大语言模型强化微调实验记录
| Method | RL-Framework | Github | |
|---|---|---|---|
| DeepscaleR | veRL | https://github.com/agentica-project/rllm | |
| Skywork-OR1 | veRL | https://github.com/SkyworkAI/Skywork-OR1 | |
| simpleRL-reason | veRL | https://github.com/hkust-nlp/simpleRL-reason | |
| Open-Reasoner-Zero | OpenRLHF | https://github.com/Open-Reasoner-Zero/Open-Reasoner-Zero |
1. Reasoning Dataset
| 名称 | 主页链接 | 规模 |
|---|---|---|
| OpenR1-Math-220k | https://huggingface.co/datasets/open-r1/OpenR1-Math-220k | 220k |
| OpenThoughts-114k | https://huggingface.co/datasets/open-thoughts/OpenThoughts-114k | 114k |
| dolphin-r1 | https://huggingface.co/datasets/cognitivecomputations/dolphin-r1 | |
| s1K | https://huggingface.co/datasets/simplescaling/s1K | 1k |
| LIMO | https://huggingface.co/datasets/GAIR/LIMO | 1k |
| Bespoke-Stratos-17k | https://huggingface.co/datasets/bespokelabs/Bespoke-Stratos-17k | 17k |
| DAPO-Math-17k | https://huggingface.co/datasets/BytedTsinghua-SIA/DAPO-Math-17k | 17k |
| General Reasoning | https://gr.inc/ | 160 余万 |
| DeepScalerR | https://github.com/agentica-project/rllm | 40K |
| AReaL-boba-Data | https://huggingface.co/datasets/inclusionAI/AReaL-boba-Data | 106k |
| nvidia/Nemotron-Post-Training-Dataset-v1 | https://huggingface.co/datasets/nvidia/Nemotron-Post-Training-Dataset-v1 | 200k |
2. Qwen2.5-1.5B-SFT
| Model | Math500 |
|---|---|
| Qwen2.5-1.5B-Base | 3.0 |
| Qwen2.5-Math-1.5B | 35.8 |
| Qwen2.5-1.5B-Instruct | 55.2 |
| Qwen2.5-1.5B-Base + SFT | 28.8 |
| Qwen2.5-1.5B-Instruct + SFT | 26.4 |
| Qwen2.5-Math-1.5B + SFT | 49.4 |
| DeepSeek-R1-Distill-Qwen-1.5B (Open-R1 Report) | 81.2 |
| DeepSeek-R1-Distill-Qwen-1.5B (DeepSeek Report) | 83.9 |
