veRL 框架概览
veRL (火山引擎强化学习库)是一个灵活、高效且可直接投入生产的强化学习训练库,专为大型语言模型(LLMs)设计。该项目是论文 《HybridFlow:灵活高效的 RLHF 框架》 的开源实现,旨在支持跨算法、模型和硬件配置的可扩展人类反馈强化学习(RLHF)。
veRL 提供了一种混合编程模型,结合了 Single-Controller 与 Multi-Controller 范式的优势,能够灵活表示并高效执行复杂的训练后数据流。该框架与现有 LLM 基础设施(包括 PyTorch FSDP、Megatron-LM、vLLM 和 SGLang)实现无缝集成。
1. 核心原则
1.1 控制流与计算流分离
HybridFlow 通过分离两个关键关注点来解决分布式强化学习训练的挑战:
- 控制流 :单进程编排 RL 算法逻辑(PPO 训练周期、优势计算、数据管理)
- 计算流 :神经网络操作的多进程分布式执行(训练、推理、权重同步)
1.2 控制流实现
控制流实现为单个 Ray 远程进程,负责协调整个训练流程。该设计在协调分布式计算的同时,支持调试和算法开发。
入口点 main_task() 函数位于 veRL/trainer/main_ppo.py,作为驱动进程:
@ray.remote(num_cpus=0.1, num_gpus=0)
def main_task(config, tokenizer):
# Single process that coordinates everything
trainer = RayPPOTrainer(...)
trainer.fit() # Main training loop1.3 计算流实现
计算流将神经网络操作分配到专门的 Ray 工作进程,每个进程负责 RLHF 流程中的特定角色。
Workers 通过 @register 装饰器系统向控制流暴露方法,该系统自动处理数据分发与收集:
class ActorRolloutRefWorker(Worker):
@register(dispatch_mode=Dispatch.DP_COMPUTE_PROTO)
def generate_sequences(self, prompts: DataProto):
# Distributed generation across multiple GPUs
@register(dispatch_mode=Dispatch.DP_COMPUTE_PROTO)
def update_actor(self, data: DataProto):
# Distributed policy training1.4 调度模式系统
@register 装饰器系统采用分发模式自动处理跨 worker 的数据分发与收集:
| Dispatch Mode 调度模式 | Usage 用法 | Data Handling 数据处理 |
|---|---|---|
Dispatch.ONE_TO_ALL | Model initialization | Broadcast same data to all workers |
Dispatch.DP_COMPUTE_PROTO | Training/inference | Split DataProto across workers, gather results |
Dispatch.MEGATRON_COMPUTE_PROTO | Megatron training Megatron | Handle TP/PP data distribution |
Dispatch.MEGATRON_PP_AS_DP_PROTO | HybridEngine generation | Treat PP dimension as DP for rollout |
1.5 关注点分离
混合流(HybridFlow)将控制逻辑与计算执行分离,从而能够:
- 集中式协调 :算法逻辑与数据流的单点控制
- 分布式计算 :通过专业化 worker 实现并行执行
- 模块化集成 :系统组件间采用清晰接口设计
2. 核心特性
veRL 具备以下核心能力:
2.1 多样化 RL 算法的轻松扩展
混合控制器编程模型支持以数行代码构建 GRPO、PPO 等 RL 数据流,通过优势估计器注册系统实现复杂训练后数据流的灵活表达与高效执行。
2.2 现有 LLM 基础设施的无缝集成
解耦计算与数据依赖,可无缝对接 FSDP、Megatron-LM、vLLM 等 LLM 框架。模块化 API 支持将模型部署至不同 GPU 组以实现高效资源利用。
2.3 业界领先的性能表现
- 高吞吐量 :集成 SOTA 级 LLM 训练与推理引擎,实现高生成与训练吞吐
- 高效的 Actor 模型重分片 : 3D-HybridEngine 消除内存冗余,降低训练与生成阶段切换时的通信开销
3. 支持的算法与特性
3.1 强化学习算法
veRL 通过 verl.trainer.ppo.core_algos 中的 ADV_ESTIMATOR_REGISTRY 和 POLICY_LOSS_REGISTRY 系统实现强化学习算法:
# Advantage estimator registration
@register_adv_est(AdvantageEstimator.GRPO)
def compute_grpo_outcome_advantage(...)
# Policy loss registration
@register_policy_loss("ppo")
def compute_policy_loss(...)| Registry Type | Purpose | Key Implementations |
|---|---|---|
ADV_ESTIMATOR_REGISTRY | Advantage computation | GAE, GRPO, RLOO, OPO, GPG GAE、GRPO、RLOO、OPO、GPG |
POLICY_LOSS_REGISTRY | Policy loss functions | PPO, GPG, custom losses |
3.2 训练特性
- 基于模型与函数的奖励机制 :支持神经 RewardModel 和可验证奖励函数(适用于数学、编程等领域)
- 多模态强化学习 :支持视觉语言模型(VLM),包括 Qwen2.5-VL、Kimi-VL
- 多轮工具调用 :先进的对话与工具集成能力
- 序列优化 : Flash Attention 2 注意力机制、序列打包、通过 DeepSpeed Ulysses 实现的序列并行
- Memory efficiency: LoRA support, Liger-kernel integration, multi-GPU LoRA RL
- 可扩展性 :支持高达 6710 亿参数的专家并行模型
3.3 支持的模型
| Model Family | Examples | Hub Support | Special Features |
|---|---|---|---|
| Qwen | Qwen-3, Qwen-2.5, Qwen2.5-VL Qwen-3、Qwen-2.5、Qwen2.5-VL | Hugging Face, ModelScope | Multi-modal support |
| Llama | Llama 3.1, Llama 3.2 Llama 3.1、Llama 3.2 | Hugging Face | Wide ecosystem support |
| DeepSeek | DeepSeek-LLM, DeepSeek-V3-0324, DeepSeek-671B DeepSeek-LLM、DeepSeek-V3-0324、DeepSeek-671B | Hugging Face | Large MoE models |
| Gemma | Gemma2 | Hugging Face | Efficient architecture |
| Other VLMs | Kimi-VL | ModelScope | Vision-language capabilities |
3.4 Model Hub 集成
veRL 通过标准化的模型适配器和检查点管理器与主流 Model Hub 实现集成:
Model Hub 集成:
- Hugging Face Transformers:原生支持
transformers库 - ModelScope:通过环境变量
VERL_USE_MODELSCOPE=True启用支持
| Model Source | Configuration | Implementation | Use Case |
|---|---|---|---|
| Hugging Face Hub | Default model loading | transformers.AutoModelForCausalLM | Standard model access |
| ModelScope Hub | VERL_USE_MODELSCOPE=True | modelscope.AutoModelForCausalLM | Chinese alternative |
| Local/HDFS Paths | Direct file paths | Local filesystem loading | Custom model deployment |
4. 分布式训练与推理
4.1 训练后端支持
veRL 通过 single_controller 框架中定义的统一 Worker 接口支持多种分布式训练后端:
| Backend | Key Features | Parallel Strategies | Recommended Use Case | Scaling Capability |
|---|---|---|---|---|
| FSDP/FSDP2 | PyTorch native, easy model integration | Data Parallel, Sequence Parallel | Research, prototyping, broad HF model support | Up to ~70B parameters |
| Megatron-LM | 5D parallelism, highly optimized | TP, PP, DP, EP, CP | Production, large-scale training, MoE models | Up to 671B+ parameters |
FSDP 特性:
- 兼容 Hugging Face Transformers
- FSDP2 支持,提供更高的吞吐量和更优的内存使用效率
- 支持 CPU 卸载与梯度累积
- 易于集成和调试
Megatron 特性:
- 张量并行(TP)、流水线并行(PP)、数据并行(DP)
- 专家并行(EP)用于混合专家模型,上下文并行(CP)
- 支持 6710 亿+参数模型(DeepSeek-V3、Qwen3-235B)
- 高度优化的内核与通信
4.2 推理引擎
veRL 通过 @register 装饰器系统的 ActorRolloutRefWorker.generate_sequences() 方法集成多推理引擎:
| Engine | Key Features | Best For | Version Support |
|---|---|---|---|
| vLLM | PagedAttention, continuous batching, high throughput | Large-scale inference, production deployments | v0.8.3+ (recommended: VLLM_USE_V1=1) |
| SGLang | Multi-turn conversations, tool calling, memory efficient | Agentic workflows, complex interactions | Latest versions supported |
| Hugging Face TGI | Simple integration, debugging | Single GPU exploration, debugging | Basic support |
vLLM 集成:
- 专为强化学习训练期间的高吞吐量生成而优化
- 采用分页注意力机制提升内存效率
- 支持张量并行计算
- CUDA 图优化技术
SGLang 集成
- 高级多轮对话支持
- 工具调用与功能集成
- 高效内存服务
- 代理循环能力
5. 性能与可扩展性特性
veRL 实现了多种并行策略与优化技术以实现高效扩展:
5.1 并行实现
| Parallelism Type | Implementation | Configuration | Use Case |
|---|---|---|---|
| Tensor Parallel (TP) | Megatron-LM, vLLM Megatron-LM, vLLM | tensor_model_parallel_size | Large model layers (>70B params) |
| Pipeline Parallel (PP) | Megatron-LM | pipeline_model_parallel_size | Memory-constrained training |
| Data Parallel (DP) | FSDP, Megatron-LM | world_size | Multi-GPU scaling |
| Expert Parallel (EP) | Megatron-LM | expert_model_parallel_size | MoE models (671B+) |
| Context Parallel (CP) | Megatron-LM | context_parallel_size | Long context training |
| Sequence Parallel (SP) | DeepSpeed Ulysses | ulysses_sequence_parallel_size>1 | Long sequence handling |
5.2 内存优化特性
| Optimization | Configuration | Backend | Description |
|---|---|---|---|
| FSDP CPU Offloading | fsdp_config.offload_policy=True | FSDP | Offload parameters to CPU |
| Megatron Offloading | megatron.param_offload=True | Megatron | Parameter, gradient, optimizer offloading |
| Gradient Checkpointing 梯度检查点 | enable_gradient_checkpointing=True | Both | Trade computation for memory |
| Sequence Packing | use_remove_padding=True | Both | Efficient sequence handling |
| Dynamic Batch Size | use_dynamic_bsz=True | FSDP | Token-based batching |
| LoRA Fine-tuning | enable_lora=True | FSDP | Parameter-efficient training |
| Flash Attention 2 | Automatic | Both | Efficient attention implementation |
| Liger Kernel | use_liger=True | SFT | Optimized CUDA kernels |
| Entropy Checkpointing | entropy_checkpointing=True | FSDP | Memory-efficient entropy calculation |
6. 核心训练系统
核心训练系统是 veRL 框架中协调多节点多 GPU 分布式强化学习训练的中枢编排层。该系统负责管理训练工作流生命周期、协调不同工作角色(Actor、评判器、推演器)、处理资源分配,并提供训练执行的主要入口点。
核心训练系统采用混合架构设计,通过 Ray 框架由 Single-Controller 进程协调分布式计算 worker。系统将控制流(单进程)与计算流(分布式 worker)分离。
6.1 主要入口点
根据后端策略不同,训练系统提供多个入口点:
| Entry Point | Purpose | Backend Support |
|---|---|---|
main_ppo.py::main() | Primary PPO training entry | FSDP, Megatron |
TaskRunner.run() | Ray remote execution wrapper Ray | All backends |
RayPPOTrainer.fit() | Core training loop | All backends |
6.2 RayPPOTrainer
RayPPOTrainer 类作为分布式 PPO 训练的核心协调器,负责管理 worker 生命周期、协调训练步骤以及处理不同 worker 类型间的数据流。
主要职责:
- worker 初始化与管理
- 训练循环执行
- worker 间的数据协调
- 检查点管理
- 验证过程执行
核心方法:
init_workers()- Initialize distributed workersinit_workers()fit()- Main training loopfit()_train_step()- Execute single training iteration_train_step()_validate()- Run validation process_validate()
6.3 训练循环实现
fit() 方法中的主训练循环实现标准 PPO 算法流程:
Sequence Generation: Actor generates responses using rollout workers
Reward Computation: Rewards are computed using reward functions or reward models
Advantage Estimation: Various estimators (GAE, GRPO, REINFORCE++) compute advantages
Policy Updates: Actor is updated using PPO loss with multiple epochs
Value Updates: Critic is updated to predict better value estimates
6.4 Worker 角色系统
RayPPOTrainer 采用基于角色的 worker 系统,不同类型 worker 处理特定训练环节。每个角色可映射至不同 worker 实现(FSDP 或 Megatron 后端)。
| Role 角色 | Class 类 | Responsibility 职责范围 |
|---|---|---|
Role.ActorRollout | ActorRolloutRefWorker | Policy training + response generation |
Role.Critic | CriticWorker | Value function training |
Role.RewardModel | RewardModelWorker | Reward computation |
Role.RefPolicy | ActorRolloutRefWorker | Reference policy for KL penalty |
6.5 Worker 初始化流程
Trainer 通过 init_workers() 方法根据选定的后端策略初始化 worker:
- Resource Pool Creation: GPU resources are allocated across nodes 资源池创建 :跨节点分配 GPU 资源
- Worker Class Selection: Backend-specific worker classes are chosen worker 类选择 :选择特定后端的 worker 类
- Ray Actor Creation: Workers are instantiated as Ray remote actors Ray Actor 创建 :将 worker 实例化为 Ray 远程 actor
- Model Initialization: Each worker initializes its models and optimizers 模型初始化 :每个 worker 初始化其模型和优化器
- Cross-Worker Synchronization: Initial state synchronization occurs 跨 worker 同步 :执行初始状态同步
6.6 数据流与处理
训练系统通过标准化的 DataProto 协议处理数据,确保组件间数据交换一致性
Key data processing functions: 关键数据处理函数:
compute_advantage()- Compute advantage estimates using GAE, GRPO, or other estimatorsapply_kl_penalty()- Apply KL divergence penalty to rewardscompute_response_mask()- Generate attention masks for response tokens
PPO 训练遵循结构化数据流模式,数据会流经不同处理阶段:
Raw data → DataLoader → DataProto batch
DataProto → Rollout → Generated responses
Responses → Reward function → Token-level rewards
All inputs → Advantage computation → Training-ready data
7. Single-Controller 模式
veRL 采用 Single-Controller 设计模式,通过中心化的 Ray 驱动进程协调分布式计算 Workers。该模式实现:
- 简化的控制流 :为复杂工作流提供单一协调点
- 弹性资源管理 :动态将 Workers 分配至不同任务
- 简易调试 :集中式日志记录与错误处理
- 模块化设计 :控制逻辑与计算逻辑清晰分离
Single-Controller 模式为 veRL 的分布式计算提供了统一抽象层,能够无缝协调不同后端的工作进程。它通过管理工作组、资源分配和方法调度模式,成为分布式训练和推理操作的基础架构。
7.1 硬件抽象
该框架通过以下方式提供硬件抽象:
get_device_name():返回适用的设备类型(CUDA、NPU、CPU)get_torch_device():返回对应的 torch 设备命名空间get_visible_devices_keyword():返回设备可见性的环境变量get_nccl_backend():返回适用的通信后端
这种抽象设计使得 veRL 只需最小代码修改即可在不同硬件平台上运行,支持:
- NVIDIA GPU
- AMD GPU
- 昇腾 NPU
- CPU (用于调试)
7.2 核心架构概述
该架构包含:
- 控制层 :定义核心接口的抽象基类
- 执行层 : worker 实现与方法装饰系统
- 后端层 : Ray 框架对抽象接口的具体实现
- 训练集成 :与 veRL 训练系统的集成
7.3 Worker
Worker 类作为所有分布式 worker 的基类,负责初始化、环境配置、通信建立和硬件抽象
Worker 类管理分布式训练环境搭建,并提供装饰方法供执行:
| Environment Variable 环境变量 | Purpose 目的 |
|---|---|
WORLD_SIZE | Total number of workers |
RANK | Worker's global rank |
LOCAL_RANK | Worker's local rank on node |
MASTER_ADDR | Master node address |
MASTER_PORT | Master node port |
CUDA_VISIBLE_DEVICES | GPU device visibility GPU |
框架包含全面的硬件抽象以支持不同平台:
| Platform | Device Type | Visible Devices Env | Communication Backend |
|---|---|---|---|
| NVIDIA GPUs NVIDIA GPU | cuda | CUDA_VISIBLE_DEVICES | nccl |
| AMD GPUs AMD GPU | cuda | HIP_VISIBLE_DEVICES | nccl |
| Ascend NPUs | npu | ASCEND_RT_VISIBLE_DEVICES | hccl |
| CPU | cpu | N/A 无 | N/A |
7.4 WorkerGroup
WorkerGroup 类负责管理工作线程集合,并为分布式执行提供方法绑定。该组件是协调分布式操作的核心抽象层。
WorkerGroup._bind_worker_method() 函数通过 @register 装饰器属性动态绑定 worker 方法,实现分布式执行模式。该机制是将本地方法调用转化为分布式操作的核心组件。
主要职责:
- 管理 worker 生命周期与引用
- 将装饰器修饰的工作方法绑定到组接口
- 提供执行模式(所有 worker、仅 rank-zero 节点等)
- 处理数据分发与结果收集
7.5 ResourcePool
ResourcePool 类负责管理跨节点的资源分配,追踪进程数量与 GPU 分布情况。它为硬件资源管理提供了可被不同后端实现的抽象层。
| Property 属性 | Description 描述 |
|---|---|
world_size | 所有节点的进程总数 |
store | 各节点进程数量列表 |
max_colocate_count | 每个 GPU 的最大进程数 |
n_gpus_per_node | 每个节点可用的 GPU 数量 |
ResourcePool 提供了一个硬件抽象层,使框架能够在分布式环境中高效分配和管理计算资源。
7.6 Ray 实现方案
Ray 后端通过放置组支持和资源调度功能,为核心抽象提供了具体实现。Ray 是 veRL 中使用的主要分布式计算后端。
7.6.1 RayWorkerGroup
RayWorkerGroup 类继承 WorkerGroup 并扩展了用于管理分布式 Ray 参与者的 Ray 特有功能。
Ray 实现的关键特性:
- Placement Groups:
sort_placement_group_by_node_ip()确保重启时 worker 布局保持一致 - Resource Bundles: 支持通过
max_colocate_count配置 GPU 与 CPU 的分配方案 - Environment Isolation: 每个 worker 获得独立的环境变量配置,保障分布式训练隔离性
- Fused Workers: 支持通过
create_colocated_worker_cls_fused()实现资源共享的共置 worker - Detached Workers: 支持持久化的 worker,可在驱动重启后继续存活
RayWorkerGroup 实现方案处理以下复杂逻辑:
- 创建并管理具有特定资源需求的 Ray Actor
- 配置分布式训练环境变量
- 协调 worker 之间的通信
- 处理方法调度与结果收集
7.6.2 Ray 资源池
RayResourcePool 继承基础 ResourcePool 并扩展了 Ray 特有的放置组管理功能。它负责创建和管理用于资源分配的 Ray 放置组。
资源包配置:
# Resource bundle configuration
bundle = {"CPU": self.max_colocate_count}
if self.use_gpu:
bundle[device_name] = 1 # GPU or NPU
if self.accelerator_type is not None:
bundle[self.accelerator_type] = 1e-4RayResourcePool 提供以下功能:
Creation and caching of Ray placement groups
支持多种硬件类型(CUDA、ROCm、NPU)
可配置的放置策略
支持分离式(持久化)放置组
7.7 调度与执行系统
该框架采用基于装饰器的系统来定义数据如何在 worker 节点间分发及方法如何执行。此系统是"Single-Controller"范式的核心,能够通过简单的方法调用来表达复杂的分布式操作。
7.7.1 核心机制
Dispatch 通过 @register 装饰器系统工作,每个 dispatch 模式都对应特定的 dispatch_fn 和 collect_fn 函数 decorator.py:378-418。当控制流调用 worker 方法时,系统会:
- 数据分发:根据 dispatch 模式将输入数据分割成多个部分
- 远程执行:将数据分发到各个 worker 进行并行计算
- 结果收集:收集所有 worker 的计算结果并合并
7.7.2 调度模式
| Dispatch Mode | Use Case | Data Pattern |
|---|---|---|
ALL_TO_ALL | Simple operations | No data distribution 无数据分发 |
ONE_TO_ALL | Broadcast operations 广播操作 | Same data to all workers 向所有 woker 发送相同数据 |
DP_COMPUTE_PROTO | Data parallel training 数据并行训练 | DataProto chunked by world_size 数据协议按 world_size 分块 |
MEGATRON_COMPUTE_PROTO | Model parallel training 模型并行训练 | DataProto chunked by dp_size 数据协议按 dp_size 分块 |
DP_COMPUTE_PROTO_WITH_FUNC | Function execution 函数执行 | DataProto chunked with function application 应用函数后的数据协议分块 |
调度系统负责处理:
- 根据调度模式将输入数据分配给各 woker
- 按照执行模式在 woker 上运行方法
- 收集并整合来自各 woker 的结果
- 处理非均匀数据分割的填充问题
7.7.3 实际应用示例
在 FSDP worker 中,generate_sequences 方法使用 DP_COMPUTE_PROTO 模式: fsdp_workers.rst:70-78
这意味着当控制流调用 actor_rollout_ref_wg.generate_sequences(prompts) 时,系统会自动:
- 将
prompts数据按 worker 数量分割 - 分发到各个 GPU worker 并行生成
- 收集所有结果并合并返回
7.7.4 绑定机制
Dispatch 模式在 WorkerGroup 初始化时通过 _bind_worker_method 绑定到具体的分发和收集函数。 这使得分布式调用对控制流来说就像单进程调用一样简单 。
7.8 注册装饰器
@register 装饰器是分布式环境中配置方法执行行为的关键机制,它通过向 worker 方法附加元数据来控制这些方法在 workergroup 中的执行方式。
示例用法:
@register(dispatch_mode=Dispatch.DP_COMPUTE_PROTO, execute_mode=Execute.ALL, blocking=True)
def generate_sequences(self, data_proto):
# Method automatically gets data distribution and collection
data_proto = data_proto.to(torch.cuda.current_device())
# Process data on this worker
return result_proto装饰器参数控制:
dispatch_mode: 输入数据在 worker 间的分配方式execute_mode: 指定执行方法的 worker 类型(ALL /RANK_ZERO)blocking:是否等待所有 worker 完成执行materialize_futures: 是否在执行前解析 Ray futures 对象
当方法被 @register 装饰后,即可通过 WorkerGroup 接口进行分布式执行,系统会自动处理数据分发和结果收集。
7.8.1 定义和作用
@register 装饰器用于将单个方法转换为可以在多个分布式工作进程上执行的方法。它不会改变方法的功能,而是为方法附加元数据,这些元数据会在 WorkerGroup 初始化时被提取和使用。 single_controller.rst:82-107
7.8.2 装饰器参数
@register 装饰器支持以下主要参数:
- dispatch_mode: 控制数据如何分发到各个工作进程
- execute_mode: 控制哪些工作进程执行方法
- blocking: 控制执行是否为阻塞式
- materialize_futures: 控制是否物化 futures
7.8.3 工作原理
- 注册阶段: 装饰器为方法附加元数据属性
- 绑定阶段: WorkerGroup 初始化时提取这些属性,生成对应的分发、执行、收集函数
- 调用阶段: 通过 WorkerGroup 调用方法时,自动处理数据分发、远程执行和结果收集
8. FSDP Workers
本节介绍 veRL 中基于 FSDP (全分片数据并行)的 woker 实现,这些节点利用 PyTorch 的 FSDP 后端为 Actor、Critic 和参考策略角色提供分布式训练能力。这些 woker 构成了 veRL 混合流架构中 FSDP 策略的计算层。
FSDP woker 采用 PyTorch 全分片数据并行策略,实现了强化学习训练所需的核心计算角色。这些 woker 设计为由 single_controller 框架管理,并与推理引擎集成以生成推演数据。
8.1 Core FSDP Worker Classes
FSDP woker 系统包含三个主要 woker 类,分别实现 RL 训练流程中的不同角色。每个 woker 类封装了分布式计算逻辑,并提供带有 @register 装饰器的 API 接口与 single controller 通信。
8.2 FSDP Actor 实现
DataParallelPPOActor 类实现了采用 FSDP 参数分片的 PPO Actor 训练。同时支持仅前向推理(用于计算对数概率)和反向训练(用于策略更新)。
8.2.1 核心特性
- Parameter Sharding: 使用 FSDP 或 FSDP2 在 GPU 间分配模型参数
- Sequence Packing: 可选
use_remove_padding参数提升内存效率 - Ulysses Sequence Parallel: 支持长上下文训练
ulysses_sequence_parallel_size > 1 - Dynamic Batching: 通过
use_dynamic_bsz配置可变序列长度支持 - Entropy Optimization: 分块熵计算和梯度检查点选项
8.2.2 核心方法
该 Actor 节点实现了两个主要计算方法:
对数概率计算 :
- 以微批次方式处理输入序列
- 支持填充模式与去除填充模式
- 处理视觉语言模型的多模态输入
- 返回对数概率值及可选的熵值
策略更新 :
- 实现 PPO 策略梯度更新
- 支持多种策略损失模式(标准/自定义)
- 处理熵正则化与 KL 散度惩罚项
- 采用 FSDP 感知的梯度裁剪范数计算
9. DataProto 协议
veRL 采用标准化的 DataProto 协议实现组件间的数据交换:
- 统一接口 :所有 Workers 采用一致的数据格式
- 类型安全 :强类型系统实现更佳的错误检测
- 高效序列化 :为分布式通信优化设计
- 可扩展性 :轻松添加新数据字段且不破坏现有代码
9.1 DataProto 的定义
DataProto 是一个数据类,作为 veRL 中分布式训练组件之间的标准化数据交换协议 。它将 PyTorch 张量与非张量数据统一在一个容器中,支持高效的序列化、批处理和分布式操作。
DataProto 包含三个主要组件:
- batch:
TensorDict类型,包含具有一致批次维度的 PyTorch 张量 - non_tensor_batch:
dict[str, np.ndarray]类型,包含非张量数据(如字符串、元数据),以 numpy 数组形式存储 - meta_info:
dict类型,包含额外的元数据和配置信息
9.2 DataProto 的主要作用
9.2.1 数据交换和传输
DataProto 作为分布式训练组件之间传递结构化数据的标准接口 protocol.py:346-409,支持创建、操作和转换数据。
9.2.2 批处理操作
提供多种批处理操作方法,包括:
slice(): 数据切片concat(): 数据连接chunk(): 数据分块union(): 数据合并select(): 数据选择
9.2.3 序列化和分布式支持
实现了针对 Ray 分布式对象存储优化的自定义序列化机制 protocol.py:267-290,支持高效的分布式数据传输。
9.2.4 异步操作支持
通过 DataProtoFuture 类支持分布式环境中的异步数据操作 protocol.py:948-995,实现延迟数据获取和异步执行。
9.2.5 训练流水线集成
提供与 PyTorch DataLoader 兼容的迭代器接口 protocol.py:625-663,支持批量整理和数据加载。
9.2.6 内存优化
包含多项内存优化功能:
- 自动填充 (auto-padding)
- 设备管理 (device management)
- 延迟求值 (lazy evaluation)
- 序列化优化 protocol.py:47-65
9.3 Notes
DataProto 是 veRL 框架的基础数据结构,广泛应用于训练、推理和 rollout 过程中。它通过 TensorDict 库实现了对多个张量的统一操作,同时支持非张量数据的处理,为分布式机器学习提供了高效的数据处理解决方案。该类还与序列平衡算法集成,支持动态批处理和负载均衡优化。
10. FAQ
10.1 entropy_checkpointing 实现的是什么功能
10.1.1 功能概述
entropy_checkpointing 实现了熵计算的梯度检查点功能,通过重新计算来减少训练过程中的内存峰值使用 。
10.1.2 具体实现
在 FSDP Actor 的实现中,entropy_checkpointing 控制熵计算是否使用 PyTorch 的 checkpoint 功能: dp_actor.py:206-211
当 entropy_checkpointing=True 时,熵计算会使用 torch.utils.checkpoint.checkpoint() 包装,这样在反向传播时会重新计算熵值而不是存储中间激活值 dp_actor.py:275-278。
10.1.3 配置方式
该功能可以通过配置文件启用: legacy_ppo_trainer.YAML:268-269 _generated_ppo_trainer.YAML:57
10.1.4 使用场景
根据性能调优文档,entropy_checkpointing 主要用于解决标准梯度检查点不适用于熵计算的问题: perf_tuning.rst:216-218
这个功能与 entropy_from_logits_with_chunking 配合使用,共同优化熵计算的内存使用 perf_tuning.rst:212-214。
10.1.5 Notes
entropy_checkpointing 是 veRL 框架中专门针对熵计算优化的内存管理功能,通过牺牲一定的计算时间来换取更低的内存占用,特别适用于大模型训练场景。
logits = logits[:, -response_length - 1 : -1, :] # (bsz, response_length, vocab_size)
log_probs = logprobs_from_logits(logits, micro_batch["responses"])
if calculate_entropy:
if not self.config.entropy_checkpointing:
entropy = verl_F.entropy_from_logits(logits) # (bsz, response_length)
else:
entropy = torch.utils.checkpoint.checkpoint(verl_F.entropy_from_logits, logits)
return entropy, log_probsvolcengine/veRLtests/trainer/config/legacy_ppo_trainer.yaml
# calculate entropy with chunking to reduce memory peak
entropy_from_logits_with_chunking: False
# recompute entropy
entropy_checkpointing: False
# checkpoint configs
checkpoint:volcengine/veRLverl/trainer/config/_generated_ppo_trainer.yaml
grad_clip: 1.0
ulysses_sequence_parallel_size: 1
entropy_from_logits_with_chunking: false
entropy_checkpointing: false
fsdp_config:
_target_: verl.workers.config.FSDPEngineConfig
wrap_policy:10.2 生成模型的 logits 为什么要这样计算
logits = output.logits
logits.div_(temperature)
logits = logits[:, -response_length - 1 : -1, :] # (bsz, response_length, vocab_size)在文本生成任务中,logits 是模型输出的原始未归一化的分数,它们代表了词汇表中每个词元(token)在下一个位置出现的可能性。
logits = output.logits: 这一步简单地从模型的输出中提取logits。output.logits的形状通常是(batch_size, sequence_length, vocab_size),其中batch_size是批次大小,sequence_length是当前序列的长度,vocab_size是词汇表的大小。logits.div_(temperature): 这里使用了温度参数temperature来调整logits。温度参数控制生成文本的随机性:- 当
temperature > 1时,logits被缩小,使得概率分布更加平滑,增加了生成文本的多样性和随机性。 - 当
temperature < 1时,logits被放大,使得高分的logits更高,低分的更低,从而让模型更倾向于选择高概率的词元,生成结果更加确定和集中。 - 当
temperature = 1时,logits不变,相当于没有应用温度调整。div_是一个就地操作(in-place operation),直接修改logits张量。
- 当
logits = logits[:, -response_length - 1 : -1, :]: 这一行代码通过切片操作选取了特定范围的logits。具体来说:-response_length - 1 : -1表示从倒数第response_length + 1个位置开始,到倒数第 2 个位置结束(不包括倒数第 1 个位置)。这里的response_length通常指的是你希望生成的回复的长度。这个切片的目的是获取生成过程中每一步对应的logits。例如,如果你正在生成一个长度为response_length的回复,那么你需要response_length个logits向量,每个向量对应生成一个词元。切片[:, -response_length - 1 : -1, :]会选取从生成开始前一个位置到生成结束前一个位置的所有logits,这样正好对应了生成response_length个词元所需的logits。
最终,logits 的形状变为 (batch_size, response_length, vocab_size),这正是后续进行采样(如贪婪搜索、束搜索、top-k 采样等)所需要的格式。
10.2.1 实际例子
假设我们正在使用一个对话模型(比如我, Qwen)来生成回复。我们有一个包含一个样本(batch_size=1)的批次。对话历史(提示词)是 "Hello, how are you?",这个提示词被分词后对应的 token 序列长度是 6。
我们希望模型生成一个长度为 4 (response_length=4) 的回复,比如 "I am fine, thank you!"。
生成过程与 logits 的产生:
在自回归生成中,模型会一步一步地生成新的 token。每生成一个新 token,模型都会基于当前的完整输入序列(历史 + 已生成的部分)来预测下一个 token 的概率分布(即 logits)。
- 步骤 0 (输入提示): 输入是
["Hello", ",", "how", "are", "you", "?"](长度=6)。模型处理这个输入,但通常我们不直接使用这一步的 logits 来生成第一个回复 token (或者根据实现方式,可能会用,但这里我们按常见方式理解)。 - 步骤 1 (生成第一个回复 token): 模型输入仍然是完整的提示词。模型的输出
output.logits会包含对 下一个 token 的预测。这个预测对应于 logits 序列的第 6 个位置(索引为 5,如果从 0 开始计数)。 - 步骤 2 (生成第二个回复 token): 模型输入是
["Hello", ",", "how", "are", "you", "?", "I"](长度=7)。模型输出的 logits 包含对 下一个 token 的预测,对应于 logits 序列的第 7 个位置(索引为 6)。 - 步骤 3 (生成第三个回复 token): 模型输入是
["Hello", ",", "how", "are", "you", "?", "I", "am"](长度=8)。模型输出的 logits 包含对 下一个 token 的预测,对应于 logits 序列的第 8 个位置(索引为 7)。 - 步骤 4 (生成第四个回复 token): 模型输入是
["Hello", ",", "how", "are", "you", "?", "I", "am", "fine"](长度=9)。模型输出的 logits 包含对 下一个 token 的预测,对应于 logits 序列的第 9 个位置(索引为 8)。
现在,模型已经生成了 4 个 token,我们得到了一个完整的输出序列,其总长度 sequence_length 是 10 (6 个提示 + 4 个回复)。output.logits 的形状是 (1, 10, vocab_size)。这个 logits 张量包含了模型在处理这 10 个 token 序列时,对 每一个位置之后 应该出现什么 token 的预测。
关键点: 我们关心的不是模型对提示词内部或整个序列之后的预测,而是模型在生成我们想要的回复时,每一步所依据的预测(logits)。具体来说,我们想要的是:
- 生成第一个回复 token "I" 时,模型在位置 5 (第 6 个) 的 logits。
- 生成第二个回复 token "am" 时,模型在位置 6 (第 7 个) 的 logits。
- 生成第三个回复 token "fine" 时,模型在位置 7 (第 8 个) 的 logits。
- 生成第四个回复 token "," 时,模型在位置 8 (第 9 个) 的 logits。
应用索引 [:, -response_length - 1 : -1, :]
现在,我们来解析这个切片:
-response_length - 1 : -1-> 这是关键。response_length是 4。-response_length - 1=-4 - 1=-5。这表示从倒数第 5 个元素开始。-1表示到倒数第 1 个元素之前结束(不包含倒数第 1 个)。- 对于一个长度为 10 的序列,索引如下:
- 正向索引: 0, 1, 2, 3, 4, 5, 6, 7, 8, 9
- 反向索引: -10, -9, -8, -7, -6, -5, -4, -3, -2, -1
- 所以,
-5 : -1选取的是索引为 -5, -4, -3, -2 的元素。 - 对应的正向索引是: 5, 6, 7, 8。
:-> 选择词汇表的所有维度。
结果:
logits[:, -response_length - 1 : -1, :] 会选取 output.logits 中索引为 5, 6, 7, 8 的这 4 个 logits 向量。这正是我们在生成 4 个回复 token 时,模型在每一步所做出的预测!
- 位置 5 的 logits: 用于生成 "I"
- 位置 6 的 logits: 用于生成 "am"
- 位置 7 的 logits: 用于生成 "fine"
- 位置 8 的 logits: 用于生成 ","
最终得到的 logits 形状是 (1, 4, vocab_size),完美对应了我们生成的 response_length=4 个 token 所依赖的模型原始预测分数。
总结:
这个切片操作 [:, -response_length - 1 : -1, :] 的精妙之处在于,它利用了生成序列的结构:
-1排除了序列最后一个位置的 logits (通常对应生成结束后的位置,我们不关心)。-response_length - 1确保了我们从生成回复的 起始位置 开始选取。因为回复是从提示词结束后开始的,而提示词占了前面的位置,所以回复部分的 logits 在序列末尾。通过从倒数第response_length + 1个位置开始,到倒数第 1 个位置之前结束,我们恰好截取了生成整个回复过程中所用到的response_length个 logits。
11. 附录: veRL 特性详解与源码解读
veRL 框架的论文([HybridFlow]):https://arxiv.org/pdf/2409.19256
veRL 框架的官方解读:https://mp.weixin.qq.com/s/JYQQs2vqnhRz82rtDI-1OQ
知乎上的一些阅读笔记:
12. veRL 介绍
12.1 RL (Post-Training)复杂计算流程给 LLM 训练带来全新的挑战
在深度学习中,数据流(DataFlow)是一种重要的计算模式抽象,用于表示数据经过一系列复杂计算后实现特定功能。神经网络的计算就是典型的 DataFlow,可以用计算图(Computational Graph)来描述,其中节点代表计算操作,边表示数据依赖。
大模型 RL 的计算流程比传统神经网络更为复杂。在 RLHF 中,需要同时训练多个模型,如 Actor、Critic、参考策略(Reference Policy)和奖励模型(Reward Model),并在它们之间传递大量数据。这些模型涉及不同的计算类型(前向反向传播、优化器更新、自回归生成等),可能采用不同的并行策略。
传统的分布式 RL 通常假设模型可在单个 GPU 上训练,或使用数据并行方式 [4,5],将控制流和计算流合并在同一进程中。这在处理小规模模型时效果良好,但面对大模型,训练需要复杂的多维并行,涉及大量分布式计算,传统方法难以应对。
12.2 HybridFlow 解耦控制流和计算流,兼顾灵活高效
大模型 RL 本质上是一个二维的 DataFlow 问题: high-level 的控制流(描述 RL 算法的流程)+ low-level 的计算流(描述分布式神经网络计算)。
近期开源的 RLHF 框架,如 DeepSpeed-Chat [6]、OpenRLHF [7] 和 NeMo-Aligner [8],采用了统一的多控制器(Multi-Controller)架构。各计算节点独立管理计算和通信,降低了控制调度的开销。然而,控制流和计算流高度耦合,当设计新的 RL 算法,组合相同的计算流和不同的控制流时,需要重写计算流代码,修改所有相关模型,增加了开发难度。
与此前框架不同, HybridFlow 采用了混合编程模型,控制流由单控制器(Single-Controller)管理,具有全局视图,实现新的控制流简单快捷,计算流由多控制器(Multi-Controller)负责,保证了计算的高效执行,并且可以在不同的控制流中复用。
尽管相比纯粹的多控制器架构,这可能带来一定的控制调度开销,但 HybridFlow 通过优化数据传输,降低了控制流与计算流之间的传输量,兼顾了灵活性和高效性。
12.3 系统设计之一: Hybrid Programming Model (编程模型创新)
12.3.1 框架逻辑分析
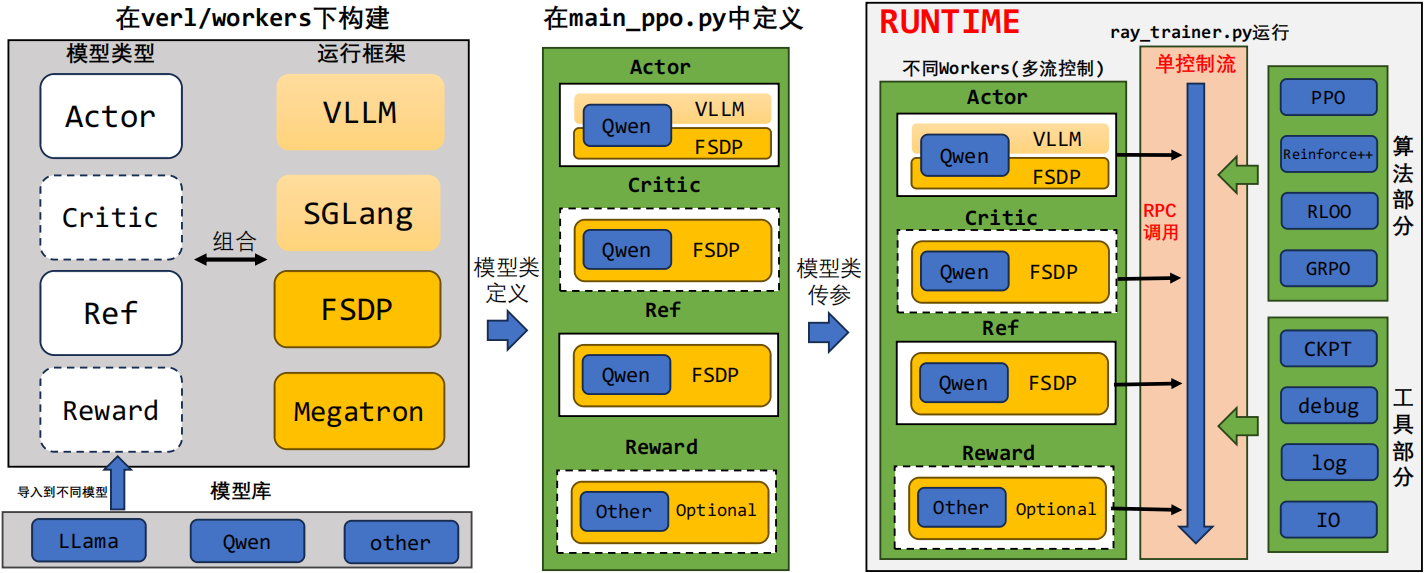
这是目前 veRL 训练框架的配置情况,对于不同的训练角色,可以选择不同的预训练模型及训练后端的支持(多控制器)。随后将他们与 main_ppo.py 中对应的角色进行绑定,然后以参数的形式传入到 ray_trainer.py 中进行调用。对于 trainer 文件中实际是以一个单控制流函数 fit() 的方式来进行,只需要从对应的模型中获得计算值的情况,然后再导入到对应的算法模块与工具模块中,就可以快速的开展 RL 训练任务。
1.运行框架中浅黄色表示推理框架,深黄色表示训练框架
2.虚线模块表示在训练过程中并不一定被需要,可以结合训练算法进行删减
3.Reward 模型有基于模型与基于规则的方法,并且目前训练推理框架可能都有支持,所以暂时写为 optional。
4.Actor 模块由于要进行 rollout 和 training 两个阶段,因此会在训练和推理框架之间进行切换(veRL 中在sharding_manager文件目录下)
12.3.2 封装单模型分布式计算
在 HybridFlow 中,每个模型(如 Actor、Critic、参考策略、奖励模型等)的分布式计算被封装为独立的模块,称为模型类。
这些模型类继承于基础的并行 Worker 类(如 3DParallelWorker、FSDPWorker 等),通过抽象的 API 接口,封装了模型的前向、反向计算、优化器更新和自回归生成等操作。该封装方式提高了代码的复用性,便于模型的维护和扩展。
对于不同的 RL 控制流,用户可以直接复用封装好的模型类,同时自定义部分算法所需的数值计算,实现不同算法。当前 HybridFlow 可使用 Megatron-LM [13] 和 PyTorch FSDP [14] 作为训练后端,同时使用 vLLM [15] 作为自回归生成后端,支持用户使用其他框架的训练和推理脚本进行自定义扩展。
12.3.3 灵活的模型部署
HybridFlow 提供了资源池(ResourcePool)概念,可以将一组 GPU 资源虚拟化,并为每个模型分配计算资源。不同的资源池实例可以对应不同设备集合,支持不同模型在同一组或不同组 GPU 上部署。这种灵活的模型部署方式,满足了不同算法、模型和硬件环境下的资源和性能需求。
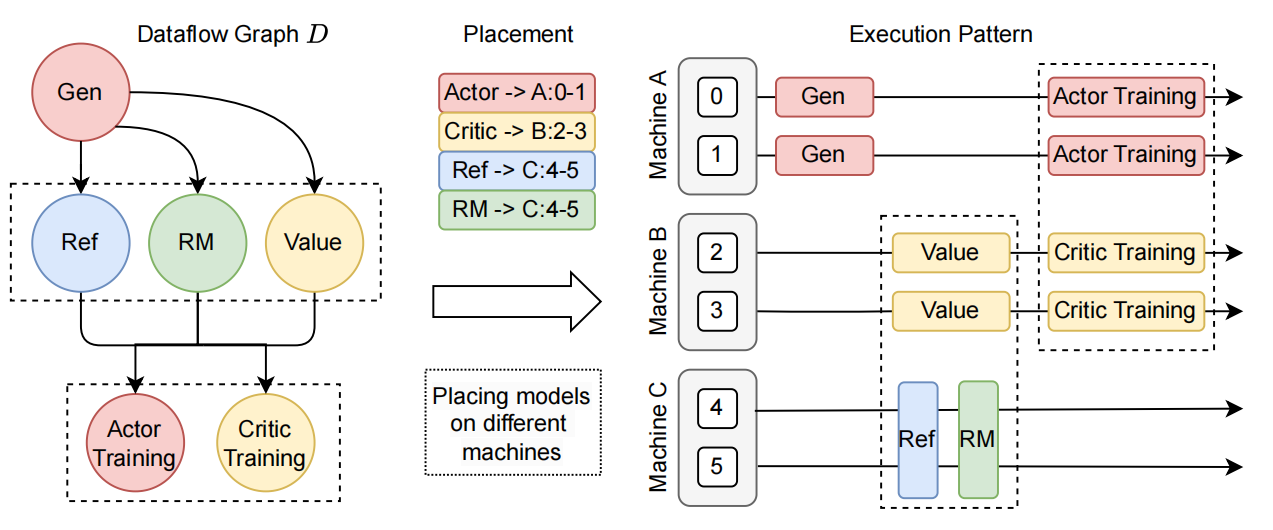
首先构建的四类模型,会通过 Ray,映射放置到不同的机器上。随后
(1)先使用 vLLM 框架和 prompt 对 Actor 先进行 response 的输出(使用专用推理框架可以让推理的速度更快)。
(2)然后将输出的结果输入给其他三个框架进行运行(一般使用训练框架,因为训练框架可以避免精度问题),以获得在 RL 算法(例如 PPO, GRPO 等框架)所需要的计算输入。
(3)最后结合计算结果,再使用训练框架来对 Actor 和 Critic 模型进行训练。
12.3.4 统一模型间的数据切分
在大模型 RL 计算流程中,不同模型之间的数据传输涉及复杂的多对多广播和数据重分片。
为解决该问题, HybridFlow 设计了一套通用数据传输协议(Transfer Protocol),包括收集(collect)和分发(distribute)两个部分。
通过在模型类的操作上注册相应的传输协议,比如: @register(transfer_mode=3D_PROTO), HybridFlow 可以在控制器层(Single-Controller)统一管理数据的收集和分发,实现模型间数据的自动重分片,支持不同并行度下的模型通信。
HybridFlow 框架已经支持多种数据传输协议,涵盖大部分数据重切分场景。同时,用户可灵活地自定义收集(collect)和分发(distribute)函数,将其扩展到更复杂的数据传输场景。
12.3.5 支持异步 RL 控制流
在 HybridFlow 中,控制流部分采用单控制器架构,可灵活实现异步 RL 控制流。
当模型部署在不同设备集合上时,不同模型计算可并行执行,这提高了系统的并行度和效率。对于部署在同一组设备上的模型, HybridFlow 通过调度机制实现了顺序执行,避免资源争夺和冲突。
12.3.6 少量代码灵活实现各种 RL 控制流算法
得益于混合编程模型的设计, HybridFlow 可以方便地实现各种 RLHF 算法,如 PPO [9]、ReMax [10]、Safe-RLHF [11]、GRPO [12] 等。用户只需调用模型类的 API 接口,按算法逻辑编写控制流代码,无需关心底层的分布式计算和数据传输细节。
例如,实现 PPO 算法只需少量代码,通过调用 actor.generate_sequences、critic.compute_values 等函数即可完成。同时,用户只需要修改少量代码即可迁移到 Safe-RLHF、ReMax 以及 GRPO 算法。
12.4 系统设计之二: 3D-HybridEngine (训练推理混合技术)降低通信内存开销
在 Online RL 算法中, Actor 模型需要在训练和生成(Rollout)阶段之间频繁切换,且两个阶段可能采用不同并行策略。
具体而言,训练阶段,需要存储梯度和优化器状态,模型并行度(Model Parallel Size, MP)可能相应增高,而生成阶段,模型无需存储梯度和优化器状态, MP 和数据并行度(Data Parallel Size, DP)可能较小。因此,在两个阶段之间,模型参数需要重新分片和分配,依赖传统通信组构建方法会带来额外通信和内存开销。
此外,为了在新的并行度配置下使用模型参数,通常需要在所有 GPU 之间进行全聚合(All-Gather)操作,带来了巨大的通信开销,增加了过渡时间。
为解决这个问题, HybridFlow 设计了 3D-HybridEngine,提升了训练和生成过程效率。
注: 3D-HybridEngine 一次迭代的流程
3D-HybridEngine 通过优化并行分组方法,实现了零冗余的模型参数重组,具体包括以下步骤:
- 定义不同的并行组
在训练和生成阶段, 3D-HybridEngine 使用不同的三维并行配置,包括:流水线并行(PP)、张量并行(TP)和数据并行(DP)的大小。训练阶段的并行配置为
- 重组模型参数过程
通过巧妙地重新定义生成阶段的并行分组,可以使每个 GPU 在生成阶段复用训练阶段已有的模型参数分片,避免在 GPU 内存中保存额外的模型参数,消除内存冗余。
- 减少通信开销
参数重组过程中, 3D-HybridEngine 仅在每个微数据并行组(Micro DP Group)内进行 All-Gather 操作,而非所有 GPU 之间进行。这大大减少了通信量,降低过渡时间,提高了整体的训练效率。
13. veRL 源码解析
13.1 核心代码阅读
13.1.1 代码结构
VeRL 仓库的核心代码逻辑(veRL)树如下所示:
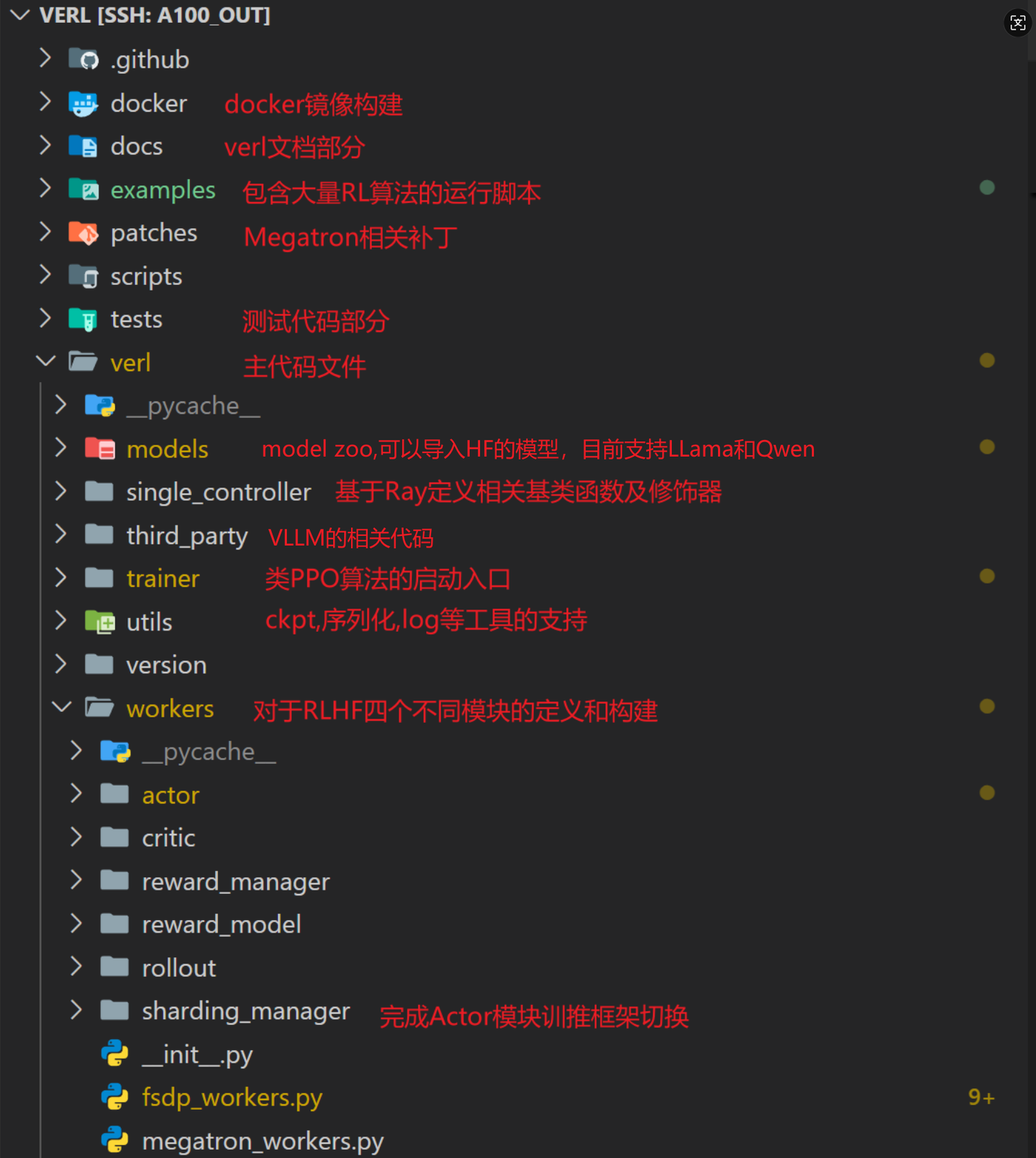
13.1.2 Trainer 组件
trainer 文件下主要放置了核心的训练逻辑,主要封装了整体 RL 算法的控制流程。目前支持的训练逻辑包括:
13.1.3 SFT
fsdp_sft_trainer.py:基于 FSDP (dpsd zero3)实现的 SFT 训练逻辑, veRL 支持在 RL 训练前通过 SFT 来 cold-start policy;
基本上就是一个 Torch-native 的 FSDP 标准 Trainer 的实现;
基于 ulysess 实现了 SFT 训练时对超长序列的序列并行支持;
Devicemesh: torch2.2 引入的新机制,用于管理设备&进程组之间的 NCCL 数据通信。veRL 借用了该机制简化了对于数据传输的控制逻辑。
- 文档:https://pytorch.org/tutorials/recipes/distributed_device_mesh.html
- Devicemesh 对于管理各种并行(模型、数据并行)时设备之间的通信非常有用,不再需要手撸进程组,以及手动管理 rank 和拓扑了,方便很多;
13.1.4 PPO/GRPO/Reinforce++/RLOO 等 RL 算法
main_ppo.py: RL 算法的入口程序,主要有以下几个主要功能:
- 选择奖励函数(model-based or rule-based),基于 Reward Manager 以及用户自定义的打分规则(一般定义在 utils/reward_score 目录下);
- 可以根据数据集中每条样本指定的 reward_style,选择针对性的 reward func;
选择训练后端(FSDP or Megatron):
- veRL 支持基于 FSDP 和 Megatron 两套后端进行模型的训练和前向传播推理,后者主要在模型规模特别大的时候,有一定的性能优势,但是自定义的修改比较麻烦,支持新架构比较麻烦,一般学术界 FSDP 后端就够用了。工业界追求极致性能时会需要 Megatron,可以进行许多定制化的优化来提升训练吞吐;
- 调用 RayPPOTrainer 进行具体的训练流程;
- 先调用 trainer 的 init_workers 函数初始化各个 rl 角色的 workergroup,然后调用 fit 函数执行实际的训练
RayPPOTrainer.py:
- 初始化 RL 中的各个 Role: RL 算法中本身涉及较多角色(Actor、Critic、RM、Ref)的协作,需要预先定义好各个模型的角色,涉及 resource_pool 的定义和分配、workerdict 和 workergroup 的初始化和分配;
- WorkerGroup 机制支持了每类 colocate model group 的具体实现,包含:
- actor_rollout_wg:支持 actor、generator 二者互相切换(通过 reload/offload params 和 reshard)的 hybrid engine;
- critic_wg (可选):支持 critic 角色,仅 PPO 需要;
- ref_policy_wg (可选):支持 reference 角色,开启 kl 需要;
- rm_wg (可选):支持 RM 角色, model based reward 需要;
- 由 init_workers 方法初始化资源池和各个 worker group;
- ResourcePoolManager:资源池管理,封装 Ray 的 placement_group,将指定的角色合理分配到设备上;
实现了一些 PPO 算法计算 loss 所需要的函数,如:
apply_kl_penalty:计算 PPO 的 token-level kl reward;
KL loss 是在 core_algos.py 里面实现的;
compute_advantage:计算优势函数的逻辑,核心算法依然是在 core_algos.py 里面实现的;
VeRL 同时支持 PPO/GRPO/Reinforce++/RLOO/Remax 等算法,这些 RL 算法的核心区别点在于 advantage 是如何计算的(critic 预测 baseline, group 计算 baseline, batch 内留一法等等),因此 VeRL 选择将 adv_estimator 单独出一套逻辑,主体同样是放在 core_algos.py 内部;
实现了一些 timer, metric 计算的函数(compute_data_metrics、compute_timing_metrics),以及 save/load 等断点续训和 ckpt 保存的逻辑(_save_checkpoint、_load_checkpoint),还有 validate 的逻辑(_validate)和 DP 负载均衡的逻辑(_balance_batch)的逻辑等等;
fit 方法实现了 rl 算法的完整的 training loop,调用了各个 worker 进行实际的计算;
需要注意, fit 方法是在单进程运行的,因此如果是在 Ray cluster 上运行,尽可能不要把 trainer 调度在 head 节点上,可能负载压力会比较大;
13.1.5 main_generation.py 适用于离线生成
13.1.6 main_eval.py 评估代码
13.1.7 core_algos.py
core_algos.py 文件也是一个非常重要的文件,包含了:
- 各种 loss 的计算逻辑:
- policy_loss (训练 Policy Model,即 actor),
- value_loss (训练 Value Model,即 critic),
- entropy_loss (Policy Model 训练的额外 trick loss,通过熵正则提升采样多样性),
- kl_loss (GRPO 等算法会把 kl loss 外置);
- 各种 advantage 的计算逻辑:
- 各个 rl 算法的核心区分点主要在 adv 如何实现,这里实现了各种 rl 算法的 adv estimation;
各类 RL 训练过程中的工程和算法超参可以参考 doc:Config Explanation
13.1.8 Workers 组件
workers 文件夹下定义了 RL 中各个角色的 worker (high-level,主要负责描述逻辑),以及各个角色计算时实际依赖的 worker (low-level,主要负责描述运算);
这里再回顾一下: worker 被 workerdict 封装后,每个设备(GPU)会运行一个。一个 colocate 的 RL 角色依托 WorkerGroup 进行管理,每个 workergroup 下管理着一组远程运行的 workers。WorkerGroup 作为 single controller 与 workers 之间的中介。我们将 worker 的方法绑定到 WorkerGroup 的方法上,通过装饰器实现具体的方法执行/数据分发的逻辑。
13.1.9 fsdp_workers.py:
基于 FSDP 训练后端,定义了一系列 RL 训练过程中可能使用的 Worker。这些 workers 是基于实际负责运算的 worker (后面会介绍)所进行的进一步封装;
13.1.10 ActorRolloutRefWorker:
- 可以选择扮演单独的 RL 中的 Actor (Policy Model)、Rollout (负责 generate response)、Reference (负责提供 ref_log_prob 计算 KL);
- 可以选择基于 hybrid engine,同时扮演多个角色,然后 veRL 通过参数的 offload/reload/reshard 进行灵活的切换;
- 目前支持了 Data Parallelism (FSDP)和 Sequence Parallelism (context 维度,基于 ulysess 实现);
- 关键方法:
init_model:根据 config 指定的 model 类型,来初始化当前 worker:
update_actor:
- 基于 DataParallelPPOActor 的 update_policy,计算 policy-Loss 并更新 Policy 模型的权重;
- 基于 ulysses_sharding_manager 支持 sequence parallel 的数据前处理和后处理,从而实现序列并行;
generate_sequences:
- 基于 vLLM 封装的 rollout 引擎,推理生成数据,使用 rollout_sharding_manager 管理数据的形状, match rollout 引擎的切分;
- compute_log_prob:基于 actor 的训练引擎,同步计算 old_logprobs,方便进行 importance sampling;
compute_ref_log_prob: 基于训练引擎,计算 ref_logprobs,方便计算 kl constraint;
save_checkpoint/load_checkpoint:实现模型参数的 offload/reload,以及保存到外部硬盘;
_build_model_optimizer:
- 指定 optim_config 一般是 actor,需要基于 FSDP 进行训练,需要初始化 FSDP wrap 的模型(进一步传给 DataParallelPPOActor 封装)、optimizer 和 lr_scheduler;
- 不指定 optim_config 一般是 ref,统一推理引擎和训练引擎,确保 KL 计算的数值准确性;
所有的涉及运算的函数,都有 dispatch_mode 装饰器,以实现 workergroup 内部的数据传输逻辑(single-controller 的设计模式);
13.1.11 CriticWorker:
- 和 ActorRolloutRefWorker 逻辑大体一致,只不过基于的后端是 DataParallelPPOCritic;
- 不需要 rollout,且额外多出了 compute_values 这个操作,通过 value head 计算 token-level value 以便 PPO 计算 Adv;
13.1.12 RewardModelWorker:
- 基于模型的 RM 打分实现;
13.1.13 megatron_workers.py:
megatron_workers.py 基于 Megatron 后端实现的 RL workers;
- 基于 Megatron 支持 4D 并行, DP、TP、SP、PP;
- 核心逻辑基本和 FSDP 版本一致,但是底层逻辑需要适配 Megatron 框架;
接下来,我们看看具体的 Actor 运算 Worker,它们被放置在当前目录的子文件夹下,默认都有 fdsp (torch-native)和 Megatron 两个写法的版本,以兼容两套训练引擎:
13.1.14 Actor:
- RL 算法(如 PPO)中扮演 Actor 角色的 Worker (Reference Model 也可以借用);
- 核心功能有:
- compute_log_prob:为了计算 KL 或者 Importance Sampling,前向传播推理得到各 token 位置的 logits 和对数概率;
- update_policy:基于预先计算好的 advantage,计算 policy loss、entropy loss 和 kl loss,然后更新 Policy Model;
13.1.15 Critic:
- Actor-Critic-based RL 算法(如 PPO)中扮演 Critic 角色的 Worker;
- 核心功能有:
- compute_values:计算 Values,参与计算 PPO 算法的 advantage;
- update_critic:计算 value loss,然后更新 Value Model;
13.1.16 Reward_model:
- 基于 Model-based 的打分模型,计算 response-level reward;
- 核心功能主要就是 compute_reward;
- rule-based reward 不需要;
13.1.17 Rollout:
- 核心功能就是在训练时候 rollout response,主要函数为 generate_sequences;
- 支持不同的生成引擎后端:
- 原生的 rollout 逻辑,最简单的从 logits->softmax->sampling 的逻辑;
- Hugging Face TGI 后端的 rollout 逻辑;
- vLLM 的 rollout 逻辑;
- 目前开源版本的推理引擎以 vLLM 为主,但 SGLang 也在接入中;
- 基于 third_party 中修改的 vLLM engine 进行推理;
- repreat 采样没有使用 n_samples 参数而是直接 repeat_interleave 输入,多次生成;
- old_log_probs 没有使用 vLLM 引擎得到的结果,为了确保 importance sampling 和 kl divergence 计算的准确性,要用训练引擎(FSDP 或者 Megatron)统一计算,避免引擎不同带来的误差;
此外,该文件夹下还有 sharding_manager,主要是负责管理不同的 parallelism 下的 sharding,包括:
- data sharding (preprocess_data, postprocess_data);
- device mesh 的管理;
- 模型参数的 reload & offload 逻辑(基于上下文管理器)
13.1.18 Single Controller 组件
实现 veRL 的核心混合编程模型的重点,即基于 single controller 机制去管理 RL 的控制流;
Worker:方便管理 worker 进程在 workergroup 进程组内部的信息(如 rank_id 和 world_size),以及资源分配的信息;
ResourcePool:管理某个资源池,包括池内节点信息和进程信息;
Workergroup:管理多个 worker 所组成的 workergroup,如负责管理 data parallelism。最重要的函数是_bind_worker_method:
- 将用户定义的方法 bind 到 WorkerGroup 实例上;
- 处理被 @register 装饰器修饰的方法;
- 配置数据分发/收集模式和执行模式;
- 同步执行当前 group 内所有 worker 的该方法,并且根据分发&执行模式正确管理执行逻辑和数据传输逻辑;
Decorator:主要定义了各种 worker 的数据分发和函数执行模式的装饰器,装饰后, workergroup 在执行 worker 的方法时,将会通过装饰器自动配置数据分发和执行的模式;
Ray:该处代码主要是基于 Ray 后端,去管理 worker(WorkerDict)和 workergroup(RayWorkerGroup)。通过 Python 语法糖,实现了 worker 的 method rebind,以让同一个 workergroup 在不同的 rl 角色之间灵活切换;
13.1.19 Models 组件
主要包含常见模型结构(主要是 Llama 结构和 qwen2 结构,允许用户集成更多的结构)的定义,包括:
Transformers 版本的模型结构定义:
- FSDP 版本的 RL 训练推理、Rollout 引擎、导出模型权重需要使用;
- 自定义新的模型结构:Add models with the FSDP backend
Megatron 版本的模型结构定义:
- Megatron 版本的 RL 训练推理需要使用;
- Megatron 版本需针对 4D Parallelism 做较多的适配;
- 自定义新的模型结构:Add models with the Megatron-LM backend
13.1.20 Utils 组件
在 utils 文件夹下定义了一些重要的工具和组件,包括:
Dataset:
- 主要包括: rl、SFT 和 rm 的 dataset;
- 处理数据集中的各个 key,包括取出了制作好的 parquet 里面的 prompt 列, apply_chat_ml + tokenize 后设为 input_ids;
- VeRL 的 dataset 和 dataloader 没有和训练过程强绑定,可以在训练过程中比较轻松地做到 dataloader 的重载或者修改,所以实现一些功能会比较方便,如动态的课程学习等;
Debug:
- 主要包括:监控 Performance (如 GPU usage)和 Trajectory (即保存 rollout 结果)的逻辑;
Logger:
- 顾名思义,主要是将一些监控指标输出到指定的位置(console 或者 wandb)的逻辑;
Megatron:
- 主要是为了在 veRL 中使用 Megatron 所编写的一些 utils,以及对原有 Megatron 实现适配 veRL 所进行的一些 patch;
Reward_score:
- 这里主要存着适配不同的 rule-grader 所编写的逻辑,包括各种 parse answer 的逻辑和 compare answer 的逻辑;
其他:如 checkpoint 管理的工具、hdfs 文件管理的工具、支持 ulysess/seq_balancing 等 feature 的工具等;
13.1.21 third_party 组件
目前主要是对开源的推理引擎 vLLM,做了一些针对 veRL 进行的定制化适配和封装(如 SPMD); 主要是继承了原始的 vLLM,以支持 veRL 所需要的一些功能,比如取出特定计算结果、更好地支持 hybrid engine (如 sync/offload params, device mesh 管理, weight loader 的兼容...)等;
13.1.22 Protocol 组件
为了支持 RL 过程中更好的数据管理和传输, veRL 设计了 DataProto 这一数据结构,主要包括:
- 基于 TensorDict 所实现的 batch,用于管理 a dictionary of tensors;
- 基于 Dict 所实现的 meta_info,用于管理当前 DataProto 的信息;
- 其余 non-tensor 数据,存在 non_tensor_batch 中;
- 以及 DataProto 使用所需要的各类数据管理逻辑,如 pop、chunk、union、concat、rename、reorder 等等;
DataProtoFuture 则是为了支持 DataProto 的异步处理而构造的,支持负责 reduce 的 collect_fn 和负责 scatter 的 dispatch_fn,从而方便 worker 的非阻塞执行。