执行器(RUNNER)
深度学习算法的训练、验证和测试通常都拥有相似的流程,因此, MMEngine 抽象出了执行器来负责通用的算法模型的训练、测试、推理任务。用户一般可以直接使用 MMEngine 中的默认执行器,也可以对执行器进行修改以满足定制化需求。
为什么需要执行器
在介绍执行器的设计之前,我们先举几个例子来帮助用户理解为什么需要执行器。下面是一段使用 PyTorch 进行模型训练的伪代码:
model = ResNet()
optimizer = SGD(model.parameters(), lr=0.01, momentum=0.9)
train_dataset = ImageNetDataset(...)
train_dataloader = DataLoader(train_dataset, ...)
for i in range(max_epochs):
for data_batch in train_dataloader:
optimizer.zero_grad()
outputs = model(data_batch)
loss = loss_func(outputs, data_batch)
loss.backward()
optimizer.step()下面是一段使用 PyTorch 进行模型测试的伪代码:
model = ResNet()
model.load_state_dict(torch.load(CKPT_PATH))
model.eval()
test_dataset = ImageNetDataset(...)
test_dataloader = DataLoader(test_dataset, ...)
for data_batch in test_dataloader:
outputs = model(data_batch)
acc = calculate_acc(outputs, data_batch)下面是一段使用 PyTorch 进行模型推理的伪代码:
model = ResNet()
model.load_state_dict(torch.load(CKPT_PATH))
model.eval()
for img in imgs:
prediction = model(img)可以从上面的三段代码看出,这三个任务的执行流程都可以归纳为构建模型、读取数据、循环迭代等步骤。上述代码都是以图像分类为例,但不论是图像分类还是目标检测或是图像分割,都脱离不了这套范式。 因此,我们将模型的训练、验证、测试的流程整合起来,形成了执行器。在执行器中,我们只需要准备好模型、数据等任务必须的模块或是这些模块的配置文件,执行器会自动完成任务流程的准备和执行。 通过使用执行器以及 MMEngine 中丰富的功能模块,用户不再需要手动搭建训练测试的流程,也不再需要去处理分布式与非分布式训练的区别,可以专注于算法和模型本身。
执行器 Runner
作为 MMEngine 中的“集大成者”,执行器涵盖了整个框架的方方面面,肩负着串联所有组件的重要责任;因此,其中的代码和实现逻辑需要兼顾各种情景,相对庞大复杂。但是不用担心!在这篇教程中,我们将隐去繁杂的细节,速览执行器常用的接口、功能、示例,为你呈现一个清晰易懂的用户界面。阅读完本篇教程,你将会:
- 掌握执行器的常见参数与使用方式
- 了解执行器的最佳实践——配置文件的写法
- 了解执行器基本数据流与简要执行逻辑
- 亲身感受使用执行器的优越性
执行器示例
下面我们将通过一个适合初学者参考的例子,说明其中最常用的参数,并为一些不常用参数给出进阶指引。
我们希望你在本教程中更多地关注整体结构,而非具体模块的实现。这种“自顶向下”的思考方式是我们所倡导的。
构建模型
首先,我们需要构建一个模型,在 MMEngine 中,我们约定这个模型应当继承 BaseModel,并且其 forward 方法除了接受来自数据集的若干参数外,还需要接受额外的参数 mode:
- 对于训练,我们需要
mode接受字符串 “loss”,并返回一个包含 “loss” 字段的字典; - 对于验证,我们需要
mode接受字符串 “predict”,并返回同时包含预测信息和真实信息的结果。
import torch.nn.functional as F
import torchvision
from mmengine.model import BaseModel
class MMResNet50(BaseModel):
def __init__(self):
super().__init__()
self.resnet = torchvision.models.resnet50()
def forward(self, imgs, labels, mode):
x = self.resnet(imgs)
if mode == 'loss':
loss = F.cross_entropy(x, labels)
return {'loss': loss}
elif mode == 'predict':
return x, labels构建数据集和数据加载器
其次,我们需要构建训练和验证所需要的**数据集 (Dataset) **和 数据加载器 (DataLoader)。 对于基础的训练和验证功能,我们可以直接使用符合 PyTorch 标准的数据加载器和数据集。
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
norm_cfg = dict(mean=[0.491, 0.482, 0.447], std=[0.202, 0.199, 0.201])
train_dataloader = DataLoader(batch_size=32,
shuffle=True,
dataset=torchvision.datasets.CIFAR10(
'data/cifar10',
train=True,
download=True,
transform=transforms.Compose([
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(**norm_cfg)
])))
val_dataloader = DataLoader(batch_size=32,
shuffle=False,
dataset=torchvision.datasets.CIFAR10(
'data/cifar10',
train=False,
download=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(**norm_cfg)
])))构建评测指标
为了进行验证和测试,我们需要定义模型推理结果的评测指标。我们约定这一评测指标需要继承 BaseMetric,并实现 process 和 compute_metrics 方法。其中 process 方法接受数据集的输出和模型 mode="predict" 时的输出,此时的数据为一个批次的数据,对这一批次的数据进行处理后,保存信息至 self.results 属性。 而 compute_metrics 接受 results 参数,这一参数的输入为 process 中保存的所有信息 (如果是分布式环境,results 中为已收集的,包括各个进程 process 保存信息的结果),利用这些信息计算并返回保存有评测指标结果的字典。
from mmengine.evaluator import BaseMetric
class Accuracy(BaseMetric):
def process(self, data_batch, data_samples):
