大型语言模型微调方法
在快速发展的人工智能领域,高效利用大型语言模型(LLM)变得越来越重要。将预训练 LLM 应用于新任务,主要有两种方式:上下文学习(In-Context Learning)和微调(Fine-tuning)。
本文将首先简要介绍 In-Context Learning,随后系统梳理微调 LLM 的各种方法。
1. In-Context Learning 与索引
自 GPT-2(Radford et al.)和 GPT-3(Brown et al.)以来,研究者发现:在通用文本语料库上预训练的生成式 LLM 具备上下文学习能力。面对模型未经专门训练的新任务,无需进一步训练或微调,只需在输入 Prompt 中提供若干目标任务的示例,模型即可完成推理。如下图所示:
In-Context Learning 示例。
当我们无法直接访问模型(例如通过 API 或用户界面与 LLM 交互)时,In-Context Learning 尤为实用。
与 In-Context Learning 相关的是 Hard Prompt Tuning 的概念——通过修改输入来改善输出,如下图所示。

Hard Prompt Tuning 图示。
之所以称为 Hard Prompt Tuning,是因为我们直接修改输入中的离散单词或标记。后文将讨论其可微分版本——Soft Prompt Tuning(通常简称为 Prompt Tuning)。
上述 Prompt 调整方法提供了一种比参数微调更节省资源的替代方案。然而,其性能通常不及微调,因为它不更新模型参数,可能限制模型对特定任务细微差别的适应能力。此外,Prompt Tuning 通常需要人工参与比较不同 Prompt 的质量,属于劳动密集型方法。
另一种基于 In-Context Learning 的方法是索引(Indexing)。在 LLM 领域,索引可视为 In-Context Learning 的变通方案,能将 LLM 转换为信息检索系统,从外部资源中提取数据。具体流程如下:
- 索引模块将文档或网站分解为较小片段,将其转换为向量并存储在向量数据库中。
- 当用户提交查询时,计算查询 Embedding 与数据库中各向量的相似度。
- 最终获取 Top-K 最相似的 Embedding 来生成响应。

索引流程图示。
2. 三种传统的基于特征和微调的方法
当我们能够直接访问 LLM 时,使用目标领域数据对其进行微调通常能获得更好的效果。那么,如何使模型适应目标任务?下图概述了三种常规方法。
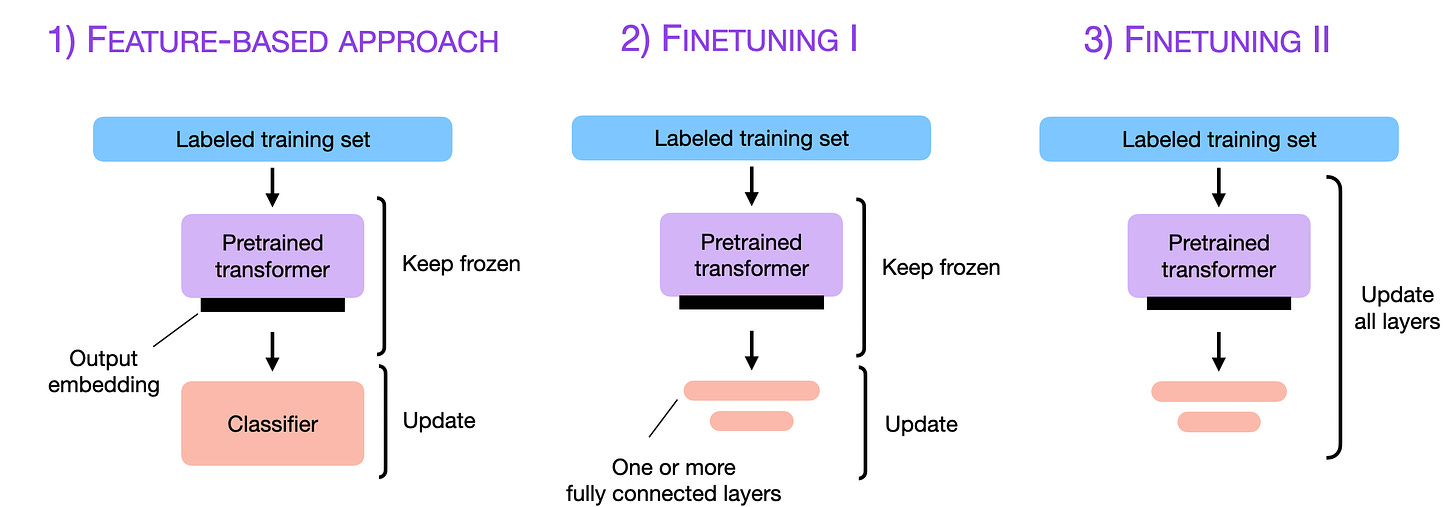
三种传统的基于特征和微调的方法。
为便于讨论,以下以编码器风格的 LLM(如 BERT,Devlin et al. 2018)为例,说明如何针对分类任务进行微调(该任务预测电影评论的正面或负面情感)。需要注意的是,同样的方法也适用于 GPT 类解码器风格的 LLM。此外,我们还可以对解码器式 LLM 进行微调,使其针对特定指令生成多句回答,而非仅做文本分类。
2.1 基于特征的方法
在基于特征的方法中,我们加载预训练 LLM 并将其应用于目标数据集。这里我们关注的是生成训练集的输出 Embedding,将其作为输入特征来训练分类模型。这种方法对 BERT 等以 Embedding 为核心的模型尤为常见,但我们同样可以从 GPT 式生成模型中提取 Embedding。
分类模型可选用逻辑回归、随机森林或 XGBoost。(根据经验,逻辑回归等线性分类器在此场景下表现最佳。)
从概念上讲,基于特征的方法可用以下代码说明:
import numpy as np
import torch
from transformers import AutoModel
from sklearn.linear_model import LogisticRegression
model = AutoModel.from_pretrained("distilbert-base-uncased")
