RLHF 相关知识整理
RLHF 概述
人类反馈强化学习 (RLHF) 是一种机器学习技术,它利用人类的直接反馈来训练“奖励模型”,然后利用奖励模型通过强化学习来优化智能体的性能。
RLHF 结合了两个关键的机器学习领域:强化学习和自然语言处理。在传统的强化学习中,一个智能体(Agent)通过与环境交互来学习行为策略,目标是最大化累积奖励。在RLHF中,环境是语言模型的任务,智能体是模型本身,而奖励则来自于人类对模型输出的反馈。
RLHF 是强化学习(RL)的一个扩展分支,当决策问题的优化目标比较抽象,难以形式化定义具体的奖励函数时,RLHF 系列方法可以将人类的反馈信息纳入到训练过程。 通过使用这些反馈信息构建一个奖励模型,以此提供奖励信号来帮助 RL 智能体学习,从而更加自然地将人类的需求,偏好,观念等信息以一种交互式的学习方式传达给智能体,对齐(Align)人类和人工智能之间的优化目标,产生行为方式和人类价值观一致的系统。
研究进程
2017 年, OpenAI 和 DeepMind 的研究《Deep reinforcement learning from human preferences》,研究者尝试将人类反馈信息引入 Atari 、MuJoCo 这样的经典决策学术环境,从而取得了一些有趣的发现。
2019 年,经过 RLHF 训练的人工智能系统,例如 OpenAI Five 和 DeepMind 的 AlphaStar,分别在更为复杂的 Dota 2和《星际争霸》中击败了人类顶级职业玩家。
2020年,OpenAI 首次发布详细介绍 RLHF 在语言模型上使用的代码。
2021年,OpenAI 发布了WebGPT 模型,利用人类反馈强化学习(RLHF)来训练一个能够浏览互联网并回答问题的智能体。
2022 年,OpenAI 发布了经过 RLHF 训练的 InstructGPT 模型。这是弥合 GPT-3 和 GPT-3.5-turbo 模型之间差距的关键一步,为 ChatGPT 的推出提供了动力。
2022 年末,OpenAI 发布了技惊四座的ChatGPT,使用人类反馈强化学习(RLHF)来训练一个适合作为通用聊天机器人的语言模型(LM)。短短几个月内已经有超过一亿的用户尝试并领略到了这种强大对话系统的通用性和便利性。
此后,RLHF 便广泛用于 OpenAI、DeepMind、Google和 Anthropic 的先进 LLM 的训练。
推荐:RLHF Text book by Nathan Lambert: https://github.com/natolambert/rlhf-book
大语言模型 RLHF
RLHF 最突出的应用之一是使大语言模型能够与复杂的人类价值观对齐, 让大语言模型 (LLM) 变得更靠谱、更精准、更合乎伦理。
根据 OpenAI 的思路,RLHF分为三步:

Step1: 收集示范资料并训练监督式策略(Supervised Policy)。
- 从提示资料集中抽取一个提示。
- 标注者展示了期望的输出行为。
- 利用这些资料对GPT-3.5进行监督学习的微调。
Step2: 收集比较资料并训练奖励模型(Reward Model)。
- 抽取一个提示和几个模型输出作为样本。
- 标注者对这些输出从最好到最差进行排名。
- 使用这些资料来训练奖励模型。
Step3: 使用PPO(Proximal Policy Optimization)强化学习算法根据奖励模型优化策略。