score, gt = data_samples
# 将一个批次的中间结果保存至 `self.results`
self.results.append({
'batch_size': len(gt),
'correct': (score.argmax(dim=1) == gt).sum().cpu(),
})
def compute_metrics(self, results):
total_correct = sum(item['correct'] for item in results)
total_size = sum(item['batch_size'] for item in results)
# 返回保存有评测指标结果的字典,其中键为指标名称
return dict(accuracy=100 * total_correct / total_size)构建执行器并执行任务
最后,我们利用构建好的模型,数据加载器,评测指标构建一个执行器 (Runner),同时在其中配置 优化器、工作路径、训练与验证配置等选项,即可通过调用 train() 接口启动训练:
from torch.optim import SGD
from mmengine.runner import Runner
runner = Runner(
# 用以训练和验证的模型,需要满足特定的接口需求
model=MMResNet50(),
# 工作路径,用以保存训练日志、权重文件信息
work_dir='./work_dir',
# 训练数据加载器,需要满足 PyTorch 数据加载器协议
train_dataloader=train_dataloader,
# 优化器包装,用于模型优化,并提供 AMP、梯度累积等附加功能
optim_wrapper=dict(optimizer=dict(type=SGD, lr=0.001, momentum=0.9)),
# 训练配置,用于指定训练周期、验证间隔等信息
train_cfg=dict(by_epoch=True, max_epochs=5, val_interval=1),
# 验证数据加载器,需要满足 PyTorch 数据加载器协议
val_dataloader=val_dataloader,
# 验证配置,用于指定验证所需要的额外参数
val_cfg=dict(),
# 用于验证的评测器,这里使用默认评测器,并评测指标
val_evaluator=dict(type=Accuracy),
)
runner.train()最后,让我们把以上部分汇总成为一个完整的,利用 MMEngine 执行器进行训练和验证的脚本:
import torch.nn.functional as F
import torchvision
import torchvision.transforms as transforms
from torch.optim import SGD
from torch.utils.data import DataLoader
from mmengine.evaluator import BaseMetric
from mmengine.model import BaseModel
from mmengine.runner import Runner
class MMResNet50(BaseModel):
def __init__(self):
super().__init__()
self.resnet = torchvision.models.resnet50()
def forward(self, imgs, labels, mode):
x = self.resnet(imgs)
if mode == 'loss':
return {'loss': F.cross_entropy(x, labels)}
elif mode == 'predict':
return x, labels
class Accuracy(BaseMetric):
def process(self, data_batch, data_samples):
score, gt = data_samples
self.results.append({
'batch_size': len(gt),
'correct': (score.argmax(dim=1) == gt).sum().cpu(),
})
def compute_metrics(self, results):
total_correct = sum(item['correct'] for item in results)
total_size = sum(item['batch_size'] for item in results)
return dict(accuracy=100 * total_correct / total_size)
norm_cfg = dict(mean=[0.491, 0.482, 0.447], std=[0.202, 0.199, 0.201])
train_dataloader = DataLoader(batch_size=32,
shuffle=True,
dataset=torchvision.datasets.CIFAR10(
'data/cifar10',
train=True,
download=True,
transform=transforms.Compose([
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(**norm_cfg)
])))
val_dataloader = DataLoader(batch_size=32,
shuffle=False,
dataset=torchvision.datasets.CIFAR10(
'data/cifar10',
train=False,
download=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(**norm_cfg)
])))
runner = Runner(
model=MMResNet50(),
work_dir='./work_dir',
train_dataloader=train_dataloader,
optim_wrapper=dict(optimizer=dict(type=SGD, lr=0.001, momentum=0.9)),
train_cfg=dict(by_epoch=True, max_epochs=5, val_interval=1),
val_dataloader=val_dataloader,
val_cfg=dict(),
val_evaluator=dict(type=Accuracy),
)
runner.train()输出的训练日志如下:
2022/08/22 15:51:53 - mmengine - INFO -
------------------------------------------------------------
System environment:
sys.platform: linux
Python: 3.8.12 (default, Oct 12 2021, 13:49:34) [GCC 7.5.0]
CUDA available: True
numpy_random_seed: 1513128759
GPU 0: NVIDIA GeForce GTX 1660 SUPER
CUDA_HOME: /usr/local/cuda
...
2022/08/22 15:51:54 - mmengine - INFO - Checkpoints will be saved to /home/mazerun/work_dir by HardDiskBackend.
2022/08/22 15:51:56 - mmengine - INFO - Epoch(train) [1][10/1563] lr: 1.0000e-03 eta: 0:18:23 time: 0.1414 data_time: 0.0077 memory: 392 loss: 5.3465
2022/08/22 15:51:56 - mmengine - INFO - Epoch(train) [1][20/1563] lr: 1.0000e-03 eta: 0:11:29 time: 0.0354 data_time: 0.0077 memory: 392 loss: 2.7734
2022/08/22 15:51:56 - mmengine - INFO - Epoch(train) [1][30/1563] lr: 1.0000e-03 eta: 0:09:10 time: 0.0352 data_time: 0.0076 memory: 392 loss: 2.7789
2022/08/22 15:51:57 - mmengine - INFO - Epoch(train) [1][40/1563] lr: 1.0000e-03 eta: 0:08:00 time: 0.0353 data_time: 0.0073 memory: 392 loss: 2.5725
2022/08/22 15:51:57 - mmengine - INFO - Epoch(train) [1][50/1563] lr: 1.0000e-03 eta: 0:07:17 time: 0.0347 data_time: 0.0073 memory: 392 loss: 2.7382
2022/08/22 15:51:57 - mmengine - INFO - Epoch(train) [1][60/1563] lr: 1.0000e-03 eta: 0:06:49 time: 0.0347 data_time: 0.0072 memory: 392 loss: 2.5956
2022/08/22 15:51:58 - mmengine - INFO - Epoch(train) [1][70/1563] lr: 1.0000e-03 eta: 0:06:28 time: 0.0348 data_time: 0.0072 memory: 392 loss: 2.7351
...
2022/08/22 15:52:50 - mmengine - INFO - Saving checkpoint at 1 epochs
2022/08/22 15:52:51 - mmengine - INFO - Epoch(val) [1][10/313] eta: 0:00:03 time: 0.0122 data_time: 0.0047 memory: 392
2022/08/22 15:52:51 - mmengine - INFO - Epoch(val) [1][20/313] eta: 0:00:03 time: 0.0122 data_time: 0.0047 memory: 308
2022/08/22 15:52:51 - mmengine - INFO - Epoch(val) [1][30/313] eta: 0:00:03 time: 0.0123 data_time: 0.0047 memory: 308
...
