MuZero
通过使用学习模型进行规划来掌握 Atari、围棋、国际象棋和将棋
2019 年 11 月 19 日,DeepMind 发布了他们最新的基于模型的强化学习算法——MuZero。
历史
MuZero 是用于棋盘游戏(国际象棋、围棋……)和 Atari 游戏的最先进的 RL 算法。它是AlphaZero的继任者,但不了解环境底层动力学。MuZero 学习环境模型并使用仅包含有用信息的内部表示来预测奖励、价值、策略和转换。MuZero 也接近价值预测网络。
它是 DeepMind 研究人员设想的一长串强化学习算法中的最新算法。它始于 2014 年,随着著名的 AlphaGo 的诞生。Alpha Go 在 2015 年击败了围棋冠军李世石。
AlphaGo使用一种称为蒙特卡洛树搜索 (MCTS) 的算法来将游戏的其余部分规划为决策树。但微妙之处在于添加了一个神经网络来智能地选择动作,从而减少了未来要模拟的动作数量。
AlphaGo 的神经网络一开始是用人类玩家的游戏历史数据来训练的,2017 年 AlphaGo 被AlphaGo Zero取代,它不再使用人类玩家的经验数据。该算法首次在没有围棋策略先验知识的情况下学会单独下棋。它与自己对抗(使用 MCTS)然后从这些部分中学习(神经网络的训练)。
AlphaZero是 AlphaGo Zero 的一个版本,我们在其中删除了与围棋游戏相关的所有小技巧,以便它可以推广到其他棋盘游戏。
2019 年 11 月,DeepMind 团队发布了一个新的、更通用的 AlphaZero 版本,称为MuZero。它的特殊性是基于模型的,这意味着算法对游戏有自己的理解。因此,游戏规则由神经网络学习。MuZero 建立了自己对游戏的理解。他可以自己想象,如果执行这样或那样的操作,游戏会是什么样子。在 MuZero 之前,动作对游戏的影响是硬编码的。这样做的结果是允许他像发现游戏的人一样玩任何游戏。
换句话说,对于国际象棋,AlphaZero 设置了以下挑战:
学习如何自己玩这个游戏——这里的规则手册解释了每块棋子如何移动以及哪些移动是合法的。它还告诉您如何判断一个位置是将死(或平局)。
另一方面,MuZero 面临着这样的挑战:
学习如何自己玩这个游戏——我会告诉你在当前位置哪些动作是合法的,以及一方获胜(或平局)的时间,但我不会告诉你游戏的总体规则。
因此,除了制定制胜策略外,MuZero 还必须开发自己的动态环境模型,以便了解其选择的影响并提前规划。想象一下,在一场你从未被告知规则的比赛中,你试图成为比世界冠军更好的玩家。MuZero 恰恰做到了这一点。在下一节中,我们将通过详细浏览代码库来探索 MuZero 如何实现这一惊人的壮举。
MuZero 伪代码
除了 MuZero 预印本外 DeepMind 还发布了 Python伪代码,详细说明了算法各部分之间的交互。
在本节中,我们将按逻辑顺序区分每个函数和类,我将解释每个部分的作用和原因。我们假设 MuZero 正在学习下国际象棋,但任何游戏的过程都是相同的,只是参数不同。所有代码均来自开源的 DeepMind伪代码。
MuZero 主函数
让我们从整个过程的概述开始,从入口函数muzero 开始。
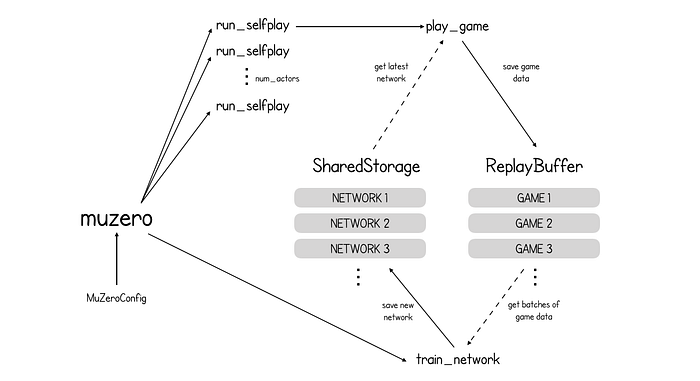
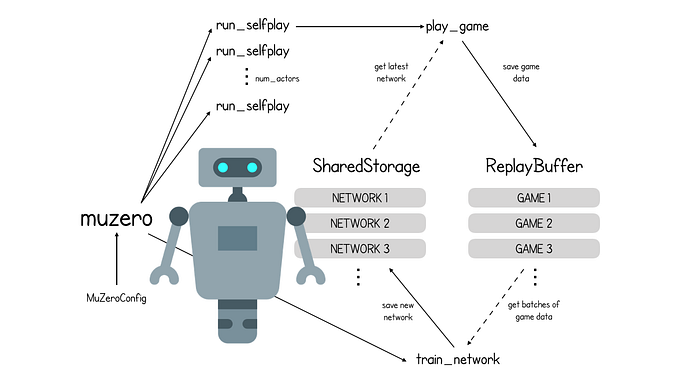
MuZero 自博弈和训练过程概述.
