AReal Lite:全异步分离式强化学习框架
这是RL infra童子功系列的最后一期了,介绍一下清华、蚂蚁的AReal Lite全异步分离式强化学习框架,全异步指的是模型更新是异步的,分离式指的是训练和推理时分离的。这两个概念其实都挺简单的,放到一起的意思其实也不难理解,但这里我还是希望通过一张图来把这个逻辑给表述清楚。
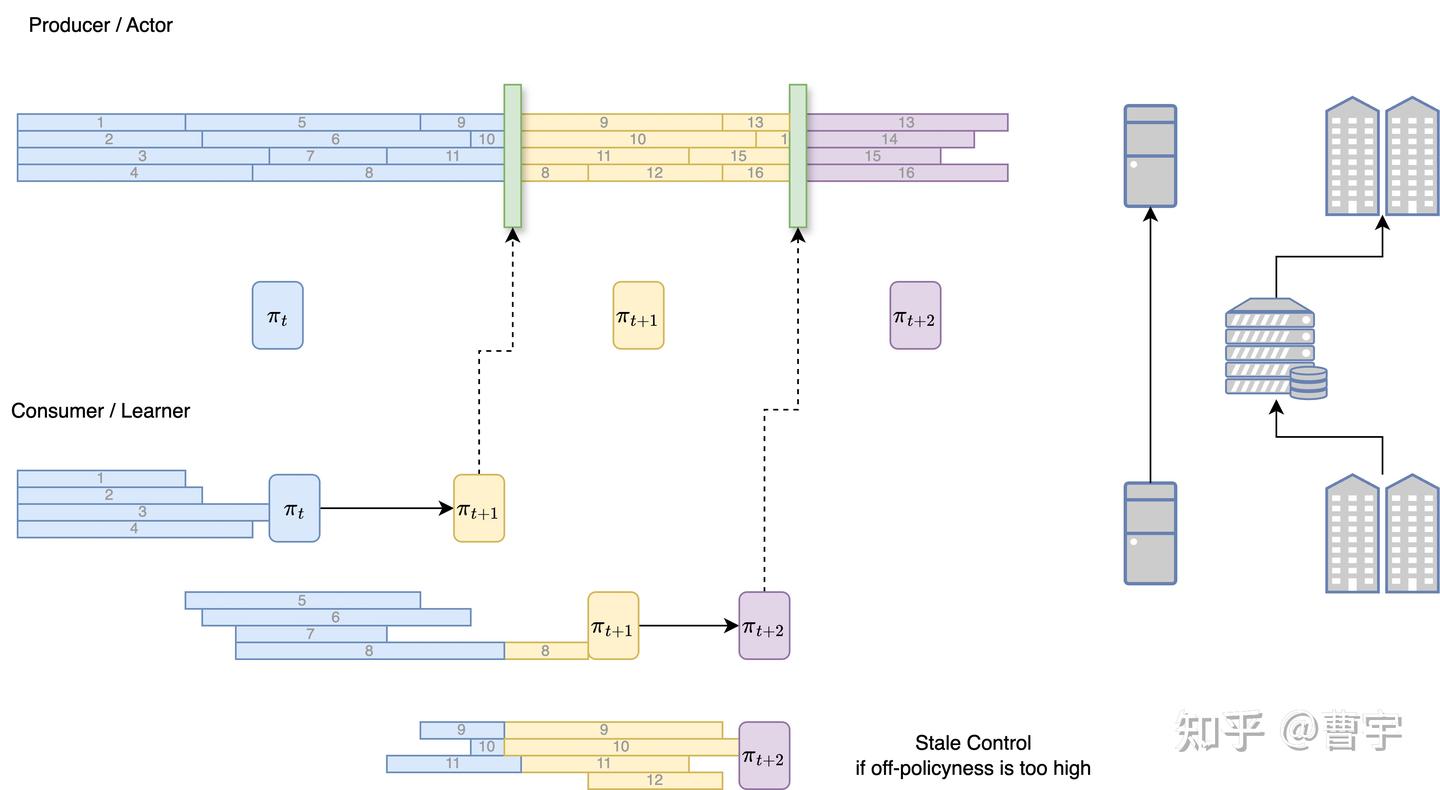

从Actor/Learner 或者 Producer/Consumer 的角度来看,整体的思路其实是这么一个样子,对应的Actor策略在满足Off-policyness的stale control(不让策略偏离太远)的情况下不断地rollout出来样本,等到Learner获得足够的样本之后训练便可以立刻开始。等到模型训练完成之后,通过NCCL或者异构的高速共享磁盘将权重更新到Actor的推理集群。所以实现了Producer和Consumer的全异步,这个解释了第一个概念。第二个概念分离式就好理解了,他们使用的是不同的资源,所以可以独立部署独立scale,甚至跨DC部署。在这样的部署逻辑下,我们可以实现异构训推(e.g. H20推,H100训)分离式scale,并在off-policyness允许的条件下极致压榨训推中间的bubble。
按照时序的角度和大家一起理一下整体的训推逻辑,主要是三个环节。
第一个环节:Producer 初始化之后,塞入包含足够的batch之后开始进行generation,对应颜色的条对应不同模型rollout的轨迹。可以注意到我们的推理流程在下一个时间节点的policy训练出来之前是不停下来的;同时对应的Episode级RM计算也在这个过程中完成。
第二个环节:Consumer一旦等到足够的batch之后,就可以开始对应的训练工作了,使用FSDP2后端结合PPO或者GRPO算法更新模型权重。这就是一个经典的强化学习Learner的步骤,然后权重更新完了之后,我们直接打断 Prodcuer的生产并通过NCCL或者共享存储更新权重至Producer的推理实例。
第三个环节:回到Producer,正在推理的Episode怎么处理呢?当Producer意识到权重更新之后,会先停下手头的工作,先把模型权重给更新了,然后对于之前解码出来的token进行一次kv cache重算,接着重算出来的新的kv cache再进行推理。(图中8所示的是第一个这样推理出来的trajectory,他的前一半是 \pi_{t} 推理出来的,后面是 \pi_{t+1})
后面的工作就是不断重复这个环节,直到消耗完所有的prompt数据,完成整体的模型训练。需要注意的是,随着训练的进行,堆积的prompt可能来不及被消耗。此时训练的off-policyness就会越来越高,图中展示了一个情况就是训练 \pi_{t+2} 的时候,实际的样本可能都是由\pi_{t} 和 \pi_{t+1} 生产出来的了。为了控制这种off-policyness对于训练的影响,AReal Lite中引入了一个叫做Stale Control的能力,使得数据-模型的off-policyness得到控制的前提下,尽量独立工作。
那么按照这个思路,AReal Lite中是如何实现这些功能的呢,为什么我们要做fully async这件事情呢? 本文主要重点解答这两个比较本质的问题。我们还是结合实战代码来看具体的实现方法和策略:
结合代码详细分析,第一个很好玩的点是AReal不对于编程范式有强要求所以也不是对于Ray进行强绑定了。这个设计很好玩,就是SPMD一套把Producer Consumer给抡起来,所以用一个torchrun或者把Ray纯粹当成是一个distributed launcher都是可以的。当然SPMD的东西,封装成Single Controller也不是什么特别难的事情,因为AReal中整体的数据传递是标准的PyTorch TensorDict,可以按照需要改造成最符合算法实际需求的样子。
第一步:Producer 的连续生成设计
Producer 的核心是 RemoteSGLangEngine,它通过异步请求和对中断的鲁棒处理实现了不间断的样本生成。
1. 异步请求与并发生成
RemoteSGLangEngine 的核心是 agenerate 异步方法。它利用 aiohttp 向 SGLang 推理服务发送生成请求,但不会阻塞等待,从而允许 WorkflowExecutor 并发管理多个生成任务,最大化吞吐量。
# arealite/engine/sglang_remote.py
async def agenerate(
self, req: LLMRequest | VLMRequest
) -> LLMResponse | VLMResponse:2. 处理生成中断与 KV Cache 复用
这是实现"连续生成"的关键。当模型权重需要更新时,正在进行的生成任务会被中断。agenerate 内部的 while 循环会捕获这种中断 (stop_reason 变为 "abort"),然后将已生成的部分 token 附加到原始输入之后,重新发起请求。这个过程对上层透明,保证了轨迹生成的完整性。
# arealite/engine/sglang_remote.py
# Deal with rollout interruption
# "abort" is the stop reason for later v0.4.9.post2 after
# we call the pause_generation endpoint
stop_reason = None
while (
stop_reason != "stop"
and len(accumulated_output_tokens) < gconfig.max_new_tokens
):
# Request is interrupted, wait for some time to avoid interfering
# with update weights requests
if stop_reason is not None:
await asyncio.sleep(0.5)
# loop until the generation is complete
result = await arequest_with_retry(
session=self.session,
addr=server_addr,
endpoint="/generate",
payload=payload,
method="POST",
max_retries=self.config.request_retries,
timeout=self.config.request_timeout,
)为了在中断后能够复用 KV Cache,系统为每个请求(由 rid 标识)分配一个固定的推理服务器。这样,即使请求被中断并重试,它也会被路由到同一台服务器,从而利用已有的计算结果。这样的作用是在AReal中原生设计的是多轮的episode,如果能够在一个episode的多个turn命中kv-cache是可以大幅增加其推理效率的,SGLang最古早的radix设计也是为了这一个部分考虑的。
# arealite/engine/sglang_remote.py
# A single "rid" shares the same sever to allow KV cache reuse
if req.rid in self.rid_to_address:
server_addr = self.rid_to_address[req.rid]
else:
server_addr = self.choose_server()
if len(self.rid_queue) >= RID_CACHE_SIZE:
# Remove the oldest entry if cache is full
oldest_rid = self.rid_queue.pop(0)
self.rid_to_address.pop(oldest_rid, None)
self.rid_to_address[req.rid] = server_addr
self.rid_queue.append(req.rid)第二步:Consumer 的 FSDP 协同与权重传递
Consumer (FSDPPPOActor) 在 SPMD 模式下通过 FSDP 实现分布式训练,并通过 NCCL 将训练好的权重高效地传递给 Producer。
1. FSDP Worker 协同
在 gsm8k_grpo.py 中,FSDPPPOActor 被初始化并由 FSDP 封装。当 actor.ppo_update(batch) 被调用时,FSDP 在底层自动处理梯度的聚合和参数的同步,开发者无需关心分布式通信的细节。
# examples/arealite/gsm8k_grpo.py
with (
stats_tracker.record_timing("train_step"),
