FeatureTools
https://featuretools.alteryx.com/en/stable/
1. 引言
一个完整的机器学习项目可概括为如下四个步骤。
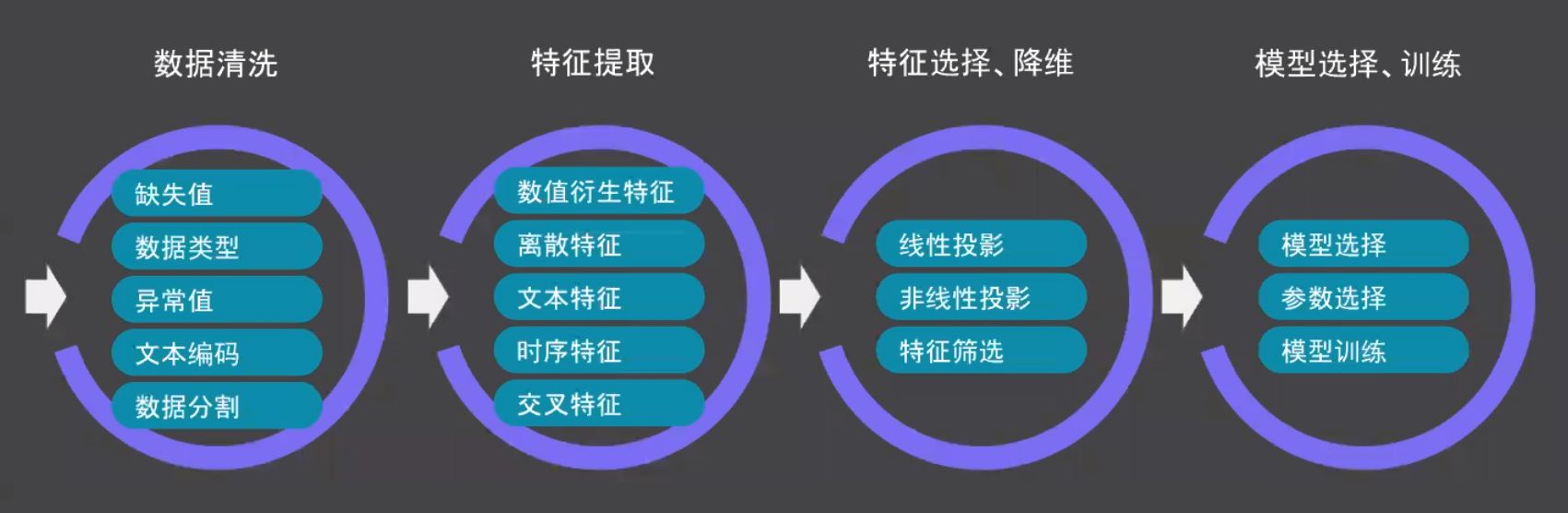
其中,特征工程(提取)往往是决定模型性能的最关键一步。而往往机器学习中最耗时的部分也正是特性工程和超参数调优。因此,许多模型由于时间限制而过早地从实验阶段转移到生产阶段从而导致并不是最优的。
自动化机器学习(AutoML)框架旨在减少算法工程师们的负担,以便于他们可以在特征工程和超参数调优上花更少的时间,而在模型设计上花更多的时间进行尝试。
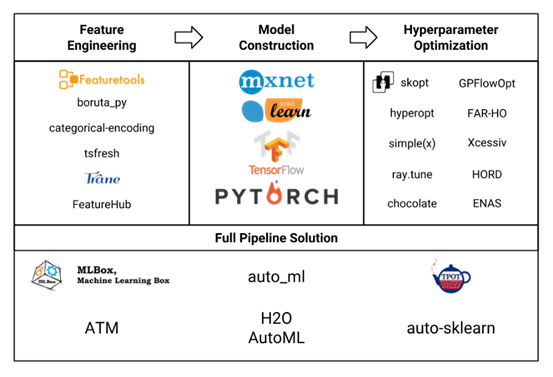
本文将对AutoML中的自动化特征工程模块的现状展开介绍,以下是目前主流的有关AUTOML的开源包。
2. 什么是自动化特征工程?
自动化特征工程旨在通过从数据集中自动创建候选特征,且从中选择若干最佳特征进行训练的一种方式。
3. 自动化特征工程工具包
3.1 Featuretools
Featuretools is a framework to perform automated feature engineering. It excels at transforming temporal and relational datasets into feature matrices for machine learning.
