OpenRLHF源码解读OpenRLHF源码解读
1. 理解PPO 训练流程
1.1 代码结构
OpenRLHF
|--examples //示例启动脚本
|----scripts
|------train_ppo_llama.sh //训练PPO
|------train_sft_llama.sh //SFT
|------train_rm_llama.sh //训练reward model
|------...... //还有很多 包括其他训练方法、分布式训练等
|--openrlhf //核心代码块
|----cli //训练入口函数
|----datasets //数据集处理相关
|----models //定义模型、loss相关
|----trainer //定义训练方法
|----utils //工具类、函数定义1.2 PPO源码解读
OpenRLHF提供了多种Post-training方法,本文只围绕PPO相关源码做解读.
首先通过几张图概述PPO训练的全过程。
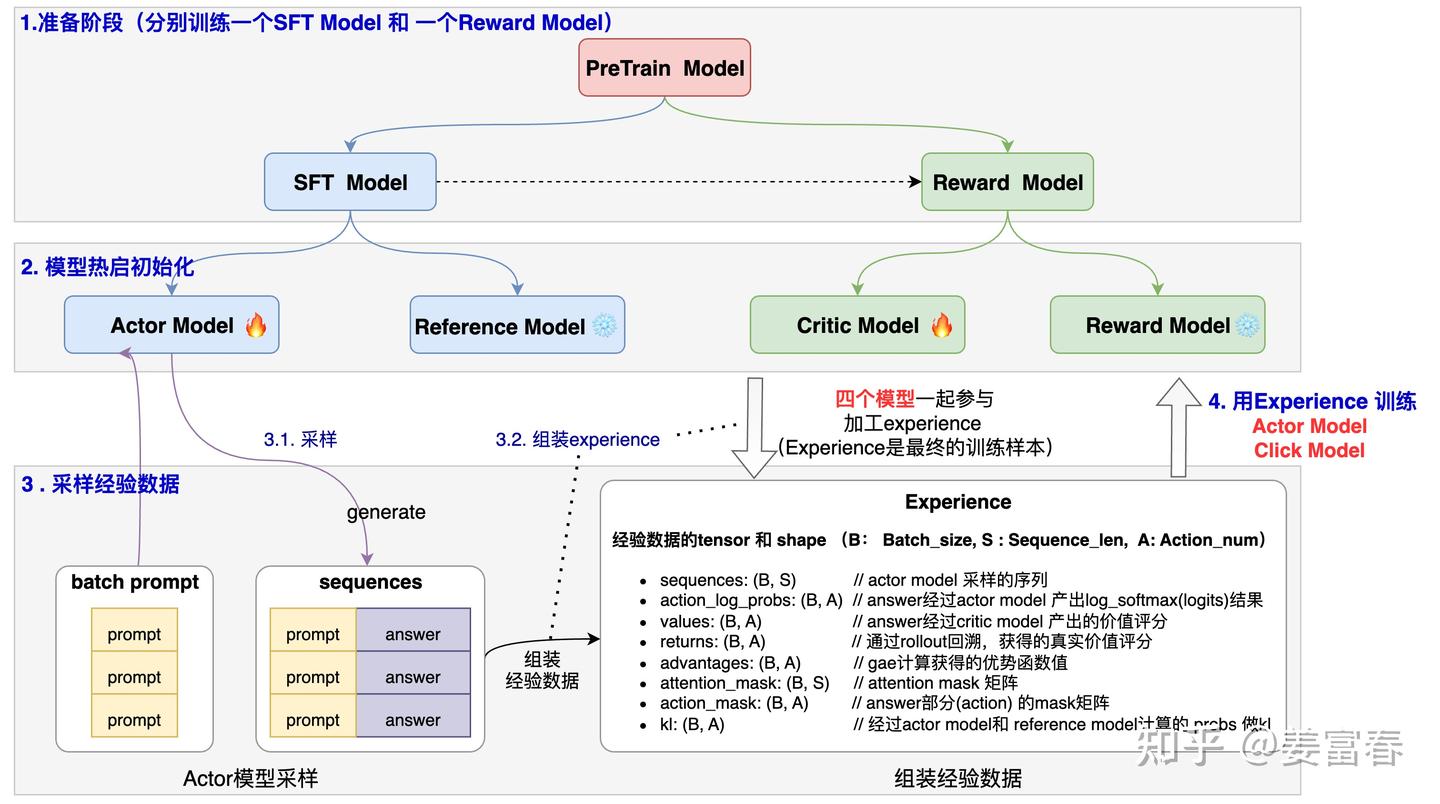
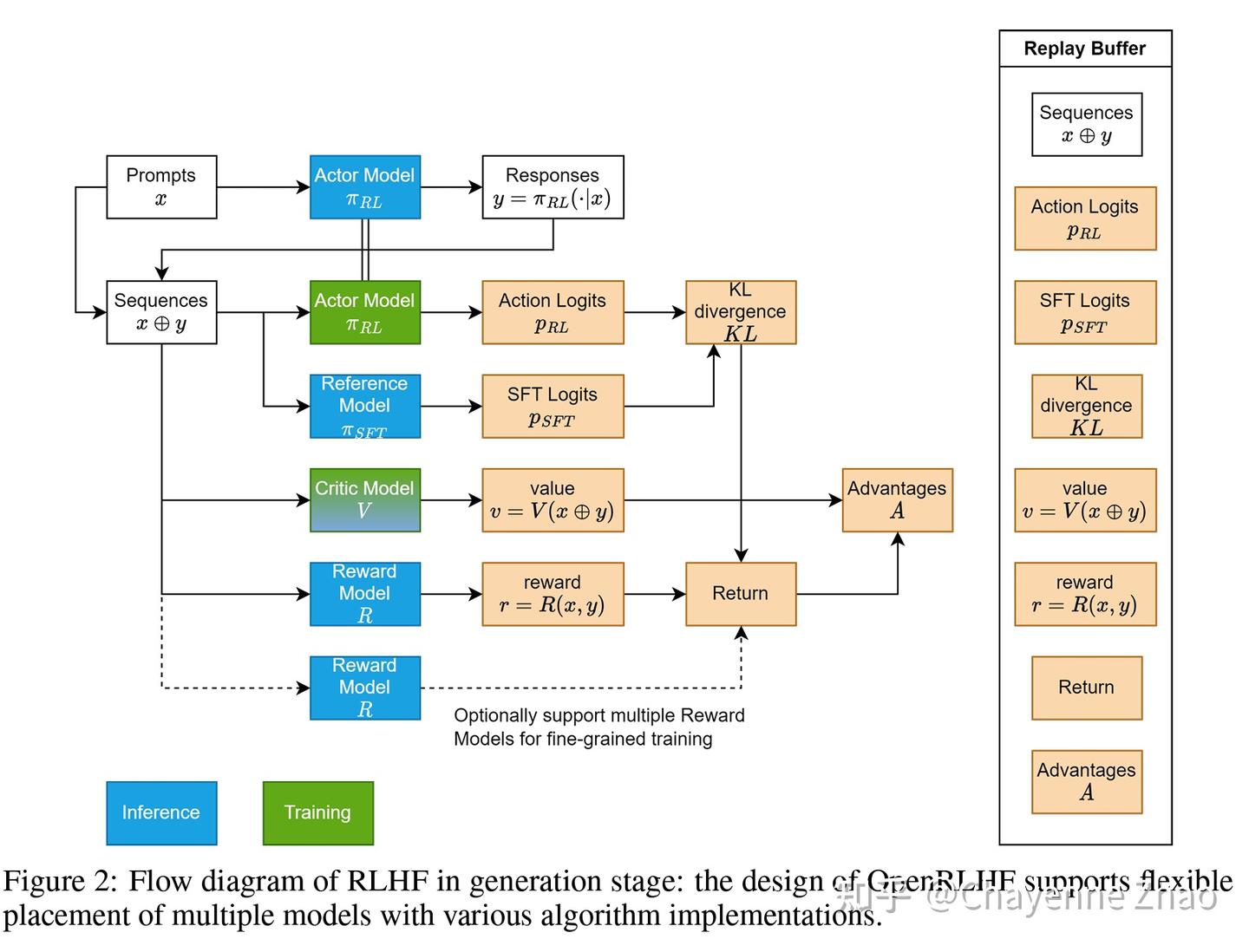
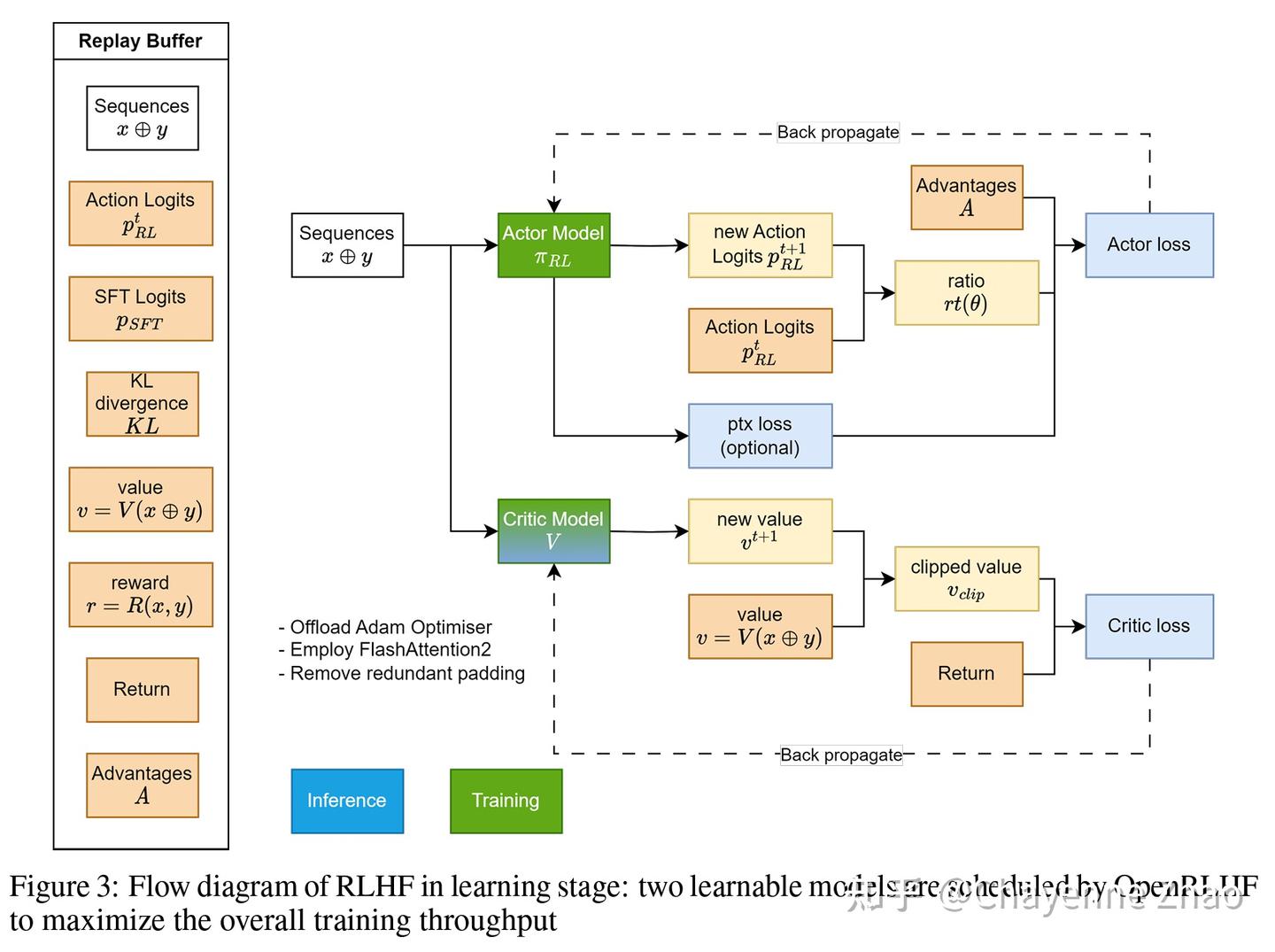
1.3.PPO训练四阶段
阶段1:先基于Pretrain model,训练一个精调模型 SFT Model 和 一个奖励模型(Reward Model)。Reward model 一般可以基于SFT model 热启 或 基于 Pretrain model 热启训练
阶段2:模型初始化,PPO过程,在线同时有四个模型,分别为
- Actor Model : 是我们要优化学习的策略模型,同时用于做数据采样,用SFT Model热启
- Reference Model : 代码中为initial_model,是为了控制Actor模型学习的分布与原始模型的分布相差不会太远的参考模型,通过loss中增加KL项,来达到这个效果。训练过程中该模型不更新
- Critic Model :是对每个状态做打分的价值模型,衡量当前token到生成结束的整体价值打分,用Reward Model热启
- Reward Model :这里实现的是ORM(Outcome Reward Model),对整个生成的结果打分,是事先训练好的Reward Model。训练过程中该模型不更新
阶段3:采样Experience数据,这个过程比较复杂, 后面将详细介绍。简述流程为:
- 首先采样一批随机指令集(Prompt)
- 调用Actor模型的generate()方法,采样1条或多条结果(sequences)
- 四个模型一起参与获得经验(experiences)的各个部分,用于后续模型训练
- 将
prompt + responses输入给 Actor Model,得到所有 token 的 log probs - 将
prompt + responses输入给 Critic Model,分别计算得得到所有 token 的 values - 将
prompt + responses输入给 Reward Model,得到最后一个 token 的 reward - 将
prompt + responses输入给 Reference Model,得到所有 token 的 log probs
- 将
阶段4: 用Experience样本,训练 Actor Model 和 Critic Model,后面单独介绍
重复3-4阶段,循环采样Experience数据-> 模型训练 ,直到loss收敛
对于第 4 步,我们当然可以一轮 experiences 就更新一次 actor 和 critic,但是为了尽可能利用这个 batch 的 experiences,我们对 actor 和 critic 做多轮更新。我们将 experiences 中多轮更新开始前的 log probs 和 values 称为 old log probs 和 old values(reward 不会多轮计算)。在每一轮中,actor 和 critic 会生成 new log probs 和 new values,然后在 old 的基础上计算 actor loss 和 critic loss,然后更新参数。