# ...
# tokenize dataset
# ...
# Generate embeddings
@torch.inference_mode()
def get_output_embeddings(batch):
output = model(
batch["input_ids"],
attention_mask=batch["attention_mask"]
).last_hidden_state[:, 0]
return {"features": output}
dataset_features = dataset_tokenized.map(
get_output_embeddings, batched=True, batch_size=10
)
X_train = np.array(imdb_features["train"]["features"])
y_train = np.array(imdb_features["train"]["label"])
X_val = np.array(imdb_features["validation"]["features"])
y_val = np.array(imdb_features["validation"]["label"])
X_test = np.array(imdb_features["test"]["features"])
y_test = np.array(imdb_features["test"]["label"])
# Train classifier
clf = LogisticRegression()
clf.fit(X_train, y_train)
print("Training accuracy", clf.score(X_train, y_train))
print("Validation accuracy", clf.score(X_val, y_val))
print("Test accuracy", clf.score(X_test, y_test))有兴趣的读者可以在此处找到完整的代码示例。
2.2 Finetuning I——更新输出层
与基于特征的方法相关的一个流行方法是微调输出层(称为 Finetuning I)。与基于特征的方法类似,我们冻结预训练 LLM 的参数,只训练新增的输出层——这类似于在 Embedding 特征上训练逻辑回归分类器或小型多层感知器。
代码实现如下:
from transformers import AutoModelForSequenceClassification
