Verl 相关特性介绍
VeRL框架的论文([HybridFlow]):https://arxiv.org/pdf/2409.19256
VeRL框架的官方解读:https://mp.weixin.qq.com/s/JYQQs2vqnhRz82rtDI-1OQ
知乎上的一些阅读笔记:
Verl 介绍
1. RL(Post-Training)复杂计算流程给 LLM 训练带来全新的挑战
在深度学习中,数据流(DataFlow)是一种重要的计算模式抽象,用于表示数据经过一系列复杂计算后实现特定功能。神经网络的计算就是典型的 DataFlow ,可以用计算图(Computational Graph)来描述,其中节点代表计算操作,边表示数据依赖。
大模型 RL 的计算流程比传统神经网络更为复杂。在 RLHF 中,需要同时训练多个模型,如 Actor 、Critic 、参考策略(Reference Policy)和奖励模型(Reward Model),并在它们之间传递大量数据。这些模型涉及不同的计算类型(前向反向传播、优化器更新、自回归生成等),可能采用不同的并行策略。
传统的分布式 RL 通常假设模型可在单个 GPU 上训练,或使用数据并行方式 [4,5],将控制流和计算流合并在同一进程中。这在处理小规模模型时效果良好,但面对大模型,训练需要复杂的多维并行,涉及大量分布式计算,传统方法难以应对。
2. HybridFlow 解耦控制流和计算流,兼顾灵活高效
大模型 RL 本质上是一个二维的 DataFlow 问题:high-level 的控制流(描述 RL 算法的流程)+ low-level 的计算流(描述分布式神经网络计算)。
近期开源的 RLHF 框架,如 DeepSpeed-Chat [6]、OpenRLHF [7] 和 NeMo-Aligner [8],采用了统一的多控制器(Multi-Controller)架构。各计算节点独立管理计算和通信,降低了控制调度的开销。然而,控制流和计算流高度耦合,当设计新的 RL 算法,组合相同的计算流和不同的控制流时,需要重写计算流代码,修改所有相关模型,增加了开发难度。
与此前框架不同,HybridFlow 采用了混合编程模型,控制流由单控制器(Single-Controller)管理,具有全局视图,实现新的控制流简单快捷,计算流由多控制器(Multi-Controller)负责,保证了计算的高效执行,并且可以在不同的控制流中复用。
尽管相比纯粹的多控制器架构,这可能带来一定的控制调度开销,但 HybridFlow 通过优化数据传输,降低了控制流与计算流之间的传输量,兼顾了灵活性和高效性。
3. 系统设计之一:Hybrid Programming Model (编程模型创新)
框架逻辑分析
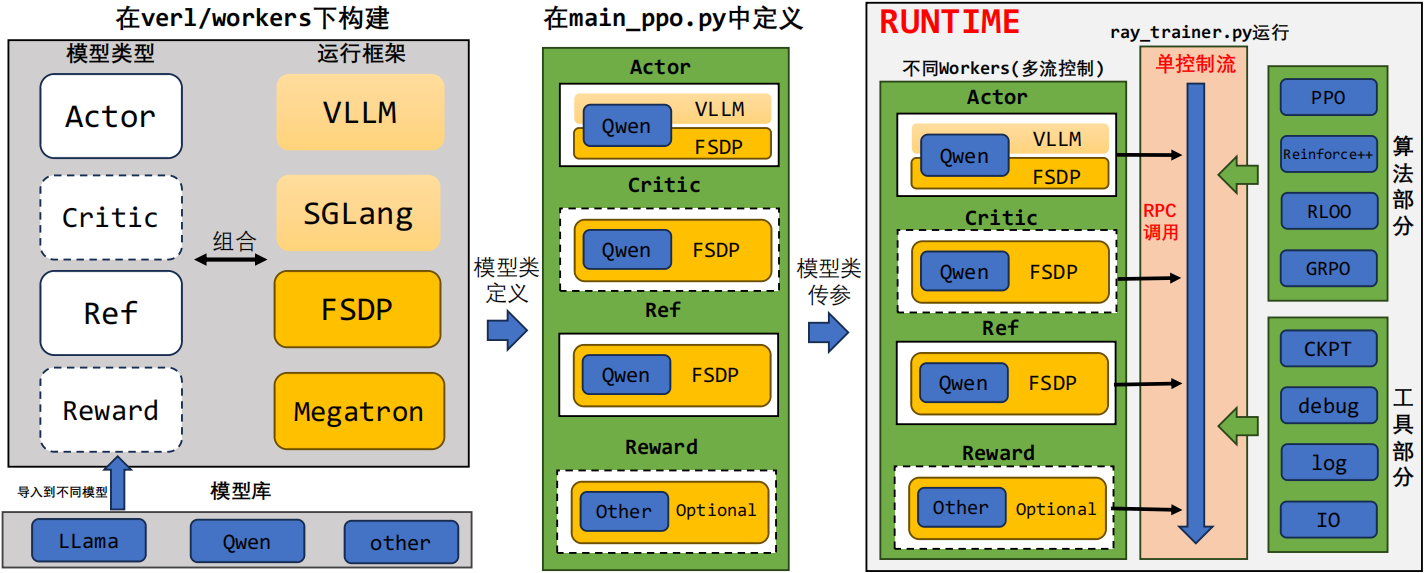
这是目前verl训练框架的配置情况,对于不同的训练角色,可以选择不同的预训练模型及训练后端的支持(多控制器)。随后将他们与main_ppo.py中对应的角色进行绑定,然后以参数的形式传入到ray_trainer.py中进行调用。对于trainer文件中实际是以一个单控制流函数fit()的方式来进行,只需要从对应的模型中获得计算值的情况,然后再导入到对应的算法模块与工具模块中,就可以快速的开展RL训练任务。
1.运行框架中浅黄色表示推理框架,深黄色表示训练框架
