ZeRO 技术原理:进阶与 Offload
前言
目前训练超大规模语言模型主要有两条技术路线:TPU + XLA + TensorFlow/JAX 和 GPU + PyTorch + Megatron-LM + DeepSpeed。前者由 Google 主导,由于 TPU 和自家云平台 GCP 深度绑定,外部开发者难以直接使用;后者背后则有 NVIDIA、Meta、Microsoft 等大厂加持,社区氛围活跃,也更受开发者欢迎。
上面提到的 DeepSpeed 的核心是 ZeRO(Zero Redundancy Optimizer)。简单来说,它是一种显存优化的数据并行(data parallelism,DP)方案。而“优化”这个话题永无止境:在过去两年里,DeepSpeed 团队发表了三篇 ZeRO 相关的论文,提出了去除冗余参数、引入 CPU 和内存、引入 NVMe 等方法,始终围绕着一个目标——将显存优化进行到底。
1. ZeRO:一种去除冗余的数据并行方案
ZeRO: Memory Optimizations Toward Training Trillion Parameter Models 发表于 SC 20。
ZeRO 是微软开发的一个可以高效利用显存的优化器,它会将模型状态(优化器状态、梯度和模型参数)分布在多个并行 GPU 之上,目的是在不使用模型并行的情况下训练数十亿参数规模的模型。
ZeRO 是 ZeRO-DP 和 ZeRO-R 两种方法的组合。ZeRO-DP 是一种增强的数据并行机制,它使用动态通信策略将优化器状态、梯度和参数进行分区,以最小化通信量并避免模型状态的冗余。ZeRO-R 则使用分区激活重计算、恒定大小缓冲区以及动态内存碎片整理机制来优化剩余状态的内存消耗。
1.1 背景知识
模型训练中的显存占用主要包括:模型参数、模型梯度、优化器状态、运算中间变量。以下图为例,训练过程中的显存占用包括一份模型参数以及对应的一份梯度;常用的 Adam 会保留两倍参数量的优化器参数,除此之外还有一些运算的中间变量。

1.1.1 Adam 优化器算法
Adam 算法的关键组成部分之一是:它使用指数加权移动平均值来估算梯度的动量和二次矩。

- 如果优化器是 SGD,除了保存模型参数
之外还要保存对应的梯度 ,因此显存占用等于参数占用的显存 × 2。 - 如果是带 Momentum 的 SGD,除了保存
和对应的梯度 ,还需要保存动量,因此显存占用 × 3。 - 如果是 Adam 优化器,动量占用的显存更多,显存占用 × 4。
根据上述分析,对于一个模型参数约 20 GB 的大模型,训练过程中需要占用的显存就会超过 80 GB。在每一张显卡中都完整地维护这些内容,显存远远不够。这就需要采用相关分布式训练技术来进行显存优化。
为解决这一关键问题,DeepSpeed 采用了多种技术手段:通过数据并行降低运算中间变量显存占比、增大吞吐量;通过 ZeRO 降低模型参数、模型梯度、优化器状态的显存占比;通过 Optimizer Offload 将优化器状态卸载到内存上;通过 Checkpointing 和算子融合避免存储运算的中间变量;最后使用通信计算重叠进一步降低整套系统的时间开销。
综合使用这些技术,DeepSpeed 可以实现单张消费级显卡全参数微调 BERT-Large,8 台 A100 小集群训练 GPT-3。在超大规模模型训练场景下,与其他框架相比最多可节省 90% 的计算资源成本。
分布式训练的核心是“切割”:将数据、参数等诸多要素切割到不同计算节点上进行运算。有切割就有合并,不同节点之间会频繁通信以同步及汇总计算结果。
这里简单介绍 5 个基本通信算子,它们是分布式训练框架的重要基础(以四张显卡为例,由 rank 0 到 rank 3 表示):
1.1.2 Broadcast
张量位于某张显卡中,广播后,每张显卡都会获得一个同样的张量。
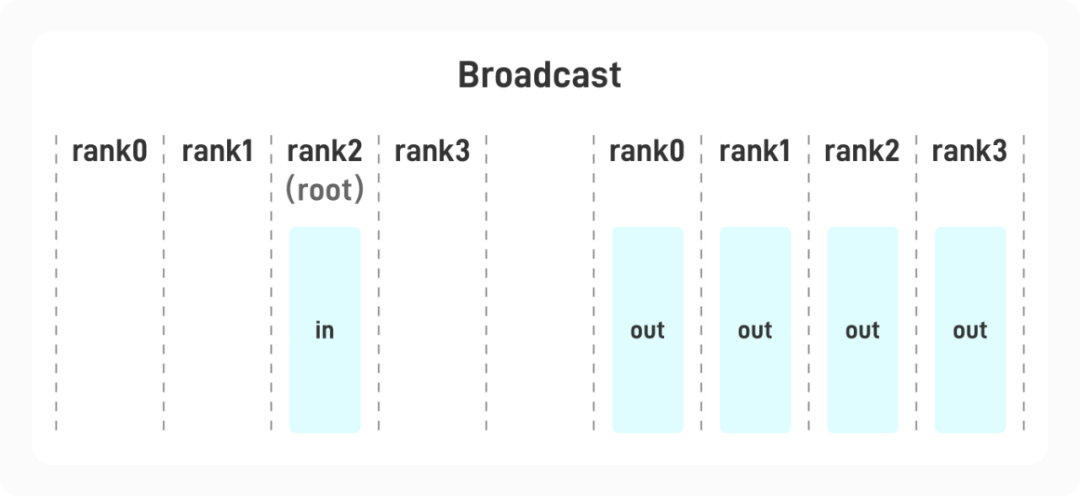
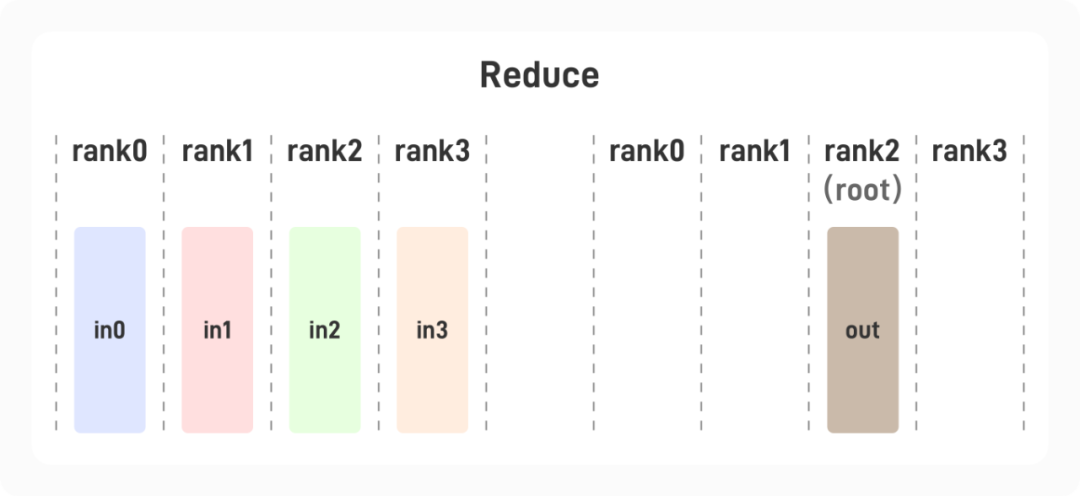
1.1.3 Reduce
每张显卡中存有一个张量,将这些张量进行如求和、取 max 等计算后,其结果置于指定的某张显卡上。
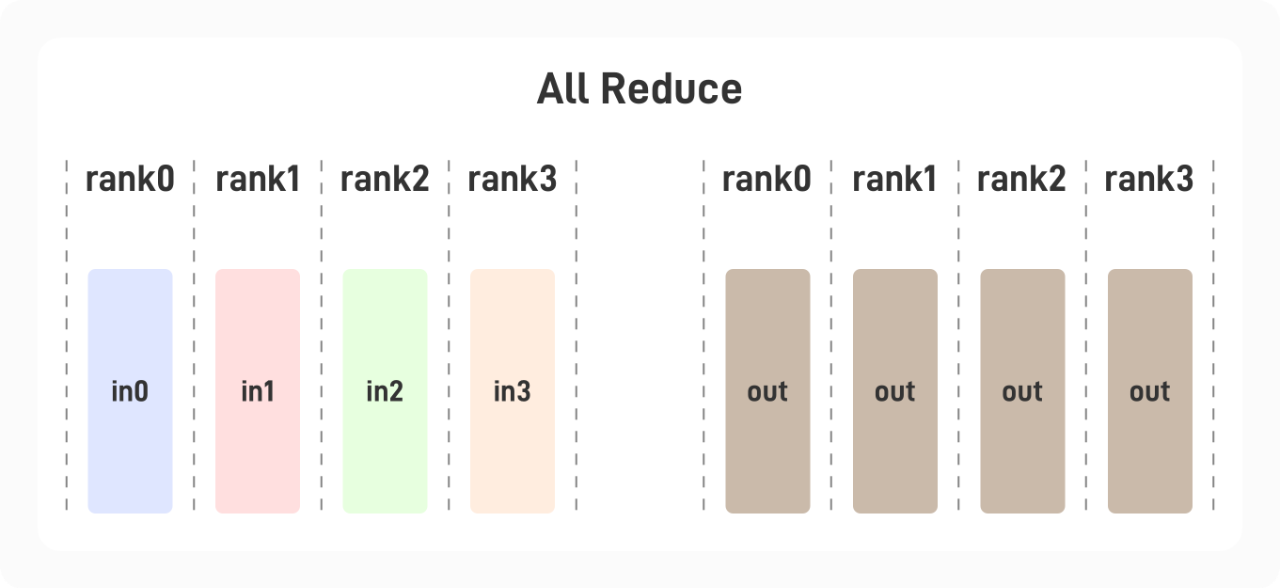
1.1.4 All-Reduce
每张显卡中存有一个张量,使用它们进行相关计算后的结果被置于所有显卡上,各张显卡上得到的结果相同。
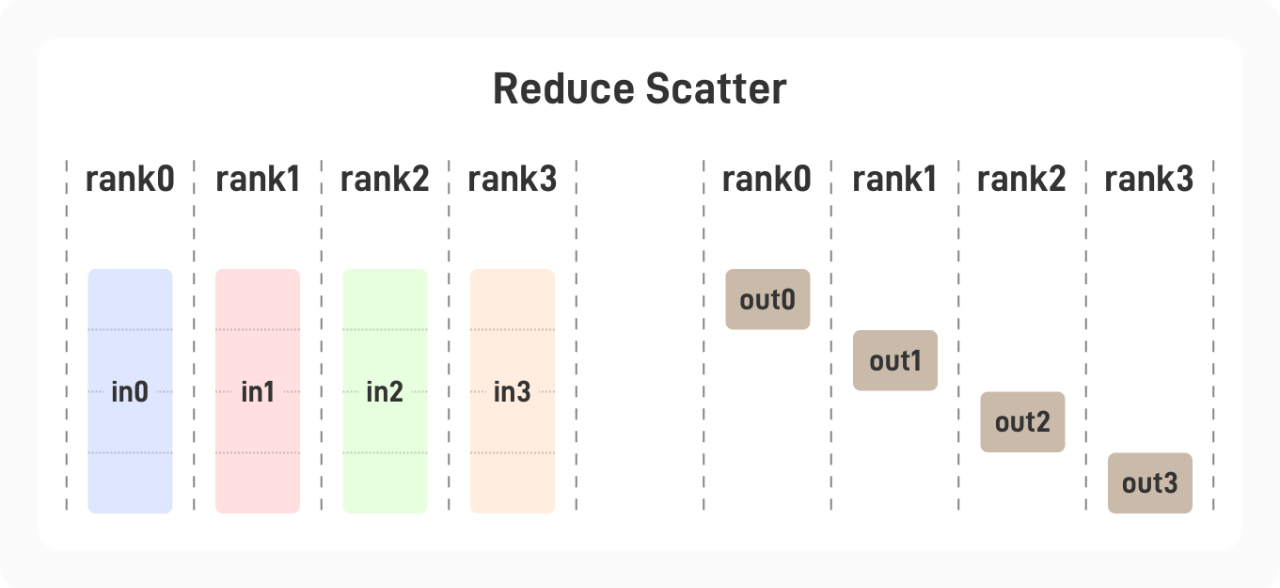
1.1.5 Reduce-Scatter
每张显卡中存有一个大小为
1.1.6 All-Gather
每张显卡中存有一个大小为
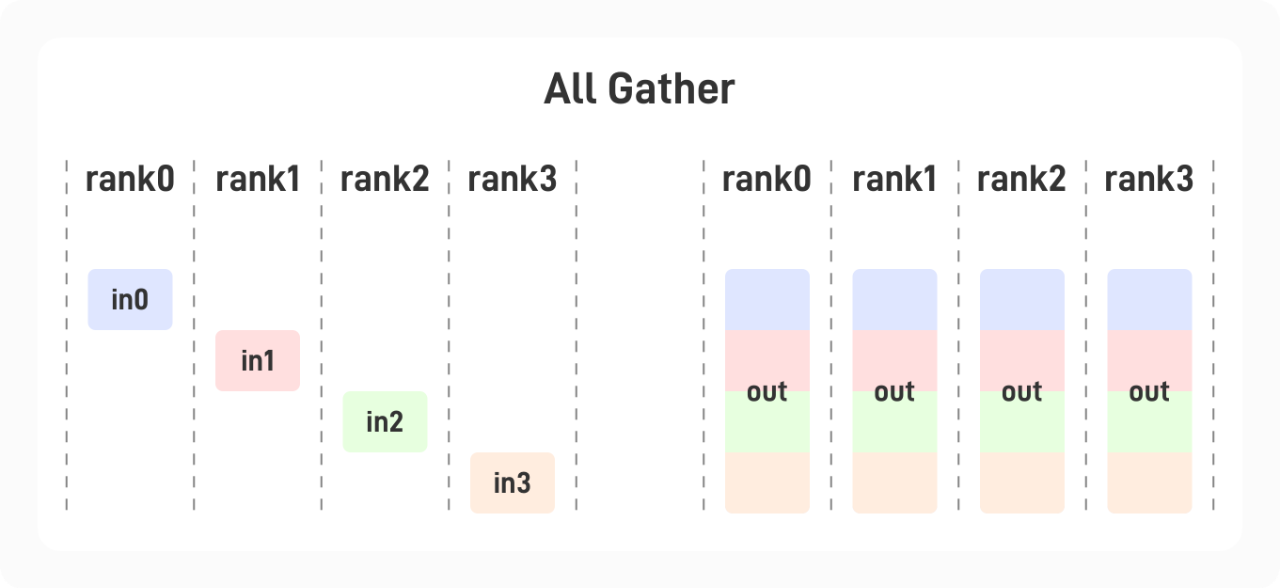
1.2 分布式训练
一种典型的分布式训练方法是使用数据并行。然而对于大模型来说,仅通过数据并行进行显存优化是远远不够的,需要更进一步地进行切割。进一步优化的技术主要来自两大路线:在算子层面进行切割的模型并行、流水线并行技术,以及在显存层面进行切割的 ZeRO 技术。在 DeepSpeed 中,采用了数据并行和 ZeRO 技术来进行模型的分布式训练,并将陆续支持模型并行与流水线并行。
1.2.1 数据并行
数据并行通过减小每张显卡上需要处理的 batch 大小来减少模型的运行中间变量。具体来说,假设有

采用数据并行策略,原模型训练需要的运算中间变量被划分到不同显卡中。图中以八卡并行为例,后面各图也采用相同的设定。
1.2.2 模型并行
模型并行技术尝试将模型计算进行切割。以全连接层为例,通过将参数矩阵分解为

采用模型并行策略,模型参数被划分到不同的显卡中。
与模型并行类似的一种解决思路是流水线并行,也是对训练计算进行切分。相比于模型并行中对 Transformer 模型进行纵向的计算切分,流水线并行将不同层的 Transformer block 计算划分到不同的显卡上。
1.2.3 分析
数据并行由于简单易实现,应用最为广泛。当然这不表示它没有“缺点”——每张卡都存储一个模型,此时显存就成了模型规模的天花板。如果我们能减少模型训练过程中的显存占用,不就可以训练更大的模型了?
一个简单的观察是:如果有 2 张卡,系统中就存在 2 份模型参数;如果有
1.3 ZeRO
在实际训练中,优化器(如 Adam)状态占用的显存要比参数和梯度二者加起来还要多。因此 ZeRO(Zero Redundancy Optimizer,零冗余优化器)技术首次提出对优化器状态进行切分,每张显卡上只负责优化器状态对应的部分参数的更新。
训练策略上,ZeRO 基于数据并行,不同的数据被划分到不同的显卡上进行计算。根据对优化器状态、梯度、参数划分程度的不同,ZeRO 包含 ZeRO-1/2/3 三个层次。
1.3.1 ZeRO-1
因为 ZeRO 基于数据并行,首先需要通过 All-Gather 操作获取完整的模型参数更新结果,随后每张显卡根据自己的数据和模型参数完成对应的前向传播和反向传播。在整个过程中,梯度和参数均完整地保留在每张卡上,随后对梯度进行 Reduce-Scatter,每张卡根据自己所划分的优化器状态和梯度来计算对应部分的模型参数。

基于 ZeRO-1 和数据并行,优化器状态和运算中间变量被划分到不同的显卡中。
1.3.2 ZeRO-2
ZeRO-2 在 ZeRO-1 的基础上进一步对梯度进行划分。由于在反向传播过程中,不需要始终保留完整的梯度——计算当前层梯度时,只需要后一层输入的梯度。因此在反向传播过程中,对于不参与后续反向传播计算的梯度,可以立即 Reduce-Scatter 到多块卡上,这样在训练过程中,梯度在每块卡上的显存占用就变为原先的
反向传播结束后,每块卡再根据部分的梯度和优化器状态计算得到更新后的模型参数,最后将更新后的参数使用 All-Gather 同步到其他显卡上。

基于 ZeRO-2 和数据并行,梯度、优化器状态和运算中间变量被划分到不同的显卡中。
1.3.3 ZeRO-3
ZeRO-3 技术则更进一步将模型参数部分进行切分。由于每张显卡只有一部分优化器状态,只更新一部分参数,一个很直观的思路就是每张显卡上只维护优化器需要更新的那一部分参数。然而,在模型的计算过程中,仍然需要完整的模型参数。
因此在 ZeRO-3 中,模型中的每个模块在计算之前都需要通过一次 All-Gather 操作将参数恢复完整,并在前向计算结束后再将模型参数释放掉。进行反向传播时,再重新使用 All-Gather 获取参数计算梯度,并使用 Reduce-Scatter 划分梯度,如下图所示。
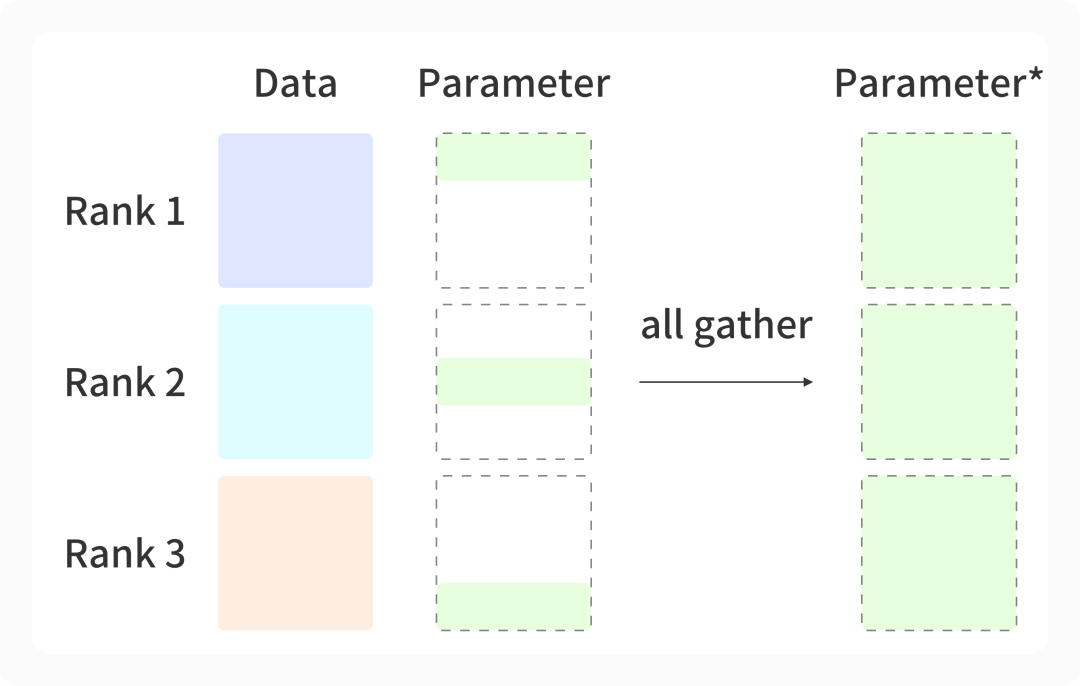
通过使用 ZeRO-3 优化,训练相关的所有信息均被切碎分散到不同的显卡上,让每张显卡上的显存占用都被降低到极致,使得每张显卡上可以容下更大的 batch size,更充分地利用计算核心,带来更大的模型吞吐,同时将训练模型所需的显卡数量降至最低。

基于 ZeRO-3 和数据并行,参数、梯度、优化器状态和运算中间变量被划分到不同的显卡中。
不过在 ZeRO 的原论文中指出,ZeRO-3 增加了额外的一次参数通信时间(即反向传播时的 All-Gather),因此会引入额外的通信开销,在部分场景下性能不及 ZeRO-2 和模型并行。为了减少额外通信量带来的效率损失,还额外引入了通信计算重叠的策略,这将在后面介绍。实验结果表明,ZeRO-3 在 NVLink + IB 的环境下训练超大规模模型,较联合使用 ZeRO-2 和模型并行的方案会带来更大的计算吞吐量提升。
1.4 显存分析
混合精度训练(mixed precision training)和 Adam 优化器基本上已经是训练语言模型的标配,我们先来简单回顾相关概念。
Adam 在 SGD 基础上,为每个参数梯度增加了一阶动量(momentum)和二阶动量(variance)。
混合精度训练,字如其名,同时存在 fp16 和 fp32 两种格式的数值。其中模型参数、模型梯度都是 fp16,此外还有 fp32 的模型参数。如果优化器是 Adam,则还有 fp32 的 momentum 和 variance。
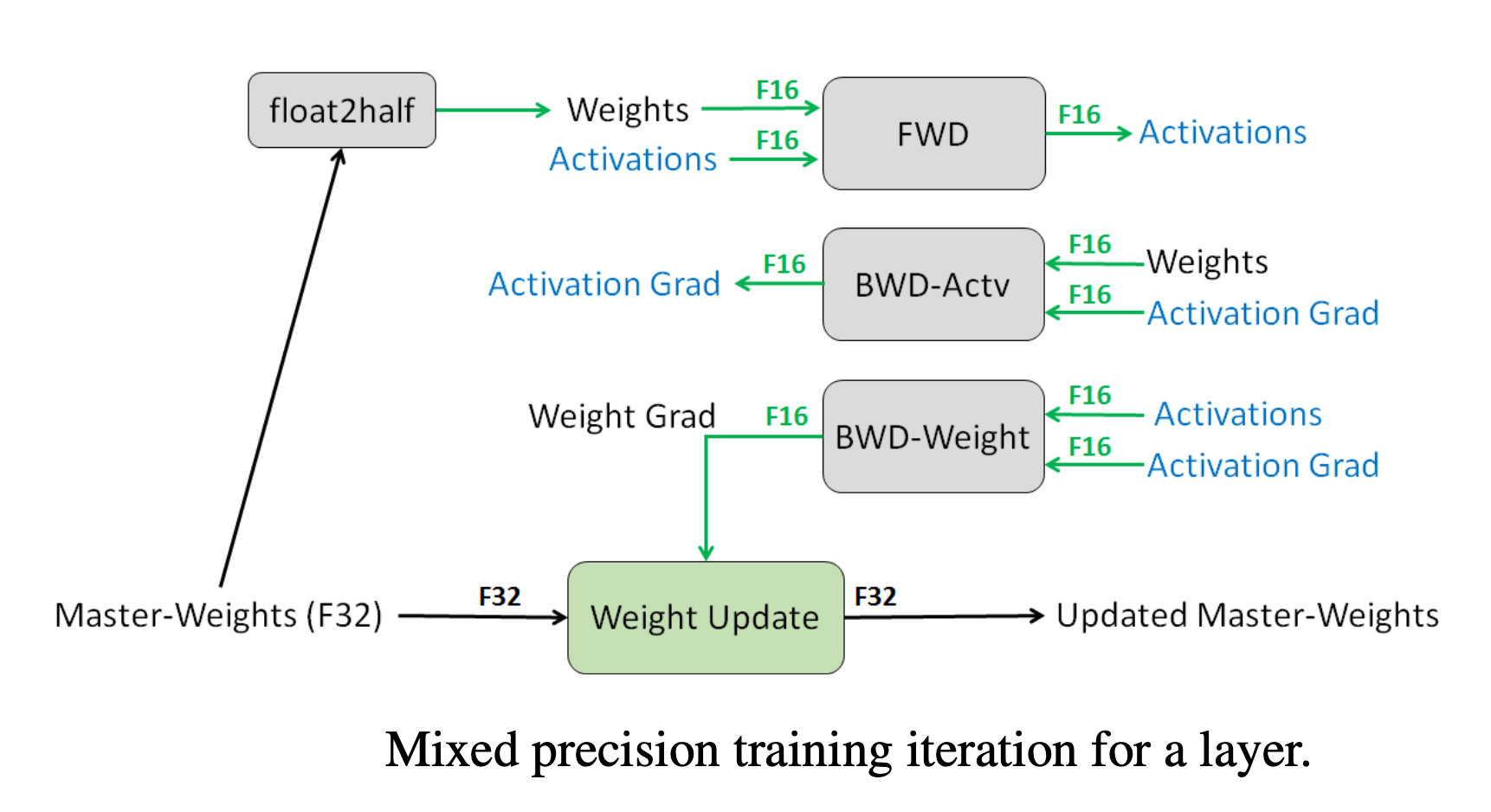
ZeRO 将模型训练阶段每张卡中的显存内容分为两类:
- 模型状态(model states):模型参数(fp16)、模型梯度(fp16)和 Adam 状态(fp32 的模型参数备份、fp32 的 momentum 和 fp32 的 variance)。假设模型参数量为
,则共需要 字节存储。可以看到,Adam 状态占比 75%。 - 剩余状态(residual states):除模型状态之外的显存占用,包括激活值(activation)、各种临时缓冲区(buffer)以及无法使用的显存碎片(fragmentation)。
来看一个例子,GPT-2 含有 1.5B 个参数,如果用 fp16 格式,只需要 3 GB 显存,但模型状态实际上需要耗费 24 GB!相比之下,激活值可以用 activation checkpointing 来大大减少,所以模型状态成了头号显存杀手,也是 ZeRO 的重点优化对象。而其中 Adam 状态又是第一个要被优化的。
针对模型状态的存储优化(去除冗余),ZeRO 使用的方法是分区(partition),即每张卡只存
- 首先进行分区操作的是模型状态中的 Adam,也就是下图中的
,这里 os 指的是 optimizer states。模型参数(parameters)和梯度(gradients)仍旧是每张卡保持一份,此时每张卡的模型状态所需显存是 字节。当 比较大时,趋向于 字节,也就是原来 字节的 1/4。 - 如果继续对模型梯度进行分区,也就是下图中的
,模型参数仍旧是每张卡保持一份,此时每张卡的模型状态所需显存是 字节。当 比较大时,趋向于 字节,也就是原来 字节的 1/8。 - 如果继续对模型参数进行分区,也就是下图中的
,此时每张卡的模型状态所需显存是 字节。当 比较大时,趋向于 0。
下图中 Memory Consumption 第二列给出了一个示例
在 DeepSpeed 中,

ZeRO-DP 优化的三个阶段中每个设备的内存消耗比较。
表示模型大小(参数数量), 表示优化器状态的内存乘数, 表示 DP 并行度,即 个 GPU。在本例中,假设基于 Adam 优化器的混合精度训练,模型大小为 ,DP 为 , 。
解决了模型状态,再来看剩余状态,即激活值(activation)、临时缓冲区(buffer)以及显存碎片(fragmentation)。
- 激活值同样使用分区方法,并且配合 checkpointing。
- 模型训练过程中经常会创建一些大小不等的临时缓冲区,比如对梯度进行 All-Reduce 等。解决办法是预先创建一个固定的缓冲区,训练过程中不再动态创建。如果要传输的数据较小,则多组数据 bucket 后再一次性传输,提高效率。
- 显存出现碎片的一大原因是使用 gradient checkpointing 后,不断地创建和销毁那些不保存的激活值。解决方法是预先分配一块连续的显存,将常驻显存的模型状态和 checkpointed activation 存放在里面,剩余显存用于动态创建和销毁 discarded activation。
1.5 通信数据量分析
下面我们就来分析通信数据量。先说结论:
传统数据并行在每一步(step/iteration)计算梯度后,需要进行一次 All-Reduce 操作来计算梯度均值。目前常用的是 Ring All-Reduce,分为 Reduce-Scatter 和 All-Gather 两步,每张卡的通信数据量(发送 + 接收)近似为
我们直接分析
这里还要注意一点:假如模型最后两层的梯度落在 GPU 0,为了节省显存,其他卡将这两层梯度删除, 怎么计算倒数第三层的梯度呢?还是因为用了 bucket,其他卡可以将梯度发送和计算倒数第三层梯度 同时进行,当二者都结束,就可以放心将后两层梯度删除了。
当 GPU 0 计算好梯度均值后,就可以更新局部的优化器状态。当反向传播过程结束,进行一次 Gather 操作更新模型参数,通信数据量是
从全局来看,相当于用 Reduce-Scatter 和 All-Gather 两步,与传统数据并行一致。
1.6 显存优化
除了上述分布式训练方法外,ZeRO 还通过 Optimizer Offload 和 Checkpointing 技术进一步减少冗余的显存占用,并以牺牲最少的通信代价为前提,在极致显存优化下仍然能够高效率地训练。
1.6.1 优化剩余状态内存
在使用 ZeRO-DP 优化模型状态对应的内存之后,剩余内存(residual memory)成为次要内存瓶颈。剩余内存包括:激活、临时缓冲区和不可用内存片段。ZeRO-R 分别优化这三个因素所消耗的内存:
- 对于激活(从前向传播结果中存储、用来支持反向传播),优化检查点会有帮助,但对于大型模型不够用。因此,ZeRO-R 通过在现有模型并行方案中识别和删除激活副本来优化激活内存。它还可以在适当的时候将激活卸载到 CPU。
- ZeRO-R 为临时缓冲区定义了适当的大小,以实现内存和计算效率的平衡。
- 在训练中,由于不同张量生命周期的变化会导致一些内存碎片。由于这些碎片的存在,即使有足够的可用内存,也会因为缺少连续内存而导致内存分配失败。ZeRO-R 根据张量的不同生命周期来主动管理内存,防止内存碎片。
ZeRO-DP 和 ZeRO-R 结合在一起形成了一个强大的深度学习训练内存优化系统,统称为 ZeRO。
1.6.2 Optimizer Offload
Optimizer Offload 是指将优化器状态从 GPU 卸载到 CPU 上,从而进一步节省显存。下面以 Adam 优化器为例介绍为什么需要将优化器的参数卸载。
在 Adam 中,优化器需要维护梯度的移动平均以及梯度平方的移动平均:
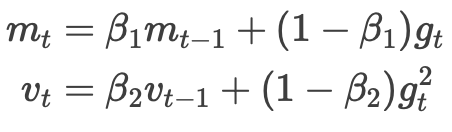
正如前文所示,与模型参数相比,Adam 优化器需要至少两份的显存占用量,这在混合精度训练中是一笔非常大的开销。通过使用 ZeRO-3 的梯度切分,每张计算卡上需要处理的梯度信息大幅减少,将这一部分 GPU 计算卸载至 CPU 上产生的通信需求较小,同时 CPU 处理这样切分后的梯度也不会特别吃力。据此,付出了极小量的额外开销就将显存开销降低至原本的一半左右。

1.6.3 Checkpointing
Checkpointing 技术是一项很早就被提出、用于优化神经网络模型训练时计算图开销的方法。这种方法在 Transformer 等结构的模型训练中能够起到非常明显的作用。目前主流的 Transformer 模型由大量的全连接层组成,下面以全连接层为例进行计算图的显存分析。
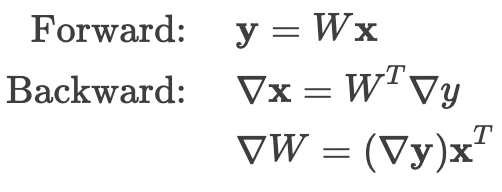
为了能够在反向传播中计算梯度,需要在正向传播时记录下参数矩阵与输入,这两部分参数随着正向传播逐层累积,消耗了大量显存。
因此,使用 Checkpointing 技术(也称为亚线性内存优化),其核心方式是通过时间换空间:在模型各层之间设置检查点,只记录每一层模型的输入向量。在反向传播时,根据最近的 checkpoint 重新计算该层的局部计算图。
1.6.4 框架实现的优化
除了上述显存优化技术外,ZeRO 在具体实现上也进行了优化,以期获得更好的加速效果。
1.6.5 混合精度
传统模型使用单精度参数进行训练。在大模型训练中,可以通过使用半精度参数来降低参数量并节省运算时间。具体实现上,ZeRO 在正向传播和反向传播过程中均使用半精度进行计算,并在优化器中维护单精度的模型参数和优化器参数。
使用混合精度的另一个好处在于能够更好地利用显卡中的 Tensor Core。较新的显卡在 CUDA Core 之外,还设置了专门用于张量运算的 Tensor Core,利用 Tensor Core 将为程序带来进一步的性能提升。使用混合精度训练能够更好地利用 Tensor Core 特性,从而为训练过程进一步加速。
1.6.6 算子融合
为了进一步提升性能,在 CPU 和 GPU 层面均进行了算子层面的实现优化。在 CPU 上,使用多线程 + SIMD(单指令流多数据流)的编程方式,对 Offload 至 CPU 计算的 Adam 优化器进行加速,使其不会成为系统的性能瓶颈。在 GPU 上,使用算子融合的方式,将 Softmax 与 NLLLoss 算子合二为一,减小了中间结果的显存占用。
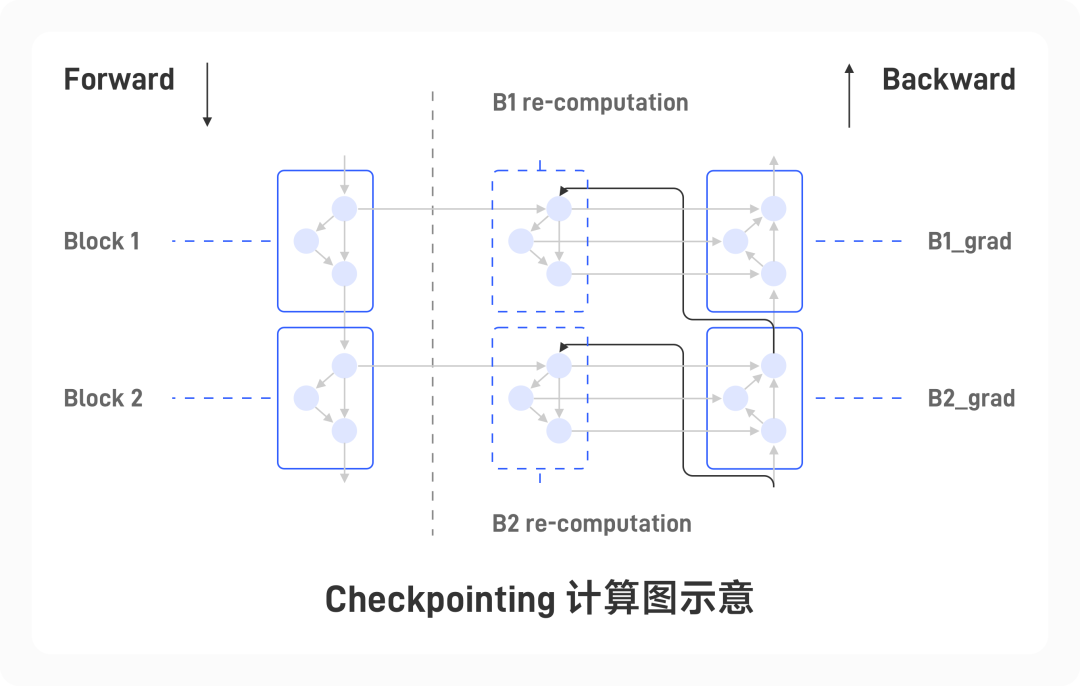
1.6.7 通信计算重叠
上文中提到,ZeRO-3 技术将引入额外的通信时间,采用通信计算重叠策略可以进行通信时间的优化。以反向传播为例,由于使用了 ZeRO-3 技术,需要将切碎至各个计算卡上的模型进行临时的重组装(对应图中的 Gather);而在反向传播(对应图中的 Calculate)之后,还需要将得到的局部梯度重新切碎到不同的计算卡上(对应图中的 Scatter)。通过不同的 CUDA stream 区分不同的操作,让运算和通信得以同时运行,通过大量的计算时间隐藏通信的时间开销。
2. ZeRO-Offload:让人人都能训练得起大模型
ZeRO-Offload: Democratizing Billion-Scale Model Training 发表于 ATC 21,一作是来自 UC Merced 的 Jie Ren,博士期间的研究方向是机器学习与 HPC 异构内存系统的内存管理。
2.1 背景
ZeRO 本质上是一种数据并行方案,但很多用户只有几张甚至一张 GPU。
单卡无法训练大模型,根本原因是显存不足。ZeRO-Offload 的核心思路是:显存不足时,利用 CPU 内存来补充。
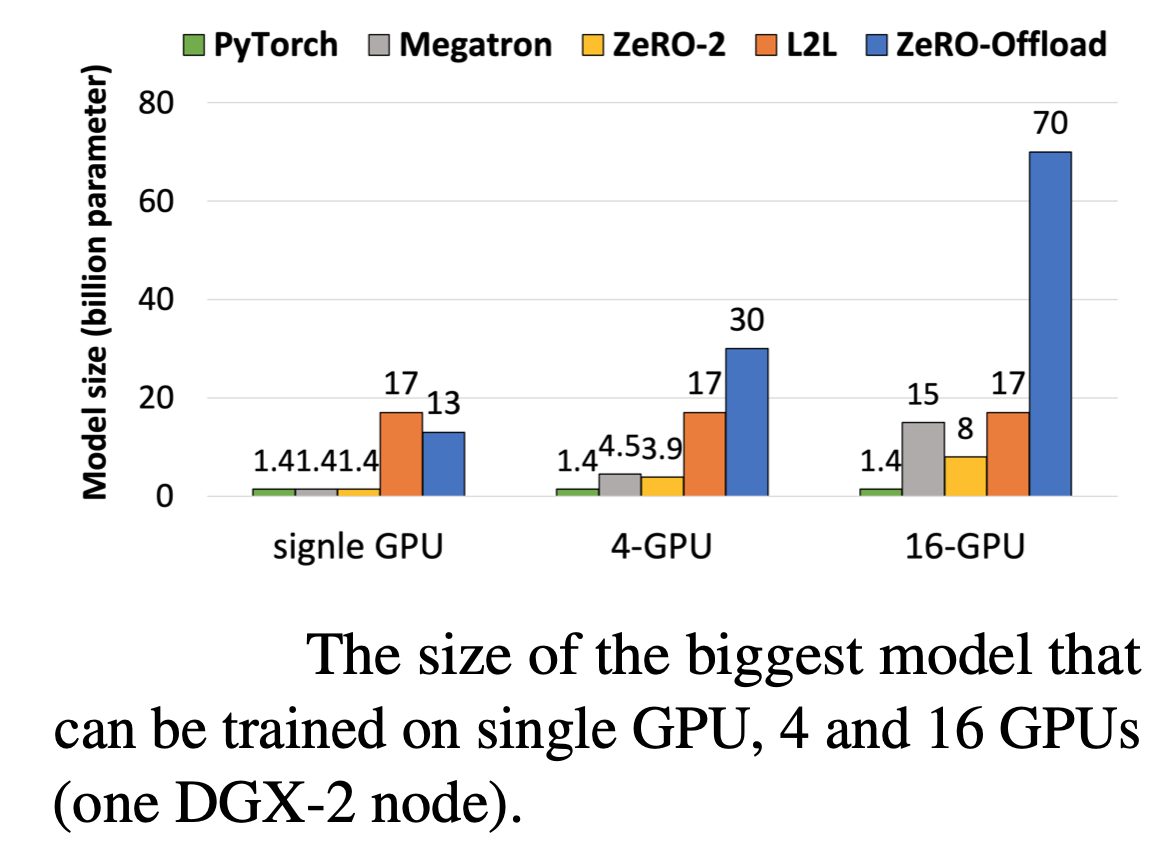
直接看效果:在单张 V100 的情况下,用 PyTorch 能训练 1.4B 的模型,吞吐量是 30 TFLOPS;有了 ZeRO-Offload 加持,可以训练 10B 的模型,并且吞吐量达到 40 TFLOPS。这么好的效果能不能扩展到多卡上?比如只用一台 DGX-2 服务器,可以训练 70B 的模型,是原来只用模型并行的 4.5 倍。在 128 张显卡的实验上基本也是线性加速,此外还可以与模型并行配合。

相比于昂贵的显存,内存廉价多了,能不能在模型训练过程中结合内存呢?其实已经有很多工作,但它们几乎只聚焦在内存上,没有用到 CPU 计算,更没有考虑多卡场景。ZeRO-Offload 则将训练阶段的某些模型状态下放(offload)到内存,并使用 CPU 进行计算。
注:ZeRO-Offload 没有涉及剩余状态(比如激活值)的下放,因为在 Transformer LM 场景中,它比模型状态占用的显存小。
ZeRO-Offload 要做的事情清楚了,那么如何设计高效的 offload 策略呢?
2.2 Offload 策略
ZeRO-Offload 并不希望为了最小化显存占用而让系统计算效率下降,否则只用 CPU 和内存不就得了。但是将部分 GPU 的计算和存储下放到 CPU 和内存,必然涉及 CPU 与 GPU 之间通信的增加,不能让通信成为瓶颈。此外 GPU 的计算效率相比 CPU 是数量级上的优势,也不能让 CPU 参与过多计算而避免成为系统瓶颈。只有前两条满足的前提下,才考虑最小化显存占用。
为了找到最优的 offload 策略,作者将模型训练过程看作数据流图(data-flow graph):
- 圆形节点表示模型状态,比如参数、梯度和优化器状态;
- 矩形节点表示计算操作,比如前向计算、反向计算和参数更新;
- 边表示数据流向。
下图是某一层的一次迭代过程(iteration/step),使用了混合精度训练。前向计算(FWD)需要用到上一次的激活值(activation)和本层的参数(parameter),反向传播(BWD)也需要用到激活值和参数来计算梯度。
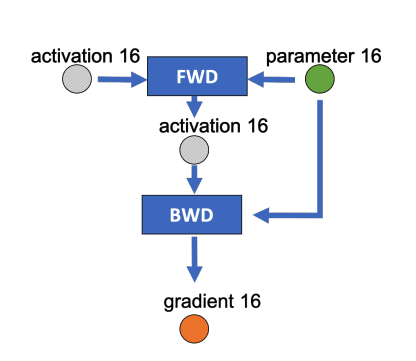
如果用 Adam 优化器进行参数更新(Param update),流程如下:
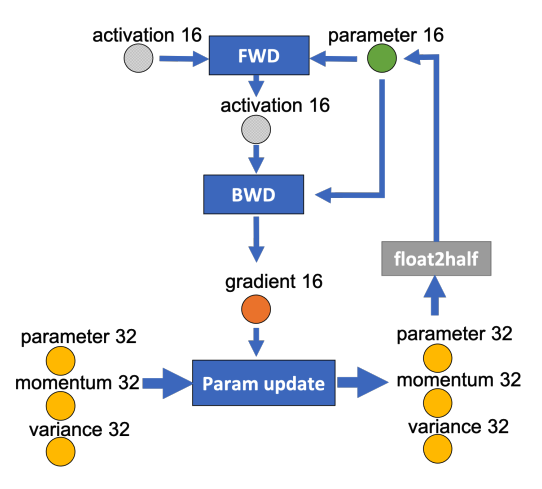
下面我们为边添加权重,物理含义是数据量大小(单位是字节)。假设模型参数量是

我们现在要做的就是沿着边把数据流图切分为两部分,分别对应 GPU 和 CPU。计算节点(矩形节点)落在哪个设备,哪个设备就执行计算;数据节点(圆形)落在哪个设备,哪个设备就负责存储。将被切分的边权重加起来,就是 CPU 与 GPU 之间的通信数据量。
ZeRO-Offload 的切分思路是:
图中有四个计算类节点:FWD、BWD、Param update 和 float2half。前两个计算复杂度大致是
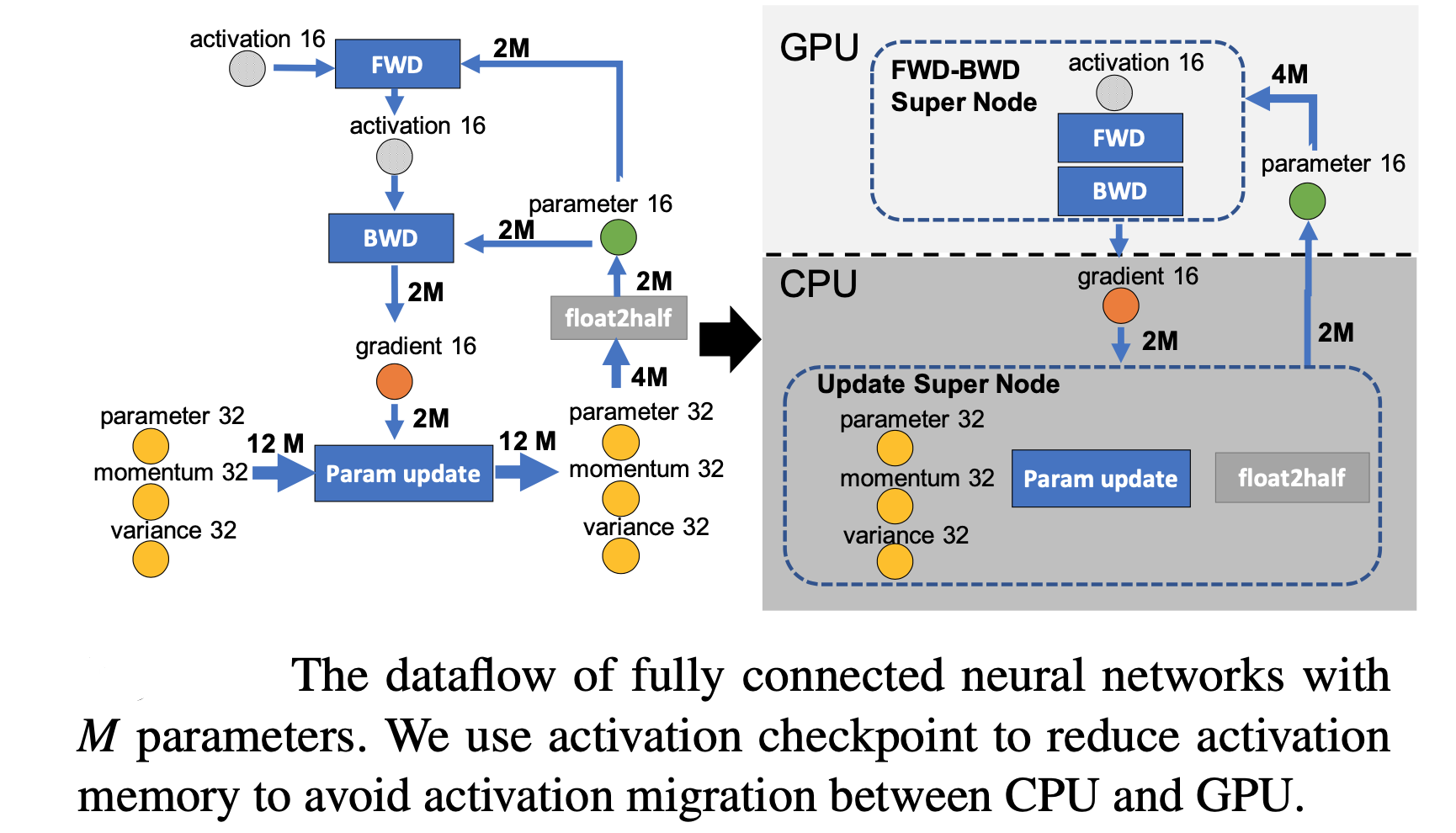
现在的计算流程是:在 GPU 上面进行前向和反向计算,将梯度传给 CPU,进行参数更新,再将更新后的参数传给 GPU。为了提高效率,可以将计算和通信并行起来。GPU 在反向传播阶段,可以待梯度值填满 bucket 后,一边计算新的梯度一边将 bucket 传输给 CPU。当反向传播结束,CPU 基本上已经有最新的梯度值了。同样,CPU 在参数更新时也同步将已经计算好的参数传给 GPU,如下图所示。

到目前为止,说的都是单卡场景。
2.3 扩展性
在多卡场景,ZeRO-Offload 利用了 ZeRO-2。回忆一下,ZeRO-2 将 Adam 状态和梯度进行了分区,每张卡只保存
注意:在多卡场景,利用 CPU 多核并行计算,每张卡至少对应一个 CPU 进程,由这个进程负责进行局部参数更新。
并且 CPU 和 GPU 的通信量和
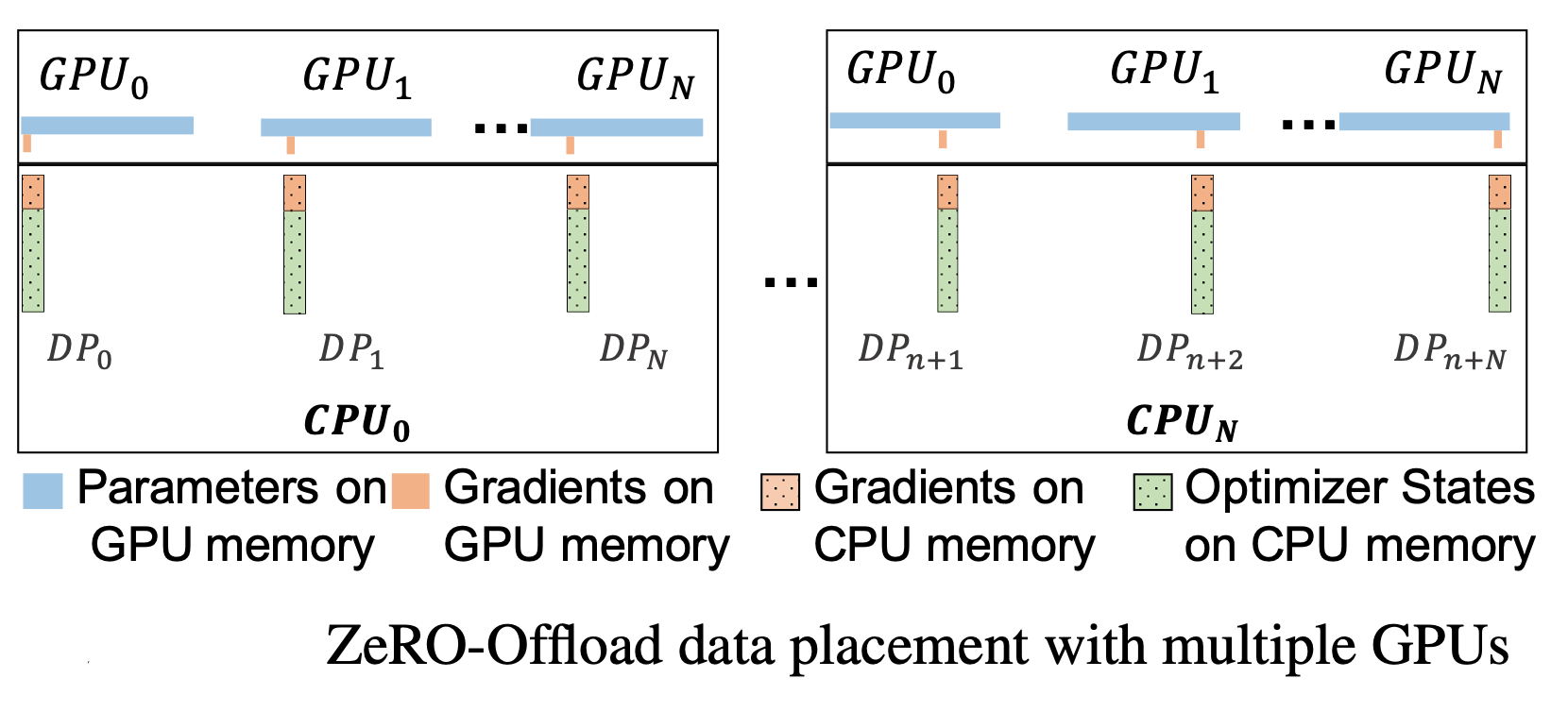
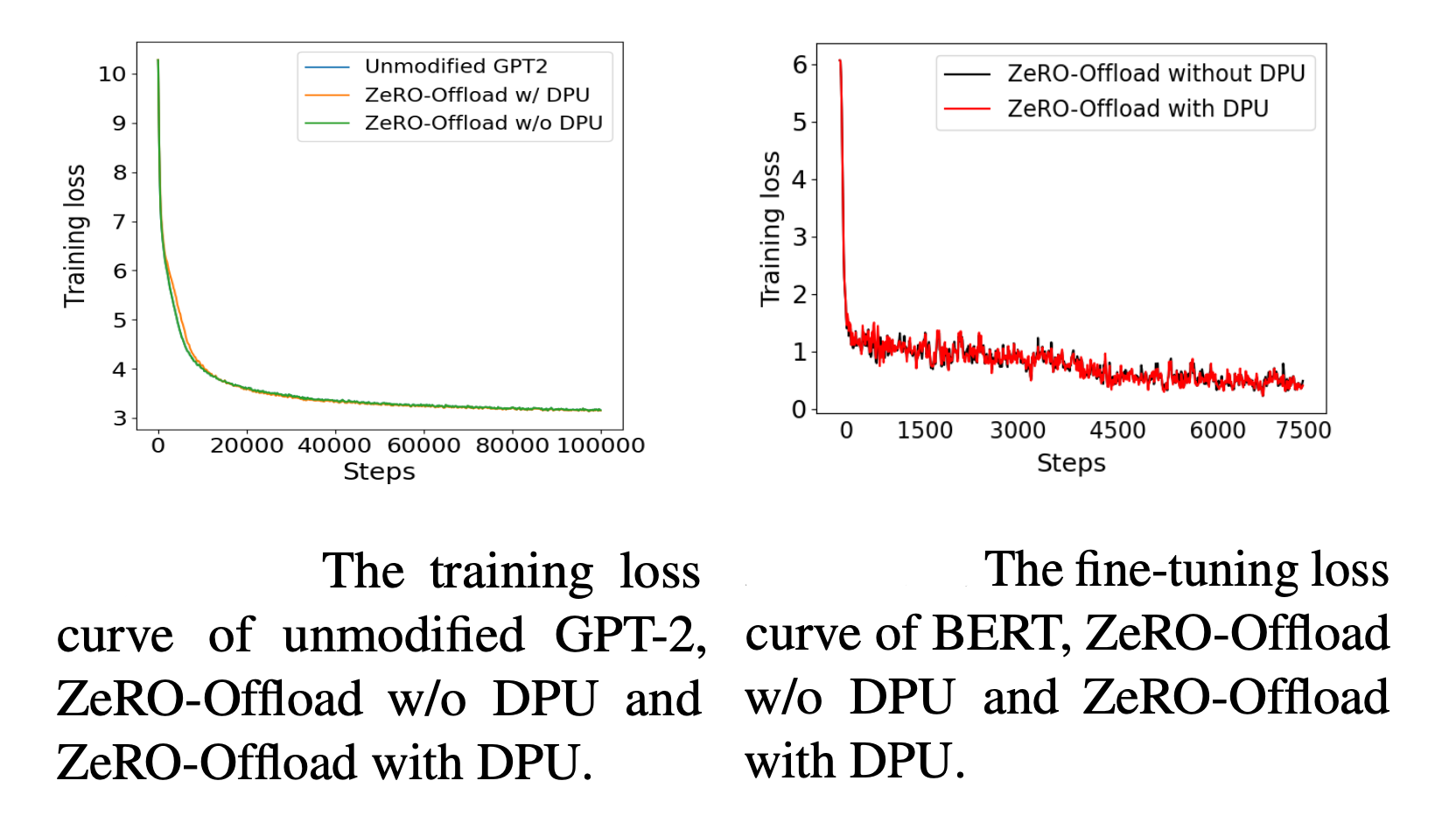
直接看效果:
但是有一个问题:当 batch size 很小时,GPU 上每个 micro-batch 计算很快,此时 CPU 计算时长会成为训练瓶颈。一种方法是让 CPU 在某个节点更新参数时延迟一步,后面就可以让 GPU 和 CPU 并行起来。
前
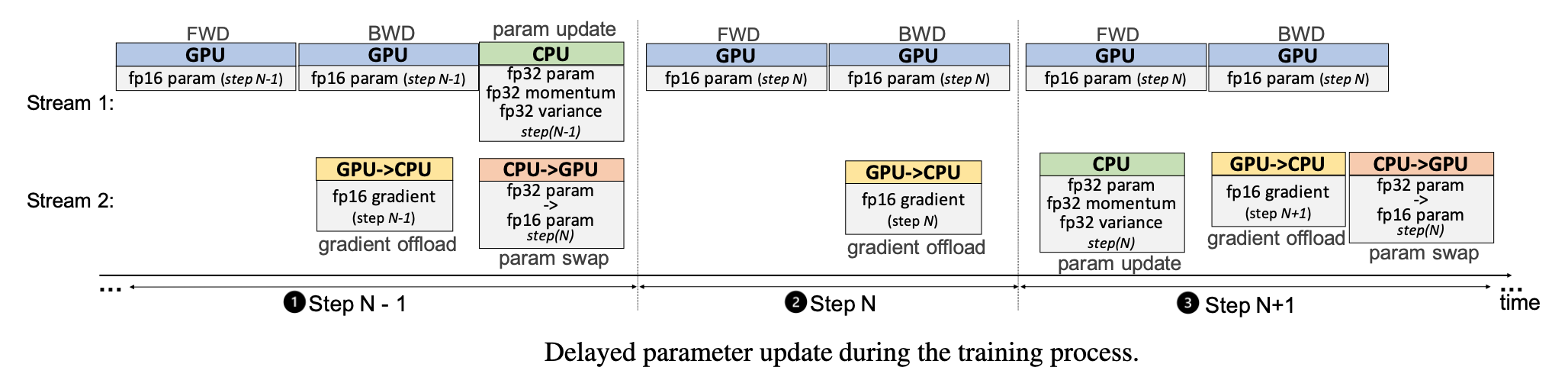
当然这样会有一个问题:用来更新参数的梯度并不是根据当前模型状态计算得到的。论文的实验结果表明暂未发现对收敛和性能产生影响。
3. ZeRO-Infinity:利用 NVMe 打破 GPU 显存墙
ZeRO-Infinity: Breaking the GPU Memory Wall for Extreme Scale Deep Learning 发表于 SC 21,同样研究 offload。ZeRO-Offload 更侧重单卡场景,而 ZeRO-Infinity 则是典型的工业界风格,奔着极大规模训练去了。
3.1 背景
从 GPT-1 到 GPT-3,两年时间内模型参数从 0.1B 增加到 175B,而同期 NVIDIA 交出的成绩单是从 V100 的 32 GB 显存增加到 A100 的 80 GB。显然,显存的提升速度远远赶不上模型增长的速度,这就是内存墙问题。
参考文献
- Samyam Rajbhandari, Jeff Rasley, Olatunji Ruwase, Yuxiong He. ZeRO: Memory Optimizations Toward Training Trillion Parameter Models.
- Zhengda Bian, Hongxin Liu, Boxiang Wang, et al. Colossal-AI: A Unified Deep Learning System For Large-Scale Parallel Training.
- Adam Paszke, Sam Gross, Francisco Massa, et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library.
- Zhengyan Zhang, Xu Han, Hao Zhou, et al. CPM: A Large-scale Generative Chinese Pre-trained Language Model.
- Zhengyan Zhang, Yuxian Gu, Xu Han, et al. CPM-2: Large-scale Cost-efficient Pre-trained Language Models.
- Jacob Devlin, Ming-Wei Chang, Kenton Lee and Kristina Toutanova. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding.
- Colin Raffel, Noam Shazeer, Adam Roberts, et al. T5: Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer.
- Alec Radford, Jeffrey Wu, Rewon Child, et al. GPT-2: Language Models are Unsupervised Multitask Learners.
- Ben Wang and Aran Komatsuzaki, et al. GPT-J from EleutherAI.
- Diederik P. Kingma, Jimmy Ba. Adam: A Method for Stochastic Optimization.
- Yang You, Jing Li, Sashank Reddi, et al. Large Batch Optimization for Deep Learning: Training BERT in 76 minutes.
- Hanlin Tang, Shaoduo Gan, Ammar Ahmad Awan, et al. 1-bit Adam: Communication Efficient Large-Scale Training with Adam's Convergence Speed.
- NCCL: https://docs.nvidia.com/deeplearning/nccl/user-guide/docs/usage/collectives.html