import lightning as L
model = AutoModelForSequenceClassification.from_pretrained(
"distilbert-base-uncased",
num_labels=2
)
# Freeze all layers
for param in model.parameters():
param.requires_grad = False
# Then unfreeze the two last layers (output layers)
for param in model.pre_classifier.parameters():
param.requires_grad = True
for param in model.classifier.parameters():
param.requires_grad = True
# Finetune model
lightning_model = CustomLightningModule(model)
trainer = L.Trainer(
max_epochs=3,
...
)
trainer.fit(
model=lightning_model,
train_dataloaders=train_loader,
val_dataloaders=val_loader
)
# Evaluate model
trainer.test(lightning_model, dataloaders=test_loader)有兴趣的读者可以在这里找到完整的代码示例。
理论上,这种方法在建模性能和速度方面与基于特征的方法表现相当,因为两者使用相同的冻结骨干模型。但基于特征的方法更便于预先计算和存储训练数据集的 Embedding 特征,因此在某些实际场景中可能更加便捷。
2.3 Finetuning II——更新所有层
虽然 BERT 原始论文(Devlin et al.)指出仅微调输出层即可达到与微调所有层相当的性能,但后者由于参数量更大,计算成本显著更高。例如,BERT Base 模型约有 1.1 亿个参数,而其用于二元分类的最后一层仅包含 1,500 个参数;最后两层共约 60,000 个参数——仅占总模型参数的 0.6%。
实际效果取决于目标任务与预训练数据的相似程度。但在实践中,微调所有层几乎总能带来更优的建模性能。
因此,追求最优性能时,更新所有层(即 Finetuning II)是使用预训练 LLM 的黄金标准。概念上,Finetuning II 与 Finetuning I 非常相似,唯一区别在于不冻结预训练 LLM 的参数:
from transformers import AutoModelForSequenceClassification
import lightning as L
model = AutoModelForSequenceClassification.from_pretrained(
"distilbert-base-uncased",
num_labels=2
)
# Freeze layers (which we don't do here)
# for param in model.parameters():
# param.requires_grad = False
# Finetune model
lightning_model = LightningModel(model)
trainer = L.Trainer(
max_epochs=3,
...
)
trainer.fit(
model=lightning_model,
train_dataloaders=train_loader,
val_dataloaders=val_loader
)
# Evaluate model
trainer.test(lightning_model, dataloaders=test_loader)有兴趣的读者可以在这里找到完整的代码示例。
如果您对实际效果感兴趣,以上代码片段使用预训练 DistilBERT 模型训练电影评论分类器,代码笔记本的实验结果如下:
- 基于特征的逻辑回归方法:83% 测试准确率
- Finetuning I,更新最后两层:87% 准确率
- Finetuning II,更新所有层:92% 准确率
这些结果印证了一般经验法则:微调更多层通常带来更好的性能,但计算成本也相应增加。

各方法的计算成本与建模性能权衡经验法则。
3. 参数高效微调(PEFT)
前文我们了解到,微调更多层通常能获得更好的效果。上述实验基于相对较小的 DistilBERT 模型。如果要微调更大的模型——尤其是那些仅能勉强载入 GPU 显存的最新生成式 LLM——该怎么办?我们可以使用基于特征的方法或 Finetuning I,但如果希望获得接近 Finetuning II 的建模质量呢?
微调 LLM 在计算资源和时间方面开销巨大,这正是研究者开发参数高效微调方法的动因。
参数高效微调(Parameter-Efficient Fine-Tuning,PEFT) 使我们能够复用预训练模型,同时最大限度减少计算和资源消耗。其优势至少包括以下五方面:
- 降低计算成本(需要更少的 GPU 和 GPU 时间);
