使用 或 来observation实现info。
- PettingZoo Classic环境将动作掩码存储在
observation字典中:mask = observation["action_mask"]
- Shimmy的OpenSpiel 环境将动作掩码存储在
info字典中:mask = info["action_mask"]
Parallel API
除了主 API 之外,我们还有一个辅助并行 API,适用于所有智能体同时执行操作和观察的环境。可以通过创建具有并行 API 支持的环境<game>.parallel_env()。该 API 基于部分可观察随机博弈 (POSG) 范式,详细信息类似于RLlib 的 MultiAgent 环境规范,只是我们允许智能体之间有不同的观察和操作空间。
例子
PettingZoo Butterfly 提供了并行环境的标准示例,例如Pistonball。
我们提供了创建两个自定义并行环境的教程:石头剪刀布(并行)和简单的网格世界环境
用法
并行环境可以按如下方式进行交互:
from pettingzoo.butterfly import pistonball_v6
parallel_env = pistonball_v6.parallel_env(render_mode="human")
observations, infos = parallel_env.reset(seed=42)
while parallel_env.agents:
# this is where you would insert your policy
actions = {agent: parallel_env.action_space(agent).sample() for agent in parallel_env.agents}
observations, rewards, terminations, truncations, infos = parallel_env.step(actions)
parallel_env.close()Wrappers
Wrappers是一种环境转换,它将环境作为输入,并输出与输入环境类似的新环境,但应用了一些转换或验证。
以下Wrappers可与 PettingZoo 环境一起使用:
PettingZoo Wrappers 包括用于在 AEC 和 Parallel API之间进行转换Wrappers,以及一组提供输入验证和其他方便的可重用逻辑的简单实用程序Wrappers。
Supersuit Wrappers 包括常用的预处理功能,例如帧堆叠和色彩还原,与 PettingZoo 和 Gymnasium 兼容。
Shimmy 兼容性Wrappers 允许常用的外部强化学习环境与 PettingZoo 和 Gymnasium 一起使用。
Shimmy Compatibility Wrappers
Shimmy包允许常用的外部强化学习环境与 PettingZoo 和 Gymnasium 一起使用。
支持的环境
OpenAI Gym
- Bindings to convert OpenAI Gym environments to Gymnasium.
Atari Environments for OpenAI Gym
DeepMind Control
- Bindings to convert DM Control environments to Gymnasium.
Behavior Suite
- Bindings to convert Behavior Suite environments to Gymnasium.
DMLab
- Bindings to convert DM Lab environments to PettingZoo.
DeepMind Control: Multi-Agent
- Bindings to convert DM Control Soccer environments to PettingZoo.
OpenSpiel
- Bindings to convert OpenSpiel environments to PettingZoo.
Melting Pot
- Bindings to convert Melting Pot environments to PettingZoo.
基本用法
单智能体
单智能体Gymnasium环境可以通过以下方式加载gym.make():
import gymnasium as gym
env = gym.make("dm_control/acrobot-swingup_sparse-v0")运行环境:
observation, info = env.reset(seed=42)
for _ in range(1000):
action = env.action_space.sample() # this is where you would insert your policy
observation, reward, terminated, truncated, info = env.step(action)
if terminated or truncated:
observation, info = env.reset()
env.close()多智能体
多智能体PettingZoo环境可以通过 Shimmy 包装器加载Compatibility。
AEC 环境
加载环境:
from shimmy import OpenSpielCompatibilityV0
env = OpenSpielCompatibilityV0(game_name="backgammon", render_mode="human")运行环境:
env.reset()
for agent in env.agent_iter():
observation, reward, termination, truncation, info = env.last()
if termination or truncation:
action = None
else:
action = env.action_space(agent).sample(info["action_mask"]) # this is where you would insert your policy
env.step(action)
env.render()
env.close()Parallel 环境
加载环境:
from shimmy import MeltingPotCompatibilityV0
env = MeltingPotCompatibilityV0(substrate_name="prisoners_dilemma_in_the_matrix__arena")运行环境:
observations = env.reset()
while env.agents:
actions = {agent: env.action_space(agent).sample() for agent in env.agents}
observations, rewards, terminations, truncations, infos = env.step(actions)
env.close()ACE 和 Parallel 相互转换
加载的环境ParallelEnv可以使用parallel_to_aec.转换为AECEnv
加载的环境AECEnv可以使用parallel_to_aec转换为ParallelEnv
- 注意:此转换对底层环境做出以下假设:
- 环境按循环步进,即它按顺序遍历每个活动智能体。
- 除周期结束外,环境不会更新智能体的观察结果。
DeepMind 控制:足球
DM Control Soccer是一个多智能体机器人环境,智能体团队可以在其中进行足球比赛。它扩展了由MuJoCo物理引擎提供支持的单智能体DM Control Locomotion库。
Shimmy 提供兼容性包装器,将所有DM Control Soccer环境转换为PettingZoo。

安装
安装shimmy所需的依赖项:
pip install shimmy[dm-control-multi-agent]用法
加载新dm_control.locomotion.soccer环境:
from shimmy import DmControlMultiAgentCompatibilityV0
env = DmControlMultiAgentCompatibilityV0(team_size=5, render_mode="human")包装现有dm_control.locomotion.soccer环境:
from dm_control.locomotion import soccer as dm_soccer
from shimmy import DmControlMultiAgentCompatibilityV0
env = dm_soccer.load(team_size=2)
env = DmControlMultiAgentCompatibilityV0(env)注意:使用env参数以外的任何参数render_mode都会导致ValueError:
- 使用
env参数来包装现有环境。 - 使用
team_size、time_limit、disable_walker_contacts、enable_field_box、terminate_on_goal和walker_type参数加载新环境。
运行环境:
observations = env.reset()
while env.agents:
actions = {agent: env.action_space(agent).sample() for agent in env.agents} # this is where you would insert your policy
observations, rewards, terminations, truncations, infos = env.step(actions)
env.close()环境加载为ParallelEnv,但可以使用PettingZoo Wrappers。转换为AECEnv
DeepMind OpenSpiel
OpenSpiel是 70 多个环境的集合,适用于常见的棋盘游戏、纸牌游戏以及简单的网格世界和社交困境。
它支持n人(单智能体和多智能体)零和、合作和一般和、单发和顺序、严格轮流和同时移动、完美和不完美信息博弈。
Shimmy 提供了兼容性包装器,将所有OpenSpiel 环境转换为PettingZoo。

注意:PettingZoo 还提供流行的棋盘和纸牌游戏环境:PettingZoo Classic。
安装
安装shimmy所需的依赖项:
pip install shimmy[openspiel]用法
加载openspiel环境:
from shimmy import OpenSpielCompatibilityV0
env = OpenSpielCompatibilityV0(game_name="backgammon", render_mode="human")包装现有openspiel环境:
import pyspiel
from shimmy.openspiel_compatibility import OpenSpielCompatibilityV0
env = pyspiel.load_game("2048")
env = OpenSpielCompatibilityV0(env)注意:一起使用env和game_name参数将产生ValueError.
- 用于
env包装现有的 OpenSpiel 环境。 - 用于
game_name加载新的 OpenSpiel 环境。
运行环境:
env.reset()
for agent in env.agent_iter():
observation, reward, termination, truncation, info = env.last()
if termination or truncation:
action = None
else:
action = env.action_space(agent).sample(info["action_mask"]) # this is where you would insert your policy
env.step(action)
env.render()
env.close()