stats_tracker.scope("grpo_actor"),
):
stats = actor.ppo_update(batch)
actor.step_lr_scheduler()
log_gpu_stats("ppo update")2. PPO 训练步骤 (ppo_update)
PPOActor.ppo_update 方法是训练的核心。它接收一个 TensorDict 格式的 data,其中包含了 Producer 生成的序列、logprobs、rewards 等信息。
切分微批次 (Micro-batching)
为了在 GPU 上更高效地训练,ppo_update 首先会将整个批次的数据切分成更小的微批次(minibatches)。
# arealite/engine/ppo/actor.py
mb_inputs = split_padded_tensor_dict_into_mb_list(
data,
mb_spec=MicroBatchSpec(n_mbs=self.config.ppo_n_minibatches),
)执行训练
然后,它会遍历这些微批次,并调用 self.engine.train_batch。这里的 self.engine 就是传入的 FSDPPPOActor 实例,它会负责在 FSDP 的上下文中执行前向传播、损失计算和反向传播。
# arealite/engine/ppo/actor.py
for mb in mb_inputs.mbs:
train_stat = self.engine.train_batch(
mb,
loss_fn=functools.partial(
grpo_loss_fn,
temperature=self.temperature,
eps_clip=self.config.eps_clip,
c_clip=self.config.c_clip,
behav_imp_weight_cap=self.config.behav_imp_weight_cap,
),
loss_weight_fn=lambda x: x["loss_mask"].count_nonzero(),
)损失函数
grpo_loss_fn (arealite/engine/ppo/actor.py:L325) 是实际计算 PPO/GRPO 损失的地方。它会计算新旧策略的 logprobs 比例、优势函数,并应用裁剪(clipping)来限制策略更新的幅度,这是 PPO 算法的标志性特征。
3. 权重传递
权重传递是连接 Consumer 和 Producer 的核心环节,由 gsm8k_grpo.py 中的 update_weights 代码块精心编排。
# examples/arealite/gsm8k_grpo.py
with stats_tracker.record_timing("update_weights"):
rollout.pause()
if dist.get_rank() == 0:
future = rollout.update_weights(weight_update_meta)
actor.upload_weights(weight_update_meta)
if dist.get_rank() == 0:
future.result()
dist.barrier(device_ids=[actor.device.index])
torch.cuda.synchronize()
rollout.resume()
actor.set_version(global_step + 1)
rollout.set_version(global_step + 1)分解步骤
rollout.pause(): 首先暂停 Producer 的样本生成,为权重更新做准备。rollout.update_weights(...): Producer (rank 0) 发起权重更新流程,准备从 Consumer 接收权重。这会触发 arealite/engine/sglang_remote.py 中的 update_weights_from_distributed 函数,让 SGLang 推理服务器加入 NCCL 通信组。actor.upload_weights(...): Consumer (FSDPPPOActor) 将自己的权重分片通过 NCCL 发送到通信组。future.result(): 等待 Producer 确认权重接收完成。dist.barrier, torch.cuda.synchronize: 确保所有进程(包括 Consumer 和 Producer 的底层进程)都完成了权重更新。rollout.resume(): 恢复 Producer 的样本生成。