- 加快训练速度(更快完成训练);
- 降低硬件要求(可使用更小的 GPU 和更少的显存);
- 提升泛化能力(减少过拟合);
- 节省存储空间(大部分权重可跨任务共享)。
近年来,研究者开发了多种技术(Lialin et al.)来实现高建模性能下的少量参数训练。这些方法统称为参数高效微调技术(PEFT)。
下图总结了一些最广泛使用的 PEFT 技术。
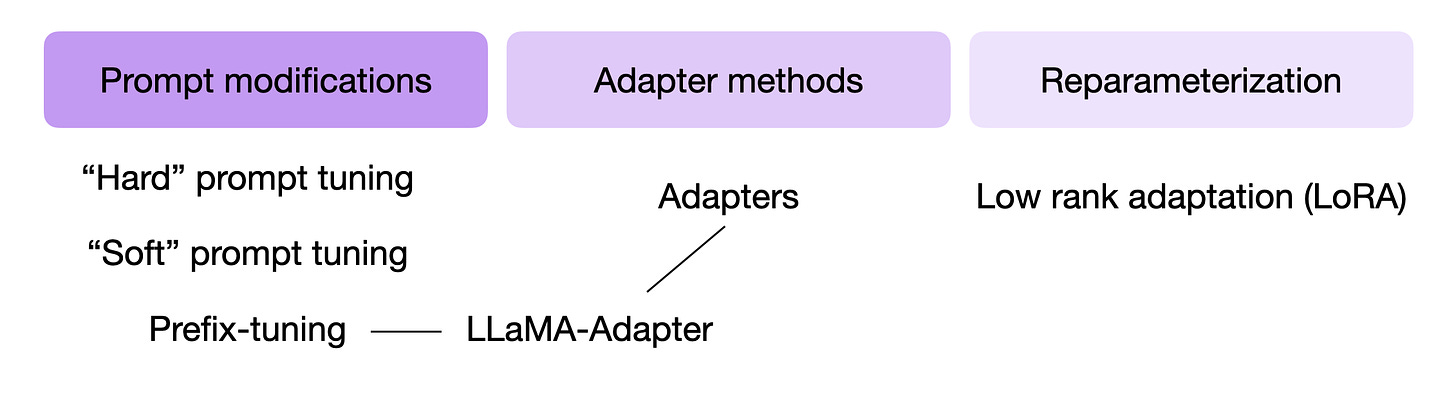
主流参数高效微调技术概览。
这些技术的核心思想是:引入少量额外参数并仅对其进行微调,而非像 Finetuning II 那样更新所有层。从某种意义上说,Finetuning I(仅微调最后一层)也可视为一种参数高效方法。然而,Prefix Tuning、Adapters 和 Low-Rank Adaptation(LoRA)等技术能够"修改"多层,以更低的成本实现更优的预测性能。
近期引起广泛关注的一种 PEFT 技术是 LLaMA-Adapter,它是为 Meta 的 LLaMA 模型(Touvron et al.)提出的。尽管 LLaMA-Adapter 在 LLaMA 背景下提出,但其思想与具体模型无关。
要理解 LLaMA-Adapter 的工作原理,需要先回顾两种相关技术:Prefix Tuning 和 Adapters。LLaMA-Adapter(Zhang et al.)融合并扩展了这两种思想。
因此,在深入 LLaMA-Adapter 之前,我们先讨论 Prompt 修改的各种概念,以理解 Prefix Tuning 和 Adapters 方法。
3.1 Prompt Tuning 与 Prefix Tuning
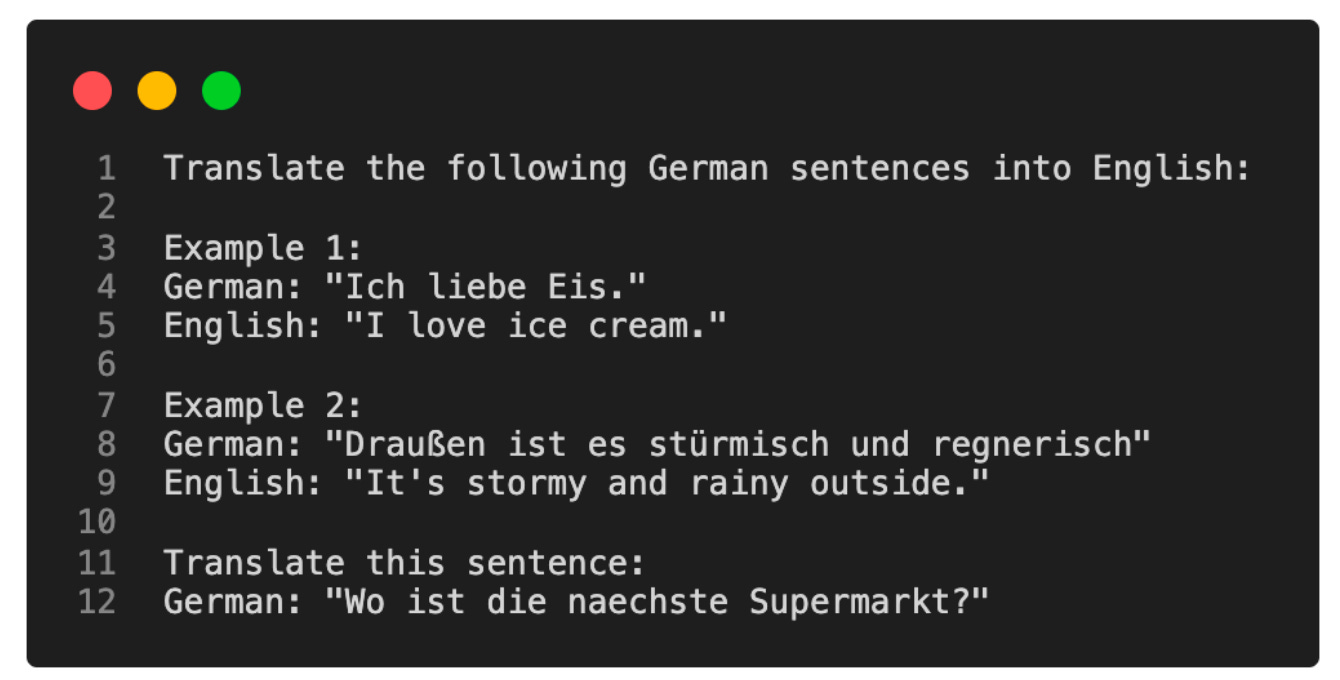
Prompt Tuning 的原始概念是指通过改变输入 Prompt 来获得更好建模结果的技术。例如,假设我们要将英语句子翻译成德语,可以用不同方式向模型提问,如下图所示。
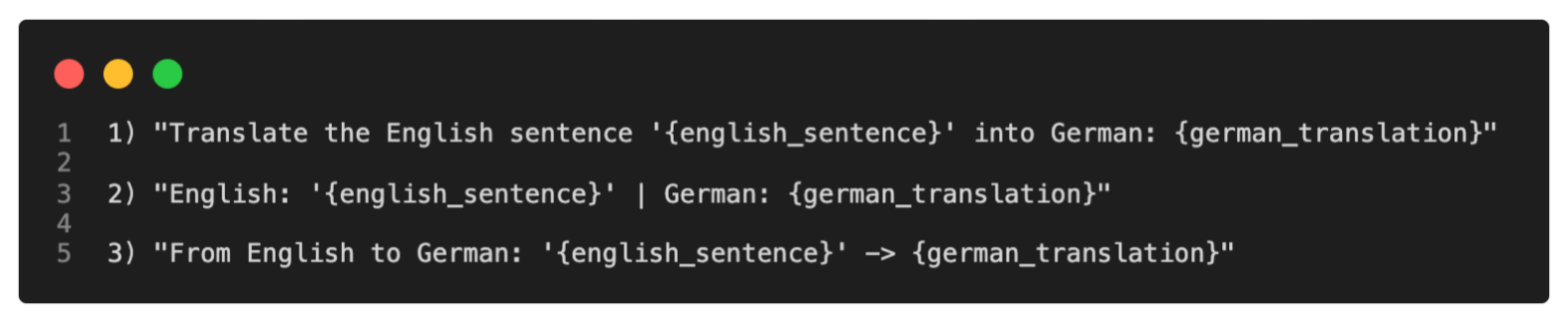
上图所示的概念称为 Hard Prompt Tuning,因为我们直接更改不可微分的离散输入标记。
与之相对,Soft Prompt Tuning 将输入标记的嵌入与可训练张量拼接。该张量可通过反向传播优化,从而提升目标任务的建模性能。
Prefix Tuning(Li and Liang)是 Prompt Tuning 的一种特殊形式。其核心思想是向每个 Transformer Block 添加可训练张量,而非仅在输入嵌入层添加。下图说明了常规 Transformer Block 与使用 Prefix 修改后的 Transformer Block 之间的区别。
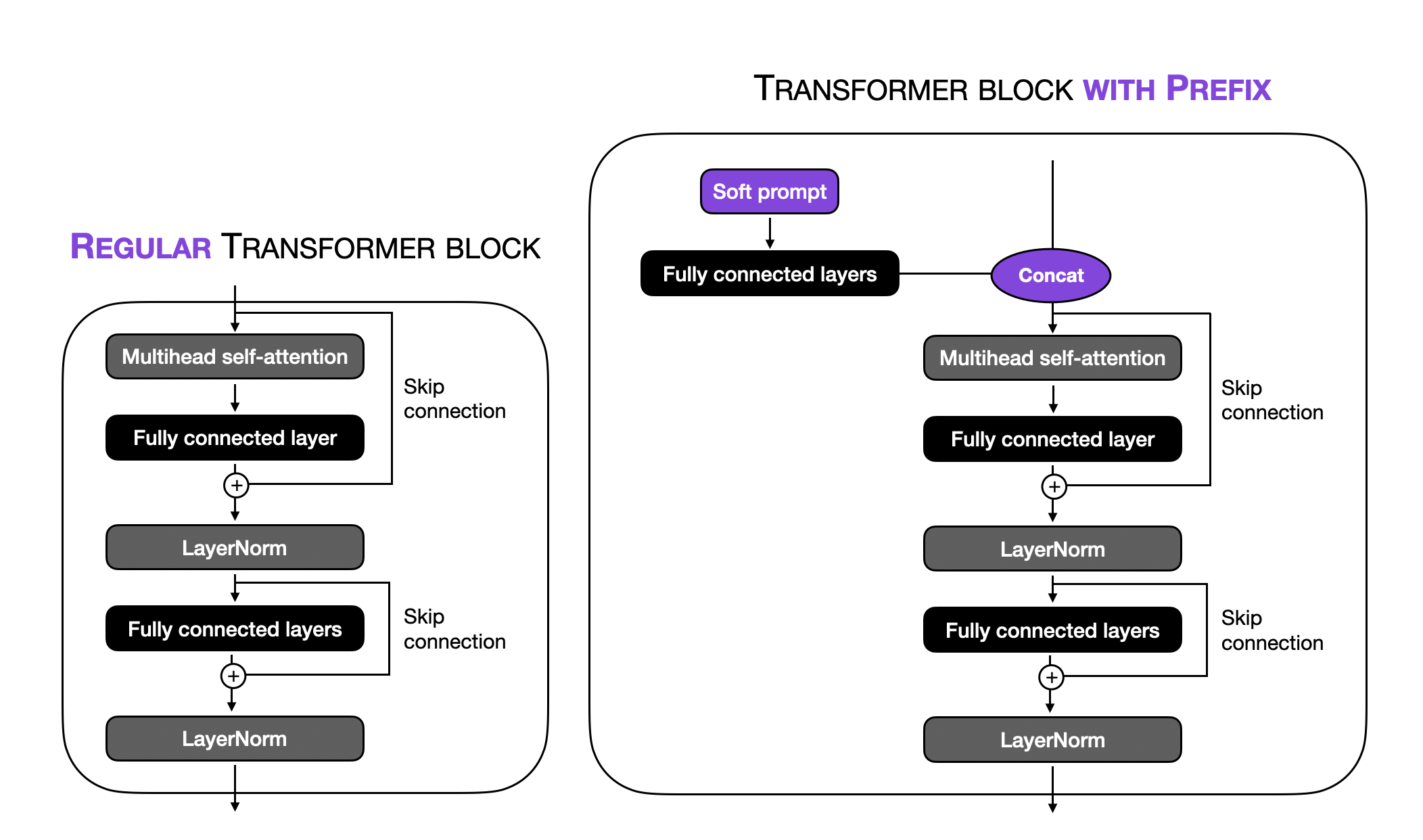
请注意,上图中"全连接层"指的是一个小型多层感知器(两个全连接层之间有一个非线性激活函数)。这些全连接层将 Soft Prompt 嵌入投影到与 Transformer Block 输入相同维度的特征空间中,以确保拼接时的维度兼容性。
使用(Python)伪代码,可以说明常规 Transformer Block 与 Prefix 修改后的 Transformer Block 之间的区别:
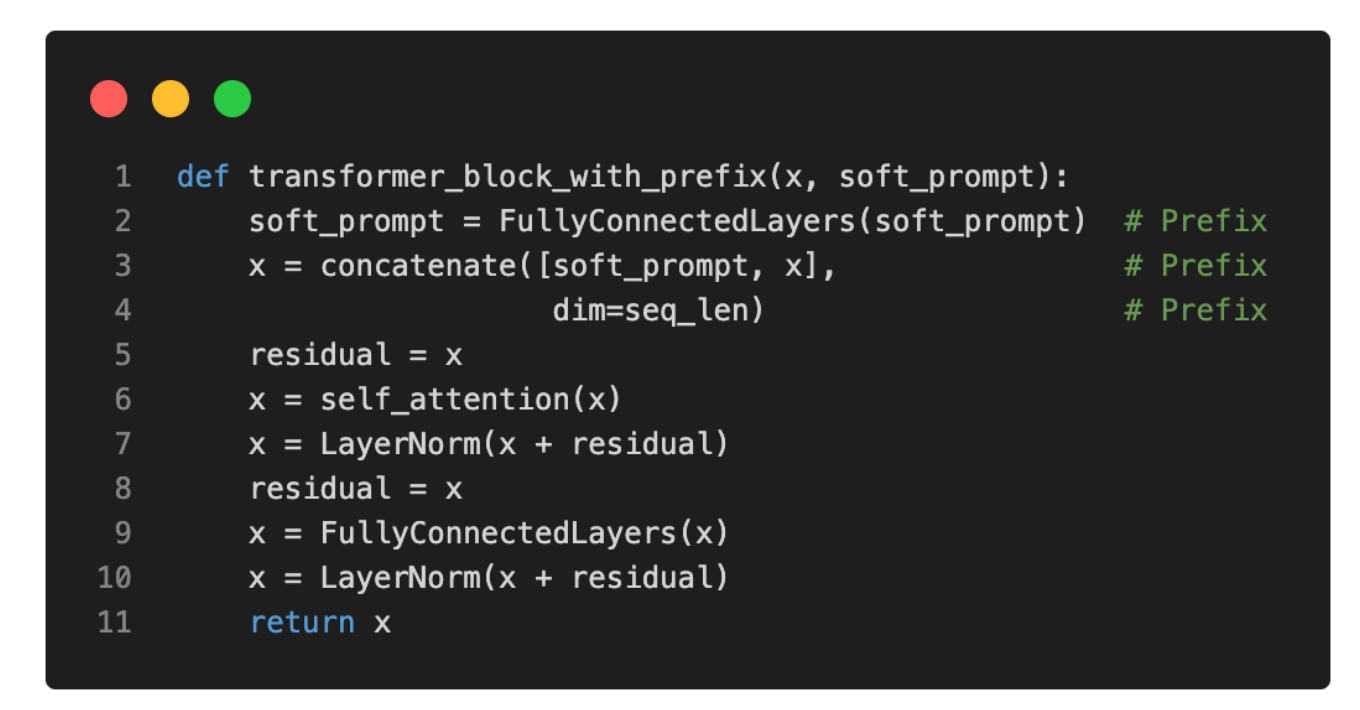
根据 Prefix Tuning 原始论文,Prefix Tuning 仅需训练 0.1% 的参数即可达到与全层微调相当的建模性能——实验基于 GPT-2 模型。此外,在许多场景中,Prefix Tuning 甚至优于全层微调,原因可能是更少的参数有助于减少在较小目标数据集上的过拟合。
最后,关于推理阶段 Soft Prompt 的使用:学习到 Soft Prompt 后,在执行微调模型的特定任务时需将其作为前缀提供,使模型能够针对特定任务调整响应。我们可以为不同任务维护多个 Soft Prompt,推理时提供相应前缀即可获得最优的任务特定结果。
3.2 Adapters
接下来讨论一种称为 Adapters 的相关方法。其核心思想是向 LLM 各 Transformer Block 添加可调层,而非仅修改输入 Prompt。
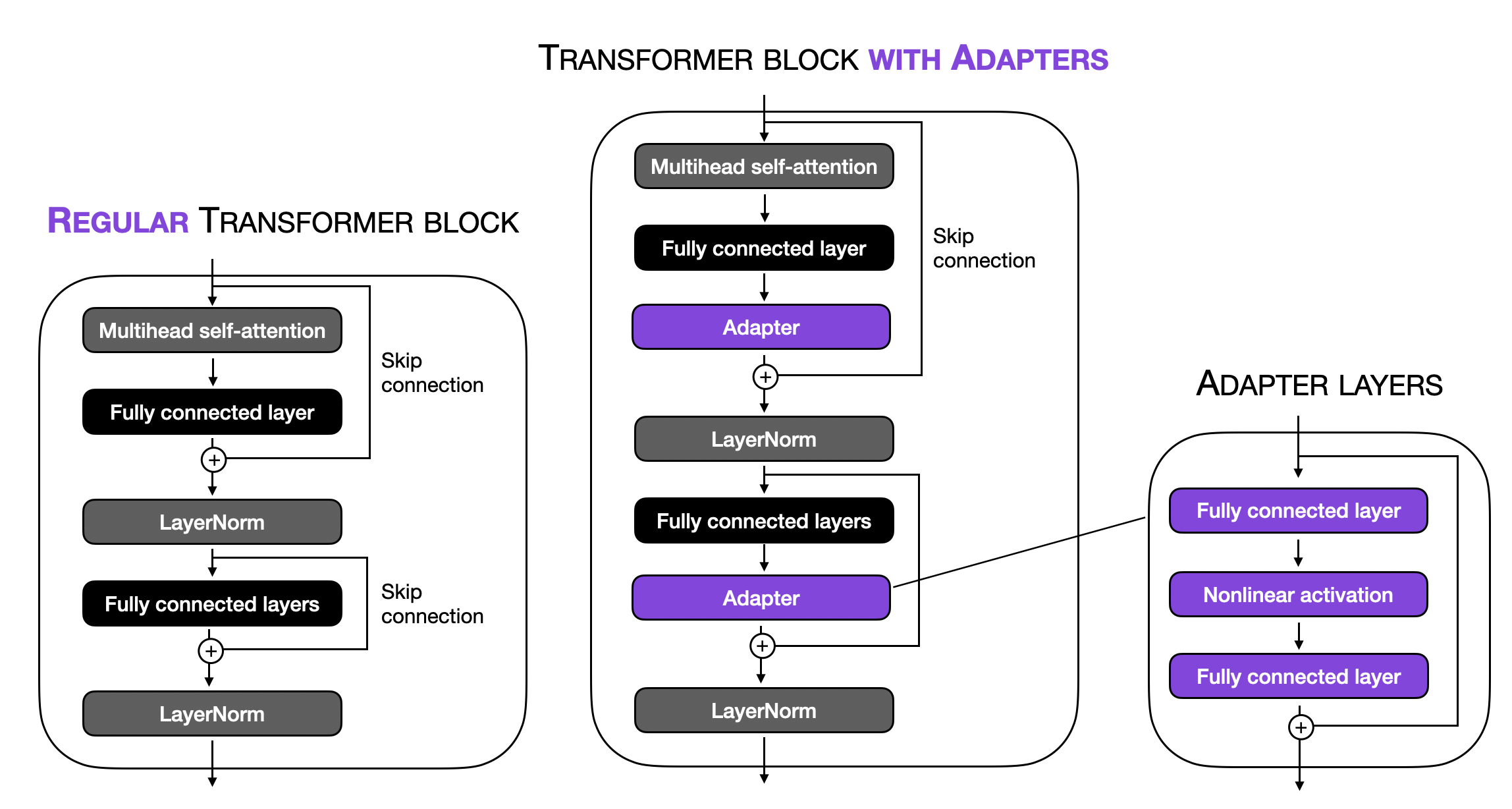
原始 Adapters 方法(Houlsby et al.)与 Prefix Tuning 有一定关联,因为它们同样向每个 Transformer Block 添加额外参数。但区别在于,Adapters 方法不是将可调张量添加到嵌入中,而是在两个位置插入 Adapter 层,如下图所示。
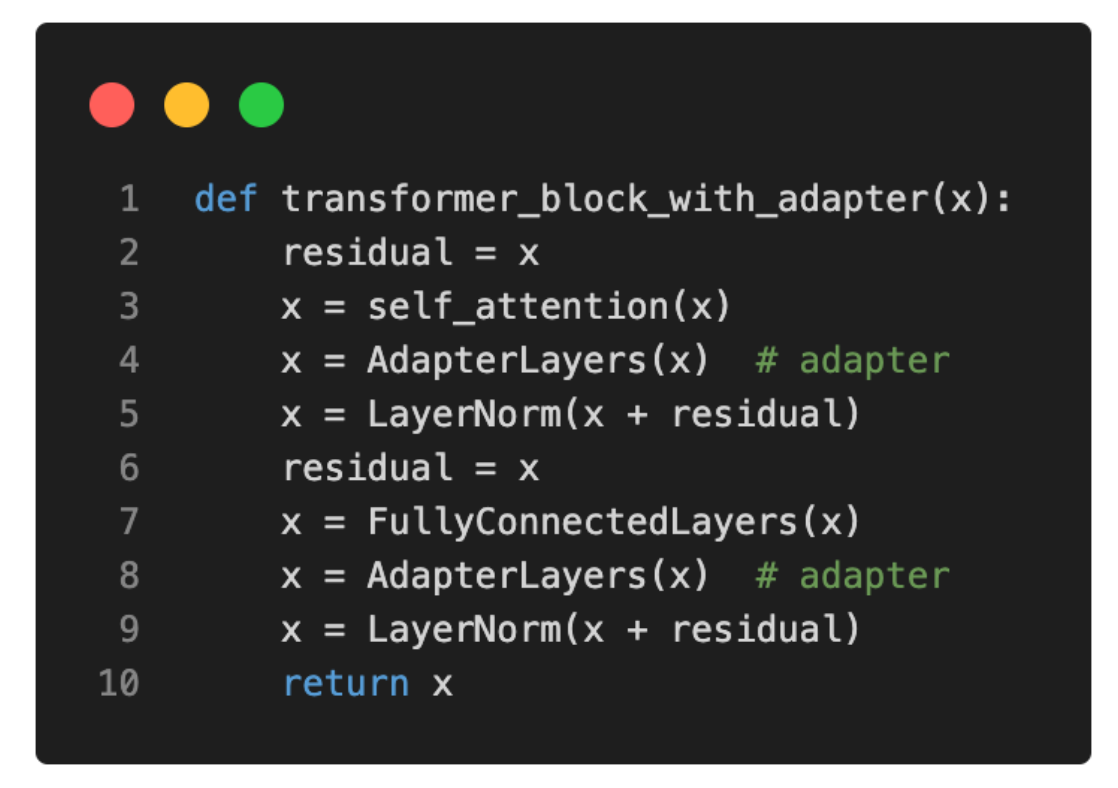
对于偏好(Python)伪代码的读者,Adapter 层可以这样表示:
使用 Adapter 层修改的 Transformer Block 示意图。
Adapter 的全连接层通常较小,具有类似自编码器的瓶颈结构。第一个全连接层将输入投影到低维表示,第二个全连接层将其投影回原始输入维度。
这如何实现参数高效?例如,假设第一个全连接层将 1024 维输入投影到 24 维,第二个全连接层再投影回 1024 维。两层共引入
