Slime 框架深度解析
Github: https://github.com/THUDM/slime
1. 引言: Slime 框架设计原则
无论 RL 算法如何演进,其最终落地仍依赖于算法与系统的深度协同。而规模化(Scale)能力则是 RL 应用价值的关键所在。本文将围绕Slime 框架展开分析,旨在从系统设计角度出发,梳理 Slime 的核心架构与实现机制,为后续 RL 算法迭代与系统协同设计提供参考依据。
1.1 如何构建持续高性能的训练框架
为了实现强化学习(Reinforcement Learning, RL)训练的高效与可持续优化,训练框架不仅需要具备当前最优的性能表现,还需具备长期维持高性能的能力。这两个目标分别对应着“快速”与“持续快速”的设计原则。
1.1.1 实现训练与推理的极致性能
RL 训练通常包含两个核心阶段:训练(Training)与推理(Inference)。为实现极致性能,Slime 选择集成当前主流的高性能训练框架 Megatron 与推理框架 SGLang,充分利用两者在模型并行与推理优化方面的优势:
- Megatron 支持多种并行策略:包括张量并行(TP)、流水线并行(PP)、专家并行(EP)、上下文并行(CP)等,适用于 Dense 与 MoE 模型的大规模训练。
- SGLang 提供多项优化技术:如张量并行、专家并行注意力(DP Attention)、DeepEP、FP8 推理等,显著提升推理效率。
通过深度集成 Megatron 与 SGLang,Slime 实现了对大规模语言模型的高效训练与推理流程支持。
1.1.2. 保持框架性能的可持续性
要确保训练框架能够持续保持高性能,需从两个维度进行设计:
(1)与训推框架同步演进
训练与推理框架本身处于持续演进之中,Slime 必须具备良好的兼容性与扩展性,以支持其不断更新与优化。为此,我们采取了以下策略:
- 参数透传机制:通过解析 Megatron 的
parse_args接口与 SGLang 的ServerArgs.add_cli_args方法,将所有训推框架的配置参数透明传递至 Slime。其中,SGLang 参数统一添加--sglang前缀以避免命名冲突。该机制确保 Slime 无需频繁修改自身代码即可适配训推框架的版本升级。 - 支持自定义参数扩展:提供类似 Megatron 的
extra_args_provider接口,允许用户灵活扩展自定义配置参数。
(2)开源协作机制
为了更有效地适配训推框架的演进方向,Slime 采用开源策略,鼓励社区参与与共建。SGLang 社区以其活跃度与开放性著称,Slime 与之保持紧密协作,推动框架设计更贴合双方需求。同时,开源也有助于吸引更多开发者参与优化与改进,形成良性生态。
1.1.3. 支持多样化的训练模式
强化学习领域发展迅速,训练策略不断演进。Slime 通过支持多种训练模式,增强框架的适应性与前瞻性:
- 支持 训推一体 与 训推分离 模式;
- 支持 同步 与 异步 数据生成;
- 可灵活切换 训练、评估、拒绝采样 等流程。
这种设计使 Slime 能够快速响应新的训练范式,为研究者提供多样化的实验平台。
1.2 支持多领域、多场景的数据生成能力
强化学习的应用场景日益丰富,涵盖数学、编程、多轮对话、工具调用、Agent 系统等多个方向。Slime 通过灵活的数据生成机制,支持各种复杂场景的高效实现。
1.2.1. 自定义数据生成模块
Slime 提供高度可定制的数据生成接口,通过 --rollout-function-path 参数指定用户自定义的 rollout 生成逻辑,实现与 SGLang 的自由交互。框架内部仅提供示例实现 sglang_example.py,用于展示异步生成与动态采样等基本功能。
此外,Slime 支持以下扩展能力:
- 替换数据生成主逻辑;
- 保留默认生成逻辑但替换部分模块;
- 利用 Data Buffer 实现跨 rollout 的数据缓存与复用,例如 partial rollout。
这种模块化设计降低了不同领域用户对框架的维护成本,提升了可复用性与可扩展性。
1.2.2. 基于 Server 的推理引擎与路由机制
Slime 采用基于 Server 的推理引擎架构,并通过 SGLang Router 管理多个推理实例。用户在实现数据生成逻辑时,只需向统一的 OpenAI 兼容接口发起请求,无需学习特定的推理引擎使用方式。
该设计具有以下优势:
- 简化用户使用成本;
- 支持外部 Agent 系统直接接入 Slime 的推理服务;
- 提升系统解耦性与灵活性。
