Ray.tune
Ray.tune是一个超参数优化库,主要适用于深度学习和强化学习模型。它结合了许多先进算法,如Hyperband算法(最低限度地训练模型来确定超参数的影响)、基于群体的训练算法(Population Based Training,在共享超参数下同时训练和优化一系列网络)、Hyperopt方法和中值停止规则(如果模型性能低于中等性能则停止训练)。
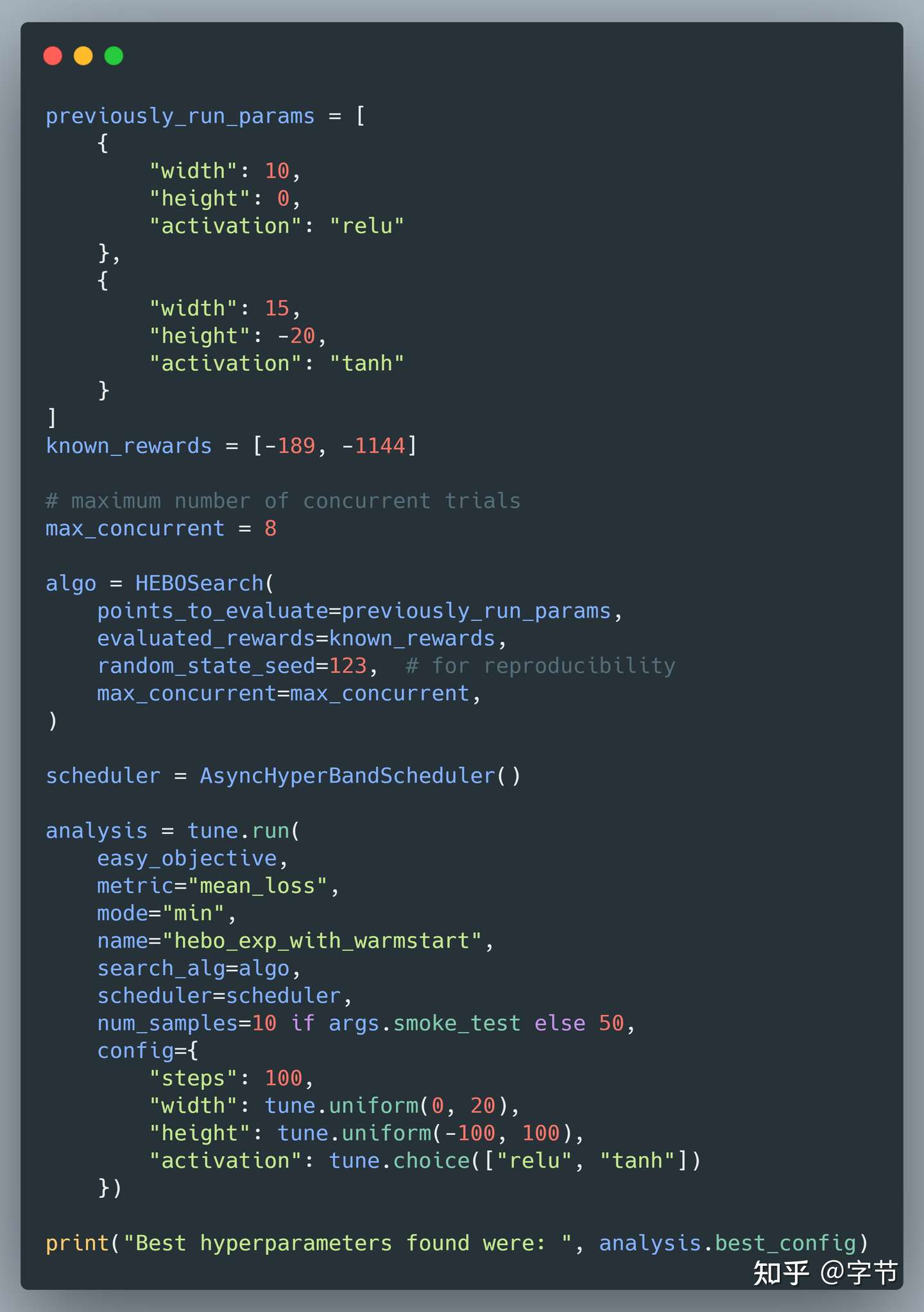
Ray Tune 的结构设计上与 AutoGluon 有很多类似之处,比如像 Hyperband 这类调度策略都放到了scheduler模块里进行实现,而参数的选择放在了searcher模块中来实现。这个抽象还是比较清晰的,可以很方便的在两个模块中做单独的扩展,例如 Ray Tune 的scheduler中实现了很多高级算法,包括 async hyperband,population based training(来自 DeepMind 的工作)等。同理在suggest模块中,Ray Tune 对接了很多成熟的超参优化库,如 hyperopt,optuna,skopt,dragonfly,ax,HpBandSter,hebo 等等,看完才知道原来有这么多的超参优化库……
Ray Tune 跟 Optuna 类似,在跟各种框架的结合上也下了不少功夫,例如对主流训练框架 Lightgbm,PyTorch,PyTorch Lightening,Keras,Horovod 等的支持,训练过程的 checkpointing 与 tensorboard 的对接,实验结果的记录也支持 MLflow 和 wandb,还包括底层架构 K8s,Docker 的对接支持等。
Ray Tune 在优化过程中的容错处理也相对更加完善,可以中途停止搜索,后续再继续优化,也可以在 Spot instance 集群上执行大规模的训练任务,节省计算成本。可以参考 BAIR 的 这篇 blog。
Ray 本身的生态环境日渐成熟强大,例如数据处理方面 Dask, Modin 都可以在 Ray 上获得“分布式 Pandas”的使用体验,Ray Serve 支持 Python 类服务的部署,RLlib 支持在 Ray 上跑分布式的强化学习任务等等。相比 Spark,感觉 Ray 在数据科学全链路上的完整性一致性体验更好,吸引了更多数据应用工作者的加入使用。
代码样例
我们也来看几个 Ray Tune 上有意思的代码案例。
Ray Tune 中的高级算法支持,华为诺亚方舟实验室的河伯框架:
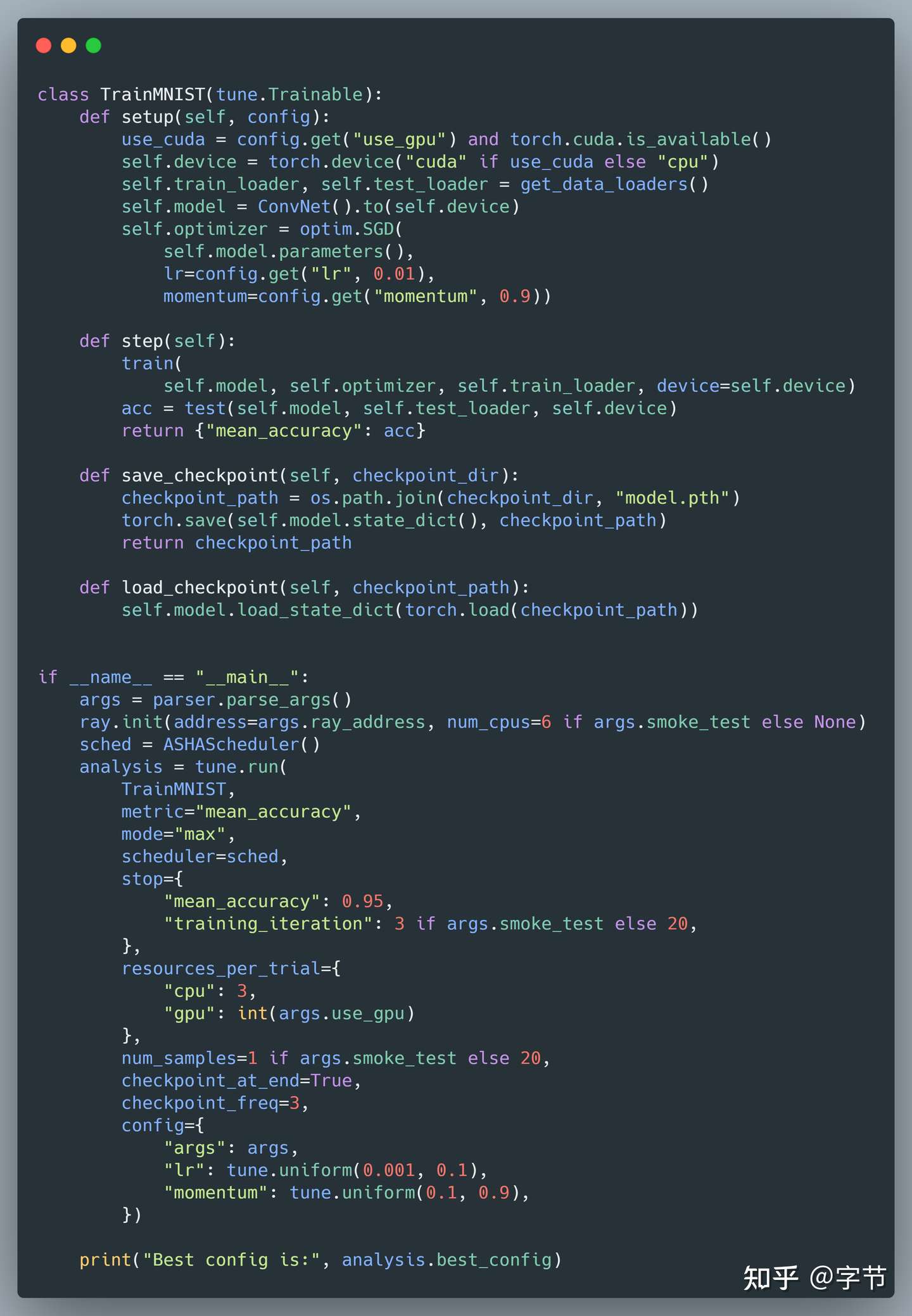
在 Trainable 中需要实现 save/load checkpoint,用以支持分布式训练容错:
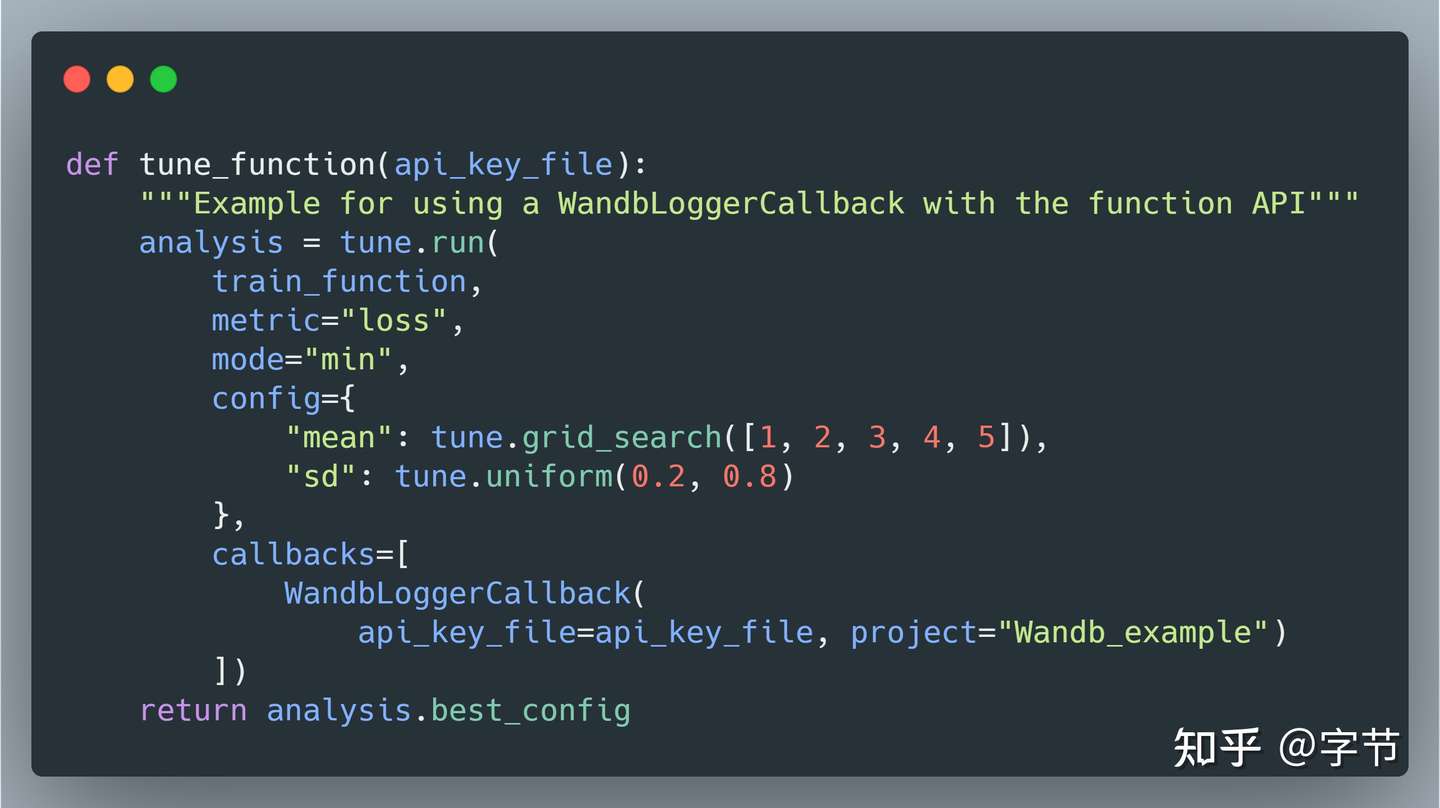
使用 callbacks 来支持 MLflow, WandB 的对接,这个结果展示就比简单的 fit summary 丰富多啦:
如果想要了解整体的集群 setup 使用流程,可以参考 官方文档 或者 这篇 blog。
总结
从上面的代码案例中可以看到,在 Ray Tune 中定义 Trainable 还是一件有点麻烦的事情,也就是对用户代码的侵入性有点强。另外 Ray 跟 K8s 的集成总体来说有点别扭,Raylet + Object Store 的设计导致很难直接利用底层抽象 infra 来做 auto scaling,同时对于具体任务的执行也基本限定在 Python 语言体系中。在未来云原生时代,Ray 框架的发展不知是否会受到一些影响。