什么是扩散模型:综述
扩散模型的灵感来自非平衡热力学。它定义了一个扩散步骤的马尔可夫链,逐步向数据添加随机噪声,然后学习逆转该过程,从而从噪声中构建所需的数据样本。与 VAE 或流模型不同,扩散模型通过固定过程学习,且潜在变量与原始数据同维。

1. 什么是扩散模型?
已经提出了几种基于扩散的生成模型,这些模型具有相似的思想,包括扩散概率模型(Sohl-Dickstein 等人,2015 年)、噪声条件分数网络(NCSN;Yang 和 Ermon,2019 年)和去噪扩散概率模型(DDPM;Ho 等人,2020 年)。
1.1 前向扩散过程
给定一个从真实分布中采样的数据
当
上述过程的一个很好的特性是,利用重参数化技巧可以在任意时间步
() 回想一下,当我们合并两个具有不同方差的高斯分布,
通常,当样本噪声更大时,可以承受更大的更新步长,所以
1.1.1 与随机梯度朗之万动力学的联系
朗之万动力学(Langevin dynamics )是物理学的一个概念,用于统计建模分子系统。结合随机梯度下降,随机梯度 Langevin 动力学( Welling & Teh 2011 ) 可以在一系列更新的马尔可夫链中仅使用
其中
与标准随机梯度下降 SGD 相比,随机梯度 Langevin 动力学将高斯噪声注入参数更新,以避免陷入局部最小值。
1.2 反向扩散过程
如果说前向过程(forward)是加噪的过程,那么逆向过程(reverse)就是扩散模型的去噪过程,也称为生成过程。
如果我们可以反转上述过程并从
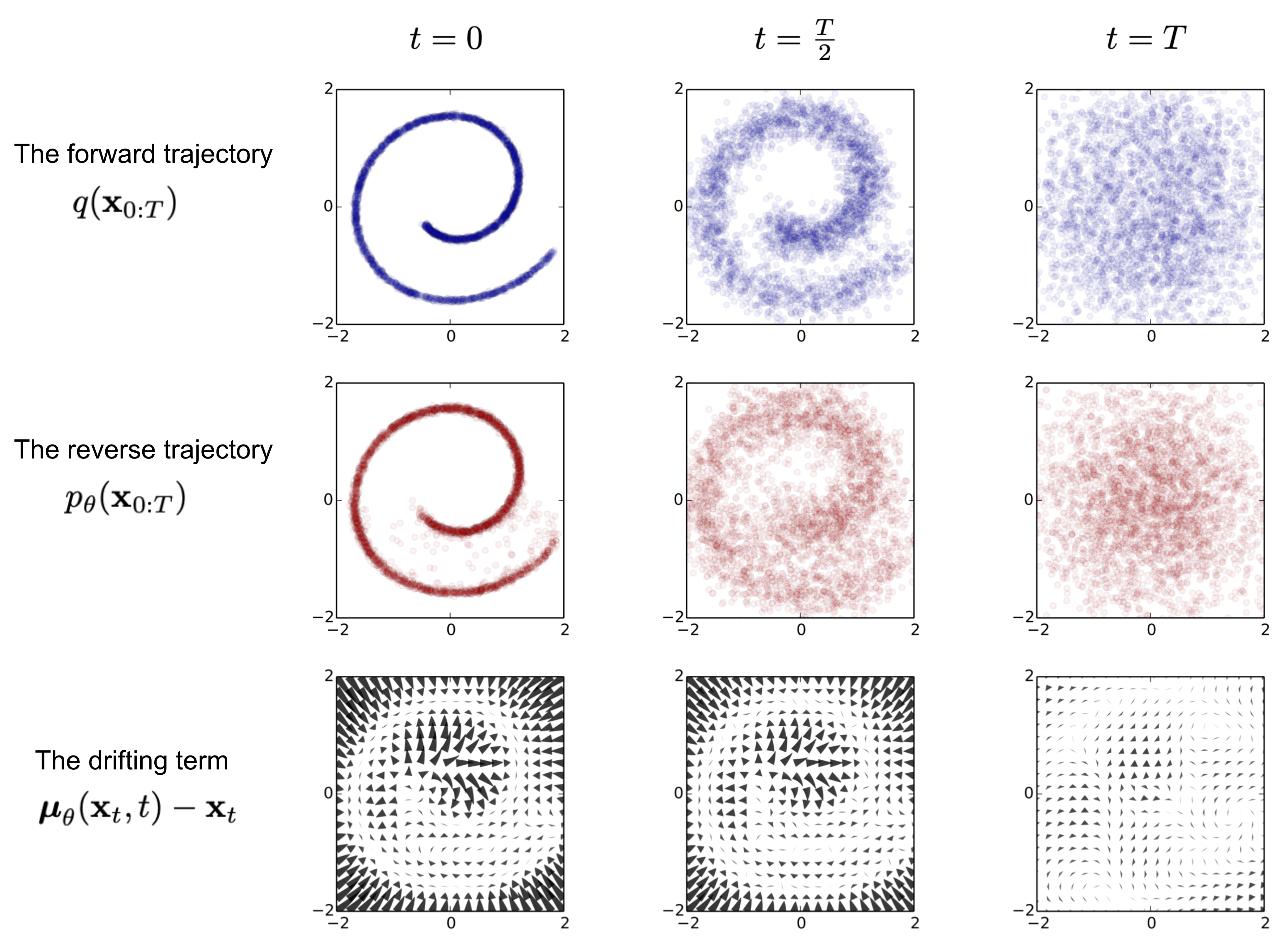
Fig. 3. An example of training a diffusion model for modeling a 2D swiss roll data. (Image source: Sohl-Dickstein et al., 2015)
值得注意的是,以
使用贝叶斯法则,我们有:
其中
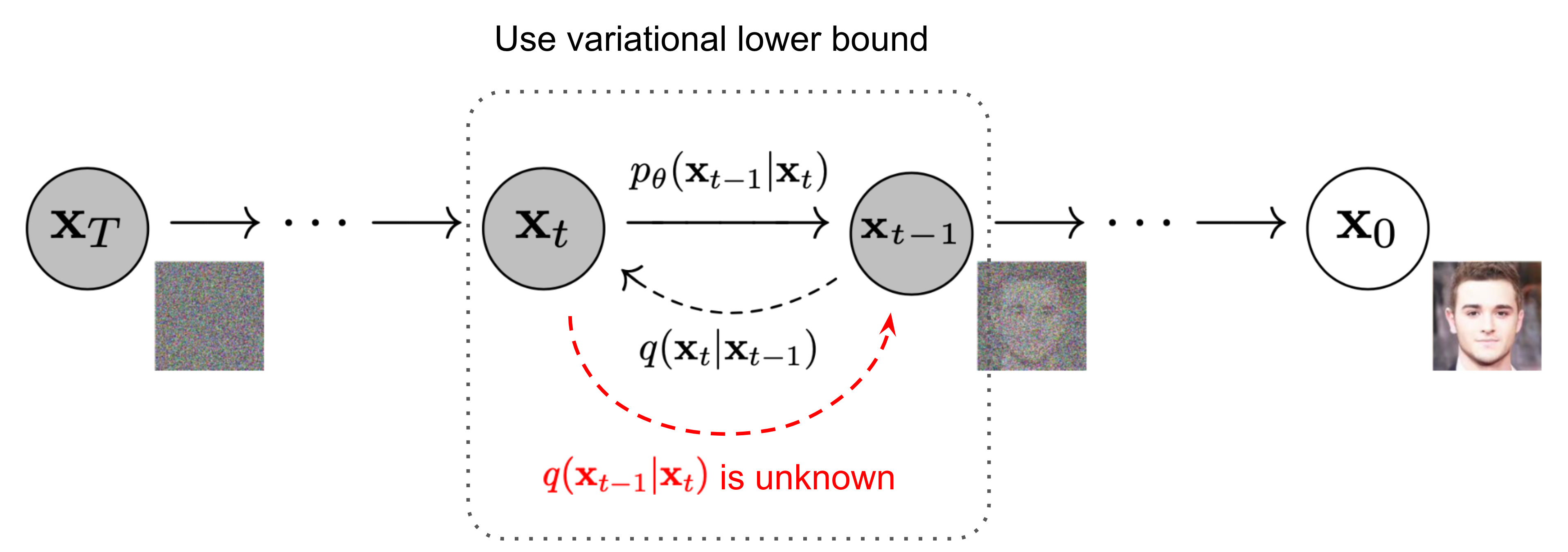
由于这个良好的属性,我们可以表示
如图 2 所示,这种设置与VAE非常相似,因此我们可以使用变分下界来优化负对数似然。
使用 Jensen 不等式也可以直接得到相同的结果。假设我们以最小化交叉熵作为学习目标,
为了将方程中的每一项转换为可分析计算的,目标可以进一步重写为几个 KL 散度和熵项的组合(参见Sohl-Dickstein 等人的附录 B 中详细的推导过程)
我们分别标记变分下界损失中的每个组件:
1.3 对于训练损失参数化
回想一下,我们需要学习一个神经网络来逼近反向扩散过程中的条件概率分布,
损失项
1.4 简化
Ho et al. (2020) 实证发现,使用一个简化的目标函数,忽略权重项,可以更好地训练扩散模型:
最终的简化目标是:
其中

图 4. DDPM 中的训练和采样算法(图片来源:Ho et al. 2020)
1.5 与噪声条件分数网络(NCSN)的联系
Song & Ermon (2019)提出了一种基于分数的生成建模方法,其中样本是使用分数匹配估计的数据分布梯度,通过Langevin 动力学 产生的。每个样本
为了使其在深度学习中扩展到高维数据,他们建议使用去噪分数匹配( Vincent, 2011 ) 或切片分数匹配(使用随机投影;Song 等人,2019)。去噪分数匹配向数据
回想一下, Langevin 动力学可以在迭代过程中仅使用分数
然而,根据流形假设,大多数数据预计会集中在低维流形中,即使观察到的数据可能看起来是任意高维。由于数据点无法覆盖整个空间,因此会对分数估计产生负面影响。在数据密度低的区域,分数估计不太可靠。加入小的高斯噪声后,使得扰动后的数据分布覆盖全空间
增加噪声水平的时间表类似于前向扩散过程。如果我们使用扩散过程注释,分数近似于
1.6
在 Ho 等人(2020) 的工作中, 前向方差被设置为一系列线性增加的常数, 从
Nichol & Dhariwal (2021)提出了几种改进技术来帮助扩散模型获得更低的 NLL。其中一项改进是使用基于余弦的方差表。调度函数的选择可以是任意的,只要它在训练过程中提供近乎线性下降, 并在
其中小偏移量
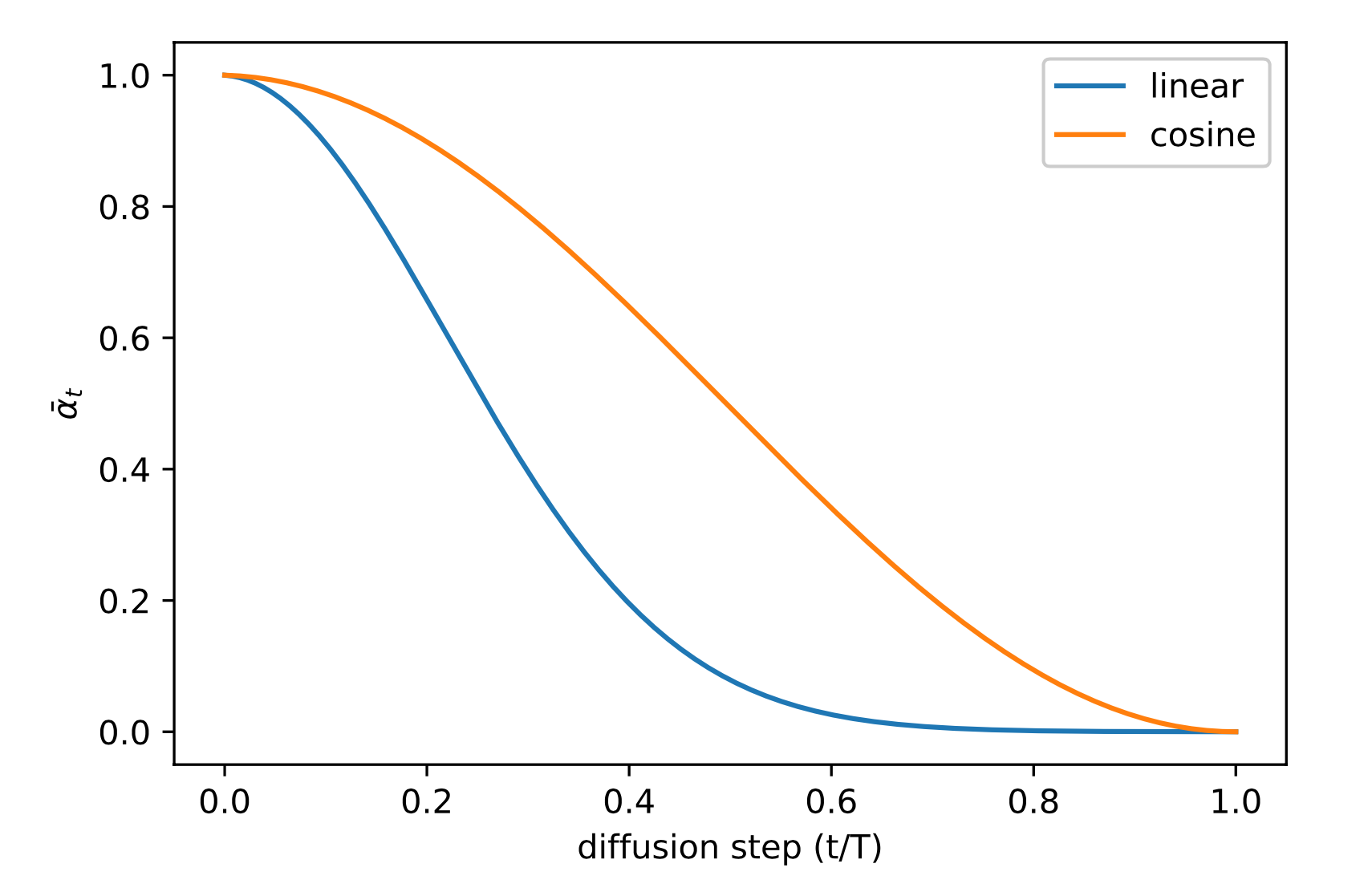
Fig. 5. Comparison of linear and cosine-based scheduling of
during training. (Image source: Nichol & Dhariwal, 2021)
1.7 逆过程方差的参数化
Ho et al. (2020) 将
Nichol & Dhariwal (2021)建议通过模型预测混合向量
然而,简单的目标
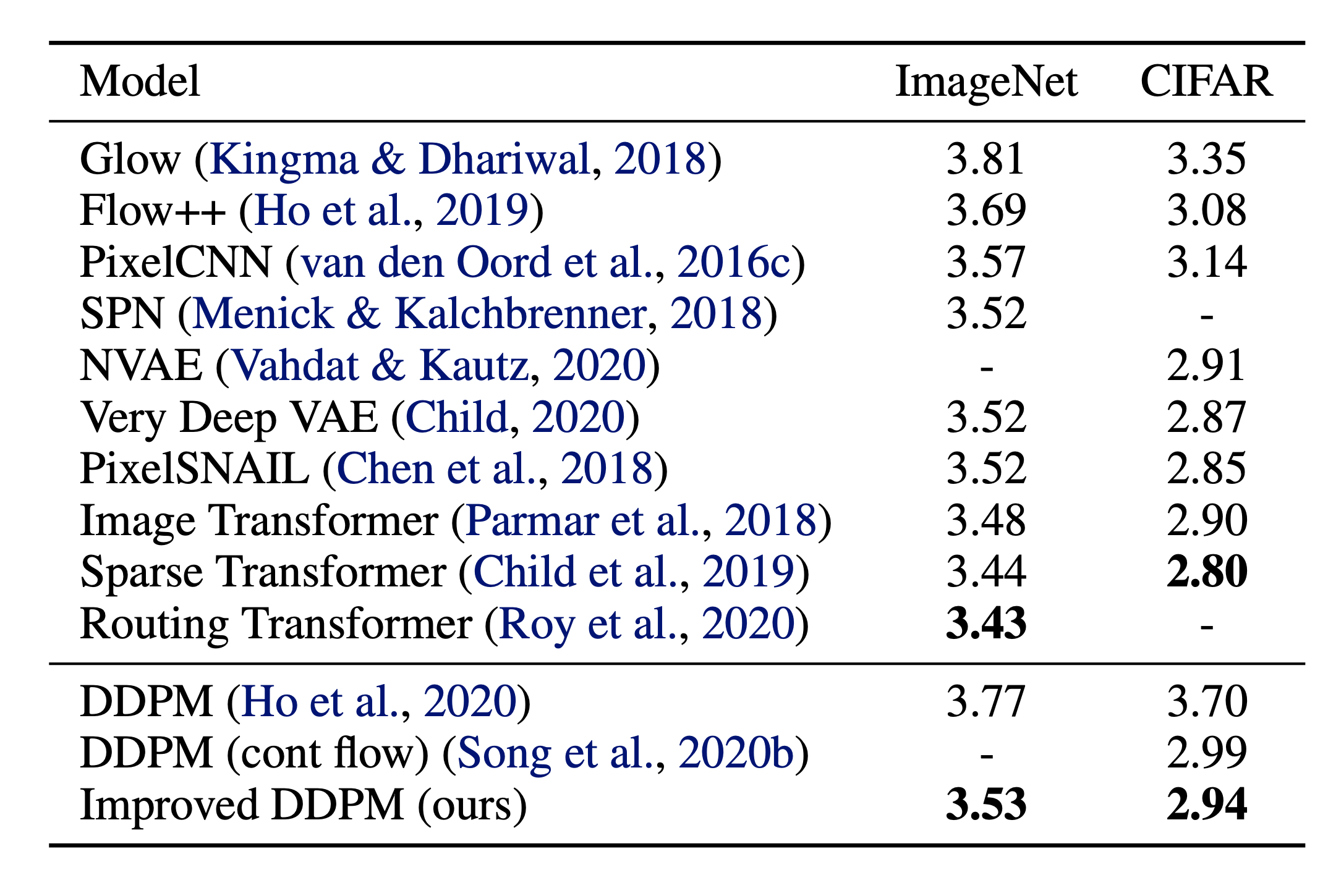
图 6. 改进的 DDPM 与其他基于似然的生成模型的负对数似然比较。NLL 以 bits/dim 为单位报告。(图片来源:Nichol & Dhariwal,2021 年)
2. 条件生成
在使用 ImageNet 数据集等条件信息对图像训练生成模型时,通常会生成以类标签或一段描述性文本为条件的样本。
2.1 分类器引导扩散
为了明确地将类信息纳入扩散过程,Dhariwal & Nichol (2021) 在噪声图像
因此,一个新的分类器引导预测器
为了控制分类器引导的强度,我们可以向增量部分添加一个权重
结果,去除扩散模型(ADM)和带有额外分类器引导的模型(ADM-G)能够比 SOTA 生成模型(例如 BigGAN)取得更好的结果。

图 7. 使用分类器引导在 DDPM 和 DDIM 中进行条件生成的算法。(图片来源:,Dhariwal & Nichol (2021))
此外,通过对 U-Net 架构的一些修改,Dhariwal & Nichol (2021)展示了扩散模型的性能优于 GAN。架构修改包括更大的模型深度/宽度、更多的注意力头、多分辨率注意力、用于上/下采样的 BigGAN 残差块、残差连接重缩放为