3. Qwen2.5-1.5B-RL
| Model | Math500 |
|---|---|
| Qwen2.5-Math-1.5B-Base | 35.8 |
| Qwen2.5-Math-1.5B-Base + SFT | 49.4 |
| Qwen2.5-Math-1.5B-Base + RL (5 Steps) | 36.8 |
| Qwen2.5-Math-1.5B-Base + RL (10 Steps) | 44.8 |
| Qwen2.5-Math-1.5B-Base + RL (15 Steps) | 55.8 |
| Qwen2.5-Math-1.5B-Base + RL (20 Steps) | 60.6 |
| Qwen2.5-Math-1.5B-Base + RL (25 Steps) | 64.8 |
| Qwen2.5-Math-1.5B-Base + RL (30 Steps) | 64.4 |
| Qwen2.5-Math-1.5B-Base + RL (35 Steps) | 67.4 |
| Qwen2.5-Math-1.5B-Base + RL (40 Steps) | 67.4 |
| Qwen2.5-Math-1.5B-Base + RL (45 Steps) | 66.0 |
| Qwen2.5-Math-1.5B-Base + RL (50 Steps) | 67.8 |
| Qwen2.5-Math-1.5B-Base + RL (55 Steps) | 68.8 |
| Qwen2.5-Math-1.5B-Base + RL (60 Steps) | 67.4 |
| Qwen2.5-Math-1.5B-Base + RL (65 Steps) | 68.2 |
| Qwen2.5-Math-1.5B-Base + RL (70 Steps) | 67.0 |
| DeepSeek-R1-Distill-Qwen-1.5B (Open-R1 Report) | 81.2 |
| DeepSeek-R1-Distill-Qwen-1.5B (DeepSeek Report) | 83.9 |
4. Qwen2.5-7B-Math-7B + Dr.GRPO
| Model | Math500 | AMC23 | AIME24 |
|---|---|---|---|
| Qwen2.5-math-7B + GRPO (math_lvl3to5_8k) | 79.0 | 62.5 | 26.7 |
| Qwen2.5-math-7B + Dr.GRPO (math_lvl3to5_8k) | 78.4 | 67.5 | 33.3 |
| Qwen2.5-math-7B + Dr.GRPO (math_lvl3to5_8k hand selected 2446) | 74.4 | 62.5 | 23.3 |
| Qwen2.5-math-7B + Dr.GRPO (math_lvl3to5_8k random selected 2446) | 74.6 | 67.5 | 23.3 |
5. System Prompt & Chat Template
5.1 模型和数据
- Model:Qwen2.5-7B-Base
- Train Dataset:GSM8k Train
- Evaluation Dataset:GSM8k Test
5.2 训练曲线
5.3 结果
| Train | qwen25-cot-template | qwen25-chat-template | default |
|---|---|---|---|
| System Prompt & Chat Template | 92.3 | 90.8 | 89.8 |
| Chat Template | 92.6 | 91.7 | 91.3 |
