Transformer 位置编码综述
不同于 RNN、CNN 等模型,Transformer 必须引入位置编码,因为纯粹的 Attention 模块无法捕捉输入顺序,即无法区分不同位置的 token。为此我们有两种选择:
- 将位置信息融入输入,这构成了绝对位置编码的一般做法;
- 调整 Attention 结构使其能分辨不同位置的 token,这构成了相对位置编码的一般做法。
Transformer 中的自注意力机制无法捕捉位置信息,因为其计算过程具有置换不变性(permutation invariant),打乱输入序列的顺序不会影响输出结果。
对于 Transformer 模型
位置编码(Position Encoding) 通过将位置信息引入输入序列,以打破模型的全对称性。为简化问题,考虑在
对上式进行二阶 Taylor 展开:
在上式中,第 2 至第 5 项仅依赖于单一位置,表示绝对位置信息;第 6 项包含
- 绝对位置编码(absolute PE):将位置信息加入到输入序列中,相当于引入索引的嵌入。例如 Sinusoidal、Learnable、FLOATER、Complex-order、RoPE。
- 相对位置编码(relative PE):通过调整自注意力运算过程,使其能分辨不同 token 之间的相对位置。例如 XLNet、T5、DeBERTa、URPE。
1. 绝对位置编码(Absolute Position Encoding)
绝对位置编码是指在输入序列经过词嵌入后的第

1.1 三角函数式(Sinusoidal)位置编码
三角函数式(Sinusoidal)位置编码是原 Transformer 模型中使用的一种显式编码。以一维三角函数编码为例:
其中

以下是正弦位置编码的 PyTorch 实现:
import numpy as np
import torch
def sinusoidal_encoding_1d(seq_len, d_model):
pos_table = np.array([
[pos / np.power(10000, 2 * i / d_model) for i in range(d_model)]
for pos in range(seq_len)
])
# pos_table[0] 作用于 [CLS],不需要位置编码
pos_table[1:, 0::2] = np.sin(pos_table[1:, 0::2])
pos_table[1:, 1::2] = np.cos(pos_table[1:, 1::2])
return torch.FloatTensor(pos_table)三角函数式位置编码具有显式的生成规律,因此可以期望它具有一定的外推性。根据三角函数的性质,位置
在图像领域,常用到二维形式的位置编码。以二维三角函数编码为例,需要分别对高度方向和宽度方向进行编码
import math
import torch
def positional_encoding_2d(d_model, height, width):
"""
:param d_model: dimension of the model
:param height: height of the positions
:param width: width of the positions
:return: d_model x height x width position matrix
"""
if d_model % 4 != 0:
raise ValueError(
"Cannot use sin/cos positional encoding with odd dimension (got dim={:d})".format(d_model)
)
pe = torch.zeros(d_model, height, width)
# Each dimension uses half of d_model
d_model = d_model // 2
div_term = torch.exp(torch.arange(0.0, d_model, 2) * -(math.log(10000.0) / d_model))
pos_w = torch.arange(0.0, width).unsqueeze(1)
pos_h = torch.arange(0.0, height).unsqueeze(1)
pe[0:d_model:2, :, :] = torch.sin(pos_w * div_term).transpose(0, 1).unsqueeze(1).repeat(1, height, 1)
pe[1:d_model:2, :, :] = torch.cos(pos_w * div_term).transpose(0, 1).unsqueeze(1).repeat(1, height, 1)
pe[d_model::2, :, :] = torch.sin(pos_h * div_term).transpose(0, 1).unsqueeze(2).repeat(1, 1, width)
pe[d_model + 1::2, :, :] = torch.cos(pos_h * div_term).transpose(0, 1).unsqueeze(2).repeat(1, 1, width)
return pe1.2 可学习(Learnable)位置编码
可学习(Learnable)位置编码是指将位置编码作为可训练参数。例如输入序列(经过嵌入层后)的大小为
可学习位置编码的缺点是缺乏外推性,即如果预训练序列的最大长度为
1.3 FLOATER:递归式位置编码
原则上,RNN 模型不需要位置编码,其结构本身就具备学习位置信息的能力(因为递归本身意味着可以训练一个"计数"模型)。因此,如果在输入后先接一层 RNN,再接 Transformer,理论上就不需要额外的位置编码。
同理,也可以用 RNN 模型来学习一种绝对位置编码。例如从一个向量
FLOATER 使用神经常微分方程(Neural ODE)构建的连续动力系统对位置编码进行递归建模:
理论上,基于递归模型的 FLOATER 位置编码也具有较好的外推性,同时比三角函数式位置编码更具灵活性(例如可以证明三角函数式位置编码是 FLOATER 的某个特解)。但递归形式的位置编码牺牲了一定的并行性,可能成为速度瓶颈。
1.4 Complex-order:复数式位置编码
绝对位置编码等价于词表索引
其中振幅
1.5 RoPE:旋转式位置编码
旋转式位置编码(Rotary Position Embedding,RoPE)是一种通过绝对位置编码的方式实现相对位置编码的方案。其核心思想是在构造查询矩阵
补充说明:关于 RoPE 的完整数学推导与实现细节,请参阅旋转式位置编码(RoPE)。
旋转矩阵
1.6 层次化位置编码
在可学习的位置编码中,假设学习到序列长度为
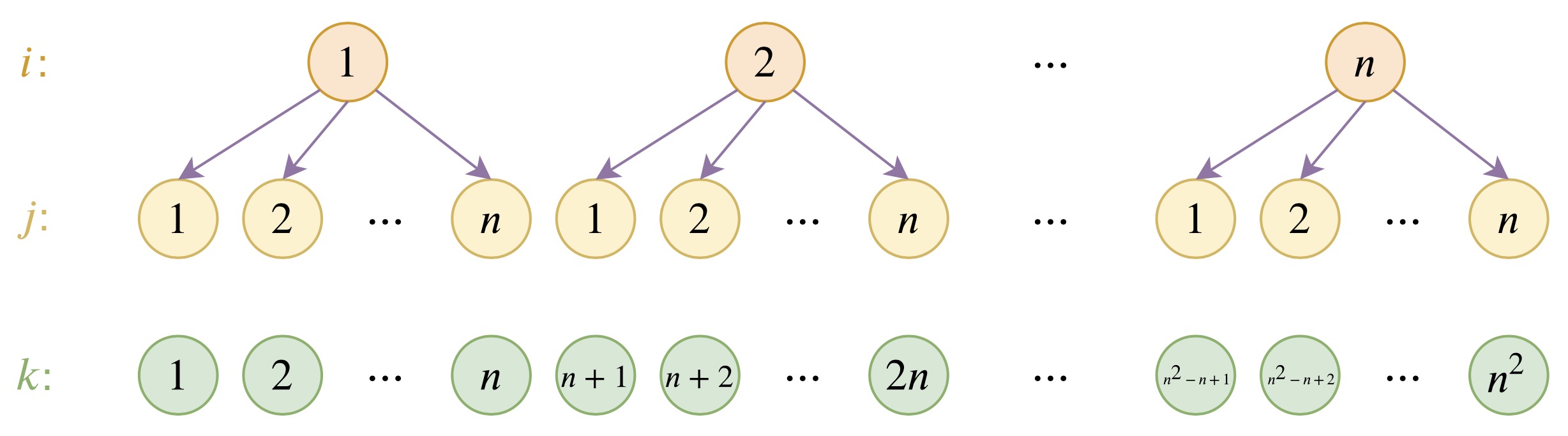
假设学习到位置编码
其中
则可以解出基编码:
2. 相对位置编码(Relative Position Encoding)
相对位置编码并非直接建模每个输入 token 的位置信息,而是在计算注意力矩阵时考虑当前向量与待交互向量之间的相对距离。由于自然语言通常更依赖于相对位置,因此相对位置编码一般也有优秀的表现。
从绝对位置编码出发,其形式相当于在输入中添加绝对位置的表示。对应的完整自注意力机制运算如下:
其中 softmax 对
为了引入相对位置信息,Google 移除了第一项中的位置编码,并将第二项
注意到绝对位置编码相当于在自注意力运算中引入了一系列
2.1 经典相对位置编码
在经典的相对位置编码设置中,移除了与
相对位置向量
2.2 XLNet 式
XLNet 式位置编码实际源自 Transformer-XL 的论文《Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context》。由于采用 Transformer-XL 架构的 XLNet 模型在一定程度上超越了 BERT,Transformer-XL 才广为人知,因此这种位置编码通常也被冠以 XLNet 之名。
在 XLNet 模型中,移除了值向量的位置编码
2.3 T5 式
T5 模型出自论文《Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer》,其中采用了一种更简洁的相对位置编码方案。思路同样源自展开式。分析各项含义,可分别理解为"输入-输入"、"输入-位置"、"位置-输入"、"位置-位置"四项注意力的组合。如果认为输入信息与位置信息应当独立(解耦),则不应有过多交互。因此,"输入-位置"项
一维形式的 T5 式相对位置编码实现过程如下:
import torch
import torch.nn as nn
from einops import rearrange
class Attention(nn.Module):
def __init__(self, dim, seq_len, heads=8, dim_head=64, dropout=0.0):
super().__init__()
inner_dim = dim_head * heads
project_out = not (heads == 1 and dim_head == dim)
self.heads = heads
self.scale = dim_head ** -0.5
self.attend = nn.Softmax(dim=-1)
self.dropout = nn.Dropout(dropout)
self.to_qkv = nn.Linear(dim, inner_dim * 3, bias=False)
self.to_out = nn.Sequential(
nn.Linear(inner_dim, dim),
nn.Dropout(dropout)
) if project_out else nn.Identity()
# Positional bias
self.pos_bias = nn.Embedding(seq_len, heads)
q_pos = torch.arange(seq_len)
k_pos = torch.arange(seq_len)
pos_indices = (q_pos[:, None] - k_pos[None, :]).abs()
self.register_buffer("pos_indices", pos_indices)
def apply_pos_bias(self, fmap):
bias = self.pos_bias(self.pos_indices)
bias = rearrange(bias, "i j h -> () h i j")
return fmap + (bias / self.scale)
def forward(self, x):
qkv = self.to_qkv(x).chunk(3, dim=-1)
q, k, v = map(lambda t: rearrange(t, "b n (h d) -> b h n d", h=self.heads), qkv)
dots = torch.matmul(q, k.transpose(-1, -2)) * self.scale
# 引入相对位置编码
dots = self.apply_pos_bias(dots)
attn = self.attend(dots)
attn = self.dropout(attn)
out = torch.matmul(attn, v)
out = rearrange(out, "b h n d -> b n (h d)")
return self.to_out(out)二维形式的 T5 式相对位置编码实现过程如下:
import torch
import torch.nn as nn
from einops import rearrange
class Attention2D(nn.Module):
def __init__(self, dim, fmap_size, heads=8, dim_head=64, dropout=0.0):
super().__init__()
inner_dim = dim_head * heads
project_out = not (heads == 1 and dim_head == dim)
self.heads = heads
self.scale = dim_head ** -0.5
self.attend = nn.Softmax(dim=-1)
self.dropout = nn.Dropout(dropout)
self.to_qkv = nn.Linear(dim, inner_dim * 3, bias=False)
self.to_out = nn.Sequential(
nn.Linear(inner_dim, dim),
nn.Dropout(dropout)
) if project_out else nn.Identity()
# Positional bias
self.pos_bias = nn.Embedding(fmap_size * fmap_size, heads)
q_range = torch.arange(fmap_size)
k_range = torch.arange(fmap_size)
q_pos = torch.stack(torch.meshgrid(q_range, q_range, indexing="ij"), dim=-1)
k_pos = torch.stack(torch.meshgrid(k_range, k_range, indexing="ij"), dim=-1)
q_pos, k_pos = map(lambda t: rearrange(t, "i j c -> (i j) c"), (q_pos, k_pos))
rel_pos = (q_pos[:, None, ...] - k_pos[None, :, ...]).abs()
x_rel, y_rel = rel_pos.unbind(dim=-1)
pos_indices = (x_rel * fmap_size) + y_rel
self.register_buffer("pos_indices", pos_indices)
def apply_pos_bias(self, fmap):
bias = self.pos_bias(self.pos_indices)
bias = rearrange(bias, "i j h -> () h i j")
return fmap + (bias / self.scale)
def forward(self, x):
qkv = self.to_qkv(x).chunk(3, dim=-1)
q, k, v = map(lambda t: rearrange(t, "b n (h d) -> b h n d", h=self.heads), qkv)
dots = torch.matmul(q, k.transpose(-1, -2)) * self.scale
# 引入相对位置编码
dots = self.apply_pos_bias(dots)
attn = self.attend(dots)
attn = self.dropout(attn)
out = torch.matmul(attn, v)
out = rearrange(out, "b h n d -> b n (h d)")
return self.to_out(out)2.4 DeBERTa 式
在 DeBERTa 模型中,移除了值向量的位置编码
2.5 Universal RPE(URPE)
注意到在相对位置编码中,如果移除值向量的位置编码
其中
3. 其他位置编码
绝对位置编码和相对位置编码虽然花样繁多,但仍属经典范畴。除此之外,还有一些非常规方案同样能够表达位置编码。
3.1 CNN 式
尽管经典的 CNN 用于 NLP 的工作《Convolutional Sequence to Sequence Learning》加入了位置编码,但一般的 CNN 模型(尤其是图像领域的 CNN 模型)并未额外加位置编码。那么 CNN 模型究竟如何捕捉位置信息?
一种可能的解释是卷积核的各向异性使其能分辨不同方向的相对位置。然而 ICLR 2020 的论文《How Much Position Information Do Convolutional Neural Networks Encode?》给出了一个出人意料的答案:CNN 模型的位置信息是由 Zero Padding 泄漏的。
为使卷积编码过程中的特征图保持一定大小,通常会对输入填充(padding)一定数量的 0。该论文表明此操作使模型具备了识别位置信息的能力。也就是说,卷积核的各向异性固然重要,但最根本的因素是 Zero Padding 的存在。可以推测,模型实际提取的是当前位置与 padding 边界的相对距离。
不过,这一能力依赖于 CNN 的局部性。像 Attention 这种全局性的无先验结构并不适用。对于只关心 Transformer 位置编码方案的读者,权当扩展视野。
参考文献
- Position Information in Transformers: An Overview:(arXiv:2102)一篇关于 Transformer 中位置编码的综述。
- Self-Attention with Relative Position Representations:(arXiv:1803)自注意力机制中的相对位置编码。
- XLNet: Generalized Autoregressive Pretraining for Language Understanding:(arXiv:1906)XLNet:使用排列语言建模训练语言模型。
- Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer:(arXiv:1910)T5:编码器-解码器结构的预训练语言模型。
- Encoding word order in complex embeddings:(arXiv:1910)在复数域空间中构造词嵌入。
- Learning to Encode Position for Transformer with Continuous Dynamical Model:(arXiv:2003)FLOATER:基于连续动力系统的递归位置编码。
- DeBERTa: Decoding-enhanced BERT with Disentangled Attention:(arXiv:2006)DeBERTa:使用分解注意力机制和增强型掩膜解码器改进预训练语言模型。
- RoFormer: Enhanced Transformer with Rotary Position Embedding:(arXiv:2104)RoFormer:使用旋转位置编码增强 Transformer。
- Your Transformer May Not be as Powerful as You Expect:(arXiv:2205)使用通用相对位置编码改进 Transformer 的通用近似性。