优先经验回放及其实现
DQN 均匀随机采样
在 Deep Q-Network 中,引入了经验回放机制,在经验记忆 (replay memory) 中均匀地选取的经验transition (replay transition) ,但是这种简单等概率的选取经验transition的方法忽视了每条transition的重要程度。并且存储数据的空间有限,当空间存满之后,每次放入一个experience就要丢弃先前的一个experience。那么就要思考下面两个问题:
- 一是选择存储哪些经验 transition
- 二是选择回放哪些经验 transition
Prioritized Experience Replay(优先经验回放)
所以在论文 Prioritized Experience Replay 中,提出了一种优先经验的方法,将一些比较重要的经验transition回放的频率高一点,从而使得学习更有效率。
Prioritizing with TD-error
引入TD-Error:引入TD-Error的目的是给每一个experience添加一个TD-Error标准,在每次进行更新时,从buffer中选择绝对值对大的TD-Error的样例进行回放。然后对该样例进行Q-learning的更新,更新Q值和TD-Error的权重。新的experience到来之后,没有已知的 TD-error,所以我们将其放到最大优先级的行列,确保所有的 experience 至少回放一次。
Stochastic Prioritization(随机优先)
使用贪婪法通过比较TD-error的大小来优先选取经验 transition 有许多问题:
- 了避免消耗太多资源遍历整个memory,我们只为那些被replay的experience更新TD-error, 如果一开始就被赋予一个很低的TD-error的transition可能在很长的一段时间内不能被选取到。
- 对于噪声也非常的敏感,会因为强化学习算法的自举而加剧这种情况出现,同时函数近似的误差也会成为另一种噪声,贪婪法优先关注经验记忆中的一部分transition,导致误差收敛得很慢。缺乏多样性使得该系统倾向于 over-fitting。
所以为了解决这些问题。引入了一种随机采样的方法介于贪婪选取与均匀选取两者之间,使得经验transition被选取到的概率随着优先级的递增而单调递增,但同时也保证对于低优先级的transition不至于零概率被选中。具体来说,定义了选取某个transitioni的概率为
$$ P(i)=\frac{p_{i}^{o} }{\sum_{k}p_{k}^{o} } $$
其中 $p_{i}>0$ 代表某个transition的优先级,指数 $\alpha$ 决定了这个优先级使用多少,如果 $\alpha=0$ 那么就相当于均分采样。
对于优先级:
第一种设置优先级的方法是 $p_{i}=|\delta_{i}|+\epsilon$,其中 $\epsilon$ 是一个小的正常量来防止TD-error变为0之后就不再被访问。
第二种设置方法是 $p_{i}=\frac{1}{rank(i)}$,其中 rank $|i|$ 就是根据 $|\delta_{i}|$ 进行排序的排位。
两种方法都是根据 $|\delta_{i}|$ 单调的,但后一种方法更加稳定。因为其对离群点不敏感。两个变体相对均匀的baseline来讲都是有很大优势
在实际实现过程中,可以将所有的排名分为batch_size个区间,在每个区间内进行均匀采样。我们可以使用sum-tree这种数据结构,这样在插入、更新一个transition 时,整体数据结构不需要排序,只要 $O(1)$,而在采样时,只需要 $O(\log N)$。
Prioritized DQN能够成功的主要原因有两个:
- Sum tree这种数据结构带来的采样的O(log n)的高效率
- Weighted Importance sampling的正确估计
Proportional Variant
由于使用贪婪法来选取优先经验的时间复杂度太高,同时还有其他问题,所以我们用 $P(i) =p_i^\alpha / \sum_kp_k^\alpha $ 来定义某个transition的选取概率,其中 $p_i$ 我们将它等同于 TD-error $|\delta_i| $ ,并用 Sum Tree 这种数据结构来表示每个存储的transition。
SumTree
Sum Tree (求和树) 是一种特殊的二叉树类型的数据结构,其中父节点的值等于其子节点的值之和。 如下图所示,根节点的值是所有叶子的值的和:13 = 3+10,42 = 29+13,依此类推…
Sum Tree 中所有叶子节点存储优先级 $p_i$ ,每个树枝节点只有两个分叉, 节点的值是两个分叉的和, 所以 SumTree 的顶端就是所有 p 的和,所以这棵树的根节点即为所有叶子节点的和,如下图所示:
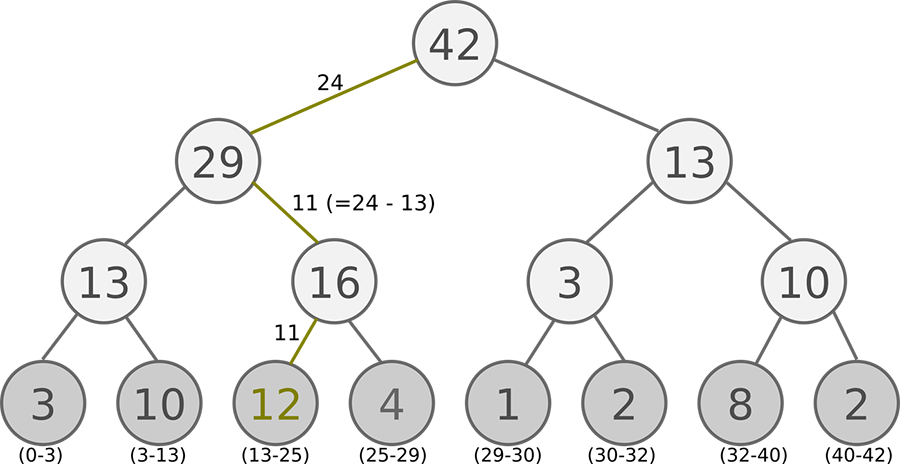
