重新思考 PPO-Clip — GRPO 时代下的各种变体
Dual-Clip PPO
Dual-Clip PPO(双裁剪近端策略优化)是标准 PPO(Proximal Policy Optimization) 算法的一种改进版本,主要目的是更有效地处理优势函数(Advantage, $A_t$)为负数的情况,从而提高算法的稳定性和性能。
标准 PPO-Clip 概述 (背景)
为了理解 Dual-Clip,我们首先回顾标准 PPO-Clip 的目标函数。PPO 目标函数(最大化形式):
$$ L^{CLIP}(\theta) = \mathbb{E}_t \left[ \min(r_t(\theta) A_t, \text{clip}(r_t(\theta), 1-\epsilon, 1+\epsilon) A_t) \right] $$
其中:
- $r_t(\theta) = \frac{\pi_{\theta}(a_t|s_t)}{\pi_{\theta_{old} }(a_t|s_t)}$ 是重要性采样比率。
- $A_t$ 是优势函数估计。
- $\epsilon$ 是裁剪超参数 (如 0.1 或 0.2)。
这个目标函数 $\min(\ldots)$ 的作用是:
- 当 $A_t \ge 0$ (动作好于平均):我们希望提高 $r_t(\theta)$ (即增加该动作的概率 $\pi_{\theta}$)。但 $\min$ 操作会限制 $r_t(\theta)$ 不能超过 $1+\epsilon$。
- 当 $A_t < 0$ (动作差于平均):我们希望降低 $r_t(\theta)$ (即减小该动作的概率 $\pi_{\theta}$)。但 $\min$ 操作会限制 $r_t(\theta)$ 不能低于 $1-\epsilon$。
标准 PPO 的缺陷 (针对 $A_t < 0$):
- 当 $A_t$ 为负时,我们希望策略更快地减少这个糟糕动作的概率(即让 $r_t(\theta)$ 趋近于 0)。然而,标准 PPO 的 $\min$ 操作会将目标函数限制在 $r_t(\theta) = 1-\epsilon$ 处,即使 $r_t(\theta)$ 进一步减小(趋近于 0),目标函数也不会再增加,导致策略对负优势的动作修改不够彻底。
Dual-Clip PPO 的核心改进
Dual-Clip PPO 引入了第三个裁剪项 $L_3$,主要作用于 $A_t < 0$ 的情况,以确保在负优势下,策略能够更严格地被惩罚。Dual-Clip PPO 目标函数(最大化形式): $$ L^{DC}(\theta) = \mathbb{E}_t \left[ \min(r_t(\theta) A_t, \text{clip}(r_t(\theta), 1-\epsilon, 1+\epsilon) A_t, \quad L_3) \right] $$
其中,第三项 $L_3$ 如下定义: $$L_3 = C \cdot A_t$$
- $C = \text{clip_ratio_c}$ 是一个新的超参数,通常设置为 2.0 ~ 5.0(原文建议 3.0)
Dual-Clip 的逻辑分解
Dual-Clip 目标函数可以分解为两种情况:
🟢 情况一:优势函数 $A_t \ge 0$ (有利动作)
$$ L^{DC}(\theta) = \mathbb{E}_t \left[ \min(r_t(\theta) A_t, \text{clip}(r_t(\theta), 1-\epsilon, 1+\epsilon) A_t) \right] $$
行为: 此时 $L_3 = C \cdot A_t \ge 0$。由于 $C > 1+\epsilon$ (通常如此),且 $A_t \ge 0$,因此 $L_3$ 会大于或等于 $r_t(\theta) A_t$ 和 $\text{clip}(\ldots) A_t$。
结论: 在 $A_t \ge 0$ 时,Dual-Clip 等同于标准 PPO-Clip。
🔴 情况二:优势函数 $A_t < 0$ (不利动作)
$$ L^{DC}(\theta) = \mathbb{E}_t \left[ \max(r_t(\theta) A_t, \text{clip}(r_t(\theta), 1-\epsilon, 1+\epsilon) A_t, \quad C \cdot A_t) \right] $$
(注:当 $A_t < 0$ 时,最大化 $\min(r A_t, \ldots)$ 相当于最大化 $\max(r A_t, \ldots)$。)
行为:
- $r_t(\theta)$ 减小 (期望行为):我们希望 $r_t(\theta)$ 变小(趋近于 0),此时 $r_t(\theta) A_t$ 和 $\text{clip}(\ldots) A_t$ 都会增大(因为 $A_t$ 是负数)。标准 PPO 的目标会被 $\text{clip}(\ldots) A_t$ 在 $r_t(\theta) = 1-\epsilon$ 处钳制住。
- $r_t(\theta)$ 增大 (不期望行为):如果 $r_t(\theta)$ 不幸增大(策略变差),目标函数会减小。
- $L_3$ 的作用:由于 $A_t < 0$ 且 $C > 1$,我们有 $C \cdot A_t$ 是一个比 $A_t$ 负得更厉害的数。当 $r_t(\theta)$ 超出 $C$ 时(即 $r_t(\theta) > C$),则 $r_t(\theta) A_t$ 会小于 $C \cdot A_t$。
通过下表对比分析在不同情况下 Dual-Clip 如何影响更新:
| 场景 | 标准 PPO 行为 | Dual-Clip 行为 |
|---|---|---|
| 好动作,适度提升 ($\hat{A} > 0$, $r \in [0.8,1.2]$) | 使用原始梯度 | 相同 |
| 好动作,大幅提升 ($\hat{A} > 0$, $r > 1.2$) | 使用裁剪梯度(限制提升) | 相同 |
| 坏动作,适度抑制 ($\hat{A} < 0$, $r < 0.8$) | 使用裁剪梯度(加强惩罚) | 相同 |
| 坏动作,大幅偏离但优势高估 ($\hat{A} < 0$, $r \gg 1.2$) | ❌ 仍允许更新(可能错误强化) | ✅ 强制限制为 $ c \cdot \hat{A} $,防止过度纠正 |
Dual-Clip 的实际限制:
在 $A_t < 0$ 时,它有效地将重要性采样比率 $r_t(\theta)$ 强行限制在了 $[0, C]$ 的范围内。如果 $r_t(\theta)$ 试图增加到超过 $C$,则 $r_t(\theta) A_t$ 会变得比 $C \cdot A_t$ 更小,$\max(\ldots)$ 操作会选择 $C \cdot A_t$。这提供了一个更严格的上限 $C$ 来惩罚那些试图大幅度增加糟糕动作概率的新策略。
核心总结: Dual-Clip PPO 的 $L_3$ 项 $(C \cdot A_t)$ 旨在防止新策略 $\pi_\theta$ 过度增加那些在旧策略 $\pi_{\theta_{old} }$ 下已经被判断为负优势的动作的概率。它提供了一个比标准 PPO 更安全的上限。
代码实现要点(Verl 框架)
# Step 1: Standard PPO clipping
pg_losses1 = -advantages * ratio
pg_losses2 = -advantages * torch.clamp(ratio, 1 - clip_low, 1 + clip_high)
clip_pg_losses1 = torch.maximum(pg_losses1, pg_losses2)
# Step 2: Upper-bound clipping (Dual-Clip)
pg_losses3 = -advantages * clip_ratio_c
clip_pg_losses2 = torch.min(clip_pg_losses1, pg_losses3)
# Step 3: Final selection based on advantage sign
pg_losses = torch.where(advantages < 0, clip_pg_losses2, clip_pg_losses1)🧠 关键点:只有当优势为负时才启用上界裁剪,因为正优势时我们希望鼓励好动作,不需要额外限制。
| 代码片段 | 作用 | Dual-Clip 关键点 |
|---|---|---|
pg_losses1 = -advantages * ratio | 计算 $-\min(r_t(\theta) A_t, \ldots)$ 中的第一项的负数形式。 | 对应 $-r_t(\theta) A_t$。 |
pg_losses2 = -advantages * torch.clamp(...) | 计算第二项的负数形式(标准裁剪)。 | 对应 $-\text{clip}(\ldots) A_t$。 |
clip_pg_losses1 = torch.maximum(pg_losses1, pg_losses2) | 标准 PPO 目标损失(负数形式):$\max(-r_t(\theta) A_t, -\text{clip}(\ldots) A_t)$。 | 对应 $\min(r_t(\theta) A_t, \text{clip}(\ldots) A_t)$ 的负数。 |
pg_losses3 = -advantages * clip_ratio_c | 计算 $L_3$ 的负数形式。 | 对应 $-C \cdot A_t$。 |
clip_pg_losses2 = torch.min(pg_losses3, clip_pg_losses1) | 结合 $L_3$ 项:$\min(-C A_t, \quad -\min(\ldots))$。这是 Dual-Clip 目标损失的负数形式。 | 这是 $A_t < 0$ 时的目标,即 $\max(C A_t, \min(\ldots))$ 的负数。 |
pg_losses = torch.where(advantages < 0, clip_pg_losses2, clip_pg_losses1) | 最终选择:$A_t < 0$ 时用 Dual-Clip 损失 (clip_pg_losses2);$A_t \ge 0$ 时用标准 PPO 损失 (clip_pg_losses1)。 | 实现了逻辑分离,确保 $L_3$ 只影响负优势下的策略更新。 |
总结
Dual-Clip PPO 通过引入 $C \cdot A_t$ 这一项,使得算法在处理不利动作时更加保守和稳定,这在一些复杂的强化学习任务(特别是自然语言处理中的人类反馈强化学习,RLHF)中表现出更好的性能。
| 特性 | 标准 PPO-Clip | Dual-Clip PPO |
|---|---|---|
| 目标 | 限制策略更新,防止步长过大。 | 在保持 PPO 优点的基础上,更严格地限制负优势下 $r_t(\theta)$ 的增加。 |
| $A_t \ge 0$ | 上限: $r_t(\theta) \le 1+\epsilon$。 | 上限: $r_t(\theta) \le 1+\epsilon$ (与标准 PPO 相同)。 |
| $A_t < 0$ | 下限: $r_t(\theta) \ge 1-\epsilon$ (减小 $r_t(\theta)$ 的动力不足)。 | 上限: $r_t(\theta) \le C$。如果 $r_t(\theta)$ 试图增加超过 $C$,会受到更严厉的惩罚 |
🎯 适用场景
Dual-Clip PPO 特别适用于以下情况:
- 稀疏奖励环境:容易出现优势估计偏差
- 长序列生成任务(如对话、代码生成):价值函数难以准确建模
- 离线强化学习(Offline RL):数据分布固定,需防止离策略更新过激
- 大模型 RLHF 训练:防止语言模型“钻牛角尖”生成奇怪但高 reward 的文本
✅ 实践建议:
- 在标准 PPO 训练不稳定时尝试启用 Dual-Clip;
- 设置
clip_ratio_c = 3.0作为起点; - 监控
pg_clipfrac_lower指标,若过高说明上界频繁触发,可能需要调整 $ c $ 或检查优势估计质量。
解耦裁剪 (Decoupled Clip)
传统的 PPO 使用对称的裁剪范围 $[1 - \epsilon, 1 + \epsilon]$PPO中的裁剪机制是保证训练稳定的核心,但它也可能带来一个严重问题:熵坍塌(entropy collapse)。它会过度抑制低概率 Token 的探索,导致模型的生成策略变得单一和确定性,缺乏多样性。这在需要创新性思维的复杂推理任务中是致命的。
为了更好地鼓励探索,DAPO 引入了Clip-Higher机制,即放宽PPO裁剪范围的上限 $ 1+ \epsilon_{\text{high} }$ , 对优势为正和为负的情况使用不同的裁剪范围,即 $[\epsilon_{\text{low} }, \epsilon_{\text{high} }]$,给低概率、但可能带来高回报的token更大的探索空间。其形式化表示为: $$ J_{\text{DAPO} }(\theta) = \mathbb{E}{(q,a) \sim P(Q), {o_i}^G \sim \pi_{\theta_{\text{old} } }(O \mid q)} \left[ \sum_{i=1}^G \frac{1}{|o_i|} \sum_{t=1}^{|o_i|} \min(r_{i,t}(\theta) A_i, \text{clip}(r_{i,t}(\theta), 1-\varepsilon_{\text{low} }, 1+\varepsilon_{\text{high} }) A_i) \right] $$
$$ s.t., 0 < \left| {o_i \mid \text{is_equivalent}(a, o_i)} \right| < G $$
动态自适应裁剪(DAC)
问题根源
让我们再次审视 PPO 和 GRPO 中使用的概率比率裁剪。其目的是防止单次更新步长过大,导致策略崩溃。约束条件为:
$$ |r_t(\theta) - 1| = \left| \frac{\pi_\theta(a_t|s_t)}{\pi_{\theta_{\text{old} } }(a_t|s_t)} - 1 \right| \leq \epsilon $$
其中,$ r_t(\theta) $ 是在 token 级别的概率比率。这个约束意味着,对于任意一个 token,新策略对其的预测概率不能与旧策略偏离太多。
现在,我们考虑一个场景:模型正在解决一个复杂的数学问题,其中某一步需要一个不常用但至关重要的符号或数字(我们称之为“稀有 token”)。在旧策略 $ \pi_{\theta_{\text{old} } } $ 中,这个 token 的概率可能非常低,比如 $ 10^{-5} $。如果这是一个正确的 token,我们希望新策略 $ \pi_\theta $ 能够大幅提升它的概率。然而,在固定裁剪的约束下,新概率的最大值被限制为 $ \pi_{\theta_{\text{old} } }(a_t|s_t) \times (1 + \epsilon) $。如果 $ \epsilon = 0.2 $,那么新概率最大也只能是 $ 1.2 \times 10^{-5} $。从 $ 10^{-5} $ 到 $ 1.2 \times 10^{-5} $ 的提升,对于整个策略的优化来说几乎是杯水车薪。
这暴露了固定裁剪的本质缺陷:它对所有 token 施加了相同的相对变化约束,却忽略了它们的绝对概率基础。对于高概率 token,小范围的相对变化是合理的;但对于极低概率的 token,这种约束会阻止模型从罕见但正确的经验中学习的机会,从而导致探索不足和学习效率低下。
DAC 的理论基础
DCPO 的作者们提出了一个洞见:裁剪边界本身不应该是固定的,而应该与 token 自身的概率动态关联。他们将约束条件从对概率比率 $ r(x) $ 的直接约束,转变为一个同时考虑了比率 $ r(x) $ 和新策略概率 $ p(x) $ 的约束。其核心思想体现在以下不等式中(为简化符号,我们将 $ p(x) $ 和 $ q(x) $ 分别代表新旧策略的 token 概率):
$$ |(r(x) - 1)p(x)| \leq \epsilon $$
这个公式的直观解释是:我们约束的是概率变化的绝对量($(r(x) - 1)q(x) = p(x) - q(x)$,这里原论文公式写作 $p(x)$ 是为了后续推导方便,其精神是相似的,即让约束与概率值本身挂钩)而非相对比率。对于一个概率很低的 token(即 $p(x)$ 和 $q(x)$ 都很小),即使其概率比率 $r(x)$ 很大,乘积 $(r(x) - 1)p(x)$ 也可能很小,从而满足约束。反之,对于一个高概率的 token,即使 $r(x)$ 只有微小的变化,这个乘积也可能很大,因此会受到更严格的限制。
这种设计契合了强化学习的探索需求:在低概率区域(未知领域)允许更大胆的探索步伐,而在高概率区域(已知领域)则采取更谨慎的微调。
DAC 边界的推导过程
接下来,我们看一下 DAC 是如何从上述理论推导出具体的、可操作的裁剪边界。
首先,将 $p(x) = r(x)q(x)$ 代入约束不等式 $|(r(x) - 1)p(x)| \leq \epsilon$,我们得到:
$$ -\epsilon_{\text{low} } \leq (r(x) - 1)r(x)q(x) \leq \epsilon_{\text{high} } $$
这里,DCPO 为上下界分别设置了不同的超参数 $\epsilon_{\text{low} }$ 和 $\epsilon_{\text{high} }$,以提供更大的灵活性。这个不等式是关于 $r(x)$ 的一个二次不等式:
$$ q(x)r(x)^2 - q(x)r(x) - \epsilon \leq 0 $$
解这个关于 $r(x)$ 的二次不等式,我们可以得到 $r(x)$ 的可行域。经过一系列代数运算,并考虑到概率比率 $r(x)$ 必须为非负,最终可以得到 $r(x)$ 的闭式解边界,也就是论文中的公式 (4):
$$ 0.5 + \frac{1}{2} \sqrt{\max\left(1 - \frac{4\epsilon_{\text{low} } }{q(x)}, 0\right)} \leq r(x) \leq 0.5 + \frac{1}{2} \sqrt{1 + \frac{4\epsilon_{\text{high} } }{q(x)} } $$
这个公式看起来复杂,但其行为趋势非常清晰:
当旧策略概率 $q(x)$ 趋近于 0 时,分母上的 $q(x)$ 使得 $\frac{4\epsilon}{q(x)}$ 这一项变得巨大。这意味着 $r(x)$ 的上界会随着 $q(x)$ 的减小而显著增大(具体行为是与 $\frac{1}{\sqrt{q(x)} }$ 成正比)。这正是我们所期望的——为低概率 token 提供了广阔的探索空间。
当旧策略概率 $q(x)$ 趋近于 1 时,根号下的项趋近于常数,使得整个边界收敛到一个较为固定的区间,与 GRPO 的行为类似,保证了在高概率区域的稳定性。
此外,为了防止 $ r(x) $ 过大导致梯度爆炸等不稳定问题,DCPO 还借鉴了 Dual-clipping 的思想,设置了一个硬性的最大上界,例如 10。
DAC vs. 固定裁剪
论文中的图 4 直观地展示了 DAC 与固定裁剪在行为上的巨大差异。
- 在固定裁剪(GRPO)中,允许的新概率 $ p(x) $ 与旧概率 $ q(x) $ 之间形成一个由直线 $ p(x) = (1 - \epsilon)q(x) $ 和 $ p(x) = (1 + \epsilon)q(x) $ 包围的狭长区域。当 $ q(x) $ 很小时,这个允许的绝对概率空间 $ (p(x) - q(x)) $ 也被压缩得非常小。
- 在动态自适应裁剪(DCPO)中,这个允许区域不再是线性的。对于低 $ q(x) $ 值,上界曲线显著向上弯曲,为 $ p(x) $ 提供了远超固定裁剪的增长空间。这片额外多出来的“探索区域”,正是 DCPO 能够更有效利用稀有但关键的 token 信息的关键所在。
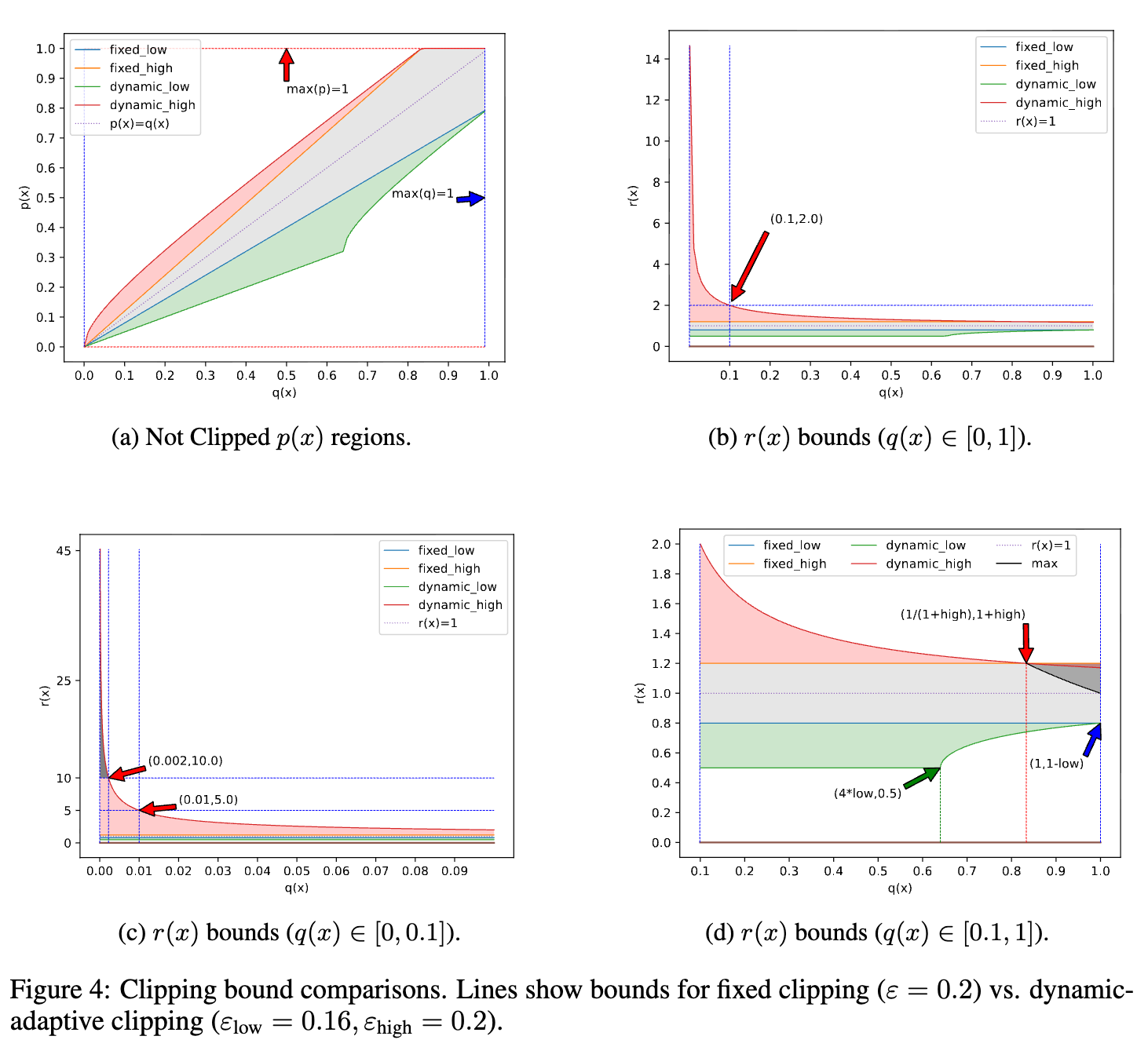
通过 DAC,DCPO 在不牺牲稳定性的前提下,极大地解放了模型的探索潜力,使得策略优化过程更加高效和有的放矢。
非对称策略优化 ASPO
策略损失函数分析
1. compute_policy_loss_vanilla 函数(PPO 基础和 Dual-Clip PPO)
这个函数实现了标准的 PPO 剪切目标(Clipped Objective),并加入了 Dual-Clip PPO 的逻辑。
- 核心逻辑:
- 计算重要性采样的比率 $r_t = \frac{\pi_{\theta}(a_t|s_t)}{\pi_{\theta_{old} }(a_t|s_t)} = \exp(\log\pi_{\theta} - \log\pi_{\theta_{old} })$。
- 计算原始策略梯度损失项 $\text{Loss}_1 = -r_t \hat{A}_t$。
- 计算剪切策略梯度损失项 $\text{Loss}_2 = -\text{clip}(r_t, 1-\epsilon, 1+\epsilon) \hat{A}_t$。
- 标准 PPO 目标是 $\text{Loss}_{\text{PPO} } = \max(\text{Loss}_1, \text{Loss}_2)$,即取 $\min(r_t \hat{A}_t, \text{clip}(r_t, 1-\epsilon, 1+\epsilon) \hat{A}_t)$。
- Dual-Clip PPO(双重剪切): 引入了额外的剪切项 $\text{Loss}_3 = -\text{clip_ratio_c} \cdot \hat{A}_t$(其中 $\text{clip_ratio_c} > 1.0$)。
- 当 优势估计 $\hat{A}_t < 0$(即当前动作不好)时,策略损失目标变为 $\text{Loss}{\text{Dual-Clip} } = \min(\text{Loss}{\text{PPO} }, \text{Loss}_3)$。这进一步限制了损失的最小化(即策略的更新),避免在新策略下不好的动作的概率被过度降低。
- 输入参数: 使用统一的 $\text{clip_ratio}$,并可选择性地使用 $\text{clip_ratio_low}$、$\text{clip_ratio_high}$ 进行不对称剪切,以及 $\text{clip_ratio_c}$ 用于 Dual-Clip。
2. compute_policy_loss_archer 函数(ARCHER 策略优化)
compute_policy_loss_archer 引入了 ARCHER (Adaptive Reward-Conditioned High-Entropy Regularization) 的策略优化思想。它主要体现在 动态剪切范围 和 基于优势符号的损失分离处理 两个方面。
- 实现优化的具体改变:
🚀 改变 1: 引入基于熵(Entropy)的 动态剪切范围
函数引入了 high_entropy_mask 和四个不同的剪切参数:
negative_low_entropy_clip_ratio_lownegative_high_entropy_clip_ratio_lowpositive_low_entropy_clip_ratio_highpositive_high_entropy_clip_ratio_high
它根据 优势 $\hat{A}_t$ 的符号 和 high_entropy_mask 动态地计算 $\text{clip_ratio}$:
| 优势符号 (A^t) | high_entropy_mask | 剪切范围 (Ratio rt) | 参数 | 目的 |
|---|---|---|---|---|
| 负 ($\hat{A}_t < 0$) | True (高熵) | $[1 - \mathbf{L}_N, \infty)$ | $\mathbf{L}_N = \text{negative_low_entropy_clip_ratio_low}$ | 相对保守地降低 $r_t$ 的下限。 |
| 负 ($\hat{A}_t < 0$) | False (低熵) | $[1 - \mathbf{H}_N, \infty)$ | $\mathbf{H}_N = \text{negative_high_entropy_clip_ratio_low}$ | 积极地降低 $r_t$ 的下限,允许更大的负向更新(即更大幅度地降低不好的动作的概率)。 |
| 正 ($\hat{A}_t > 0$) | True (高熵) | $(-\infty, 1 + \mathbf{L}_P]$ | $\mathbf{L}_P = \text{positive_low_entropy_clip_ratio_high}$ | 相对保守地提高 $r_t$ 的上限。 |
| 正 ($\hat{A}_t > 0$) | False (低熵) | $(-\infty, 1 + \mathbf{H}_P]$ | $\mathbf{H}_P = \text{positive_high_entropy_clip_ratio_high}$ | 积极地提高 $r_t$ 的上限,允许更大的正向更新(即更大幅度地增加好的动作的概率)。 |
优化效果: 这是一个 自适应的策略更新。
- 对于 低熵(即策略分布较集中,可能更确定或更自信)的动作,允许使用 更大的 $\epsilon$(即 $\mathbf{H}_N$ 和 $\mathbf{H}_P$ 通常大于 $\mathbf{L}_N$ 和 $\mathbf{L}_P$),使得策略更新可以更激进。
- 对于 高熵(即策略分布较分散,可能更不确定)的动作,使用 更小的 $\epsilon$,使得策略更新更保守,以维持探索。
🚀 改变 2: 基于优势符号的 策略损失项分离处理
函数将策略损失项 根据 $\hat{A}_t$ 的符号 分为 $\text{negative_pg_losses}$ 和 $\text{positive_pg_losses}$ 两部分,并分别处理 Dual-Clip 逻辑。
- 优势 $\hat{A}_t < 0$ (负向更新):
negative_pg_losses_clip:使用动态 $\text{negative_clip_ratio}$ 的 PPO 剪切项。- 引入 $\text{negative_dual_clip_ratio} = \min(\text{negative_clip_ratio}, \text{negative_clip_ratio_c})$。
negative_pg_losses_dual:当 $\text{negative_clip_ratio} > \text{negative_clip_ratio_c}$ 时激活。- 不同之处:
compute_policy_loss_vanilla的 Dual-Clip 项是 $-\hat{A}_t \cdot \text{clip_ratio_c}$,而compute_policy_loss_archer的 Dual-Clip 项是 $-\hat{A}_t \cdot \text{negative_dual_clip_ratio.detach()} \cdot \log\pi$,这看起来是一个不同的实现,它结合了 $\text{negative_dual_clip_ratio}$ 和 $\log\pi$。
- 优势 $\hat{A}_t > 0$ (正向更新):
positive_pg_losses_clip:使用动态 $\text{positive_clip_ratio}$ 的 PPO 剪切项。- 引入 $\text{positive_dual_clip_ratio} = \min(1 / \text{positive_clip_ratio}, \text{positive_clip_ratio_c})$。
positive_pg_losses_dual:当 $1 / \text{positive_clip_ratio} > \text{positive_clip_ratio_c}$ 时激活。- 不同之处: 为正向优势引入了一个 Dual-Clip 机制,但这里的实现逻辑比较复杂,似乎是在 $\text{clip}(1/r_t, 1, \text{clip_ratio_c})$ 上进行操作,而不是在 $r_t$ 上,这进一步限制了 $r_t$ 的上限,避免过度增加好的动作的概率。
优化总结
compute_policy_loss_archer 函数主要实现了以下优化:
- 分段式、自适应剪切(Entropy-Conditioned Clipping): 根据动作的 熵水平 和 优势符号 动态调整 PPO 的剪切范围 ($\epsilon$。这使得策略在不确定(高熵)的动作上更新保守,在确定(低熵)的动作上更新激进,从而平衡探索和利用。
- 正负优势的 Dual-Clip 分离: 提供了独立的 $\text{negative_clip_ratio_c}$ 和 $\text{positive_clip_ratio_c}$,用于分别控制负向更新和正向更新的 Dual-Clip 行为,实现更精细的策略控制。
- 对正向更新的限制: 引入了一种 针对 $\hat{A}_t > 0$ 的 Dual-Clip 机制,旨在防止新策略过度偏离旧策略,即使是在有利的动作上,这有助于提高训练稳定性。