1.3. 保障训练过程的正确性
在追求性能与灵活性的同时,Slime 也高度重视训练过程的正确性与可调试性,具体体现在以下几个方面:
- KL 散度初始化校验:在 RL 训练的第一步,确保 KL 散度为 0,验证策略更新的合理性;
- 模块化调试支持:支持单独加载 Megatron 或 SGLang,便于隔离调试与性能调优;
- 数据持久化能力:支持 rollout 数据的保存与加载,便于复现训练过程中的随机性问题;
- 内部验证与经验总结:在智谱内部进行了大量训练实践,积累了丰富的调试与优化经验,并整理为 Q&A 文档供用户参考。
1.4. 不止于 RL 框架:统一的后训练框架架构
在解决了上述问题后,Slime 展现出超越传统 RL 框架的能力,成为一个统一的 LLM 后训练框架。通过灵活的资源调度与数据生成机制,Slime 可以支持多种训练任务:
- SFT(Supervised Fine-Tuning):仅启动 Megatron,从已有数据文件中加载数据;
- Reject Sampling:启动 Megatron 与 SGLang,由 SGLang 生成数据但不更新参数;
- Evaluation:仅启动 SGLang,上报评估指标。
这些功能均基于 Slime 的统一架构实现,复用同一套流程与接口,展现出其在架构设计上的优越性。
2. 框架整体设计
Slime 是一个面向大规模 RL 训练的系统框架,采用 Ray 作为统一的调度器,Megatron-LM 作为训练后端,SGLang 作为推理后端。该框架支持资源训推一体化部署与分离部署两种模式,具备良好的可扩展性与灵活性。
其设计目标明确:降低训练与推理之间的数据传输开销,同时尽可能贴近真实生产环境中的组件结构,以支持高效的大规模 RL 训练。从实际部署效果来看,Slime 成功实现了上述目标,具备良好的工程实践价值。

2.1 数据流视角:Buffer 的作用
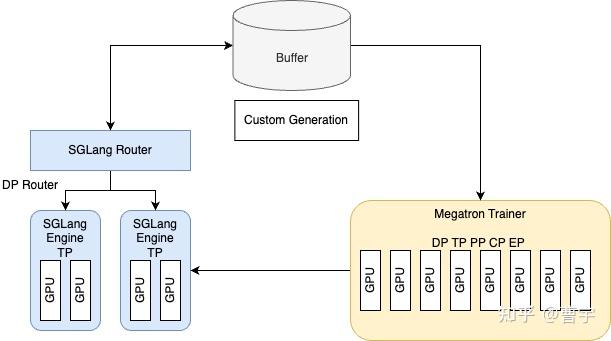
从数据流的角度来看,Slime 的核心模块之一是 Buffer,它以 Ray Actor 的形式实现。Buffer 不仅负责维护 rollout 数据集(即策略生成的样本数据),还支持用户自定义 generate_rollout 方法,从而实现灵活多样的 rollout 策略。
通过 Ray 的远程调用机制,训练模块与推理模块均可与 Buffer 进行高效的双向数据交互,确保系统各组件之间的数据一致性与低延迟传输。
2.1.1 Rollout(推理 / 样本生成)
Rollout 阶段采用 SGLang 的 router 实现数据并行(Data Parallelism, DP)。Router 根据缓存感知(cache-aware)策略进行负载均衡,将推理请求合理分配至各个 SGLang Engine。
Rollout 模块直接持有 Buffer 的引用,能够双向控制 rollout 数据的生成与拉取,形成闭环的数据流管理机制。
2.1.2. Train(训练)
训练模块尽量复用 Megatron-LM 提供的原生训练器(Trainer),以支持复杂的并行策略。目前 Slime 支持 5D 并行策略(Tensor Parallelism, Pipeline Parallelism, Data Parallelism, Context Parallelism, Expert Parallelism),并在兼容 GPT 类模型的基础上,将并行逻辑尽可能交由 Megatron 原生组件处理,从而降低系统复杂度,提升训练稳定性与效率。
2.2 控制流程与资源调度
Slime 的整体控制流程如下图所示,具体细节将在后续章节中展开。
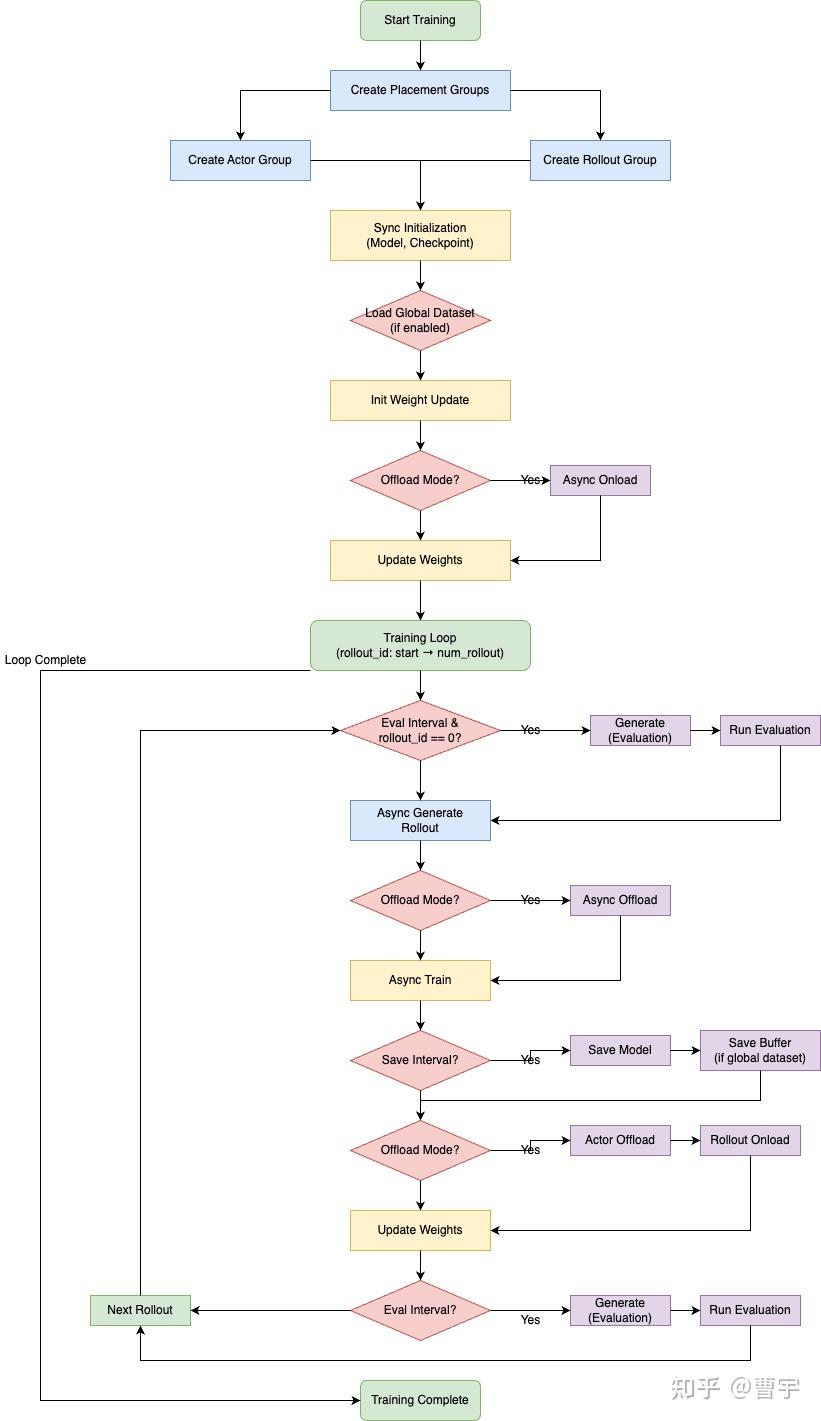
Placement Group 的资源调度机制
Slime 采用 Ray 作为资源调度框架,支持分离式(Separated)与集中式(Co-located)两种资源部署策略。该机制的核心在于 Ray 的 Placement Group(PG)调度模型,通过逻辑资源的划分实现对 GPU 的细粒度控制。
Placement Group 的配置
系统根据当前运行模式(train 或 debug)创建具名的 Placement Group:
- Co-located 模式:Rollout 与训练 Actor 共享同一个 PG,实现资源复用。
- Debug 模式:Actor 与 Rollout 可分别独占 PG,便于组件级调试。
这种设计允许用户在调试复杂 RL 系统时,隔离并单独运行某个模块(如 rollout),而无需启动整个系统,提升了调试效率与系统可控性。
GPU 资源的逻辑分配策略
Ray 通过 Placement Group 的调度机制实现对 GPU 的逻辑资源管理。虽然 Ray 本身不强制限制 GPU 的物理使用,但它通过“虚拟资源”的方式实现逻辑上的资源划分与调度。
例如,在训练阶段,每个训练 Actor 请求 0.8 个 GPU;而在推理阶段,每个 Rollout Engine 请求 0.2 个 GPU。调度器首先满足训练 Actor 的资源需求,在每张 GPU 上预留 0.2 的“空闲”逻辑资源。随后,Rollout Engine 可以精确地填充这些空闲资源,实现推理与训练的 co-location 部署。
这种机制不仅提高了资源利用率,也有效降低了跨节点通信的开销。
示例代码:Placement Group 的资源分配
以下代码片段展示了 Slime 中 Placement Group 的资源配置逻辑。
训练组资源配置
# slime/ray/placement_group.py
def allocate_train_group(num_nodes, num_gpus_per_node, pg, debug_rollout_only):
return RayTrainGroup(
num_nodes=num_nodes,
num_gpus_per_node=num_gpus_per_node,
pg=pg,
num_gpus_per_actor=0.8, # 每个训练 Actor 分配 0.8 个 GPU
debug_rollout_only=debug_rollout_only,
)Rollout 引擎资源配置
# slime/ray/rollout.py
for i in range(num_engines):
num_gpus = 0.2 # 每个 Rollout Engine 分配 0.2 个 GPU
num_cpus = num_gpus
scheduling_strategy = PlacementGroupSchedulingStrategy(
placement_group=pg,
placement_group_capture_child_tasks=True,
placement_group_bundle_index=reordered_bundle_indices[i * num_gpu_per_engine],
)
rollout_engines.append(
RolloutRayActor.options(
num_cpus=num_cpus,
num_gpus=num_gpus,
scheduling_strategy=scheduling_strategy,
).remote(
args,
rank=i,
data_buffer=data_buffer,
)
)在非 co-located 模式下,由于 Placement Group 本身是分离的,训练 Actor 与 Rollout 模块将分别被调度至各自指定的 PG 中,实现资源隔离。
3. 训练初始化流程解析
Slime 框架的训练初始化过程采用分层架构设计,分为三层:RayTrainGroup(顶层)、TrainRayActor(中层)与 Megatron-LM(底层)。该设计不仅实现了模块化职责划分,还支持异步调度与灵活的资源管理,适用于大规模分布式 RL 场景。
3.1. RayTrainGroup:训练组的管理与调度
RayTrainGroup 是训练任务的顶层控制器,负责 TrainRayActor 实例的创建、初始化与资源分配。其核心职责包括:
- 接收上层指令(如
train.py的启动参数); - 将训练配置广播至所有 TrainRayActor;
- 管理分布式训练组的生命周期。
RayTrainGroup 中的所有异步方法均使用 def 定义。这是因为在 Ray 框架中,调用 .remote() 方法会立即返回一个 Future 对象(句柄),实际任务在后台异步执行。只有在显式调用 ray.get() 时才会阻塞等待结果。这种异步调度机制提升了系统响应速度与资源利用率。
3.2. TrainRayActor:分布式训练的基本单元
TrainRayActor 是 Slime 中分布式训练的最小执行单元,每个 Actor 负责一部分训练任务,并与 RolloutRayActor 建立连接,用于模型权重的同步更新。其核心设计点包括:
3.2.1 权重内存管理:CuMemAllocator 的使用