2.2 无分类器引导
没有独立的分类器
隐式分类器的梯度可以用条件和非条件分数估计器表示。一旦插入到分类器引导的修改分数中,分数就不再依赖于单独的分类器。
他们的实验表明,无分类器引导可以在 FID(区分合成和生成图像)和 IS(质量和多样性)之间取得良好的平衡。
引导扩散模型 GLIDE ( Nichol, Dhariwal & Ramesh, et al. 2022 ) 探索了两种引导策略,CLIP 引导和无分类器引导,并发现后者更受青睐。他们推测这是因为 CLIP 引导利用了对 CLIP 模型的对抗性示例,而不是优化更好的匹配图像生成。
3. 加速扩散模型
通过遵循反向扩散过程的马尔可夫链,从 DDPM 生成样本速度非常慢,因为
3.1 更少的采样步骤和蒸馏
一种简单的方法是运行跨步采样计划(Nichol & Dhariwal,2021),每隔
对于另一种方法,让我们根据所需的标准偏差进行参数化
回想一下,
让
在生成过程中,我们不必遵循整个链
虽然,在实验中,所有模型都经过
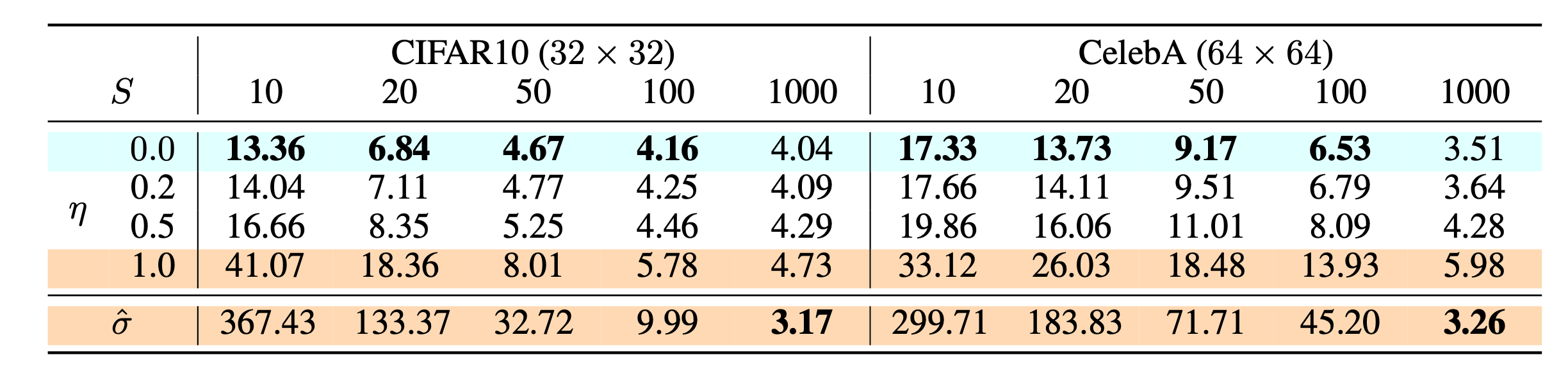
图 8. 在 CIFAR10 和 CelebA 数据集上,不同设置的扩散模型的 FID 得分,包括 DDIM(
) 和 DDPM( ). (图片来源:Song et al., 2020)
与 DDPM 相比,DDIM 能够:
- 使用更少的步骤生成更高质量的样本。
- 具有“一致性”属性,因为生成过程是确定性的,这意味着以相同潜变量为条件的多个样本应该具有相似的高级特征。
- 由于一致性,DDIM 可以在潜在变量中进行语义上有意义的插值。
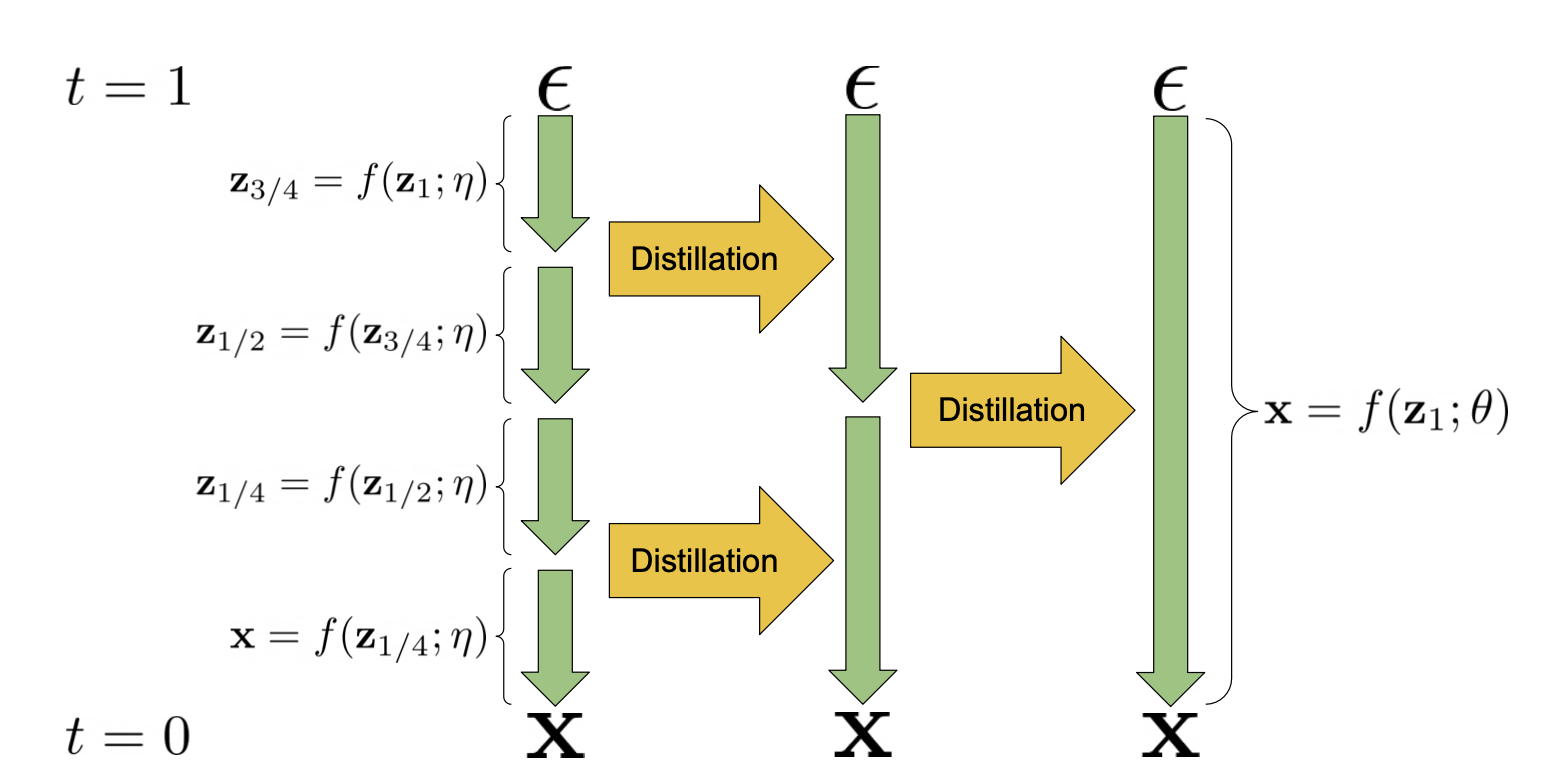
图 9. 渐进蒸馏可以将每次迭代中的扩散采样步骤减少一半。 (图片来源:Salimans & Ho,2022)
3.1.1 渐进式蒸馏
渐进式蒸馏(Salimans 和 Ho,2022)是一种将经过训练的确定性采样器蒸馏为采样步骤减半的新模型的方法。学生模型从教师模型初始化,并朝着一个目标进行去噪,其中一个学生 DDIM 步骤匹配 2 个教师步骤,而不是使用原始样本

图 10. 算法 1(扩散模型训练)和算法 2(渐进式蒸馏)并排比较,其中渐进式蒸馏中的相对变化以绿色突出显示。
3.1.2 一致性模型
一致性模型(Song 等人,2023)学习将扩散采样轨迹上的任何中间噪声数据点

图 11. 一致性模型学习将轨迹上的任何数据点映射回其起源。(图片来源:Song 等人,2023)
给定一个轨迹
一致性模型有可能在单步中生成样本,同时仍然保持在多步采样过程中为了更好的质量而进行计算交换的灵活性。
论文介绍了两种训练一致性模型的方法:
- 一致性蒸馏(CD):通过最小化相同轨迹生成的对生成的模型输出之间的差异,将扩散模型蒸馏到一致性模型。这使得采样评估成本更低。一致性蒸馏损失是:
其中:
是一步 ODE 求解器的更新函数; ,均匀分布在 ; - 网络参数
是 的指数移动平均(EMA)版本,这极大地稳定了训练(就像在 DQN 或动量对比学习中一样); 是一个正的距离度量函数,满足 且 当且仅当 ,例如 , 或 LPIPS(学习感知图像补丁相似性)距离; 是一个正的权重函数,论文中设置 。
- 一致性训练(CT):另一种选择是独立训练一致性模型。注意到在 CD 中,使用预训练的分数模型
来近似真实分数 但在 CT 中我们需要一种方法来估计这个分数函数,并且存在一个无偏估计 。CT 损失定义如下:
根据论文中的实验,他们发现:
- Heun ODE 求解器比欧拉一阶求解器工作得更好,因为具有相同
的高阶 ODE 求解器具有更小的估计误差。 - 在不同的距离度量函数
选项中,LPIPS 度量比 和 距离工作得更好。 - 更小的
导致更快的收敛但更差的样本,而更大的 导致更慢的收敛但在收敛时更好的样本。
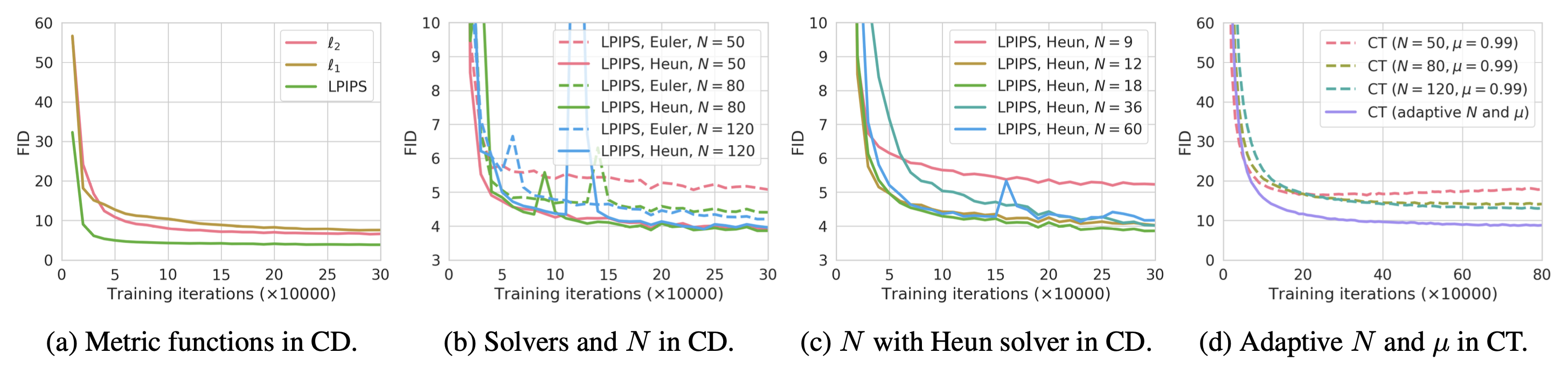
图 12. 在不同配置下的一致性模型性能比较。CD 的最佳配置是 LPIPS 距离度量、Heun ODE 求解器和
。(图片来源:Song 等人,2023)
3.2 潜在变量空间
Latent diffusion model ( LDM ; Rombach & Blattmann, et al. 2022 ) 在隐空间而不是在像素空间中运行扩散过程,使训练成本更低,推理速度更快。这是基于这样的观察:大多数图像的比特贡献于感知细节,而在积极压缩后,语义和概念组合仍然保留。LDM 通过首先使用自动编码器减少像素级冗余,然后在学习到的潜在空间中使用扩散过程操作/生成语义概念,松散地分解了感知压缩和语义压缩。
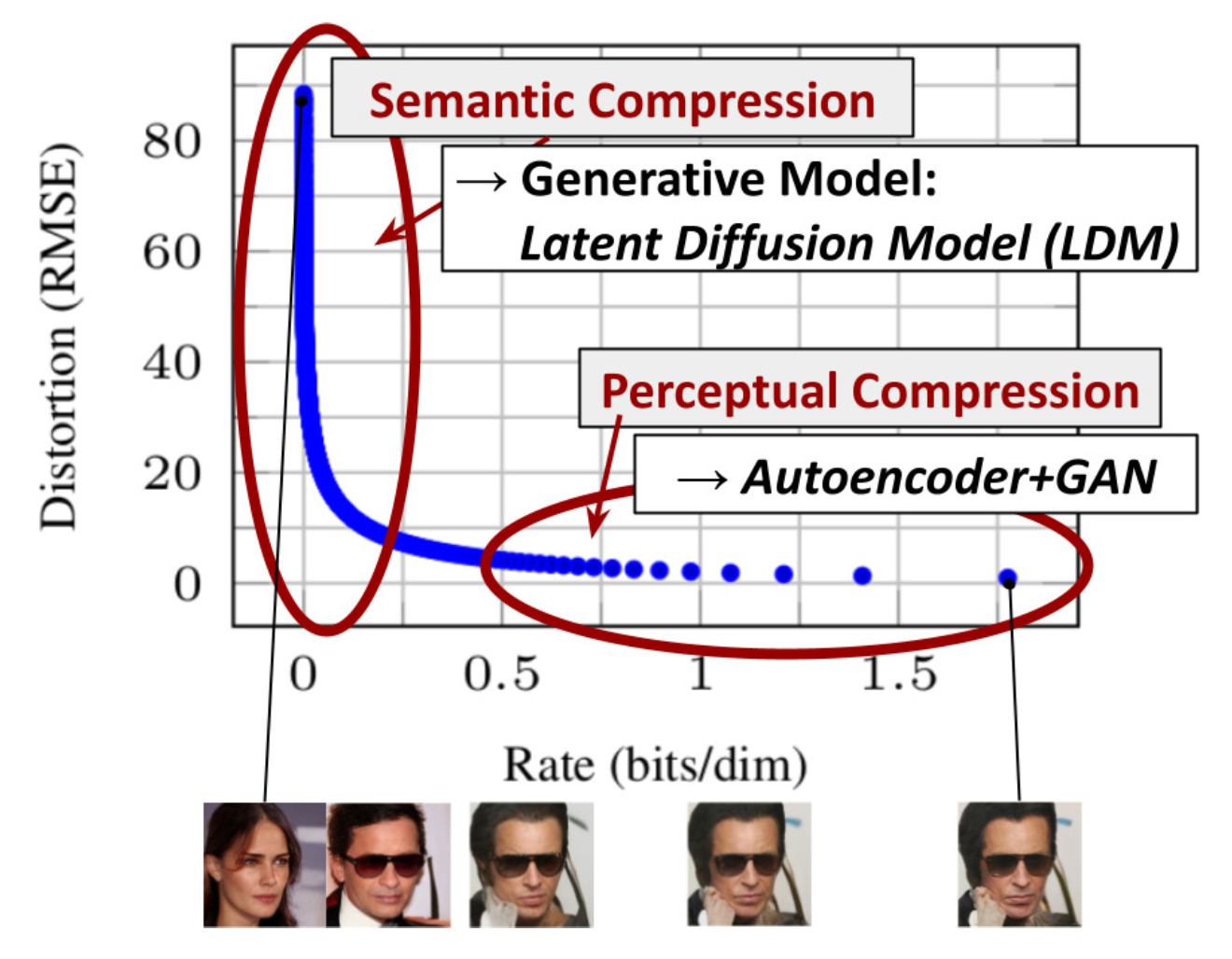
Fig. 13. The plot for tradeoff between compression rate and distortion, illustrating two-stage compressions - perceptural and semantic comparession. (Image source: Rombach & Blattmann, et al. 2022)
感知压缩过程依赖于自动编码器模型。编码器
扩散和去噪过程发生在隐变量
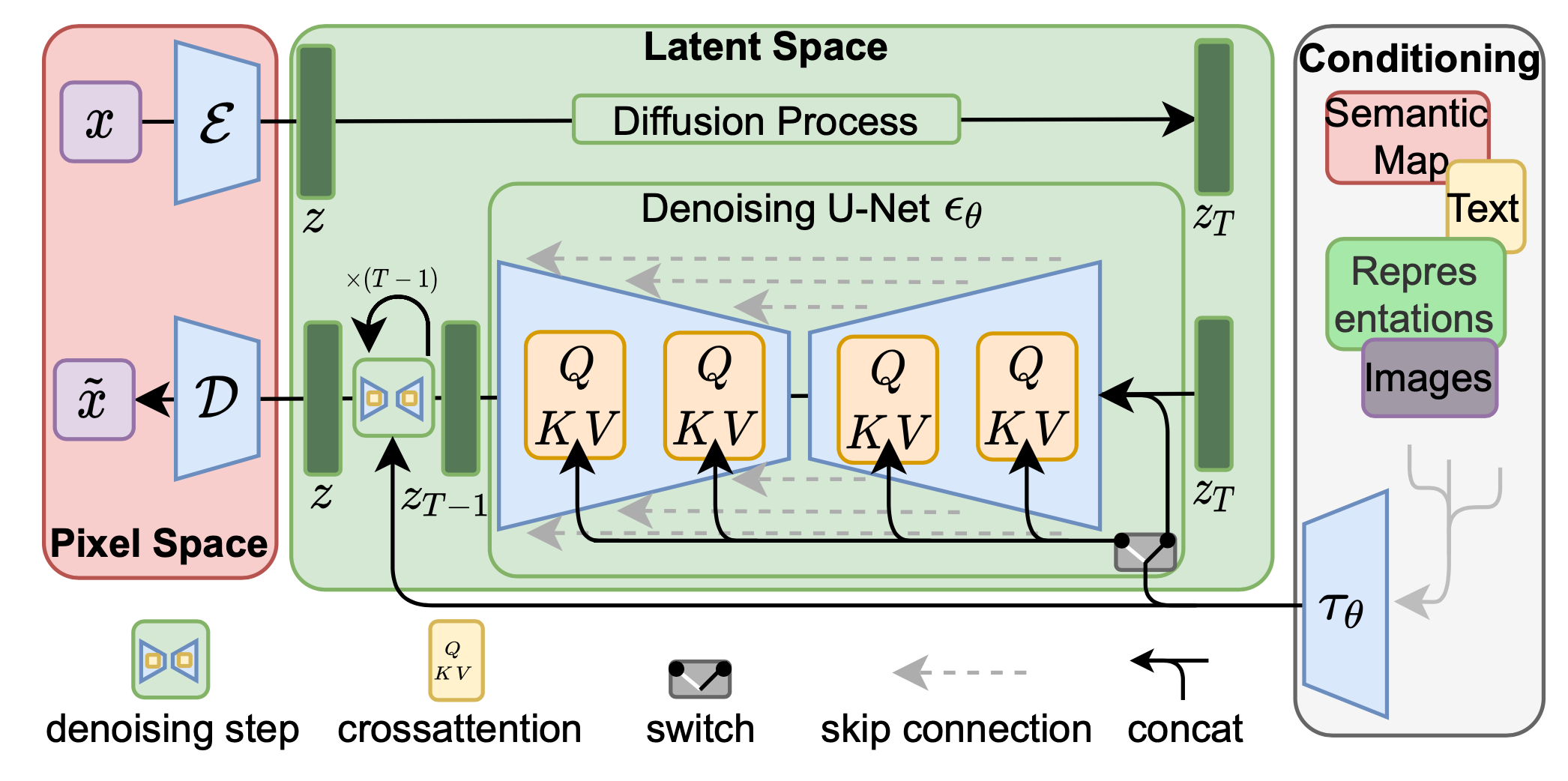
Fig. 14. The architecture of latent diffusion model. (Image source: Rombach & Blattmann, et al. 2022)
4. 提高生成分辨率和质量
为了生成高分辨率的高质量图像,Ho 等人(2021)提出了使用逐步增加分辨率的多个扩散模型的 Pipeline。Pipeline 模型之间的噪声条件增强对最终图像质量至关重要,这是通过对每个超分辨率模型
