The RDD
Spark是用于大规模数据处理的集群计算框架。 Spark为统一计算引擎提供了3种语言(Java,Scala和Python)的一组库。 这个定义实际上是什么意思?
统一:借助Spark,无需将多个API或系统中的应用程序组合在一起。 Spark为您提供了足够的内置API来完成工作
计算引擎:Spark处理来自各种文件系统的数据加载并在其上运行计算,但不会永久存储任何数据本身。 Spark完全在内存中运行-允许无与伦比的性能和速度
库:Spark由为数据科学任务而构建的一系列库组成。 Spark包括用于SQL(SparkSQL),机器学习(MLlib),流处理(Spark流和结构化流)和图分析(GraphX)的库
Spark Application
每个Spark Application 程序都包含一个驱动程序和一组分布式工作进程(执行程序)。
Spark Driver
驱动程序运行我们应用程序的main()方法,并在其中创建SparkContext。 Spark驱动程序具有以下职责:
- 在集群中的节点上或客户端上运行,并通过集群管理器调度作业执行
- 响应用户的程序或输入
- 分析,安排和分配各个部门的工作
- 存储有关正在运行的应用程序的元数据,并在WebUI中方便地公开它
Spark Executors
Executors 是负责执行任务的分布式过程。每个Spark应用程序都有其自己的执行程序集,这些执行程序在单个Spark应用程序的生命周期内保持有效。
- Executor执行Spark作业的所有数据处理
- 将结果存储在内存中,仅在驱动程序有特别指示时才保留在磁盘上
- 完成结果后,将结果返回给驱动程序
- 每个节点可以具有从每个节点1个执行程序到每个核心1个执行程序的任意位置
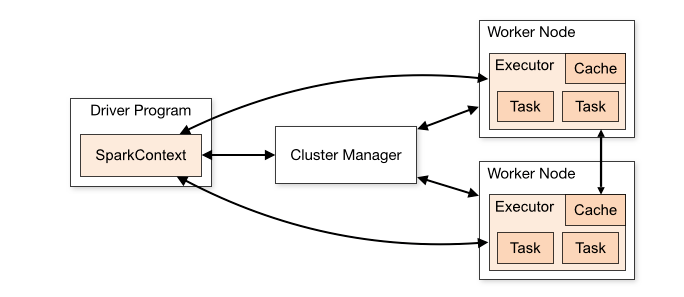
Spark Application工作流程当您将作业提交给Spark进行处理时,幕后还有很多事情要做。
我们的独立应用程序启动,并初始化其SparkContext。 只有拥有SparkContext之后,才能将应用程序称为驱动程序
- 我们的驱动程序要求集群管理器提供启动其执行程序的资源
- 集群管理器启动执行程序
- 我们的驱动程序运行我们的实际Spark代码
- 执行程序运行任务并将其结果发送回驱动程序
- SparkContext已停止并且所有执行程序都已关闭,将资源返回给集群
Spark架构概述
Spark具有定义明确的分层架构,其基于两个主要抽象的组件具有松散耦合:
- 弹性分布式数据集(RDD)
- 有向无环图(DAG)

From PySpark-Pictures by Jeffrey Thompson.
弹性分布式数据集
RDD本质上是Spark的构建块:一切都由它们组成。 甚至Sparks更高级别的API(DataFrame,Dataset)也由RDD组成。
弹性:由于Spark在机器集群上运行,因此硬件故障造成的数据丢失是一个非常现实的问题,因此RDD具有容错能力,并且在发生故障时可以自行重建.
分布式:单个RDD存储在群集中的一系列不同节点上,不属于单个源(也不属于单个故障点)。 这样我们的集群可以并行地在RDD上运行
数据集:值的集合-您应该已经知道的这个值
Apache Spark的最为核心的抽象是弹性分布式数据集(RDD)。 RDD是可以并行操作的元素的容错集合。您可以并行化驱动程序中的现有集合,或引用外部存储系统(如共享文件系统、HDFS、HBase或提供Hadoop InputFormat的任何数据源)中的数据集来创建它们。
我们在Spark中使用的所有数据都将存储在某种形式的RDD中,因此必须完全理解它们。
Spark提供了许多在RDD之上构建的“高级” API,这些API旨在抽象化复杂性,即DataFrame和Dataset。 Scala和Python中的Spark-Submit和Spark-Shell着重于读取-评估-打印循环(REPL),是针对数据科学家的,他们经常希望对数据集进行重复分析。 仍然需要理解RDD,因为它是Spark中所有数据的基础结构。
RDD在口语上等同于:“分布式数据结构”。 JavaRDD<String>本质上只是一个List String,分布在我们集群中的每个节点之间,每个节点都获得List的几个不同块。 使用Spark,我们需要始终在分布式环境中进行思考。
RDD通过将其数据分成一系列分区存储在每个执行程序节点上来工作。 然后,每个节点将仅在其自己的分区上执行其工作。 这就是Spark如此强大的原因:如果Executor死亡或任务失败,Spark可以从原始源中重建所需的分区,然后重新提交任务以完成任务。
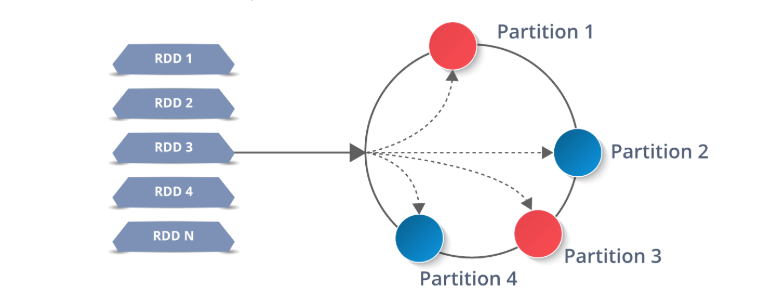
Spark RDD partitioned amongst executors
RDD操作
RDD是不可变的,这意味着一旦创建它们,就不能以任何方式对其进行更改,而只能对其进行转换。转换RDD的概念是Spark的核心,可以将Spark Jobs视为这些步骤的任意组合:
将数据加载到RDD中