2022/08/22 15:52:54 - mmengine - INFO - Epoch(val) [1][313/313] accuracy: 35.7000如果你通读了上述样例,即使不了解实现细节,你也一定大体理解了这个训练流程,并感叹于执行器代码的紧凑与可读性(也许)。这也是 MMEngine 所期望的:结构化、模块化、标准化的训练流程,使得复现更加可靠、对比更加清晰。
为什么使用执行器
提示
这一部分内容并不能教会你如何使用执行器乃至整个 MMEngine,如果你正在被雇主/教授/DDL催促着几个小时内拿出成果,那这部分可能无法帮助到你,请随意跳过。但我们仍强烈推荐抽出时间阅读本章节,这可以帮助你更好地理解并使用 MMEngine
执行器是 MMEngine 中所有模块的“管理者”。所有的独立模块——不论是模型、数据集这些看得见摸的着的,还是日志记录、分布式训练、随机种子等相对隐晦的——都在执行器中被统一调度、产生关联。事物之间的关系是复杂的,但执行器为你处理了一切,并提供了一个清晰易懂的配置式接口。这样做的好处主要有:
- 你可以轻易地在已搭建流程上修改/添加所需配置,而不会搅乱整个代码。也许你起初只有单卡训练,但你随时可以添加1、2行的分布式配置,切换到多卡甚至多机训练
- 你可以享受 MMEngine 不断引入的新特性,而不必担心后向兼容性。混合精度训练、可视化、崭新的分布式训练方式、多种设备后端……我们会在保证后向兼容性的前提下不断吸收社区的优秀建议与前沿技术,并以简洁明了的方式提供给你
- 你可以集中关注并实现自己的惊人想法,而不必受限于其他恼人的、不相关的细节。执行器的缺省值会为你处理绝大多数的情况
所以,MMEngine 与执行器会确实地让你更加轻松。只要花费一点点努力完成迁移,你的代码与实验会随着 MMEngine 的发展而与时俱进;如果再花费一点努力,MMEngine 的配置系统可以让你更加高效地管理数据、模型、实验。便利性与可靠性,这些正是我们努力的目标。
执行器(架构)
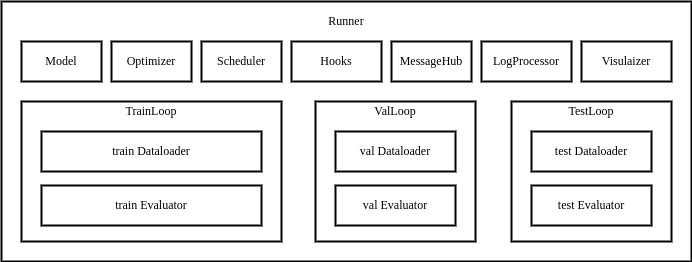
MMEngine 的执行器内包含训练、测试、验证所需的各个模块,以及循环控制器(Loop)和钩子(Hook)。用户通过提供配置文件或已构建完成的模块,执行器将自动完成运行环境的配置,模块的构建和组合,最终通过循环控制器执行任务循环。执行器对外提供三个接口:train, val, test,当调用这三个接口时,便会运行对应的循环控制器,并在循环的运行过程中调用钩子模块各个位点的钩子函数。
执行流程
当用户构建一个执行器并调用训练、验证、测试的接口时,执行器的执行流程如下:
创建工作目录 -> 配置运行环境 -> 准备任务所需模块 -> 注册钩子 -> 运行循环
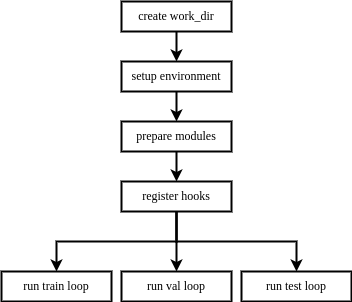
执行器具有延迟初始化(Lazy Initialization)的特性,在初始化执行器时,并不需要依赖训练、验证和测试的全量模块,只有当运行某个循环控制器时,才会检查所需模块是否构建。因此,若用户只需要执行训练、验证或测试中的某一项功能,只需提供对应的模块或模块的配置即可。
循环控制器
在 MMEngine 中,我们将任务的执行流程抽象成循环控制器(Loop),因为大部分的深度学习任务执行流程都可以归纳为模型在一组或多组数据上进行循环迭代。 MMEngine 内提供了四种默认的循环控制器:
EpochBasedTrainLoop基于轮次的训练循环IterBasedTrainLoop基于迭代次数的训练循环ValLoop标准的验证循环TestLoop标准的测试循环
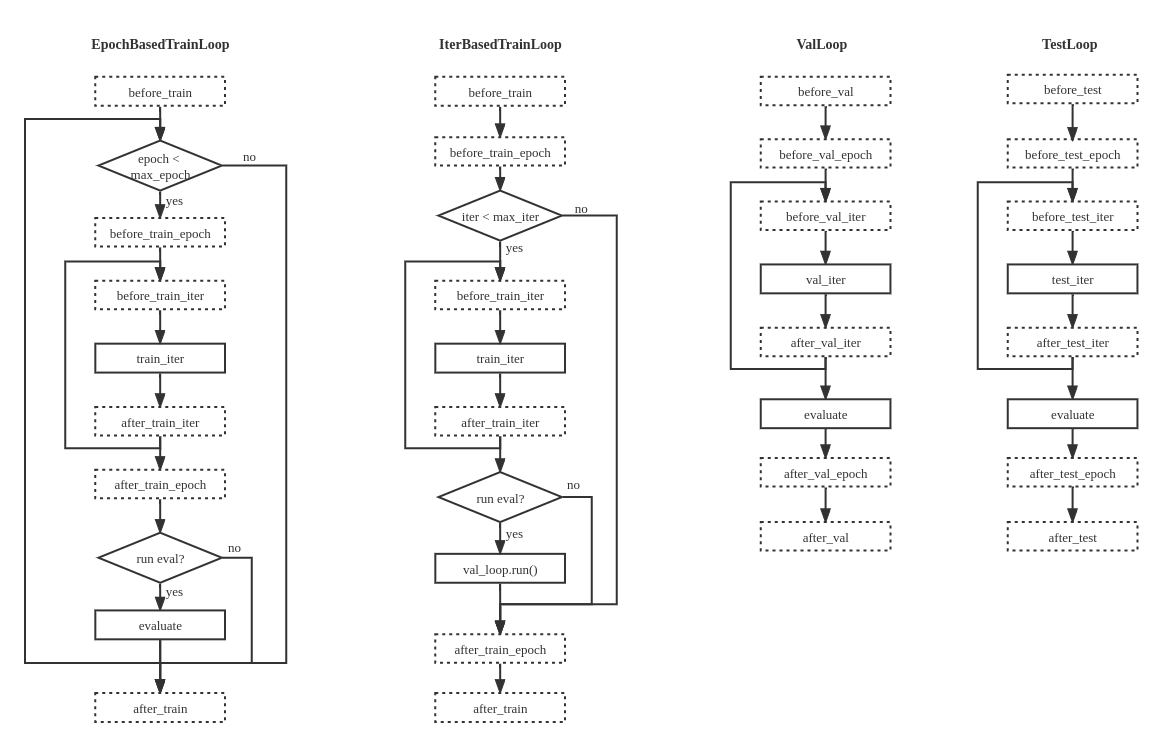
MMEngine 中的默认执行器和循环控制器能够完成大部分的深度学习任务,但不可避免会存在无法满足的情况。有的用户希望能够对执行器进行更多自定义修改,因此,MMEngine 支持自定义模型的训练、验证以及测试的流程。
用户可以通过继承循环基类来实现自己的训练流程。循环基类需要提供两个输入:runner 执行器的实例和 dataloader 循环所需要迭代的迭代器。 用户如果有自定义的需求,也可以增加更多的输入参数。