| No System Prompt, No Chat Template | 64.4 | 89.8 | 90.6 |
结论
训练和评估保持一致的模板和数据处理方式确保最佳模型性能。
6. MindSpore VS OpenRLHF
| Model | Framework | With qwen25-math-cot prompt | Without prompt |
|---|---|---|---|
| Qwen2.5-7B | - | 67.4 | 79.7 |
| Qwen2.5-7B + GRPO on gsm8k_train | MindRLHF(mindspore) | 83.5 | 88.0 |
| Qwen2.5-7B + GRPO on gsm8k_train | OpenRLHF(PyTorch) | 92.6 | 91.7 |
7. DeepSeek-R1-Distill-Qwen-32B 模型 NPU 测试
max_new_tokens=32768
temperature=0.6
top_p=0.95| Model | MATH-500 (Qwen-math-eval) | MATH-500 (DeepSeek Reported) |
|---|---|---|
| DeepSeek-R1-Distill-Qwen-32B | 93.2 | 94.3 |
| 模型 | AIME 2024 n_samples=64 | AIME 2024(DeepSeek Reported) |
|---|---|---|
| DeepSeek-R1-Distill-Qwen-32B | 70.625 | 72.6 |
| 模型 | AIME 2025 n_samples=64 | AIME 2025(Skywork Reported ) |
|---|---|---|
| DeepSeek-R1-Distill-Qwen-32B | 55.052 | 59.0 |
8. Skywork-OR1-32B 模型 NPU 测试
| 模型 | AIME 2024 n_samples=64 | AIME 2024(Skywork Reported) |
|---|---|---|
| Skywork-OR1-32B | 81.25 | 82.2 |
| 模型 | AIME 2025 n_samples=64 | AIME 2025(Skywork Reported) |
|---|---|---|
| Skywork-OR1-32B | 72.66 | 73.3 |
9. Qwen QwQ 32B 模型测试
AIME24 & 25 评测
| 模型 | AIME 2024 n_samples=64 | AIME 2024(QwQ Reported) | AIME 2025 n_samples=64 | AIME 2025(QwQ Reported) |
|---|---|---|---|---|
| Qwen QwQ 32B | 79.0 | 79.5 | 67.2 | 69.5 |
10. MindSpeedRL vs OpenRLHF
| 框架 | Branch | 模型 | 超参数 | 标识 | 结果 | |
|---|---|---|---|---|---|---|
| Exp1 | MindSpeedRL | Dev | Qwen 2.5 7B | top_p: 1.0, top_k: -1, temperature: 1.0 | 橙色 | 训练曲线正常 |
| Exp2 | MindSpeedRL | Dev | Qwen 2.5 7B | top_p: 0.9, top_k: 50, temperature: 0.8, min_p: 0.01 | 褐色 | 训练曲线 150 steps 崩了 |
| Exp3 | MindSpeedRL | Master | Qwen 2.5 7B | top_p: 1.0, top_k: -1, temperature: 1.0 | 绿色 | 训练曲线正常 |
| Exp4 | OpenRLHF | Main | Qwen 2.5 7B | top_p: 0.9, top_k: 50, temperature: 0.8, min_p: 0.01 | 灰色 | 训练曲线正常 |
10.1 MindSpeedRL 性能指标 vs Mindspore
10.1.1 MindSpore
| Base Model | NPU 卡数 | rollout_batch_size | num_generations | max_decode_length | mean_response_length | time_per_step |
|---|---|---|---|---|---|---|
| R1-Distill-Qwen-32B | 32 | 32 | 16 | 16 | 8.5K | 2h |
| R1-Distill-Qwen-32B | 64 | 32 | 16 | 16k | 8.1K | 1h |
| R1-Distill-Qwen-32B | 128 | 32 | 16 | 16k | 7.7K | 32min |
10.1.2 MindSpeed
| Base Model | NPU 卡数 | rollout_batch_size | num_generations | max_decode_length | mean_response_length | time_per_step |
|---|---|---|---|---|---|---|
| R1-Distill-Qwen-32B | 32 | 128 | 8 | 8k | 5K | 30min |
| R1-Distill-Qwen-32B | 32 | 32 | 8 | 16k | 8K | 20min |
| R1-Distill-Qwen-32B | 32 | 128 | 8 | 16k | 7K | 50min |
| R1-Distill-Qwen-32B | 32 | 64 | 8 | 16k | 8.5k | 50min |
| R1-Distill-Qwen-32B | 64 | 128 | 8 | 16k | 8.1k | 48min |
| R1-Distill-Qwen-32B | 128 | 32 | 16 | 16k | 7.8k | 22min |
10.2 OpenRLHF
针对 OpenRLHF 的 华为 NPU 适配工作。
- 通过参考 ATorch 中的类似实现,我们在检测到昇腾 NPU 设备可用时,为 OpenRLHF 添加了
transfer_to_npu()函数。 - 支持昇腾 NPU 上的 vLLM 和 Ray 框架。代码在 CANN 8.1.RC1 (通常于 3 月底正式发布)环境下测试。
- 将 Open-R1 中使用的规则奖励移植到 OpenRLHF,为 OpenRLHF 添加了规则奖励模型,支持 PPO、GRPO、Reinforce++ 等算法强化微调。
- 为 OpenRLHF 实现了自定义 KL 散度裁剪算法。
- 为 OpenRLHF 实现了 Dr-GRPO 算法和 Token-level Loss。
10.3 MindSpeed-RL
- 为 MindSpeed-RL 添加了 RLOO、Reinforce++ 等算法。
- 将 Open-R1 中使用的规则奖励移植到 MindSpeed-RL,支持 GRPO、RLOO、Reinforce++ 等算法强化微调。
11. 饱和实验
11.1 RL 的探索困境:为什么 SFT 能改变 long-term exploration
小规模 SFT 改变 RL 的初始探索模式并不反常。然而,随着 RL 进行, policy 应当能探索到不同的思维模式,但实际表现却是 RL 很难跳出 SFT 给定的思维模式(例如 R1 中的 Okay、Wait 等字样)。这是为什么?上述理论仅适用于 step 不多的情况,因此我们从自回归的角度来解释 SFT 的长期效应(long-term effect)。
直觉上, LLM 的自回归生成决定了初始 token 和靠后的 token 受到随机性的影响不同。当靠后的 token 没有收敛到较好的状态时,初始 token 无法得到有效的 advantage。例如模型总是在 100 token 后生成乱码,初始 token 的 advantage 都是 0,模式不会改变。
我们观察 long-CoT-math 的 RL Replay Buffer,记录每个 token 在 initial policy 上的 logprob,并按照 token 在 response 中的位置计算最低 1% 分位数。例如,取所有 response 的第二个 token,计算 1% 分位数作为 position=2 的 logprob。如果这个值随着 RL 过程下降了,说明输出模式在该 position 发生了改变,即信息从后向前传递到了这个位置。
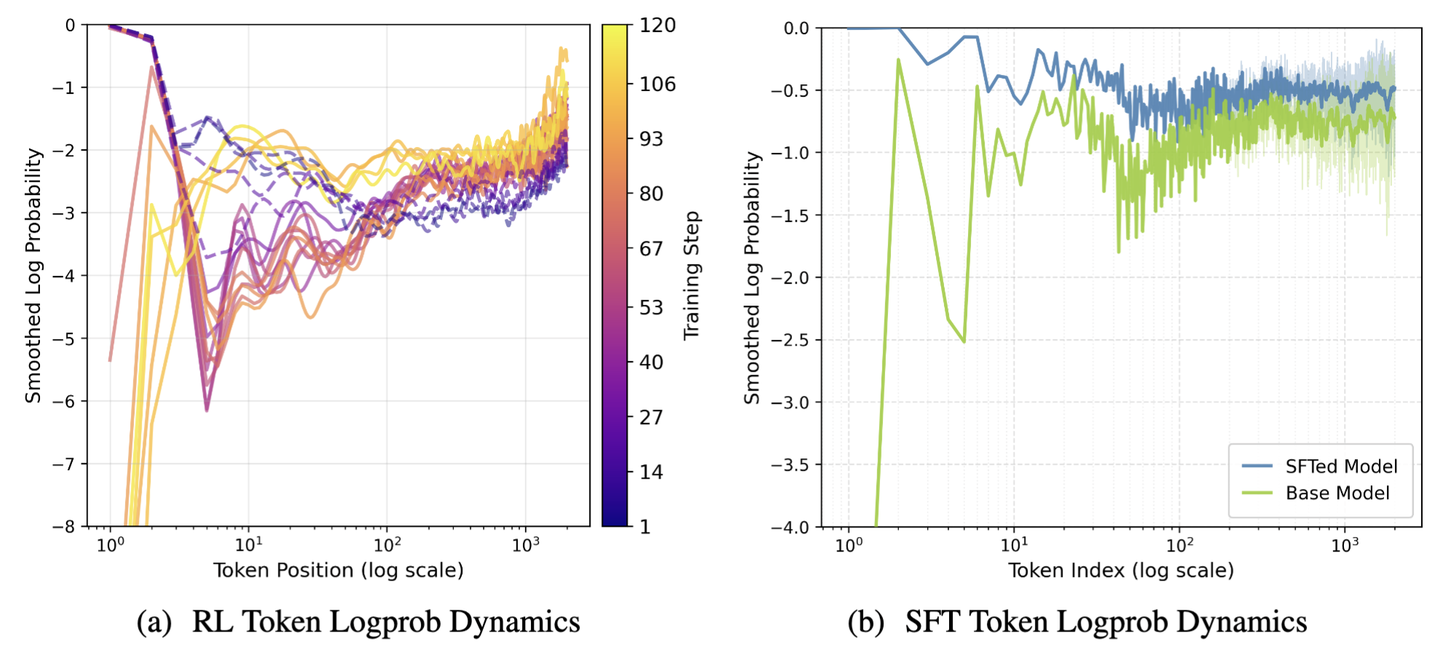
测试结果如上图所示,左图表现出非常有趣的曲线:随着 RL 进行,曲线颜色由深变浅, logprob 最低的位置逐渐向前转移。而 policy 收敛时靠后的 token logprob 竟然升高了。这说明 RL 表现出从后向前的模式转变:靠后的 token 优先被改变,而靠前的 token 最后改变。但 SFT 的趋势则相反,右图显示 SFT 前后的 logprob 变化,靠前的 token 反而是提升最多的。这说明了 RL 和 SFT 的互补关系:如果我们对探索的先验有一定认识,通过 SFT 修改靠前的 token 分布将远优于通过 RL 自主探索。LLM RL 的探索与经典 RL 的不同也可以从这里看出, LLM 的探索更需要依靠小规模 SFT 这一工具,而非通过随机性遍历状态空间。
12. 基于 open-thoughts 强化微调
12.1 Base Model
model: open-thoughts/OpenThinker3-7B
link: https://huggingface.co/open-thoughts/OpenThinker3-7B
12.1.1 AIME 24/25 评测
| 模型 | AIME 2024 n_samples=8 | AIME 2024( Reported) | AIME 2025 n_samples=8 | AIME 2025( Reported) |
|---|---|---|---|---|
| OpenThinker3-7B | 0.7041 | 69.0 | 0.5916 | 53.3 |
12.2 RL Data 预处理
Hugging Face hub: nvidia/AceReason-Math
Num instances: 50k
link: https://huggingface.co/datasets/nvidia/AceReason-Math
处理流程:
- 过滤包含网页和中文的样本 ~38k
- 部署模型,每个样本采样 8 次,剔除全对样本, 剩下约 10K 数据
12.3 第一阶段 RL 训练:
Strict On-policy
cosine_length_penalty
Batch_size: 128
max_tokens: 16384
lr: 1e-6
lr_decay_style: cosine
12.3.1 Reward Func
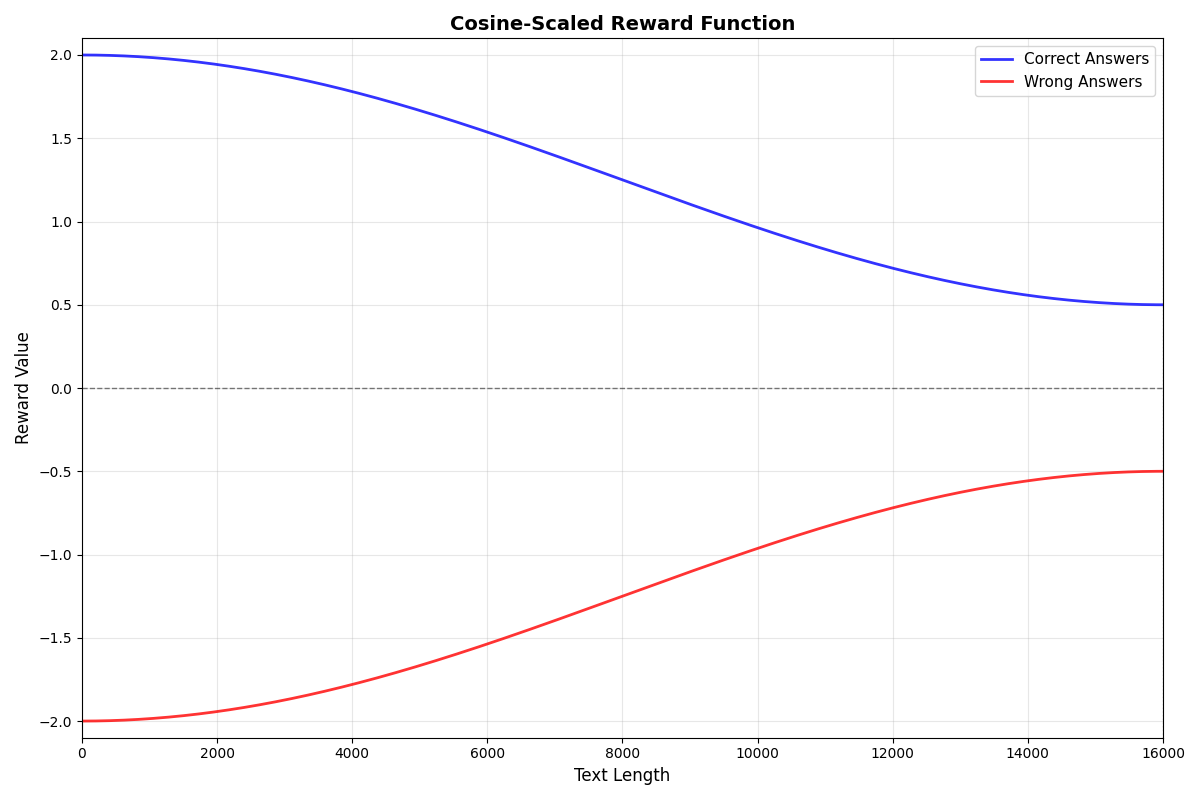
训练结果:
Task: math_opensource/aime24, Accuracy: 0.6479166666666667 Evaluation complete!
Task: math_opensource/aime25, Accuracy: 0.5354166666666667 Evaluation complete!
12.4 RL 前后在 AIME 上推理长度对比
12.4.1 Aime24 长度对比
12.4.2 Aime25 长度对比
12.5 第二阶段 RL 训练:
12.5.1 数据处理
- 部署 Step200 的 RL 模型, 对 10 K 训练数据进行 8 次采样
13. 基于 Open-Reasoner-V1 的继续训练
13.1 Open-Reasoner-V1 评估结果
| max tokens | 16K | 32K | 64K | 128K |
|---|---|---|---|---|
| AIME24 | 42.0 | 77.9 | 85.7 | 85.7 |
| AIME25 | 33.4 | 75.6 | 83.9 | 84.2 |
13.2 续训练数据处理 Part1
从 AM-DeepSeek-R1-0528-Distilled 筛选 CoT Length >32K 的数据进行 8 次采样
13.2.1 SFT 数据
- 从采样的 COT 数据筛选出正确的样本 ~ 48k
13.2.2 DPO 偏好数据
- 排除全部错误的数据
- 有对有错的 CoT 选择(正确,错误)进行配对
- 全部答对的 COT, 选择 top2 Cot 长度最短的 answer 和 Top2 最长的 answer 构成 2x2 的 pair
总数据 ~ 55K
13.2.3 DPO 数据格式
| id | prompt | completion_1 | completion_2 | preferred |
|---|---|---|---|---|
| 1 | Describe a cat | A small domesticated carnivorous mammal with fur. | A furry, small-sized pet that purrs and likes to play. | completion_2 |
| 2 | Explain ML | Machine learning is the study of computer algorithms... | It's about making computers learn from data without being explicitly programmed. | completion_2 |
| 3 | Favorite food | Pizza is loved for its versatility and flavor. | Everybody loves pizza because it can be customized to match individual tastes. | completion_1 |
13.3 DPO Loss
13.4 续训练数据处理 Part2
从 AM-DeepSeek-R1-0528-Distilled SFT 训练筛选数据, 进行 8 次采样, 采样长度 64K。
13.4.1 DPO 偏好数据
- 排除全部错误的数据
- 有对有错的 CoT 选择(正确,错误)进行配对
- 全部答对的 COT, 选择 top2 Cot 长度最短的 answer 和 Top2 最长的 answer 构成 2x2 的 pair
总数据 ~ 72K
13.5 训练曲线
14. Simpo 训练
- 直接使用原始的 SimPO 训练出现了乱码
- 修改 SimPO 的损失公式,增加了监督微调的损失,和原来的损失加权
def get_batch_loss_metrics(
self,
all_policy_logits,
label
) -> Tuple[torch.Tensor, Dict]:
"""
Computes the sum log probabilities of the labels under the given logits.
Otherwise, the average log probabilities.
Args:
all_policy_logits: Logits of the policy model.
all_reference_logits: Logits of the reference model.
label: The label tensor.
Returns:
A tuple containing the loss tensor and a dictionary of metrics.
"""
metrics = {}
(
policy_chosen_log_probs,
policy_rejected_log_probs,
policy_chosen_log_probs_avg,
) = self._compute_log_probs(all_policy_logits, label)
losses, chosen_rewards, rejected_rewards = self.compute_preference_loss(
policy_chosen_log_probs,
policy_rejected_log_probs,
)
# sft_loss = -policy_chosen_log_probs_avg
if self.args.pref_ftx > 1e-6:
sft_loss = -policy_chosen_log_probs
losses += self.args.pref_ftx * sft_loss
reward_accuracies = (chosen_rewards > rejected_rewards).float()
prefix = ""
metrics["{}rewards/accuracies".format(prefix)] = reward_accuracies.detach().mean()
if self.args.pref_ftx > 1e-6:
metrics["{}sft_loss".format(prefix)] = sft_loss.detach().mean()
metrics["{}odds_ratio_loss".format(prefix)] = (
(losses - sft_loss) / self.args.simpo_beta).detach().mean()
return losses.mean(), metrics- 在新的损失函数下,重新训练
- 在 300 步时对模型进行评测
Task: math_opensource/aime24, Accuracy: 0.8458333333333333 Evaluation complete!
Task: math_opensource/aime25, Accuracy: 0.8270833333333333 Evaluation complete!
14.1 实现了强化学习中 Pass@k 作为 reward 的 advantage 函数的计算
14.2 Pass@k 训练详解
14.2.1 Pass@k 指标的定义
给定一个问题
Pass@k 指标被定义为从这
简单来说,只要在这
14.2.2 Pass@k 训练与优势函数的解析解
为了进一步提升 Pass@k 训练的效率和效果,我们不再依赖传统强化学习中的基线(baseline)来估计优势函数,而是直接推导出了一个解析解。这个解析解可以更精确地量化每个答案对最终 Pass@k 奖励的贡献。
我们分别计算了正向答案(positive responses)和负向答案(negative responses)的优势值解析解。其中,
解析解推导:
首先,我们定义一个批次中 Pass@k 奖励的平均值和标准差:
基于均值
通过这个解析解,我们能更精准地计算每个答案的优势值,并指导模型进行更有效的更新。
15. 清洗训练数据集
实现多节点数据并行推理代码。
实现了更加鲁棒的数学评估流程, 对于任意模型生成的结果,可以自动提取 answer 并和 ground_truth 进行比对给出得分。
使用 PCL-Reasoner 模型对 am-thinking 数据集共 100k 进行 8 次推理采样,已完成 60% 。
从 am-thinking-0528 中通过规则等方法清洗数据约 3K
从 skywork 105k 数据集中清洗出 55K
15.1 周报
- 对 PCL-Reasoner-V1 模型在 aime24 和 aime25 上进行 64 次采样评估模型性能:
16. AIME24
Performance Summary:
-------------------
Total Jobs: 1920
Correct: 1668 (86.9%)
AIME25
Performance Summary:
-------------------
Total Jobs: 1920
Correct: 1635 (85.2%)基于 PCL-Reasoner-V1、 PCL-Reasoner-V1 经过 RL 之后的模型 PCL-Reasoner-R1,开源的 OpenReasoning-Nemotron-32B三个模型在 AIME 数据集上的 64 次采样数据, 使用拒绝采样训练 PCL-Reasoner-V1。
在 Hugging Face 上找到两个开源数据集, 这两个数据集的数学 benchmark 难度较大,和 aime 相当
基于 PCL-Reasoner-V1 对这两个数据集进行 8 次采样推理。
16.1 Exp1
16.2 使用拒绝采样训练 PCL-Reasoner-V1
- 实验一:使用全部推理数据,保留推理路径正确的所有样本数据进行训练, 测试结果
2025-10-16 09:05:49,313 - math_eval - INFO - eval.py:163 - ✅ Task: math_opensource/aime24, Accuracy: 85.83%
2025-10-16 09:06:02,241 - math_eval - INFO - eval.py:163 - ✅ Task: math_opensource/aime25, Accuracy: 85.51%- 实验二:使用全部推理数据,保留推理路径正确率 0< acc < 1.0 的数据进行训练, 训练 160 Step, 测试结果
2025-10-27 09:18:12,130 - math_eval - INFO - eval.py:163 - ✅ Task: math_opensource/aime24, Accuracy: 98.54%
2025-10-27 09:18:23,990 - math_eval - INFO - eval.py:163 - ✅ Task: math_opensource/aime25, Accuracy: 97.71%- 实验三: 使用 Omni-math 数据 8 次采样, 保留推理路径正确率 0< acc < 1.0 的数据进行训练, 训练 160 Step, 测试结果
2025-10-28 14:37:23,317 - math_eval - INFO - eval.py:163 - ✅ Task: math_opensource/aime24, Accuracy: 86.25%
2025-10-28 14:37:36,353 - math_eval - INFO - eval.py:163 - ✅ Task: math_opensource/aime25, Accuracy: 82.50%