TrainRayActor 在初始化模型时,采用了与 vLLM 相同的底层内存分配器 CuMemAllocator,其特点包括:
- 支持通过标签(tag)对模型参数进行定向卸载(offload)或加载(onload);
- 比 PyTorch 默认的内存管理更底层、更高效;
- 是实现模型 sleep/wake 模式的前提。
初始化代码片段如下:
allocator = CuMemAllocator.get_instance() if self.args.offload else None
with allocator.use_memory_pool(tag="model") if allocator else nullcontext():
(self.model, self.optimizer, self.opt_param_scheduler, loaded_rollout_id) = (
megatron_utils.initialize_model_and_optimizer(args, with_optimizer=True))
start_rollout_id = loaded_rollout_id + 13.2.2 模型状态管理:Sleep 与 Wake 接口
TrainRayActor 提供了与 vLLM 兼容的模型参数状态管理接口,支持将模型参数在 GPU 与 CPU 之间动态切换,提升资源利用率并降低内存占用。
- sleep 方法:将模型参数从 GPU 卸载至 CPU;
- wake_up 方法:将模型参数从 CPU 加载回 GPU。
示例代码如下:
def sleep(self, tags):
assert self.args.offload
assert "model" in tags
with timer("sleep"):
if isinstance(tags, str):
tags = (tags,)
clear_memory()
print_memory("before offload model")
self.update_cpu_params_dict()
allocator = CuMemAllocator.get_instance()
allocator.sleep(offload_tags=tags)
clear_memory()
print_memory("after offload model")def wake_up(self, tags):
assert self.args.offload
with timer("wake_up"):
clear_memory()
print_memory("before wake_up model")
if isinstance(tags, str):
tags = (tags,)
allocator = CuMemAllocator.get_instance()
allocator.wake_up(tags)
clear_memory()
print_memory("after wake_up model")此类设计显著提升了模型在多任务调度与资源受限场景下的适应能力。
3. Megatron-LM:核心训练逻辑封装
训练逻辑的核心部分由 Megatron-LM 提供,通过 megatron_utils 模块进行封装。Megatron 支持多种并行策略(如 TP、PP、DP、CP、EP),并通过原生的训练器实现高效的分布式训练。
Slime 尽量复用 Megatron 的原生组件,以降低系统复杂度、提升训练稳定性与可维护性。
4. 推理初始化流程解析
Slime 的推理初始化流程同样采用三层架构设计,分别由 RolloutGroup(顶层)、RolloutRayActor(中层)与 SGLangEngine(底层)构成。
4.1. RolloutGroup:推理组的生命周期管理
RolloutGroup 是推理任务的顶层控制器,负责以下关键初始化操作:
4.1.1 启动 Router(负载均衡器)
通过 multiprocessing.Process 启动一个独立的 sglang_router 进程。该组件作为推理请求的负载均衡器,接收来自客户端的请求,并将其分发至后端的 SGLang 引擎,实现推理请求提交与执行的解耦。
4.1.2 创建 Buffer Actor
创建一个中心化的 Buffer Actor,用于统一管理 rollout 数据流的生命周期,包括:
- 生成 prompts;
- 接收生成结果;
- 存储数据供训练模块使用。
Buffer Actor 是训练与推理之间数据交互的核心组件。