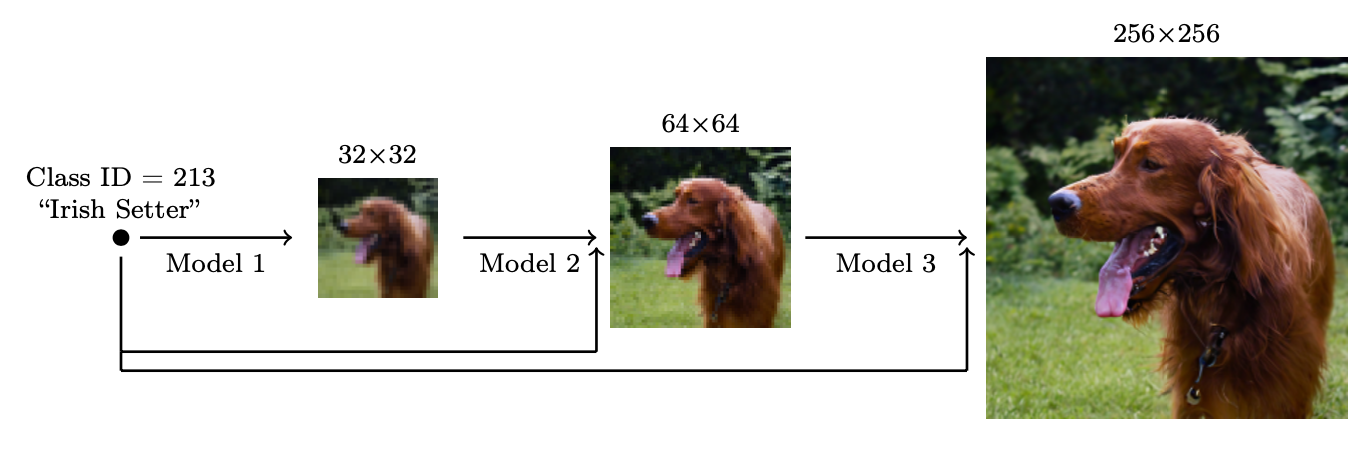
图 15. 逐步增加分辨率的多个扩散模型的级联 Pipeline。(图片来源:Ho 等人,2021)
他们发现最有效的噪声是在低分辨率时应用高斯噪声,在高分辨率时应用高斯模糊。此外,他们还探索了两种形式的条件增强,这需要对训练过程进行小的修改。请注意,条件噪声仅在训练时应用,而不在推理时应用。
- 截断条件增强在低分辨率时提前停止扩散过程,步骤
。 - 非截断条件增强运行完整的低分辨率逆向过程,直到步骤 0,但随后通过
破坏它,然后将破坏的 输入到超分辨率模型中。
4.1 unCLIP
两阶段扩散模型 unCLIP(Ramesh 等人,2022)大量利用 CLIP 文本编码器产生高质量的文本引导图像。给定一个预训练的 CLIP 模型
- 一个先验模型
:给定文本 输出 CLIP 图像嵌入 。 - 一个解码器
:给定 CLIP 图像嵌入 和可选的原始文本 生成图像。
这两个模型支持条件生成,因为
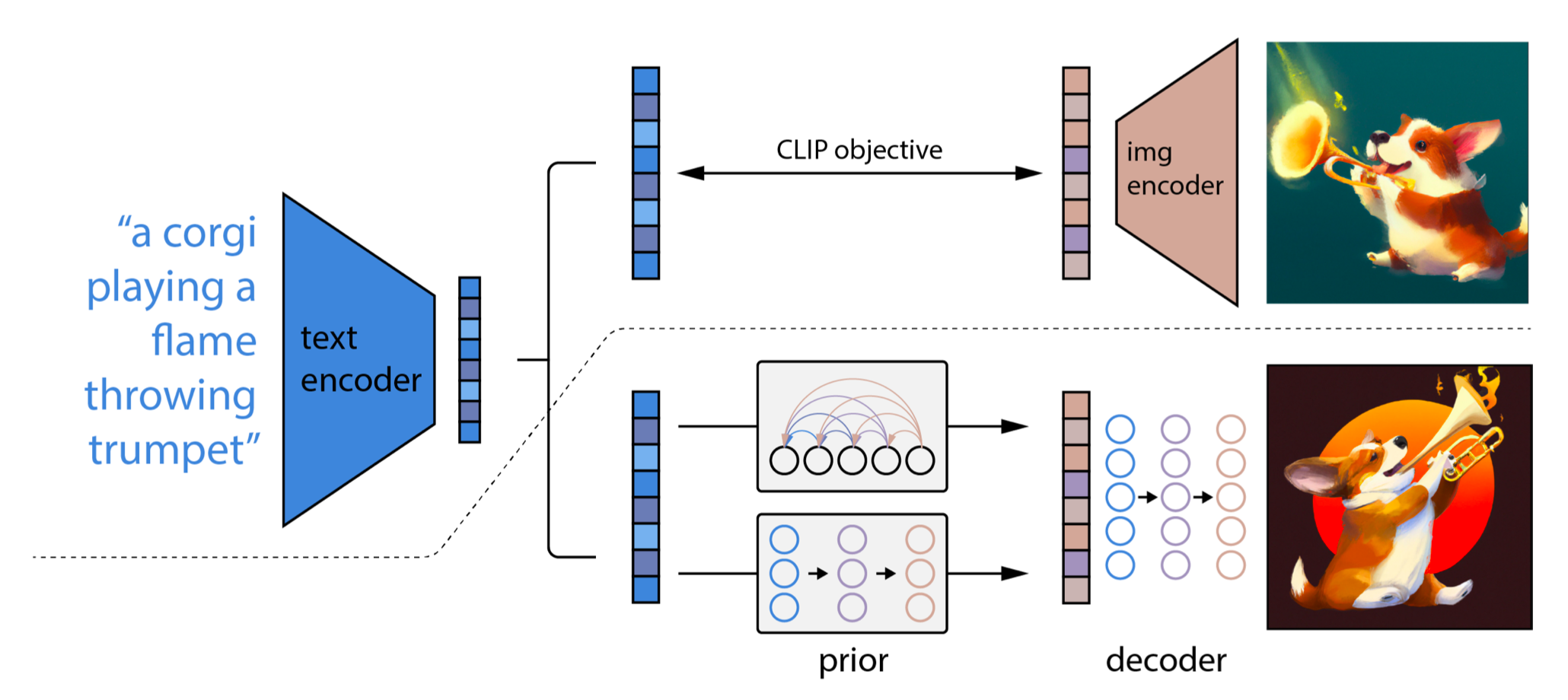
图 16. unCLIP 的架构。(图片来源:Ramesh 等人,2022)
unCLIP 遵循两阶段图像生成过程:
- 给定文本
,首先使用 CLIP 模型生成文本嵌入 。使用 CLIP 潜在空间通过文本实现零样本图像操作。 - 一个扩散或自回归先验
处理这个 CLIP 文本嵌入以构建图像先验,然后一个扩散解码器 生成一个图像,该图像受先验条件限制。这个解码器也可以在图像输入的条件下生成图像变体,保留其风格和语义。
4.2 Imagen
Imagen(Saharia 等人,2022)不是使用 CLIP 模型,而是使用预训练的大型语言模型(LM)(即冻结的 T5-XXL 文本编码器)对文本进行编码以生成图像。有一个普遍趋势表明,更大的模型尺寸可以带来更好的图像质量和文本图像对齐。他们发现,在 MS-COCO 上,T5-XXL 和 CLIP 文本编码器的性能相似,但在 DrawBench(涵盖 11 个类别的提示集合)上,人类评估更喜欢 T5-XXL。
当应用无分类器引导时,增加
- 静态阈值化:将
预测限制在 。 - 动态阈值化:在每个采样步骤中,计算
作为绝对像素值的某个百分位数值;如果 ,则将预测限制在 并除以 。
Imagen 修改了 U-Net 的几个设计,使其成为高效的 U-Net。
- 通过为较低分辨率添加更多的残差锁,将模型参数从高分辨率块转移到低分辨率块;
- 将跳跃连接缩放
; - 为了提高前向传递的速度,颠倒下采样(移到卷积之前)和上采样操作(移到卷积之后)的顺序。
他们发现噪声条件增强、动态阈值化和高效 U-Net 对图像质量至关重要,但扩大文本编码器尺寸比 U-Net 尺寸更重要。
5. 模型架构
扩散模型有两种常见的骨架架构选择:U-Net 和 Transformer。
5.1 U-Net
U-Net(Ronneberger 等人,2015)由一个下采样堆栈和一个上采样堆栈组成。