-------------------------------------------------------
# 初始化RLHF中的四个模型
# --------------------------------------------------------------
actor, critic, reward, ref = initialize_models()
# --------------------------------------------------------------
# 训练
# --------------------------------------------------------------
# 对于每一个batch的数据
for i in steps:
# 先收集经验值
exps = generate_experience(prompts, actor, critic, reward, ref)
# 一个batch的经验值将被用于计算ppo_epochs次loss,更新ppo_epochs次模型
# 这也意味着,当你计算一次新loss时,你用的是更新后的模型
for j in ppo_epochs:
actor_loss = cal_actor_loss(exps, actor)
critic_loss = cal_critic_loss(exps, critic)
actor.backward(actor_loss)
actor.step()
critc.backward(critic_loss)
critic.step()2. 模型结构
2.1. Actor Model 模型结构(Reference Model 同 Actor Model一致)
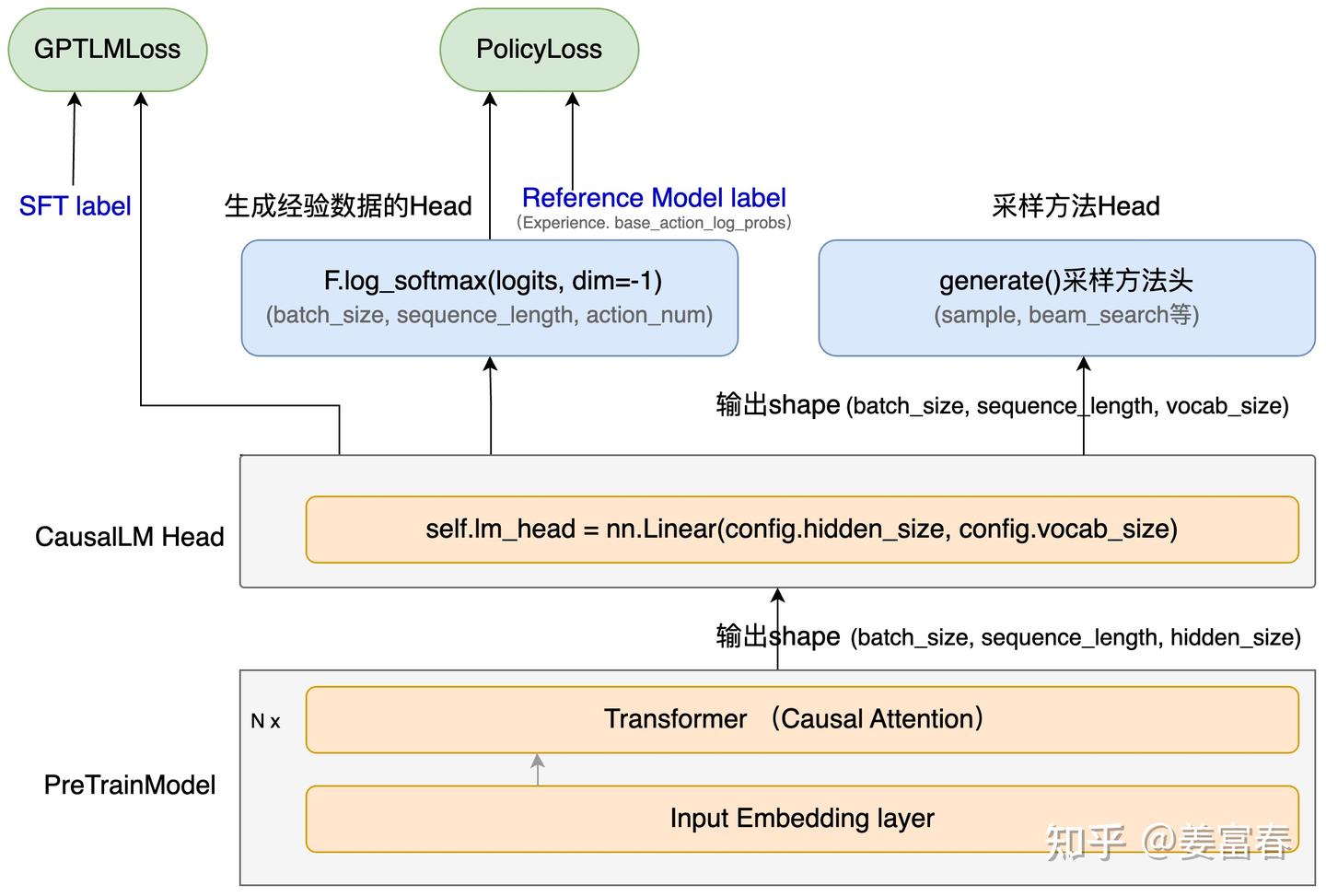
Actor网络(我们要更新训练的网络)
- PreTrainModel 和 CausalLM Head 都是 Huggingface 定义的标准模型层。详见:LlamaForCausalLM类定义
- 2个处理Head:
- F.log_softmax(logits): 采样经验数据的数据处理Head,获取log(p),方便后面计算KL和计算loss
- generate():采样Head,详见 :generate方法定义 。generate可以定义多种生成策略(beam search , sample N等)和配置多种生成参数(topP, temperature等)。
2.2. Reward Model 模型结构
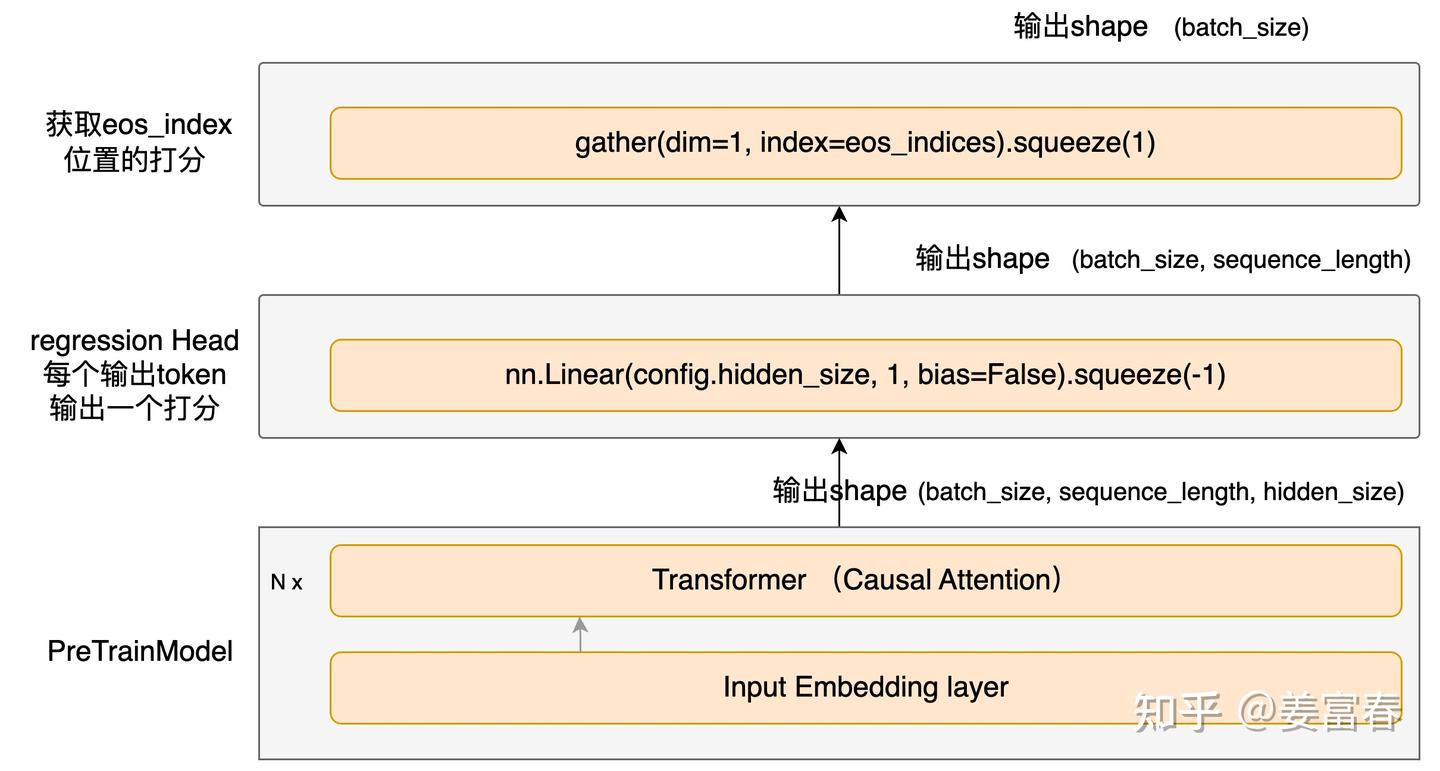
图3、Reward Model网络
- 这里的Reward Model是个ORM(Outcome Reward Model),即对输出的sequence做整体打分,每个输出序列会输出eos位置的打分结果。
2.3. Critic Model 模型结构
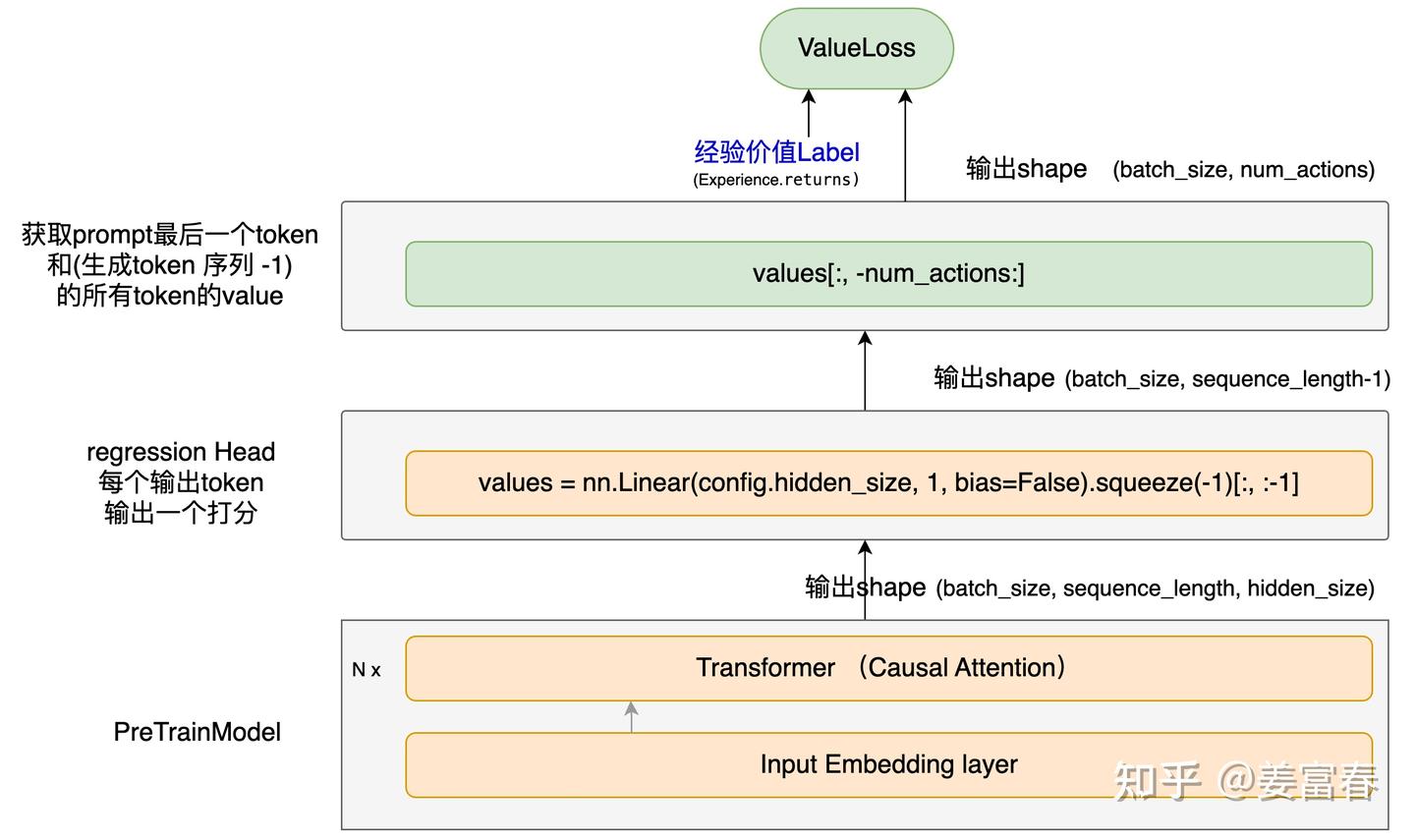
图4、Critic网络(PPO训练阶段要更新的价值评估网络)
- Critic用于评估当前状态的价值(当前token到生成eos累计预估价值),每个状态都会计算价值打分
- Critic用于评估当前状态的价值(当前token到生成eos累计预估价值),每个状态都会计算价值打分
注:从图中第二层(Linear层)可以看到,输出结果先做了[:, :-1]的切片操作,然后再取生成长度的切片[:, -num_actions:]。这个操作表示整体价值打分序列往前移了一位,这是因为在生成模型中,一个step数据:$(s_i, a_i, s_{i+1}, r_i)$ 的描述。当 $i = 1$ 时,$s_1$ 就是输入的prompt,状态 $s_1$ 的end位置是prompt的最后一个token的位置,而这个位置就是上述两次切片操作后的首token位置,表示第一个状态。$a_1$ 是生成的第一个token,$s_2$ 是prompt+生成的第一个token,$r_1$ 是从 $s_1 \rightarrow s_2$ 的即时奖励。
3. Experience数据采样过程
3.1. 采集经验数据过程简述