MMEngine 中同样提供了 LOOPS 注册器对循环类进行管理,用户可以向注册器内注册自定义的循环模块,然后在配置文件的 train_cfg、val_cfg、test_cfg 中增加 type 字段来指定使用何种循环。 用户可以在自定义的循环中实现任意的执行逻辑,也可以增加或删减钩子(hook)点位,但需要注意的是一旦钩子点位被修改,默认的钩子函数可能不会被执行,导致一些训练过程中默认发生的行为发生变化。 因此,我们强烈建议用户按照本文档中定义的循环执行流程图以及钩子设计 去重载循环基类。
from mmengine.registry import LOOPS, HOOKS
from mmengine.runner import BaseLoop
from mmengine.hooks import Hook
# 自定义验证循环
@LOOPS.register_module()
class CustomValLoop(BaseLoop):
def __init__(self, runner, dataloader, evaluator, dataloader2):
super().__init__(runner, dataloader, evaluator)
self.dataloader2 = runner.build_dataloader(dataloader2)
def run(self):
self.runner.call_hooks('before_val_epoch')
for idx, data_batch in enumerate(self.dataloader):
self.runner.call_hooks(
'before_val_iter', batch_idx=idx, data_batch=data_batch)
outputs = self.run_iter(idx, data_batch)
self.runner.call_hooks(
'after_val_iter', batch_idx=idx, data_batch=data_batch, outputs=outputs)
metric = self.evaluator.evaluate()
# 增加额外的验证循环
for idx, data_batch in enumerate(self.dataloader2):
# 增加额外的钩子点位
self.runner.call_hooks(
'before_valloader2_iter', batch_idx=idx, data_batch=data_batch)
self.run_iter(idx, data_batch)
# 增加额外的钩子点位
self.runner.call_hooks(
'after_valloader2_iter', batch_idx=idx, data_batch=data_batch, outputs=outputs)
metric2 = self.evaluator.evaluate()
...
self.runner.call_hooks('after_val_epoch')
# 定义额外点位的钩子类
@HOOKS.register_module()
class CustomValHook(Hook):
def before_valloader2_iter(self, batch_idx, data_batch):
...
def after_valloader2_iter(self, batch_idx, data_batch, outputs):
...上面的例子中实现了一个与默认验证循环不一样的自定义验证循环,它在两个不同的验证集上进行验证,同时对第二次验证增加了额外的钩子点位,并在最后对两个验证结果进行进一步的处理。在实现了自定义的循环类之后,只需要在配置文件的 val_cfg 内设置 type='CustomValLoop',并添加额外的配置即可。
# 自定义验证循环
val_cfg = dict(type='CustomValLoop', dataloader2=dict(dataset=dict(type='ValDataset2'), ...))