def muzero(config: MuZeroConfig):
storage = SharedStorage()
replay_buffer = ReplayBuffer(config)
for _ in range(config.num_actors):
launch_job(run_selfplay, config, storage, replay_buffer)
train_network(config, storage, replay_buffer)
return storage.latest_network()向函数muzero传递一个MuZeroConfig对象,该对象存储有关运行参数化的重要信息,例如action_space_size(可能的动作数量)和num_actors(要启动的并行游戏模拟数)。
在高层次上,MuZero 算法有两个独立的部分——自博弈(创建游戏数据)和训练(生成神经网络的改进版本)。SharedStorage和ReplayBuffer对象可以被算法的两部分访问并分别存储不同版的本神经网络模型参数和游戏数据。
Shared Storage和Replay Buffer
该SharedStorage对象包含用于保存神经网络版本和从存储中检索最新神经网络的方法。
class SharedStorage(object):
def __init__(self):
self._networks = {}
def latest_network(self) -> Network:
if self._networks:
return self._networks[max(self._networks.keys())]
else:
# policy -> uniform, value -> 0, reward -> 0
return make_uniform_network()
def save_network(self, step: int, network: Network):
self._networks[step] = network我们还需要一个ReplayBuffer来存储玩游戏过程中产生的数据。采用以下形式:
class ReplayBuffer(object):
def __init__(self, config: MuZeroConfig):
self.window_size = config.window_size
self.batch_size = config.batch_size
self.buffer = []
def save_game(self, game):
if len(self.buffer) > self.window_size:
self.buffer.pop(0)
self.buffer.append(game)
...请注意window_size参数限制Replay Buffer中存储的最大游戏局数。在 MuZero 中,被设置为最新的 1,000,000 场比赛。
自博弈 (run_selfplay)
创建Shared Storage和replay buffer后,MuZero 启动num_actors个独立运行的并行游戏环境。对于国际象棋,num_actors设置为 3000。每个actor都运行一个函数run_selfplay,从存储中获取最新版本的网络,用它玩游戏 ( play_game) 并将游戏数据保存到shared buffer。
# Each self-play job is independent of all others; it takes the latest network
# snapshot, produces a game and makes it available to the training job by
# writing it to a shared replay buffer.
def run_selfplay(config: MuZeroConfig, storage: SharedStorage,
replay_buffer: ReplayBuffer):
while True:
network = storage.latest_network()
game = play_game(config, network)
replay_buffer.save_game(game)因此,总而言之,MuZero 正在与自己进行数千场比赛,将这些比赛保存到Replay Buffer中,然后根据这些比赛的数据进行自我训练。到目前为止,这与 AlphaZero 没有什么不同。
MuZero 的 3 个神经网络
AlphaZero 和 MuZero 都使用一种称为蒙特卡洛树搜索 (MCTS)的技术来选择下一个最佳着法。
想法是,为了选择下一个最佳动作,从当前位置“播放”可能的未来场景,使用神经网络评估它们的价值并选择最大化未来预期值的动作。这似乎是我们人类在下棋时脑子里在做的事情,而人工智能也是为了利用这种技术而设计的。
但是,MuZero 有一个问题。由于它不知道游戏规则,它不知道给定的动作将如何影响游戏状态,因此它无法想象 MCTS 中的未来场景。它甚至不知道如何计算出在给定位置上哪些动作是合法的,或者其中一方是否获胜。
MuZero 论文中惊人的进展表明这无关紧要。MuZero 通过在自己的想象中创建环境的动态模型并在该模型中进行优化来学习如何玩游戏。
下图显示了 AlphaZero 和 MuZero 中 MCTS 流程的比较:
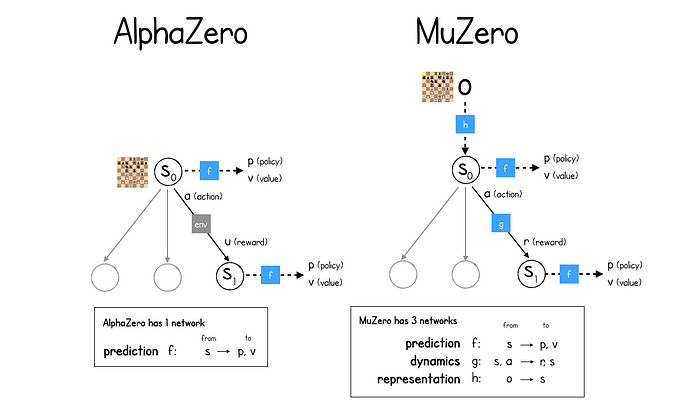
而 AlphaZero 只有一个神经网络(预测), MuZero 需要三个 (预测,动力学,表示)
AlphaZero 预测网络 f的工作是预测给定游戏状态的策略p和价值v。该策略是所有动作的概率分布,值只是估计未来奖励的值。每次 MCTS 命中一个未探索的叶节点时都会进行此预测,以便它可以立即为新位置分配一个估计值,并为每个后续动作分配一个概率。这些值被回填到树上,返回到根节点,因此经过多次模拟后,根节点对当前状态的未来值有了很好的了解,探索了许多不同的可能未来。
MuZero 也有一个预测神经网络f,但现在它运行的“游戏状态”是一个隐藏的表示,MuZero 通过动态神经网络g学习如何进化。动态网络采用当前隐藏状态s和选择的动作a并输出奖励r和新状态。注意在 AlphaZero 中,如何在 MCTS 树中的状态之间移动只是询问环境的情况。MuZero 没有这个奢侈,所以需要建立自己的动态模型!
最后,为了将当前观察到的游戏状态映射到初始表示,MuZero 使用第三个表示神经网络,h。
因此,MuZero 需要两个推理函数,以便通过 MCTS 树进行预测:
initial_inference对于当前状态。h网络后连接f网络(表示后跟预测)。recurrent_inference用于在 MCTS 树内的状态之间移动。f网络后连接g(表示其次是动态)。
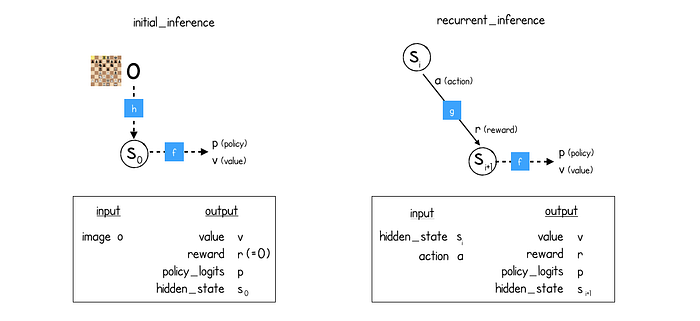
MuZero 中的两种推理
伪代码中未提供确切的模型,但随附的论文中提供了详细说明。
class NetworkOutput(typing.NamedTuple):
value: float
reward: float
policy_logits: Dict[Action, float]
hidden_state: List[float]
class Network(object):
def initial_inference(self, image) -> NetworkOutput:
# representation + prediction function
return NetworkOutput(0, 0, {}, [])
def recurrent_inference(self, hidden_state, action) -> NetworkOutput:
# dynamics + prediction function
return NetworkOutput(0, 0, {}, [])
def get_weights(self):