由图1可看到经验数据(Experience)采集过程如下:
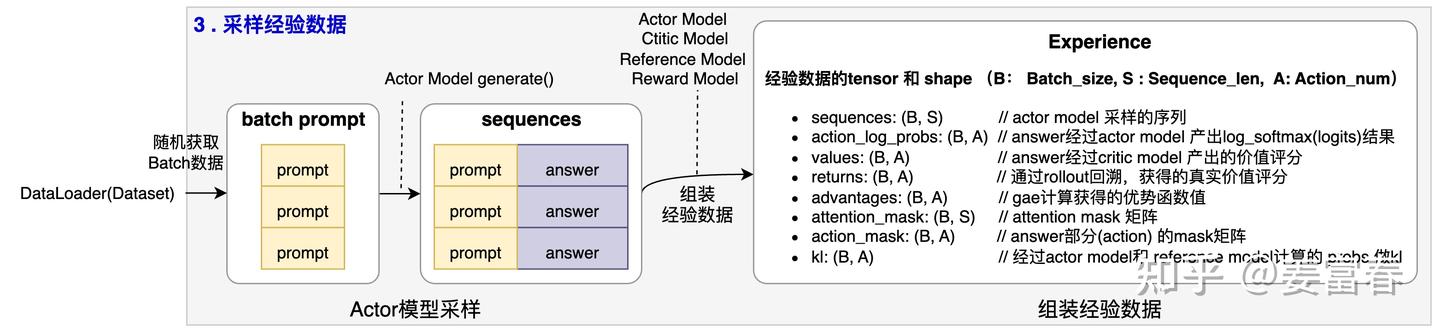
图2、PPO采样经验数据过程
3阶段处理:
- 获取一个Batch 指令数据:从Dataset中获取一个Batch的Prompt
- 生成sequence数据:拿一个Batch的Prompt数据送入到Actor模型的generate()方法,采样一条或多条结果,组成sequences<Prompt, Answer>数据。
- 组装Experience数据:通过四个模型(Actor, Reference, Critic, Reward)将数据加工成Experience。Experience里面维护了多个Tensor域,为下一步训练Actor,Critic模型做准备。
下面通过配合一些源码和数据图,详细讲解下从拿到一个Batch的Prompt数据到最终获取Experience数据的过程
3.2. 经验数据采集步骤详解
3.2.1. 关键代码块
首先从源码中截取关键的代码块(ppo_trainer.py)
class PPOTrainer(ABC):
"""
Trainer for Proximal Policy Optimization (PPO) algorithm.
"""
def __init__(self,...) -> None:
# 采样Experience的类实例
self.experience_maker = NaiveExperienceMaker(
actor,critic,reward_model,initial_model,
tokenizer,prompt_max_len,
self.kl_ctl,strategy,
remote_rm_url,reward_fn,
)
def fit(
self,prompts_dataloader,...) -> None:
for episode in range(start_episode, args.num_episodes):
for rand_prompts in self.prompts_dataloader:
###################
# 1. Experience采样过程
###################
for i, experience in enumerate(
self.experience_maker.make_experience_list(rand_prompts, self.generate_kwargs)
):
self.replay_buffer.append(experience)
###################
# 2. PPO训练过程
###################
status = self.ppo_train(steps)
...从源码看,NaiveExperienceMaker.make_experience_list是采样Experience的核心方法,该方法将输入的batch_prompt经过处理后,组装生成Experience数据。
下面我们看下make_experience_list的核心代码。(看代码注释)
def make_experience_list(self, all_prompts: Union[str, List[str]], generate_kwargs) -> List[Experience]:
"""
Make a list of experience with the micro_rollout_batch_size.
This method will first calculate the response sequences and rewards for the given prompts.
Then, if we need certain processing for the rewards or do certain filtering, we can process the rollout as a whole.
After that, we will calculate the advantages and returns for each experience.