2.虚线模块表示在训练过程中并不一定被需要,可以结合训练算法进行删减
3.Reward模型有基于模型与基于规则的方法,并且目前训练推理框架可能都有支持,所以暂时写为optional。
4.Actor模块由于要进行rollout和training两个阶段,因此会在训练和推理框架之间进行切换(verl中在sharding_manager文件目录下)
3.1 封装单模型分布式计算
在 HybridFlow 中,每个模型(如 Actor、Critic、参考策略、奖励模型等)的分布式计算被封装为独立的模块,称为模型类。
这些模型类继承于基础的并行 Worker 类(如 3DParallelWorker 、FSDPWorker 等),通过抽象的 API 接口,封装了模型的前向、反向计算、优化器更新和自回归生成等操作。该封装方式提高了代码的复用性,便于模型的维护和扩展。
对于不同的 RL 控制流,用户可以直接复用封装好的模型类,同时自定义部分算法所需的数值计算,实现不同算法。当前 HybridFlow 可使用 Megatron-LM [13] 和 PyTorch FSDP [14] 作为训练后端,同时使用 vLLM [15] 作为自回归生成后端,支持用户使用其他框架的训练和推理脚本进行自定义扩展。
3.2 灵活的模型部署
HybridFlow 提供了资源池(ResourcePool)概念,可以将一组 GPU 资源虚拟化,并为每个模型分配计算资源。不同的资源池实例可以对应不同设备集合,支持不同模型在同一组或不同组 GPU 上部署。这种灵活的模型部署方式,满足了不同算法、模型和硬件环境下的资源和性能需求。
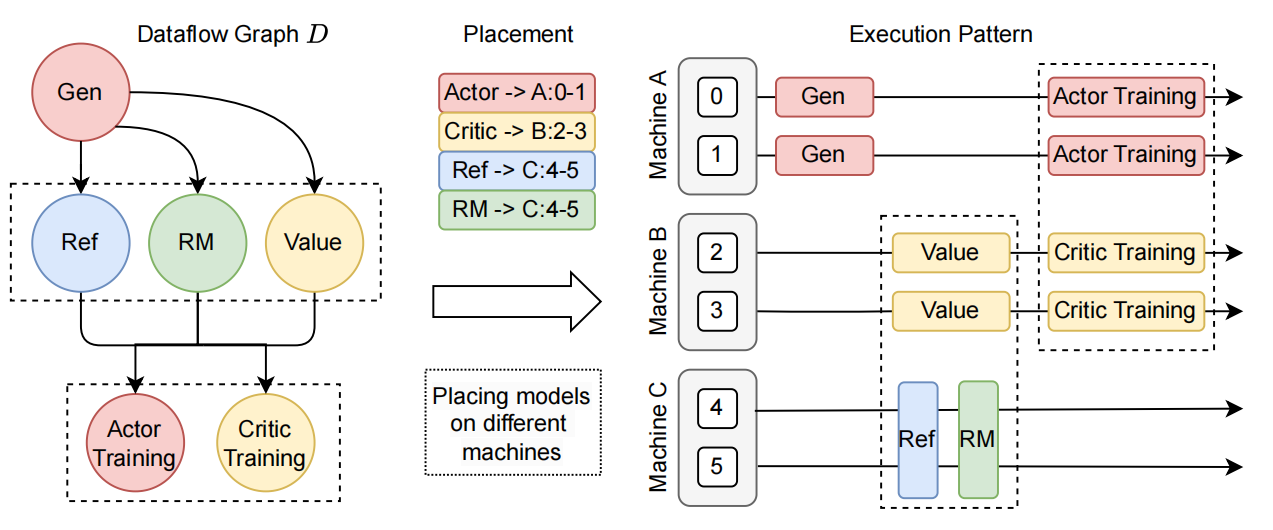
首先构建的四类模型,会通过Ray,映射放置到不同的机器上。随后
(1)先使用vllm框架和prompt对Actor先进行response的输出(使用专用推理框架可以让推理的速度更快)。
(2)然后将输出的结果输入给其他三个框架进行运行(一般使用训练框架,因为训练框架可以避免精度问题),以获得在RL算法(例如PPO,GRPO等框架)所需要的计算输入。
(3)最后结合计算结果,再使用训练框架来对Actor和Critic模型进行训练。
3.3 统一模型间的数据切分
在大模型 RL 计算流程中,不同模型之间的数据传输涉及复杂的多对多广播和数据重分片。
为解决该问题,HybridFlow 设计了一套通用数据传输协议(Transfer Protocol),包括收集(collect)和分发(distribute)两个部分。
通过在模型类的操作上注册相应的传输协议,比如:@register(transfer_mode=3D_PROTO),HybridFlow 可以在控制器层(Single-Controller)统一管理数据的收集和分发,实现模型间数据的自动重分片,支持不同并行度下的模型通信。
HybridFlow 框架已经支持多种数据传输协议,涵盖大部分数据重切分场景。同时,用户可灵活地自定义收集(collect)和分发(distribute)函数,将其扩展到更复杂的数据传输场景。
3.4 支持异步 RL 控制流
在 HybridFlow 中,控制流部分采用单控制器架构,可灵活实现异步 RL 控制流。
当模型部署在不同设备集合上时,不同模型计算可并行执行,这提高了系统的并行度和效率。对于部署在同一组设备上的模型,HybridFlow 通过调度机制实现了顺序执行,避免资源争夺和冲突。