# Returns the weights of this network.
return []
def training_steps(self) -> int:
# How many steps / batches the network has been trained for.
return 0综上所述,在缺乏实际国际象棋规则的情况下,MuZero 在其脑海中创造了一个它可以控制的新游戏,并以此来规划未来。这三个网络(预测、动态和表示)一起优化,因此在想象环境中表现良好的策略在真实环境中也表现良好。
使用 MuZero 玩游戏 (play_game)
我们现在将逐步执行该play_game函数:
# Each game is produced by starting at the initial board position, then
# repeatedly executing a Monte Carlo Tree Search to generate moves until the end
# of the game is reached.
def play_game(config: MuZeroConfig, network: Network) -> Game:
game = config.new_game()
while not game.terminal() and len(game.history) < config.max_moves:
# At the root of the search tree we use the representation function to
# obtain a hidden state given the current observation.
root = Node(0)
current_observation = game.make_image(-1)
expand_node(root, game.to_play(), game.legal_actions(),
network.initial_inference(current_observation))
add_exploration_noise(config, root)
# We then run a Monte Carlo Tree Search using only action sequences and the
# model learned by the network.
run_mcts(config, root, game.action_history(), network)
action = select_action(config, len(game.history), root, network)
game.apply(action)
game.store_search_statistics(root)
return game首先,Game创建一个新对象并启动主游戏循环。当满足终止条件或移动次数超过允许的最大值时,游戏结束。
我们从根节点开始 MCTS 树。
root = Node(0)每个节点存储与其被访问次数相关的关键统计信息visit_count,to_play,选择该节点的动作的预测先验概率,价值总和value_sum,其子节点children,隐藏状态hidden_state, 通过移动到该节点而获得的预测奖励reward。
class Node(object):
def __init__(self, prior: float):
self.visit_count = 0
self.to_play = -1
self.prior = prior
self.value_sum = 0
self.children = {}
self.hidden_state = None
self.reward = 0
def expanded(self) -> bool:
return len(self.children) > 0
def value(self) -> float:
if self.visit_count == 0:
return 0
return self.value_sum / self.visit_count接下来我们要求游戏返回当前观察(对应上图中o)......
current_observation = game.make_image(-1)…并使用游戏提供的已知合法行为和函数提供的关于当前观察的推断来扩展根节点initial_inference。
expand_node(root, game.to_play(), game.legal_actions(),network.initial_inference(current_observation))# We expand a node using the value, reward and policy prediction obtained from
# the neural network.
def expand_node(node: Node, to_play: Player, actions: List[Action],
network_output: NetworkOutput):
node.to_play = to_play
node.hidden_state = network_output.hidden_state
node.reward = network_output.reward
policy = {a: math.exp(network_output.policy_logits[a]) for a in actions}
policy_sum = sum(policy.values())
for action, p in policy.items():
node.children[action] = Node(p / policy_sum)我们还需要向根节点动作添加探索噪音——这对于确保 MCTS 探索一系列可能的动作而不是仅仅探索它当前认为最佳的动作很重要。对于国际象棋,root_dirichlet_alpha= 0.3。
add_exploration_noise(config, root)# At the start of each search, we add dirichlet noise to the prior of the root
# to encourage the search to explore new actions.
def add_exploration_noise(config: MuZeroConfig, node: Node):
actions = list(node.children.keys())
noise = numpy.random.dirichlet([config.root_dirichlet_alpha] * len(actions))
frac = config.root_exploration_fraction
for a, n in zip(actions, noise):
node.children[a].prior = node.children[a].prior * (1 - frac) + n * frac我们现在进入主要的 MCTS 过程,我们将在下一节中介绍。
run_mcts(config, root, game.action_history(), network)MuZero 中的蒙特卡罗搜索树 (run_mcts)
# Core Monte Carlo Tree Search algorithm.
# To decide on an action, we run N simulations, always starting at the root of
# the search tree and traversing the tree according to the UCB formula until we
# reach a leaf node.
def run_mcts(config: MuZeroConfig, root: Node, action_history: ActionHistory,
network: Network):
min_max_stats = MinMaxStats(config.known_bounds)
for _ in range(config.num_simulations):
history = action_history.clone()
node = root
search_path = [node]
while node.expanded():
action, node = select_child(config, node, min_max_stats)
history.add_action(action)
search_path.append(node)
# Inside the search tree we use the dynamics function to obtain the next
# hidden state given an action and the previous hidden state.
parent = search_path[-2]
network_output = network.recurrent_inference(parent.hidden_state,
history.last_action())
expand_node(node, history.to_play(), history.action_space(), network_output)
backpropagate(search_path, network_output.value, history.to_play(),
config.discount, min_max_stats)由于 MuZero 不了解环境规则,因此它也不知道在整个学习过程中可能获得的奖励界限。创建该MinMaxStats对象是为了存储有关当前遇到的最小和最大奖励的信息,以便 MuZero 可以相应地规范化其价值输出。或者,也可以使用国际象棋 (-1, 1) 等游戏的已知边界对其进行初始化。
MCTS 主循环迭代num_simulations,其中一次的模拟是通过 MCTS 树直到到达叶节点(即未探索的节点)和随后的反向传播。
首先,history使用从游戏开始至今采取的行动列表进行初始化。当前node是root节点并且search_path仅包含当前节点。
模拟如下图所示进行:
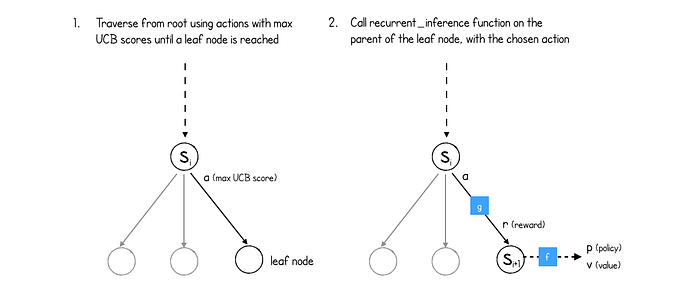
MuZero 首先向下遍历 MCTS 树,始终选择 UCB(置信上限)得分最高的动作:
# Select the child with the highest UCB score.
def select_child(config: MuZeroConfig, node: Node,
min_max_stats: MinMaxStats):
_, action, child = max(
(ucb_score(config, node, child, min_max_stats), action,
child) for action, child in node.children.items())
return action, childUCB 分数是根据选择动作的先验概率P(s,a)和已经选择动作的次数来平衡动作的估计值Q(s,a)和探索奖励的度量N(s,a)。
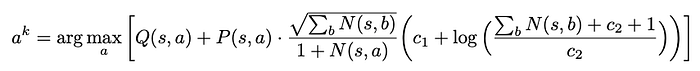
在 MCTS 树的每个节点选择具有最高 UCB 分数的动作。
在模拟的早期,探索奖励占主导地位,但随着模拟总数的增加,价值项变得更加重要。
最终,该过程将到达叶节点(尚未扩展的节点,因此没有子节点)。
此时,recurrent_inference在叶节点的父节点上调用该函数,以获得预测的奖励和新的隐藏状态(来自动态网络)以及新隐藏状态的策略和值(来自预测网络)。
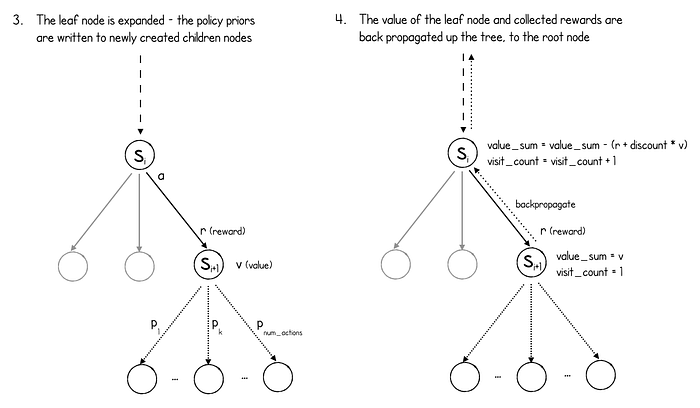
MCTS过程(叶子扩展和反向传播)
如上图所示,叶节点现在通过创建新的子节点(一个用于游戏中的每个可能的动作)并为每个节点分配其各自的先验策略来扩展。注意,MuZero 不会检查这些动作中的哪些是合法的,或者该动作是否导致游戏结束(它做不到),因此无论它是否合法, MuZero为每个动作都创建了一个节点。
最后,网络预测的值沿着搜索路径进行反向传播。
# At the end of a simulation, we propagate the evaluation all the way up the
# tree to the root.
def backpropagate(search_path: List[Node], value: float, to_play: Player,
discount: float, min_max_stats: MinMaxStats):
for node in search_path:
node.value_sum += value if node.to_play == to_play else -value
node.visit_count += 1
min_max_stats.update(node.value())
value = node.reward + discount * value请注意 Value 值根据不同的玩家来翻转的(如果叶节点对于应该玩的玩家是正数,那么对于另一个玩家来说它将是负数)。此外,由于预测网络预测未来值,在搜索路径上收集的奖励被收集起来并添加到折扣叶节点值中,因为它被传播回树。
请记住,由于这些是预测的奖励,而不是来自环境的实际奖励,因此即使对于像国际象棋这样的游戏来说,奖励的收集也是相关的,在这种游戏中,真正的奖励只在游戏结束时才会颁发。MuZero 正在玩自己想象的游戏,其中可能包括临时奖励,即使它所模仿的游戏没有。
这样就完成了一次MCTS过程的模拟。
在经过num_simulations的模拟之后,进程停止,并根据访问根的每个子节点的次数选择一个动作
def select_action(config: MuZeroConfig, num_moves: int, node: Node,
network: Network):
visit_counts = [
(child.visit_count, action) for action, child in node.children.items()
]
t = config.visit_softmax_temperature_fn(
num_moves=num_moves, training_steps=network.training_steps())
_, action = softmax_sample(visit_counts, t)
return action
def visit_softmax_temperature(num_moves, training_steps):
if num_moves < 30:
return 1.0
else:
return 0.0 # Play according to the max.对于前 30 个动作,softmax 的温度设置为 1,这意味着每个动作的选择概率与它被访问的次数成正比。从第 30 步开始,选择访问次数最多的动作。
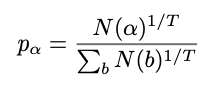
softmax_sample:从根节点选择动作'alpha'的概率(N为访问次数)
虽然访问次数可能感觉是一个奇怪的指标来选择最终行动,但事实并非如此,因为 MCTS 流程中的 UCB 选择标准旨在最终花更多时间探索它认为真正高价值机会的行动,一旦它在此过程的早期充分探索了替代方案。
然后将所选操作应用于真实环境,并将相关值附加到以下列表中game目的。
game.rewards— 游戏每回合收到的真实奖励列表game.history— 游戏每回合采取的行动列表game.child_visits— 在游戏的每一轮从根节点开始的行动概率分布列表game.root_values— 游戏每一轮根节点的值列表
这些列表很重要,因为它们最终将用于构建神经网络的训练数据!
这个过程继续进行,每回合从头开始创建一个新的 MCTS 树,并用它来选择一个动作,直到游戏结束。
所有游戏数据 ( rewards, history, child_visits, root_values) 都保存到replay buffer,然后actor可以自由地开始新游戏。
训练(train_network)
原始入口函数的最后一行启动了train_network使用Replay Buffer中的数据持续训练神经网络的过程。
def train_network(config: MuZeroConfig, storage: SharedStorage,
replay_buffer: ReplayBuffer):
network = Network()
learning_rate = config.lr_init * config.lr_decay_rate**(
tf.train.get_global_step() / config.lr_decay_steps)
optimizer = tf.train.MomentumOptimizer(learning_rate, config.momentum)
for i in range(config.training_steps):
if i % config.checkpoint_interval == 0:
storage.save_network(i, network)
batch = replay_buffer.sample_batch(config.num_unroll_steps, config.td_steps)
update_weights(optimizer, network, batch, config.weight_decay)
storage.save_network(config.training_steps, network)它首先创建一个新的Network对象(存储 MuZero 的三个神经网络的随机初始化实例)并根据已完成的训练步骤数设置学习率衰减。我们还创建了梯度下降优化器,它将计算每个训练步骤中权重更新的幅度和方向。
该函数的最后一部分只是循环training_steps(在论文中为 1,000,000,对于国际象棋)。在每一步,它都会从Replay Buffer中采样一批数据,并使用它们来更新网络,并且每隔checkpoint_interval(=1000)将其保存到存储中。
因此,我们需要讨论两个最后的部分——MuZero 如何创建一批训练数据,以及它如何使用它来更新三个神经网络的权重。
创建训练批次 (replay_buffer.sample_batch)
ReplayBuffer 类包含一个sample_batch从Replay Buffer中抽取一批观察值的方法:
class ReplayBuffer(object):
def __init__(self, config: MuZeroConfig):
self.window_size = config.window_size
self.batch_size = config.batch_size
self.buffer = []
def sample_batch(self, num_unroll_steps: int, td_steps: int):
games = [self.sample_game() for _ in range(self.batch_size)]
game_pos = [(g, self.sample_position(g)) for g in games]
return [(g.make_image(i), g.history[i:i + num_unroll_steps],
g.make_target(i, num_unroll_steps, td_steps, g.to_play()))
for (g, i) in game_pos]
...国际象棋的 MuZero默认batch_size为 2048。此局数是从Replay Buffer中选择的,并从每个局中选择一个位置。
单个batch是元组列表,其中每个元组由三个元素组成:
g.make_image(i)— 所选位置的观察g.history[i:i + num_unroll_steps]— 所选位置之后采取的下一步num_unroll_steps行动的列表(如果存在)g.make_target(i, num_unroll_steps, td_steps, g.to_play()— 将用于训练神经网络的目标列表。具体来说,这是一个元组列表:target_value,target_reward和target_policy。
下面显示了示例批处理的图表,其中num_unroll_steps= 5(MuZero 使用的默认值):
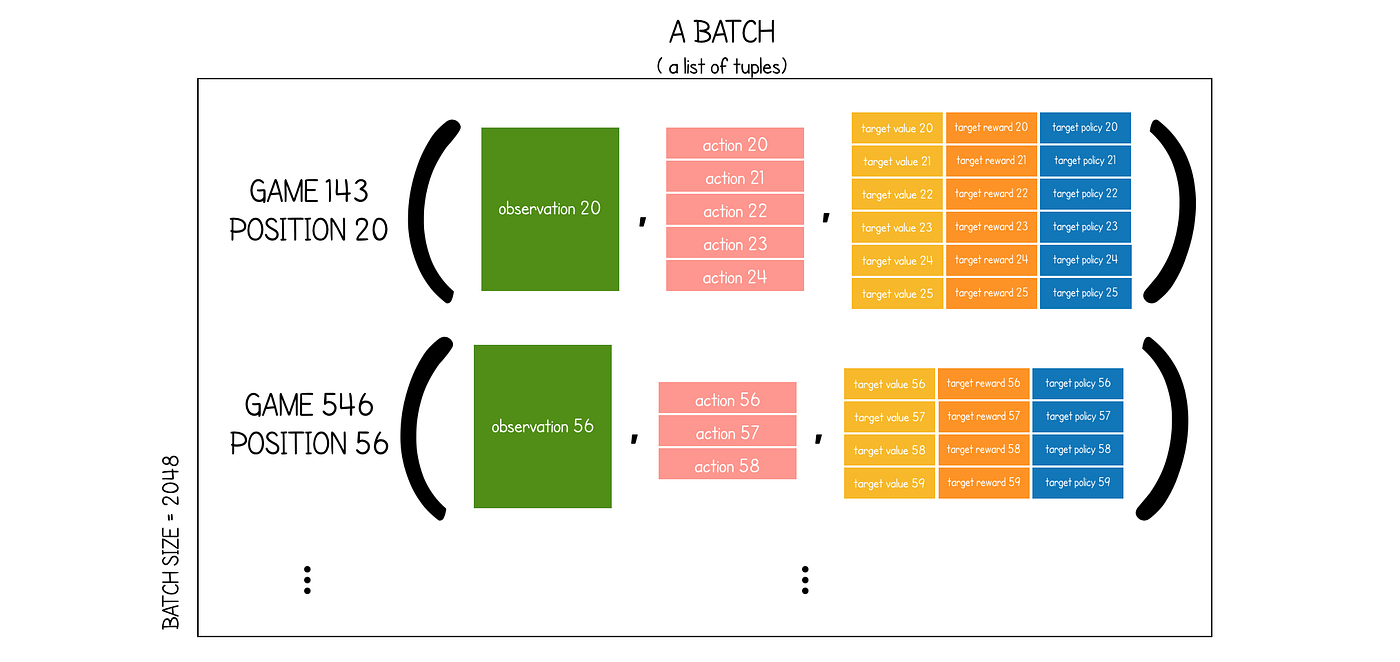
您可能想知道为什么每次观察都需要多个未来动作。原因是我们需要训练我们的动态网络,而唯一的方法是训练小的顺序数据流。
对于批处理中的每个观察,we will be ‘unrolling’ the position num_unroll_steps into the future using the actions provided。对于初始位置,我们将使用该initial_inference函数来预测价值、奖励和策略,并将这些与目标价值、目标奖励和目标策略进行比较。对于后续动作,我们将使用该recurrent_inference`函数来预测价值、奖励和策略,并与目标价值、目标奖励和目标策略进行比较。这样,所有三个网络都用于预测过程,因此所有三个网络中的权重都将更新。
现在让我们更详细地了解如何计算目标。
class Game(object):
"""A single episode of interaction with the environment."""