Featuretools使用一种称为深度特征合成(Deep Feature Synthesis,DFS)的算法,该算法遍历通过关系数据库的模式描述的关系路径。当DFS遍历这些路径时,它通过应用于数据的操作(包括和、平均值和计数)生成综合特征。例如,对来自给定字段client_id的事务列表应用sum操作,并将这些事务聚合到一个列中。尽管这是一个深度操作,但该算法可以遍历更深层的特征。Featuretools最大的优点是其可靠性和处理信息泄漏的能力,同时可以用来对时间序列数据进行处理。

Featuretools程序包中的三个主要组件:
- 实体(Entities)
- 深度特征综合(Deep Feature Synthesis ,DFS)
- 特征基元(Feature primitives)
- 一个Entity可以视作是一个Pandas的数据框的表示,多个实体的集合称为Entityset。
- 深度特征综合(DFS)与深度学习无关,不用担心。实际上,DFS是一种特征工程方法,是Featuretools的主干。它支持从单个或者多个数据框中构造新特征。
- DFS通过将特征基元应用于Entityset的实体关系来构造新特征。这些特征基元是手动生成特征时常用的方法。例如,基元“mean”将在聚合级别上找到变量的平均值。
使用示例
Featuretools是用了DFS来专门处理时间和关系数据集,核心是DFS,下面通过带时间戳的客户事务的示例来分析这个过程。
数据
处理的是关系数据集,它包括实体集(EntitySet)和关系(Relationship)。
实体集(EntitySet):是实体的集合,在FeatureTools一个关系表称为一个实体。
关系:在FeatureTools只描述一对多的关系,一所在的实体为父实体,多所在的实体为子实体,一个父亲可以有多个孩子。例如一个客户可以拥有多个会话,那么客户表就是会话表的父表。关系表示由子实体指向父实体。
下面以带时间戳的客户事务组成的关系数据集为例:
In [1]: import featuretools as ft
In [2]: es = ft.demo.load_mock_customer(return_entityset=True)
In [3]: es
Out[3]:
Entityset: transactions #实体集,数据集是关于客户事务的
Entities: #实体,即四张表,包含实体名称及其表的行和列
transactions [Rows: 500, Columns: 5] #会话的事件列表
products [Rows: 5, Columns: 2] #产品及其关联属性,主键为product_id
sessions [Rows: 35, Columns: 4] #会话及其关联属性,主键为session_id
customers [Rows: 5, Columns: 4] #客户及其关联属性,主键为customer_id
Relationships: #关系,一对多,子->父
transactions.product_id -> products.product_id
transactions.session_id -> sessions.session_id
sessions.customer_id -> customers.customer_id
注:主键为能唯一地标识表中的每一行的一个列或者多列的组合,通过它可强制表的实体完整性。DFS(Deep Feature Synthesis)
如果没有自动化的特性工程,数据科学家会编写代码来为客户聚合数据,并应用不同的统计功能(add,average,sum...)来量化客户的行为,工作量巨大。而DFS(深度特征合成)能够自动化这个过程,通过叠加聚合和转换操作来生成不同的深度特征让数据科学家更加直观地了解各种数据并加以选取,大大节省了数据科学家的时间。
DFS有三个关键概念:
- 特征源于数据集中数据点之间的关系。
- 对数据库或日志文件中常见的多表和事务数据集进行特征工程,这是因为这种数据格式是公司记录客户数据最常见的类型。
- 在数据集中,许多特性都是通过使用类似的数学运算得到的。比如我们衡量一个客户的最大购买力需要对他所有的购买金额使用max操作,同样衡量一趟航班的最长延误时间。
注:翻译自Feature Labs。
Primitives
DFS能对关系数据集进行各种数学运算并产生我们需要的新表,但是该如何操作才能使得新表的主键及其属性(特征)是我们所需的呢?为此,FeatureTools的dfs函数使用了特征原语(Feature primitives)。
原语(primitives)定义了可应用于原始数据集以产生新Features的计算或操作(count,sum等),它只约束输入和输出数据类型,因此可以跨数据集应用。FeatureTools使用了两种类型的原语(Primitive):
- Aggregation primitives:聚合操作。应用于实体集的父子关系中。例如 “count”, “sum”, “avg_time_between”,需要聚合父子表的特征。以下面的示例为例子,count首先找到客户表(target entity)的客户id,然后根据数据中的关系找到它的子表session,然后计算子表同一客户id的session有多少个,从而生成新的特征。
- Transform primitives:转换操作。将一个实体的一个或多个变量作为输入,并为该实体输出一个新变量,应用于单个实体,例如:“hour”、“time_since_precious”、“absolute”。同样以下面的例子为例,对于客户表中,只要涉及到有月份的特征,都将它的月份提取出来形成新的特征,新特征是从原表中产生的。
示例
In [4]: feature_matrix, feature_defs = ft.dfs(entityset=es,
...: target_entity="customers",
...: agg_primitives=["count"],
...: trans_primitives=["month"])
...:
In [5]: feature_matrix
Out[5]:
zip_code COUNT(sessions) MONTH(join_date) MONTH(date_of_birth)
customer_id
5 60091 6 7 7
4 60091 8 4 8
1 60091 8 4 7
3 13244 6 8 11
2 13244 7 4 8FeatureTools的dfs函数定义了:
- 处理的数据集对象:entityset
- 生成新表的主键的来源target_entity
- Aggregation primitives、Transform primitives
处理时间
当数据科学家想要对时间数据进行特征工程的时候,选取哪一时间段的数据用于计算至关重要。Featuretools 标注了时间索引的实体提供了截取(cutoff) 操作,从而使得它能在计算之前自动地过滤在在设定的截取时间以后的数据。
接下来解释一下时间索引(time index) 和 截取时间(cutoff time)
时间索引(time index):表示表中一行被知道或者发生的时间。例如,对于session表,那么session发生的时间即为它的时间索引,能够用于特征合成。而对于客户表,它可能含有生日以及加入的日期(join date),那么加入日期是时间索引,因为它表示了客户首次在数据集中可用的时间。
截取时间(cutoff time):指定行数据可用于特征计算的最后一个时间点。在此时间点之后的任何数据都将在特征计算或者操作之前过滤掉。
注:时间索引在截取时间后面的行将自动忽略。
示例
预测客户1, 2, 3 在 2014-1-1 04:00 以后会不会做某事,用参数cutoff_time过滤 2014-1-1 04:00以后的数据,同时我们还能设置要使用到截取时间前多长时间内的数据,即时间窗,参数为training_window,以两小时为例:
In [5]: fm, features = ft.dfs(entityset=es,
...: target_entity='customers',
...: cutoff_time=pd.Timestamp("2014-1-1 04:00"),
...: instance_ids=[1,2,3],
...: cutoff_time_in_index=True,
training_window="2 hour")有些数据不仅涉及到时间点,还涉及到时间段。比如一个session能涉及到多个事务,而每个事务的发生时间不一样,有时候session的start time在时间窗之前,但是涉及的事务有在时间窗的。因此Featuretools提供了EntitySet.add_last_time_indexes() 让session表增加了最后发生时间的特征。从而能够找到了在时间窗内所有有关的实体。
3.2. Boruta-py
scikit-learn-contrib/boruta_py
在许多数据分析和建模项目中,数据科学家会收集到成百上千个特征。更糟糕的是,有时特征数目会大于样本数目。这种情况很普遍,但在大多数情况下,并不是所有的变量都是与机器试图理解和建模的内容相关的。所以数据科学家可以尝试设计一些有效的方法来选择那些重要的特征,并将它们合并到模型中,这叫做特征选择。
Boruta-py是Brouta特征降维策略的一种实现,以“全相关”方式来解决问题。这种算法能保留对模型有显著贡献的所有特征,这与很多特征降维方法使用的“最小最优特征集”思路相反。Boruta方法先对目标特征进行随机重新排序并组成合成特征,然后在原始特征集上训练简单的决策树分类器,再在特征集中把目标特征替换成合成特征,用这三个步骤来确定特征重要性。其中,不同特征对应的性能差异可用于计算它们的相对重要性。
Boruta是一种全相关的特征选择方法,其他大部分都是最小最优的;这意味着它试图找到所有携带可用于预测的信息的特征,而不是找到一些可能的分类器误差最小的特征的紧凑子集。使用全相关特性是因为当机器试图理解生成数据的现象时,它应该关注所有与之相关的因素,而不仅仅是在特定方法的最显著的特征。
算法步骤
- 创建阴影特征 (shadow feature) : 对每个真实特征R,随机打乱顺序,得到阴影特征矩阵S,拼接到真实特征后面,构成新的特征矩阵N = [R, S].
- 用新的特征矩阵N作为输入,训练模型,能输出feature_importances_的模型,如RandomForest, lightgbm,xgboost都可以,得到真实特征和阴影特征的feature importances,
- 取阴影特征feature importance的最大值S_max,真实特征中feature importance大于S_max的,记录一次命中。
- 用(3)中记录的真实特征累计命中,标记特征重要或不重要。
- 删除不重要的特征,重复1-4,直到所有特征都被标记。
使用示例
这个项目模拟scikit-learn接口,因此使用fit、transform 或 fit_tansform 来进行特征选择。
参数
estimator : object
一个有监督的学习估计器,带有一个'fit'方法,返回feature_importances_ 属性。重要的特征必须对应feature_importances_中的高绝对值。
n_estimators : int or string, default = 1000
设置 estimators 的数量. 如果是 'auto' 则根据数据集的大小自动确定.
perc : int, default = 100
我们使用用户定义的百分位数来选择阴影和真实特征比较的阈值,而不是最大值,因为最大值往往过于严格。perc越低,就会有越多的不相关特征被选为相关的,但也会有较少相关的特性被遗漏,两者需要权衡。
alpha : float, default = 0.05
在两个修正步骤中,被修正的p值被拒绝的程度。
two_step : Boolean, default = True
如果您想使用Bonferroni更正Boruta的原始实现,只需将其设置为False。
max_iter : int, default = 100
要执行的最大迭代数。
verbose : int, default=0
控制输出的信息。
属性
n_features_ : int 选择特征的数量
support_ : 形如 [n_features]的数组,True为选择的特征
support_weak_ : 形如 [n_features]的数组,暂定选取的特征
ranking_ : 形如 [n_features]的数组,特征的等级ranking, ranking_[i]对应于第i个特征的ranking。
代码示例:
i*mport pandas as pd
from sklearn.ensemble import RandomForestClassifier
from boruta import BorutaPy
# 导入数据
X = pd.read_csv('examples/test_X.csv', index_col=0).values
y = pd.read_csv('examples/test_y.csv', header=None, index_col=0).values
y = y.ravel()
# 定义随机森林分类器
rf = RandomForestClassifier(n_jobs=-1, class_weight='balanced', max_depth=5)
# 设置 Boruta 特征选择的参数
feat_selector = BorutaPy(rf, n_estimators='auto', verbose=2, random_state=1)
# 发现所有相关的特征-5个特征会被选择
feat_selector.fit(X, y)
# 查看前五个选择的特征
feat_selector.support_
# 查看选择的特征的rank
feat_selector.ranking_
# 用 transform() 过滤掉数据x不相关的特征
X_filtered = feat_selector.transform(X)输出示例
训练结束后,可以输出特征ranking_,表示特征的重要性等级,在特征选择中也是一个很有用的指标。
>>>feat_selector.fit(X, y)
//拟合的一些信息
BorutaPy finished running.
Iteration: 13 / 100
Confirmed: 5
Tentative: 0
Rejected: 5
BorutaPy(alpha=0.05,
estimator=RandomForestClassifier(bootstrap=True, class_weight='balanced',
criterion='gini', max_depth=5, max_features='auto',
max_leaf_nodes=None, min_impurity_decrease=0.0,
min_impurity_split=None, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
n_estimators=74, n_jobs=-1, oob_score=False,
random_state=RandomState(MT19937) at 0x226811D5DB0, verbose=0,
warm_start=False),
max_iter=100, n_estimators='auto', perc=100,
random_state=RandomState(MT19937) at 0x226811D5DB0, two_step=True,
verbose=2)
>>>feat_selector.support_
array([ True, True, True, True, True, False, False, False, False,
False]) //筛选后的特征,False代表滤除掉此特征
>>>feat_selector.ranking_
array([1, 1, 1, 1, 1, 2, 4, 6, 3, 5]) //越高代表越重要
# 用 transform() 过滤掉数据x不相关的特征
>>> X_filtered = feat_selector.transform(X)
array([[ 0. , -0.05193964, -2.0362205 , 0.61377086, 0. ],
[ 1. , 0.58291516, 1.04749347, 1.37545586, 1. ],
[ 1. , 0.72640099, 0.75092816, 1.16757011, 1. ],
...,
[ 0. , -0.15821768, -2.20124347, 1.27271473, 1. ],
[ 1. , 0.5848914 , -0.99888891, -0.16948063, 2. ],
[ 0. , -0.05607609, 0.03402959, -0.72097011, 0. ]])3.3 Categorical-encoding
scikit-learn-contrib/categorical-encoding
Categorical Encoding扩展了很多实现 scikit-learn 数据转换器接口的分类编码方法,并实现了常见的分类编码方法,例如单热编码和散列编码,也有更利基的编码方法,如基本编码和目标编码。
这个库对于处理现实世界的分类变量来说很有用,比如那些具有高基数的变量。这个库还可以直接与 pandas 一起使用,用于计算缺失值,以及处理训练集之外的变换值。
功能
包括以下15种编码方法,这些编码的功能、参数定义以及属性由官网知悉。
- Backward Difference Coding
- BaseN
- Binary
- CatBoost Encoder
- Hashing
- Helmert Coding
- James-Stein Encoder
- Leave One Out
- M-estimate
- One Hot
- Ordinal
- Polynomial Coding
- Sum Coding
- Target Encoder
- Weight of Evidence
使用示例
import category_encoders as ce
encoder = ce.BackwardDifferenceEncoder(cols=[...])
encoder = ce.BaseNEncoder(cols=[...])
encoder = ce.BinaryEncoder(cols=[...])
encoder = ce.CatBoostEncoder(cols=[...])
encoder = ce.HashingEncoder(cols=[...])
encoder = ce.HelmertEncoder(cols=[...])
encoder = ce.JamesSteinEncoder(cols=[...])
encoder = ce.LeaveOneOutEncoder(cols=[...])
encoder = ce.MEstimateEncoder(cols=[...])
encoder = ce.OneHotEncoder(cols=[...])
encoder = ce.OrdinalEncoder(cols=[...])
encoder = ce.SumEncoder(cols=[...])
encoder = ce.PolynomialEncoder(cols=[...])
encoder = ce.TargetEncoder(cols=[...])
encoder = ce.WOEEncoder(cols=[...])
encoder.fit(X, y)
X_cleaned = encoder.transform(X_dirty)import pandas as pd
import category_encoders as ce
# 数据
df = pd.DataFrame({'ID':[1,2,3,4,5,6],
'RATING':['G','B','G','B','B','G']})
df # 编码前的数据
ID RATING
0 1 G
1 2 B
2 3 G
3 4 B
4 5 B
5 6 G
# 二值编码
encoder = ce.BinaryEncoder(cols=['RATING']).fit(df)
# 编码数据
df_transform = encoder.transform(df)
df_transform #编码后的数据
ID RATING_0 RATING_1
0 1 0 1
1 2 1 0
2 3 0 1
3 4 1 0
4 5 1 0
5 6 0 13.4 Tsfresh
这个库专注于时间序列数据的特征生成,它由一个德国零售分析公司支持,是他们数据分析流程中的一步。
Tsfresh是*处理时间序列的关系数据库的特征工程工具,能自动从时间序列中提取100多个特征。该软件包包含多种特征提取方法和一种稳健的特征选择算法,还包含评价这些特征对回归或分类任务的解释能力和重要性的方法。
TsFresh能自动地计算出大量的时间序列特征,即所谓的特征,这些特征描述了时间序列的基本特征,如峰数、平均值或最大值或更复杂的特征,如时间反转对称统计。同时通过假设检验来将特征消减到最能解释趋势的特征,称为去相关性。然后,可以使用这些特征集在时间序列上构造统计或机器学习模型,例如在回归或分类任务中使用。
它能提取出一系列用于描述时间序列趋势的形态特征,这些特征中包括一些简单特征(如方差)和复杂特征(近似熵)。
这个库能从数据中提取趋势特征,让机器学习算法更容易地解释时间序列数据集。它使用假设检验来获取大量生成特征集,并将其减少到少量最具解释性的趋势特征。
Tsfresh还与pandas和sklearn兼容,可嵌入到现有的数据科学流程中。Tsfresh库的优势在于其可扩展的数据处理实现,这部分已经在具有大量时间序列数据的生产系统中进行了测试。
3.5. Trane
这个库是麻省理工学院HDI项目的产品。
Trane库可用来处理存储在关系数据库中的时间序列数据,和表示时间序列问题。它能列举出关于数据集的元信息,数据科学家能从数据库中的时间序列数据中提取这些特征来构建有监督问题。
这个过程存储在JSON文件中,数据科学家能改写这个文件来描述列和数据类型。该框架通过处理这个文件来生成可能的预测问题,这些问题能用于修改数据集。
这个项目对feature-tools库很有帮助,可用来以半自动方式生成额外特征。