转换RDD
在RDD上执行操作
实际上,我编写的每一个Spark作业都完全由这些类型的任务组成,并带有香草味的Java语言。
Spark定义了一组用于处理RDD的API,可以将其分为两大类:转换和操作。
转换会从现有的RDD创建一个新的RDD。
操作在其RDD上运行计算后,会将一个或多个值返回给驱动程序。
例如,地图函数weatherData.map()是一种转换,它通过函数传递RDD的每个元素。
Reduce是一个RDD操作,它使用某些函数来聚合RDD的所有元素,并将最终结果返回给驱动程序。
懒惰评估
“我选择一个懒惰的人做艰苦的工作。因为一个懒惰的人会找到一种简单的方法来做到这一点。 - 比尔盖茨”
Spark中的所有转换都是惰性的。这意味着,当我们告诉Spark通过现有RDD的转换来创建RDD时,直到对该数据集或其子对象执行特定操作之前,它不会生成该数据集。然后,Spark将执行转换以及触发转换的操作。这使Spark可以更有效地运行。
让我们重新检查之前的Spark示例中的函数声明,以识别哪些函数是动作,哪些是转换:
16:JavaRDD<String> weatherData = sc.textFile(inputPath);第16行既不是动作也不是变换。它是sc(我们的JavaSparkContext)的功能。
17:JavaPairRDD <String,Integer> tempsByCountry = weatherData.mapToPair(新函数..第17行是weatherData RDD的转换,其中我们将weatherData的每一行映射到由(City,Temperature)组成的一对
26:JavaPairRDD <String,Integer> maxTempByCountry = tempsByCountry.reduce(新函数...第26行也是一种转换,因为我们正在遍历键值对。这是对tempsByCountry的一种转换,在该转换中,我们将每个城市的温度降低到最高记录温度。
31:maxTempByCountry.saveAsHadoopFile(destPath,String.class,Integer.class,TextOutputFormat.class);最后,在第31行,我们触发了Spark动作:将RDD保存到文件系统中。 由于Spark订阅了惰性执行模型,因此直到这一行Spark生成weatherData,tempsByCountry和maxTempsByCountry才最终保存我们的结果。
有向无环图每当在RDD上执行操作时,Spark都会创建DAG,即无向循环的有限直接图(否则我们的工作将永远运行)。 请记住,图只不过是一系列连接的顶点和边,并且该图也没有什么不同。 DAG中的每个顶点都是Spark函数,在RDD上执行某些操作(map,mapToPair,reduceByKey等)。
在MapReduce中,DAG由两个顶点组成:“贴图”→“缩小”。
在我们上面的MaxTemperatureByCountry示例中,DAG涉及更多:
parallelize → map → mapToPair → reduce → saveAsHadoopFile
DAG使Spark可以优化其执行计划并最大程度地减少改组。 我们将在以后的文章中更深入地讨论DAG,因为它不在本Spark概述的范围之内。
评估循环
使用我们的新词汇,让我们重新检查我在第一部分中定义的MapReduce的问题,如下所述:
MapReduce在批处理数据方面表现出色,但是在重复分析和小的反馈循环方面却落后。在计算之间重用数据的唯一方法是将其写入外部存储系统(例如HDFS)” “在计算之间重复使用数据”?听起来像是可以对其执行多项操作的RDD!假设我们有一个文件“ data.txt”,并且想要完成两个计算:
- 文件中所有行的总长度
- 文件中最长行的长度
在MapReduce中,每个任务将需要单独的作业或精美的MulitpleOutputFormat实现。只需四个简单的步骤,Spark即可轻松实现:
1.将data.txt的内容加载到RDD中
JavaRDD<String>行= sc.textFile(“ data.txt”);2.将“行”的每一行映射到其长度(为简洁起见使用Lambda函数)
JavaRDD<Integer> lineLengths = lines.map(s-> s.length());3.解决总长度:减少lineLengths以找到总线长总和,在这种情况下,是RDD中每个元素的总和
int totalLength = lineLengths.reduce((a,b)-> a + b);4.解决最长的长度:减小lineLengths以找到最大的行长
int maxLength = lineLengths.reduce((a,b)-> Math.max(a,b));请注意,第3步和第4步是RDD动作,因此它们将结果返回到我们的Driver程序,在本例中为Java int。还要记住,Spark是懒惰的,并且拒绝执行任何工作,直到看到一个动作为止,在这种情况下,它直到第3步才开始任何实际的工作。