DPO 模型推导
1. 概述
RLHF (Reinforcement Learning from Human Feedback)使用强化学习(Reinforcement Learning)它利用人类的直接反馈来训练“奖励模型”,然后利用奖励模型通过强化学习来优化语言模型的策略 ,以输出可以获得高奖励的回答。
RLHF 方法也存在一些问题。首先,奖励模型的构建需要耗费大量的人力和时间成本。其次,由于奖励模型是基于人类反馈的,因此可能存在主观性和偏见。最后, RLHF 方法需要使用复杂的强化学习算法,这增加了实现难度和计算成本。
为了解决这些问题,斯坦福研究者提出了 DPO (Direct Preference Optimization)算法作为 RLHF 的替代。DPO 算法不需要显式地构建奖励模型,而是直接优化模型生成的回答之间的偏好关系。
DPO 算法的核心思想在于,它假设模型生成的多个回答之间存在偏好关系,即某些回答比其他回答更受用户欢迎。因此, DPO 算法通过比较不同回答之间的偏好关系来优化模型的策略,而不是依赖于显式的奖励模型。
在实际应用中, DPO 算法已经在一些模型中得到了验证。例如, Zephyr 模型就是基于 DPO 算法进行优化的。Zephyr 模型使用 Mistral 7B 作为基础模型,并通过微调来适应不同的任务。在微调过程中, Zephyr 模型使用 DPO 算法来优化生成回答的质量,从而提高了模型的性能。
2. 预备知识
2.1 KL 散度
KL 散度也称为相对熵(Relative Entropy),是衡量两个概率分布差异的一种方法。它是两个概率分布 P 和 Q 之间的非对称距离度量,定义为:
其中, P 是数据的真实分布,而 Q 是模型或估计分布。KL 散度的值总是非负的,当且仅当 P 和 Q 完全相同时, KL 散度为零。
2.2 Bradley-Terry 模型
下面通过一个例子介绍 Bradley-Terry 模型 如何对比较关系进行建模:
| win | Loss | |
|---|---|---|
| A vs B | 8 | 4 |
| A vs C | 3 | 5 |
在这个例子中, A 和 B 对战, 胜 8 场,输 4 场, A 和 C 对战, 胜 3 场, 输 5 场。问题是 B 和 C 对战,获胜的几率有多大?
这个问题可以通过 Bradley-Terry 模型建模。
Bradley-Terry 模型假设每个个体都有一个隐含的实力参数
我们可以通过 MLE 对参数
计算得到:
不使用 MLE, 我们也可以使用机器学习的方式通过迭代优化的方式来进行求解, 上述问题的一般的 Loss 函数可表示成:
可以看到,这就是一般分类问题的交叉熵损失函数的样式, 优化的目标损失函数的值越小越好。 而其中
3. RLHF 研究
现有的 RLHF 流程通常包括三个阶段: 1)监督微调(SFT); 2)偏好采样和奖励学习; 3) RL 优化。
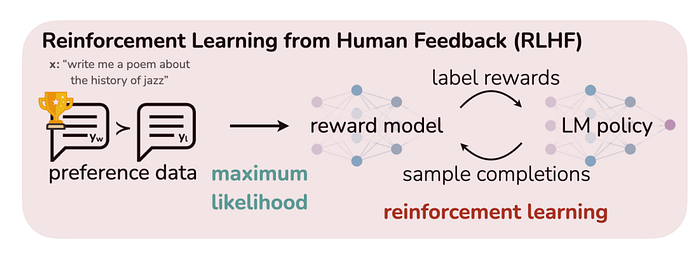
3.1 SFT
RLHF 通常以对感兴趣下游任务(对话、摘要等)的高质量数据进行监督学习来微调预训练的 LM 开始,以获得模型
3.2 Reward Model
在 RLHF 的第二阶段, 我们需要训练一个 Reward 模型来为生成的结果打分。大模型的输入的 Prompt 为 x, 输出的回答为 y,回答的好坏可以通过 Reward 模型打分。
Reward 模型有可能返回负数, 因此我们加上一个指数函数变换, 从而得到 BT 模型中,人类偏好分布
假设我们可以访问来自
其中,
在 LMs 的背景下,网络
3.3 RL 微调阶段
在 RL 阶段,我们使用学习到的奖励函数为语言模型提供反馈。具体来说,我们构建了以下优化问题:
其中
RL 微调阶段的目标是:我们希望找到一个能够最大化奖励的策略,同时我们也希望该策略与初始未优化策略的行为不能相差太大。
4. Direct Preference Optimization (DPO)
DPO 完全消除了对奖励模型的需要。
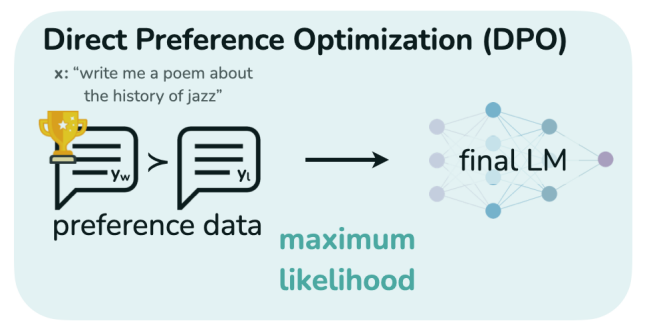
DPO 的策略目标为:
求解上述优化问题的最有解为:
其中:
重新排列
4.1 DPO 更新的作用是什么?
为了深入理解 DPO,分析损失函数
其中
当
直观上,损失函数
4.2 DPO 概述
一般 DPO 流程如下:
- 对于每个提示
,从参考模型 中采样完成 ,用人类偏好标注以构建离线偏好数据集 。 - 优化语言模型
以最小化给定 和 以及期望的 的 。
在实践中,使用公开可用的偏好数据集,而不是生成样本和收集人类偏好。偏好数据集是使用
当可以取得
当
这个过程有助于减少真实参考分布(不可用)和 DPO 使用的
5. DPO 推导
5.1 推导 DPO 的训练目标
进一步,将上式化简得到:
接下来,令:
Z(x) 称为划分函数, 注意划分函数仅是
这是一个有效的概率分布,因为对于所有
现在,由于
Gibbs 不等式告诉我们, KL 散度最小化为 0 当且仅当两个分布相同时。因此我们有最优解:当分布
进一步:
根据 Bradley-Terry 模型, 对于比较关系建模的损失函数可表示为:
这样,我们就得到了 最终的 DPO 损失函数:
因此,不需要优化奖励函数,我们就能优化最优策略。
5.2 在 Bradley-Terry 模型下推导 DPO 目标
在 Bradley-Terry 偏好模型下推导 DPO 目标是直接的,我们有
上面,我们展示了可以将(不可用的)真实奖励通过其相应的最优策略表示:
将方程(39)代入方程(38)我们得到: