PyTorch FSDP 深度解析
ChatGPT 掀起的大模型训练浪潮让不少同学跃跃欲试。在寻找训练 baseline 时,大家肯定发现大模型训练的 codebase 更倾向于使用 DeepSpeed、ColossalAI 等大模型训练框架,而鲜有问津 PyTorch 原生的 FSDP(FullyShardedDataParallel)。这到底是为什么?是 FSDP 不够节省显存?训练速度太慢?还是不好用?请耐心看完这篇文章,相信一定会有所收获。
1. FSDP 的前世今生
FSDP 的实现借鉴了 FairScale。PyTorch 在开发大型特性时,一般会新建一个库做验证性支持并收集用户反馈,FairScale、Dynamo(PyTorch 2.0 的基石)、torchdistx 均是如此。等到特性日益成熟后,就会合入 PyTorch 主库。相比于 PyTorch 官方 Tutorial 对 FSDP 的简短介绍,FairScale 的文档显然做得更好。在正式开始介绍之前,先看一张 FairScale 的架构图,可以据此判断:你的场景是否真的需要 FSDP?
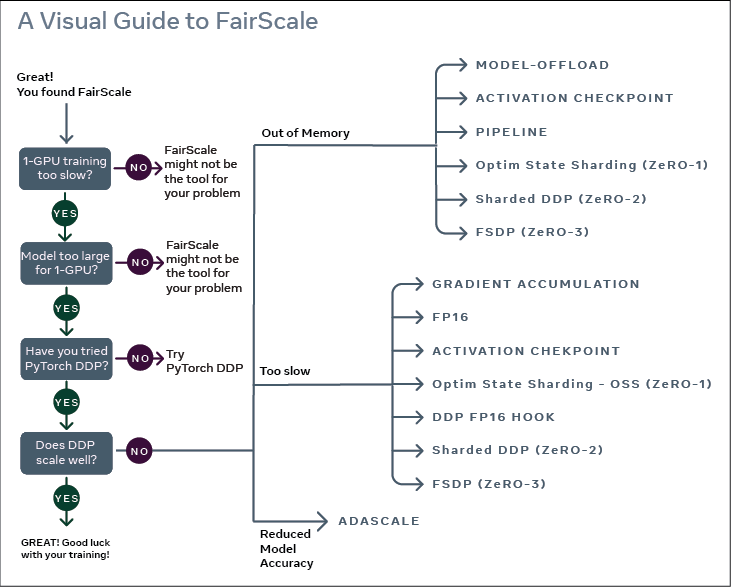
2. ZeRO 系列简介
看过上面这张图的同学肯定会发现,FairScale 把 FSDP 定义为 ZeRO-3。考虑到有些小伙伴可能对 ZeRO 系列的大模型优化策略不是很熟悉,这里做一个简短介绍:
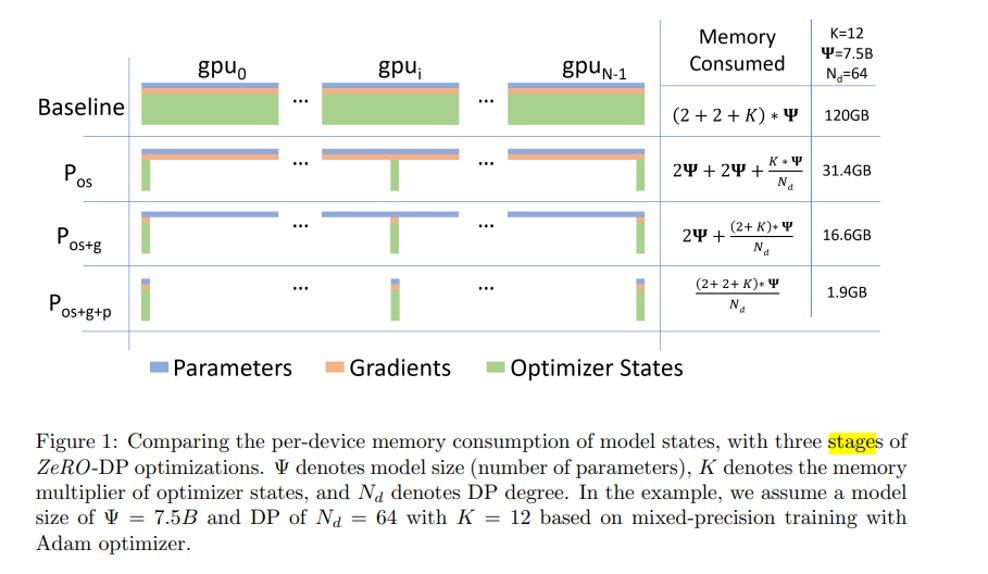
模型训练时,显存占用大体可分为三部分:激活值、模型权重、模型梯度和优化器状态。对于视觉模型而言,显存占比最大的是激活值,因此混合精度训练能够大幅降低激活值的显存占用(fp16)。然而对于大语言模型或多模态模型而言,优化后三者的显存占用则更为重要。
以 PyTorch 为例,当你使用 DistributedDataParallel 时,每个进程都会为模型参数、模型梯度、优化器状态分配内存,并在训练过程中同步更新这些数据。这种做法虽然通过数据并行达到了加速训练的目的,但显存分配策略显然不够高效。既然每个进程的参数都一样,为什么还需要保存完整的参数?ZeRO 的核心思想就是让每个进程只保存参数的一部分,需要时再通过 All-Gather 聚合到各进程。ZeRO 有三个阶段的优化策略:
- ZeRO-1:只把优化器状态进行分片;
- ZeRO-2:对优化器状态 + 梯度进行分片;
- ZeRO-3:对优化器状态 + 梯度 + 模型参数进行分片。
以 7.5B(
fp32 训练: 模型参数量为
,其梯度也为 ,使用 Adam 时优化器状态为 。普通 fp32 训练实际占用的内存为 字节(4 为 fp32 数据占据的字节数)。 fp16 训练: 开启混合精度训练时,为保证参数更新精度,优化器状态需维持 fp32,此外还需额外保存一份 fp32 模型参数拷贝。因此显存占用为:
(模型参数)+ (模型梯度)+ (优化器状态)+ (fp32 参数拷贝,DeepSpeed 实现中存储在优化器) 字节。
带入这样的视角,就能理解为什么上图中 7.5B 的模型显存占用可以高达 120 GB,以及 ZeRO 系列为何如此有效。
3. FSDP = ZeRO-3?
言归正传,FairScale 说 FSDP 相当于 ZeRO-3 的优化,那我们不妨通过一个简单的例子来感受一下(例子中优化器选择 SGD,因为 PyTorch 的 Adam 做了大量优化,实际显存占用会明显高于理论值)。在正式测试之前,先来看单卡 fp32 训练、单卡 fp16 训练、DDP fp16 训练的测试:
3.1 单卡 fp16 + fp32
import torch
import torch.nn as nn
from torch.cuda import max_memory_allocated
from torch.cuda.amp import autocast
class Layer(nn.Module):
def __init__(self):
super().__init__()
self.linear = nn.Sequential(
*(nn.Linear(10000, 10000) for _ in range(10))
)
def forward(self, x):
return self.linear(x)
def test_fp32():
model = Layer().cuda()
optimizer = torch.optim.SGD(model.parameters(), lr=0.1, momentum=0.9)
data = torch.ones(10000).cuda()
for _ in range(10):
optimizer.zero_grad()
output = model(data)
loss = output.sum()
loss.backward()
optimizer.step()
memory = max_memory_allocated()
print(f"step memory allocate: {memory / 1e9:.3f}G")
def test_fp16():
torch.cuda.init()
model = Layer().cuda()
optimizer = torch.optim.SGD(model.parameters(), lr=0.1, momentum=0.9)
data = torch.ones(10000).cuda()
for _ in range(10):
with autocast(device_type="cuda"):
optimizer.zero_grad()
output = model(data)
loss = output.sum()
loss.backward()
optimizer.step()
memory = max_memory_allocated()
print(f"memory allocated: {memory / 1e9:.3f}G")跑过代码后,显存占用如下:
- fp32:12.035 G
- fp16:14.035 G
AMP 显存占用竟然多了 2 G?这是怎么算的?这里就不得不提到 AMP 的实现方式了。PyTorch 的 AMP 不会改变模型权重的类型,仍然以 fp32 存储。它选择在白名单算子的 forward/backward 前后,把 fp32 的 weights 转换成 fp16,以计算出 fp16 的激活值和梯度。其中 fp16 的梯度还会进一步转换成 fp32,以保证参数更新精度。
既然权重和梯度仍然保留 fp32,优化器状态也理应保持不变,那为什么还多了 2 G?原因在于 forward 和 backward 时这份 fp16 的权重被缓存了,这部分实现在 AMP 的 C++ 代码里。缓存的 fp16 权重就是多出 2 G 的源头。
要想节省这部分显存,需要给 autocast 传入 cache_enabled=False:
def test_fp16():
torch.cuda.init()
model = Layer().cuda()
optimizer = torch.optim.SGD(model.parameters(), lr=0.1, momentum=0.9)
data = torch.ones(10000).cuda()
for _ in range(10):
with autocast(device_type="cuda", cache_enabled=False):
optimizer.zero_grad()
output = model(data)
loss = output.sum()
loss.backward()
optimizer.step()
memory = max_memory_allocated()
print(f"memory allocated: {memory / 1e9:.3f}G")这样一来,显存消耗为 12.235 G,基本和 fp32 一致,符合预期。
3.2 DDP 训练
DDP 只是在每个进程创建模型并更新模型而已,显存占用应该还是 12 G 吧?
import torch
import torch.distributed as dist
from torch.cuda import max_memory_allocated
from torch.cuda.amp import autocast
from torch.nn.parallel import DistributedDataParallel as DDP
def _test_ddp_fp16():
rank = dist.get_rank()
model = DDP(Layer().cuda())
optimizer = torch.optim.SGD(model.parameters(), lr=0.1, momentum=0.9)
data = torch.ones(10000).cuda()
for _ in range(10):
with autocast(device_type="cuda", cache_enabled=False):
optimizer.zero_grad()
output = model(data)
loss = output.sum()
loss.backward()
optimizer.step()
memory = max_memory_allocated()
if rank == 0:
print(f"memory allocated: {memory / 1e9:.3f}G")然而结果是:16.036 G。
原理也很简单:DDP 执行 gradient computation 和 gradient synchronization 时需要一个桶(bucket,具体介绍见之前的 DDP 介绍)。桶会保留一份 gradient 的拷贝,因此会额外消耗 4 G 左右的显存。
3.3 FSDP 训练
我们在使用 FSDP 时,需要通过配置 auto_wrap_policy 参数来选择模型分片策略,否则显存优化只能达到 ZeRO-1 的水准。如何配置 auto_wrap_policy 以及对应的原理会在后面章节具体介绍。
import inspect
from functools import partial
import torch
import torch.distributed as dist
import torch.nn as nn
from torch.cuda import max_memory_allocated
from torch.distributed.fsdp import FullyShardedDataParallel
from torch.distributed.fsdp.wrap import _module_wrap_policy
def _test_fsdp_fp16():
rank = dist.get_rank()
fsdp_model = FullyShardedDataParallel(
module=Layer(),
device_id=rank,
auto_wrap_policy=partial(
_module_wrap_policy,
module_classes=nn.Linear,
),
)
optimizer = torch.optim.SGD(fsdp_model.parameters(), lr=0.1, momentum=0.9)
data = torch.ones(10000).cuda()
for _ in range(10):
optimizer.zero_grad()
output = fsdp_model(data)
loss = output.sum()
loss.backward()
optimizer.step()
memory = max_memory_allocated()
if rank == 0:
print(f"step memory allocate: {memory / 1e9:.3f}G")
torch.cuda.reset_max_memory_allocated()结果是 1.524 G,显存占用基本等价于 ZeRO-3 的优化效果。
之所以做这些内存占用分析,是希望大家从 DDP 切换到 FSDP 时,能够理性看待显存优化的效果。
4. FSDP 分片策略
上一章我们提到,需要通过 auto_wrap_policy 来指定模型分片策略,那么这个参数是如何起作用的呢?以及为什么不配置这个参数,其优化效果只能达到 ZeRO-1。
与 DistributedDataParallel 类似,FSDP 也是通过一个 model wrapper:FullyShardedDataParallel 来实现参数切分的逻辑。被 wrap 的 model 会成为 root FSDP module,而 root FSDP module 在构建时,会根据用户定义的 auto_wrap_policy 递归地把 submodule wrap 成 child FSDP module:

以官方实现的 _module_wrap_policy 为例,其中关键参数 module_classes 用于说明哪个类型的 submodule 应该被 wrap 成 child FSDP module:
from typing import Set, Type
import inspect
import torch.nn as nn
def _module_wrap_policy(
module: nn.Module,
recurse: bool,
nonwrapped_numel: int,
module_classes: Set[Type[nn.Module]],
) -> bool:
"""
该 auto wrap policy 将 ``module_classes`` 中任意类型的 module 都 wrap 为独立的 FSDP 实例。
给定的 root module 一定会被 wrap。由于 wrap 是自底向上进行的,每个 FSDP 实例管理其子树中
尚未被 child FSDP 实例管理的参数。
Args:
module (nn.Module): 当前正在考虑的 module。
recurse (bool): 如果为 ``False``,则本函数必须决定是否将 ``module`` wrap 为 FSDP 实例;
如果为 ``True``,则函数仍在 DFS 递归向下遍历。
nonwrapped_numel (int): 尚未被 wrap 的参数数量。
module_classes (Set[Type[nn.Module]]): 需要被 wrap 为 FSDP 实例的 module 类型集合。
Returns:
当 ``recurse=True`` 时返回 ``True``;当 ``recurse=False`` 时返回是否 wrap 当前 ``module``。
"""
if recurse:
return True # 始终递归
if inspect.isclass(module_classes):
module_classes = (module_classes,)
return isinstance(module, tuple(module_classes))在上一章中我们将其指定为 nn.Linear,也就是说每个 nn.Linear 都会被 wrap 成 child FSDP module。所有的 FSDP module 在 forward 过程中都会触发参数的 unshard(All-Gather)和 shard。
root FSDP module 的 forward:会在 pre-forward 阶段 All-Gather 不同进程的参数,并注册一些 pre-backward-hook 和 post-backward-hook。然后在 post-forward 阶段释放不属于当前 rank 的参数。
其中 pre-backward-hook 会在执行 backward 之前再次 gather 参数,而 post-backward-hook 负责实现梯度的 Reduce-Scatter,即梯度同步 + 梯度分发。需要注意的是,FSDP module forward 时不会进一步 gather child FSDP module 的 parameter。
相比于 child FSDP module,root FSDP module 的 forward 还会额外做一些 CUDA stream 初始化等工作,这里不做额外展开。

child FSDP module 的 forward:主体逻辑基本同 root FSDP module。
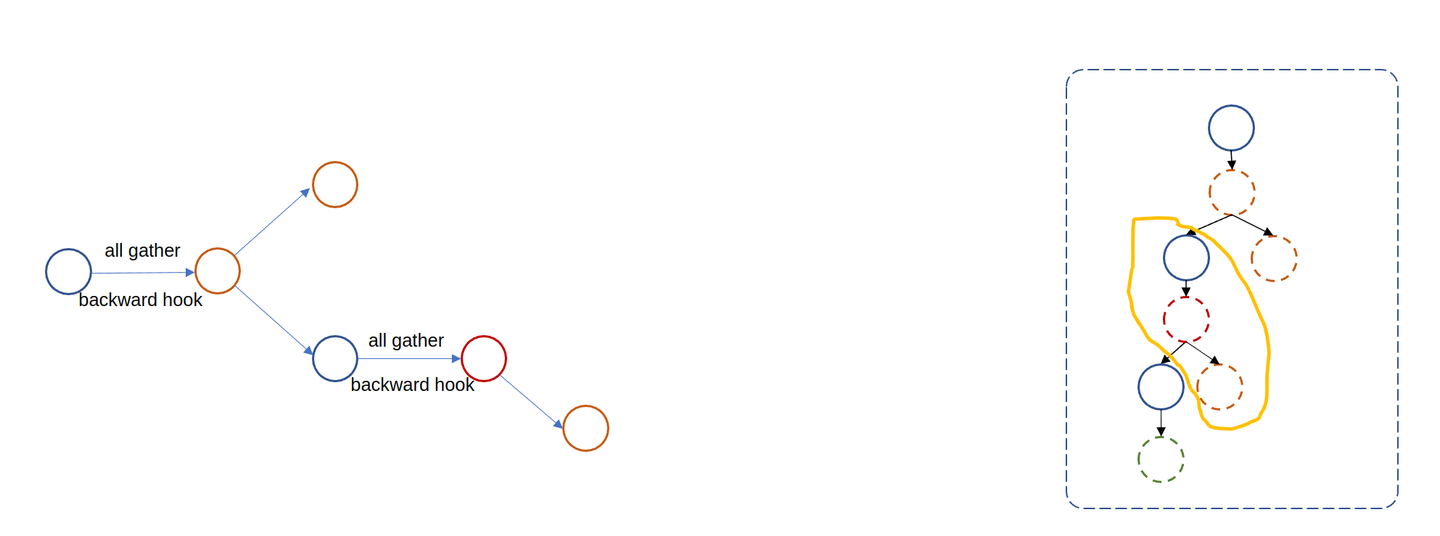
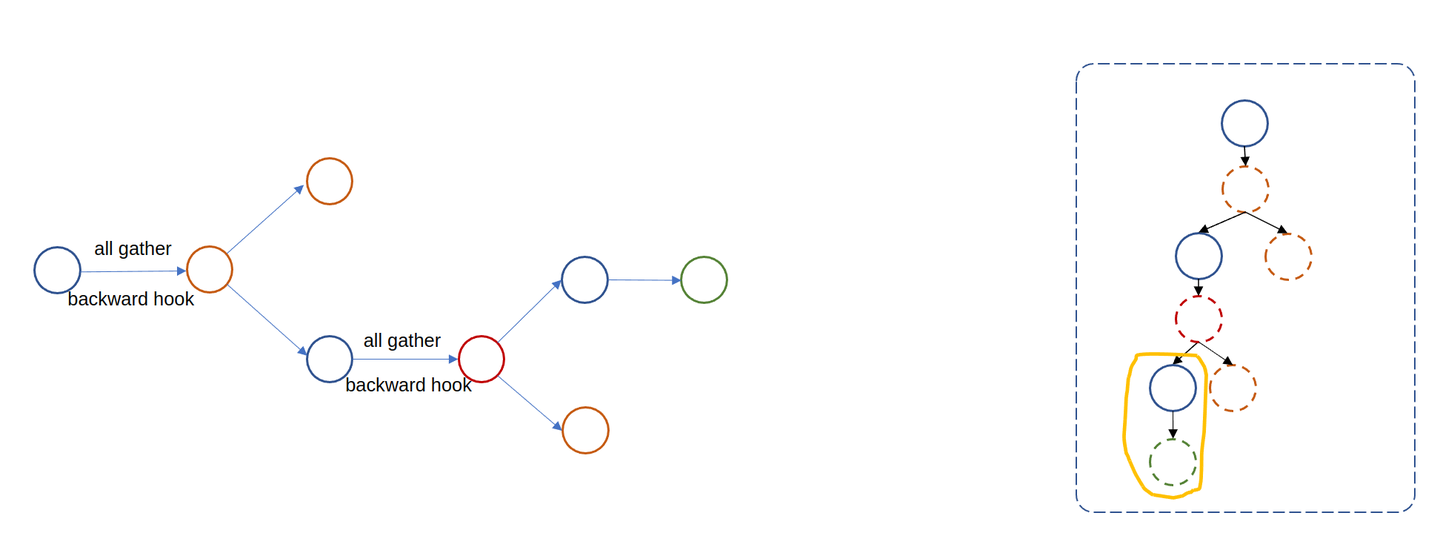
可见每次 FSDP module 只会 gather 部分参数,这符合我们的预期。那如果我们不设置 auto_wrap_policy 又会如何?那就是没有 child FSDP module:
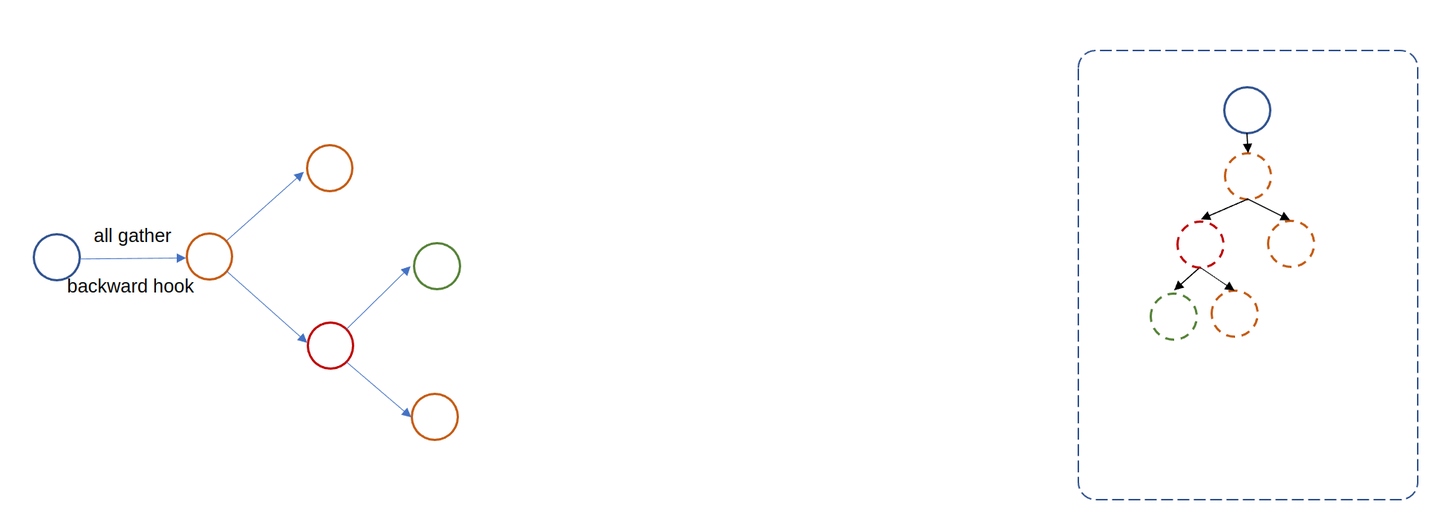
root FSDP module 在 forward 阶段会直接 gather 所有参数,也就意味着无法做到 ZeRO-3 中通过对参数分片来节省显存。但是 ZeRO-1 和 ZeRO-2 里对梯度和优化器状态的分片仍然可以做到。理由是 forward 阶段仍然会注册 post-backward-hook,因此 gradient Reduce-Scatter 的逻辑仍然会起作用。构建 optimizer 时传入的是 root FSDP module 的 parameters,因此优化器会直接更新分片后的参数、记录分片后参数的状态,所以优化器状态的分片优化也是有效的。
auto_wrap_policy 需要遵循一定的接口规范,即接受以下几个参数:
- module:递归遍历 submodule 时访问到的 module。
- recurse:判断一个 submodule 为 child FSDP module 后,是否再进一步递归判断该 submodule 的 submodule 需要被 wrap 成 child FSDP module。
- nonwrapped_numel:这个参数的含义是当前模块不需要被分片的参数数量。一般来说包含两部分,即已经被分片的参数和用户指定的需要被忽略的参数(
ignored_params)。基于这个参数可以实现 size-based wrap policy,例如官方实现的size_based_auto_wrap_policy。
FSDP 把 auto_wrap_policy 这个参数的配置权交给用户,扩展性固然提升,但也无形中增加了学习成本。比如 auto_wrap_policy 会起什么作用,它的几个入参的含义是什么,刚使用 FSDP 的用户难免会为此感到困惑。
然而如果 FSDP 的使用成本仅限于此,相信大家还是愿意去学习和使用的。然而一些隐性的约定和一些奇奇怪怪的报错,就非常劝退了。
5. FSDP 试错的血与泪
5.1 替换 submodule 的风险
上一章我们提到,FSDP 会把 submodule 替换成 wrap 之后的 child FSDP module。看到这你或许会奇怪,如果 parent module 访问了 submodule 的一些属性或者方法,此时 submodule 被替换成 FSDP module,难道不会触发 AttributeError 吗?对于这种情况,FSDP 机智地重载了 __getattr__ 方法:
def __getattr__(self, name: str):
"""Forward missing attributes to the wrapped module."""
try:
return super().__getattr__(name) # defer to nn.Module's logic
except AttributeError:
return getattr(self._fsdp_wrapped_module, name)这样对于没有定义的属性,它就会从 submodule 里去找。然而这样做仍然会有风险:
- 如果你访问的属性恰巧和 child FSDP module 本身的属性重名,就会出现拿错属性的情况。
- 如果你直接访问了 submodule 的 parameter,并对其做了一些操作。由于 parameter 是在 forward 阶段才会被 gather,那么此时你直接获取的是一个分片后的参数,大概率也会报错。
- 如果你恰巧没有直接调用 child FSDP module 的
__call__方法,例如这种情况:
import torch.nn as nn
class Layer(nn.Module):
def __init__(self):
super().__init__()
self.processor = nn.Linear(1, 1)
self.linear1 = nn.Linear(1, 1)
self.linear2 = nn.Linear(1, 1)
def forward(self, x):
return self.linear1(x) + self.linear2(x)
class ToyModel(nn.Module):
def __init__(self):
super().__init__()
self.linear = nn.Linear(1, 1)
self.layer = Layer() # 会被 auto wrap policy 指定为 child FSDP module
def forward(self, x):
y = self.linear(self.layer.processor(x))
return self.layer(y)假设 Layer 被 wrap 成了 FSDP module,由于 ToyModel.forward 里直接调用了 self.layer.processor 的 forward,此时由于 layer 的 forward 没有被触发,layer.processor 里的参数仍然处于分片状态,也会报错。
又例如这种情况:
class A:
def loss(self, inputs, data_samples):
feats = self.extract_feat(inputs)
return self.head.loss(feats, data_samples)
class B:
def loss(self, feats, data_samples, **kwargs):
cls_score = self(feats) # 没有走 FSDP 的 forward
losses = self._get_loss(cls_score, data_samples, **kwargs)
return losses假如 class A 中的 self.head 类型为 class B,且被 wrap 成了 child FSDP module。那么在执行 self.head.loss 时,会通过 FSDP 的 __getattr__ 方法直接找到 class B 的 loss,此时的局部变量 self 已经是 class B 实例而并非 FSDP wrapper,因此在执行 self(feats) 时不会进入 FSDP 的 forward 触发参数 All-Gather,进一步引发错误。
5.2 多参数组的优化器
PyTorch 的 optimizer 支持对 model 里的不同参数设置不同的学习率、动量等超参数。设置过程大概类似这样:
param_groups = []
for module in model.modules():
if isinstance(module, nn.BatchNorm2d):
param_groups.append({"params": [module.weight], "lr": 0.01})
param_groups.append({"params": [module.bias], "lr": 0.1})
else:
...
optimizer = torch.optim.SGD(param_groups, lr=0.1)然而问题在于,在 PyTorch 2.0 之前,一旦 root FSDP module、child FSDP module 构建完成,它会删除原有的参数,例如 bn.weight、bn.bias,转而将 FSDP module 下所有未被切片的参数转换成一个大的 flatten parameter。举个例子,如果上一章的 example 里没有指定 auto_wrap_policy,那么就只会保留最外层的 root FSDP module。那么所有 linear 层的 parameters 都会汇总成一个大的 flatten parameter,放在 root_fsdp_module 下:
rank = dist.get_rank()
fsdp_model = FullyShardedDataParallel(
module=Layer(),
device_id=rank,
# auto_wrap_policy=partial(
# _module_wrap_policy,
# module_classes=nn.Linear),
)
print(list(fsdp_model.parameters()))此时每个 rank 只会打印出一个参数:
[Parameter containing:
Parameter(FlatParameter([-4.6519e-05, -6.2861e-03, 3.9519e-03, ..., -3.2763e-03,
7.1111e-04, -8.2136e-03], device='cuda:3', requires_grad=True))]因此在 PyTorch 2.0 之前,一旦使用了 FSDP,就很难对每个参数设置不同的学习率了,因为 FSDP wrap 之后多个参数会合并成一个参数。之后的 gradient 分片、参数更新也都是基于 flatten tensor 实现的。
由于参数更新也是基于 flatten tensor 实现的,因此 FSDP 要求每个 FSDP module 下的参数 dtype 和 requires_grad 属性统一,否则无法 concat 成一个大的 flatten tensor。
PyTorch 2.0 为 FSDP 添加了 use_orig_params 参数。开启该参数后,FSDP wrap 过程中不会删除原有的参数,而会让原有参数的内存指向 flatten params 的某个区域。这是一个很棒的更新,在不引入额外显存消耗的情况下,让用户仍然能够访问到分片之前的参数,并为其设置不同的优化器超参。引入这个参数后,按理说 FSDP module 下所有参数 requires_grad 属性统一的限制应该也解除了,但不幸的是 PyTorch 2.0 并没有调整这部分逻辑。不过在主分支上已经修复了这个问题,相信即将到来的 PyTorch 2.1 能够解决这个痛点。
5.3 FSDP 的接口稳定性
尽管早在 PyTorch 1.11,FSDP 就已经是一个 beta 版本的特性了,然而时至今日,FSDP 模块仍然处于高速迭代的状态。FSDP 的开发者也于 2023 年 2 月发起了一个 discussion,介绍了一些设计理念以及内部的重构。
除此之外,FSDP 的外部接口更新得也比较快。打开 PyTorch FSDP 的 API 文档,你会发现不少接口都贴上了 deprecated 标签。不过总的来说,新接口确实比老接口更易用、灵活很多,MMEngine 这次集成 FSDP 也都是基于新接口开发的。
总结
FSDP 在显存节省方面,其效果确实与 ZeRO-3 等价,但需要注意的是,在开启混合精度训练(autocast)的情况下,需要把 cache_enabled 设置为 False。
FSDP 在易用性方面上手成本比较高。用户需要理解 FSDP wrap module 的逻辑、auto_wrap_policy 的作用以及一些限制。在不足够熟悉 FSDP 本身的逻辑和限制、不足够了解 model 结构的情况下,容易出现报错,且 error message 和 error 真正的诱因没有太大关联,难以 debug。
PyTorch 2.0 通过 use_orig_params 参数大大提升了 FSDP 的易用性,但是对 requires_grad 属性统一的限制仍然存在。要解决这个问题可以坐等 PyTorch 2.1 更新,并指定 use_orig_params=True。但如果想要临时解决,需要在 auto_wrap_policy 做一些改动,由于是基于 FSDP 内部协议做的修改,可能不是很稳定,这里就不做赘述。
总的来说,FSDP 在易用性方面确实差强人意,但在灵活性方面留给了用户更大的操作空间。相信随着 PyTorch 的不断迭代,FSDP 也会逐渐变得和 DDP 一样好用。MMEngine 也会紧跟 FSDP 更新的动向,在保持灵活性的基础上,尽可能地降低大家的使用门槛,总结出一套简单、易配置的最佳实践。