- 下采样:每个步骤由两个 3x3 卷积(未填充的卷积)的重复应用组成,每个卷积后面跟着一个 ReLU 和一个步长为 2 的 2x2 最大池化。在每个下采样步骤中,特征通道的数量翻倍。
- 上采样:每个步骤由特征图的上采样组成,后面跟着一个 2x2 卷积,每个步骤将特征通道的数量减半。
- 快捷方式:快捷连接导致与下采样堆栈的相应层进行连接,并将必要的高分辨率特征提供给上采样过程。

图 17. U-Net 架构。每个蓝色方块是一个特征图,顶部标记了通道数,左侧底部标记了高度 x 宽度维度。灰色箭头标记了快捷连接。(图片来源:Ronneberger,2015)
为了使图像生成能够根据额外的图像进行条件组合信息(如 Canny 边缘、Hough 线、用户涂鸦、人类后骨架、分割图、深度和法线)。
5.2 ControlNet
ControlNet(Zhang 等人,2023)通过在 U-Net 的每个编码器层中添加一个“夹心”零卷积层的可训练副本,引入了架构变化。准确地说,给定一个神经网络块
- 首先,冻结原始块的原始参数
。 - 克隆它成为一个具有可训练参数
的副本和一个额外的条件向量 。 - 使用两个零卷积层,表示为
和 ,这是 1x1 的卷积层,其权重和偏置初始化为零,将这两个块连接起来。零卷积通过消除初始训练步骤中的随机噪声作为梯度来保护这个背骨。 - 最终输出是:
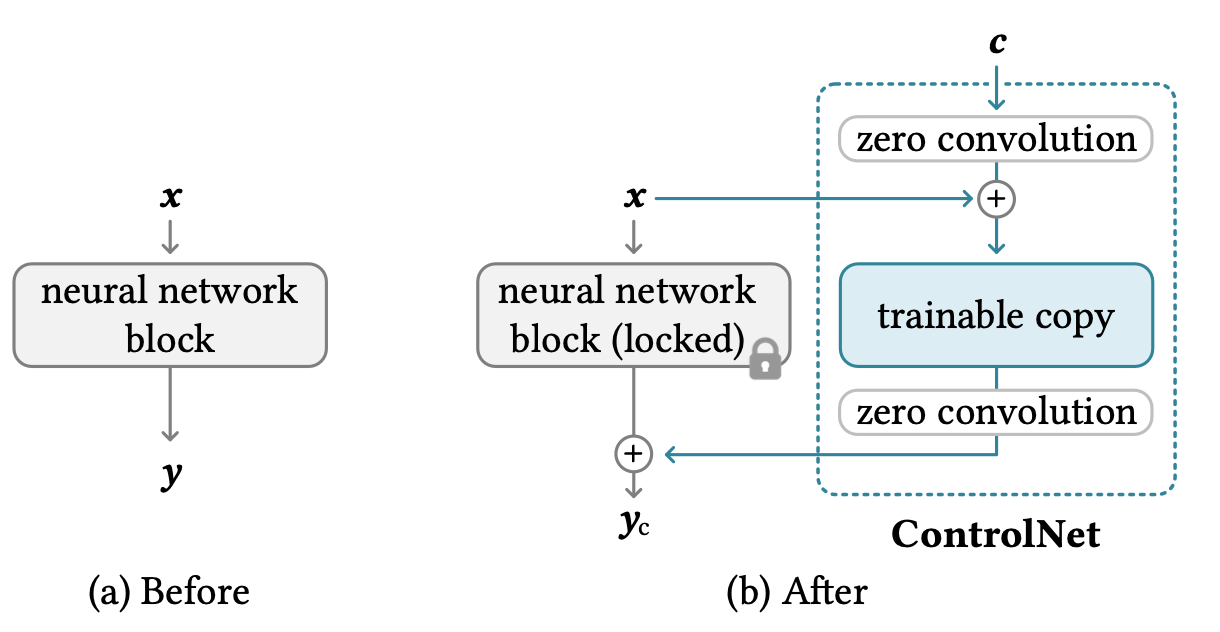
图 18. ControlNet 架构。(图片来源:Zhang 等人,2023)
5.3 Diffusion Transformer
Diffusion Transformer(DiT; Peebles 和 Xie,2023)用于扩散建模,在潜在补丁上操作,使用与 LDM(潜在扩散模型)相同的设计空间。DiT 具有以下设置:
将输入
的潜在表示作为 DiT 的输入。 将噪声潜在的大小
“分块化”成大小为 的补丁,并将其转换为大小为 的补丁序列。 然后这个补丁序列的令牌通过 Transformer 块。他们探索了三种不同的设计,用于根据上下文信息(如时间步
或类标签 )进行生成的条件。在三种设计中,adaLN(自适应层归一化)-Zero 工作得最好,比 in-context 条件和 cross-attention 块更好。比例和偏移参数 和 是从 和 的嵌入向量之和中回归出来的。维度-wise 缩放参数 也是回归出来的,并立即应用于 DiT 块内任何残差连接之前。 变压器解码器输出噪声预测和输出对角线协方差预测。
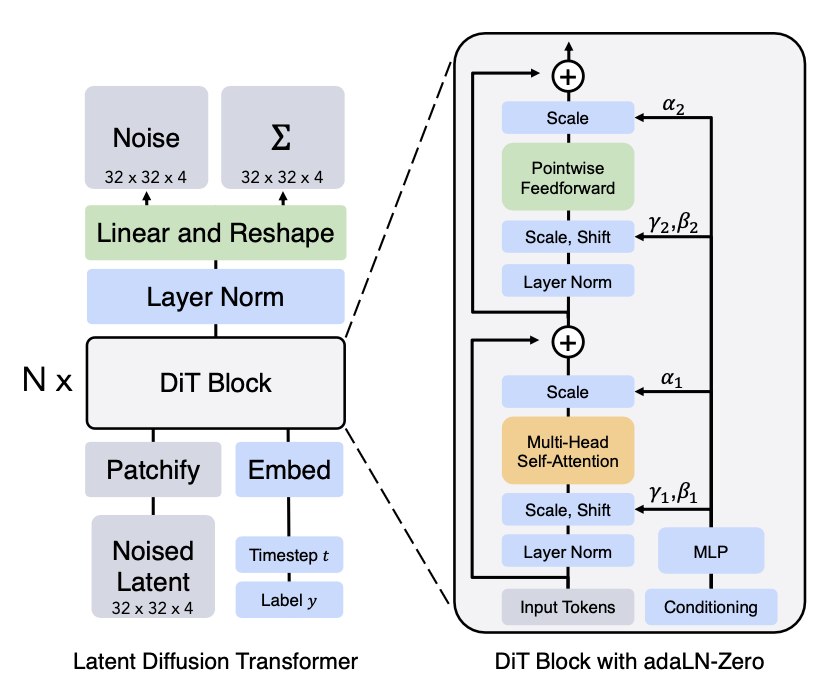
图 19. Diffusion Transformer(DiT)架构。(图片来源:Peebles 和 Xie,2023)
Transformer 架构可以轻松地扩展,它以其可扩展性而闻名。这是 DiT 的最大优势之一,因为其性能随着更多的计算和更大的 DiT 模型而扩展,根据实验,更大的 DiT 模型在计算上更有效率。
