从 AutoEncoder 到 Beta-VAE
自编码器(Autoencoder)是一种通过瓶颈层(bottleneck layer)压缩高维数据并重建输入的神经网络模型。其副产物是降维:瓶颈层学习到的低维表示可作为嵌入向量用于检索、数据压缩,或揭示数据的潜在生成因素。变分自编码器(VAE)在自编码器的基础上引入了概率化建模,将在后文详细介绍。
1. 符号
| Symbol | Mean |
|---|---|
| 数据集, | |
| 每个数据点都是一个 | |
| 来自数据集的一个数据样本, | |
| 在 bottleneck layer 学习到的压缩向量 | |
| 参数化的编码函数 | |
| 参数化的解码函数 | |
| 估计后验概率函数,也称为概率编码器。 | |
| 给定潜在编码生成真实数据样本的似然,也称为概率解码器 |
2. AutoEncoder
自编码器是一种神经网络,旨在以无监督的方式学习恒等函数以重建原始输入,同时压缩过程中的数据,从而发现更高效和压缩的表示。这个想法起源于20 世纪 80 年代,后来由Hinton & Salakhutdinov 于 2006 年发表的开创性论文得到推广。
它由两个网络组成:
- 编码器网络:它将原始的高维输入变换成潜在的低维编码。输入尺寸大于输出。
- 解码器网络:解码器网络从编码中恢复数据,可能具有越来越大的输出层。

图 1. AutoEncoder 模型架构图。
编码器网络本质上完成了降维,就像我们使用主成分分析(PCA)或矩阵分解(MF)一样。此外,AutoEncoder 针对数据重建在编码层面进行了显式优化。一个好的中间表示不仅可以捕获隐变量,而且有利于完整的解压过程。
该模型包含由
参数
3. 降噪 AutoEncoder
由于 AutoEncoder 学习恒等函数,当网络参数多于数据点个数时,我们面临“过度拟合”的风险。
为了避免过度拟合并提高鲁棒性, Denoising Autoencoder (Vincent et al. 2008) 提出了对基本 AutoEncoder 的修改。通过以随机方式向输入向量的某些值添加噪声或
其中
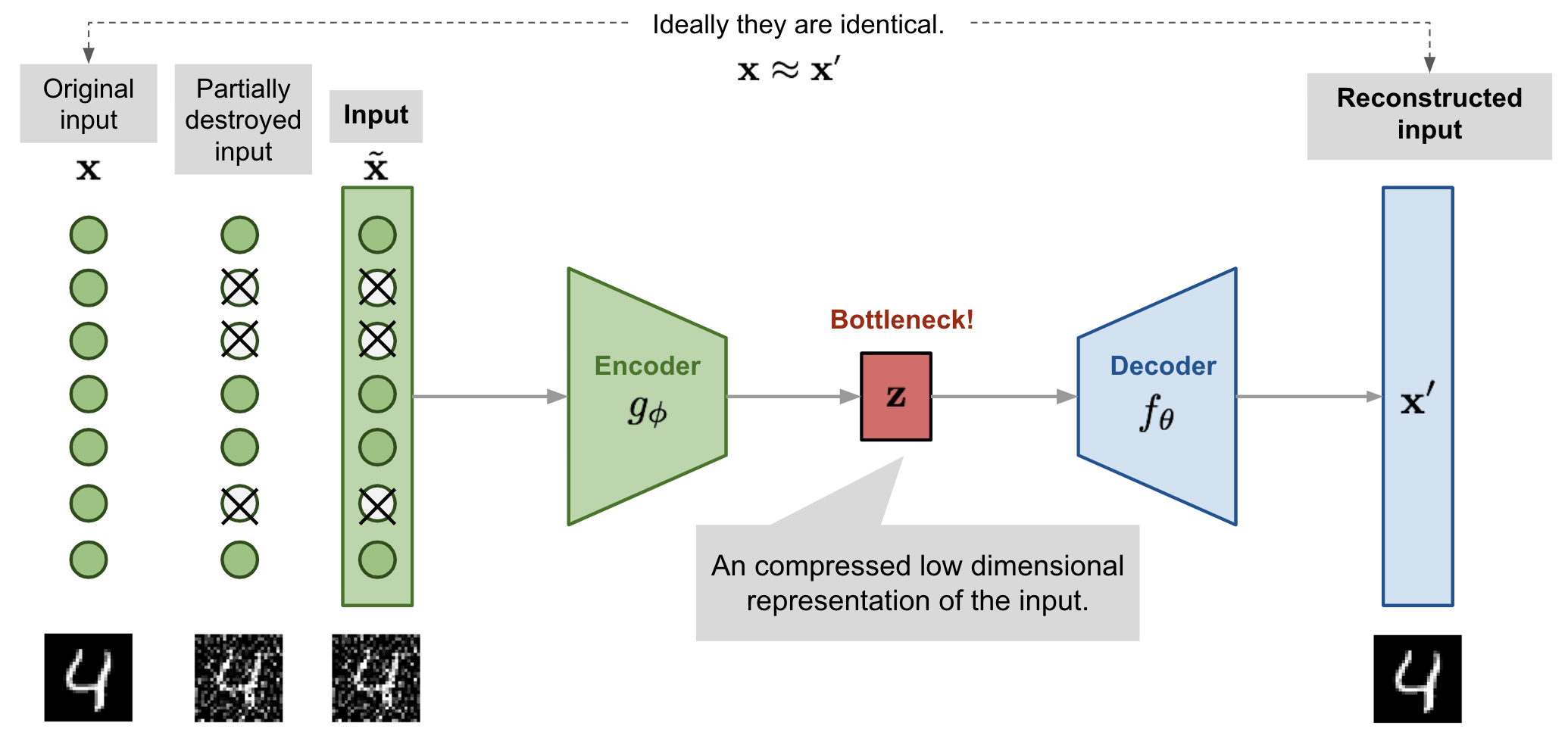
图 2. 去噪 AutoEncoder 模型架构图。
这种设计的动机是,即使视图被部分遮挡或损坏,人类也可以轻松识别物体或场景。为了“修复”部分损坏的输入,去噪 AutoEncoder 必须发现并捕获输入维度之间的关系,以便推断缺失的部分。
对于具有高冗余度的高维输入(如图像),模型可能依赖于从许多输入维度的组合中收集的证据来恢复去噪版本,而不是过度拟合一个维度。这为学习强大的潜在表示奠定了良好的基础。
噪声由随机映射
在原始 DAE 论文的实验中,是这样应用噪声的:随机选择固定比例的输入维度,并将它们的值强制为 0。听起来很像 dropout,对吧?好吧,去噪 AutoEncoder 是在 2008 年提出的,比 dropout 论文早了 4 年(Hinton,等人,2012 年);)
4. 稀疏 AutoEncoder
稀疏自动编码器对隐藏单元激活应用“稀疏”约束,以避免过度拟合并提高稳健性。它强制模型只有少量隐藏单元同时被激活,或者换句话说,隐藏神经元在大部分时间应该是不活动的。
回想一下,常见的激活函数包括 sigmoid、tanh、relu、leaky relu 等。神经元在值接近 1 时激活,在值接近 0 时不激活。
假设在第
该约束是通过在损失函数中添加惩罚项来实现的。KL 散度
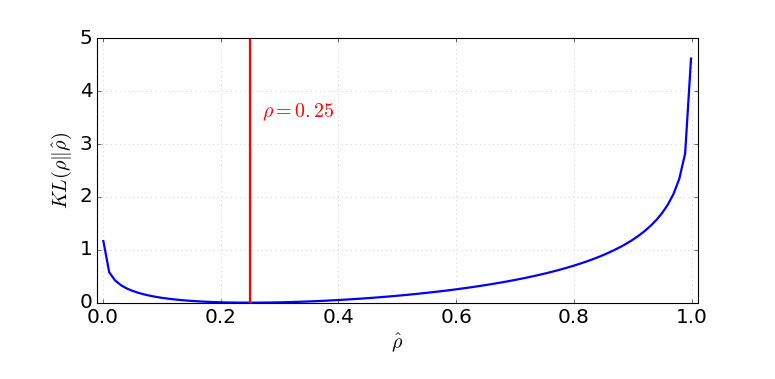
图 4. 具有均值
和具有均值的伯努利分布 之间的 KL 散度
5.
在

图 5. 不同稀疏度 k 的 k-稀疏 AutoEncoder 的过滤器,从具有 1000 个隐藏单元的 MNIST 中学习。(图片来源:Makhzani 和 Frey,2013 年)
6. 收缩 AutoEncoder
与稀疏 AutoEncoder 类似,收缩AutoEncoder( Rifai, et al, 2011 ) 鼓励学习的表示留在收缩空间中以获得更好的鲁棒性。
它在损失函数中添加了一个项来惩罚对输入过于敏感的表示,从而提高对训练数据点周围小扰动的鲁棒性。灵敏度是通过编码器激活的雅可比矩阵相对于输入的 Frobenius 范数来衡量的:
其中
该惩罚项是学习编码相对于输入维度的所有偏导数的平方和。作者声称,根据经验,发现这种惩罚可以刻画对应于低维非线性流形的表示,同时对与流形正交的多数方向保持更大的不变性。
7. VAE:变分 AutoEncoder
Variational Autoencoder ( Kingma & Welling, 2014 ) 的缩写VAE的思想实际上与上述所有 AutoEncoder 模型不太相似,但深深植根于变分贝叶斯和图模型的方法。
不是将输入映射到固定向量,而是将其映射到分布。我们将参数化为
- Prior
- Likelihood
- Posterior
假设我们知道对于这个分布的真实参数
- 首先,从先验分布
采样 . - 然后由条件分布
生成一个值 .
最优参数
通常我们使用对数概率将 RHS 上的乘积转换为总和:
现在我们更新方程以更好地演示数据生成过程,从而导出编码向量:
不幸的是,以这种方式计算
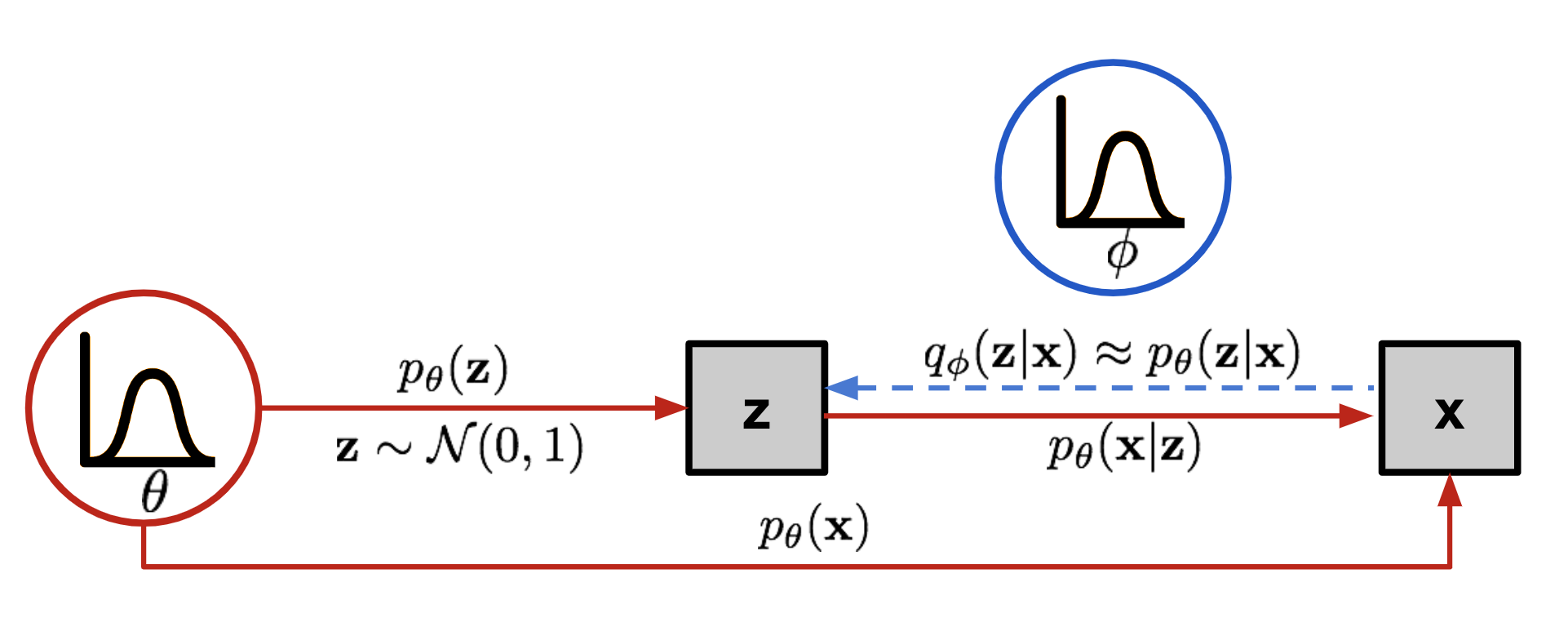
图 6. Variational Autoencoder 涉及的图形模型。实线表示生成分布
虚线表示分布 来近似难以处理的 posterior .
现在,这个结构看起来很像一个 AutoEncoder:
- 条件概率
定义一个生成模型,类似于上面介绍过的解码器 。 也称为概率解码器。 - 逼近函数
是概率编码器,起着和 类似的作用。
7.1 损失函数:ELBO
估计后验
在我们的例子中,我们想最小化
但是为什么要用
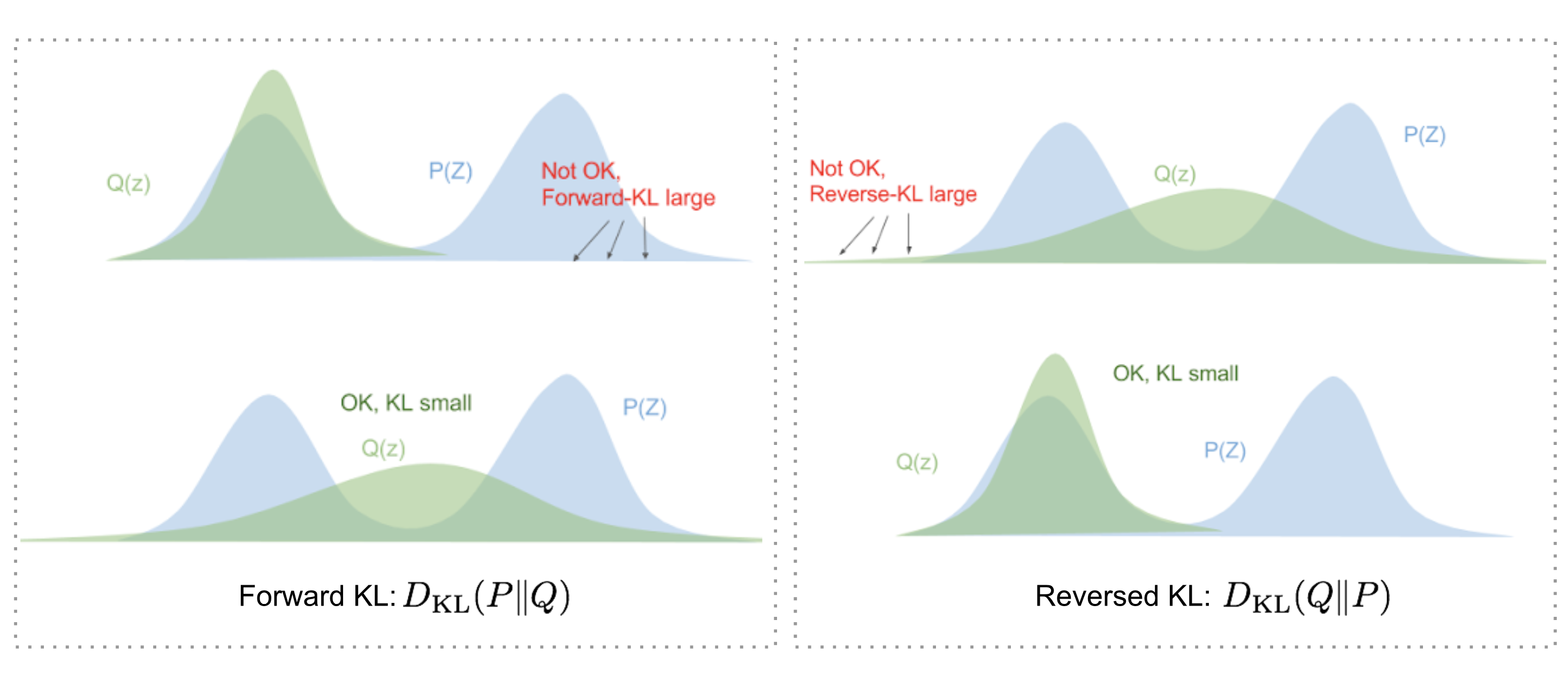
图 7. 正向和反向 KL 散度对如何匹配两个分布有不同的要求。(图片来源:blog.evjang.com/2016/08/variational-bayes.html)
- 前向 KL 散度:
; 我们必须确保 P(z)>0 时 Q(z)>0。优化的变分分布 必须覆盖整个 。 - 反向 KL 散度:
; 最小化反向 KL 散度, 在 下, 压缩 .
现在让我们扩展等式:
所以我们有:
重新排列等式的左侧和右侧,
等式的 LHS 正是我们在学习真实分布时想要最大化的:我们想要最大化生成真实数据的(对数)似然(即日志
上面的定义了我们的损失函数:
在变分贝叶斯方法中,此损失函数称为变分下界或证据下界。名称中的“下界”部分来自于 KL 散度始终为非负的事实,因此
因此,通过最小化损失,我们正在最大化生成真实数据样本的概率下限。
7.2 重新参数化技巧
损失函数中的期望项调用生成样本
例如,常见的选择形式
其中⊙指的是逐元素乘积。
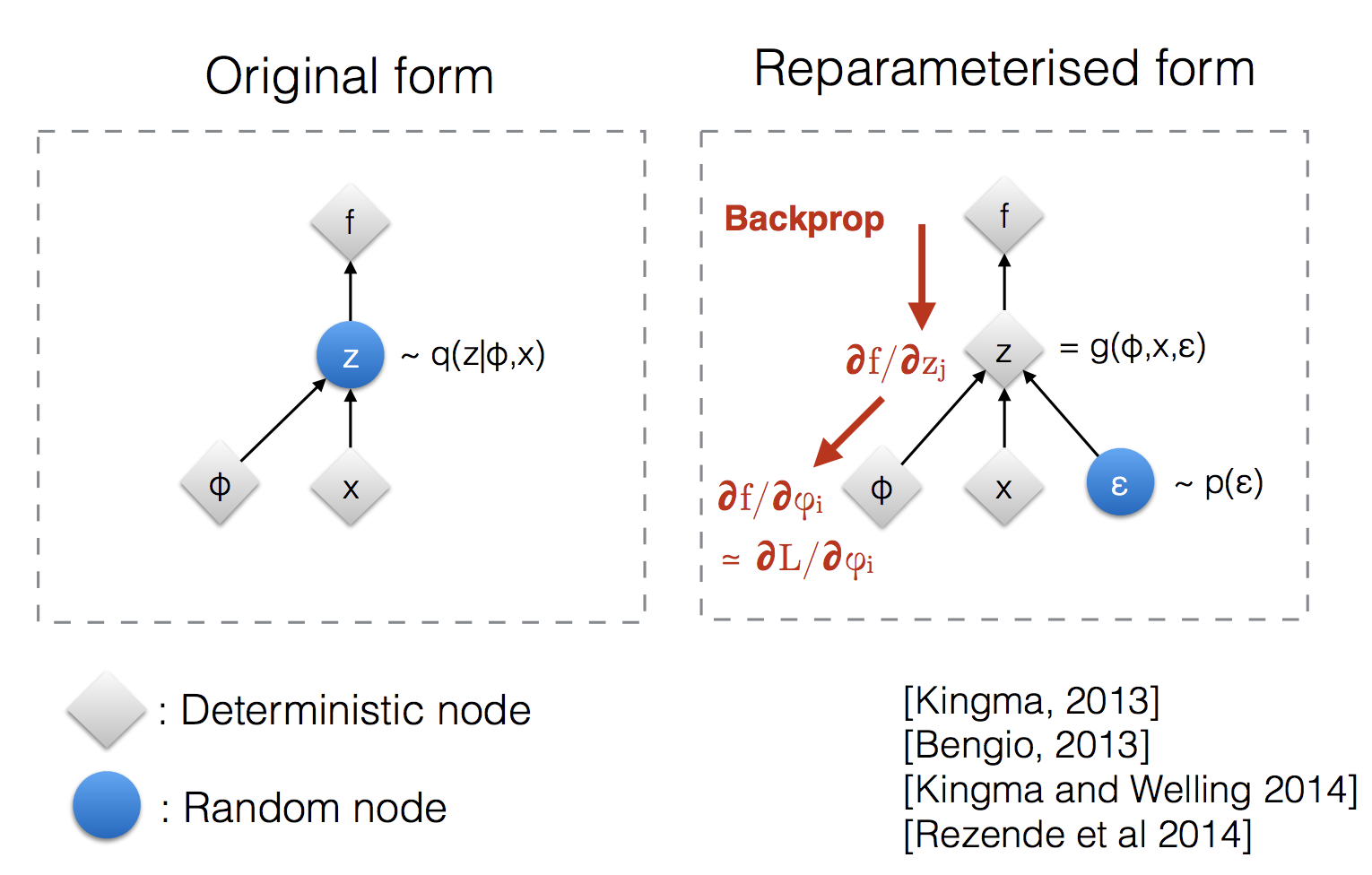
图 8. 重参数化技巧如何使
采样过程可训练。(图片来源:Kingma 的 NIPS 2015 研讨会演讲中的幻灯片 12 )
重参数化技巧也适用于其他类型的分布,而不仅仅是高斯分布。在多元高斯情况下,我们通过学习分布的均值和方差,
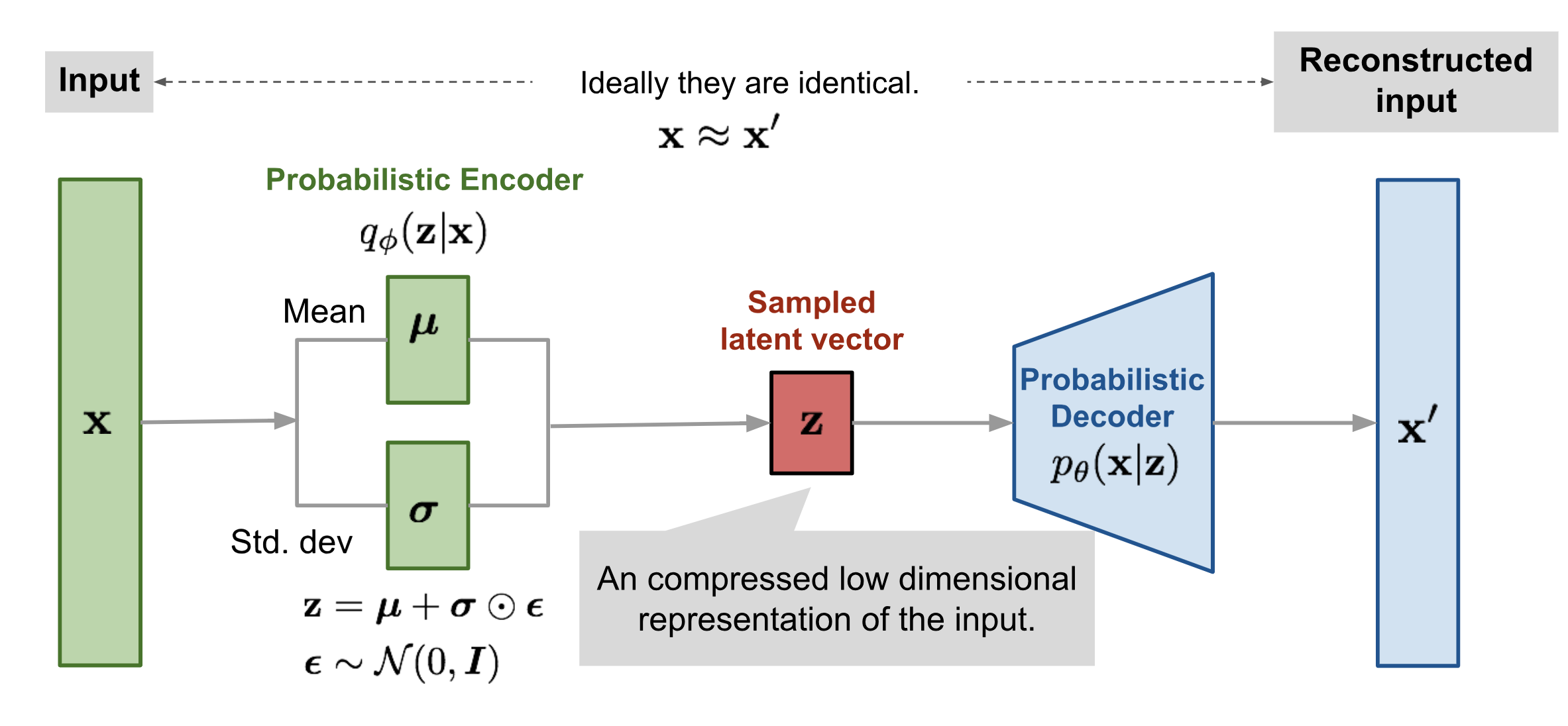
图 9. 具有多元高斯假设的变分 AutoEncoder 模型的图示。
8. Beta-VAE
如果推断的潜在表示中的每个变量
例如,一个基于人脸照片训练的模型可能会在不同的维度上捕捉到温柔、肤色、头发颜色、头发长度、情绪、是否戴眼镜等许多其他相对独立的因素。这种解构表示对人脸图像的生成非常有利。
β-VAE ( Higgins et al., 2017 ) 是变分 AutoEncoder 的一种改进,特别强调发现解构潜在因子。在 VAE 中遵循相同的动机,我们希望最大化生成真实数据的概率,同时保持真实后验分布和估计后验分布之间的距离很小(比如,在一个小常数 d 下):
我们可以将其重写在KKT 条件下带有拉格朗日乘数
其中拉格朗日乘数
由于否定
当
伯吉斯等人。(2017)讨论了在
9. VQ-VAE 和 VQ-VAE-2
VQ-VAE 模型(“矢量量化变分 AutoEncoder”;van den Oord 等人,2017 年)通过编码器学习离散隐变量,因为离散表示可能更自然地适合语言、语音、推理等问题,等等
矢量量化 (VQ) 是一种将
让
编码器输出
请注意,离散隐变量在不同的应用程序中可以具有不同的形状;例如,1D 用于语音,2D 用于图像,3D 用于视频。
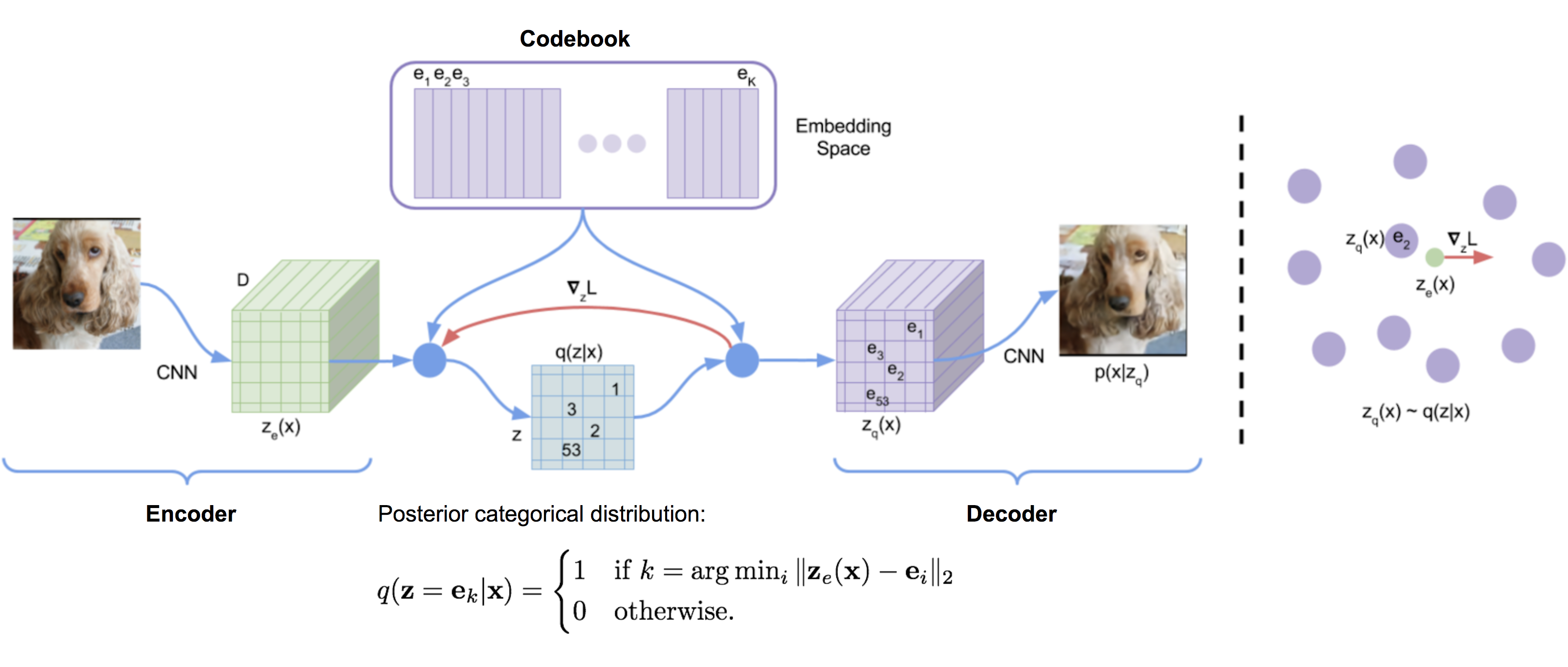
图 10. VQ-VAE 的架构(图片来源:van den Oord, et al. 2017)
因为 argmin() 在离散空间上不可微,所以来自解码器输入
- VQ 损失:嵌入空间和编码器输出之间的 L2 误差。
- 重建损失:一种鼓励编码器输出靠近嵌入空间并防止它从一个编码向量到另一个编码向量波动过于频繁的措施。
其中stop_gradient运算符。
嵌入向量通过 EMA(指数移动平均)更新。给定一个编码向量
其中(
VQ-VAE-2 ( Ali Razavi, et al. 2019 ) 是一个结合自注意力自回归模型的两层的层次结构的 VQ-VAE 。
- 阶段 1 是训练分层 VQ-VAE:分层隐变量的设计旨在将局部信息(即纹理)与全局信息(即对象形状)分开。较大的底层编码的训练是以较小的顶层编码为条件的,因此它不必从头开始学习所有内容。
- 第 2 阶段是在潜在的离散 codebook 上学习先验知识,以便我们从中采样并生成图像。通过这种方式,解码器可以接收与训练中的分布相似的分布中采样的输入向量。使用多头自注意力层增强的强大自回归模型用于捕获先验分布(如PixelSNAIL;Chen 等人 2017)。
考虑到 VQ-VAE-2 依赖于在简单的分层设置中配置的离散隐变量,其生成的图像质量非常惊人。
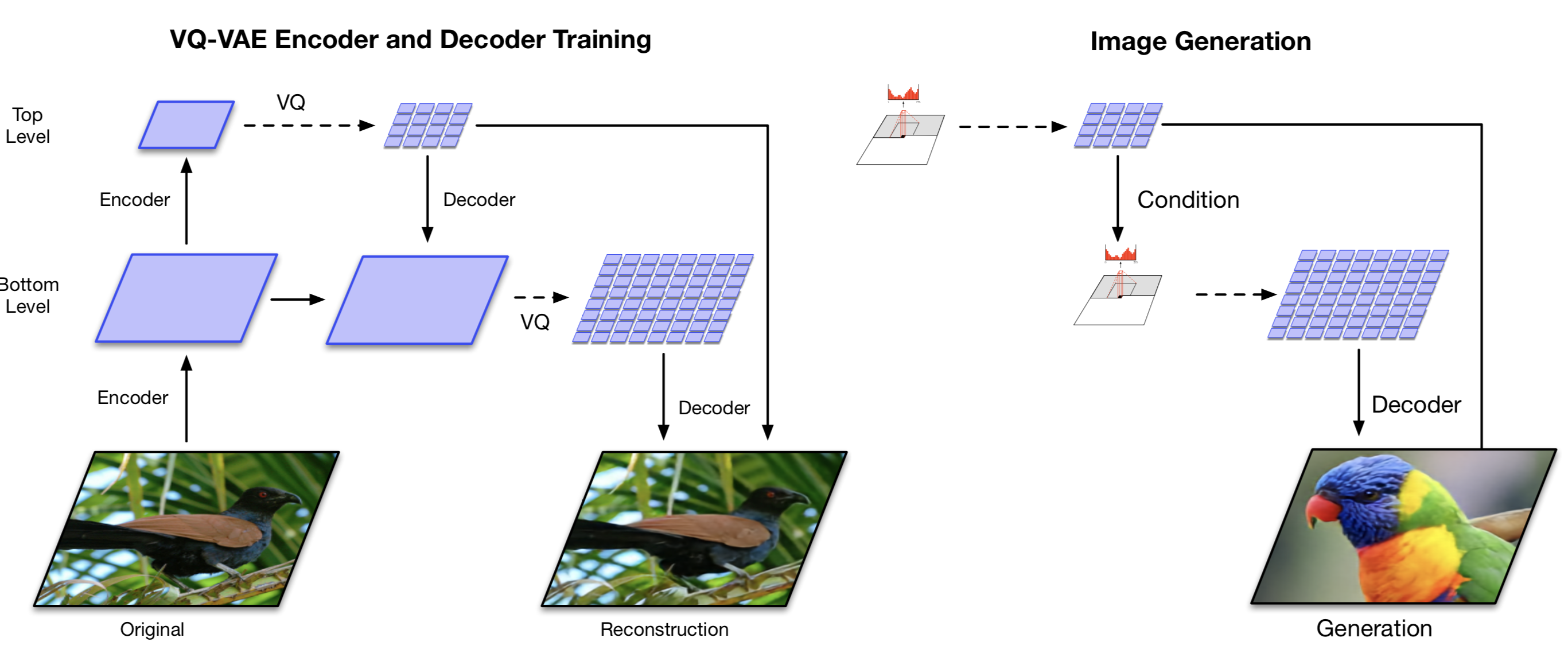
图 11. 分层 VQ-VAE 和多阶段图像生成的架构。(图片来源:Ali Razavi, et al. 2019)

VQ-VAE-2 算法。(图片来源:Ali Razavi, et al. 2019)
10. TD-VAE
TD-VAE(“Temporal Difference VAE”;Gregor 等人,2019 年)处理时序数据。它依赖于三个主要思想,如下所述。
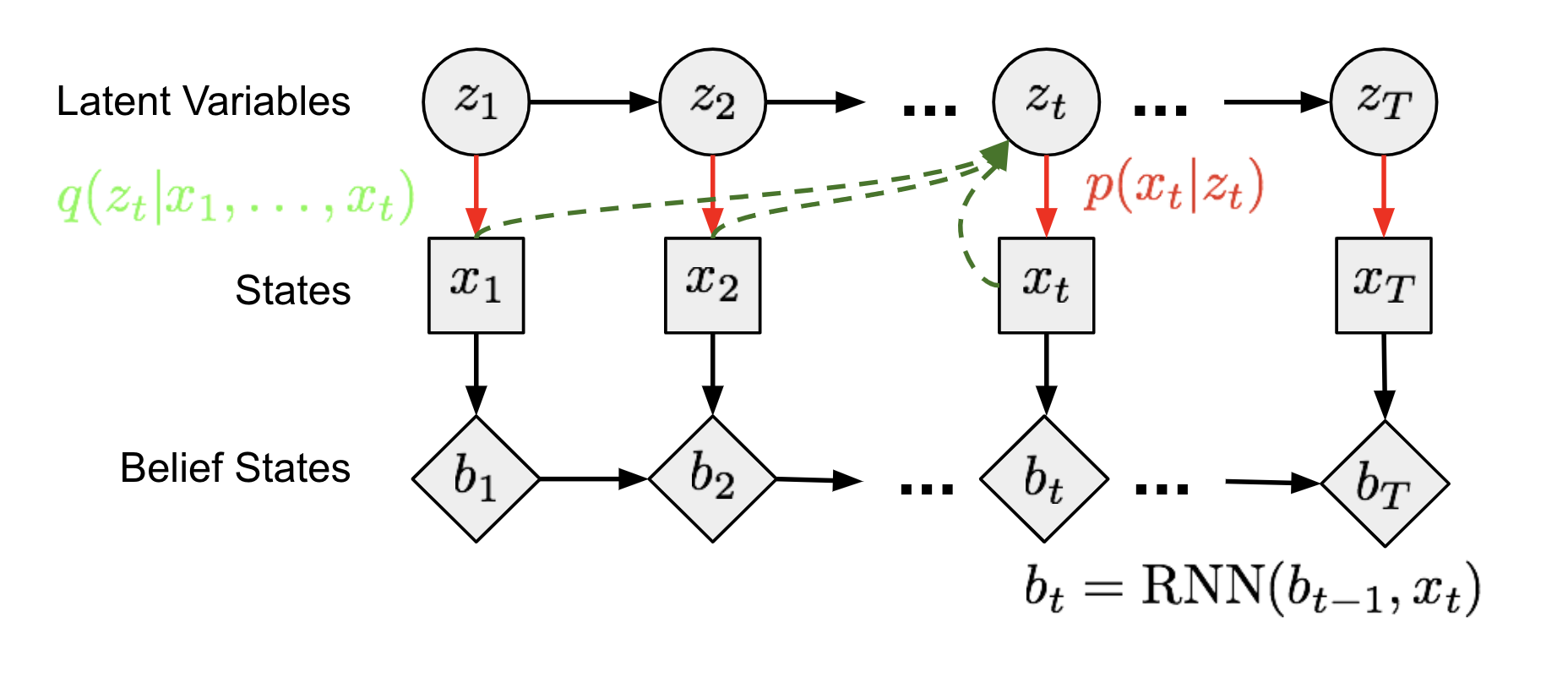
图 13. 作为马尔可夫链模型的状态空间模型。
1. 状态空间模型
在(潜在)状态空间模型中,一系列未观察到的隐藏状态
图 13 中的马尔可夫链模型中的每个时间步都可以用与图 6 类似的方式进行训练,其中难处理的后验
2. 信念状态
Agent 应该学习对所有过去的状态进行编码以推理未来,称为信念状态,
3. 跳跃式预测
此外,智能体需要根据目前收集到的所有信息来想象遥远的未来,这表明具有跳跃式预测的能力,即预测未来几个步骤的状态。
回想一下我们从上面的方差下限中学到的东西:
现在让我们模拟状态的分布
继续扩大等式:
注意两点:
- 根据马尔可夫假设,可以忽略红色项。
- 蓝色项根据马尔可夫假设展开。
- 绿色项被扩展为包括回到过去的一步预测作为平滑分布。
准确地说,有四种类型的分布需要学习:
是解码器分布:
是通用定义的编码器;
是过渡分布:
捕获隐变量之间的顺序依赖性;
是信念分布:
- 两个
和 都可以使用信念状态来预测隐变量; ; ;
是平滑分布:
- 回到过去的平滑项
也可以重写为依赖于信念状态; ;
为了结合跳跃预测的思想,顺序 ELBO 不仅要在
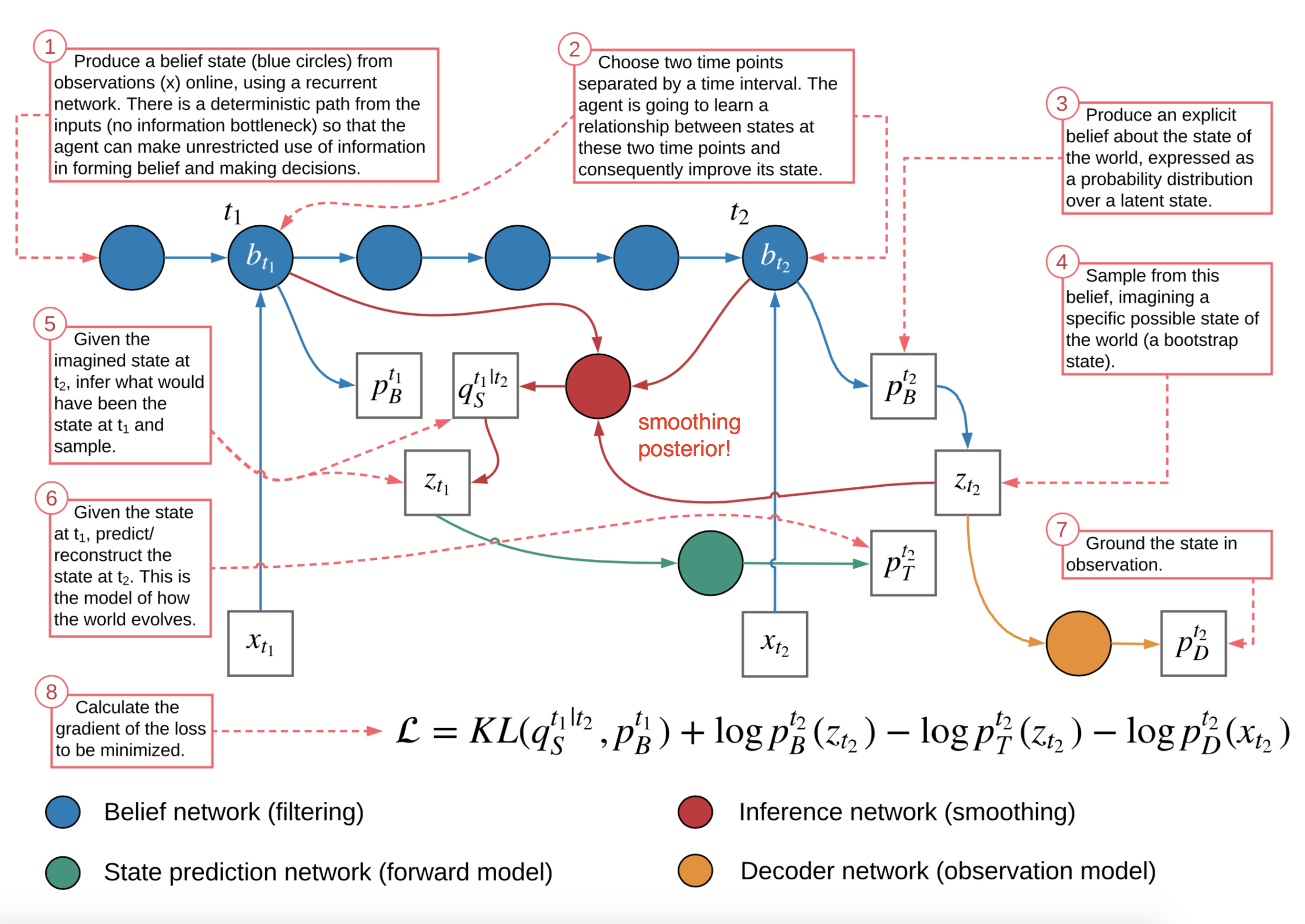
图 14. TD-VAE 架构的详细概述。(图片来源:TD-VAE 论文)
参考
[1] Geoffrey E. Hinton, and Ruslan R. Salakhutdinov. “Reducing the dimensionality of data with neural networks." Science 313.5786 (2006): 504-507.
[2] Pascal Vincent, et al. “Extracting and composing robust features with denoising autoencoders." ICML, 2008.
[3] Pascal Vincent, et al. “Stacked denoising autoencoders: Learning useful representations in a deep network with a local denoising criterion.". Journal of machine learning research 11.Dec (2010): 3371-3408.
[4] Geoffrey E. Hinton, Nitish Srivastava, Alex Krizhevsky, Ilya Sutskever, and Ruslan R. Salakhutdinov. “Improving neural networks by preventing co-adaptation of feature detectors.” arXiv preprint arXiv:1207.0580 (2012).
[5] Sparse Autoencoder by Andrew Ng.
[6] Alireza Makhzani, Brendan Frey (2013). “k-sparse autoencoder”. ICLR 2014.
[7] Salah Rifai, et al. “Contractive auto-encoders: Explicit invariance during feature extraction." ICML, 2011.
[8] Diederik P. Kingma, and Max Welling. “Auto-encoding variational bayes." ICLR 2014.
[9] Tutorial - What is a variational autoencoder? on jaan.io
[10] Youtube tutorial: Variational Autoencoders by Arxiv Insights
[11] “A Beginner’s Guide to Variational Methods: Mean-Field Approximation” by Eric Jang.
[12] Carl Doersch. “Tutorial on variational autoencoders." arXiv:1606.05908, 2016.
[13] Irina Higgins, et al. "β-VAE: Learning basic visual concepts with a constrained variational framework." ICLR 2017.
[14] Christopher P. Burgess, et al. “Understanding disentangling in beta-VAE." NIPS 2017.
[15] Aaron van den Oord, et al. “Neural Discrete Representation Learning” NIPS 2017.
[16] Ali Razavi, et al. “Generating Diverse High-Fidelity Images with VQ-VAE-2”. arXiv preprint arXiv:1906.00446 (2019).
[17] Xi Chen, et al. “PixelSNAIL: An Improved Autoregressive Generative Model." arXiv preprint arXiv:1712.09763 (2017).
[18] Karol Gregor, et al. “Temporal Difference Variational Auto-Encoder." ICLR 2019.