重新思考 PPO-Clip
1. Dual-Clip PPO
Dual-Clip PPO (双裁剪近端策略优化)是标准 PPO (Proximal Policy Optimization) 算法的一种改进版本,主要目的是更有效地处理优势函数(Advantage,
1.1 标准 PPO-Clip 概述 (背景)
为了理解 Dual-Clip,我们首先回顾标准 PPO-Clip 的目标函数。PPO 目标函数(最大化形式):
其中:
是重要性采样比率。 是优势函数估计。 是裁剪超参数 (如 0.1 或 0.2)。
这个目标函数
- 当
(动作好于平均):我们希望提高 (即增加该动作的概率 )。但 操作会限制 不能超过 。 - 当
(动作差于平均):我们希望降低 (即减小该动作的概率 )。但 操作会限制 不能低于 。
标准 PPO 的缺陷 (针对
- 当
为负时,我们希望策略更快地减少这个糟糕动作的概率(即让 趋近于 0)。然而,标准 PPO 的 操作会将目标函数限制在 处,即使 进一步减小(趋近于 0),目标函数也不会再增加,导致策略对负优势的动作修改不够彻底。
1.2 Dual-Clip PPO 的核心改进
Dual-Clip PPO 引入了第三个裁剪项
其中,第三项
是一个新的超参数,通常设置为 2.0 ~ 5.0 (原文建议 3.0)
1.3 Dual-Clip 的逻辑分解
Dual-Clip 目标函数可以分解为两种情况:
1.3.1 🟢 情况一:优势函数
行为: 此时
结论: 在
1.3.2 🔴 情况二:优势函数
(注:当
行为:
减小 (期望行为):我们希望 变小(趋近于 0),此时 和 都会增大(因为 是负数)。标准 PPO 的目标会被 在 处钳制住。 增大 (不期望行为):如果 不幸增大(策略变差),目标函数会减小。 的作用:由于 且 ,我们有 是一个比 负得更厉害的数。当 超出 时(即 ),则 会小于 。
通过下表对比分析在不同情况下 Dual-Clip 如何影响更新:
| 场景 | 标准 PPO 行为 | Dual-Clip 行为 |
|---|---|---|
| 好动作,适度提升 ( | 使用原始梯度 | 相同 |
| 好动作,大幅提升 ( | 使用裁剪梯度(限制提升) | 相同 |
| 坏动作,适度抑制 ( | 使用裁剪梯度(加强惩罚) | 相同 |
| 坏动作,大幅偏离但优势高估 ( | ❌ 仍允许更新(可能错误强化) | ✅ 强制限制为 |
Dual-Clip 的实际限制:
在
核心总结: Dual-Clip PPO 的
1.4 代码实现要点(veRL 框架)
# Step 1: Standard PPO clipping
pg_losses1 = -advantages * ratio
pg_losses2 = -advantages * torch.clamp(ratio, 1 - clip_low, 1 + clip_high)
clip_pg_losses1 = torch.maximum(pg_losses1, pg_losses2)
# Step 2: Upper-bound clipping (Dual-Clip)
pg_losses3 = -advantages * clip_ratio_c
clip_pg_losses2 = torch.min(clip_pg_losses1, pg_losses3)
# Step 3: Final selection based on advantage sign
pg_losses = torch.where(advantages < 0, clip_pg_losses2, clip_pg_losses1)🧠 关键点:只有当优势为负时才启用上界裁剪,因为正优势时我们希望鼓励好动作,不需要额外限制。
| 代码片段 | 作用 | Dual-Clip 关键点 |
|---|---|---|
pg_losses1 = -advantages * ratio | 计算 | 对应 |
pg_losses2 = -advantages * torch.clamp(...) | 计算第二项的负数形式(标准裁剪)。 | 对应 |
clip_pg_losses1 = torch.maximum(pg_losses1, pg_losses2) | 标准 PPO 目标损失(负数形式): | 对应 |
pg_losses3 = -advantages * clip_ratio_c | 计算 | 对应 |
clip_pg_losses2 = torch.min(pg_losses3, clip_pg_losses1) | 结合 | 这是 |
pg_losses = torch.where(advantages < 0, clip_pg_losses2, clip_pg_losses1) | 最终选择:clip_pg_losses2);clip_pg_losses1)。 | 实现了逻辑分离,确保 |
总结
Dual-Clip PPO 通过引入
| 特性 | 标准 PPO-Clip | Dual-Clip PPO |
|---|---|---|
| 目标 | 限制策略更新,防止步长过大。 | 在保持 PPO 优点的基础上,更严格地限制负优势下 |
| 上限: | 上限: | |
| 下限: | 上限: |
🎯 适用场景
Dual-Clip PPO 特别适用于以下情况:
- 稀疏奖励环境:容易出现优势估计偏差
- 长序列生成任务(如对话、代码生成):价值函数难以准确建模
- 离线强化学习(Offline RL):数据分布固定,需防止离策略更新过激
- 大模型 RLHF 训练:防止语言模型“钻牛角尖”生成奇怪但高 reward 的文本
✅ 实践建议:
- 在标准 PPO 训练不稳定时尝试启用 Dual-Clip;
- 设置
clip_ratio_c = 3.0作为起点; - 监控
pg_clipfrac_lower指标,若过高说明上界频繁触发,可能需要调整或检查优势估计质量。
2. 解耦裁剪 (Decoupled Clip)
传统的 PPO 使用对称的裁剪范围
为了更好地鼓励探索, DAPO 引入了Clip-Higher机制,即放宽 PPO 裁剪范围的上限
3. 动态自适应裁剪(DAC)
3.1 问题根源
让我们再次审视 PPO 和 GRPO 中使用的概率比率裁剪。其目的是防止单次更新步长过大,导致策略崩溃。约束条件为:
其中,
现在,我们考虑一个场景:模型正在解决一个复杂的数学问题,其中某一步需要一个不常用但至关重要的符号或数字(我们称之为“稀有 token ”)。在旧策略
这暴露了固定裁剪的本质缺陷:它对所有 token 施加了相同的相对变化约束,却忽略了它们的绝对概率基础。对于高概率 token,小范围的相对变化是合理的;但对于极低概率的 token,这种约束会阻止模型从罕见但正确的经验中学习的机会,从而导致探索不足和学习效率低下。
3.2 DAC 的理论基础
DCPO 的作者们提出了一个洞见:裁剪边界本身不应该是固定的,而应该与 token 自身的概率动态关联。他们将约束条件从对概率比率
这个公式的直观解释是:我们约束的是概率变化的绝对量(
这种设计契合了强化学习的探索需求:在低概率区域(未知领域)允许更大胆的探索步伐,而在高概率区域(已知领域)则采取更谨慎的微调。
3.3 DAC 边界的推导过程
接下来,我们看一下 DAC 是如何从上述理论推导出具体的、可操作的裁剪边界。
首先,将
这里, DCPO 为上下界分别设置了不同的超参数
解这个关于
这个公式看起来复杂,但其行为趋势非常清晰:
当旧策略概率
趋近于 0 时,分母上的 使得 这一项变得巨大。这意味着 的上界会随着 的减小而显著增大(具体行为是与 成正比)。这正是我们所期望的——为低概率 token 提供了广阔的探索空间。 当旧策略概率
趋近于 1 时,根号下的项趋近于常数,使得整个边界收敛到一个较为固定的区间,与 GRPO 的行为类似,保证了在高概率区域的稳定性。
此外,为了防止
3.4 DAC vs. 固定裁剪
论文中的图 4 直观地展示了 DAC 与固定裁剪在行为上的巨大差异。
- 在固定裁剪(GRPO)中,允许的新概率
与旧概率 之间形成一个由直线 和 包围的狭长区域。当 很小时,这个允许的绝对概率空间 也被压缩得非常小。 - 在动态自适应裁剪(DCPO)中,这个允许区域不再是线性的。对于低
值,上界曲线显著向上弯曲,为 提供了远超固定裁剪的增长空间。这片额外多出来的“探索区域”,正是 DCPO 能够更有效利用稀有但关键的 token 信息的关键所在。
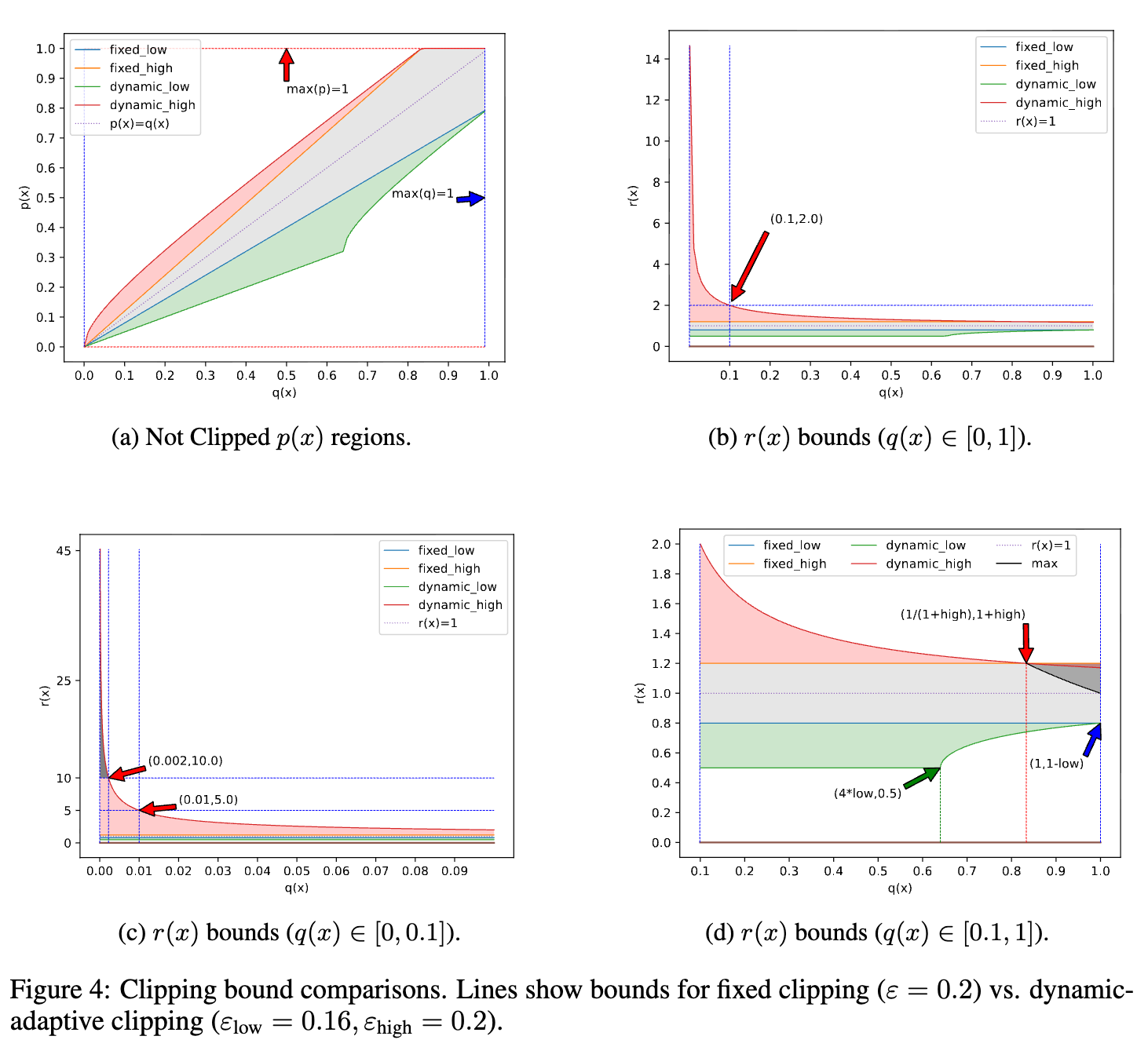
通过 DAC, DCPO 在不牺牲稳定性的前提下,极大地解放了模型的探索潜力,使得策略优化过程更加高效和有的放矢。
4. 非对称策略优化 ASPO
4.1 策略损失函数分析
4.1.1 compute_policy_loss_vanilla 函数(PPO 基础和 Dual-Clip PPO)
这个函数实现了标准的 PPO 剪切目标(Clipped Objective),并加入了 Dual-Clip PPO 的逻辑。
- 核心逻辑:
- 计算重要性采样的比率
。 - 计算原始策略梯度损失项
。 - 计算剪切策略梯度损失项
。 - 标准 PPO 目标是
,即取 。 - Dual-Clip PPO (双重剪切): 引入了额外的剪切项
(其中 )。 - 当 优势估计
(即当前动作不好)时,策略损失目标变为 。这进一步限制了损失的最小化(即策略的更新),避免在新策略下不好的动作的概率被过度降低。
- 当 优势估计
- 计算重要性采样的比率
- 输入参数: 使用统一的
,并可选择性地使用 、 进行不对称剪切,以及 用于 Dual-Clip。
4.1.2 compute_policy_loss_archer 函数(ARCHER 策略优化)
compute_policy_loss_archer 引入了 ARCHER (Adaptive Reward-Conditioned High-Entropy Regularization) 的策略优化思想。它主要体现在 动态剪切范围 和 基于优势符号的损失分离处理 两个方面。
- 实现优化的具体改变:
4.1.3 🚀 改变 1: 引入基于熵(Entropy)的 动态剪切范围
函数引入了 high_entropy_mask 和四个不同的剪切参数:
negative_low_entropy_clip_ratio_lownegative_high_entropy_clip_ratio_lowpositive_low_entropy_clip_ratio_highpositive_high_entropy_clip_ratio_high
它根据 优势 high_entropy_mask 动态地计算
| 优势符号 (A^t) | high_entropy_mask | 剪切范围 (Ratio rt) | 参数 | 目的 |
|---|---|---|---|---|
| 负 ( | True (高熵) | 相对保守地降低 | ||
| 负 ( | False (低熵) | 积极地降低 | ||
| 正 ( | True (高熵) | 相对保守地提高 | ||
| 正 ( | False (低熵) | 积极地提高 |
优化效果: 这是一个 自适应的策略更新。
- 对于 低熵(即策略分布较集中,可能更确定或更自信)的动作,允许使用 更大的
(即 和 通常大于 和 ),使得策略更新可以更激进。 - 对于 高熵(即策略分布较分散,可能更不确定)的动作,使用 更小的
,使得策略更新更保守,以维持探索。
4.1.4 🚀 改变 2: 基于优势符号的 策略损失项分离处理
函数将策略损失项 根据
- 优势
(负向更新): negative_pg_losses_clip:使用动态的 PPO 剪切项。 - 引入
。 negative_pg_losses_dual:当时激活。 - 不同之处:
compute_policy_loss_vanilla的 Dual-Clip 项是,而 compute_policy_loss_archer的 Dual-Clip 项是,这看起来是一个不同的实现,它结合了 和 。
- 优势
(正向更新): positive_pg_losses_clip:使用动态的 PPO 剪切项。 - 引入
。 positive_pg_losses_dual:当时激活。 - 不同之处: 为正向优势引入了一个 Dual-Clip 机制,但这里的实现逻辑比较复杂,似乎是在
上进行操作,而不是在 上,这进一步限制了 的上限,避免过度增加好的动作的概率。
4.1.5 优化总结
compute_policy_loss_archer 函数主要实现了以下优化:
- 分段式、自适应剪切(Entropy-Conditioned Clipping): 根据动作的 熵水平 和 优势符号 动态调整 PPO 的剪切范围 (
。这使得策略在不确定(高熵)的动作上更新保守,在确定(低熵)的动作上更新激进,从而平衡探索和利用。 - 正负优势的 Dual-Clip 分离: 提供了独立的
和 ,用于分别控制负向更新和正向更新的 Dual-Clip 行为,实现更精细的策略控制。 - 对正向更新的限制: 引入了一种 针对
的 Dual-Clip 机制,旨在防止新策略过度偏离旧策略,即使是在有利的动作上,这有助于提高训练稳定性。