过程奖励模型(Process Reward Model)
过程监督 (Process Supervision)
思维链采用逐步推理的方式得到最终结果,如果模型在某一步出现幻想 (Hallucination),则差之毫厘,谬以千里,后面的错误会被放大,导致错误结果。
OpenAI最近提出使用过程监督 (Process Supervision) 减少大模型幻想并提升大模型的数学推理能力,所以什么是过程监督?
过程监督 (Process Supervision) 是相对于之前的结果监督 (Outcome Supervison) 而言。众所周知,大模型基于人工反馈的强化学习部分需要用到奖励模型 (Reward Model, RM),数学推理能力是基于思维链 (Chain of Thought)。传统的奖励模型采用的是结果监督的方式,仅使用思维链的最终结果进行判别与反馈,而过程监督则是对思维链的每步推理都进行反馈。因此,过程监督是针对思维链和奖励模型的一种改进方案。
过程监督的动机
过程监督可以精确地指出发生错误的位置并提供反馈。还有个优势是可解释的对齐 (Alignment),更容易训练出人类背书的模型。已有研究发现,在逻辑推理领域,使用结果监督的方式,存在“歪打正着”的现象,即模型会用一个错误推理得到正确的结果。显然这种情况可以通过过程监督的方式解决。
还有一点值得提到的是对齐税 (Alignment Tax),即对齐后的模型在下游任务上可能会有性能损失。从实验结果来看,过程监督不仅没有负面效应,反而对模型性能有促进作用 (至少在数学领域如此)。
数据采集
显然,过程监督最大的阻碍是没有数据。之前的数据集都缺少逐步标注对错的结果,因此设计了一个标注UI:
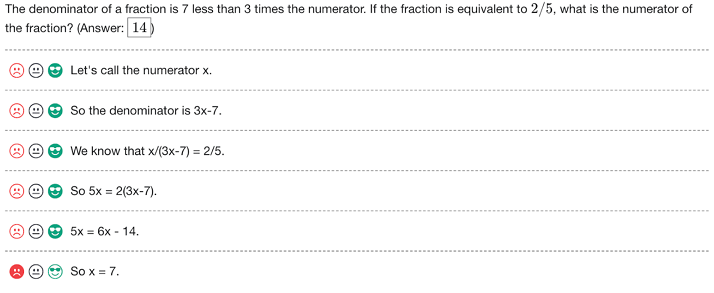
所有结果都由大规模generator生成,每步的标注结果分三类:positive, negative和neutral:
A positive label indicates that the step is correct and reasonable. A negative label indicates that the step is either incorrect or unreasonable. A neutral label indicates ambiguity. In practice, a step may be labelled neutral if it is subtly misleading, or if it is a poor suggestion that is technically still valid.
neutral标签的目的在于可在推理阶段灵活处理模糊结果,可正可负。
这个数据集叫做 PRM800K,包括 12K 个问题,75K 个解答和 800K 个步骤的标注。
采集策略
最简单的策略是随机选择generator生成的解答。但这么做的最大问题在于如果所选的解答有明显错误,那么人工标注的意义就不大了。因此,作者们倾向于选择一些更难的例子,也就是更容易骗过奖励模型的例子。这个策略在传统机器学习中也非常常见,比如分类问题,选择更难分类的数据从而让模型更加健壮。
具体来说,作者们倾向于选择“看起来对但最终答案错误”的解答 (convincing wrong-answer)。convincing表示目前最优的奖励模型 (Process-supervised Reward Model, PRM) 对其打分较高,wrong-answer代表它的最终答案错误。期待用这样的策略可以获取更多的信息:保证当前的PRM至少有一处对该解答判断有误。
此外,PRM还在数据采集的过程中不断迭代,对每个问题都生成N个结果,选择PRM打分前K个进行标注。
结果奖励模型(ORM)
用如下方式对ORM进行训练:对每个问题,随机采样generator生成的固定数目的解答,并训练 ORM 预测每个解答是否正确。实践中的判断可以自动完成,用最后一个token评判对错。推理时,用 ORM 对最后一个token的预测作为总得分。