"""
####################
# 1. 调用Actor generate()方法获取Prompt的生成结果,把结果存储到Sample对象
####################
samples_list = self.generate_samples(all_prompts, generate_kwargs)
torch.distributed.barrier()
####################
# 2. 调用make_experience 对每个Sample做处理,组装Experience部分字段(除了advantage和return)
####################
experiences = []
for samples in samples_list:
experiences.append(self.make_experience(samples).to_device("cpu"))
experiences, rewards = self.process_experiences(experiences)
####################
# 3. 通过从后往前回溯计算的方式,获取advantage和return值
####################
for experience, reward in zip(experiences, rewards):
num_actions = experience.info["num_actions"]
if self.advantage_estimator == "gae":
experience.advantages, experience.returns = self.get_advantages_and_returns(
experience.values,
reward,
experience.action_mask,
generate_kwargs["gamma"],
generate_kwargs["lambd"],
)
if not getattr(self, "packing_samples", False):
return_sums = reward.sum(dim=-1)
else:
return_sums = torch.tensor(
[each_reward.sum() for each_reward in reward], device=torch.cuda.current_device()
)
experience.info["return"] = return_sums
return experiences为了进一步讲清楚数据采样的过程,先针对源码中几个数据结构做下说明。源码中一共有两个主要的数据类。
3.2.2. 数据类型描述:Sample 和 Experience
描述数据shape的符号说明:
B: batch_size
S: Sequence_len,是一个Batch padding后的Prompt + response的长度
A: num_actions, 是生成的token长度
注:Sample有两种数据存储格式 batched or packed,batched 格式是默认的,是做了padding对齐的格式; 而packed格式是非padding对齐的连续存储的格式,本文主要以batched数据格式为例,描述数据处理过程。
sample数据类定义如下(数据域含义看注释)
@dataclass
class Samples:
sequences: torch.Tensor # Prompt 和 response,shape[B, S]
attention_mask: Optional[torch.LongTensor] # attention mask,标识去掉padding有效的attention位置,shape[B, S]
action_mask: Optional[torch.BoolTensor] # action_mask, 标识有效的生成token(去除生成部分组Batch的padding),shape[B, A]
num_actions: Union[int, torch.Tensor] # num_actions, 表示action_mask的长度 int
response_length: torch.Tensor # response部分 token的数量,shape[B,]
total_length: torch.Tensor # sequences 所有token(prompt + response)所有token的数量,shape[B,]- Experience
Experience数据类定义如下(数据域含义看注释)
@dataclass
class Experience:
sequences: torch.Tensor # 同Sample的sequences定义,shape[B, S]
action_log_probs: torch.Tensor # action 计算log(softmax(logits))的结果,shape[B, A]
values: torch.Tensor # critic 模型预估的当前状态打分预估值,shape[B, A]
returns: Optional[torch.Tensor] # returns 按gae方法计算的平衡偏差和方差的状态打分,shape[B, A]
advantages: Optional[torch.Tensor] # 按gae方法计算的优势得分值,shape[B, A]
attention_mask: Optional[torch.LongTensor] # attention mask,同Sample定义,shape[B, S]
action_mask: Optional[torch.BoolTensor] # action_mask,同Sample定义,shape[B, A]
info: Optional[dict] # 保留一些中间信息,shape[B, A]
kl: Optional[torch.Tensor] = None # 计算Actor预估分布和reference预估的分布的KL散度,shape[B, A]我们注意到上面的数据描述中,出现了action 和 action_num,在语言模型中,action 怎么理解呢? 我们用一条sequence数据,描述下在语言模型中: si (状态) , ai (动作)的具体的含义。如图3所示
蓝色块:表示Prompt的token
红色块:表示生成的有效token
绿色块:表示eos生成结束token
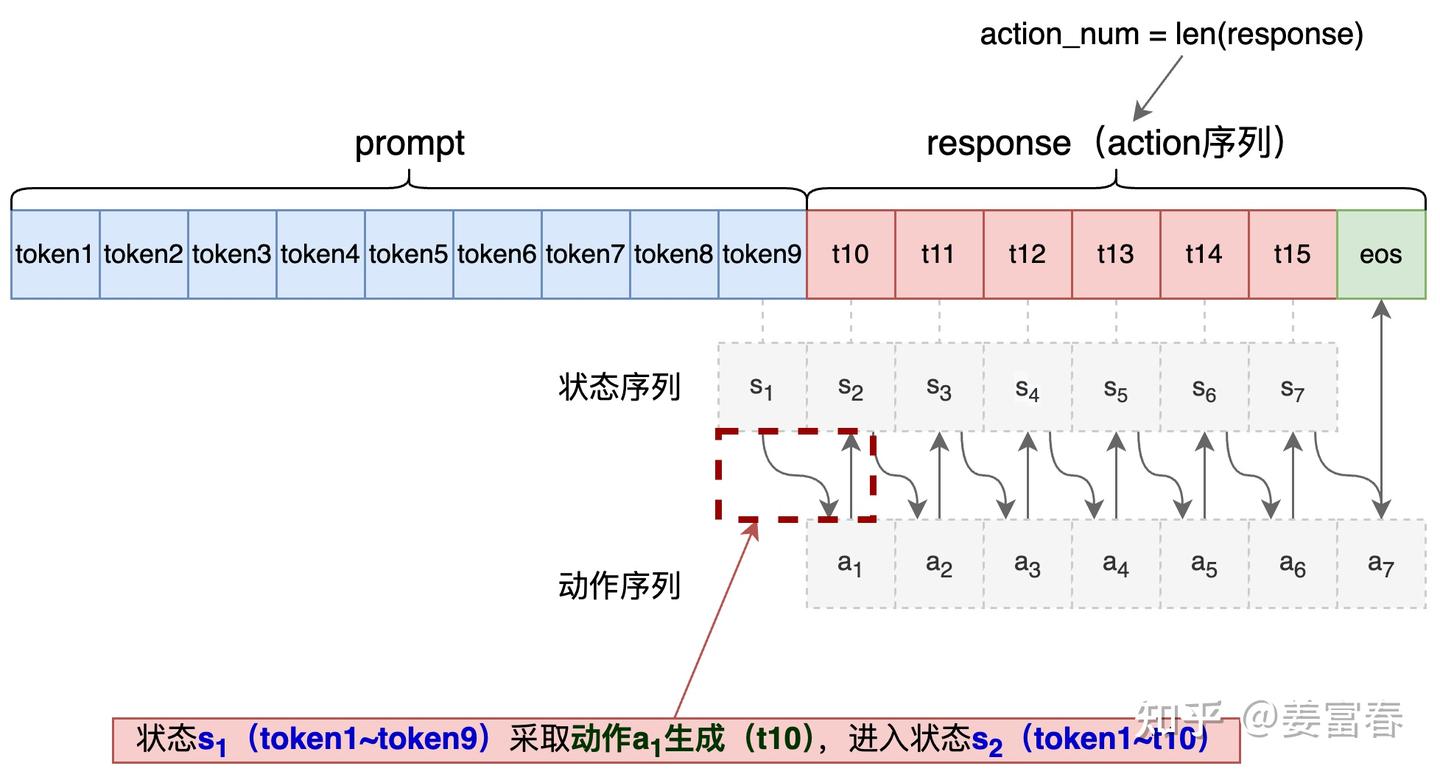
图3、LLM中状态、动作的描述
我们注意到上图,状态序列和动作序列错开一位,因为先有状态才能采取动作进入下一个状态,所以初始prompt就是第一个初始状态。基于prompt生成的第一个token是第一个动作,然后前序token+当前生成的token作为下一个状态。
语言模型中动作 a 和状态 s 描述为:
- 状态 $s_i$ :是从初始token到 i 位置的token序列
- 动作 $a_i$ : 是基于 $s_i$ 状态序列,生成的下一个token
到此,把一些数据结构和生成模型中的状态、动作都描述清楚了,下面我们通过一系列数据图,串起来完整的采样Experience数据的过程。
3.2.3. Batch Prompt数据 -> Sample数据
samples_list = self.generate_samples(all_prompts, generate_kwargs)上面generate_samples是把Batch Prompt数据处理成Sample数据的实现。下面基于几步图化操作描述下处理过程
1. 基于args.micro_rollout_batch_size的配置,将数据做micro_batch 处理
比如当前Batch = 8 , micro_rollout_batch_size = 4 。
则数据处理如下
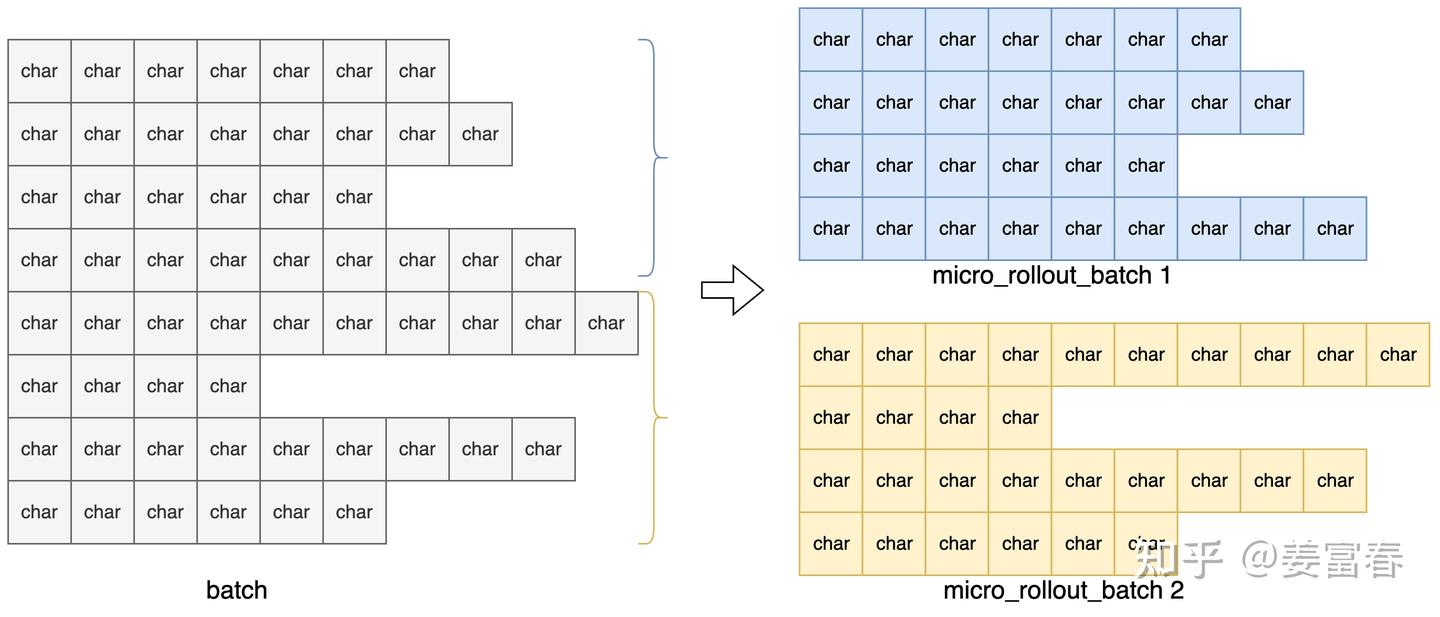
图4、batch -> micro_rollout_batch
下面为了描述方便,我们只以一个micro_rollout_batch=4 (上图的micro_rollout_batch 1) 为例,描述后续数据处理过程
2. 调用tokenize_fn,将Prompt token化,padding做左对齐处
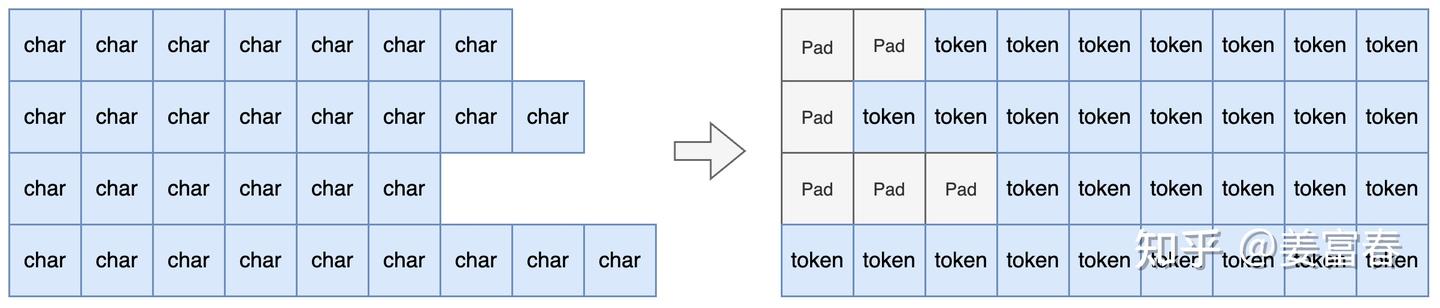
图5、Tokenizer处理
注: 生成模型的Batch处理数据,都采用'left'模式对齐,方便并行化做decoder过程
3. 调用Actor.generate()方法生成sequences,attention_mask, action_mask
sequences,attention_mask, action_mask几个数据图示化如下
- sequences
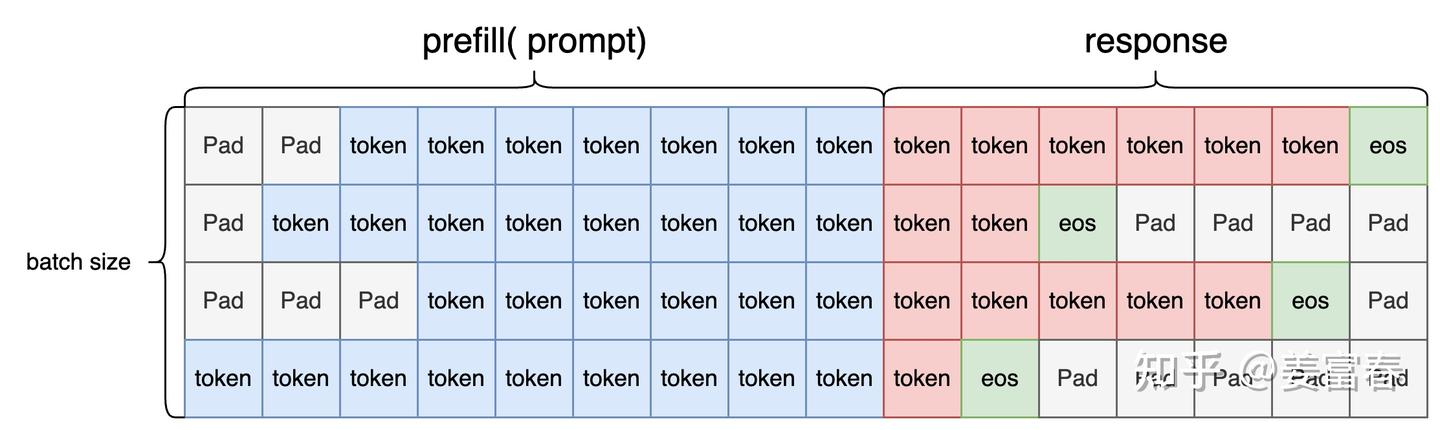
图6、sequences 数据
- attention_mask
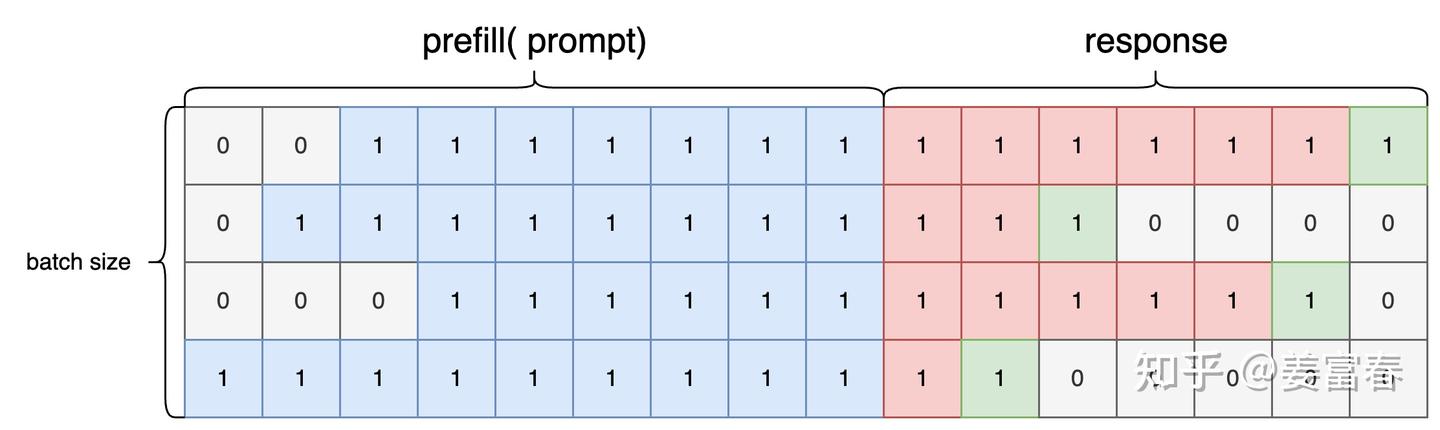
图7、attention mask 数据(非padding置1)
- action_mask
# action_mask处理过程
state_seq = sequences[:, input_len - 1 : -1]
action_mask = state_seq.ne(eos_token_id) & state_seq.ne(pad_token_id)
action_mask[:, 0] = 1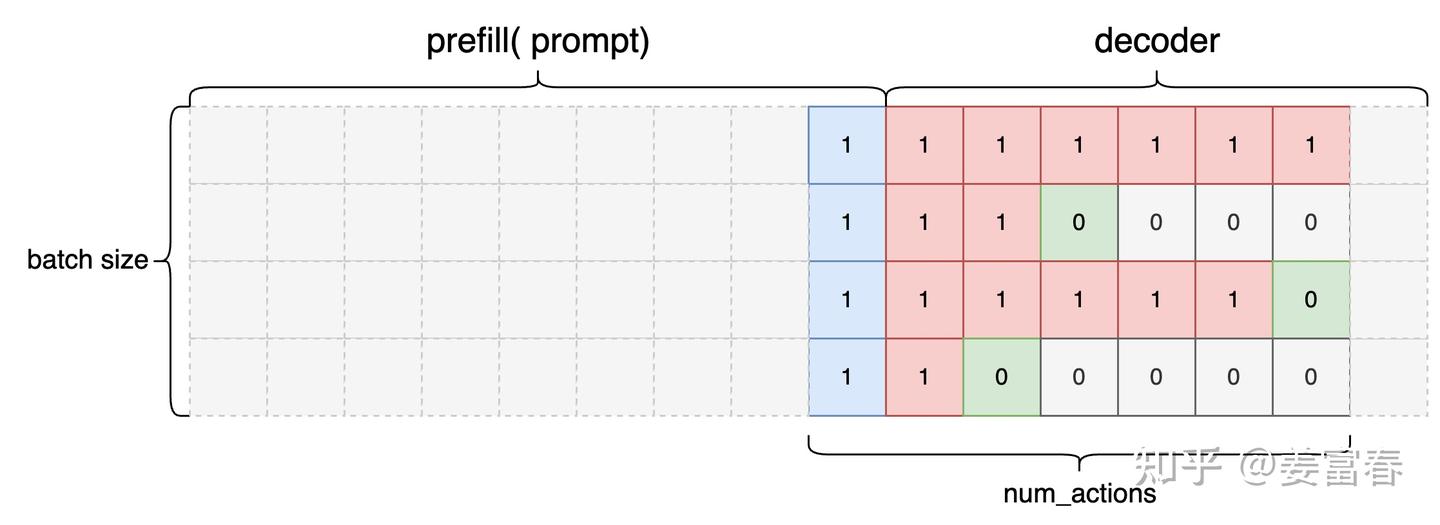
图8、action mask 数据(实际是对有效状态位置1)
action_mask 矩阵shape=[B, A],也就是序列长度是生成token数(num_actions),实现中action_mask实际是对有效状态位置值1 (整体按num_actions长度,向前平移1位)
4. 数据封装成Sample
上面已经描述清楚Sample的关键域:sequences, attention_mask,action_mask,num_actions。可以按Sample 定义封装到数据类内。
经过上述步骤,已经把一个Batch的Prompt 处理成了Sample数据,接下来看看Sample数据进一步封装成Experience数据的处理。
3.2.4. Sample数据 -> Experience数据
#https://github.com/OpenRLHF/OpenRLHF/blob/main/openrlhf/trainer/ppo_utils/experience_maker.py#L265
self.make_experience(samples).to_device("cpu")上面make_experience方法是把Sample数据处理成Experience数据的过程。下面描述代码里的几个关键步骤。
1. 通过Actor模型计算action_log_probs (Experience.action_log_probs)
action_log_probs = self.actor(sequences, num_actions, attention_mask)action_log_probs的数据视图如下:
注:灰色虚线块,表示不存在的块,画出完整的sequence是为了方便理解数据的生效位置
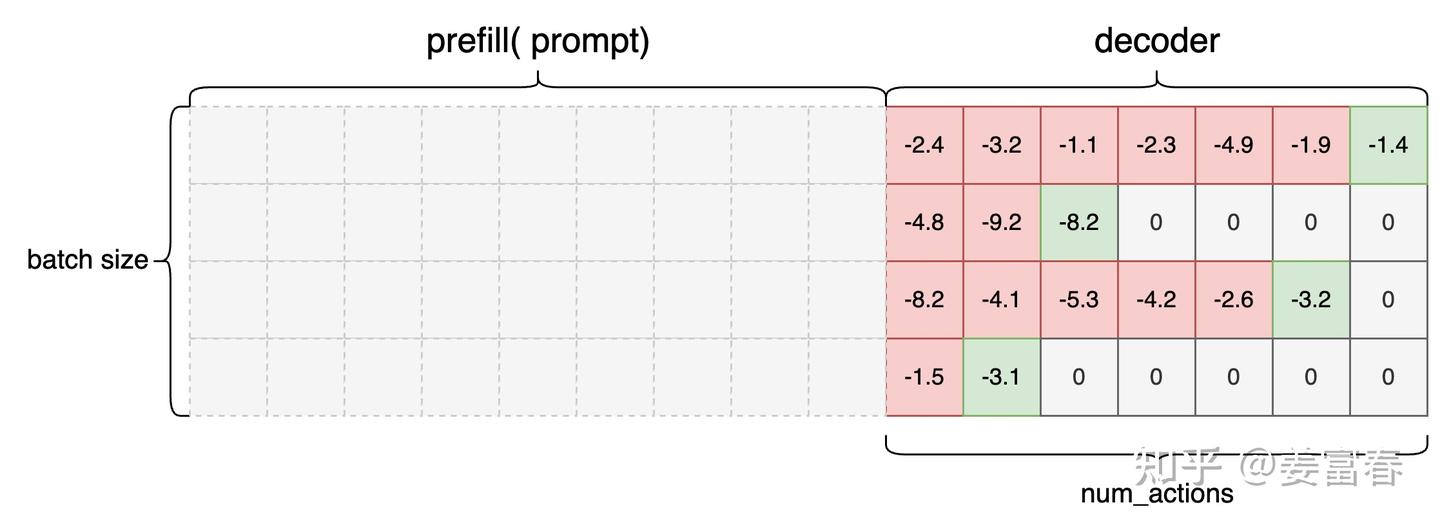
图9, action_log_probs数据图示
action_log_probs 是为了计算KL的中间变量。每个token位置,首先按词表维度(vocab_size)计算softmax,再取log, 最后根据label token的token_id取到该位置的log_probs值。由于probs是 (0,1) 的值,取log,是 (−∞,0) 区间的值。所以上面图中的值都是负数。
2. 通过Reference模型计算base_action_log_probs
Actor模型和Reference模型结构是一样的,数据操作逻辑也是一样的,同步骤1操作。base_action_log_probs 也是为了计算KL散度的中间变量
3. 计算action_log_probs 和base_action_log_probs 的KL散度(Experience.kl)
这里计算KL散度,并没有实际用两个概率分布(词表长度),然后通过KL的公式计算。而是使用了一种轻量的近似方法计算的KL散度。详见: Approximating KL Divergence。
# 源码:https://github.com/OpenRLHF/OpenRLHF/blob/main/openrlhf/models/utils.py#L7
def compute_approx_kl(log_probs: torch.Tensor, log_probs_base: torch.Tensor,...) -> torch.Tensor:
log_ratio = log_probs.float() - log_probs_base.float()
log_ratio = -log_ratio
log_ratio = log_ratio.exp() - 1 - log_ratio4. 通过Critic模型计算状态节点的预估价值 (Experience.value)
Critic是预估状态的价值,看代码实现时,参考图3,先理解LLM中状态的起始位置。最终状态序列长度是num_actions(生成token的数量),状态序列起始位置是Prompt的最后一个token,结束位置是最后eos token 前一个token, 所以计算出的Critic预估状态价值的数据为:

图10、Critic模型预估状态价值数据
5. 通过Reward模型,计算Batch中每个序列的打分 (Experience.info.r)
在RLHF中,Reward Model是一个ORM(outcome Reward Model) 也就是对完整的生成response输出一个打分。代码实现上取每个sequence eos token位置的预估打分值。如图11,图中"xx"也是会并行计算出的Reward值,单最终只取了序列最后eos位置的score作为完整序列的打分值。最后reward处理成[B, 1]格式,每个序列一个打分。

图11、序列Reward打分数据
调用(cumpute_reward方法)将Reward值还原到二维空间并赋值到eos位置,其他位置都清零0(为下一步计算优势奖励值做准备)。如图12所示
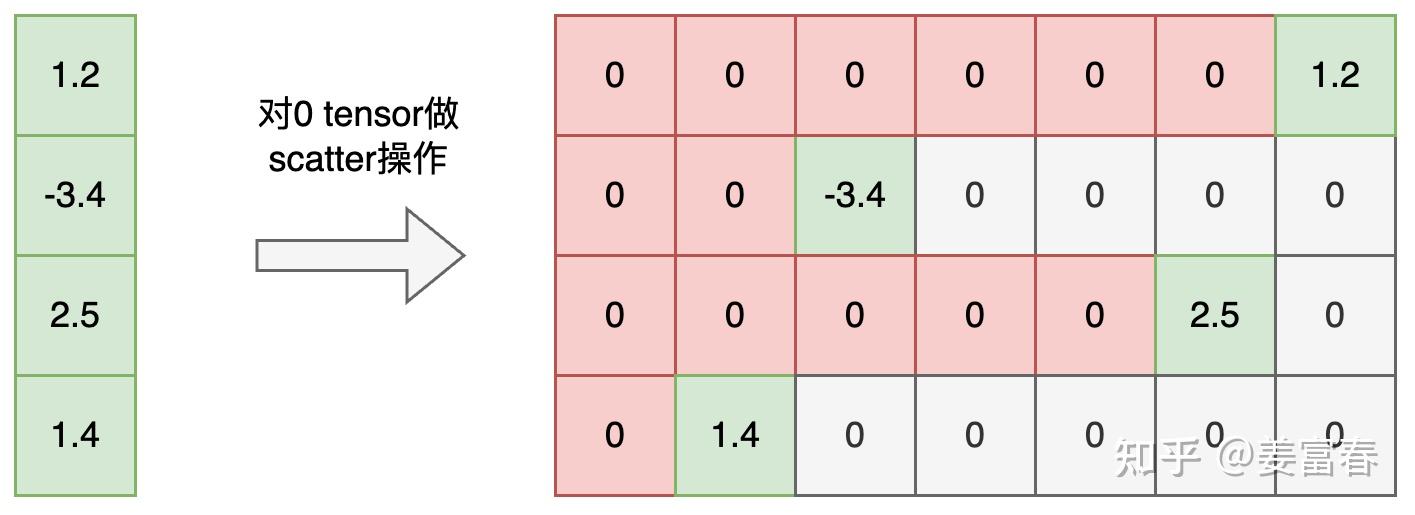
图12、Reward做scatter操作
Reward 计算函数
from typing import Union, Optional, Tuple, List
import torch
def compute_reward(
r: Union[torch.Tensor, float],
kl_coef: float,
kl: Union[torch.Tensor, List[torch.Tensor]],
action_mask: Optional[torch.Tensor] = None,
num_actions: Optional[Union[int, List[int]]] = None,
reward_clip_range: Tuple[float, float] = (-float("inf"), float("inf")),
) -> Union[torch.Tensor, List[torch.Tensor]]:
"""
Computes the reward for an action sequence, incorporating KL penalties.
Parameters:
- r (torch.Tensor | float): The base reward (single value or per batch).
- kl_coef (float): Coefficient for the KL penalty.
- kl (torch.Tensor | List[torch.Tensor]): KL divergence values.
- action_mask (torch.Tensor, optional): Mask indicating valid actions.
- num_actions (int | List[int], optional): Number of valid actions per sequence.
- reward_clip_range (Tuple[float, float]): Min and max clipping values for reward.
Returns:
- torch.Tensor | List[torch.Tensor]: Computed reward values.
"""
kl_coef = max(kl_coef, 0.0) # Ensure KL coefficient is non-negative
# Clip rewards if range is provided
if isinstance(r, torch.Tensor):
r = r.clamp(*reward_clip_range)
else:
r = max(min(r, reward_clip_range[1]), reward_clip_range[0])
# Case: Using action mask
if action_mask is not None:
kl_penalty = -kl_coef * kl # KL penalty term
# Find last valid action index per sequence
eos_indices = action_mask.size(1) - 1 - action_mask.long().fliplr().argmax(dim=1, keepdim=True)
# Scatter final reward at the last valid action
last_reward = torch.zeros_like(kl).scatter_(
dim=1, index=eos_indices, src=r.unsqueeze(1).to(kl.dtype)
)
return last_reward + kl_penalty
# Case: No action mask, using num_actions instead
if isinstance(kl, torch.Tensor):
raise ValueError("num_actions mode expects kl to be a list of tensors.")
if num_actions is None:
raise ValueError("num_actions must be provided when action_mask is None.")
rewards = []
for i, (kl_segment, action_len) in enumerate(zip(kl, num_actions)):
kl_penalty = -kl_coef * kl_segment
kl_penalty[action_len - 1] += r[i] if isinstance(r, torch.Tensor) else r # Assign final reward
rewards.append(kl_penalty)
return rewards该代码的主要功能是计算强化学习(RL)或策略优化任务中的奖励(reward),并考虑了 KL 散度(Kullback-Leibler divergence)的惩罚项。具体来说:
KL 惩罚计算
kl_penalty = -kl_coef * kl- 该公式表示:对 KL 散度值乘以
-kl_coef,从而形成一个惩罚项,避免策略偏离过远。
终止奖励的计算(针对 action_mask 方案)
- 代码使用
action_mask计算序列的最后一个有效动作索引,并在该索引位置添加奖励。
6. 计算优势奖励值(Experience.advantages)和 状态奖励值(Experience.returns)
计算优势奖励值(advantage)有多种方法,代码中有["gae", "reinforce", "rloo"] 三种实现,本文只沿着"gae"的计算方式做梳理。
gae(Generalized Advantage Estimation)是PPO论文中实现的优势奖励值计算方法,可平衡优势预估的偏差和方差,这里不展开方法细节,详见:原始PPO论文。代码注释中有一段较清晰的计算公式
详见源码:https://github.com/OpenRLHF/OpenRLHF/blob/main/openrlhf/trainer/ppo_utils/experience_maker.py#L356
def get_advantages_and_returns(values: torch.Tensor, rewards: torch.Tensor,)
"""Function that computes advantages and returns from rewards and values.
Calculated as in the original PPO paper: https://arxiv.org/abs/1707.06347
Note that rewards may include a KL divergence loss term.
Advantages looks like this:
Adv1 = R1 + γ * λ * R2 + γ^2 * λ^2 * R3 + ...
- V1 + γ * (1 - λ) V2 + γ^2 * λ * (1 - λ) V3 + ...
Returns looks like this:
Ret1 = R1 + γ * λ * R2 + γ^2 * λ^2 * R3 + ...
+ γ * (1 - λ) V2 + γ^2 * λ * (1 - λ) V3 + ...
Input:
- values: Tensor of shape (batch_size, response_size)
- rewards: Tensor of shape (batch_size, response_size)
Output:
- advantages: Tensor of shape (batch_size, response_size)
- returns: Tensor of shape (batch_size, response_size)
"""其中:
$\gamma$:是时间步衰减因子,表示离当前状态越近奖励值影响越大,越远越衰减。默认值:1不衰减。
$\lambda$:是平衡取观测值的步数的参数。默认值:0.95
- 当 $\lambda \rightarrow 1$ 时,$adv1 = R1 + \gamma R2 + \gamma^2 R3 + \ldots - V1$ 表示更多用观测值计算,偏差小,方差大
- 当 $\lambda \rightarrow 0$ 时,$adv1 = R1 + \gamma V2 - V1$ 表示更多用估计值计算,偏差大,方差小
计算advantage 和 return是个从后向前回溯计算的过程,如图13所示,使用value 和 reward数据,从后向前依次计算advantage 和 return。
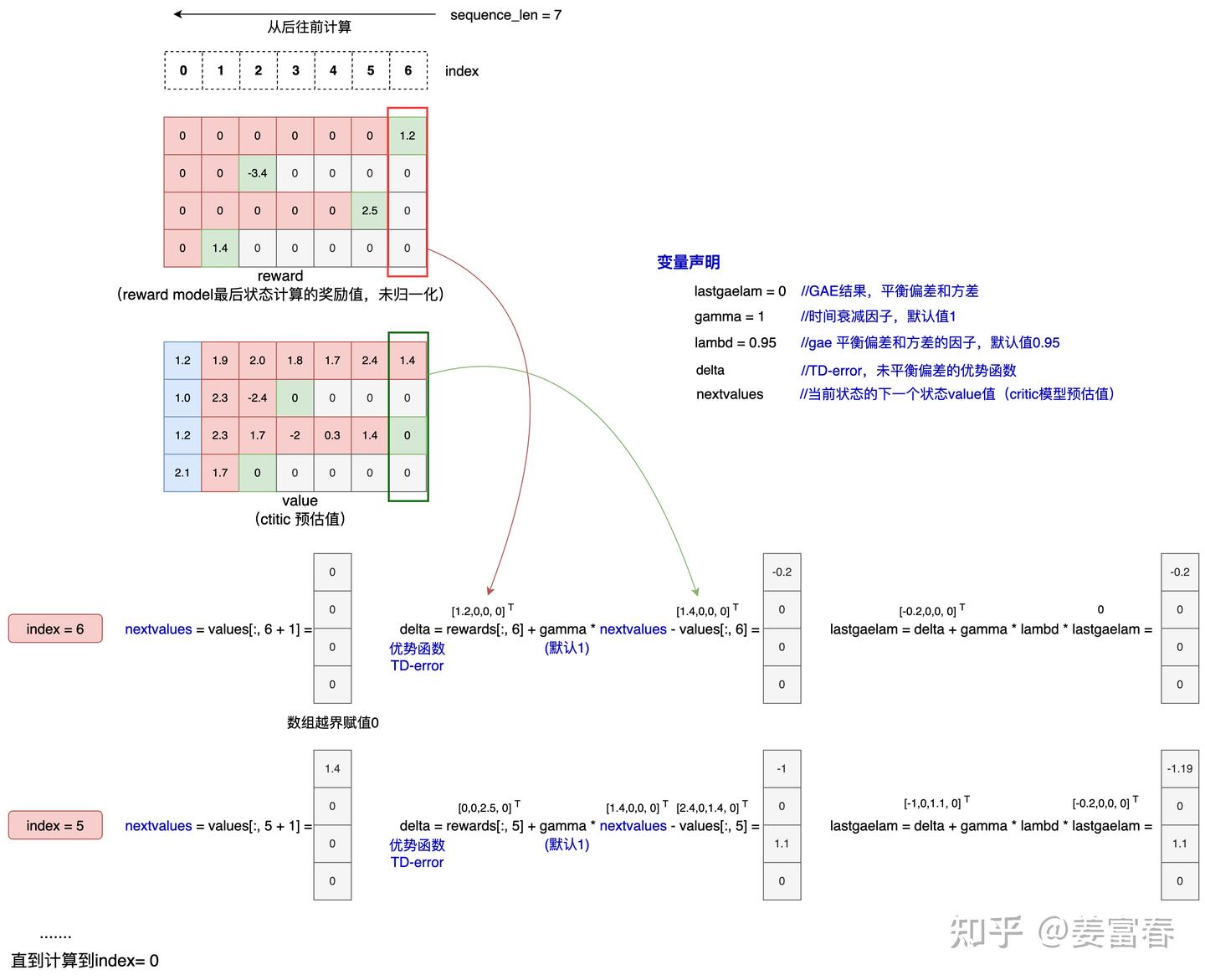
图13、advantage从后向前回溯计算过程
至此我们已经收集到了Experience数据类的所有信息。
4. PPO 模型训练过程
4.1. 核心源码
PPO训练过程:详见PPOtrainer源码的ppo_train()入口函数。核心代码块如下:
class PPOTrainer(ABC):
################
# 1.loss定义 (Actor模型两个loss, Critic模型一个loss)
################
self.actor_loss_fn = PolicyLoss(eps_clip)
self.critic_loss_fn = ValueLoss(value_clip)
self.ptx_loss_fn = GPTLMLoss()
def ppo_train(self, global_steps=0):
################
# 2. 加载经验数据(Experience)
################
dataloader = DataLoader(...)
for epoch in range(self.max_epochs):
for experience in pbar:
################
# 3. 执行一步训练
################
status = self.training_step(experience, global_steps)
def training_step(self, experience: Experience, global_steps) -> Dict[str, float]:
################
# 3.1. 训练Actor 模型,支持2种任务同时训练(SFT和PPO),对应loss GPTLMLoss, PolicyLoss
################
status = self.training_step_actor(experience)
################
# 3.2. 训练Critic 模型,通过Valueloss计算损失
################
status.update(self.training_step_critic(experience))上述代码流程描述可知,PPO训练过程,在一个训练步骤中,Actor和Critic模型依次训练更新。在训练Actor模型时,代码实现中加入了一个可配置的SFT任务,所以Actor是可以同时多任务训练的。具体训练如下图所示。
4.2. 模型训练框架
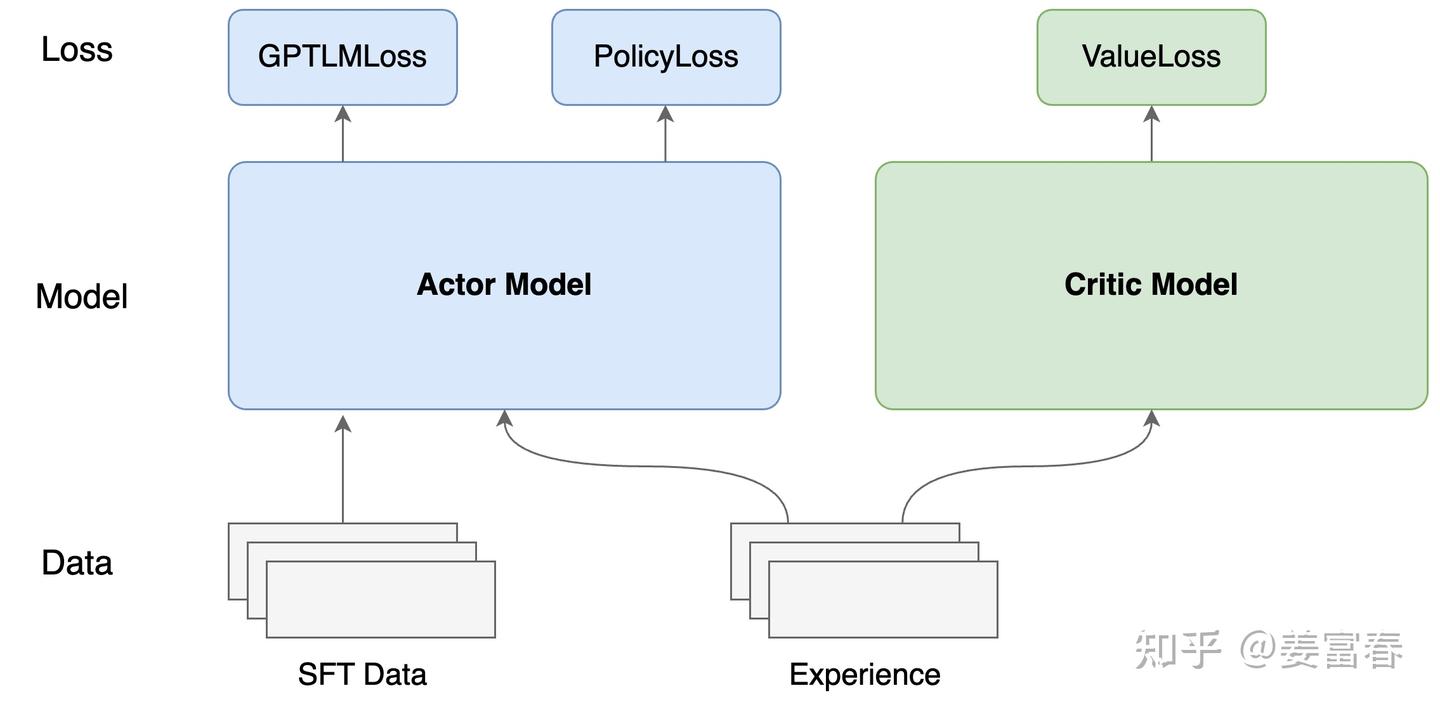
图1、PPO训练框图
当前我们基本整理清楚了PPO的完整训练流程。接下来我们进一步看下3个loss函数,理解下模型计算损失的过程。
4.3. Loss 函数
4.3.1. GPTLMLoss
GPTLMLoss核心代码块,如下:
# 源码:https://github.com/OpenRLHF/OpenRLHF/blob/main/openrlhf/models/loss.py#L11C7-L11C16
class GPTLMLoss(nn.Module):
def __init__(self, ring_attn_group=None):
self.loss = nn.CrossEntropyLoss(ignore_index=self.IGNORE_INDEX)
def forward(self, logits: torch.Tensor, labels: torch.Tensor) -> torch.Tensor:
shift_logits = logits[..., :-1, :].contiguous()
shift_labels = labels[..., 1:].contiguous()
loss = self.loss(shift_logits.view(-1, shift_logits.size(-1)), shift_labels.view(-1))GPTLMLoss就是LLM做next token predict任务的loss(CrossEntropyLoss)。计算loss时,对应 i 位置的预估值logit,取 i+1 位置的token_id作为label来计算loss。在PPO训练中Actor的SFT任务是个可选的任务。没有这个任务也不影响模型的训练。
4.3.2. PolicyLoss
PlicyLoss的核心代码块(看注释)
class PolicyLoss(nn.Module):
def forward(self,
log_probs: torch.Tensor,
old_log_probs: torch.Tensor,
advantages: torch.Tensor,
action_mask: Optional[torch.Tensor] = None) -> torch.Tensor:
#################
#1. 重要性采样 important-sampling
# 下面公式:(log(p) - log(p')).exp() = log(p/p').exp() = p/p'
# 转换下就两个概率的比,表示重要性采样,保证PPO算法是个off-policy算法,提升训练效率
#################
ratio = (log_probs - old_log_probs).exp()
#################
# 2. clip-PPO 算法,详见下方公式
#################
surr1 = ratio * advantages
surr2 = ratio.clamp(1 - self.clip_eps, 1 + self.clip_eps) * advantages
loss = -torch.min(surr1, surr2)
loss = masked_mean(loss, action_mask, dim=-1).mean()
return loss这里实现的就是原始论文中的clip-ppo算法,我们把原文公式列在下面:
$$ L^{CLIP}(\theta) = \mathbb{E}_t [min(r_t(\theta)A_t, clip(r_t(\theta), 1 - \epsilon, 1 + \epsilon)A_t)] $$
其中: $$ r_t(\theta) = \frac{\pi_\theta(a_t|s_t)}{\pi_{\theta_{old} }(a_t|s_t)} $$ $r_t(\theta) $ 是important-sampling的权重,有了这个权重保证了PPO训练可以采样一次训练多次,将on-policy的训练转成off-policy的模式,提升训练效率;$A_t $ 是经验数据(Experience)中计算好的优势价值打分;$\epsilon $ 是clip超参。代码实现和下面公式完全能对应上,对Loss的详细理解参考PPO原论文,不过多赘述。
4.3.3. ValueLoss
ValueLoss的核心代码块
class ValueLoss(nn.Module):
def forward(
self,
values: torch.Tensor,
old_values: torch.Tensor,
returns: torch.Tensor) -> torch.Tensor:
loss = (values - returns) 2ValueLoss计算就是对比状态预估价值(values)和实际计算的经验价值(returns)的相近程度,典型的回归问题。用MSE(Mean Squared Loss)计算损失。
5. OpenRLHF 训练参数分析
5.1参数总览
从一个最基础的脚本train_ppo_llama_ray.sh入手。
set -x
ray job submit --address="http://127.0.0.1:8265" \
--runtime-env-json='{"working_dir": "/openrlhf"}' \
-- python -m openrlhf.cli.train_ppo_ray \
--ref_num_nodes 1 \
--ref_num_gpus_per_node 2 \
--reward_num_nodes 1 \
--reward_num_gpus_per_node 2 \
--critic_num_nodes 1 \
--critic_num_gpus_per_node 2 \
--actor_num_nodes 1 \
--actor_num_gpus_per_node 2 \
--vllm_num_engines 2 \
--vllm_tensor_parallel_size 2 \
--colocate_critic_reward \
--colocate_actor_ref \
--pretrain OpenRLHF/Llama-3-8b-sft-mixture \
--reward_pretrain OpenRLHF/Llama-3-8b-rm-mixture \
--save_path /openrlhf/examples/checkpoint/llama3-8b-rlhf \
--micro_train_batch_size 16 \
--train_batch_size 128 \
--micro_rollout_batch_size 32 \
--rollout_batch_size 1024 \
--max_samples 100000 \
--max_epochs 1 \
--prompt_max_len 1024 \
--generate_max_len 1024 \
--zero_stage 3 \
--bf16 \
--actor_learning_rate 5e-7 \
--critic_learning_rate 9e-6 \
--init_kl_coef 0.01 \
--prompt_data OpenRLHF/prompt-collection-v0.1 \
--input_key context_messages \
--apply_chat_template \
--normalize_reward \
--packing_samples \
--adam_offload \
--flash_attn \
--gradient_checkpointing \
--load_checkpoint \
--use_wandb {wandb_token}
# --runtime-env-json='{"setup_commands": ["pip install openrlhf[vllm]"]}' [Install deps]
# --ref_reward_offload [Offload to CPU]
# --remote_rm_url http://localhost:5000/get_reward5.2 模型参数
- pretrain:Actor模型
- reward_pretrain:Reward模型
这两个参数的含义非常简单,就是Actor模型和Reward模型的路径,其实OpnenRLHF同样支持传入Critic模型的路径,参数名是critic_pretrain。因为我们这里没有传入,则Critic模型会读取Reward模型的配置,即初始参数一样,如果没有设置Reward模型,则会继承自Actor模型。如果使用 Reinforce++ 或者GRPO这类Critic Free的算法,则不设置Critic模型。Refrence模型继承自Actor模型,两者参数一样,并且Refrence模型不会更新。
5.3 优化参数
- actor_learning_rate:Actor模型学习率
- critic_learning_rate:Critic模型学习率
OpnenRLHF默认使用的是Warmup-Decay的学习率调度器,所以也支持设置warmup步数等其他的相关参数,具体的可以在train_ppo_ray.py中找到相关的参数。
5.4 数据参数
micro_train_batch_size:训练阶段单卡分配的experience数量
train_batch_size: 训练时全局的experience数量
micro_rollout_batch_size:探索阶段单卡分配的experience数量
rollout_batch_size:探索阶段的prompt数量
max_samples:实际使用的最大prompt数量
n_samples_per_prompt:每个prompt需要生成多少个experience
max_epochs:训练阶段experience的学习次数
num_episodes:数据集迭代次数
首先,当我们给定一个数据集之后,框架会从中选择至多max_samples个prompt。假设我们的数据集仅有1024个prompt,并且1024小于max_samples,则1024个prompt全部保留。
之后我们进入探索阶段,由于一次探索完1024个prompt的时间太长了,所以我们选择一次只对rollout_batch_size个prompt进行探索。我们假设rollout_batch_size为32,则一共需要探索1024÷32=32步。这个32步就是我们在wandb或者tensorboard上面看到的步骤,我们称之为explore step。
我们会用 vllm 对每个prompt进行采样 n_samples_per_prompt 次,得到所有的samples。我们假设 n_samples_per_prompt 为8,则得到了32×8=256个样本,即每个样本都是一个问答对,一共有32个问题,并且相同的问题回答了8次。
之后需要生成 experience,这个时候就需要切换到训练引擎,即在1步内单卡负责生成 micro_rollout_batch_size个经验,我们假设micro_rollout_batch_size为4,我们有8张卡,则1步一共可以生成32个experience。由于我们一共有256个样本,所以需要一共需要256÷32=8步可以得到全部的experience。
在make experience阶段我们主要利用Reward模型得到每个答案的奖励分数、用Critic模型给出每个答案每一步的Value值(如果有Critic模型),以及用Refrence模型和Actor模型给出每个答案每一步的预测概率并且计算出对应的KL惩罚值(如果有Refrence模型)。
现在我们已经结束了探索阶段,进入了训练阶段。我们刚才一共得到了256个experience,但是我们的显卡不足以一次性在所有的样本上进行训练,因此我们设置train_batch_size为128,即每次只更新128个experience,则需要256÷128=2步,也就是说在训练阶段模型更新了2次,我们称之为update step。假设micro_train_batch_size为4,我们有8张卡,则1步一共可以训练32个experience,那么我们需要4步梯度累计,然后才进行反向传播。
当update step大于1,也就是所有的experience不能一次更新完的时候,就称之为off policy,反之如果update step=1,也就是模型探索一步就更新一步,则称之为on policy。
并且我们需要注意,如果max_epochs>1,此时这一组经验被训练了多次,即对256个experience进行了多次优化,那么此时的策略一定是off policy,所以一般情况下我们默认这个参数为1即可,因为我们希望尽可能地确保我们的优化是on policy的。
经过以上流程,我们对于数据集进行了1次完整的探索和训练阶段,即我们的数据集有1024个prompt,每次探索和训练其中的32个,则经过以上流程循环1024÷32=32步,我们已经探索并且训练完了整个数据集。
我们的整个训练流程则需要对整个数据进行num_episodes次的迭代探索和训练,因此整个数据集被探索了32×num_episodes次。
接下来这里会给使用8卡训练一个包含8192条数据集的例子,仅供大家参考
- micro_train_batch_size:4
- train_batch_size:32
- micro_rollout_batch_size:4
- rollout_batch_size:8
- max_samples:8192
- n_samples_per_prompt:16
- max_epochs:1
- num_episodes:1
我们首先计算出 global step,也就是在wand中监控到的global step,是8192(max_samples)÷8(rollout_batch_size)×1(max_epochs)×1(num_episodes)=1024步。
之后我们计算每一个global step内的情况,首先每个global step内有8(rollout_batch_size)×16(n_samples_per_prompt)=128(样本数量)。这个样本是用vllm采样得到的,具体可以看后面的vllm参数。对于128个样本,我们8卡单步可以得到8(gpu数量)×4(micro_rollout_batch_size)=32个experience,所以make experience需要128÷32=4步。
之后我们进入训练,我们的train_batch_size=32,所以每一个global step内需要更新128(experience数量)÷32(train_batch_size)=4步,因此这是一个off policy的策略,也就是说每个global step我们实际上更新了模型4次,所以全部训练更新了模型1024(global step)×4(每个global step内update step个数)=4096步。
我们一次前向传播可以计算8(gpu数量)×4(micro_train_batch_size)=32个experience,正好等于train_batch_size,所以无需梯度累计。
5.5 算法参数
- advantage_estimator:优势计算函数,也是最核心的
- lambd:GAE中的平衡系数
- gamma:计算奖励时的折扣因子
- init_kl_coef:KL惩罚系数
- use_kl_loss:是否使用KL损失函数
- kl_estimator:KL的估计函数
5.6 生成参数
- temperature:采样阶段的温度系数
- prompt_max_len:prompt最大长度
- generate_max_len:生成回答的最大长度