AsyncFlow: An Asynchronous Streaming RL Framework for Efficient LLM Post-Training
一种高效的异步流式强化学习框架用于大语言模型后训练
摘要
强化学习(Reinforcement Learning, RL)已成为大语言模型(Large Language Models, LLMs)后训练阶段的关键技术。然而,传统任务共置(task-collocated)的RL框架面临显著的可扩展性瓶颈,而任务分离(task-separated)框架则常因复杂的数据流导致资源空闲和工作负载不均衡。此外,多数现有框架与特定训练或推理引擎深度耦合,难以支持用户自定义的后端系统。为应对上述挑战,本文提出 AsyncFlow —— 一个面向高效LLM后训练的异步流式强化学习框架。
具体而言,我们设计了一个分布式数据存储与传输模块 TransferQueue,以全流式方式实现统一的数据管理与细粒度调度,从而在RL任务间自动实现流水线重叠和动态负载均衡。进一步,我们提出一种基于生产者-消费者模式的异步工作流机制,通过在可控的策略陈旧性阈值内延迟参数更新,有效减少计算空闲时间。更重要的是,AsyncFlow在架构上与底层训练和推理引擎解耦,通过服务导向的接口封装,提供高度模块化和可定制的用户体验。大量实验表明,相比当前最先进的基线系统,AsyncFlow平均提升吞吐量达1.59倍,最大提升达2.03倍。本工作为下一代RL训练系统的设计提供了可行的技术路径与架构启示。
1 引言
大语言模型(LLMs)通过在海量自然语言语料上进行无监督的下一个词预测训练,展现出卓越的语言理解与生成能力,被视为通往人工通用智能(AGI)的重要路径。随着模型参数从百万级扩展至万亿级,其智能水平持续提升。然而,预训练所依赖的数据资源正面临枯竭。研究表明,公开可用的高质量文本数据预计将在2028年前耗尽,这将严重制约模型规模的进一步扩展。
为突破这一瓶颈并提升模型对齐能力,指令微调(Instruction Tuning)与基于人类反馈的强化学习(Reinforcement Learning from Human Feedback, RLHF)被广泛应用于后训练阶段,使模型行为更符合人类偏好与社会价值观。此外,强化学习还提供了一种“数据飞轮”机制:通过自生成高质量响应与奖励信号,实现模型性能的迭代增强。近期具备人类级推理能力的模型出现,进一步验证了后训练中强化学习的潜力与扩展性。
与仅涉及单一模型的预训练不同,RL后训练工作流包含多个模型与任务,系统设计复杂度显著提升。以广泛使用的近端策略优化(PPO)算法为例,其涉及六个核心任务:
- Actor(Actor)Rollout
- Reference Model(Reference)推理
- Critic(Critic)推理
- Reward Model(Reward)推理
- Actor 参数更新
- Critic 参数更新
这些任务之间存在严格的数据依赖关系,且需采用不同的并行策略,导致高效、可扩展的RL系统设计极具挑战。
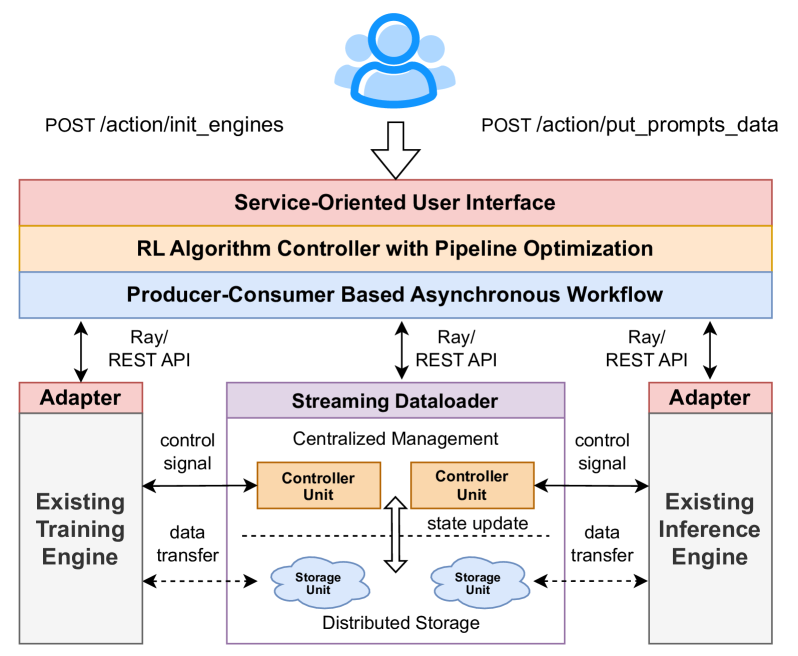
现有RL后训练框架主要分为两类:任务共置与任务分离。
任务共置框架(如 DeepSpeed-Chat)将所有任务部署于同一组设备上,串行执行。其主要缺陷包括:
- 内存效率低下:需同时加载所有模型参数,造成巨大显存开销;
- 重分片开销大:Actor Rollout 与更新阶段的并行策略不同,切换时需重新分片,引入显著延迟;
- 并行效率低:小模型难以充分利用大集群资源,存在资源浪费。
任务分离框架(如 OpenRLHF)将不同任务分配至独立资源池,通过分布式调度工具(如 Ray)管理。但其面临以下问题:
- 资源空闲严重:由于任务间存在数据依赖(如 Actor 和 Critic 更新需等待 Rollout 完成),导致计算资源利用率下降;
- 数据流复杂:嵌套并行策略加剧跨任务数据调度难度,影响整体效率;
- 引擎耦合性强:多数框架与特定训练/推理引擎(如 Megatron-LM、vLLM)深度绑定,缺乏灵活性,限制了工业界用户的定制需求。
为解决上述问题,本文提出 AsyncFlow —— 一个基于任务分离架构、支持异步流式处理的强化学习框架。其核心设计包括:
- 分布式数据管理模块 TransferQueue:通过集中式元数据控制与分布式数据平面,实现全流式数据调度,自动实现任务间流水线重叠与负载均衡;
- 异步生产者-消费者工作流:在可控陈旧性前提下延迟参数更新,最大化计算资源利用率;
- 服务导向接口设计:与底层训练/推理引擎解耦,支持多种后端,兼顾研究灵活性与工业部署需求。
本文贡献总结如下:
- 提出 TransferQueue,实现RL任务间的自动流水线重叠与动态负载均衡,显著提升任务分离框架的训练效率;
- 设计基于生产者-消费者模式的异步工作流机制,有效平衡训练效率与收敛稳定性;
- 提供服务导向的API接口,支持异构训练/推理后端,弥合学术研究与工业部署之间的鸿沟;
- 在大规模集群上开展实验,相比现有SOTA框架,吞吐量平均提升1.59倍,最高提升达2.03倍。
所提出技术已集成至Ascend驱动的 MindSpeed-RL 框架,代码开源地址:https://gitee.com/ascend/MindSpeed-RL。
2 系统概述
图2展示了AsyncFlow的层次化架构设计。该框架旨在构建一个可扩展、高效且灵活的异步流式RL训练系统。
- 资源层:基于Ray构建,负责计算资源的分配与调度。通过执行时间模拟器对硬件资源进行预优化,提升训练效率。
- 后端层:提供模块化适配器,支持多种异构训练与推理引擎(如 DeepSpeed、vLLM、TensorRT-LLM 等),确保框架对后端的“引擎不可知性”(engine-agnostic)。
- 优化层:核心创新所在,解决任务分离框架中的两大挑战——数据流管理与资源利用率。包含:
- TransferQueue:流式数据加载器,动态调度复杂数据流;
- 异步工作流:基于生产者-消费者模式,延迟参数更新以减少空闲。
- 接口层:提供统一的算法控制入口,满足研究需求;同时提供服务导向API,便于工业场景集成。
综上,AsyncFlow通过分层设计,实现了算法灵活性、系统可扩展性与工程实用性的统一,为后训练RL系统提供了新的架构范式。
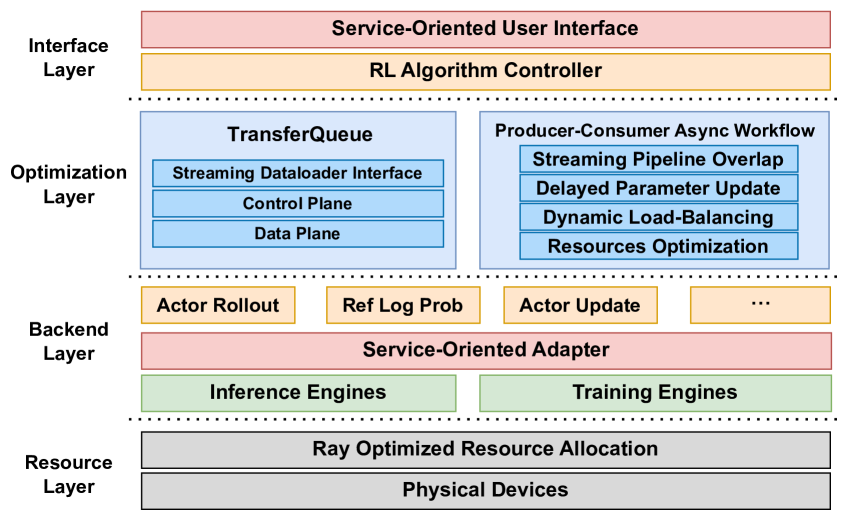
图2. AsyncFlow框架的层次化架构设计。
3 TransferQueue:高性能异步流式数据加载器
在任务分离的RL框架中,任务间的数据依赖是导致资源空闲的主要原因。传统实现往往采用批处理模式,需等待整个批次数据生成后才启动下游任务,造成严重延迟。为此,我们提出 TransferQueue —— 一个具备分布式存储能力的集中式数据管理模块,作为异步流式数据加载器。
TransferQueue的核心设计理念包括:
- 流式数据调度:允许下游任务在数据生成过程中即开始消费,实现任务间流水线重叠;
- 集中式元数据管理:为每个RL任务提供全局数据状态视图,消除手动定义复杂数据流的需要;
- 解耦控制与数据平面:借鉴软件定义网络(SDN)思想,分离元数据控制与真实数据传输,提升系统可扩展性与I/O效率。
3.1 架构概述
如图3所示,TransferQueue作为连接训练与推理集群的流式调度中枢,管理整个RL后训练过程的数据流动。
- 控制器(Controller):每个RL任务对应一个独立的TransferQueue控制器,负责维护该任务所需数据的元数据,包括:
- 数据存储位置(全局索引)
- 数据状态(是否就绪)
- 消费状态(是否已被某个数据并行组消费)
控制器间相互独立,避免任务间干扰。
- 数据存储单元(Storage Unit):分布式存储训练样本,每个单元负责一部分全局批次数据。样本通过全局索引唯一标识,支持跨节点寻址。
数据交互流程如下:
- 写入触发:当新数据(如Actor生成的响应)写入存储单元时,触发元数据更新通知;
- 请求处理:数据并行组(DP Group)向其对应控制器发送读取请求;
- 元数据组装:控制器扫描元数据,筛选出状态就绪且未被消费的样本,按微批次大小打包;
- 数据读取:DP组根据返回的元数据,直接从分布式存储单元中读取真实数据;
- 结果写回:计算完成后,DP组将结果原子性写回存储单元,更新元数据。
为兼容主流训练框架,我们将上述逻辑封装为PyTorch DataLoader,用户可无缝集成至现有工作流。
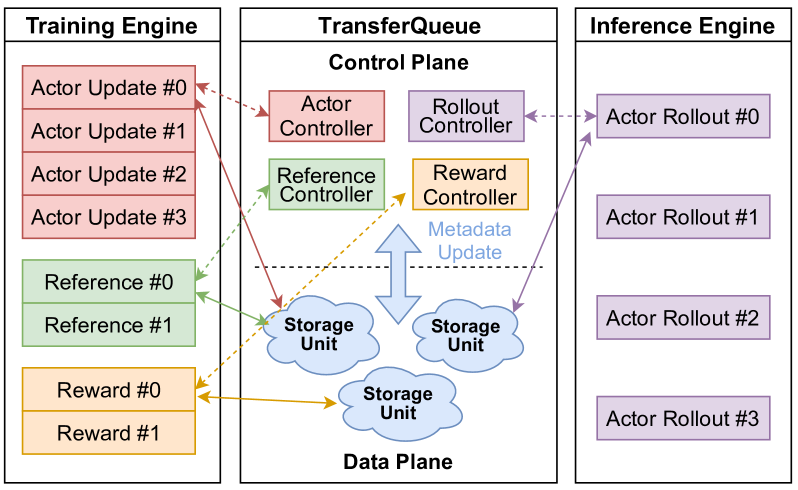
图3. TransferQueue的架构设计。每个DP组与其对应的TransferQueue控制器交互,以获取元数据,然后在数据平面中与存储单元执行读/写操作。虚线表示元数据通信,而实线表示带有真实数据的通信过程。所有这些交互过程都被封装为一个分布式流式数据加载器,以便无缝集成到训练和推理引擎中。
3.2 数据平面:分布式数据传输与存储
3.2.1 数据结构
为满足不同RL任务的多样化数据需求,TransferQueue采用二维列式数据结构(见图4):
- 行:表示一个完整的训练样本(experience);
- 列:表示任务特定的数据字段,如
prompts、actor_responses、ref_log_probs等。
该设计优势在于:
- 按需读取:任务仅请求所需列,减少不必要的数据传输;
- 并发访问:支持对不同行/列的并发读写,提升高并发场景下的吞吐;
- 分布式存储:样本按行分布于多个存储单元,实现负载均衡与带宽分散。
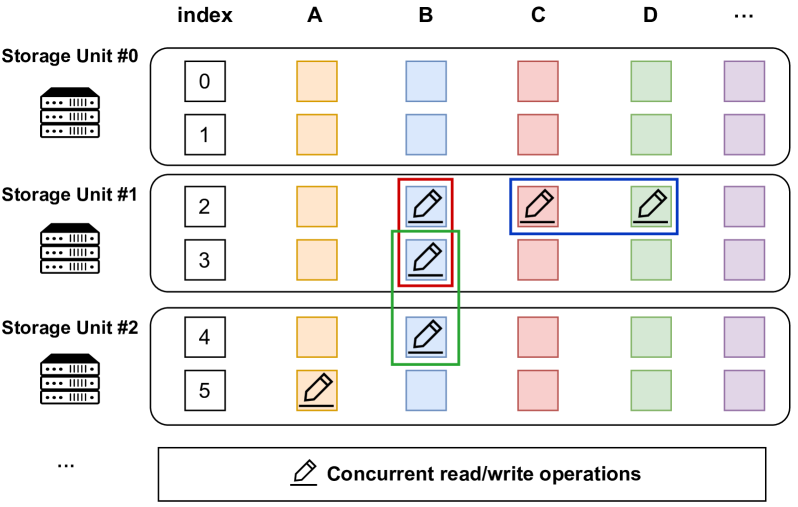
图4. TransferQueue的数据结构。每一行代表一个完整的数据样本,而每一列代表任务特定的数据组件。通过全局索引,我们可以在不同的存储单元中准确寻址数据样本,以进行并发读/写操作。
3.2.2 元数据通知
当新数据写入存储单元后,系统自动触发元数据广播机制(见图5):
- 存储单元将写入的行索引与列标识符广播至所有已注册的控制器;
- 控制器据此更新本地元数据表,将对应条目标记为“就绪”(状态1)。
该机制确保控制器能实时感知数据可用性,为流式调度提供基础。
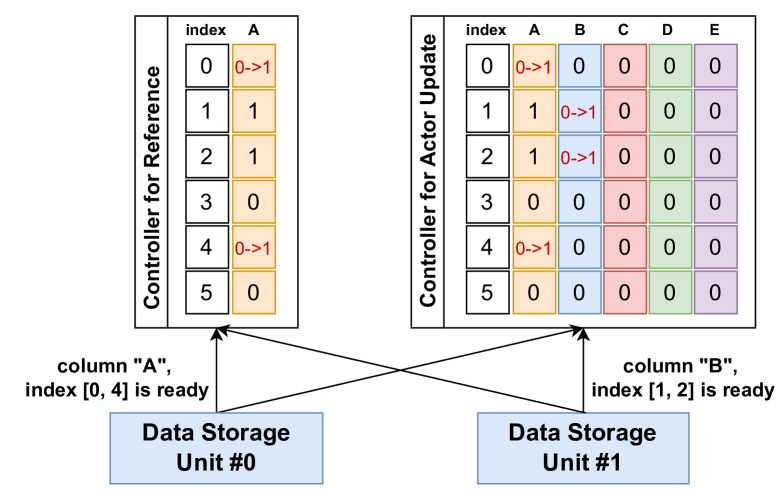
图5. TransferQueue的元数据通知过程。数据存储单元会将元数据(包括全局索引和对应的数据列)广播给所有控制器。
3.3 控制平面:集中式数据管理视图
为应对LLM训练中嵌套并行策略带来的复杂数据流,TransferQueue的控制平面提供集中式数据状态视图,实现跨任务协调。
- 每个控制器维护其任务范围内的元数据,使用二进制状态指示器:
- $0$:数据未就绪
- $1$:数据已就绪
如图6所示,当收到读取请求时,控制器执行以下操作:
- 扫描元数据,筛选出所有列状态均为1且未被消费的样本;
- 若可用样本数超过请求微批次大小,依据负载均衡策略(如最短队列优先)选择样本;
- 将选中样本标记为“已消费”,防止重复使用;
- 返回元数据,供请求方读取真实数据。
该设计支持动态负载均衡:计算较快的实例可获取更多数据,避免空等;同时可实现标记级负载均衡,确保各DP组处理的token总数均衡,减少训练空闲。
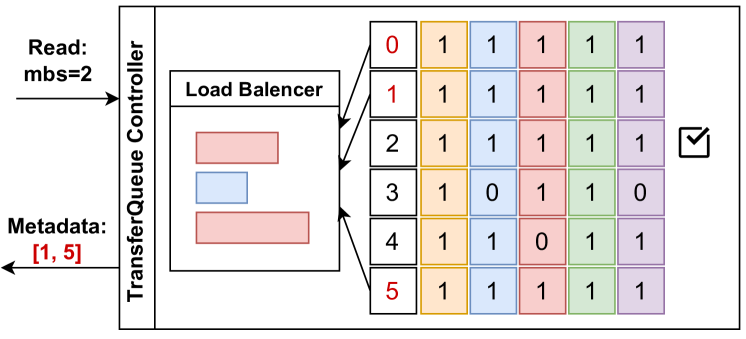
图6. TransferQueue控制器的调度过程。红色索引表示相应的数据样本满足RL任务的要求,而勾号表示相应的数据已在早期请求中被消费。
3.4 交互接口
为了简化TransferQueue的使用,我们将它的功能封装到一个PyTorch DataLoader中。如代码1所示,用户首先通过指定当前RL任务、所需输入数据列和微批次大小来初始化TransferQueue作为流式数据加载器。在每次前向步骤中,然后可以通过迭代器包装器轻松检索所需的数据。此接口简化了TransferQueue的集成,确保与现有训练工作流的无缝兼容性。
# 在类RolloutWorker(BaseWorker)中
def generate_sequences(self):
# 定义数据列并初始化TransferQueue
experience_consumer_stage = 'actor_Rollout'
experience_columns = ['prompts', 'prompt_length']
experience_count = self.rl_config.Rollout_dispatch_size
data_loader = self.create_stream_data_loader(
experience_consumer_stage=experience_consumer_stage,
experience_columns=experience_columns,