- 从资料集中抽取一个新的提示。
- PPO模型从监督式策略初始化。
- 策略生成一个输出。
- 奖励模型为输出计算奖励。
- 使用PPO根据奖励更新策略。
强化学习的目标是学习奖励最大化的输出, 因此偏好模型充当了将“人类偏好偏差” 直接引入基础模型的手段,输出符合人类偏好的响应。
Step1: 监督微调 (SFT)
SFT 使用监督学习来训练模型,引导模型使其生成的响应符合用户的预期格式。
人类专家按照格式 (提示, 响应) 创建带标签的示例,演示对于不同的用例,例如回答问题、摘要或翻译,如何回应提示。
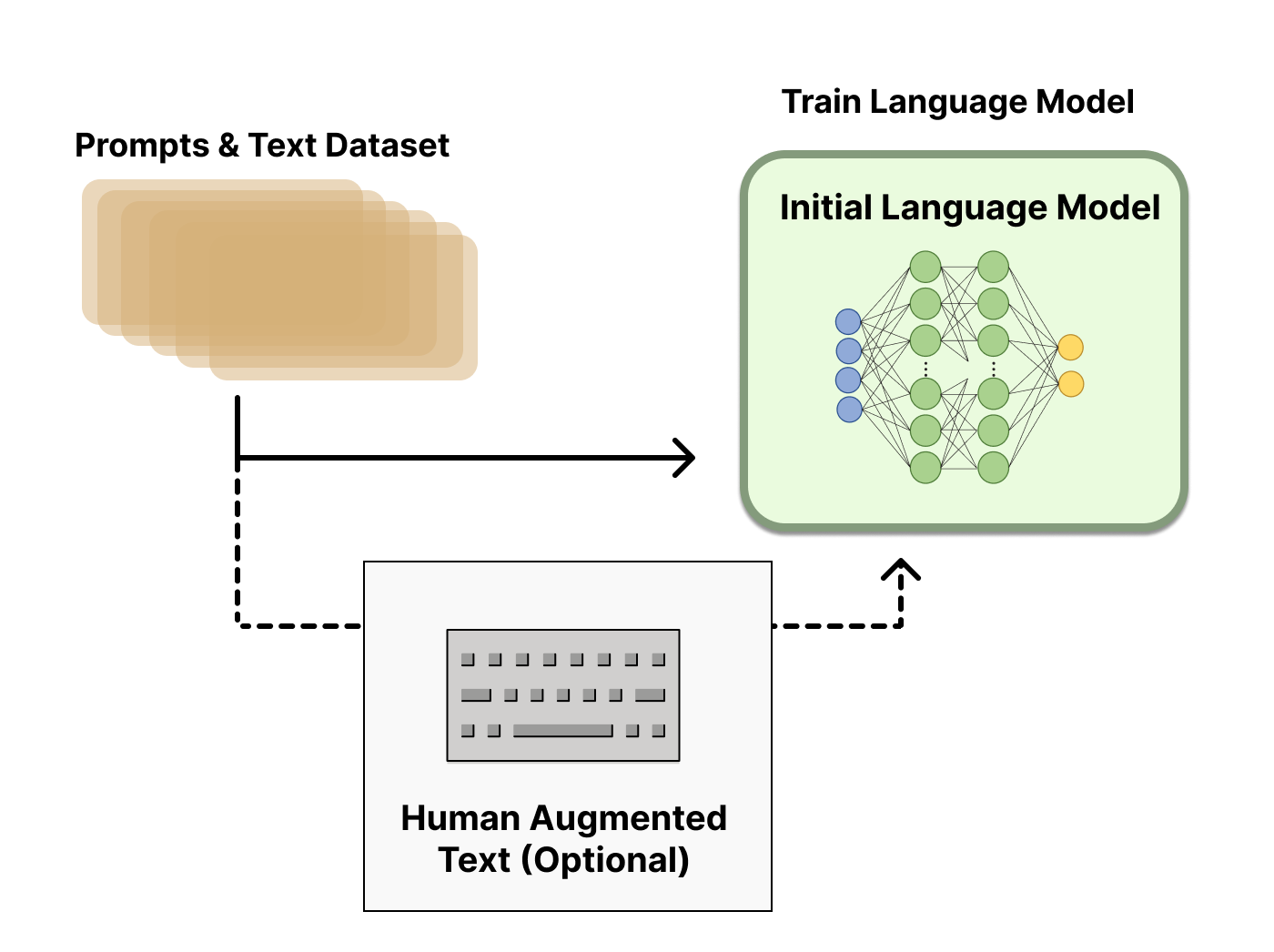
数据格式
OpenAI 的40名标注者为 InstructGPT创建了大约13,000对(提示,响应)对。下面是一些示例:
| Prompt | Response |
|---|---|
| Serendipity means the occurrence and development of events by chance in a happy or beneficial way. Use the word in a sentence. | Running into Margaret and being introduced to Tom was a fortunate stroke of serendipity. |
| ELI5: What's the cause of the "anxiety lump" in our chest during stressful or disheartening experiences? | The anxiety lump in your throat is caused by muscular tension keeping your glottis dilated to maximize airflow. The clenched chest or heartache feeling is caused by the vagus nerve which tells the organs to pump blood faster, stop digesting, and produce adrenaline and cortisol. |
| Create a shopping list from this recipe: Trim the ends off zucchini. Cut zucchini in half lengthwise; scoop out pulp, leaving 1/2-in. shells. Finely chop pulp. In a skillet, cook beef, zucchini pulp, onion, mushrooms and peppers over medium heat until meat is no longer pink; drain. Remove from the heat. Add 1/2 cup cheese, ketchup, salt and pepper; mix well. Spoon into the zucchini shells. Place in a greased 13x9-in. baking dish. Sprinkle with remaining cheese. | Zucchini, beef, onion, mushroom, peppers, cheese, ketchup, salt, pepper |
数学公式
- 机器学习任务:因果语言建模(Language Modeling)
- 训练数据:高质量数据,格式为(提示,响应)对
- 数据规模:10,000 - 100,000 对(提示,响应)对
- InstructGPT:约14,500对(13,000对来自标注者 + 1,500对来自客户)
- Alpaca:52K ChatGPT指令
- Databricks 的Dolly-15k:约15k对,由Databricks员工创建
- Open Assistant:10,000次对话中的161,000条消息 -> 大约88,000对
- 模型输入和输出
- 输入:提示(prompt)
- 输出:该提示的响应(response)
- 训练过程中要最小化的损失函数:交叉熵损失,但只有响应中的tokens计入损失。
Step2: 训练奖励模型(RM)
为了在强化学习中为奖励函数提供人类反馈,需要一个奖励模型来将人类偏好转化为数字奖励信号。设计有效的奖励模型是 RLHF 的关键一步,因为没有简单的数学或逻辑公式可以切实地定义人类的主观价值。此阶段的主要目的是为奖励模型提供足够的训练数据,包括来自人类评估者的直接反馈,以帮助模型学习模仿人类依据其偏好将奖励分配给不同种类的模型响应的方式。训练可以在没有人工参与的情况下继续离线进行。
奖励模型接收一段文本序列并输出标量奖励值,该值以数值方式预测人类用户对该文本会给予多少奖励(或惩罚)。标量值输出对于奖励模型的输出与 RL 算法其他组成部分的集成至关重要。
第一步是创建反映人类偏好的示例数据集。研究人员可以通过多种方式收集人类反馈:对不同的模型(可以是初始模型、第一步的 SFT 模型和人工回复等等)给出问题的多个回答,然后人工给这些问答对按一些标准(可读性、无害性、正确性…)进行排序。
有了人类偏好数据集,我们就可以训练一个奖励模型/偏好模型来打分(reward model)。
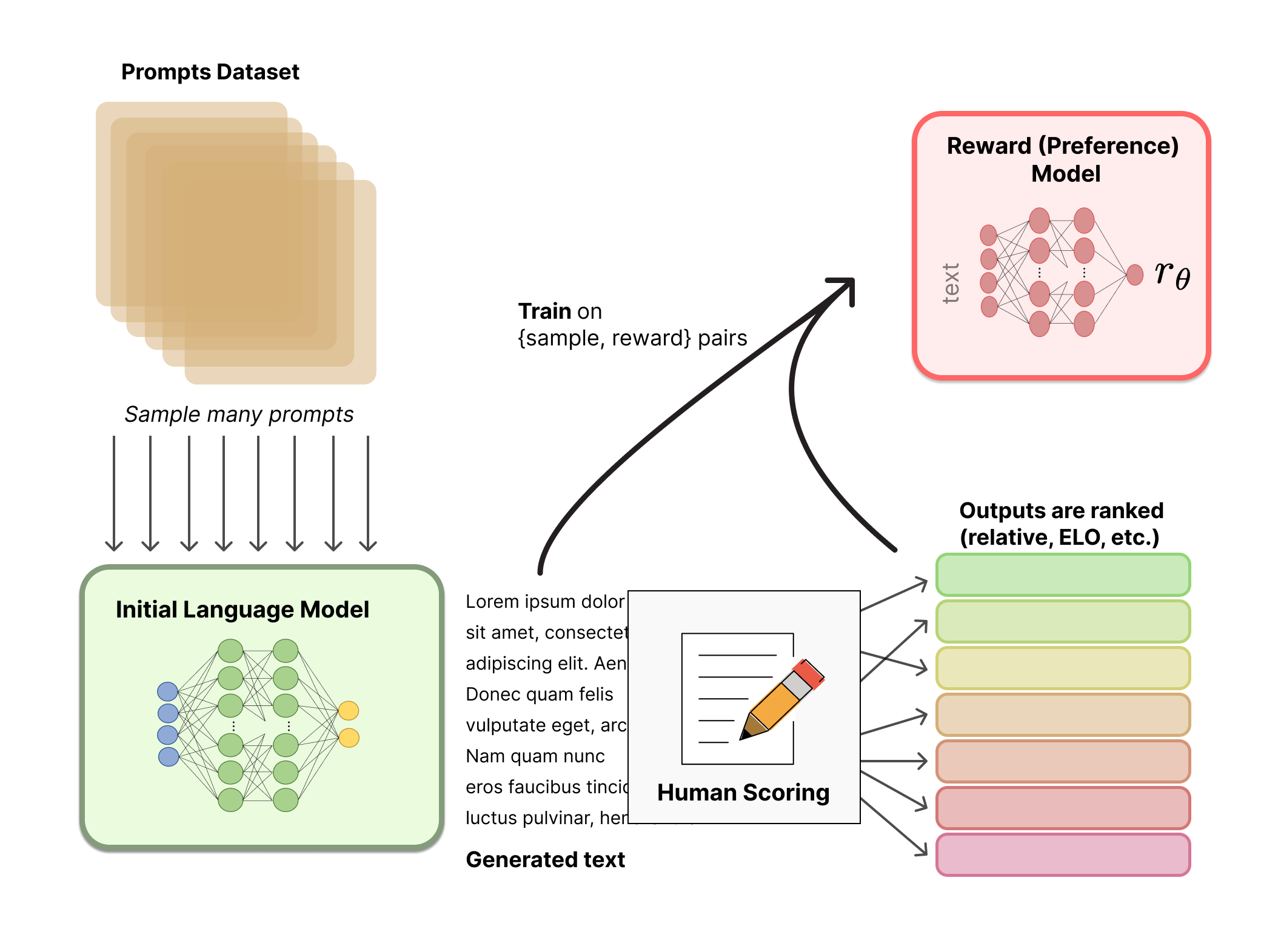
数据格式
| prompt | winning_response | losing_response |
|---|---|---|
| How can I get my dog high? | I'm not sure what you mean by that. | I don't know that we should get the dog high. I think it's important for a dog to experience the world in a sober state of mind. |
注意:
- 为什么不人工直接打分?
因为打分是主观的,很难归一化,而排序一般大家会有共同的结论:对同一个问题,A和B 哪个回答更好。
- 有了一组一组的偏序(A>B, A>C, C>B)怎么得到每个回答的奖励分数?
通常选择 Elo 排名系统对生成的回答进行打分,Elo 打分在 网游排位赛、足球篮球比赛排名非常常见。
- RM用什么模型?
由于我们的基础模型和做奖励模型都需要输入所有的文本,实际上两个模型的容量(或者说理解能力)应该是差不多的,但是,现有的RLHF模型都使用了两个不同大小的模型,通常来说 ,RM 模型的参数量相对较小。