6. 快速总结
- 优点:易处理性和灵活性是生成建模中两个相互冲突的目标。易处理模型可以分析评估并以低成本拟合数据(例如通过高斯或拉普拉斯),但它们不能轻易地描述丰富数据集中的结构。灵活模型可以适应数据中的任意结构,但评估、训练或从这些模型中采样通常是昂贵的。扩散模型既易于分析又灵活。
- 缺点:扩散模型依赖于一系列很长的马尔可夫链扩散步骤来生成样本,因此在时间和计算方面可能非常昂贵。已经提出了新的方法来使过程更快,但采样仍然比 GAN 慢。
7. References
[1] Jascha Sohl-Dickstein et al. “Deep Unsupervised Learning using Nonequilibrium Thermodynamics.” ICML 2015.
[2] Max Welling & Yee Whye Teh. “Bayesian learning via stochastic gradient langevin dynamics.” ICML 2011.
[3] Yang Song & Stefano Ermon. “Generative modeling by estimating gradients of the data distribution.” NeurIPS 2019.
[4] Yang Song & Stefano Ermon. “Improved techniques for training score-based generative models.” NeuriPS 2020.
[5] Jonathan Ho et al. “Denoising diffusion probabilistic models.” arxiv Preprint arxiv:2006.11239 (2020). [code]
[6] Jiaming Song et al. “Denoising diffusion implicit models.” arxiv Preprint arxiv:2010.02502 (2020). [code]
[7] Alex Nichol & Prafulla Dhariwal. “Improved denoising diffusion probabilistic models” arxiv Preprint arxiv:2102.09672 (2021). [code]
[8] Prafula Dhariwal & Alex Nichol. “Diffusion Models Beat GANs on Image Synthesis.” arxiv Preprint arxiv:2105.05233 (2021). [code]
[9] Jonathan Ho & Tim Salimans. “Classifier-Free Diffusion Guidance.” NeurIPS 2021 Workshop on Deep Generative Models and Downstream Applications.