experience_count=experience_count,
use_vllm=True,
pad_to_multiple_of=self.generate_config.infer_tensor_parallel_size,
)
data_iter = iter(data_loader)
for batch_data, index in data_iter:
# 执行推理
prompts_data = batch_data['prompts']
responses = self.Rollout.generate_sequences(prompts_data)
# 将生成的响应写入TransferQueue
self.collect_transfer_queue_data(responses, index)代码1. TransferQueue使用示例
该接口设计确保了与现有训练流程的无缝集成,用户无需关心底层分布式细节。
3.5 高并发设计
TransferQueue旨在通过以下三个步骤解决大规模后训练挑战。
- 首先,其解耦的控制平面和数据平面架构使得数据存储单元能够扩展,以应对高并发操作。当出现I/O或网络带宽瓶颈时,可以轻松初始化额外的数据存储单元,以扩展总带宽并减少系统延迟。这种设计还支持轻松切换到其他存储后端,例如Mooncake Store、Redis或其他为LLM训练量身定制的存储系统。此外,控制平面中的调度过程和数据平面中的I/O操作并发执行,创建了一个能够高效处理多个传入请求的流水线工作流。
- 其次,TransferQueue通过指定每个DP组中的一个Rank与系统接口来优化通信效率,考虑到DP组中的每个Rank(不考虑序列并行性时)应接收相同的数据。检索到的数据随后在DP组内的其他Rank之间进行广播。这种方法显著减少了在大规模后训练场景中对TransferQueue的直接请求数量。
- 第三,我们消除了在数据存储和传输过程中不必要的填充。TransferQueue本身支持可变长度的数据传输。对于设备到设备的华为集体通信库(HCCL)通信,张量沿着序列维度进行拼接以进行广播操作,然后我们使用长度元数据恢复接收到的张量。这种策略最小化了由于填充而导致的冗余通信开销,特别是在具有大微批次大小的设置中。总之,这些设计缓解了数据存储和传输瓶颈,确保了大规模后训练工作负载的稳健高并发性能。
4 基于生产者-消费者模式的异步工作流优化
任务分离架构中的关键挑战之一在于流水线气泡,即由于跨设备的数据依赖导致的硬件资源闲置。为解决这一问题,AsyncFlow引入了多项优化技术以最大化硬件利用率:
- 流式数据加载器:通过实现RL任务间的流水线重叠,显著减少后训练阶段的端到端执行时间。
- 延迟参数更新机制:在离线策略场景下,通过允许Actor(actor)Rollout和更新之间存在一步异步性,有效消除了预热和冷却阶段的气泡现象。
- 动态负载均衡策略:主动资源规划确保细粒度的执行时间优化,充分释放任务分离框架的可扩展性潜力。
4.1 RL任务之间的流式流水线重叠
利用TransferQueue,AsyncFlow不仅简化了数据流管理,还通过实现RL任务间的流水线重叠来提高训练吞吐量。在这种范式中,所有训练和推理实例只需与流式数据加载器交互,由其动态地在任务间调度最细粒度的数据样本。如图7所示,这种架构支持无缝扩展至任何具有不同任务的RL算法,无需手动重新调度数据流。

图7. 流式流水线重叠。
4.2 异步离线策略气泡减少
4.2.1 基本异步RL算法
传统的LLM后训练中的RL算法主要采用同步在线策略范式,其中Actor Rollout和Actor更新在相同的参数状态下运行。尽管这种范式确保了算法的收敛性,但其严格的同步要求导致计算效率低下,严重限制了大规模后训练的可扩展性。然而,最近的研究成果挑战了这一范式:优化技术,如部分Rollout和流式Rollout,实际上放宽了在线策略假设,允许在更新阶段使用旧模型生成的响应数据。这些创新为探索异步、离线策略框架创造了机会,这些框架承诺通过流水线重叠显著提高训练效率,同时保持收敛保证。如图8(a)所示,同步在线策略算法在Actor Rollout和Actor更新阶段之间强制执行严格的同步,这导致了跨迭代的预热和冷却气泡。一种直接的缓解策略是增加Actor Rollout阶段的全局批次大小,转而采用异步离线策略场景,其中Actor更新使用过时的参数生成的响应,如图8(b)所示。这种适应扩展了RL流水线的稳定阶段,从而减少了预热和冷却阶段中气泡的比例。然而,算法收敛性约束对Actor Rollout和Actor更新阶段之间允许的版本差异施加了严格限制。实证研究表明,Actor Rollout和Actor更新之间的一步异步性不会导致显著的性能或收敛性退化。而当版本差异超过这一阈值时,性能会以对数方式下降。这种权衡突显了在大规模LLM后训练中协调训练效率与算法稳定性之间的关键需求。

图8(a). 同步在线策略;图8(b). 异步离线策略。
4.2.2 延迟参数更新机制
为了解决上述困境,我们提出了一种延迟参数更新机制,通过将Actor Rollout的模型权重与Actor更新解耦,进一步消除流水线气泡。如图8(c)所示,这种机制将参数更新延迟一步,使得在跨迭代的转换期间能够持续进行Rollout。具体而言,当Actor更新完成时,Actor Rollout工作器并不会立即停止生成响应。相反,它继续使用旧模型权重生成响应,同时异步地将接收到的新参数写入主机内存。新参数将在当前生成迭代完成时加载到Ascend神经网络处理单元(NPUs)中,将暴露的同步开销减少到相对较快的主机到设备(H2D)传输。通过允许持续的一步异步性,它使得稳定阶段几乎可以无限扩展,通过消除预热和冷却阶段来实现。尽管与StreamRL在概念上相似,但我们的方法通过TransferQueue的集中式数据流管理,进一步增强了可扩展性,实现了训练引擎中所有RL任务的重叠。总之,这种设计有效地减少了RL后训练工作流中的预热和冷却流水线气泡,充分挖掘了任务分离框架的架构潜力。此外,我们提出了一种新的参数更新机制,能够实现子步骤异步算法工作流,如图8(d)所示。为了高效地为下游任务提供数据,我们通常为Actor Rollout任务分配丰富的硬件资源。这种设置允许Rollout实例依次执行参数更新,而其他实例继续满足下游训练任务的数据需求。因此,在每个迭代中,我们可以利用最近更新的参数来生成部分数据,实现子步骤异步性。此外,这种设计还最小化了检查点加载的开销,从而提高了系统效率。我们将这种机制的实现细节留作未来的重要工作。
4.2.3 参数更新重叠
参数更新模块主要由部署在训练集群上的WeightSender和部署在推理集群上的WeightReceiver组成。为了最小化RL训练流水线中的权重传输时间,发送器和接收器被设计为支持同步和异步两种模式。在同步模式下,Actor Rollout被参数更新过程阻塞。为了缩短暴露的传输时间,我们利用Ascend NPUs之间的高带宽HCCL链路传输模型权重。为了进一步减少端到端时间,我们进一步开发了一种异步参数更新过程,该过程可以与异步RL算法的计算任务完全重叠。具体而言,训练引擎中的模型权重被卸载到主机设备,并通过主机网络异步传输到推理引擎,将计算工作负载与权重同步过程解耦。这种设计确保了参数更新过程既不会阻塞也不会干扰正在进行的计算任务,从而保持了连续的RL工作流。
4.3 任务资源规划
为了实现图8(c)中所示的理想工作流,我们构建了一个基于图的资源规划模块,该模块可以在给定的资源约束下准确搜索最优配置。通过在不同配置下模拟计算和通信时间,我们可以获得最小化整个RL工作流端到端时间的资源分配设置和超参数。鉴于LLM后训练的巨大搜索空间,我们采用了结合分析方法和基于分析的方法的混合成本模型。分析方法根据硬件规格和理论计算及通信量估算执行时间,提供快速评估,能够快速缩小搜索空间。相比之下,基于分析的方法通过实际运行训练和推理任务提供块级性能。它提供了更准确的评估,但以更高的时间消耗为代价。利用混合成本模型,我们在效率和准确性之间取得了良好的平衡,使其非常适合优化LLM后训练的复杂RL工作流。
5 服务导向型用户界面
为了提供卓越的用户体验,强化学习(RL)框架应当提供一个高级抽象层,用于协调所有特定于算法的任务。对于学术研究而言,这种设计提供了一个统一的算法开发入口点,通过标准化的API实现快速实验。对于工业场景而言,支持各种训练和推理后端同时保持架构灵活性至关重要。因此,维护一个合适的用户界面极为关键。在AsyncFlow中,我们实现了一个分层的服务导向型接口,如图9所示。具体而言,用户级接口封装了供最终用户使用的RL算法逻辑,并暴露了一组关键API来控制后训练工作流。此外,后端级接口提供了RL任务的模块化抽象,通过几个后端适配器将算法逻辑与执行引擎解耦。上述设计实现了关注点的清晰分离:算法研究人员可以与高级API交互以进行算法设计,而基础设施工程师可以专注于低级实现以实现更高的效率。这种接口的协同作用很好地平衡了学术灵活性与工业可扩展性,确保AsyncFlow能够同时满足快速算法迭代和生产级部署的需求。

图9. 服务导向型用户界面架构。
5.1 用户级接口
AsyncFlow在Trainer类中提供了一个RL算法控制器,作为主训练工作流的集中入口点。这一抽象无缝地组织了关键的RL任务,例如generate_sequences和update。研究人员可以通过Trainer类轻松修改核心RL算法。为了便于工业场景中的工作流自动化,我们实现了一些关键API,以最少的配置启动完整的后训练任务,例如:
init_engines:初始化训练和推理引擎。put_prompts_data:将提示数据集加载到后训练系统中。put_experience_data和get_experience_data:在训练和推理引擎之间协调生成的体验数据。weight_sync_notify:通知训练和推理引擎更新模型权重。
上述用户级接口提供了对后训练工作流的直观控制,从而简化了系统使用。
5.2 后端级接口
考虑到不同的训练和推理后端引擎,我们通过Adapter类设计了一个低级的RL任务抽象,如代码2所示。
# 基础适配器
class RLAdapter:
pass
class MindSpeedAdapter(RLAdapter):
def __init__(self, forward_backward_func, model, batches, forward_step):
self.forward_backward_func = forward_backward_func
self.forward_step = forward_step
self.model = model
self.batches = batches
...
# 抽象RL任务:compute_log_prob
def compute_log_prob(self):
...
losses_reduced = self.forward_backward_func(
forward_step_func=self.forward_step,
data_iterator=iter(self.batches),
model=self.model,
micro_batch_size=self.micro_batch_size,
forward_only=True,
collect_non_loss_data=True,
)
...
class VLLMAdapter(RLAdapter):
pass代码2. 后端级接口。
这一层确保了各种训练/推理后端(例如FSDP、DeepSpeed、vLLM)的无缝集成,同时保持与自定义设计框架的兼容性,允许工程师优化硬件利用率或切换系统,而不会破坏工作流的完整性。
6 评估
6.1 实验设置
模型
在评估AsyncFlow框架时,我们选择了Qwen2.5系列模型,参数规模从7B到32B不等。Qwen2.5被广泛用于学术研究和工业工作流,是RL后训练评估的常用基础模型。
RL算法
我们实现了组相对策略优化(GRPO)作为评估的代表性RL算法。GRPO通过利用每个提示的多个响应来估计偏好信号,从而消除了对单独Critic模型的需求。这一设计显著提高了后训练效率,如在DeepSeek-R1中的成功应用。PPO(近端策略优化)的支持目前正在开发中。
数据集
我们采用了DeepScaleR数据集进行RL后训练。该数据集包含超过4万个从美国数学邀请赛(AIME)、美国数学竞赛(AMC)等精心编译的数学问题-答案-解答对。利用该数据集,DeepScaleR-1.5B-Preview在多个基准测试中超越了OpenAI的o1-Preview,证明了该数据集的有效性。在最近开发的RL后训练框架中,DeepScaleR是一个常见的数据集选择。
硬件配置与并行化策略
我们使用大规模Ascend NPU集群评估所提出的RL框架。每个节点拥有16个NPUs,系统内存为2880GB。
软件版本
我们使用Ascend Extension for PyTorch 7.0.0(PyTorch-2.5.1)和Ascend Compute Architecture for Neural Networks(CANN)8.1.RC1作为NPU支持的基本软件平台。在AsyncFlow中,我们使用vLLM-Ascend 0.7.3作为推理后端,MindSpeed作为训练后端。
基线
我们将所提出的AsyncFlow与verl进行比较,后者是利用高效的3D-HybridEngine减少重分片开销的最先进的任务共置RL框架。除了训练效率高外,其单控制器和多控制器范式相结合还极大地简化了软件开发。在实验中,我们选择Pytorch FSDP作为训练后端,vLLM-ascend 0.7.3作为推理后端。为了在Ascend NPU平台上运行,我们对verl(2025年4月7日的版本,提交号d13434f)进行了必要的适配。
6.2 总体性能分析
我们在从32到1024个NPUs的集群上进行了广泛的实验,评估了AsyncFlow在Qwen2.5-7B和Qwen2.5-32B模型上的性能。如图10所示,AsyncFlow在所有配置中均优于verl基线,平均吞吐量提升了1.59倍。值得注意的是,在大规模集群中,AsyncFlow的性能提升尤为显著,其中7B模型在256个NPUs上达到了2.03倍的峰值性能。在512个NPUs上,AsyncFlow的吞吐量分别是verl的1.76倍和1.82倍。即使在32个NPUs的资源受限环境中,AsyncFlow的7B模型吞吐量仍比verl高出33.4%,显示出良好的适应性。这一现象与先前的研究一致,任务分离框架在大规模场景中展现出更大的潜力。关键的是,AsyncFlow保持了较高的扩展效率,在集群规模扩大16倍时,线性度分别达到了0.65和0.88——这一突破为在工业规模上高效训练LLM推理代理铺平了道路。
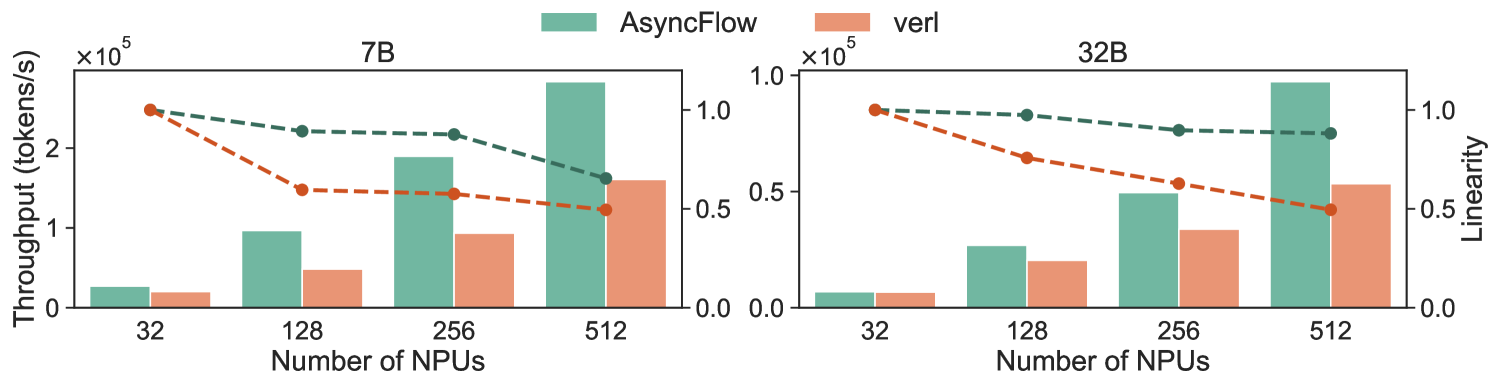
图10. 不同集群和模型规模下的端到端吞吐量和可扩展性分析。我们报告了10-20次迭代的平均吞吐量,以减少初始阶段的测量波动。
6.3 消融研究
为了验证所提方法的有效性,我们进行了一系列消融研究,结果总结在表1中。
| 编号 | 设置 | 归一化吞吐量 |
|---|---|---|
| ➀ | 基线 | 1 |
| ➁ | 启用TransferQueue | 2.01 |
| ➂ | ➁ + 启用异步优化 | 2.74 |
表1. 在512个NPUs上运行7B模型时的性能提升分解。
基线
我们建立了一个基线场景,代表传统的任务分离RL框架,禁用了所有提出的优化。在这种场景中,每个RL任务被分配到独立的硬件资源上,且一次只有一个任务执行。这一顺序工作流如图7顶部所示。
TransferQueue
作为AsyncFlow的核心特性之一,TransferQueue实现了RL任务之间的细粒度重叠。与基线相比,集成TransferQueue后吞吐量提升了2.01倍。
异步工作流优化
为了最小化迭代间的空闲时间,我们实现了优化的异步工作流。它包括延迟参数更新机制、重叠技术和任务资源分配策略。这一优化进一步使吞吐量比启用了TransferQueue的基线提升了36.3%。
6.4 AsyncFlow的优化工作流
为了严格评估所提出的异步离线策略工作流的有效性,我们以甘特图(图11)的形式展示了分布式训练和推理实例的经验执行时间线。它表明,在优化的数据流调度下,RL任务实现了显著的并行性,且任务间的空闲时间极小。这一观察结果从经验上验证了任务分离RL框架能够在资源利用率和可扩展性之间取得良好的平衡,从而在大规模设置中实现高效的后训练。
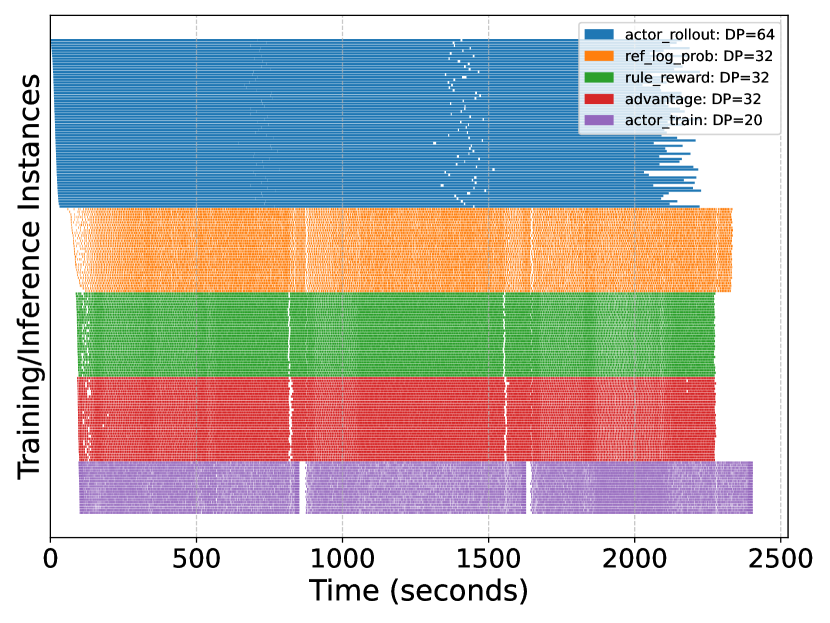
图11. AsyncFlow工作流。我们展示了在512个NPUs上运行32B模型的0-3次迭代。
6.5 异步RL算法的稳定性
为了评估所提出的异步RL工作流是否影响模型性能,我们在相同的时钟时间约束下测量了平均奖励和响应长度,结果如图12所示。实验在16个NPUs上部署的7B模型上进行,交替启用和禁用异步工作流。结果表明,奖励分数的差异可以忽略不计,且响应长度的方差呈现出收敛趋势。