在抽样时,我们将存储的优先级的总和 root priority 除以 batch size ,分成 batch size 个区间(n=sum(p)/batch_size)。 如图中的例子,将所有 node 的 priority 加起来是42, 如果 batch size = 6 ,那么分成: [0-7], [7-14], [14-21], [21-28], [28-35], [35-42] 六个区间,再分别在六个区间中均匀地随机选择一个数,从根节点依次往下搜索。
比如在第4区间 [21-28] 里选到了24, 就按照这个 24 从最顶上的42开始向下搜索. 首先看到最顶上 42 下面有两个 child nodes, 拿着手中的24对比左边的 child 29, 如果 左边的 child 比自己手中的值大, 那我们就走左边这条路, 接着再对比 29 下面的左边那个点 13, 这时, 手中的 24 比 13 大, 那我们就走右边的路, 并且将手中的值根据 13 修改一下, 变成 24-13 = 11. 接着拿着 11 和 13左下角的 12 比, 结果 12 比 11 大, 因为 12 已经是叶子节点,则搜索完毕, 那我们就选 12 当做这次选到的优先级, 并且也选择 12 对应的数据.
图中叶子节点下面括号中的区间代表该优先级可以被搜索到的范围,由此可见优先级大的被搜索到的概率越高,同时优先级小的,也有一定概率被选中。
代码实现
我们用顺序存储来实现这个二叉树,为了方便,我们规定 sum tree 必须是满二叉树:
SumTree 有效抽样
class SumTree:
def __init__(self, capacity):
# sum tree 能存储的最多优先级个数
self.capacity = capacity
# 顺序表存储二叉树
self.tree = [0] * (2 * capacity - 1)
# 每个优先级所对应的经验transition
self.data = [None] * capacity
self.size = 0
self.curr_point = 0
# 添加一个节点数据,默认优先级为当前的最大优先级+1
def add(self, data):
self.data[self.curr_point] = data
self.update(self.curr_point, max(self.tree[self.capacity - 1:self.capacity + self.size]) + 1)
self.curr_point += 1
if self.curr_point >= self.capacity:
self.curr_point = 0
if self.size < self.capacity:
self.size += 1
# 更新一个节点的优先级权重
def update(self, point, weight):
idx = point + self.capacity - 1
change = weight - self.tree[idx]
self.tree[idx] = weight
parent = (idx - 1) // 2
while parent >= 0:
self.tree[parent] += change
parent = (parent - 1) // 2
def get_total(self):
# 获取所有叶子节点之和
return self.tree[0]
# 获取最小的优先级,在计算重要性比率中使用
def get_min(self):
return min(self.tree[self.capacity - 1:self.capacity + self.size - 1])
# 根据一个权重进行抽样
def sample(self, v):
idx = 0
while idx < self.capacity - 1:
l_idx = idx * 2 + 1
r_idx = l_idx + 1
if self.tree[l_idx] >= v:
idx = l_idx
else:
idx = r_idx
v = v - self.tree[l_idx]
point = idx - (self.capacity - 1)
# 返回抽样得到的 位置,transition信息,该样本的概率
return point, self.data[point], self.tree[idx] / self.get_total()Memory (Prioritized的ReplayBuffer,DQN不采用)
class Memory(object):
def __init__(self, batch_size, max_size, beta):
self.batch_size = batch_size # mini batch大小