第三步:Stale Control 的 Capacity 设计
Stale Control 的核心思想是:不能让 Producer 领先 Consumer 太多。如果 Producer 生成了大量基于旧策略的样本,而 Consumer 还在处理更早的数据,那么训练的 off-policyness 就会过高,导致训练不稳定。WorkflowExecutor 中的 get_capacity 方法精妙地实现了这一控制逻辑。
1. Capacity 的计算
get_capacity 方法 (arealite/api/workflow_api.py:L78) 用于决定 Producer 当前还可以生成多少新的样本。它的计算综合了多种因素,其中最关键的就是 Stale Control。
# arealite/api/workflow_api.py
# Staleness control
version = self.inference_engine.get_version()
ofp = self.config.max_head_offpolicyness
sample_cnt = self.rollout_stat.accepted + self.rollout_stat.running
consumer_bs = max(1, self.config.consumer_batch_size // world_size)
capacity = min(capacity, (ofp + version + 1) * consumer_bs - sample_cnt)2. 逻辑分解
version = self.inference_engine.get_version(): 获取当前 Consumer (Learner) 的模型版本号 v_L。ofp = self.config.max_head_offpolicyness: 获取一个关键的超参数,ofp,它定义了 Producer 的模型版本 v_P 最多可以领先 Consumer 多少个版本。例如,如果 ofp 为 2,那么 v_P 不能超过 v_L + 2。sample_cnt = self.rollout_stat.accepted + self.rollout_stat.running: 计算当前在系统中正在生成或已生成但尚未被消费的样本总数。consumer_bs: 获取 Consumer 一次训练所需的批次大小。capacity = min(capacity, (ofp + version + 1) * consumer_bs - sample_cnt): 这是 Stale Control 的核心公式。(ofp + version + 1) * consumer_bs计算出了在当前的 version 和 ofp 限制下,系统中允许存在的最大样本数。这个数量对应于版本 v_L 到 v_L + ofp 所需的所有数据。- 减去 sample_cnt (当前已有的样本数),就得到了还可以生成的样本数,即 capacity。
举例说明
假设 version=5,ofp=2,consumer_bs=64,sample_cnt=500。
- 系统允许的最大样本数是 (2 + 5 + 1) * 64 = 512。
- 当前已有 500 个样本。
- 那么,还可以生成的 capacity 就是 512 - 500 = 12。
- 一旦 sample_cnt 达到 512,capacity 就会变为 0,因为后面的off-policyness会超出限制WorkflowExecutor 的 _rollout_thread_async (arealite/api/workflow_api.py:L115) 将会停止提交新的生成任务,从而强制 Producer 等待 Consumer "赶上来",有效控制了策略的陈旧度。
Rollout 建模逻辑
讲到这里我们回头再来看一下AReal lite中对于rollout的建模逻辑与方式,看看有哪些有意思的地方。对于数据生成,主要采用的是arun_episode这个接口
# arealite/workflow/rlvr.py
async def arun_episode(self, engine: InferenceEngine, data):