[10] Yang Song, et al. “Score-Based Generative Modeling through Stochastic Differential Equations.” ICLR 2021.
[11] Alex Nichol, Prafulla Dhariwal & Aditya Ramesh, et al. “GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models.” ICML 2022.
[12] Jonathan Ho, et al. “Cascaded diffusion models for high fidelity image generation.” J. Mach. Learn. Res. 23 (2022): 47-1.
[13] Aditya Ramesh et al. “Hierarchical Text-Conditional Image Generation with CLIP Latents.” arxiv Preprint arxiv:2204.06125 (2022).
[14] Chitwan Saharia & William Chan, et al. “Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding.” arxiv Preprint arxiv:2205.11487 (2022).
[15] Rombach & Blattmann, et al. “High-Resolution Image Synthesis with Latent Diffusion Models.” CVPR 2022.code
[16] Song et al. “Consistency Models” arxiv Preprint arxiv:2303.01469 (2023)
[17] Salimans & Ho. “Progressive Distillation for Fast Sampling of Diffusion Models” ICLR 2022.
[18] Ronneberger, et al. “U-Net: Convolutional Networks for Biomedical Image Segmentation” MICCAI 2015.
[19] Peebles & Xie. “Scalable diffusion models with transformers.” ICCV 2023.
[20] Zhang et al. “Adding Conditional Control to Text-to-Image Diffusion Models.” arxiv Preprint arxiv:2302.05543 (2023)