图解混合专家模型(MoE)
在看最新发布的大型语言模型(LLM)时,你可能经常会在标题中看到 "MoE" 这个词。那么,这个 "MoE" 到底代表什么?为什么现在有这么多 LLM 都在使用它呢?
在这篇图解指南中,原作者使用超过 50 张图片进行可视化,带你一步步深入了解这个关键组成部分——混合专家模型(MoE,Mixture of Experts)。

在这份图解指南中,我们将依照典型的大语言模型(LLM)架构,依次讲解 MoE 的两个核心组成部分:专家(Experts) 和 路由器(Router)。
1. 什么是混合专家模型
混合专家模型(MoE,Mixture of Experts) 是一种提升大型语言模型(LLM)质量的技术,它通过引入多个不同的子模型(即"专家")来实现更好的性能。
MoE 的结构主要由两个核心组成部分构成:
- 专家(Experts):每一层前馈神经网络(FFNN)不再是一个单一结构,而是由多个"专家"组成。每个"专家"本质上也是一个前馈神经网络。
- 路由器(Router)或门控网络(Gate Network):负责决定每个 token(词元)应该被送到哪些专家那里去处理。
在使用 MoE 架构的大语言模型中,我们会在模型的每一层看到多个(具有一定专长的)专家:
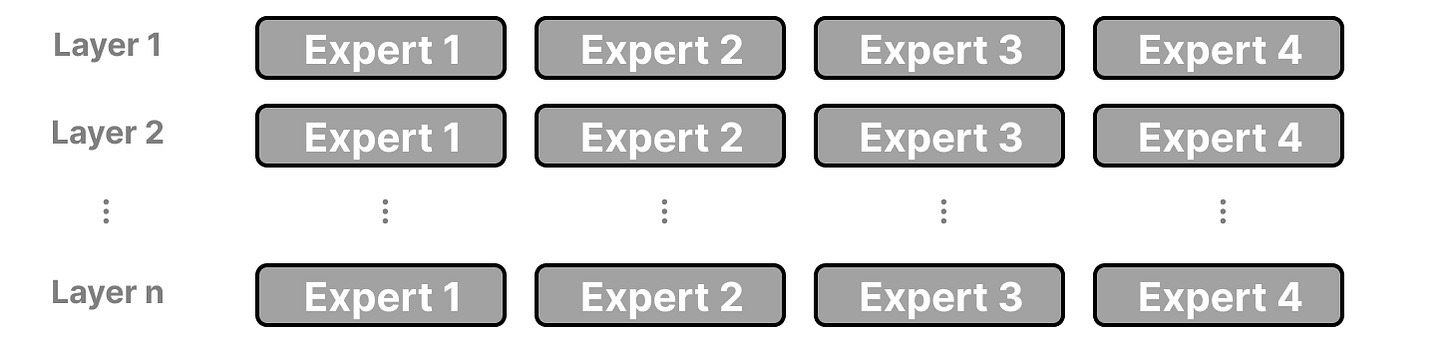
需要注意的是,这里的"专家"并不是指在某个具体学科领域(比如"心理学"或"生物学")特别擅长的模型。它们最多只是在处理某些词语的语法结构方面表现更好:

更准确地说,这些专家擅长处理某些特定上下文中出现的特定 token。
而路由器(或门控网络)的作用,就是根据输入内容选择最合适的专家来处理每个 token:

每个专家并不是一个完整的 LLM,而只是 LLM 架构中的一个子模块。
2. 专家模块
为了更好地理解"专家"代表什么,以及它们是如何工作的,我们先来看看 MoE 想要替代的是什么——稠密层(dense layers),也就是传统的全连接层。
2.1 稠密层
混合专家模型(MoE)的出发点,是 LLM 中最基础的组件之一:前馈神经网络(FFNN,Feedforward Neural Network)。
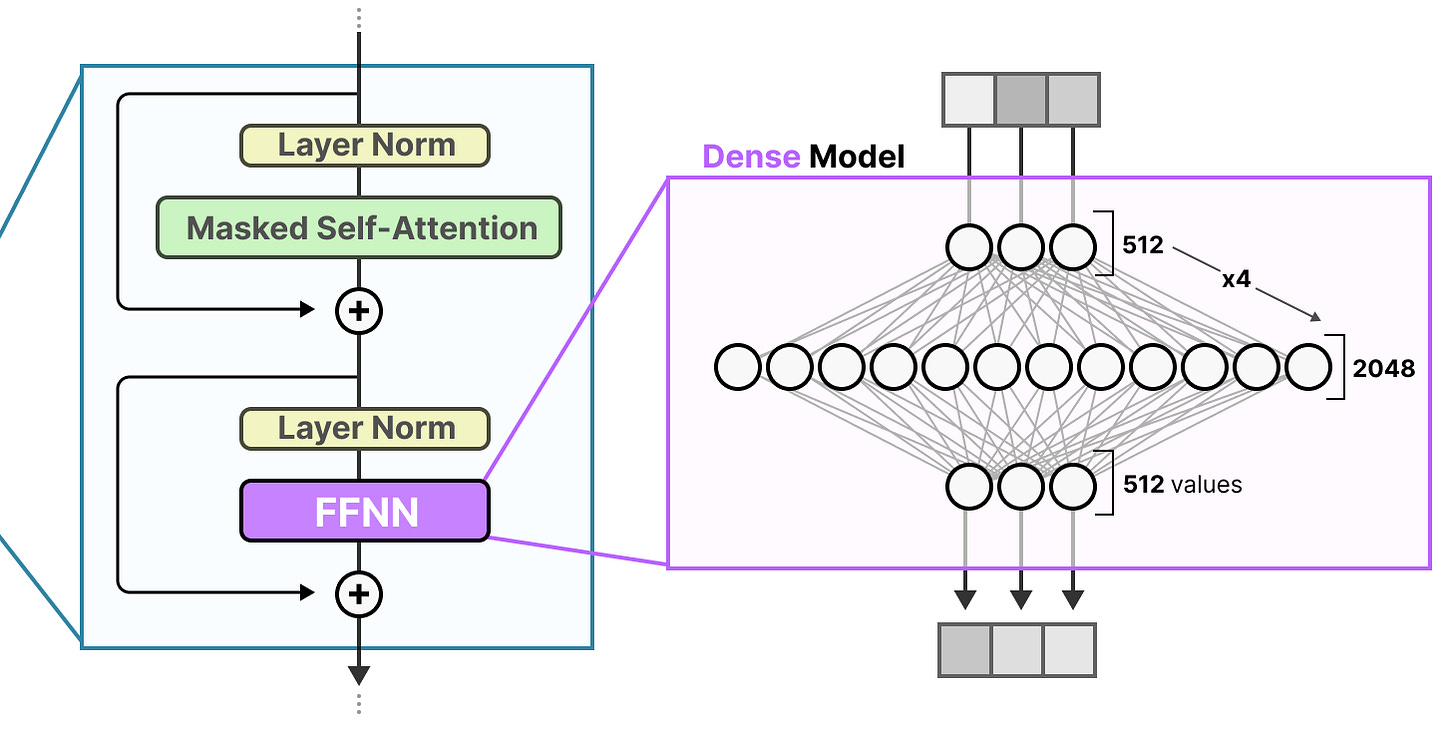
回想一下,在一个标准的仅解码器(decoder-only)Transformer 架构中,FFNN 位于层归一化(layer normalization)之后:

不了解 decoder-only Transformer 的人看到上面这个图可能会困惑。下面讲解一下:
普通的 Transformer 是 post-LN,结构如下:
input
│
├─ Masked Multi-Head Self-Attention
├─ Residual Add + LayerNorm
│
├─ Encoder-Decoder Cross Attention
├─ Residual Add + LayerNorm
│
├─ Feedforward Neural Network (FFNN)
├─ Residual Add + LayerNorm但是 decoder-only Transformer 架构的模型(如 GPT 系列)使用 pre-LN,并且因为是 decoder-only,不需要交叉注意力层(编码器-解码器注意力层),因此架构如下:
Input
│
├─ LayerNorm
│
├─ Masked Multi-Head Attention
│
├─ Residual Add
│
├─ LayerNorm
│
├─ Feedforward Neural Network (FFNN)
│
├─ Residual AddFFNN 的作用,是利用注意力机制生成的上下文信息,并进一步转换这些信息,从而捕捉数据中更复杂的关联关系。
不过,FFNN 的规模增长得非常快。为了学到这些复杂关系,它通常会对输入数据进行"扩展":
2.2 稀疏层
传统 Transformer 中的 FFNN 被称为稠密模型(dense model),因为它的所有参数(包括权重和偏置)在每次前向传播时都会被激活。所有部分都会参与运算,没有遗漏。
如果我们仔细观察一个稠密模型,会发现输入在计算中"激活"了所有的参数:
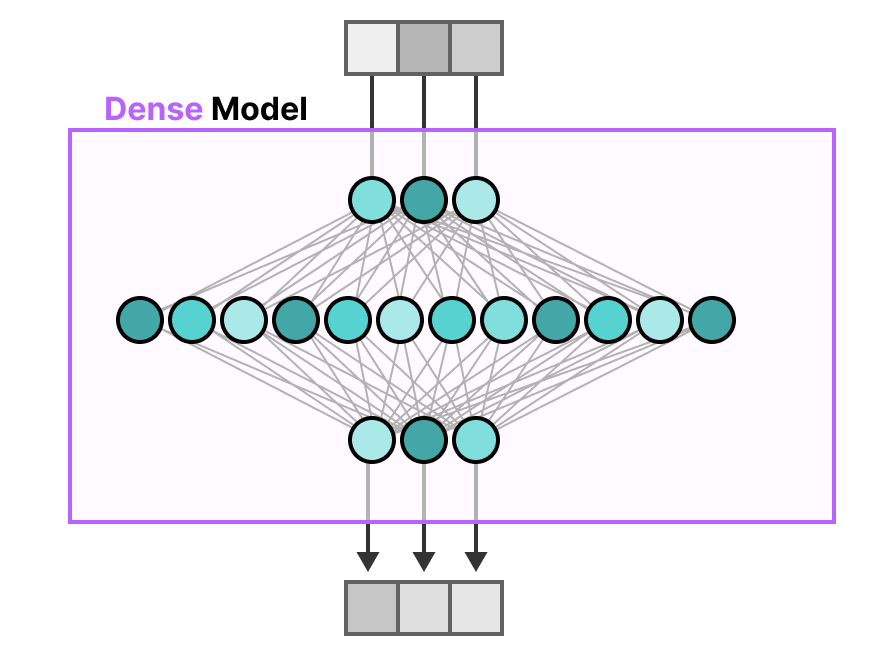
相反,稀疏模型(sparse models) 只激活部分参数,这就与 MoE 的机制密切相关了。
举个例子:我们可以把一个稠密模型拆成若干片(也就是所谓的专家),然后重新训练。在模型实际运行时,每次只激活其中的一小部分专家:

背后的思想是:每个专家在训练时学会了不同的知识。因此,在推理阶段(即模型实际使用时),只会调用那些与当前任务最相关的专家。
当我们向模型提问时,系统就会选择最适合回答这个问题的专家:

2.3 专家学到了什么
前面我们讲到,专家所学的信息比起整个领域而言,是更为细粒度的信息。因此,"专家"这一名称有时会产生误导。

上图是 ST-MoE 论文中,编码器模型中专家表现出的专门化。通俗理解就是不同专家捕获不同的信息。
然而,解码器模型中的专家似乎并没有表现出同样类型的专门化。当然这也并不意味着所有专家都是一样的。
举个例子,在论文 Mixtral 8x7B 中,每个 token 都用第一个选择它的专家进行颜色标记。就是你一句话输入进去,不同的专家会注意到不同的 token,每个专家用不同颜色表示,如果在这个句子中,某个词语第一次就被引导到某个专家,那就用这个专家的颜色进行标记。

这张图显示,专家们更倾向于关注语法结构,而不是具体的领域知识。
因此,虽然解码器的专家看起来没有明显的专业领域,但它们好像会用于处理某些特定类型的 token。
2.4 专家的架构
虽然我们可以把专家想象成把一个稠密模型的隐藏层切分成若干部分,但实际上它们通常是完整的 FFNN 结构:

由于大多数大型语言模型有多个解码器块,一段文本在生成过程中会经过多个专家的处理:

不同的 token 会选择不同的专家,这就导致模型在计算时会走不同的"路径":
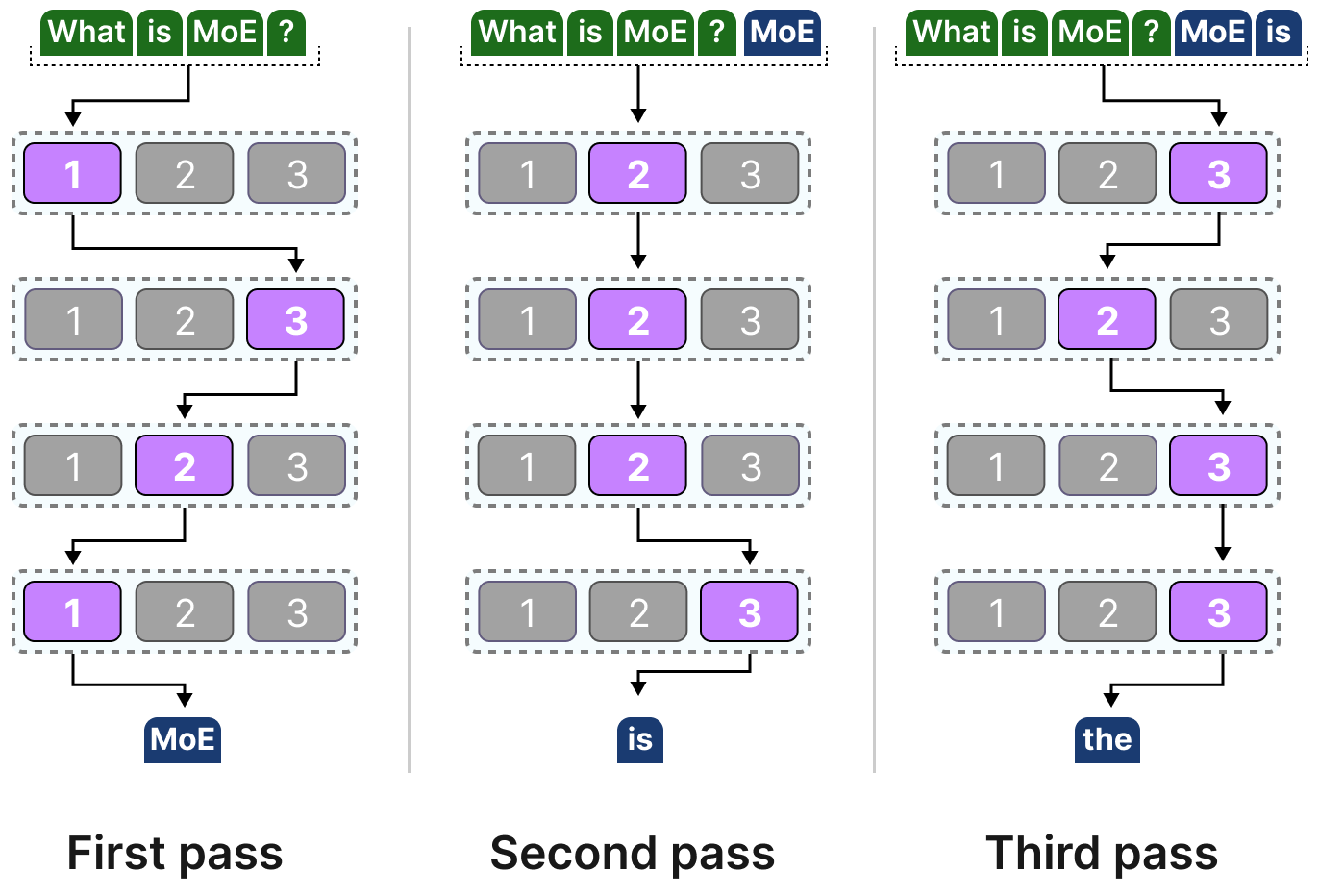
如果我们更新对解码器块的可视化表示,它现在会包含更多的 FFNN(每个对应一个专家):

因此,解码器块在推理时可以根据需要使用多个 FFNN(即不同的专家)。
3. 路由机制
现在我们已经有了一组专家,那模型是怎么知道该使用哪些专家的呢?
在专家模块之前,会加入一个路由器(router)(也称为门控网络 gate network),它是专门训练用于决定每个 token 应该交给哪一个专家来处理的。
3.1 路由器
路由器本身也是一个前馈神经网络(FFNN),它的作用是:根据每个 token 的输入内容,输出一组概率值,并据此选择最匹配的专家。

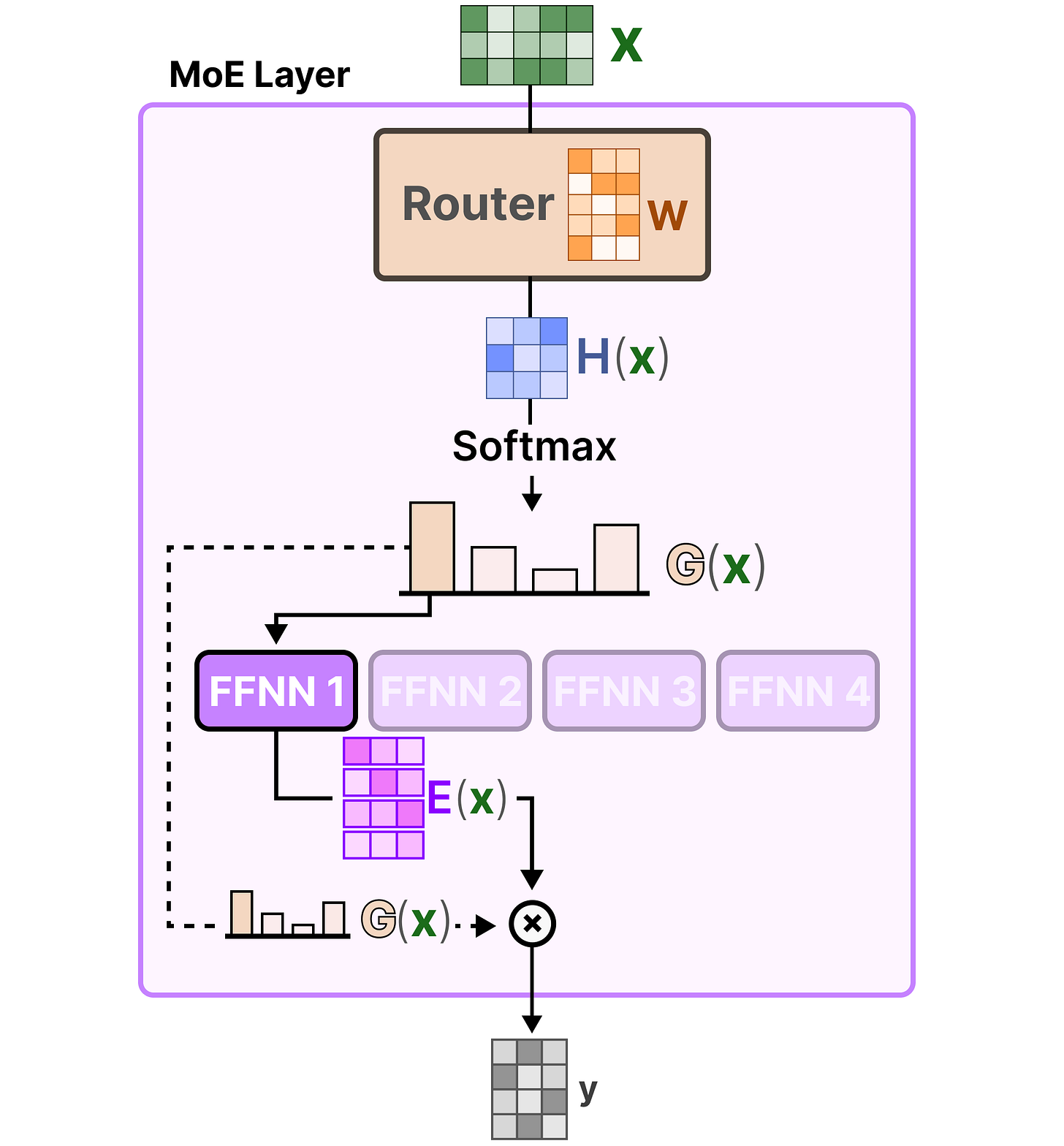
每个专家的输出会乘以对应的"门控值"(也就是刚才输出的概率),最终汇总后作为该层的输出。
路由器 + 一组专家(FFNN 被选中的一小部分)= 构成了一个 MoE 层(MoE Layer):

一个 MoE 层通常有两种大小类型:稀疏 MoE 或者稠密 MoE。
两者都使用路由器来选择专家,但稀疏 MoE 每次只选择少量专家参与计算,而稠密 MoE 所有专家都会参与计算,但参与程度可能不同。

例如:对一组 token,Dense MoE 会将每个 token 分发给所有专家,而 Sparse MoE 只会分发给其中少数几个。
目前大多数大语言模型的 MoE 实现均采用稀疏 MoE,因为它能有效降低推理成本,非常适合大规模模型。
3.2 专家选择的过程
路由器其实是 MoE 中最核心的组件之一。它不仅决定推理阶段该选哪些专家,也决定训练阶段哪些专家要被更新。
最基础的做法是,将输入 token 的表示向量

对打分结果做 softmax,得到一个不同专家的概率分布

然后根据这些概率值,选出和输入最相关的专家。
最后把每个路由器的输出与对应的专家相乘,加权求和,得到该 token 的最终输出:

我们把所有步骤汇总起来,这就完成了一个 token 从路由器流向专家的完整过程:

3.3 路由的挑战
不过,虽然这个机制看起来简单,但实际上会出现一个问题:某些专家收敛更快,导致路由器倾向于反复选择它们。

这样一来会导致一些问题:被选择的专家不均匀,部分专家几乎不会被训练到,最终训练和推理时都容易出现偏倚和性能下降。
为了解决这个问题,我们引入了负载均衡(load balancing)。其目的是让每个专家在训练和推理中都能被公平地使用,避免在某几个专家上过拟合。
4. 负载均衡
为了让不同专家的使用更加平衡,我们需要关注的是路由器(Router),因为它决定了每一次选用哪些专家。
4.1 KeepTopK 策略
一种常见的路由负载均衡方法是通过一个叫做 KeepTopK 的简单扩展,引入可训练的高斯噪声,以防止模型总是选中同一批专家:

接下来,除了你想要激活的 Top-k 个专家(比如前 2 个),其他专家的分数全部设为
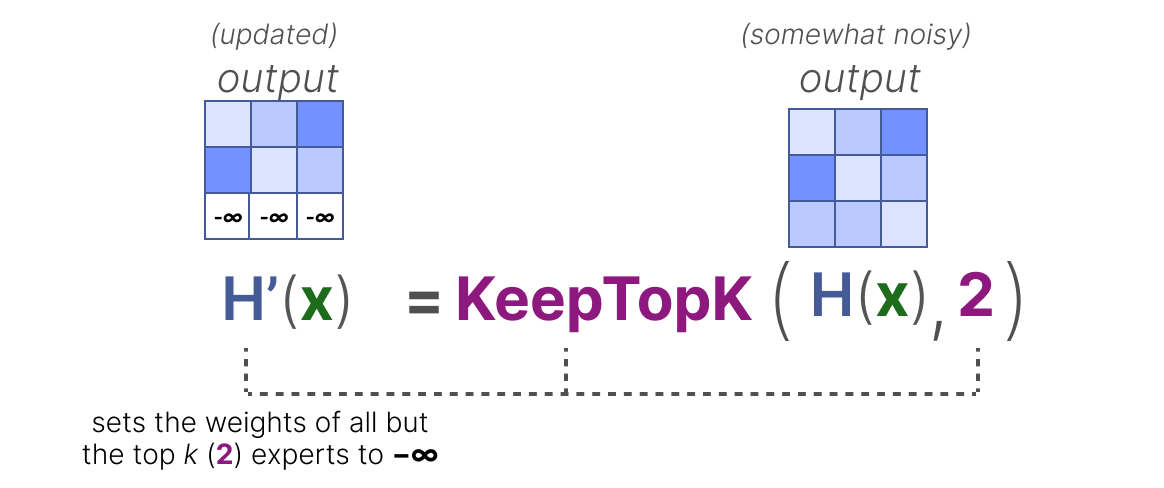
这样一来,在做 Softmax 时,分数为

虽然现在也有很多好用的替代方案(新的 MoE 路由算法),但 KeepTopK 仍然是许多大型语言模型中常用的策略。而且,它可以加噪声,也可以不加噪声。
4.1.1 Token Choice
KeepTopK 策略是每个 token 会被送到少数几个专家那里处理。这种方法被称为 Token Choice。Top-1 路由每个 token 只交给一个专家处理。

Top-k 路由将每个 token 同时送给

这种方法的优点是:可以根据每个专家的权重贡献,融合多个专家的知识,更灵活。
4.1.2 辅助损失
为了让训练过程中的专家使用更加平均,研究者在主损失之外,引入了一个辅助损失(Auxiliary Loss)(或者叫负载均衡损失(Load Balancing Loss))。
这个损失项的作用是强制每个专家在训练中有差不多的"重要性"。
辅助损失的第一步,是对整个 batch 中每个专家的路由概率值求和——统计在该 batch 中,每个专家"被选中的概率"之和:

这样就得到了每个专家的一个重要性分数(importance score),表示这个专家在整个 batch 中,在不考虑输入内容的情况下,有多大可能被选中。
接下来,我们利用这些重要性分数计算变异系数(Coefficient of Variation,CV),衡量各个专家的重要性差异:

如果 CV 很高,说明某些专家总被选中,而其他专家几乎没被用:

如果 CV 很低,说明所有专家被使用得差不多,这正是我们想要的"负载均衡"状态。

利用这个 CV 分数,我们可以在训练过程中不断更新辅助损失,使模型的优化目标之一就是尽可能降低 CV 值,从而让每个专家的使用重要性趋于一致:

最后,这个辅助损失会作为一个单独的损失项,加入到整体训练目标中一起优化。
总结一下三步:
🧩 第一步:计算每个专家的"重要性分数"
🧮 第二步:计算"变异系数"
💡 第三步:优化目标 = 降低 CV
4.2 专家容量
模型中的不平衡,不仅体现在被选中的专家不平均,也体现在发送给专家的 token 分布不均。
比如:如果大量输入 token 都被不均衡地路由到了某一个专家(而其他专家几乎不会接收到 token),那可能会导致训练不充分:

所以问题不只是"用了哪个专家",而是"每个专家被用了多少次"。
为了解决这个问题,可以引入一个限制机制,限制每个专家一次最多能处理多少个 token,称之为专家容量(Expert Capacity)。一旦某个专家达到容量上限,剩下的 token 就会被路由给下一个候选专家:
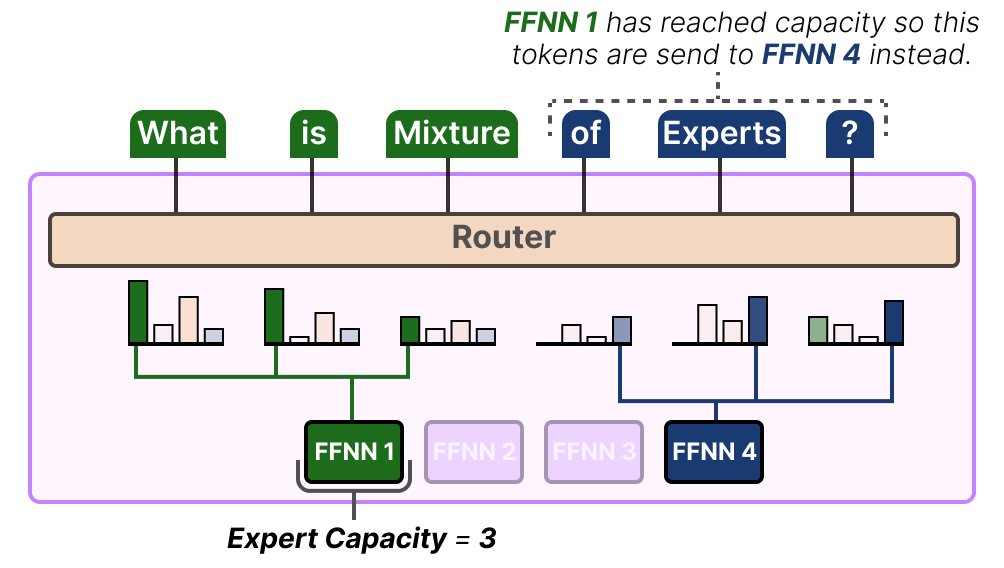
如果所有候选专家都已满,token 将不会被任何专家处理,而是跳过当前 MoE 层,进入下一层。这种情况被称为 token overflow(token 溢出)。

4.3 用 Switch Transformer 简化 MoE
Switch Transformer 是最早尝试解决 MoE 模型训练不稳定问题的 Transformer 架构之一(如前面讨论的专家负载不均衡问题)。它简化了 MoE 大部分架构和训练过程,同时提高了训练稳定性。
4.3.1 切换层
切换层(Switch Transformer)是在 T5(encoder-decoder 架构)基础上改造的模型,将传统 Transformer 中的前馈神经网络(FFNN)层替换为 Switching Layer(切换层)。该切换层本质上是稀疏 MoE 层,采用 Top-1 路由策略,每个 token 只被路由到一个最合适的专家上。

路由器在计算选择哪个专家时没有做特殊处理,仍是用输入 token 乘上每个专家的权重,然后做一次 softmax(与前文"专家选择的过程"部分一致)。

相比之前的 Top-k 路由策略,这种结构(Top-1 路由)基于一个假设:每个 token 只需一个专家就够用。
4.3.2 专家容量因子
专家容量因子(Capacity Factor)是一个非常重要的超参数,它决定了每个专家最多能处理多少个 token。
Switch Transformer 对这一点做了扩展,它允许你设置专家容量因子(capacity factor),显式地控制专家容量。

专家容量的组成部分很简单:

如果你把容量因子设置得大一点,每个专家就能处理更多的 token。

但是,如果容量因子太大,则会浪费计算资源;反之,如果容量因子太小,大量 token 将无法找到可用专家,导致前文所述的 token 溢出问题,进而影响模型性能。
4.3.3 辅助损失
为了进一步避免 token 被丢弃,Switch Transformer 引入了一个更简单版本的辅助损失函数。
这个简化的损失函数不再计算变异系数(coefficient variation),而是衡量每个专家实际被分配到的 token 的比例与路由器为该专家分配的概率之间的关系:
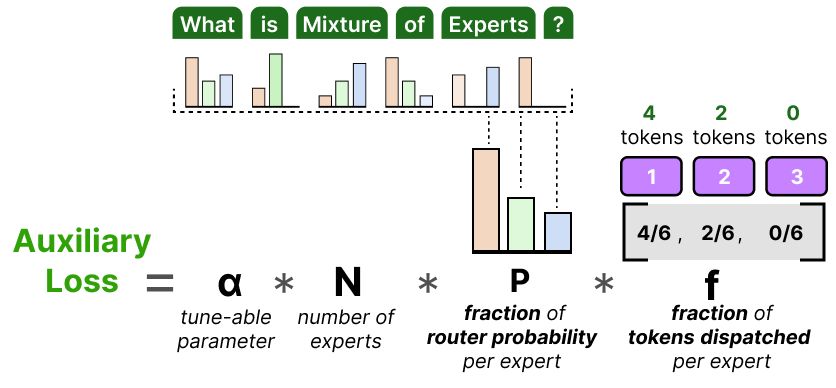
由于我们的目标是将 token 在
5. 视觉模型中的 MoE
MoE 并不是语言模型专属的技术。视觉模型(如 ViT)也是基于 Transformer 架构,所以也具备使用 MoE 的潜力。
快速回顾一下,ViT(Vision Transformer)是一种将图像切分成 patch(图像块)然后像处理文本 token 一样对它们进行处理的架构。

这些 patch(或 token)会被映射为 embedding(并加上额外的位置 embedding),然后送入编码器中:

这些 patch 一旦进入编码器,处理方法就与 token 相同,使得这种架构非常适合引入 MoE。
5.1 Vision-MoE
Vision-MoE(V-MoE)是最早在图像模型中实现 MoE 的方案之一。它以 ViT 架构为基础,用稀疏 MoE 替代了编码器中的稠密 FFNN 层。
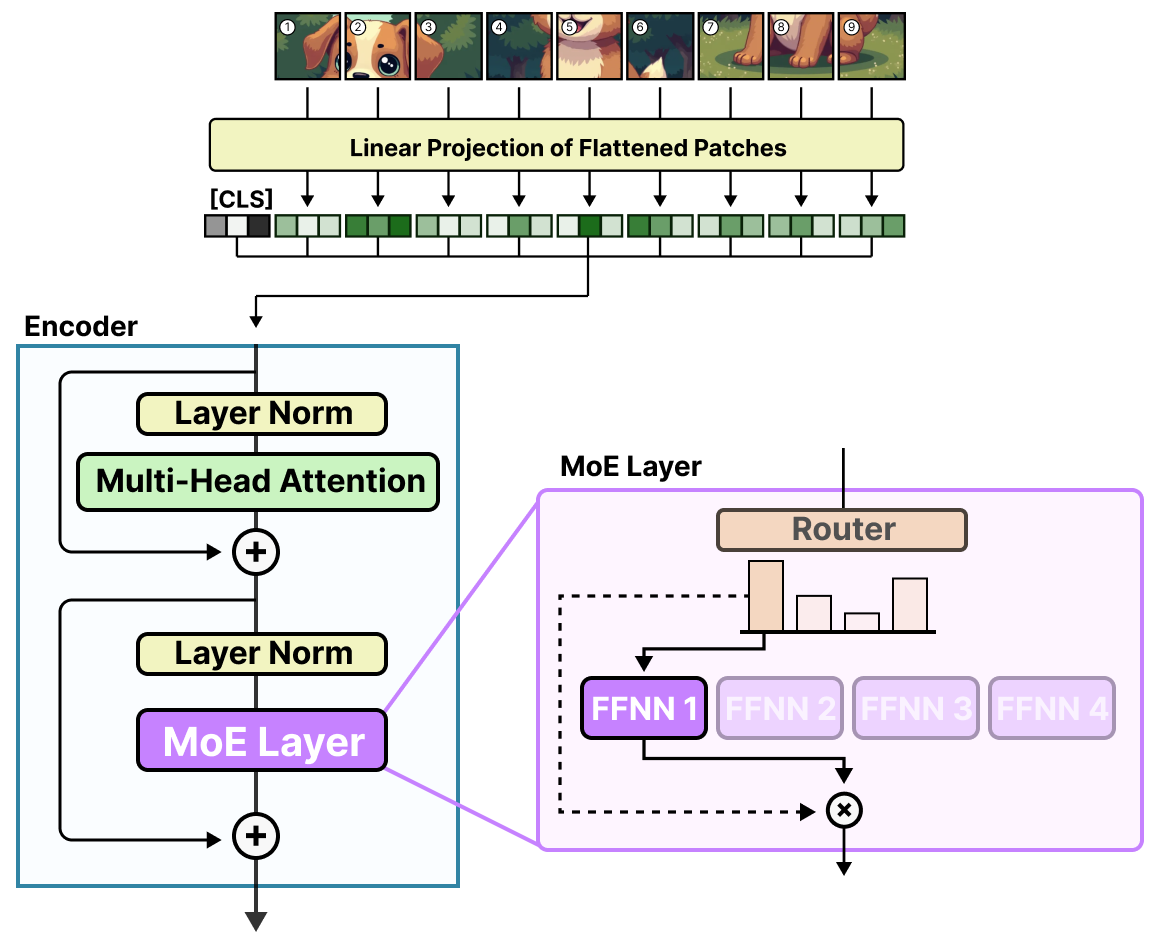
相较于语言模型,ViT 模型规模相对较小,但可以通过添加专家模块进行大规模扩展。
在图像处理时,经常会将其切分为许多 patch,所以每个专家会预设一个较小容量,以此降低硬件限制。但是预设容量太小也容易导致 patch 被丢弃(类似于 token 溢出)。

为了在保持低容量的同时尽可能减少关键 patch 的丢弃,网络会为每个 patch 设置重要性分数,优先处理重要性更高的 patch。这样溢出的 token 通常是不重要的。这种方法被称为批优先路由(Priority Routing)。

因此,即使一部分 token 丢失,重要的 patch 仍能被优先路由到专家。

优先路由机制使模型即使处理较少的 patch,也能聚焦在最重要的信息上。
5.2 从稀疏 MoE 到软 MoE
在 V-MoE 中,优先评分机制有助于区分重要和不重要的 patch。然而,patch 是需要分配到各个专家处理的,没被处理的 patch 中的信息就会丢失。
Soft-MoE 的目的是通过混合 patch,将离散的 patch(token)分配方式转变为更"软"的连续分配方式。
第一步是将输入

接着对路由信息矩阵按列做 softmax 操作,我们就可以更新每个 patch 的 embedding。

更新后的 patch embedding 本质上是所有 patch embedding 的加权平均。

可视化之后可以看到,所有 patch 就好像被"混合"了。这些组合后的 patch 会被发送给每个专家,在生成输出之后,再次与路由矩阵相乘。

路由矩阵既在 token 层面影响输入,也在专家层面影响输出。
因此,我们得到的是"软"的 patch/token,而不是离散的输入。
6. 激活参数 vs 稀疏参数:以 Mixtral 8x7B 为例
MoE 广受关注的一个关键优势是节省计算资源。虽然 MoE 模型需要加载更多的参数(稀疏参数),但在推理时只激活其中一小部分专家(即激活参数)。

换句话说,我们仍然需要将整个模型(包括所有专家)加载到设备上(稀疏参数),但在推理时只需使用其中的一部分(激活参数)。因此,MoE 模型在加载时需要更大的显存(VRAM),但推理速度更快。
我们来看一个例子——Mixtral 8x7B,比较稀疏参数和激活参数的数量。
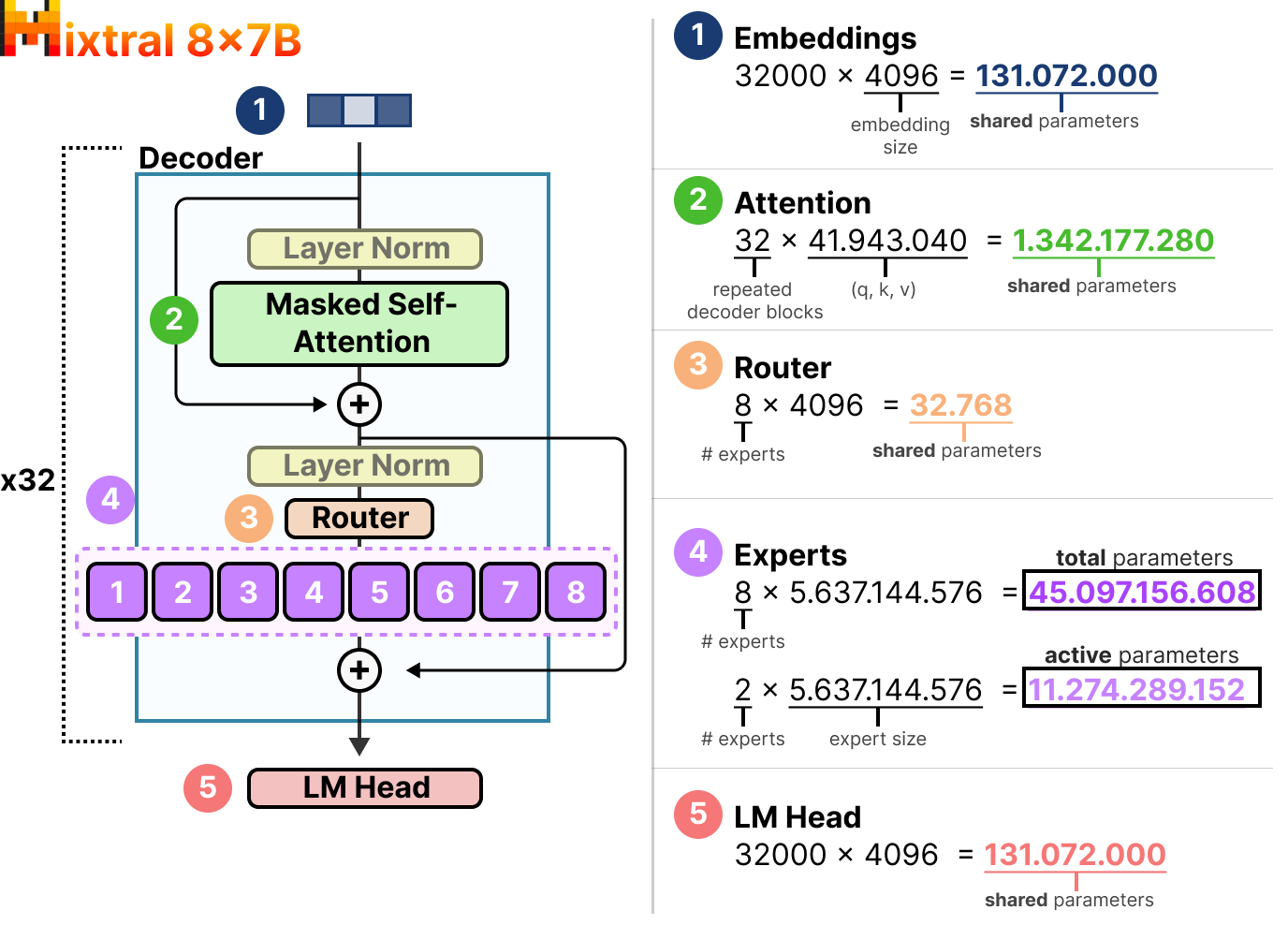
在这个模型中,每个专家的大小是 5.6B,而不是 7B。

需要加载
因此,Mixtral 8x7B 表面上是一个"大模型",但每次推理只用了"小模型"的算力。这正是 MoE 架构兼顾"能力"和"效率"的核心所在。
结论
混合专家模型(MoE)的介绍到这里就告一段落了。希望这篇文章能帮助你更好地理解这项技术的潜力所在。如今几乎所有主流大语言模型中都包含 MoE 变体,MoE 已经不再是实验性的选择,而是将长期存在的关键技术之一。
7. 参考资源
以下是一些深入了解 MoE 的推荐资源:
- MoE 综述论文 (2022) 和 MoE 最新进展综述 (2024) 全面介绍了 MoE 领域的最新创新。
- Expert Choice Routing:一种近年来受到广泛关注的专家选择路由方法。
- Conditional Computation 博客:详细梳理了多篇 MoE 主要论文及其发现。
- MoE 发展时间线:按时间线梳理了 MoE 的发展历程。