4.1.3 创建 Rollout Engines(推理引擎)
这是初始化的核心环节。RolloutGroup 会创建一组 RolloutRayActor 实例,并为每个引擎分配以下资源:
- HTTP 端口:用于接收外部推理请求;
- NCCL 端口:用于分布式通信;
- GPU 资源:通过 Ray 的 Placement Group 分配逻辑 GPU 资源。
该机制确保了跨节点推理任务的高效执行。
4.1.4 创建 Lock Actor
创建一个简单的分布式锁 Actor,用于在模型权重更新时防止数据竞争,确保所有 Rollout 引擎使用一致的模型参数,避免推理过程中的状态不一致问题。
4.2. RolloutRayActor:面向 Ray 的推理接口
RolloutRayActor 是面向 Ray 分布式环境的推理接口层,封装了 SGLang 引擎的调用逻辑,并负责与 Buffer Actor 的数据交互。
4.3. SGLangEngine:推理任务的执行者
SGLangEngine 是 SGLang 框架的具体实现,负责实际的文本生成任务。它通过高效的缓存机制与调度策略,实现低延迟、高吞吐的推理能力。
5. 模型与参数同步机制
在强化学习系统中,训练与推理之间的模型参数一致性是确保训练稳定性和策略收敛性的关键环节。Slime 框架通过一套高效的模型同步机制,实现了训练模块(TrainRayActor)与推理模块(RolloutRayActor)之间的参数一致性管理。本节将从模型初始化流程出发,深入分析 Slime 的模型同步设计与实现。
5.1 模型同步初始化流程
在 TrainRayActor 的 __init__ 方法中,最终通过调用 megatron_utils.initialize_model_and_optimizer 完成模型与优化器的初始化。这一过程包括以下几个关键步骤:
5.1.1. 分布式环境初始化
megatron_utils.init(args)该方法负责初始化 PyTorch 的分布式通信环境(torch.distributed),并设置 Megatron-LM 的模型并行组(Model Parallel Group, MP)和流水线并行组(Pipeline Parallel Group, PP)。这是构建分布式训练环境的基础。
5.1.2. 分词器与配置的串行加载
为了避免多个 rank 同时访问 Hugging Face 缓存目录导致文件损坏,Slime 采用串行加载策略:
- 仅由 rank 0 加载分词器与模型配置;
- 其他 rank 通过分布式通信获取已加载的配置。
这一机制有效避免了多进程并发读写带来的资源竞争问题。
5.1.3. 模型与优化器初始化
模型初始化过程中使用了 CuMemAllocator 上下文管理器,为后续的显存卸载(sleep)功能提供支持:
with allocator.use_memory_pool(tag="model") if allocator else nullcontext():
(self.model, self.optimizer, self.opt_param_scheduler, loaded_rollout_id) = (
megatron_utils.initialize_model_and_optimizer(args, with_optimizer=True))
start_rollout_id = loaded_rollout_id + 1模型初始化遵循 Megatron-PAI 的最佳实践,通过提供 model_provider 函数构建 GPT 类模型,避免对 Megatron 原生逻辑的盲目修改,提升与主流生态的兼容性。
5.1.4. Reference Model 初始化
Slime 支持加载与主模型相同初始权重的 Reference Model,用于在训练中计算 KL 散度,作为策略更新的参考基准。该模型支持按需卸载至 CPU,以节省显存资源。
5.2 参数同步连接机制
训练模块与推理模块之间的参数同步是 Slime 框架的重要组成部分。其连接机制通过 RayTrainGroup 提供的 async_init_weight_update_connections 接口实现,具体流程如下:
5.2.1. 设置数据缓冲区
ray.get([actor.set_data_buffer.remote(rollout.data_buffer) for actor in self._actor_handlers])将 Rollout 模块中的 Buffer Actor 设置为所有 TrainRayActor 的数据源,确保训练与推理之间的数据一致性。