但这种自动评价方式有一些瑕疵:步骤出错但结果正确的解答可能会被误判。
过程奖励模型(PRM)
过程奖励模型PRM(Process Reward Model)可以对推理过程中的每个推理步骤进行评分,逐步评估推理路径,识别可能出现的任何错误的特定位置来提供精确的反馈,这是强化学习和自动校正中有价值的信号。
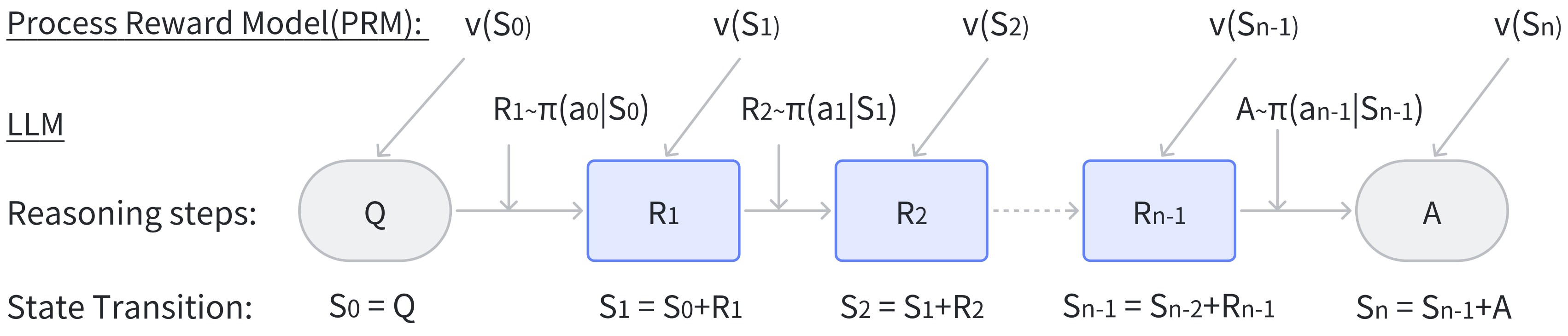
过程奖励模型原理
ORM 目标函数
对于 ORM,给定一个数学问题 q 和其解 s ,ORM( Q×S→ℝ )为 s 分配一个单一实数值,已表明 s 是否正确。ORM 通常使用交叉熵损失进行训练: $$ {\mathcal L}{ORM} = y log r_{s} + (1-y_{s})log(1-r_{s}) $$ 中 ys是标签,表示 s 是否正确,rs是 ORM 模型分配给 s 的 sigmoid 分数。
PRM 目标函数
过程奖励模型的核心思想是通过步骤级别的标注数据集,训练过程奖励模型来预测解决方案中每个中间步骤的正确性,基本原理如下: $$ r_{s_i}=PRM([q,s_{1:i-1}], s_i) $$ 其中 $s_{1:i}=[s_1,...,s_i]$ 表解决方案 $s$ 中的第 $s_i$ 个步骤,这提供了比 ORM 更精确和更细粒度的反馈,因为它识别了错误的确切位置。
给定一个数学问题 $q$ 和对应的解决方案 $s$,PRM为 $s$ 的每个推理步骤 $s_i$ 分配一个分数,通常使用以下方式进行训练:
$$ {\mathcal L}{PRM} = \sum\limits\limits^{K} y_{s_i} log r_{s_i} + (1-y_{s_i})log(1-r_{s_i}) $$
其中 $y_{s_i}$ 是步骤 $s_{i}$ 的标签,表示步骤 $s_{i}$ 是否正确;$r_{s_{i} }$ 是PRM为步骤 $s_{i}$ 的分配的sigmoid分数,$K$ 表示 $s$ 包含的推理步骤数。
PRM 的训练
PRM 的训练有更多细节:训练PRM对每一步推理的最后一个token进行评判。让PRM对整个解答的每一步都进行预测,下图中是PRM对同一问题的两个不同解答的打分可视化,绿色代表PRM打出高分,红色代表低分(有错):

为了对不同解答进行比较,需要对每个解答统一打分,做法是将每步的正确概率相乘。
训练PRM时,遇到每一个出错步时就停止。这么做的目的是让过程监督和结果监督的方案更可比:对于正确解答,两种方案对模型提供了同样的信息,每步都是正确的;对错误解答,两种方案都犯了至少一个错误,但过程监督额外提供了错误发生的位置信息。
总结
奖励模型在RLHF过程中扮演举足轻重的作用,它的好坏直接影响模型的最终性能。
参考文献
[3]Let’s Verify Step by Step: a good introduction to PRMs.
[4]Solving math word problems with process- and outcome-based feedback: the canonical citation in all PRM and reasoning works in 2023.
[5]Scaling Relationship on Learning Mathematical Reasoning with Large Language Models: A paper that studies the method of rejection sampling for reasoning problems, among other contributions.
[6]Let's reward step by step: Step-Level reward model as the Navigators for Reasoning