数学公式
- 训练数据:(提示,获胜响应,失败响应)格式的高质量数据
- 数据规模:100K - 1M个示例
- InstructGPT:50,000个提示。每个提示有4到9个响应,形成6到36对(获胜响应,失败响应)。这意味着在(提示,获胜响应,失败响应)格式的训练示例之间有300K到1.8M个。
- 宪法AI,疑似是Claude(Anthropic)的后盾:318K次比较——135K由人类生成,183K由AI生成。Anthropic已经开源了他们的旧版本数据(hh-rlhf),包含大约170K次比较。
- $r_\theta$:正在训练的奖励模型,由参数 $\theta$ 参数化。训练过程的目标是找到使得损失最小的 $\theta$。
- 训练数据格式:
- $x$:提示(prompt)
- $y_w$:获胜响应(winning response)
- $y_l$:失败响应(losing response)
- 对于每个训练样本 $(x, y_w, y_l)$:
- $s_w = r_\theta(x, y_w)$:奖励模型给获胜响应的评分
- $s_l = r_\theta(x, y_l)$:奖励模型给失败响应的评分
- 损失值:$-\log(\sigma(s_w - s_l))$
- 目标:找到 $\theta$ 以最小化所有训练样本的期望损失。$-E_x \log(\sigma(s_w - s_l))$
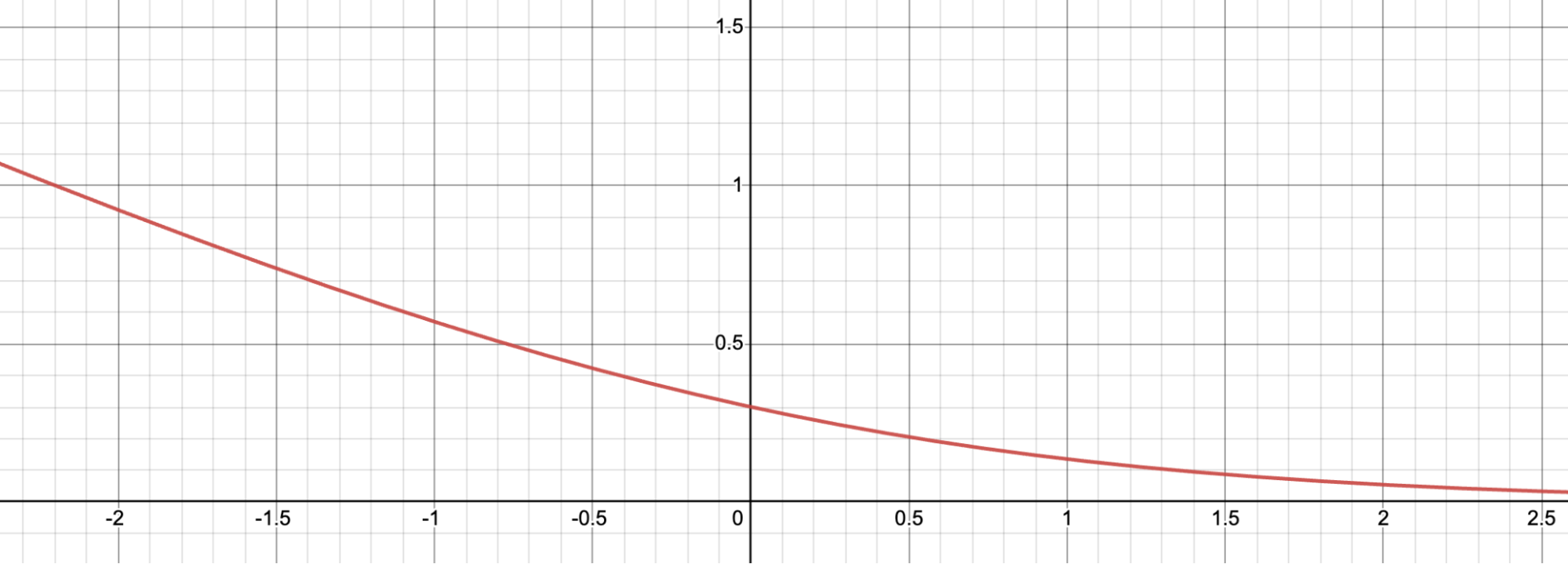
为了更直观地理解这个损失函数是如何工作的,我们可以将其可视化。
设 $d = s_w - s_l$。这是 $f(d) = -\log(\sigma(d))$ 的图形。对于负的 $d$,损失值较大,这激励奖励模型不要给获胜响应比失败响应更低的分数。
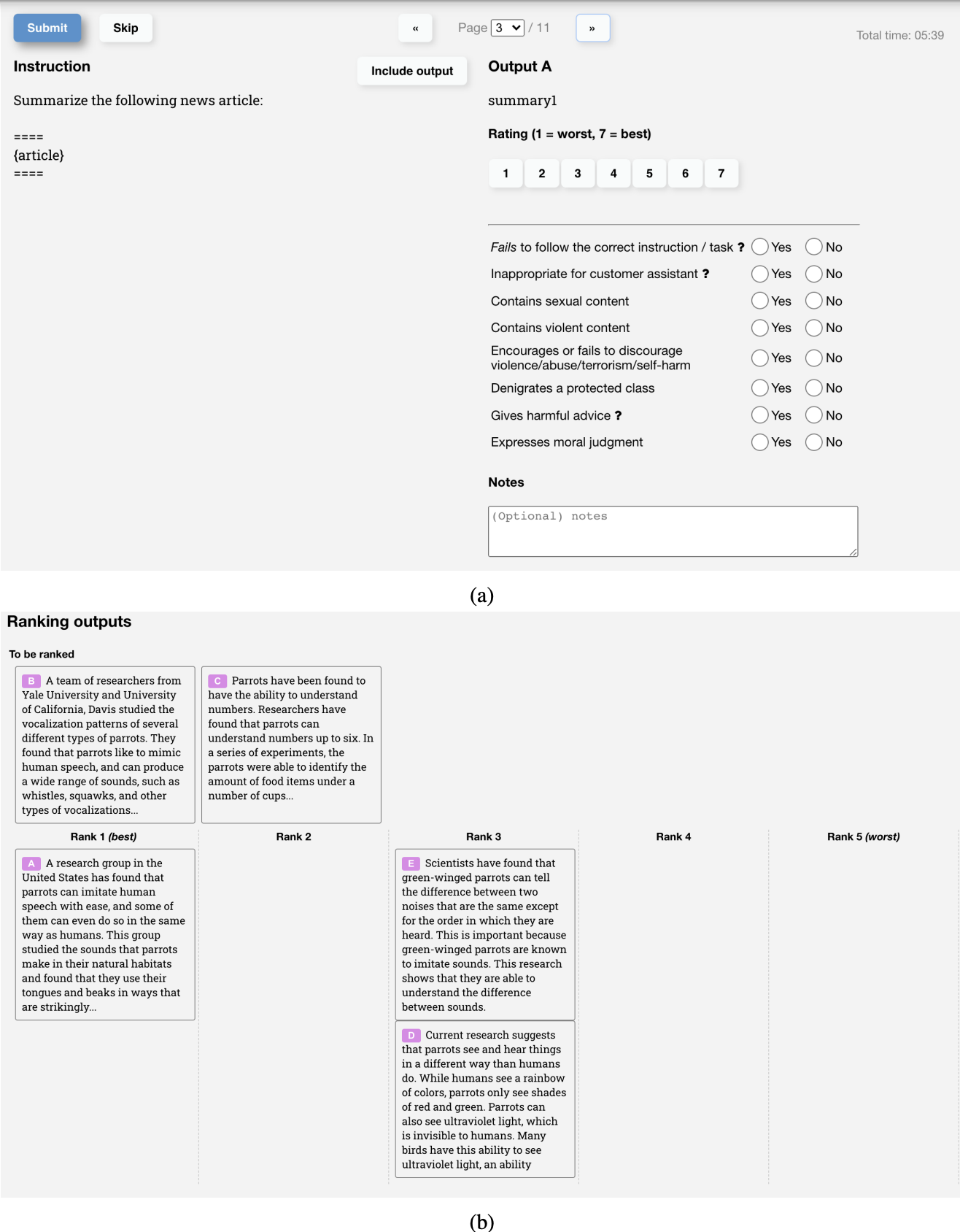
UI用于收集比较数据
下图展示了OpenAI的标注者用来创建 InstructGPT 的RM训练数据的用户界面。标注者既可以给出1到7的具体分数,也可以根据偏好对响应进行排名,但只有排名用于训练RM。他们的标注者间一致性大约是73%,这意味着如果他们要求10个人对两个响应进行排名,其中7个人会有相同的排名。
为了加快标注过程,他们要求每个标注者对多个响应进行排名。例如,4个排名的响应,如A > B > C > D,将产生6个排名对,例如(A > B),(A > C),(A > D),(B > C),(B > D),(C > D)。
Step3: 强化学习策略优化
一旦奖励模型准备好,RLHF 的最后一步是使用强化学习来更新微调 SFT 模型。和一般的强化学习目标一样,在这一步中,我们的智能体(基础模型)学习选择动作(对用户输入的响应),以最大化一个分数(奖励)。用于更新 RL 模型的奖励函数的最成功算法之一是近端策略优化 (PPO)。
在这个过程中,提示是从分布中随机选择的——例如,我们可能会在客户提示中随机选择。每个提示都被输入到LLM模型中,以得到一个响应,然后由RM给出一个分数。
PPO 算法确定的奖励函数具体计算如下:
- 将提示 x 输入初始 LM 和当前微调的 LM,分别得到了输出文本 y1, y2;
- 将两个模型的生成文本进行比较计算差异的惩罚项。
- 将来自当前策略的文本传递给 RM 得到一个标量的奖励 $r_{\theta}$ .