5.2.2. 同步并行化配置
actor_parallel_configs = ray.get([actor.get_parallel_config.remote() for actor in self._actor_handlers])
ray.get(rollout.async_set_parallel_config(parallel_config))获取所有 TrainRayActor 的并行配置信息,并将其同步至 Rollout 模块,确保推理时能够正确识别模型的并行结构。
5.3.3. 建立参数同步连接
return [
actor.connect_rollout_engines.remote(
rollout.rollout_engines,
rollout.rollout_engine_lock,
)
for actor in self._actor_handlers
]触发训练 Actor 与推理引擎之间的连接建立,为后续的参数同步打下基础。
5.3. 通信组的建立策略
Slime 根据训练与推理模块是否 co-located(是否共享 GPU 资源),采用两种不同的通信策略来实现高效的参数同步:
策略一:Co-located 场景(CUDA IPC)
当训练 Actor 与推理引擎部署在同一组 GPU 上时,Slime 为每个推理引擎创建一个仅包含同 GPU 上训练 Actor 的 torch.distributed 通信组。通信后端使用 NCCL,自动选择高效的 CUDA IPC 机制,实现 GPU 显存之间的直接数据拷贝,避免跨节点通信开销。
策略二:Distributed 场景(TCP/NCCL)
当训练与推理分布在不同节点上时,Slime 采用以下流程建立跨节点通信:
- 由每个 TrainRayActor 的 rank 0 广播其 IP 与端口;
- 所有 TrainRayActor 与 RolloutRayActor 加入该通信组;
- 最终建立一个基于 TCP 的
torch.distributed通信组。
该机制确保了参数同步在不同部署场景下的高效性与可靠性。
5.4 权重格式转换与消费机制
由于训练模块使用 Megatron-LM 的并行化权重格式,而推理模块通常消费 Hugging Face 格式的模型,Slime 在训练过程中将 Megatron 权重转换为 HF 格式,供 Rollout 模块使用。
这一设计避免了复杂的权重 resharding 操作,简化了模型同步流程,提升了系统的可维护性与扩展性。
6. 训练主流程
Slime 框架的设计旨在确保训练过程能够高效且稳定地运行。其核心流程包括样本生成、模型训练及权重更新三个主要阶段。本文将详细解析这些阶段的设计与实现细节。
6.1 样本生成(Rollout)
6.1.1. RolloutGroup 的样本生成代理
RolloutGroup 负责代理样本生成任务至 Buffer Actor。通过调用 async_generate 方法,可以异步触发数据生成流程。
# 文件: slime/ray/rollout.py
class RolloutGroup:
def async_generate(self, rollout_id, evaluation=False):
return self.data_buffer.generate.remote(rollout_id, evaluation=evaluation)6.2.2. Buffer Actor 的动态加载机制
Buffer Actor 不仅负责样本数据的管理,还支持动态加载用户自定义的 generate_rollout 函数,从而实现高度灵活的数据生成逻辑。例如,在 slime/rollout/sglang_example.py 中定义的 generate_rollout_async 函数展示了如何异步获取 prompts 并提交生成任务。
async def generate_rollout_async(args, rollout_id, data_buffer):
samples = await data_buffer.get_samples(sampling_batch_size * args.n_samples_per_prompt)
for sample in samples:
state.pendings.add(
asyncio.create_task(
generate_and_rm(...)