def __init__(self, action_space_size: int, discount: float):
self.environment = Environment() # Game specific environment.
self.history = []
self.rewards = []
self.child_visits = []
self.root_values = []
self.action_space_size = action_space_size
self.discount = discount
def make_target(self, state_index: int, num_unroll_steps: int, td_steps: int,
to_play: Player):
# The value target is the discounted root value of the search tree N steps
# into the future, plus the discounted sum of all rewards until then.
targets = []
for current_index in range(state_index, state_index + num_unroll_steps + 1):
bootstrap_index = current_index + td_steps
if bootstrap_index < len(self.root_values):
value = self.root_values[bootstrap_index] * self.discount**td_steps
else:
value = 0
for i, reward in enumerate(self.rewards[current_index:bootstrap_index]):
value += reward * self.discount**i # pytype: disable=unsupported-operands
if current_index < len(self.root_values):
targets.append((value, self.rewards[current_index],
self.child_visits[current_index]))
else:
# States past the end of games are treated as absorbing states.
targets.append((0, 0, []))
return targets
...
view rawpseudocode.py hosted with ❤ by GitHub该函数使用 TD-learning 的思想来计算位置从到make_target的每个状态的目标值。变量state_index state_index + num_unroll_steps``current_index.
TD-learning 是强化学习中常用的技术——其思想是我们可以使用一个位置的估计折扣值更新状态值td_steps到不久的将来加上到那时为止的折扣奖励,而不是仅仅使用情节结束时累积的总折扣奖励。
当我们根据估计值更新估计值时,我们说我们在自举。是未来头寸的bootstrap_index指数td_steps,我们将使用它来估计真实的未来回报。
该函数首先检查是否bootstrap_index在剧集结束之后。如果是,value则设置为 0,否则value设置为位置的折扣预测值bootstrap_index。
current_index然后,将和之间累积的折扣奖励bootstrap_index添加到value。
最后,有一个检查以确保current_index不是在剧集结束之后。如果是,则附加空目标值。否则,将计算出的 TD 目标值、来自 MCTS 的真实奖励和策略附加到目标列表中。
对于国际象棋,td_steps实际上设置为max_moves总是bootstrap_index在剧集结束后落下。在这种情况下,我们实际上是在使用蒙特卡洛估计目标值(即所有未来奖励的贴现总和到 episode 结束)。这是因为国际象棋的奖励只在剧集结束时颁发。TD-Learning和Monte Carlo估计的区别如下图所示:
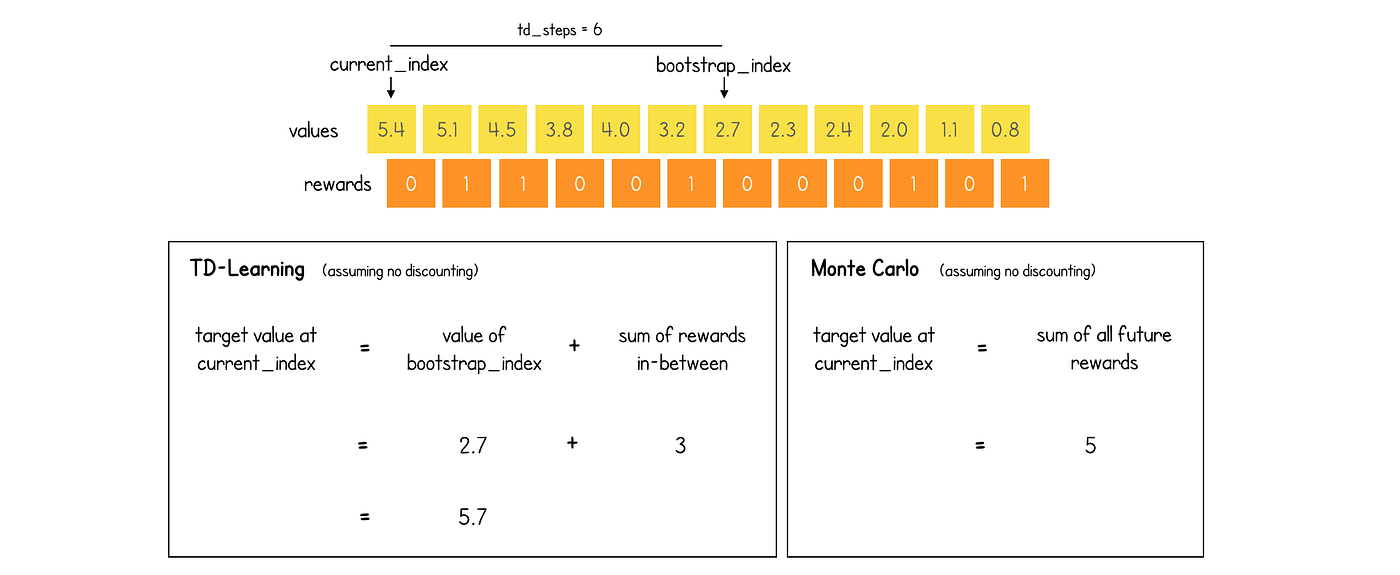
TD-Learning方法和Monte Carlo方法在目标值设定上的区别
现在我们已经了解了目标是如何构建的,我们可以了解它们如何适应 MuZero 损失函数,最后,了解它们如何在update_weights函数中用于训练网络。
MuZero 损失函数
Muzero 的损失函数如下:
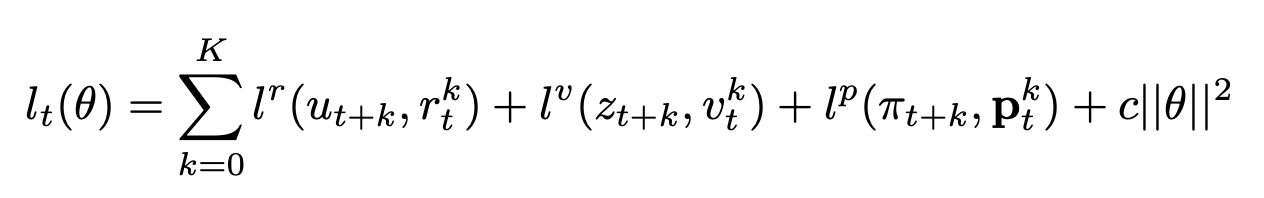
这里,K是num_unroll_steps变量。换句话说,我们正在努力减少三种损失:
- 提前预测的奖励 步骤与实际奖励之间的差异
- 提前预测值
k步数t(v)与TD目标值的差值 - 提前预测的策略 步骤与 MCTS 策略之间的差异
这些损失在推出过程中相加,以生成批次中给定位置的损失。还有一个正则化项来惩罚网络中的大权重。
更新三个 MuZero 网络(update_weights)
def update_weights(optimizer: tf.train.Optimizer, network: Network, batch,
weight_decay: float):
loss = 0
for image, actions, targets in batch:
# Initial step, from the real observation.
value, reward, policy_logits, hidden_state = network.initial_inference(
image)
predictions = [(1.0, value, reward, policy_logits)]
# Recurrent steps, from action and previous hidden state.
for action in actions:
value, reward, policy_logits, hidden_state = network.recurrent_inference(
hidden_state, action)
predictions.append((1.0 / len(actions), value, reward, policy_logits))
hidden_state = tf.scale_gradient(hidden_state, 0.5)
for prediction, target in zip(predictions, targets):
gradient_scale, value, reward, policy_logits = prediction
target_value, target_reward, target_policy = target
l = (
scalar_loss(value, target_value) +
scalar_loss(reward, target_reward) +
tf.nn.softmax_cross_entropy_with_logits(
logits=policy_logits, labels=target_policy))
loss += tf.scale_gradient(l, gradient_scale)
for weights in network.get_weights():
loss += weight_decay * tf.nn.l2_loss(weights)
optimizer.minimize(loss)
view rawpseudocode.py hosted with ❤ by GitHub该update_weights函数为批次中的 2048 个位置中的每一个逐个构建损失。
首先,初始观察通过initial_inference网络进行预测value,reward并policy从当前位置开始。这些用于创建predictions列表,以及给定的权重 1.0。
然后,依次循环每个动作,并recurrent_inference要求函数预测下一个value和reward当前policy的hidden_state。这些附加到predictions列表的权重为1/num_rollout_steps(以便函数的总权重recurrent_inference等于函数的权重initial_inference)。
然后,我们计算将predictions与其对应的目标值进行比较的损失——这是scalar_loss和reward的value组合softmax_crossentropy_loss_with_logits。policy
优化然后使用此损失函数同时训练所有三个 MuZero 网络。
所以……这就是您使用 Python 训练 MuZero 的方式。
总结
总之,AlphaZero 天生就知道三件事:
- 当它做出给定的动作时,棋盘会发生什么。例如,如果它执行“将棋子从 e2 移动到 e4”的操作,它知道下一个棋盘位置是相同的,只是棋子已经移动了。
- 给定位置的合法移动是什么。例如,AlphaZero 知道如果您的皇后不在棋盘上、有棋子阻挡移动或者您在 c3 上已有棋子,则您不能将“皇后移至 c3”。
- 比赛结束时,谁赢了。例如,它知道如果对手的王处于被控制状态并且不能脱离被控制状态,它就赢了。
换句话说,AlphaZero 可以想象可能的未来,因为它知道游戏规则。
在整个训练过程中,MuZero 无法访问这些基本游戏机制。值得注意的是,通过添加几个额外的神经网络,它能够应对不知道规则的情况。
令人难以置信的是,MuZero 实际上改进了 AlphaZero 在围棋中的表现。这可能表明它正在寻找比 AlphaZero 在使用实际棋盘位置时找到的更有效的方法来通过其隐藏表示来表示位置。
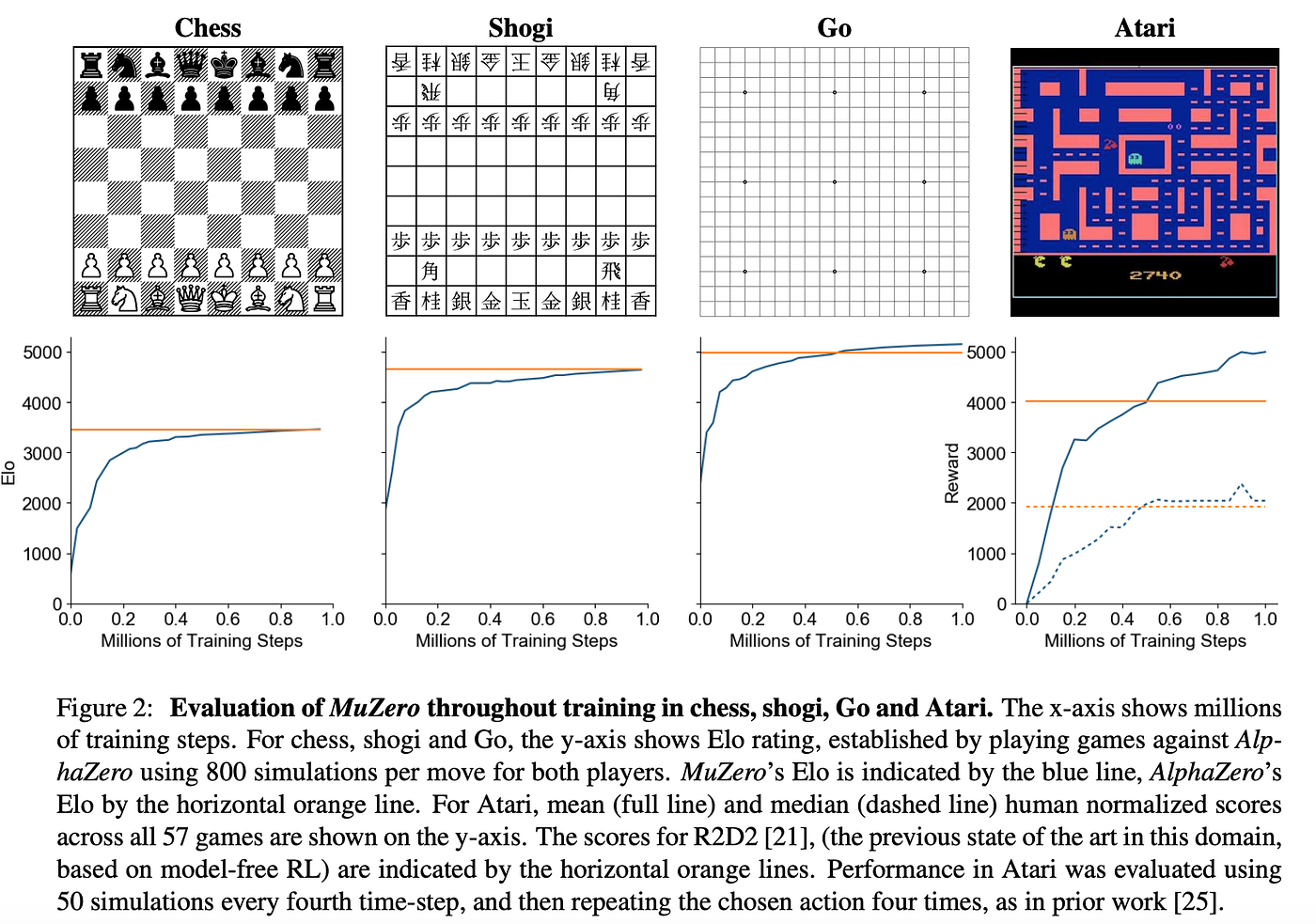
MuZero 在国际象棋、将棋、围棋和 Atari 游戏中的表现总结。
最后,我想简要总结一下为什么我认为这种发展对 AI 非常重要。
Why this is a kind of a big deal
AlphaZero 已经被认为是迄今为止 AI 最伟大的成就之一,它在一系列游戏中实现了超人的实力,而无需人类专业知识作为输入。
从表面上看,花费如此多的额外努力来证明算法不会因拒绝访问规则而受到阻碍,这似乎很奇怪。这有点像成为国际象棋世界冠军,然后闭着眼睛参加所有未来的比赛。这只是聚会的把戏吗?
答案是,这从来都不是关于 DeepMind 的围棋、国际象棋或任何其他棋盘游戏。这是关于智能本身。
当您学习游泳时,您并没有首先获得流体动力学的规则手册。当您学习用积木建造塔楼时,您并没有准备好牛顿万有引力定律。当你学会说话时,你是在不懂任何语法的情况下学习的,即使在今天,你可能仍然很难向非母语人士解释语言的所有规则和怪癖。
关键是,生活在没有规则手册的情况下学习。
这是如何运作的仍然是宇宙最大的秘密之一。这就是为什么我们继续探索不需要直接了解环境力学来提前计划的强化学习方法如此重要的原因。
MuZero 论文和同样令人印象深刻的WorldModels论文(Ha,Schmidhuber)之间存在相似之处。两者都创建仅存在于智能体内部的环境内部表示,并用于想象可能的未来以训练模型以实现目标。两篇论文实现这一目标的方式不同,但有一些相似之处:
- MuZero 使用表示网络嵌入当前观察,WorldModels 使用变分自动编码器。
- MuZero 使用动态网络对想象环境建模,WorldModel 使用循环神经网络。
- MuZero 使用 MCTS 和预测网络来选择动作,World Models 使用进化过程来进化最佳动作控制器。
当两个以自己的方式开创性的想法实现相似的目标时,这通常是一个好兆头。这通常意味着双方都发现了一些更深层次的潜在真相——也许这两把铲子只是击中了宝箱的不同部分。
我们的实现
这个存储库基于MuZero 伪代码。我们努力使代码井井有条,并进行了很好的注释,以便于理解 MuZero 的工作原理。该代码异步工作(并行/多线程)。我们添加了一个具有完全连接网络 (MLP) 的版本和一些工具,例如用于理解模型的可视化工具 ( diagnostic_model ) 和超参数搜索工具。其他功能请参考readme。
结构
有四个组件是在专用线程中同时运行的类。保存最新的shared storage神经网络权重,self-play使用这些权重生成自玩游戏并将它们存储在replay buffer. 最后,那些玩过的游戏被用于train网络并将权重存储在共享存储中。这些组件从 MuZero 类启动和管理,muzero.py神经网络的结在models.py.

Here is the diagram of the muzero network applied to the Atari game: 
延伸阅读
要了解技术部分,我们推荐以下文章。