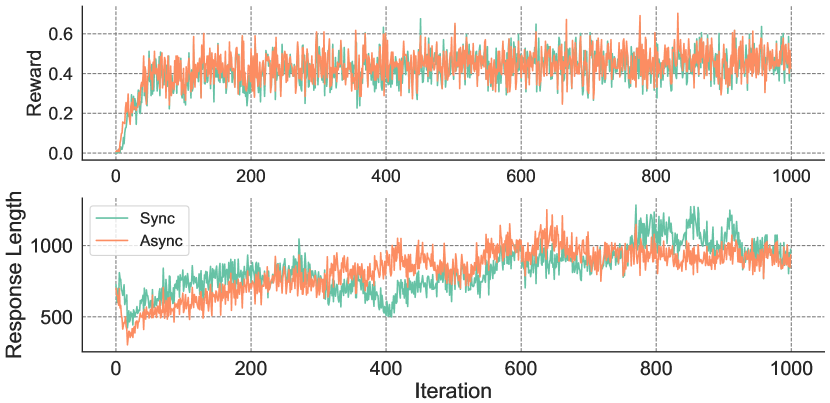
图12. 异步RL工作流与同步RL工作流的奖励和平均响应长度比较。
7 相关工作
7.1 LLM后训练框架
随着后训练阶段成为部署最先进的大语言模型以优化其能力的不可或缺的环节,众多框架应运而生,旨在高效管理和优化这一过程。在本研究中,我们根据强化学习任务如何映射到物理设备,将后训练框架分为两类范式:任务共置和任务分离。
任务共置框架在相同的设备集上执行Actor Rollout和Actor更新。示例包括TRL、DeepSpeed-Chat、NeMo-Aligner、RLHFuse和verl。这些框架在小规模后训练中实现了高资源利用率,因为所有设备在任何给定时间都在处理相同的计算任务。
相比之下,任务分离框架将Actor Rollout和Actor更新解耦到不同的硬件资源中。近期高质量的框架,如OpenRLHF、k1.5、Seed1.5-Thinking、StreamRL和AReaL,在大规模后训练场景中展现出强大的竞争力。这种范式与LLM推理(内存密集型)和训练(计算密集型)的发散性计算需求相契合,通过专门的资源分配实现了更好的硬件利用率。
7.2 RLHF算法
在RLHF算法中,PPO作为基础算法,协调了四个核心组件:Actor模型、Reference Model、Reward Model和Critic模型。这种多组件架构引入了内在的计算复杂性,给可扩展性和训练效率带来了挑战。为了缓解这些限制,近期的变体,如GRPO和DAPO,通过消除特定组件来简化工作流。在这些变体中,GRPO通过在策略和参考输出之间进行组相对比较来近似优势,从而消除了Critic模型;而DAPO进一步通过动态参考策略消除了Reference Model,该策略利用历史策略检查点作为自适应基线。这些简化旨在减少计算开销,但本质上以某些功能为代价,例如PPO中显式值函数估计所提供的稳定性保证。
7.3 LLM后训练系统优化
考虑到RL后训练工作流的端到端时间构成,Actor Rollout阶段因其自回归推理特性而受到了显著的研究关注,这从根本上使其与训练任务区分开来。RLHFuse引入了阶段融合策略,通过自动迁移机制实现Actor Rollout与下游任务的并发执行。StreamRL进一步增强了调度灵活性,通过引入响应长度预测器来实现。通过将提示分类为几种响应长度级别,它动态地将它们分派给不同的实例,在最大化吞吐量与由于长尾响应导致的偏斜之间取得平衡。同样,部分Rollout技术被引入到k1.5中,通过截断长响应来实现下游任务的流水线化,而无需等待完整生成。值得注意的是,与推理服务相比,Rollout阶段在后训练系统中缺乏严格的服务级别目标(SLO),这使得能够采用更广泛的调度策略以最大化系统吞吐量。
8 结论
在本工作中,我们提出了一个任务分离的强化学习框架,旨在为大规模集群提供模块化且可扩展的后训练能力。为此,我们首先引入了TransferQueue,这是一个具有分布式存储能力的流式数据加载器。通过动态路由跨训练和推理实例的复杂数据依赖性,它克服了在后训练任务开始之前预定义的静态数据依赖图所施加的瓶颈。此外,我们开发了一个基于生产者-消费者模式的异步工作流,通过允许Actor Rollout和Actor更新之间存在一步参数异步性,在保持算法完整性的同时,最小化了跨迭代的硬件空闲时间。通过将参数更新与计算任务重叠,这一设计在维持算法收敛稳定性的同时,显著提高了训练效率。为了便于使用,我们实现了一组服务导向的接口,提供了算法工作流和后端引擎的两级抽象,有效地弥合了理论研究与工业部署之间的差距。广泛的实验表明,与最先进的基线相比,AsyncFlow实现了显著的吞吐量提升,我们强调我们的任务分离框架在扩展到更大集群时展现出优越的线性扩展能力。对于未来的工作,我们在Rollout系统设计中发现了关键的机会。在生成的响应足以支持下游任务的约束下,我们可以为每个推理实例错开参数更新的时机,以消除响应生成过程中的同步障碍。这种方法不仅减少了暴露的转换时间,还能够实现子步骤异步工作流,其中Actor Rollout和Actor更新之间的陈旧性阈值低于一个训练步骤。总之,我们的研究为任务分离RL框架的设计提供了启示,这些框架在大规模后训练场景中展现出优越的可扩展性和效率。