self.max_size = 2**math.floor(math.log2(max_size)) # 保证 sum tree 为完全二叉树
self.beta = beta
self._sum_tree = SumTree(max_size)
def store_transition(self, s, a, r, s_, done):
self._sum_tree.add((s, a, r, s_, done))
def get_mini_batches(self):
n_sample = self.batch_size if self._sum_tree.size >= self.batch_size else self._sum_tree.size
total = self._sum_tree.get_total()
# 生成 n_sample 个区间
step = total // n_sample
points_transitions_probs = []
# 在每个区间中均匀随机取一个数,并去 sum tree 中采样
for i in range(n_sample):
v = np.random.uniform(i * step, (i + 1) * step - 1)
t = self._sum_tree.sample(v)
points_transitions_probs.append(t)
points, transitions, probs = zip(*points_transitions_probs)
# 计算重要性比率
max_impmortance_ratio = (n_sample * self._sum_tree.get_min())**-self.beta
importance_ratio = [(n_sample * probs[i])**-self.beta / max_impmortance_ratio
for i in range(len(probs))]
return points, tuple(np.array(e) for e in zip(*transitions)), importance_ratio
# 训练完抽取的samples后,要更新tree中的sample的TD-Error
def update(self, points, td_error):
for i in range(len(points)):
self._sum_tree.update(points[i], td_error[i])Rank-based Variant
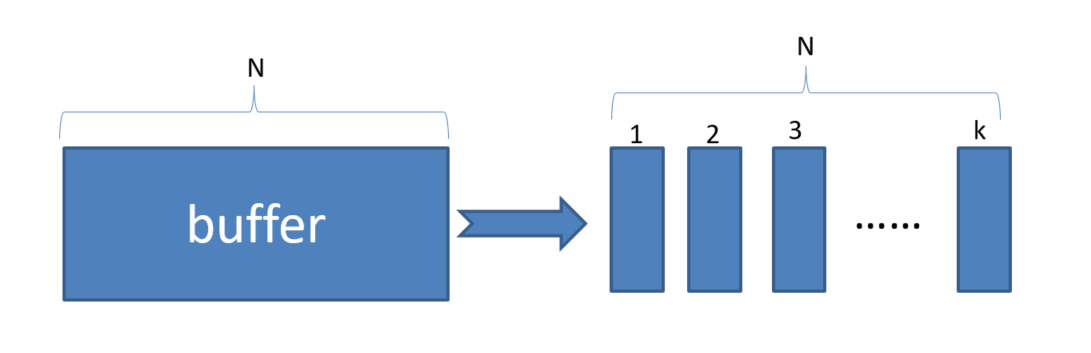
将buffer分为k个等概率的分段,从每一个分段中进行贪婪优先采样
Annealing the bias (消除偏差)
利用随机更新得来的期望值的预测依赖于这些更新,对应其期望的同样的分布。优先回放引入了误差,因为它以一种不受控的形式改变了分布,从而改变了预测会收敛到的 solution(即使 policy 和 状态分布都固定)。我们可以用下面的重要性采样权重(importance-sample weights)来修正该误差。
Importance samplingn(重要性采样)
重要性采样是统计学中估计某一分布性质时使用的一种方法。该方法从与原分布不同的另一个分布中采样,而对原先分布的性质进行估计。数学表示为: $$ E_{X\sim A}[f(X)]=E_{X\sim B}\left[\frac{P_{A}(X)}{P_{B}(X)}f(X)\right] $$ 其中 $P_{A}(X)=\frac{1}{N}$也就是均匀采样,N为整个记忆库的大小,$P_{B}(X)=P(i)$,则重要性权重为:
$$ w_i=\left(\frac{1}{N}\cdot\frac{1}{P(i)}\right)^{\theta} $$ 着 $\beta=1$则可以完全补偿非均匀分布所带来的偏差。为了稳定性方面的考虑,我们规格化重要性权重:
$$ w_j=\frac{(N\cdot P(j))^{-\beta} }{\max_i w_i} $$ 这些重要性权重可以应用到Q-learning的更新中,用 $w_{i}\delta_{i}$代替原先的 $\delta_{i}$。
Importance sampling 的影响:
在典型的强化学习场景中,更新的无偏性在训练结束接近收敛时是最重要的,因为由于策略、状态分布和引导目标的改变,有bias会高度不稳定,与未修正的优先重放相比,Importance sampling 使学习变得不那么具有侵略性,一方面导致了较慢的初始学习,另一方面又降低了过早收敛的风险,有时甚至是更好的最终结果。与uniform重放相比,修正的优先级排序平均表现更好。
PER 算法流程
将Prioritized Experience Replay 优先经验回放和 Double Q-learning 相结合,就是将均匀随机采样 替换为 本文提出的 随机优先和重要性采样方法,具体算法见下图:
