低秩适配(LoRA)微调
关键要点:在人工智能快速发展的今天,高效利用大型语言模型变得越来越重要。本文将介绍如何以计算高效的方式,使用低秩适应(LoRA)对 LLM 进行微调。
1. 为什么要微调
预训练的大型语言模型通常被称为基础模型,原因在于它们在各类任务上表现良好,可作为目标任务微调的起点。正如上一篇文章(了解大型语言模型的参数高效微调:从 Prefix Tuning 到 LLaMA-Adapters)所述,微调能使模型适应目标领域和目标任务。然而,模型越大,参数更新的计算成本越高。
作为全层更新的替代方案,研究者已开发了多种参数高效方法,如 Prefix Tuning 和 Adapters。目前,一种更为流行的参数高效微调技术是 Low-Rank Adaptation(LoRA),Hu et al.。什么是 LoRA?它如何工作?与其他微调方法相比表现如何?本文将逐一解答。
2. 使权重更新更高效
基于上述思想,LoRA(Hu et al.) 提出将权重变化
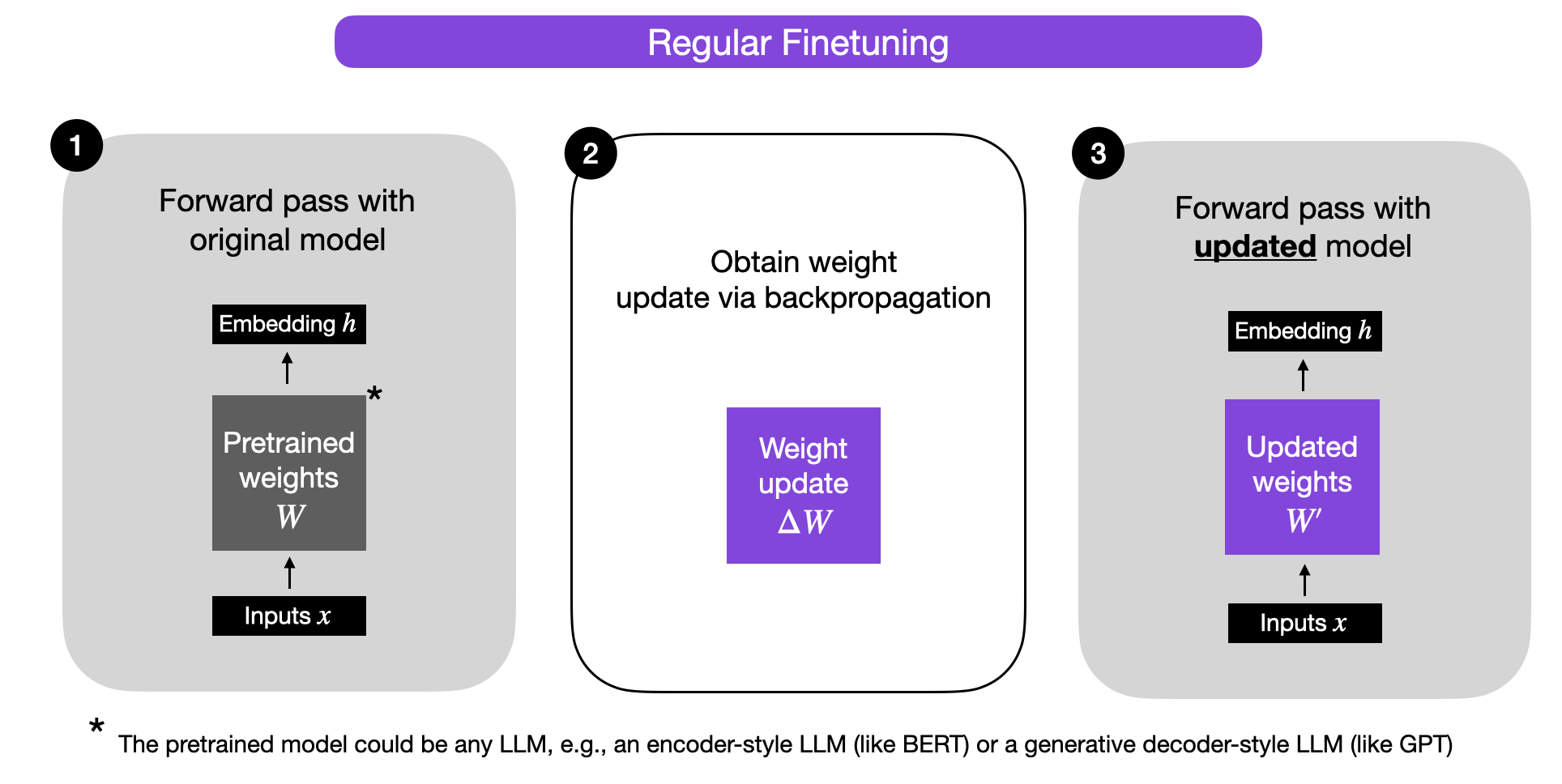
在深入 LoRA 之前,先简要回顾常规微调的训练过程。什么是权重变化
得到
下图对此进行了说明(为简化,省略偏置向量):
或者,我们可以将权重更新矩阵分离,按如下方式计算输出:
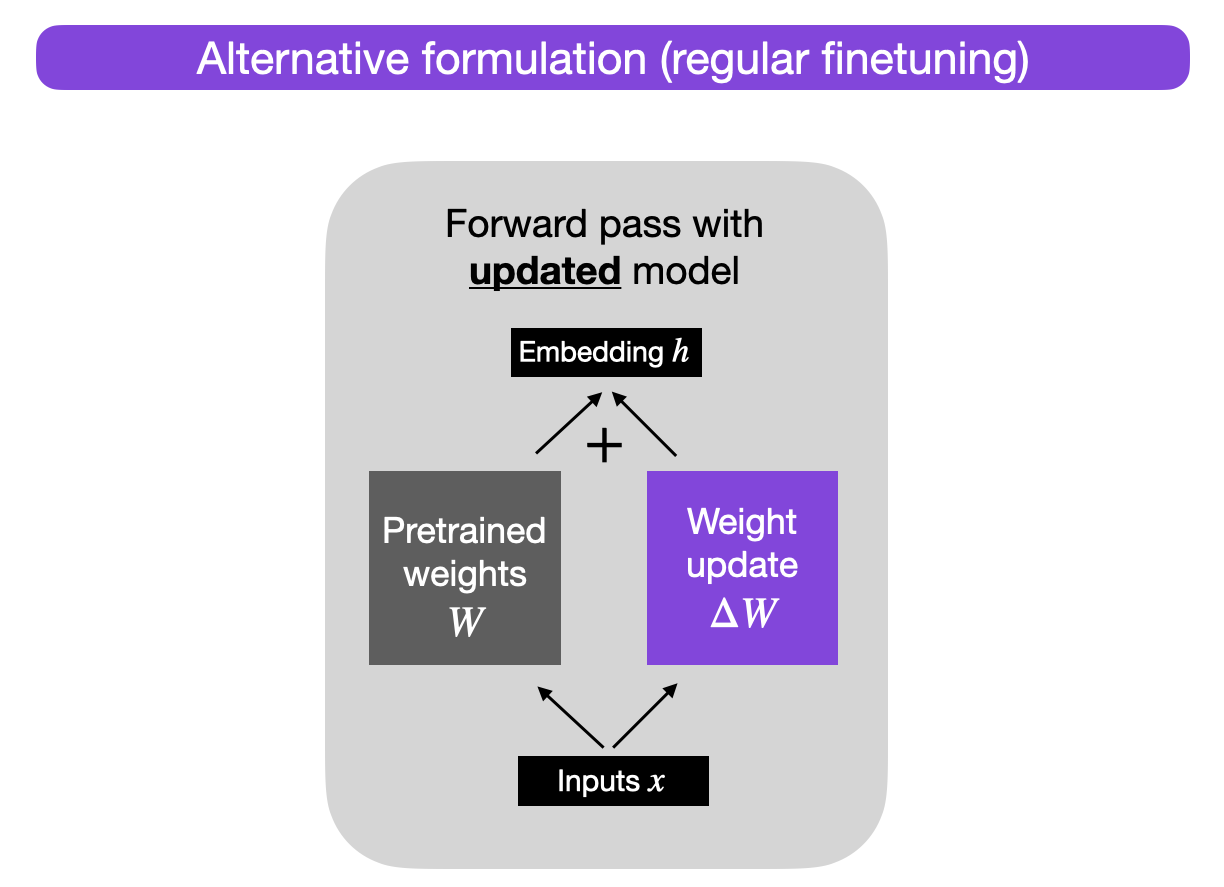
其中
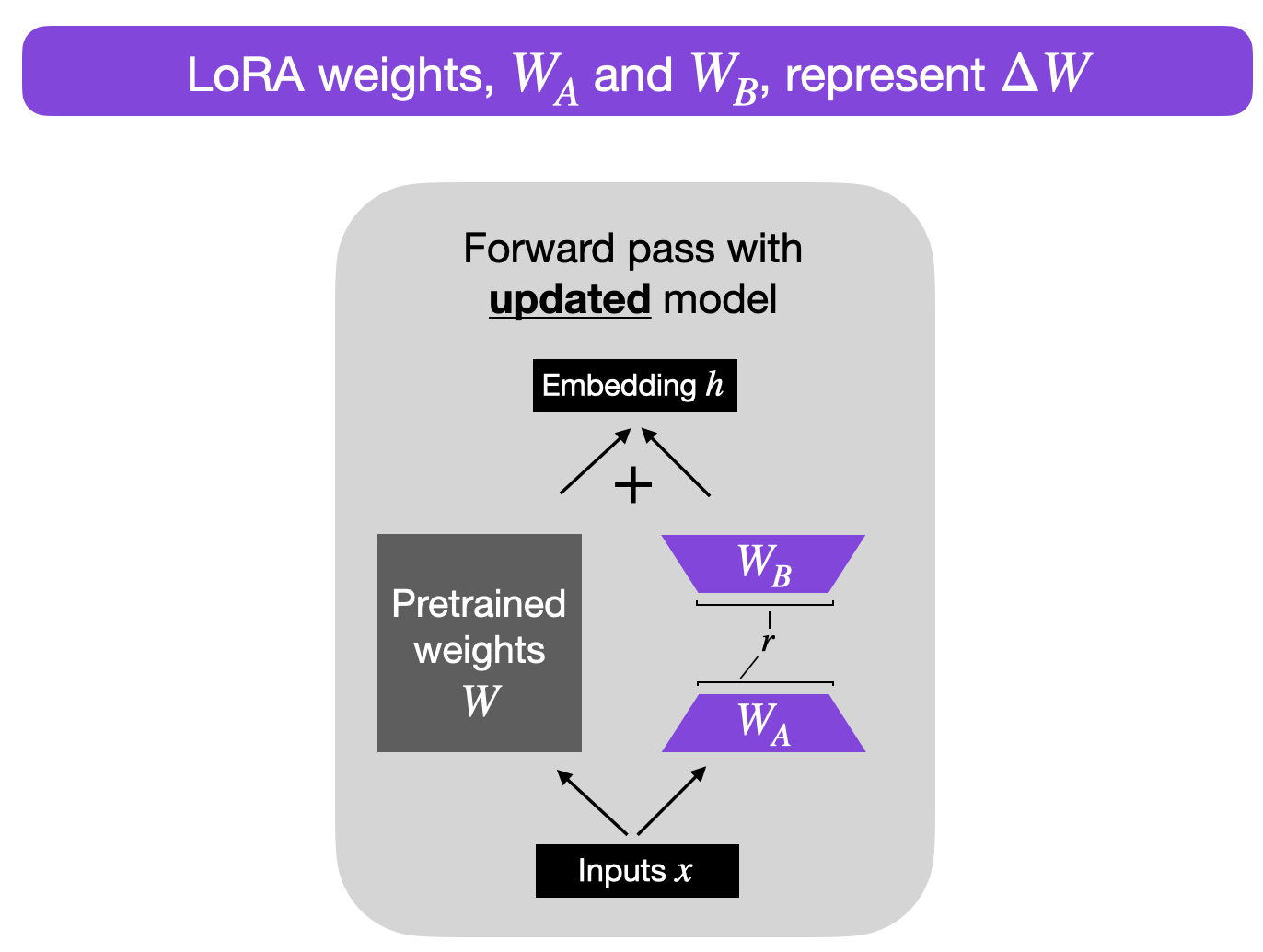
为什么要这样做?目前这种替代公式有助于说明 LoRA 的原理,后文将进一步解释。
在神经网络中训练全连接(即"密集")层时,权重矩阵通常具有满秩——即矩阵没有线性相关("冗余")的行或列。相反,低秩意味着矩阵存在冗余行或列。
虽然预训练模型的权重在预训练任务上具有满秩,但 LoRA 作者引用 Aghajanyan(2020)的研究指出:预训练大型语言模型在适应新任务时具有较低的"内在维度"。
低内在维度意味着数据可通过低维空间有效表示或近似,同时保留大部分关键信息和结构。换言之,我们可以将适应任务的新权重矩阵分解为低维(更小)矩阵,而不会丢失太多重要信息。
例如,假设
其中
2.1 选择秩
上图中的
总之,在 LoRA 中选择
2.2 实现 LoRA
LoRA 的实现相对简单,可将其视为 LLM 中全连接层的改进前向传播。伪代码如下:
import math
import torch
import torch.nn as nn
input_dim = 768 # 例如,预训练模型的隐藏尺寸
output_dim = 768 # 例如,层的输出尺寸
rank = 8 # 低秩适应的秩 r
W = ... # 来自具有形状 input_dim x output_dim 的预训练网络
W_A = nn.Parameter(torch.empty(input_dim, rank)) # LoRA 权重 A
W_B = nn.Parameter(torch.empty(rank, output_dim)) # LoRA 权重 B
# 初始化 LoRA 权重
nn.init.kaiming_uniform_(W_A, a=math.sqrt(5))
nn.init.zeros_(W_B)
def regular_forward_matmul(x, W):
h = x @ W
return h
def lora_forward_matmul(x, W, W_A, W_B, alpha=1.0):
h = x @ W # 常规矩阵乘法
h += x @ (W_A @ W_B) * alpha # 使用缩放的 LoRA 权重
return h在上述伪代码中,alpha 是一个缩放因子,用于调整组合结果(原始模型输出加低秩适应)的幅度。它平衡了预训练模型的知识和新的任务特定适应——默认情况下 alpha 通常设为 1。另请注意,
2.3 参数效率
如果引入了新的权重矩阵,为何还能实现参数高效?关键在于新矩阵
2.4 减少推理开销
在实践中,如果训练后保持原始权重
然而,保持
以具体数字说明:一个完整的 7B LLaMA checkpoint 需要 23GB 存储空间,而选择
2.5 实践效果
LoRA 在实践中表现如何?与全量微调及其他参数高效方法相比如何?根据 LoRA 论文,在多个任务特定基准测试中,LoRA 的建模性能略优于 Adapters、Prompt Tuning 和 Prefix Tuning。通常,LoRA 的性能甚至优于全层微调,如下表所示(ROUGE 是评估语言生成质量的指标)。
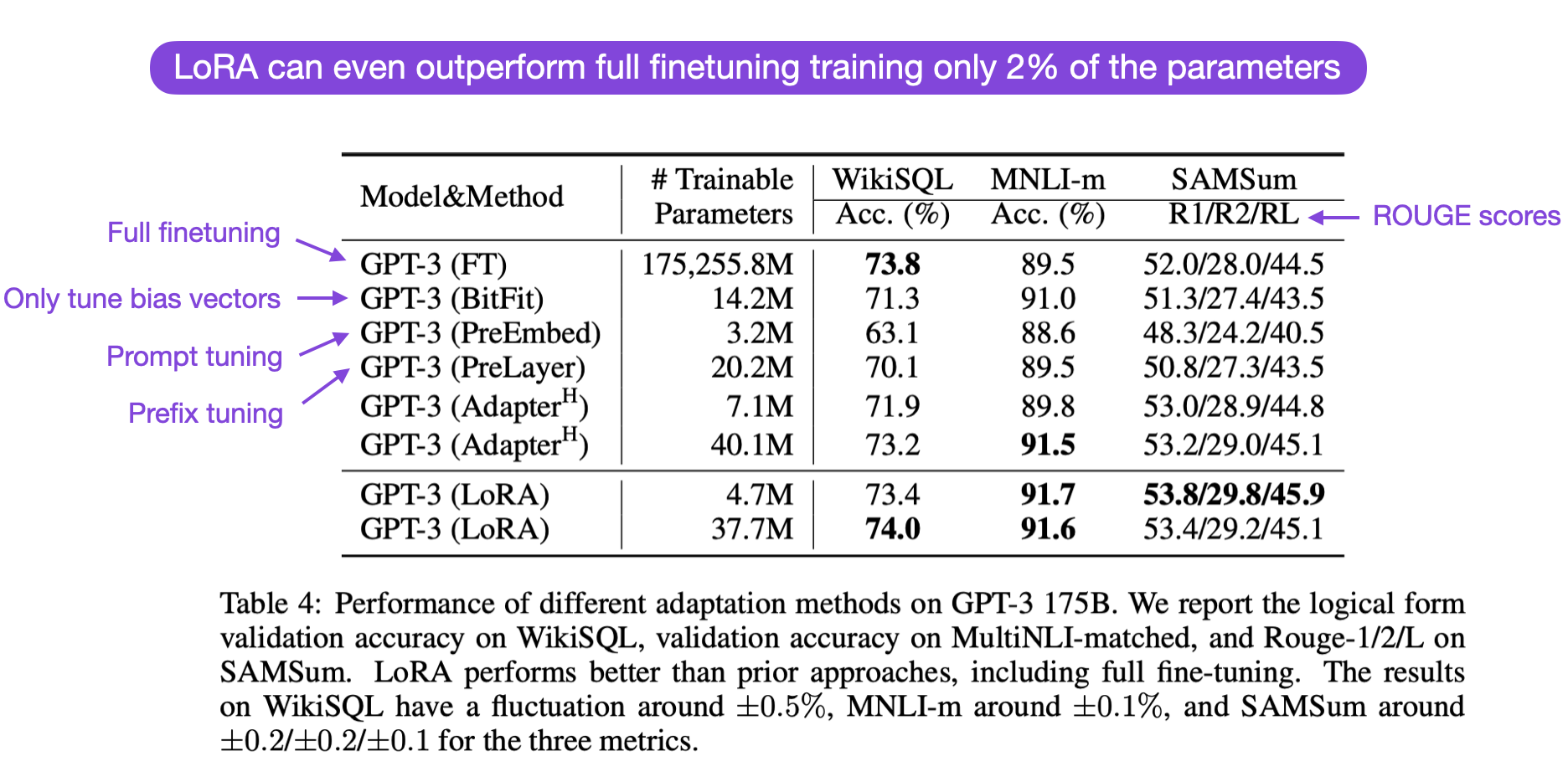
值得注意的是,LoRA 与其他微调方法是正交的,即它可以与 Prefix Tuning 和 Adapters 组合使用。