3.5 少量代码灵活实现各种 RL 控制流算法
得益于混合编程模型的设计,HybridFlow 可以方便地实现各种 RLHF 算法,如 PPO [9]、ReMax [10]、Safe-RLHF [11]、GRPO [12] 等。用户只需调用模型类的 API 接口,按算法逻辑编写控制流代码,无需关心底层的分布式计算和数据传输细节。
例如,实现 PPO 算法只需少量代码,通过调用 actor.generate_sequences 、critic.compute_values 等函数即可完成。同时,用户只需要修改少量代码即可迁移到 Safe-RLHF 、ReMax 以及 GRPO 算法。
4. 系统设计之二:3D-HybridEngine (训练推理混合技术)降低通信内存开销
在 Online RL 算法中,Actor 模型需要在训练和生成(Rollout)阶段之间频繁切换,且两个阶段可能采用不同并行策略。
具体而言,训练阶段,需要存储梯度和优化器状态,模型并行度(Model Parallel Size, MP)可能相应增高,而生成阶段,模型无需存储梯度和优化器状态,MP 和数据并行度(Data Parallel Size, DP)可能较小。因此,在两个阶段之间,模型参数需要重新分片和分配,依赖传统通信组构建方法会带来额外通信和内存开销。
此外,为了在新的并行度配置下使用模型参数,通常需要在所有 GPU 之间进行全聚合(All-Gather)操作,带来了巨大的通信开销,增加了过渡时间。
为解决这个问题,HybridFlow 设计了 3D-HybridEngine ,提升了训练和生成过程效率。
注:3D-HybridEngine 一次迭代的流程
3D-HybridEngine 通过优化并行分组方法,实现了零冗余的模型参数重组,具体包括以下步骤:
- 定义不同的并行组
在训练和生成阶段,3D-HybridEngine 使用不同的三维并行配置,包括:流水线并行(PP)、张量并行(TP)和数据并行(DP)的大小。训练阶段的并行配置为 𝑝-𝑡-𝑑 。在生成阶段,我们新增一个新的微数据并行组(Micro DP Group,𝑑𝑔),用于处理 Actor 模型参数和数据的重组。生成阶段的并行配置为 𝑝𝑔-𝑡𝑔-𝑑𝑔-𝑑 。
- 重组模型参数过程
通过巧妙地重新定义生成阶段的并行分组,可以使每个 GPU 在生成阶段复用训练阶段已有的模型参数分片,避免在 GPU 内存中保存额外的模型参数,消除内存冗余。
- 减少通信开销
参数重组过程中,3D-HybridEngine 仅在每个微数据并行组(Micro DP Group)内进行 All-Gather 操作,而非所有 GPU 之间进行。这大大减少了通信量,降低过渡时间,提高了整体的训练效率。
Verl 源码解析
核心代码阅读
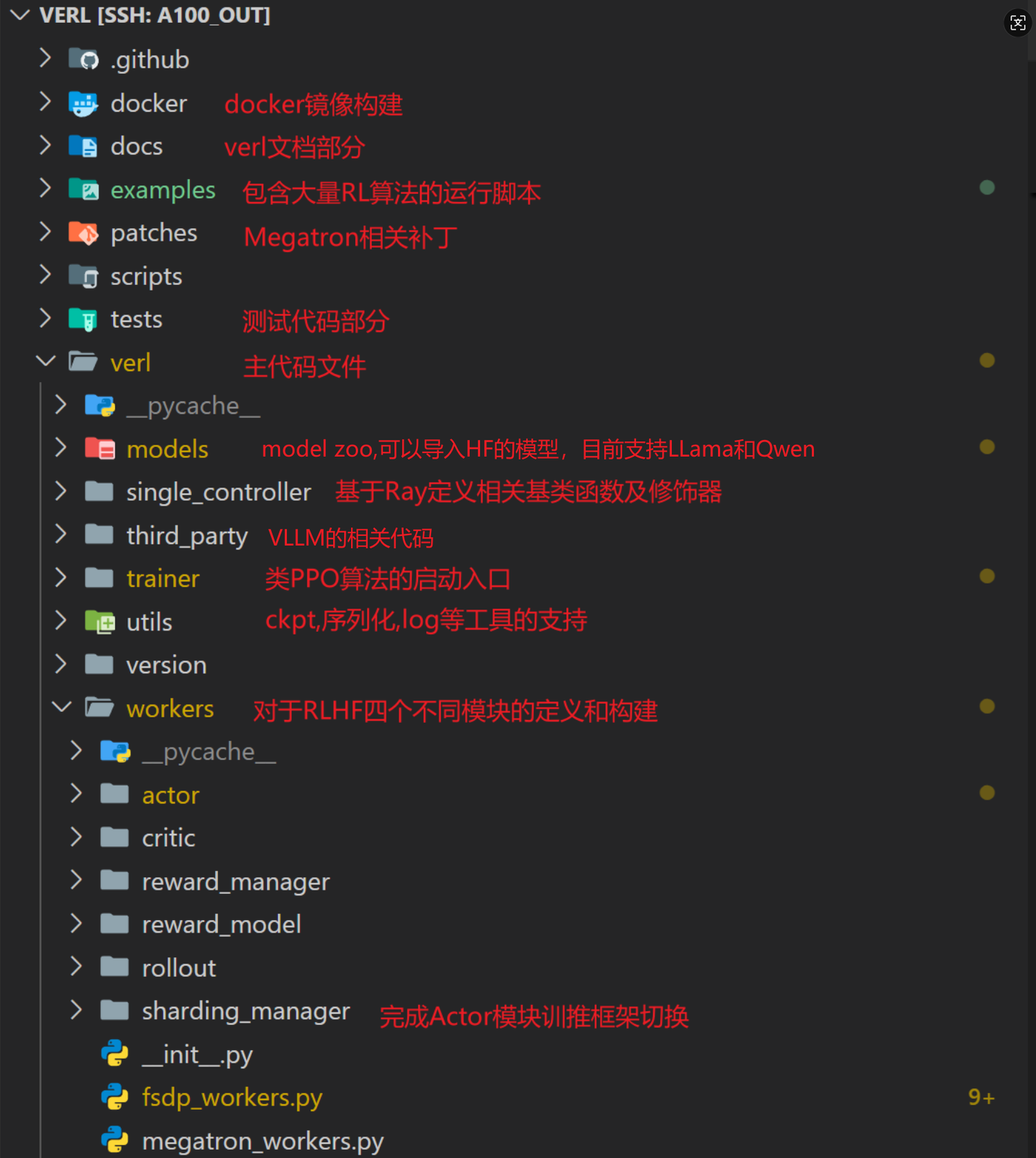
代码结构
VeRL仓库的核心代码逻辑(verl)树如下所示:
Trainer 组件
trainer文件下主要放置了核心的训练逻辑,主要封装了整体RL算法的控制流程。目前支持的训练逻辑包括:
1. SFT
fsdp_sft_trainer.py:基于FSDP(dpsd zero3)实现的SFT训练逻辑,verl支持在RL训练前通过sft来cold-start policy;
基本上就是一个Torch-native的FSDP标准Trainer的实现;
基于ulysess实现了sft训练时对超长序列的序列并行支持;
Devicemesh:torch2.2引入的新机制,用于管理设备&进程组之间的NCCL数据通信。Verl借用了该机制简化了对于数据传输的控制逻辑。
- 文档:https://pytorch.org/tutorials/recipes/distributed_device_mesh.html
- Devicemesh对于管理各种并行(模型、数据并行)时设备之间的通信非常有用,不再需要手撸进程组,以及手动管理rank和拓扑了,方便很多;
2. PPO/GRPO/Reinforce++/RLOO等RL算法
main_ppo.py:RL算法的入口程序,主要有以下几个主要功能:
- 选择奖励函数(model-based or rule-based),基于Reward Manager以及用户自定义的打分规则(一般定义在utils/reward_score目录下);
- 可以根据数据集中每条样本指定的reward_style,选择针对性的reward func;
选择训练后端(FSDP or Megatron):
- Verl支持基于FSDP和Megatron两套后端进行模型的训练和前向传播推理,后者主要在模型规模特别大的时候,有一定的性能优势,但是自定义的修改比较麻烦,支持新架构比较麻烦,一般学术界FSDP后端就够用了。工业界追求极致性能时会需要megatron,可以进行许多定制化的优化来提升训练吞吐;
- 调用RayPPOTrainer进行具体的训练流程;
- 先调用trainer的init_workers函数初始化各个rl角色的workergroup,然后调用fit函数执行实际的训练
RayPPOTrainer.py:
- 初始化RL中的各个Role:RL算法中本身涉及较多角色(Actor、Critic、RM、Ref)的协作,需要预先定义好各个模型的角色,涉及resource_pool的定义和分配、workerdict和workergroup的初始化和分配;
- WorkerGroup机制支持了每类colocate model group的具体实现,包含:
- actor_rollout_wg:支持actor、generator二者互相切换(通过reload/offload params和reshard)的hybrid engine;
- critic_wg(可选):支持critic角色,仅ppo需要;
- ref_policy_wg(可选):支持reference角色,开启kl需要;
- rm_wg(可选):支持RM角色,model based reward需要;
- 由init_workers方法初始化资源池和各个worker group;
- ResourcePoolManager:资源池管理,封装ray的placement_group,将指定的角色合理分配到设备上;
实现了一些PPO算法计算loss所需要的函数,如:
apply_kl_penalty:计算PPO的token-level kl reward;
KL loss是在core_algos.py里面实现的;
compute_advantage:计算优势函数的逻辑,核心算法依然是在core_algos.py里面实现的;
VeRL同时支持PPO/GRPO/Reinforce++/RLOO/Remax等算法,这些RL算法的核心区别点在于advantage是如何计算的(critic预测baseline,group计算baseline,batch内留一法等等),因此VeRL选择将adv_estimator单独出一套逻辑,主体同样是放在core_algos.py内部;
实现了一些timer,metric计算的函数(compute_data_metrics、compute_timing_metrics),以及save/load等断点续训和ckpt保存的逻辑(_save_checkpoint、_load_checkpoint),还有validate的逻辑(_validate)和dp负载均衡的逻辑(_balance_batch)的逻辑等等;
fit方法实现了rl算法的完整的training loop,调用了各个worker进行实际的计算;
需要注意,fit方法是在单进程运行的,因此如果是在ray cluster上运行,尽可能不要把trainer调度在head节点上,可能负载压力会比较大;
3. main_generation.py 适用于离线生成
4. main_eval.py 评估代码
5. core_algos.py
core_algos.py 文件也是一个非常重要的文件,包含了:
- 各种loss的计算逻辑:
- policy_loss(训练policy model,即actor),
- value_loss(训练value model,即critic),
- entropy_loss(policy model训练的额外trick loss,通过熵正则提升采样多样性),
- kl_loss(grpo等算法会把kl loss外置);
- 各种advantage的计算逻辑:
- 各个rl算法的核心区分点主要在adv如何实现,这里实现了各种rl算法的adv estimation;
各类RL训练过程中的工程和算法超参可以参考doc:Config Explanation
Workers组件
workers文件夹下定义了RL中各个角色的worker(high-level,主要负责描述逻辑),以及各个角色计算时实际依赖的worker(low-level,主要负责描述运算);
这里再回顾一下:worker被workerdict封装后,每个设备(GPU)会运行一个。一个colocate的RL 角色依托WorkerGroup进行管理,每个workergroup下管理着一组远程运行的 workers。WorkerGroup 作为single controller与 workers 之间的中介。我们将 worker 的方法绑定到 WorkerGroup 的方法上,通过装饰器实现具体的方法执行/数据分发的逻辑。
1. fsdp_workers.py:
基于FSDP训练后端,定义了一系列RL训练过程中可能使用的Worker。这些workers是基于实际负责运算的worker(后面会介绍)所进行的进一步封装;
ActorRolloutRefWorker:
- 可以选择扮演单独的RL中的Actor(Policy Model)、Rollout(负责generate response)、Reference(负责提供ref_log_prob计算KL);
- 可以选择基于hybrid engine,同时扮演多个角色,然后verl通过参数的offload/reload/reshard进行灵活的切换;
- 目前支持了Data Parallelism(fsdp)和Sequence Parallelism(context维度,基于ulysess实现);
- 关键方法:
init_model:根据config指定的model类型,来初始化当前worker:
update_actor:
- 基于DataParallelPPOActor的update_policy,计算policy-Loss并更新Policy模型的权重;
- 基于ulysses_sharding_manager支持sequence parallel的数据前处理和后处理,从而实现序列并行;
generate_sequences:
- 基于vllm封装的rollout引擎,推理生成数据,使用rollout_sharding_manager管理数据的形状,match rollout引擎的切分;
- compute_log_prob:基于actor的训练引擎,同步计算old_logprobs,方便进行importance sampling;
compute_ref_log_prob: 基于训练引擎,计算ref_logprobs,方便计算kl constraint;
save_checkpoint/load_checkpoint:实现模型参数的offload/reload,以及保存到外部硬盘;
_build_model_optimizer:
- 指定optim_config一般是actor,需要基于FSDP进行训练,需要初始化fsdp wrap的模型(进一步传给DataParallelPPOActor封装)、optimizer和lr_scheduler;
- 不指定optim_config一般是ref,统一推理引擎和训练引擎,确保KL计算的数值准确性;
所有的涉及运算的函数,都有dispatch_mode装饰器,以实现workergroup内部的数据传输逻辑(single-controller的设计模式);
CriticWorker:
- 和ActorRolloutRefWorker逻辑大体一致,只不过基于的后端是DataParallelPPOCritic;
- 不需要rollout,且额外多出了compute_values这个操作,通过value head计算token-level value以便PPO计算Adv;
RewardModelWorker:
- 基于模型的RM打分实现;
2. megatron_workers.py:
megatron_workers.py 基于megatron后端实现的RL workers;
- 基于megatron支持4D并行,DP、TP、SP、PP;
- 核心逻辑基本和FSDP版本一致,但是底层逻辑需要适配megatron框架;
接下来,我们看看具体的Actor运算Worker,它们被放置在当前目录的子文件夹下,默认都有fdsp(torch-native)和megatron两个写法的版本,以兼容两套训练引擎:
Actor:
- RL算法(如PPO)中扮演Actor角色的Worker(Reference model也可以借用);
- 核心功能有:
- compute_log_prob:为了计算KL或者Importance Sampling,前向传播推理得到各token位置的logits和对数概率;
- update_policy:基于预先计算好的advantage,计算policy loss、entropy loss和kl loss,然后更新policy model;
Critic:
- Actor-Critic-based RL算法(如PPO)中扮演Critic角色的Worker;
- 核心功能有:
- compute_values:计算Values,参与计算PPO算法的advantage;
- update_critic:计算value loss,然后更新value model;
Reward_model:
- 基于Model-based的打分模型,计算response-level reward;
- 核心功能主要就是compute_reward;
- rule-based reward不需要;
Rollout:
- 核心功能就是在训练时候rollout response,主要函数为generate_sequences;
- 支持不同的生成引擎后端:
- 原生的rollout逻辑,最简单的从logits->softmax->sampling的逻辑;
- huggingface TGI后端的rollout逻辑;
- vllm的rollout逻辑;
- 目前开源版本的推理引擎以vllm为主,但sglang也在接入中;
- 基于third_party中修改的vllm engine进行推理;
- repreat采样没有使用n_samples参数而是直接repeat_interleave输入,多次生成;
- old_log_probs没有使用vllm引擎得到的结果,为了确保importance sampling和kl divergence计算的准确性,要用训练引擎(FSDP或者Megatron)统一计算,避免引擎不同带来的误差;
此外,该文件夹下还有sharding_manager,主要是负责管理不同的parallelism下的sharding,包括:
- data sharding(preprocess_data,postprocess_data);
- device mesh的管理;
- 模型参数的reload & offload逻辑(基于上下文管理器)
Single Controller组件
实现verl的核心混合编程模型的重点,即基于single controller机制去管理RL的控制流;
Worker:方便管理worker进程在workergroup进程组内部的信息(如rank_id和world_size),以及资源分配的信息;
ResourcePool:管理某个资源池,包括池内节点信息和进程信息;
Workergroup:管理多个worker所组成的workergroup,如负责管理data parallelism。最重要的函数是_bind_worker_method:
- 将用户定义的方法bind到WorkerGroup实例上;
- 处理被@register装饰器修饰的方法;
- 配置数据分发/收集模式和执行模式;
- 同步执行当前group内所有worker的该方法,并且根据分发&执行模式正确管理执行逻辑和数据传输逻辑;
Decorator:主要定义了各种worker的数据分发和函数执行模式的装饰器,装饰后,workergroup在执行worker的方法时,将会通过装饰器自动配置数据分发和执行的模式;
Ray:该处代码主要是基于ray后端,去管理worker(WorkerDict)和workergroup(RayWorkerGroup)。通过Python语法糖,实现了worker的method rebind,以让同一个workergroup在不同的rl角色之间灵活切换;
Models组件
主要包含常见模型结构(主要是llama结构和qwen2结构,允许用户集成更多的结构)的定义,包括:
Transformers版本的模型结构定义:
- FSDP版本的RL训练推理、Rollout引擎、导出模型权重需要使用;
- 自定义新的模型结构:Add models with the FSDP backend
Megatron版本的模型结构定义:
- Megatron版本的RL训练推理需要使用;
- Megatron版本需针对4D Parallelism做较多的适配;
- 自定义新的模型结构:Add models with the Megatron-LM backend
Utils组件
在utils文件夹下定义了一些重要的工具和组件,包括:
Dataset:
- 主要包括:rl、sft和rm的dataset;
- 处理数据集中的各个key,包括取出了制作好的parquet里面的prompt列,apply_chat_ml + tokenize后设为input_ids;
- VeRL的dataset和dataloader没有和训练过程强绑定,可以在训练过程中比较轻松地做到dataloader的重载或者修改,所以实现一些功能会比较方便,如动态的课程学习等;
Debug:
- 主要包括:监控Performance(如GPU usage)和Trajectory(即保存rollout结果)的逻辑;
Logger:
- 顾名思义,主要是将一些监控指标输出到指定的位置(console或者wandb)的逻辑;
Megatron:
- 主要是为了在verl中使用megatron所编写的一些utils,以及对原有megatron实现适配verl所进行的一些patch;
Reward_score:
- 这里主要存着适配不同的rule-grader所编写的逻辑,包括各种parse answer的逻辑和compare answer的逻辑;
其他:如checkpoint管理的工具、hdfs文件管理的工具、支持ulysess/seq_balancing等feature的工具等;
third_party组件
目前主要是对开源的推理引擎vLLM,做了一些针对verl进行的定制化适配和封装(如SPMD); 主要是继承了原始的vllm,以支持verl所需要的一些功能,比如取出特定计算结果、更好地支持hybrid engine(如sync/offload params,device mesh管理,weight loader的兼容...)等;
Protocol组件
为了支持RL过程中更好的数据管理和传输,verl设计了DataProto这一数据结构,主要包括:
- 基于TensorDict所实现的batch,用于管理a dictionary of tensors;
- 基于Dict所实现的meta_info,用于管理当前DataProto的信息;
- 其余non-tensor数据,存在non_tensor_batch中;
- 以及DataProto使用所需要的各类数据管理逻辑,如pop、chunk、union、concat、rename、reorder等等;
DataProtoFuture则是为了支持DataProto的异步处理而构造的,支持负责reduce的collect_fn和负责scatter的dispatch_fn,从而方便worker的非阻塞执行。