input_ids = self.tokenizer.apply_chat_template(
data["messages"],
tokenize=True,
add_generation_prompt=True,
enable_thinking=self.enable_thinking,
)
n_samples = self.gconfig.n_samples
req = LLMRequest(
rid=uuid.uuid4().hex,
input_ids=input_ids,
gconfig=self.gconfig.new(n_samples=1),
)
resps = await asyncio.gather(*[engine.agenerate(req) for _ in range(n_samples)])以及:
# arealite/workflow/multi_turn.py
async def arun_episode(self, engine: InferenceEngine, data):
# Placeholders for the results
seq, logprobs, loss_mask, versions = [], [], [], []
messages = data["messages"]
# Run multi-turn rollout until correct
t = reward = 0
discount = 1
rid = uuid.uuid4().hex
while reward == 0 and t < self.max_turns:
# Amend a prompt if the previous answer is incorrect
if t > 0:
messages += [
{"role": "assistant", "content": completions_str},
{
"role": "user",
"content": "Your answer is not correct. Please try to answer it again.",
},
]
# Convert the prompt into input_ids
input_ids = self.tokenizer.apply_chat_template(
messages,
tokenize=True,
add_generation_prompt=True,
)
# Send generate request to get the response.
req = LLMRequest(
rid=rid,
input_ids=input_ids,
gconfig=self.gconfig.new(n_samples=1),
)
resp = await engine.agenerate(req)这两个是实际传入到RemoteSGLangEngine的方法,主要的rollout逻辑封装在了workflow中。batch = rollout.prepare_batch(train_dataloader, workflow=workflow) 再之后按照之前所述的异步逻辑进行训推分离。作为一个重度LangGraph Agent流派,到轻度手搓agent流派再到no framework流派,其实对于agentic和workflow的关系我也是一直在探索的状态。实际业务中现在完全用agentic的方式自由编排还不是特别现实,但是直接引入很重的类似于Beam + networkx的LangGraph确实也是限制模型在发挥。
这样的设计相对比较折中,没有直接把gym的env的step那一整套照搬过来,也保留了未来对于agentic的支持度。对于比较喜欢手搓的同学还是比较友好的,用户可以直接感知的几乎就直接是LLMRequest了,等到后期做到和Slime一样支持组建级别的分别调测应该还是挺好用的。
总结
好了两套童子功打完收工,继续回去研究算法了。最后稍微总结一下,强化学习infra领域未来会不会出现一个框架一统天下的局面呢,个人觉得还是比较难的。因为对于强化学习来说,具体的环境建模的思路其实和算法逻辑耦合的比较严重,对于agentic RL的理解不同势必会造成大家在做算法实践的过程中有不同的建模偏好。AReal Lite这次主要是面向算法开发者,大幅度砍掉了例如parameter relocation和megatron的后端同步这些比较复杂的逻辑,在炎炎夏日提供了一个较为清爽的接口,是一个非常有想法的开源全异步分离式强化学习框架实践。