根据 Adapter 原始论文,使用 Adapter 方法训练的 BERT 模型达到了与全量微调 BERT 模型相当的性能,而仅需训练 3.6% 的参数。
此外,研究者将 Adapter 方法与仅微调 BERT 输出层的方法进行了对比,发现 Adapter 用更少的参数即可达到甚至超越仅微调顶层的性能:
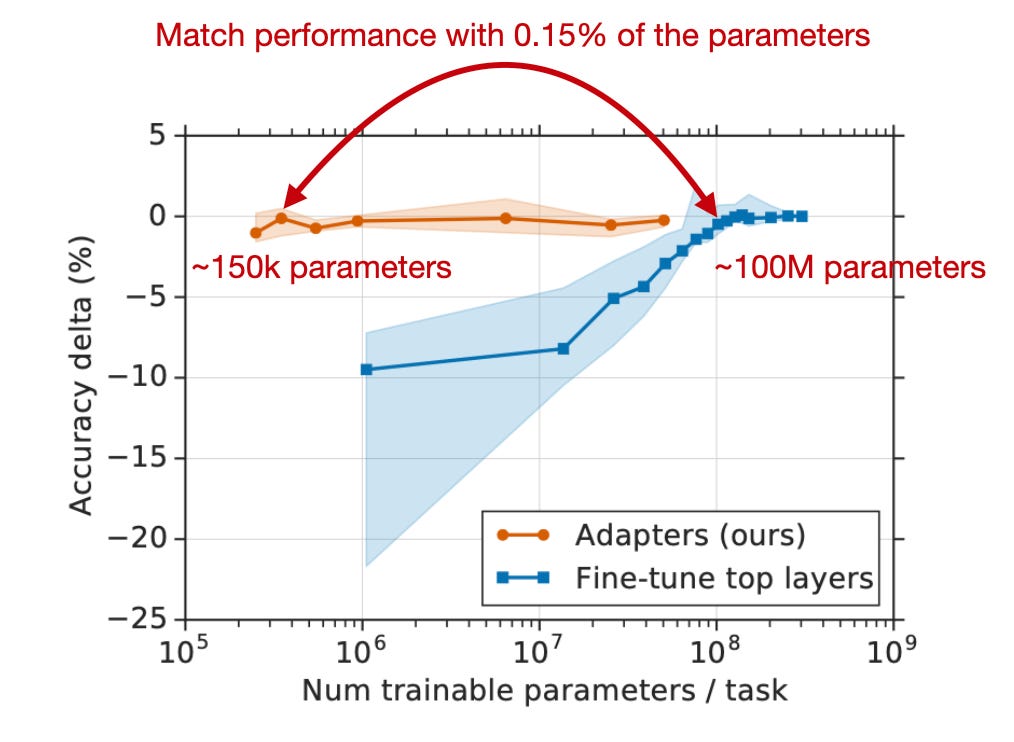
Adapter 论文注释图,https://arxiv.org/abs/1902.00751。
那么 Adapters 方法与 Prefix Tuning 相比表现如何?根据 Prefix Tuning 原始论文,当仅调优模型参数总数的 0.1% 时,Adapters 方法性能略逊于 Prefix Tuning。而当 Adapters 调优 3% 的参数时,其性能才与仅用 0.1% 参数的 Prefix Tuning 持平。因此可以得出结论:Prefix Tuning 是两者中更为高效的方法。
3.3 LLaMA-Adapter
LLaMA-Adapter(Zhang et al.)扩展了 Prefix Tuning 和原始 Adapters 方法的思想,是一种针对 LLaMA(Meta 推出的 GPT 替代方案)的 PEFT 方法。
与 Prefix Tuning 类似,LLaMA-Adapter 将可调 Prompt 张量添加到嵌入输入中。但不同的是,前缀在嵌入表中学习和维护,而非外部提供。模型中每个 Transformer Block 拥有独立的学习前缀,允许跨不同层进行更精细的适配。
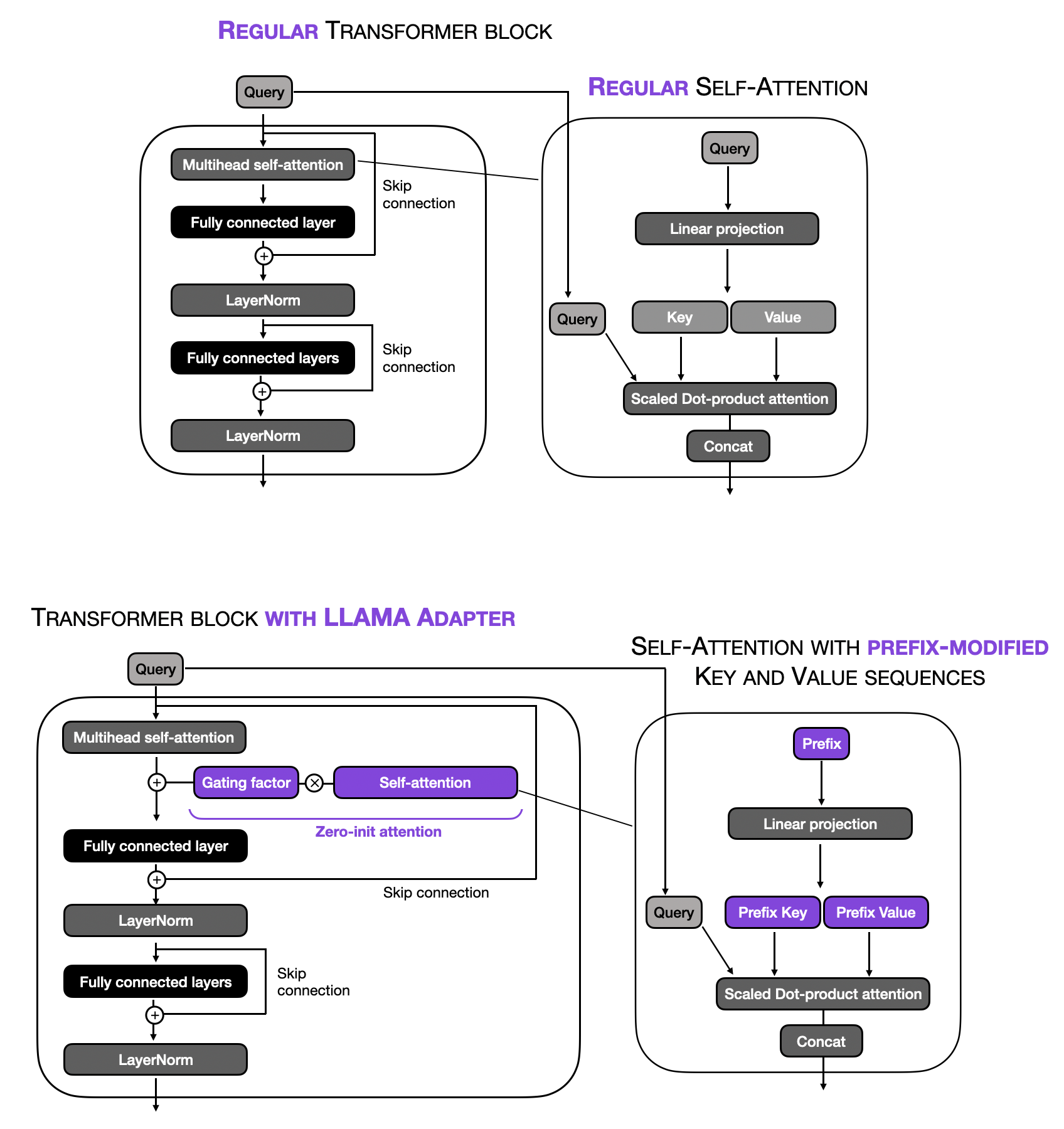
此外,LLaMA-Adapter 引入了零初始化注意力机制与门控。其动机在于:Adapters 和 Prefix Tuning 可能因引入随机初始化的张量(前缀 Prompt 或 Adapter 层)而破坏预训练 LLM 的语言知识,导致训练初期不稳定和高损失值。
与 Prefix Tuning 和原始 Adapters 的另一区别是,LLaMA-Adapter 仅将可学习的自适应 Prompt 添加到最顶部的
虽然 LLaMA-Adapter 的基本思想源于 Prefix Tuning(前置可调 Soft Prompt),但在具体实现上存在细微差异。例如,可调 Soft Prompt 仅修改自注意力输入的 Key 和 Value 序列;然后根据门控因子(训练开始时设为零)决定是否使用前缀修饰注意力。下图展示了这一概念:
伪代码表示如下:
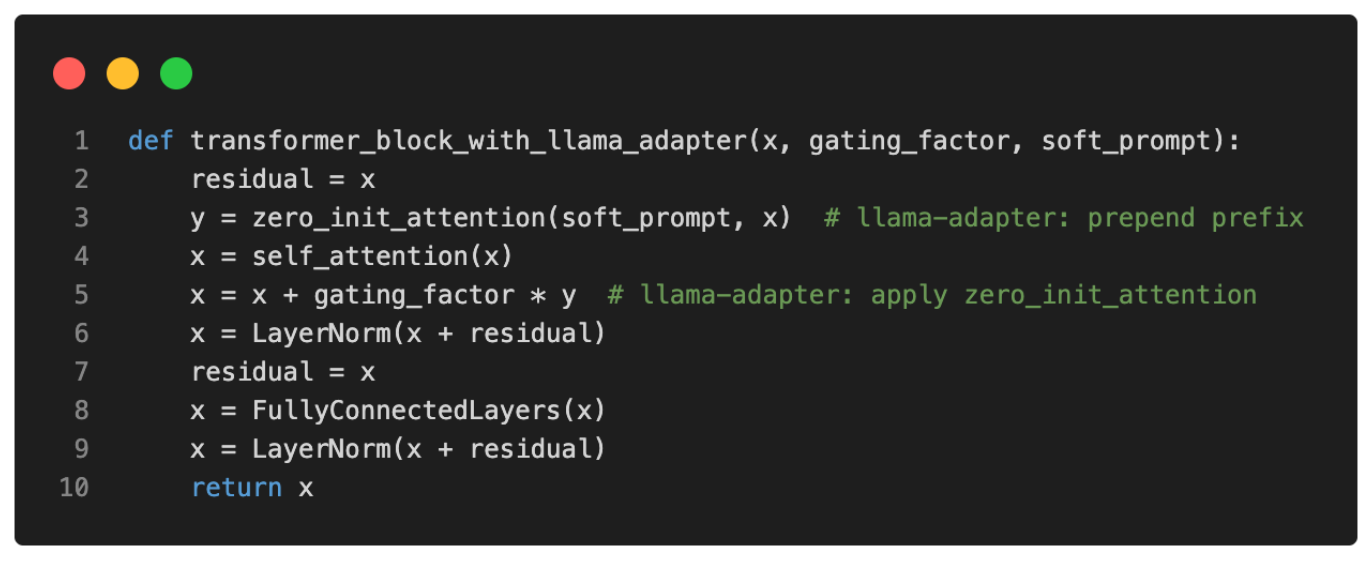
总结而言,LLaMA-Adapter 与常规 Prefix Tuning 的区别在于:仅修改顶部 Transformer Block,并引入门控机制以稳定训练。虽然研究者专门在 LLaMA 上进行实验,但该 Adapter 方法是通用的,同样适用于 GPT 等其他类型 LLM。
使用 LLaMA-Adapter,研究者在包含 52k 指令对的数据集上,仅用 1 小时(8 张 A100 GPU)即可微调一个 70 亿参数的 LLaMA 模型。微调后的模型在问答任务上优于研究中所有其他模型,而仅有 1.2M 参数(Adapter 层)需要微调。
如果您想查看 LLaMA-Adapter 方法,可以在此处找到基于 GPL 许可的 LLaMA 代码的原始实现。
4. 基于人类反馈的强化学习(RLHF)
在基于人类反馈的强化学习(RLHF)中,预训练模型通过监督学习与强化学习的结合进行微调。该方法由 ChatGPT 模型推广,而 ChatGPT 基于 InstructGPT(Ouyang et al.)。
RLHF 通过让人类对不同模型输出进行排名或评级来收集反馈,形成奖励信号。收集到的奖励标签用于训练奖励模型,该模型随后指导 LLM 适应人类偏好。
奖励模型本身通过监督学习训练(通常以预训练 LLM 作为基础模型)。随后,奖励模型用于更新预训练 LLM,训练采用近端策略优化(PPO,Schulman et al.)算法。
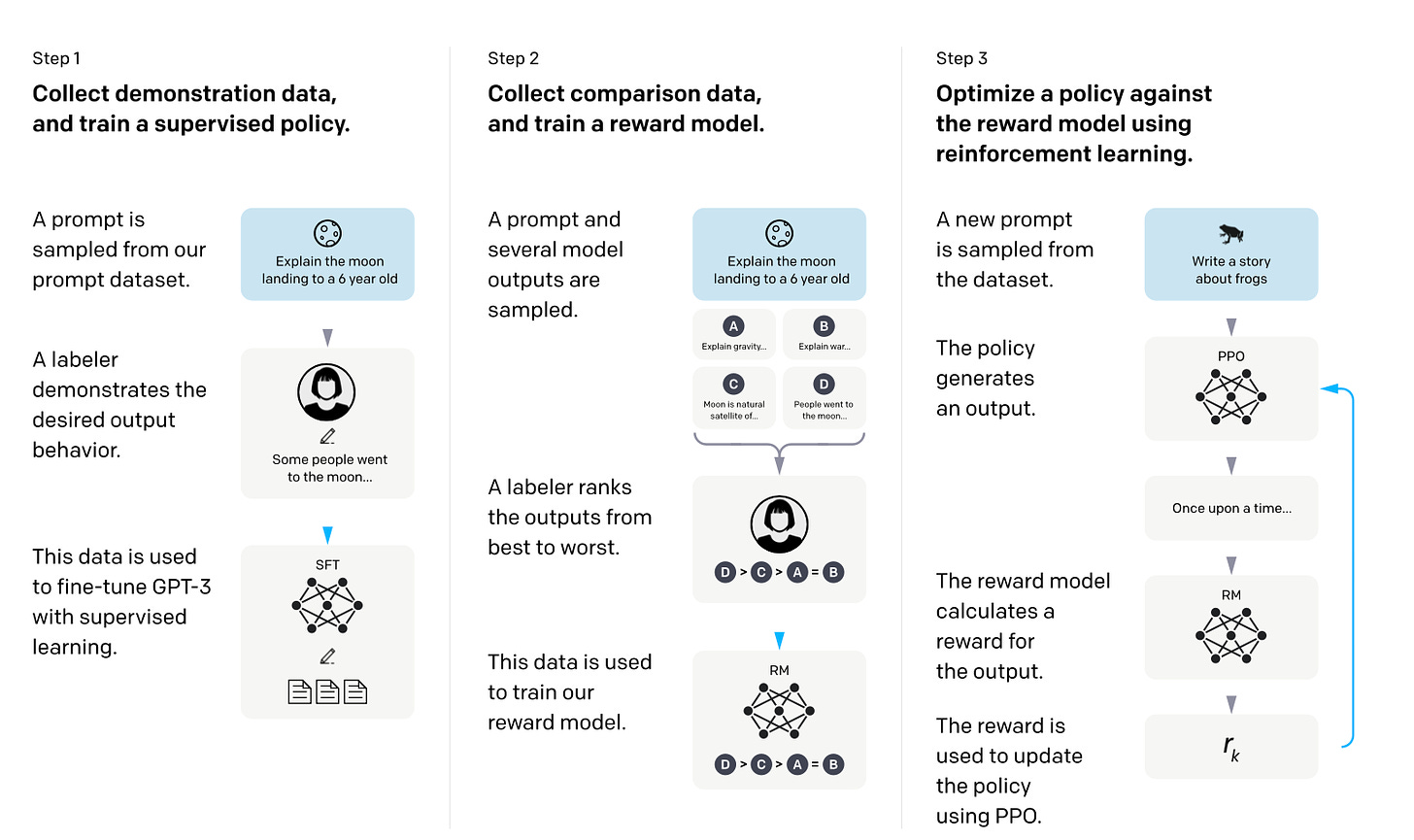
InstructGPT 论文中 RLHF 流程概览。
为什么使用奖励模型而非直接根据人类反馈训练模型?这是因为让人类实时参与学习过程会形成瓶颈——我们无法实时获取人类反馈。
结论
微调预训练 LLM 是将模型定制为特定业务需求、与目标领域数据对齐的有效方法。该过程使用与目标领域相关的较小数据集调整模型参数,使模型学习领域特定的知识和词汇。
然而,由于 LLM 参数量巨大,更新 Transformer 模型中的多个层成本极高,因此研究者开发了参数高效的替代方案。
本文讨论了传统 LLM 微调的几种参数高效替代方案,包括通过 Prefix Tuning 前置可调 Soft Prompt 和插入 Adapter 层。我们重点介绍了 LLaMA-Adapter 方法,它结合了可调 Soft Prompt 前置与门控机制以稳定训练。
此外,基于人类反馈的强化学习(RLHF)可作为监督微调的补充手段,有望进一步提升模型性能。