)
)
while len(data) < target_data_size:
done, state.pendings = await asyncio.wait(state.pendings, return_when=asyncio.FIRST_COMPLETED)
for task in done:
sample = task.result()
data.append(sample)
return data这种设计为开发者提供了极大的灵活性,使得他们可以根据具体需求定制数据生成策略。
6.2 数据流:Rollout -> Buffer -> Train
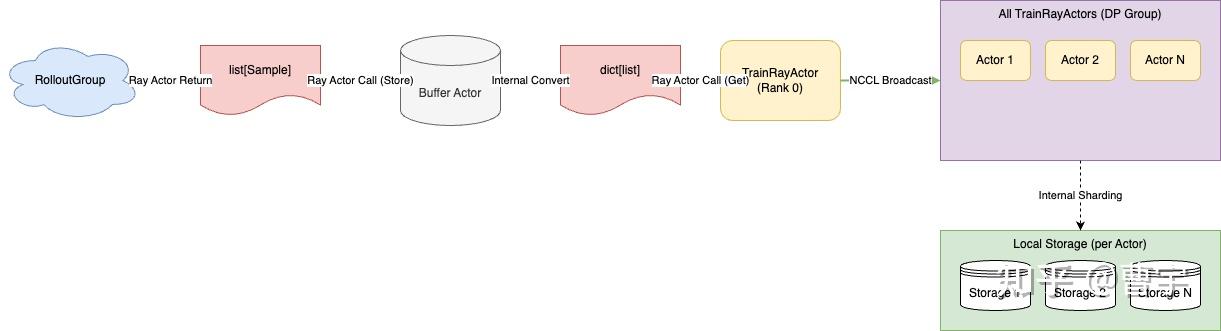
在 Rollout 过程中产生的样本数据被转换成标准 Python 字典格式并存储于 Buffer 中,然后通过 Ray 对象存储高效传输给训练 Actor。
6.3 模型训练
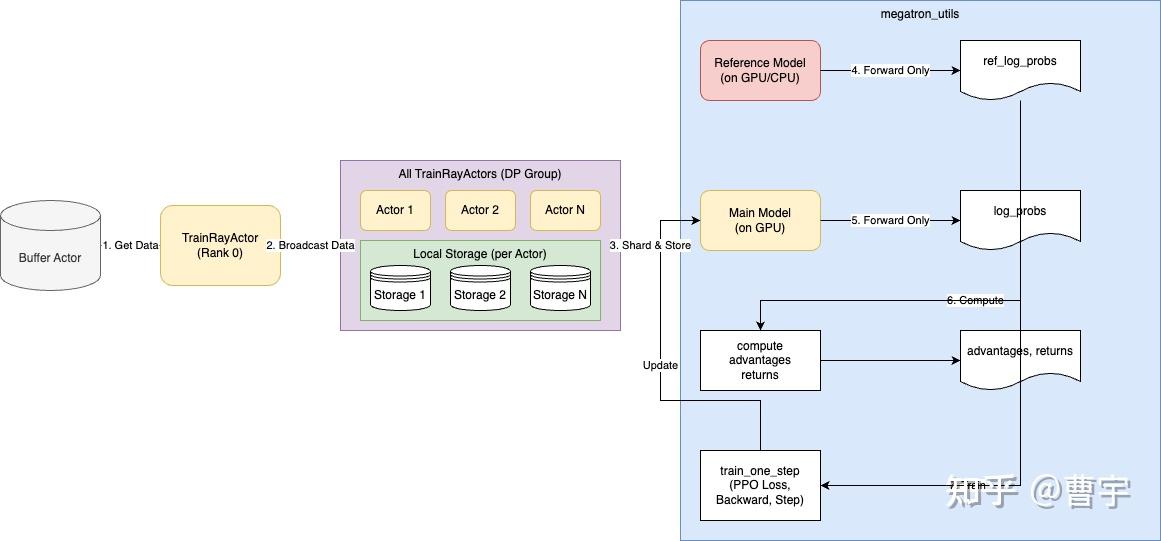
6.3.1. 数据获取与分发
TrainRayActor 的 rank 0 从 Buffer 获取数据并通过 dist.broadcast_object_list 将数据广播给所有其他 ranks。每个 TrainRayActor 根据其数据并行(DP)排名对接收到的数据进行切分,并存入名为 LOCAL_STORAGE 的进程内全局字典中。
6.3.2. 关键计算步骤
- Ref Log Probs 计算:使用 Reference Model 进行前向传播,计算 ref_log_probs。
- Actor Log Probs 计算:使用主策略模型进行前向传播,计算 log_probs。
- 优势函数计算:基于 log_probs 和 rewards 计算 KL 散度,进而得到 advantages 和 returns。
- 执行训练步骤:利用计算出的 advantages 调用
megatron_utils.train执行优化步骤,包括前向传播计算 loss、反向传播、梯度裁剪和参数更新。
6.3.3. 核心 Loss 计算
- Policy Loss:实现了标准 PPO clip loss 及其变体。
- Entropy Loss:借助 Megatron Core 的
fused_vocab_parallel_cross_entropy高效计算交叉熵。 - Context Parallelism (CP) Loss:处理序列被切分到多个 GPU 上的情况,确保损失正确归一化。
6.4 权重同步
训练完成后,需要将更新后的权重同步到 SGLang 推理引擎。根据部署场景的不同,采用两种不同的同步路径:
分布式同步(TCP/NCCL)
- 暂停推理 & 准备参数:通过 Ray 调用暂停所有 SGLang 引擎的生成任务。
- 重组权重 & 转换为 HF 格式:使用
all_gather收集参数分片,移除词表 padding,并将 Megatron 格式的权重转换为 Hugging Face 格式。 - 广播权重:在之前建立的
_model_update_groups通信组内,由 rank 0 使用dist.broadcast广播转换好的权重。
Co-located 同步(CUDA IPC)
- 加载并对齐参数:将 CPU 上的权重加载到其源 rank 的 GPU 上,并通过内部广播确保所有训练 Actor 都有完整的参数。
- 重组权重 & 转换:流程类似分布式同步,但操作对象是已在 GPU 上的权重。
- 发送 IPC 句柄:将转换好的权重序列化,获取指向 GPU 显存的轻量级 IPC 句柄,并在 IPC 通信组内收集所有句柄。SGLang 引擎接收后直接从对应的显存地址读取数据完成更新。
总结:Slime —— 面向决策大模型的在线学习框架
Slime 并不仅仅是一个 RLHF(人类反馈强化学习)的实现框架,它更是一个将大规模分布式训练与高性能推理服务深度融合、具备高度可扩展性的“决策大模型”在线学习系统。其核心价值在于,成功应对了在真实工业场景中部署和持续优化大型 AI Agent 所面临的关键工程挑战。
一、核心优势
1. 工业级的“训推一体”架构
Slime 构建于 Ray 的 Actor 模型之上,实现了训练与推理模块的深度集成:
- 训练引擎:基于 Megatron-LM,支持多种并行策略(TP/PP/DP/CP/EP),适用于千亿参数级模型的高效训练;
- 推理引擎:集成 SGLang,具备低延迟、高吞吐的推理能力,满足在线服务场景需求;
- 统一调度:通过 Ray 的 Placement Group 和资源调度机制,实现训练与推理任务的资源协同分配与灵活部署。
这种“训推一体”的设计,极大降低了系统间的通信开销,提升了整体训练效率与部署灵活性。
2. 高效的“知识流动”闭环
Slime 实现了强化学习的核心飞轮机制:生成 → 训练 → 同步,构建了一个闭环的学习系统:
- 数据流:通过异步的 Buffer Actor 管理 rollout 数据,结合高效的 NCCL Broadcast 机制,实现从“探索”到“学习”的低延迟数据回传;
- 权重流:根据部署模式(分布式或 co-located),自适应选择 NCCL Broadcast 或 CUDA IPC 实现权重同步,确保从“学习”到“行动”的低延迟知识更新。
这一闭环机制是实现持续在线学习和策略迭代的关键。
3. 高度灵活与可扩展的架构设计
Slime 的模块化设计赋予其强大的扩展能力:
- 可插拔的探索与评估逻辑:用户可通过配置文件指定
rollout_function_path和custom_rm_path,自定义 Agent 的探索行为与奖励建模逻辑,无需修改框架核心; - 模型无关性支持:借助
slime_plugins机制,Slime 可灵活适配多种模型架构,支持快速扩展新的模型结构与训练策略。
这种设计显著降低了新功能的接入成本,提升了系统的通用性与可维护性。
二、未来挑战与发展方向
尽管 Slime 在大规模 RL 训练与推理方面已具备强大的工程能力,但在面对更复杂、更开放的 Agentic 场景时,仍存在若干值得探索的技术挑战与发展方向:
1. 支持长序列与延迟奖励机制
当前的 RL 框架多假设奖励信号即时反馈,但在实际应用中,奖励往往需要经过多轮交互才能获得。如何构建支持超长序列建模与延迟奖励处理的训练流程,是未来需要重点突破的方向。
2. 彻底异步与解耦的系统架构
目前 Slime 的训练与推理仍保持一定程度的同步耦合。未来可进一步解耦为完全独立的异步集群:
- 使用分布式数据库或对象存储构建持久化经验池(Experience Pool);
- 支持按需采样与异步训练,提升系统的容错性与资源利用率;
- 实现真正的“生产-消费”分离模式,支持更大规模的并发训练与推理。
3. 多智能体与多模态扩展
随着 AI Agent 应用场景的扩展,对多智能体协作与多模态输入的支持成为必然趋势:
- 多智能体协同训练:构建支持协作、竞争、通信等行为的多智能体训练机制;
- 多模态输入建模:扩展模型输入接口,支持图像、音频、文本等多模态数据的联合建模;
- 任务分解与策略组合:支持复杂任务的分层建模与策略组合,提升 Agent 的泛化能力与适应性。