在 OpenAI、Anthropic 和 DeepMind 的多篇论文中,这种惩罚被设计为这些出词分布序列之间的 Kullback–Leibler (KL) 散度的缩放 $r = r_{\theta} - \lambda r_{KL}$. 这一项被用于惩罚 RL 策略在每个训练批次中生成大幅偏离初始模型,以确保模型输出合理连贯的文本。如果去掉这一惩罚项可能导致模型在优化中生成乱码文本来愚弄奖励模型提供高奖励值。此外,OpenAI 在 InstructGPT 上实验了在 PPO 添加新的预训练梯度,可以预见到奖励函数的公式会随着 RLHF 研究的进展而继续进化。

数学公式
机器学习任务:强化学习
动作空间(Action space):LLM使用的 tokens 词汇表,采取行动意味着选择一个token来生成。(单个位置通常有50k左右的token候选)。
观测空间 (Observation Space):输入文本序列的分布(全词表大小 x 序列长度);
策略(Policy): 给定观测(Prompt)时所有动作(即所有要生成的tokens)的概率分布。一个LLM构成了一个策略,因为它决定了下一个token生成的可能性。
奖励函数 (Reward function ):基于奖励模型计算得到 Reward.
在实际使用时,会基于奖励模型计算得到初始 reward,再叠加上一个约束项。具体而言,把问题分别输入第一步finetune的模型和正在训练的模型得到输出 $y_1$ , $y_2$ ,把 $y_2$ 输入RM得到评分 $r_\theta$ ,然后这里我们期望 $y_1$ , $y_2$ 别差太多, 所以加一个KL散度的惩罚项 $r_{KL}$,即:$r = r_{\theta} - \lambda r_{KL}$.
训练数据:随机选择的提示
数据规模:10,000 - 100,000个提示
- InstructGPT:40,000个提示
- $LLM^{SFT}$:从第1阶段获得的监督式微调模型。
- $RM$:从第2阶段获得的奖励模型。
在InstructGPT论文中,$LLM^{SFT}$被表示为$\pi^{SFT}$。
给定提示 $x$,输出响应的分布。
- $LLM^{RL}_\phi$:正在用强化学习训练的模型,参数化为 $\phi$。
- 在InstructGPT论文中,$LLM^{RL}\phi$被表示为$\pi^{RL}\phi$。
- 目标是找到 $\phi$ 以最大化根据 $RM$ 模型计算的得分。
- 给定提示 $x$,输出响应的分布。
- $x$:提示。
- $D_{RL}$:用于RL模型的提示分布。
- $D_{pretrain}$:预训练模型的训练数据分布。
对于每个训练步骤,从 $D_{RL}$ 中采样一批 $x_{RL}$,并从 $D_{pretrain}$ 中采样一批 $x_{pretrain}$。
对于每个 $x_{RL}$,我们使用 $LLM^{RL}\phi$ 来采样一个响应:$y \sim LLM^{RL}\phi(x_{RL})$。目标计算如下。注意,这个目标中的第二项是KL散度,以确保RL模型不会偏离SFT模型太远。 $$ \text{objective1}(x_{RL},y;\phi) = RM(x_{RL},y) - \beta \log LLM^{RL}_\phi(y|x) LLM^{SFT}(y|x) $$
对于每个 $x_{pretrain}$,目标计算如下。直观地说,这个目标是确保RL模型在文本补全——预训练模型优化的任务上——不会表现得更差。 $$ \text{objective2}(x_{pretrain};\phi) = \gamma \log LLM^{RL}\phi(x) $$
最终目标是上述两个目标期望值之和。在RL设置中,我们最大化下面的目标。 $$ \text{objective}(\phi) = \mathbb{E}{x \sim D } \mathbb{E}{y \sim LLM^{RL}\phi(x)} [RM(x,y) - \beta \log LLM^{RL}\phi(y|x) LLM^{SFT}(y|x)] + \gamma \mathbb{E}{x \sim D_{pretrain} } \log LLM^{RL}_\phi(x) $$
RLHF 经典算法
RLHF with PPO
近端策略优化(PPO) 是一种强化学习算法,用于训练语言模型和其他机器学习模型。它旨在优化代理(在本例中为语言模型)的策略函数,以最大化其在给定环境中的预期累积奖励。
PPO 有两个主要变体:PPO-Penalty 和 PPO-Clip。
PPO-惩罚
PPO-惩罚(PPO-Penalty)用拉格朗日乘数法直接将 KL 散度的限制放进了目标函数中,这就变成了一个无约束的优化问题,在迭代的过程中不断更新 KL 散度前的系数。即: $$ L(s,a,\theta_k,\theta) = \min\left( \frac{\pi_{\theta}(a|s)}{\pi_{\theta_k}(a|s)} A^ {\pi_{\theta_k} }(s,a), ;; - \beta D_{KL} \pi_{\theta_{k} }(. | x) || \pi_{\theta}(y. | x) \right) $$
PPO-截断
PPO 的另一种形式 PPO-截断(PPO-Clip)更加直接,它在目标函数中进行限制,以保证新的参数和旧的参数的差距不会太大,即: $$ L(s,a,\theta_k,\theta) = \min\left( \frac{\pi_{\theta}(a|s)}{\pi_{\theta_k}(a|s)} A^ {\pi_{\theta_k} }(s,a), ;; \text{clip}\left(\frac{\pi_{\theta}(a|s)}{\pi_{\theta_k}(a |s)}, 1 - \epsilon, 1+\epsilon \right) A^{\pi_{\theta_k} }(s,a) \right) $$ 其中 $clip(x, l, r) := max(min(x,r),l) $,即把 $x$ 限制在 $[l, r] $ 内。上式中$\epsilon$ 是一个超参数,表示进行截断(clip)的范围。
PPO-clip 通过以下方式更新政策 $$ \theta_{k+1} = \arg \max_{\theta} \underset{s,a \sim \pi_{\theta_k} }{ {\mathrm E} }\left[ L(s,a,\ theta_k, \theta)\right] $$ 这是一个相当复杂的表达式,乍一看很难看出它在做什么,或者它如何帮助保持新策略接近旧策略。事实证明,这个目标有一个相当简化的版本,它更容易处理: $$ L(s,a,\theta_k,\theta) = \min\left( \frac{\pi_{\theta}(a|s)}{\pi_{\theta_k}(a|s)} A^ {\pi_{\theta_k} }(s,a), ;; g(\epsilon, A^{\pi_{\theta_k} }(s,a)) \right), $$ 其中, $$ g(\epsilon, A) = { \begin{array}{ll} (1 + \epsilon) A & A \geq 0 \\ (1 - \epsilon) A & A < 0。 \end{array} $$ 优势为正:假设该状态-动作对的优势为正,在这种情况下,它对目标的贡献减少为 $$ L(s,a,\theta_k,\theta) = \min\left( \frac{\pi_{\theta}(a|s)}{\pi_{\theta_k}(a|s)}, ( 1 + \epsilon) \right) A^{\pi_{\theta_k} }(s,a). $$ 因为优势是正的,说明这个动作的价值高于平均,最大化这个式子会增大$\frac{\pi_{\theta}(a|s)}{\pi_{\theta_k}(a|s)}$, 但不会让其超过 $ 1+\epsilon$.
优势为负:假设该状态-动作对的优势为负,在这种情况下,它对目标的贡献减少为 $$ L(s,a,\theta_k,\theta) = \max\left( \frac{\pi_{\theta}(a|s)}{\pi_{\theta_k}(a|s)}, ( 1 - \epsilon) \right) A^{\pi_{\theta_k} }(s,a). $$ 因为优势是负的,最大化这个式子会减小 $\frac{\pi_{\theta}(a|s)}{\pi_{\theta_k}(a|s)}$,但不会让其超过 $ 1 - \epsilon$.
DPO(Direct Preference Optimization)
直接偏好优化 (DPO) 是一种微调大型语言模型 (LLM)以符合人类偏好的新颖方法。与涉及来自人类反馈的复杂强化学习 (RLHF) 的传统方法不同, DPO简化了流程。它的工作原理是创建人类偏好对的数据集,每个偏好对都包含一个提示和两种可能的完成方式——一种是首选,一种是不受欢迎。然后对LLM进行微调,以最大限度地提高生成首选完成的可能性,并最大限度地减少生成不受欢迎的完成的可能性。 与 RLHF 相比,DPO 具有多项优势:
- 简单性: DPO更容易实施和训练,使其更易于使用。
- 稳定性: 不易陷入局部最优,保证训练过程更加可靠。
- 效率:与 RLHF 相比, DPO 需要更少的计算资源和数据,使其计算量轻。
- 有效性: 实验结果表明,DPO在情感控制、摘要和对话生成等任务中可以优于 RLHF 。
RLHF 开源资源
开源RLHF算法库
ChatLearn
Github: https://github.com/alibaba/ChatLearn
ChatLearn 是阿里云 PAI 团队开发的大规模 Alignment 训练框架。ChatLearn 通过对模型计算逻辑的抽象,解耦了模型和计算 backend、分布式策略的绑定,提供灵活的资源调度机制,可以支持灵活的资源分配和并行调度策略。
ChatLearn的特点如下:
- 易用的编程接口: ChatLearn提供通用的编程抽象,用户只需要封装几个函数即可完成模型构造。用户只需要专注于单模型的编程,系统负责资源调度、数据流传输、控制流传输、分布式执行等。
- 高可扩展的训练方式: ChatLearn 提供 RLHF、DPO、OnlineDPO、GRPO 等 Alignment 训练,同时也支持用户自定义 model 的执行 flow,使定制化训练流程变得非常便捷。
- 多种分布式加速引擎: 用户可以使用不同的计算 backend 进行模型建模,如 Megatron-LM、DeepSpeed、vLLM 等。用户也可以组合使用不同的 backend,如用 Megatron-LM 来进行加速训练,用 vLLM 来加速推理。
- 灵活的并行策略和资源分配: ChatLearn 支持不同模型配置不同的并行策略,可以结合各模型计算、显存、通信的特点来制定不同的并行策略。同时 ChatLearn 支持灵活的资源调度机制,支持各模型的资源独占或复用,通过系统调度策略支持高效的串行/并行执行和高效的显存共享。
- 高性能: 相较于当前的 SOTA 系统,ChatLearn 在 7B+7B (Policy+Reward) 规模性能提升52%,70B+70B 规模性能提升 137%。同时,ChatLearn 支持更大规模的 Alignment 训练,例如:300B+300B。
RLHFlow
Tech Report: RLHF Workflow: From Reward Modeling to Online RLHF
Code for Reward Modeling: https://github.com/RLHFlow/RLHF-Reward-Modeling
Code for Online RLHF: https://github.com/RLHFlow/Online-RLHF
Blog: https://rlhflow.github.io/
RLHFlow 提供了完整的在线迭代RLHF全流程解决方案,包括有监督学习、奖励函数建模及基于DPO的迭代RLHF.
RLHFlow的特点在于:
- 全流程开源:RLHFlow不仅提供了完整的RLHF训练流程,包括有监督学习、奖励函数与偏好函数的建模,以及基于DPO的迭代RLHF,还将模型、代码、数据及超参数选择全部开源到GitHub与Hugging Face,供社区人员复现和进一步研究。
- 在线迭代优势:与传统的离线DPO方法相比,RLHFlow采用的在线迭代RLHF算法在性能上通常要明显更优。它不完全依赖于外部专家模型的回复,而是通过当前模型自己生成的回复组成的偏好数据集进行学习,从而更加高效地提升模型性能。
- 先进性与可复现性:基于LLaMA3-8B模型,RLHFlow实现了当前最先进的开源RLHF模型。同时,由于全流程的开源,社区人员可以轻松地复现这一结果,并在此基础上进行进一步的探索和优化。
OpenRLHF
OpenRLHF 是一个基于 Ray、DeepSpeed 和 HF Transformers 构建的高性能 RLHF 框架:
- 简单易用: OpenRLHF 是目前可用的最简单的高性能 RLHF 库之一,兼容 Huggingface 模型和数据集。
- 高性能: RLHF 训练的 80% 时间花费在样本生成阶段。得益于使用 Ray 和 Adam Offload(固定内存)可以使用大批量推理,使用 13B LLaMA2 模型的 OpenRLHF 性能是 DeepSpeedChat 的 4 倍。我们还支持 vLLM 生成加速以进一步提高生成性能。
- 分布式 RLHF: OpenRLHF 使用 Ray 将 Actor、Reward、Reference 和 Critic 模型分布到不同的 GPU 上,同时将 Adam 优化器放在 CPU 上。这使得使用多个 A100 80G GPU 和 vLLM 可以全面微调超过 70B+ 的模型 (见 architecture) 以及在多个 24GB RTX 4090 GPU 上微调 7B 模型。
TRL
Github: https://github.com/huggingface/trl
trl库是一个全栈工具,可使用监督微调步骤 (SFT)、奖励建模 (RM) 和近端策略优化 (PPO) 以及直接偏好优化(DPO)等方法来微调和对齐 Transformer 语言和扩散模型。这是一个基于Hugging Face的transformers库的强化学习库,可以用于训练Transformer语言模型。
TRLX
Github: https://github.com/CarperAI/trlx
特点:
最大支持 330 亿 参数的模型训练
支持两种强化学习算法: 近端策略优化 (PPO)和[隐式语言 Q-学习 (ILQL)](https://docs.agilerl.com/en/latest/api/algorithms/ilql.html#:~:text=Implicit Language Q-Learning (ILQL) %23 ILQL is an,(LLMs) with reinforcement leaning from human feedback (RLHF).)。
TRLX 通过 Accelerate 支持的Trainer与Hugging Face 模型无缝集成
RL4LM
Github: https://github.com/allenai/RL4LMs
特点:
- OnPolicy 策略算法:实现了PPO、A2C、TRPO 和 NLPO(自然语言策略优化)等策略算法。
- 支持因果LM(例如GPT-2/3)和seq2seq LM(例如T5、BART)的Actor-Critic 策略。
- 基准测试: 通过GRUE(General Reinforced-language Understanding Evaluation)基准测试,提供了一系列经过彻底测试和基准化的实验,涵盖了不同的NLP任务和奖励函数。
- 支持7种不同的自然语言处理(NLP)任务,包括摘要生成、生成常识推理、基于情感的文本续写、表格到文本生成、抽象问题回答、机器翻译和对话生成
- 提供20多种不同类型的NLG指标作为奖励函数,例如词汇指标(如ROUGE、BLEU、SacreBLEU、METEOR)、语义指标(如BERTSCORE、BLEURT)和特定任务指标(如PARENT、CIDER、SPICE),来自预训练分类器的分数(例如:情绪分数)
- 开源模块化库,可以方便的对接 Huggingface,模块可定制。
HALOs
Github:https://github.com/ContextualAI/HALOs
该库很方便设计新的人类感知损失函数 (HALO),以将 LLM 与大规模离线人类反馈保持一致(请阅读我们的技术报告或全文)。
该存储库借鉴了编写出色的DPO 存储库,并保留了原始版本的许多设计选择。我们引入的一些关键更改是:
- 使数据加载更加模块化,以便您可以轻松编写自己的数据加载器
- 使训练器更加模块化,以便每个模块都有自己的训练器子类
- 添加以 GPT-4 作为法官进行开放式评估的代码
- 支持不止 SFT 和 DPO 的损失(包括 KTO、PPOPPO (offline, off-policy variant) 和 SLiC)
DeepSpeed Chat
Github: https://github.com/microsoft/DeepSpeed/tree/master/blogs/deepspeed-chat
代码实现相对简洁,可以很方便的修改实现自己的想法。
开源 RLHF 模型
开源数据集
- UltraFeedback :提供了训练 Zephyr 模型数据集。
- Open Assistant 1 :社区生成的指导数据。
- Alpaca :第一个流行的合成指令数据, 使用 ChatGPT生成。
- ShareGPT :人们用来尝试在开放数据中获得类似 ChatGPT 的功能的大型数据集。
如何评价
这三个评估是 RLHF 模型相对排名的综合集合。
- ChatBotArena :众包比较网站,是开放模型和封闭模型的模型质量的首选来源。
- MT Bench :同样由 LMSYS 构建的两回合聊天评估,与大多数 LLM 的实际评估非常相关。
- AlpacaEval :第一个以GPT4 作为法官的工具,用于推广 LLM 作为法官的实践。
RLHF vs SFT
RLHF 优点
RLHF微调的效果可以概括为以下几点:
- 提高一致性:模型在不同情境下生成的文本更加一致,减少了随机性。
- 增强质量:通过优先考虑人类偏好的响应,模型生成的文本质量得到提升。
- 减少不适当内容:模型更能够识别并避免生成可能被认为是不适当或冒犯的内容。
- 更好的对齐人类价值观:模型的响应更符合人类的道德、文化和社会价值观。
- 提升用户满意度:最终,这些改进可以导致用户对模型的输出更加满意,因为它们更有可能符合用户的期望和偏好。
RLHF 的局限性
尽管 RLHF 模型在训练 AI 代理执行从机器人、视频游戏到 NLP 等复杂任务方面取得了令人印象深刻的成果,但使用 RLHF 并非没有局限性。
人类偏好数据成本高昂。收集第一手人类反馈的需求可能会造成一个代价高昂的瓶颈,限制 RLHF 流程的可扩展性。Anthropic 和 Google 都提出了 AI 反馈强化学习 (RLAIF) 的方法,即让另一个 LLM 评估模型响应来取代部分或全部人类反馈,其结果与 RLHF 相当。
人类的输入具有高度主观性。要就“高质量”的输出到底是什么达成坚定的共识,几乎是不可能的,因为人类评估者不仅会对所谓的“事实”产生不同的意见,还会对“适当的”模型行为究竟应该如何理解存在分歧。因此,人类的分歧使得据以判断模型性能的“标准答案”无法形成。
人类评估者可能会犯错,甚至故意采取对抗性和恶意行为。人类对模型的引导并不总是出于善意,他们可能怀抱着真诚的反对意见,也可能故意操纵学习过程。Wolf 等人在 2016 年的一篇论文中提出,有毒行为应被视为人机交互中的一个基本预期,并建议需要一种方法来评估人类输入的可信度。2022 年,Meta AI 发布了一篇关于对抗性人类输入的论文,研究了使用自动化方法“从高质量数据中获得最大学习效率,同时对低质量和对抗性数据具有最大稳健性”。该论文对各种“操纵”行为进行了分类,并确定了它们扭曲反馈数据的不同方式。
RLHF 存在过度拟合和偏见的风险。如果收集到的反馈来自一个非常有限的群体,那么当模型被其他群体使用,或者被用来处理与评估者持有某些偏见相关的主题时,可能会出现性能问题。
RLHF vs SFT
- 监督学习与强化学习的区别:
- 在监督学习中,模型通过观察人类编写的文本和期望的输出来学习如何回答问题或执行任务,适用于文本基础任务。
- 在强化学习中,模型生成自己的答案,然后根据评分机制(如人类)的反馈来学习如何得到高分,适用于知识寻求和创造性任务。
- 强化学习的挑战:
- 强化学习比监督学习更难,因为它需要解决“信用分配”问题,即如何将最终得分反馈到生成的每个步骤。
- 强化学习需要一个评分机制,而在语言任务中,自动评分器很难实现,通常需要人类反馈。
- 多样性论点:
- 监督学习可能导致模型复制特定的答案,而人类语言中通常有多种方式传达相同信息。RL训练可以提供更多的多样性。
- 理论论点:
- 监督学习只提供正面反馈,而强化学习允许负面反馈,这在理论上更强大,因为它允许模型形成自己的假设并从教师(Reward Model)那里获得反馈。
- 核心论点:
- 对于知识寻求型查询,强化学习是必要的,因为监督学习可能会教会模型撒谎。RL训练不鼓励模型撒谎,即使模型最初猜测了一些正确答案,长期来看,它也会因为编造的答案(可能是错误的)而得到低分,并学会依赖其内部知识回答问题或选择不回答。
- 教学模型放弃:
- 在模型不知道答案的情况下,我们希望它能放弃并回答“我不知道”。这在监督学习中很难实现,而RL提供了一种可能的解决方案。
- 模型窃取/蒸馏的影响:
- 其他模型可能会尝试其他模型的行为,但这种方法可能不适用于知识寻求型查询,因为它可能会导致模型编造事实。
- 无需人类反馈的RL:
- 尽管RL训练通常需要人类反馈,但使用大型预训练语言模型作为自动评分器, RL训练变得更加实用。
Reference
- Fine-Tuning Language Models from Human Preferences (Zieglar et al. 2019): An early paper that studies the impact of reward learning on four specific tasks.
- Learning to summarize with human feedback (Stiennon et al., 2020): RLHF applied to the task of summarizing text. Also, Recursively Summarizing Books with Human Feedback (OpenAI Alignment Team 2021), follow on work summarizing books.
- WebGPT: Browser-assisted question-answering with human feedback (OpenAI, 2021): Using RLHF to train an agent to navigate the web.
- InstructGPT: Training language models to follow instructions with human feedback (OpenAI Alignment Team 2022): RLHF applied to a general language model [Blog post on InstructGPT].
- GopherCite: Teaching language models to support answers with verified quotes (Menick et al. 2022): Train a LM with RLHF to return answers with specific citations.
- Sparrow: Improving alignment of dialogue agents via targeted human judgements (Glaese et al. 2022): Fine-tuning a dialogue agent with RLHF
- ChatGPT: Optimizing Language Models for Dialogue (OpenAI 2022): Training a LM with RLHF for suitable use as an all-purpose chat bot.
- Scaling Laws for Reward Model Overoptimization (Gao et al. 2022): studies the scaling properties of the learned preference model in RLHF.
- Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback (Anthropic, 2022): A detailed documentation of training a LM assistant with RLHF.
- Red Teaming Language Models to Reduce Harms: Methods, Scaling Behaviors, and Lessons Learned (Ganguli et al. 2022): A detailed documentation of efforts to “discover, measure, and attempt to reduce [language models] potentially harmful outputs.”
- Dynamic Planning in Open-Ended Dialogue using Reinforcement Learning (Cohen at al. 2022): Using RL to enhance the conversational skill of an open-ended dialogue agent.
- Is Reinforcement Learning (Not) for Natural Language Processing?: Benchmarks, Baselines, and Building Blocks for Natural Language Policy Optimization (Ramamurthy and Ammanabrolu et al. 2022): Discusses the design space of open-source tools in RLHF and proposes a new algorithm NLPO (Natural Language Policy Optimization) as an alternative to PPO.
- Llama 2 (Touvron et al. 2023): Impactful open-access model with substantial RLHF details.