# 额外点位的钩子
custom_hooks = [dict(type='CustomValHook')]自定义执行器
更进一步,如果默认执行器中依然有其他无法满足需求的部分,用户可以像自定义其他模块一样,通过继承重写的方式,实现自定义的执行器。执行器同样也可以通过注册器进行管理。具体实现流程与其他模块无异:继承 MMEngine 中的 Runner,重写需要修改的函数,添加进 RUNNERS 注册器中,最后在配置文件中指定 runner_type 即可。
from mmengine.registry import RUNNERS
from mmengine.runner import Runner
@RUNNERS.register_module()
class CustomRunner(Runner):
def setup_env(self):
...上述例子实现了一个自定义的执行器,并重写了 setup_env 函数,然后添加进了 RUNNERS 注册器中,完成了这些步骤之后,便可以在配置文件中设置 runner_type='CustomRunner' 来构建自定义的执行器。
基本数据流
接下来,我们将稍微深入执行器的内部,结合图示来理清其中数据的流向与格式约定。
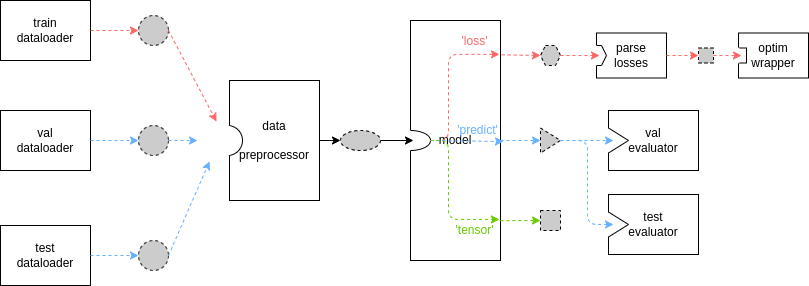
上图是执行器的基本数据流,其中虚线边框、灰色填充的不同形状代表不同的数据格式,实线方框代表模块或方法。由于 MMEngine 强大的灵活性与可扩展性,你总可以继承某些关键基类并重载其中的方法,因此上图并不总是成立。只有当你没有自定义 Runner 或 TrainLoop ,并且你的自定义模型没有重载 train_step、val_step 与 test_step 方法时上图才会成立(而这在检测、分割等任务上是常见的,参考模型教程)。
Dataloader、model、evaluator 之间的数据格式如何约定
针对图中所展示的基本数据流,上述三个模块之间的数据传递可以用如下伪代码表示
python# 训练过程 for data_batch in train_dataloader: data_batch = data_preprocessor(data_batch) if isinstance(data_batch, dict): losses = model.forward(**data_batch, mode='loss') elif isinstance(data_batch, (list, tuple)): losses = model.forward(*data_batch, mode='loss') else: raise TypeError() # 验证过程 for data_batch in val_dataloader: data_batch = data_preprocessor(data_batch) if isinstance(data_batch, dict): outputs = model.forward(**data_batch, mode='predict') elif isinstance(data_batch, (list, tuple)): outputs = model.forward(**data_batch, mode='predict') else: raise TypeError() evaluator.process(data_samples=outputs, data_batch=data_batch) metrics = evaluator.evaluate(len(val_dataloader.dataset))
上述伪代码的关键点在于:
- data_preprocessor 的输出需要经过解包后传递给 model
- evaluator 的
data_samples参数接收模型的预测结果,而data_batch参数接收 dataloader 的原始数据
为什么 model 产生了 3 个不同的输出? loss、predict、tensor 是什么含义?
前面的例子中对此有一定的描述,你需要在自定义模型的 forward 函数中实现 3 条数据通路,适配训练、验证等不同需求。模型文档中对此有详细解释
可以看出红线是训练流程,蓝线是验证/测试流程,绿线是什么?
在目前的执行器流程中,
'tensor'模式的输出并未被使用,大多数情况下用户无需实现。但一些情况下输出中间结果可以方便地进行 debug。
如果我重载了 train_step 等方法,上图会完全失效吗?
默认的
train_step、val_step、test_step的行为,覆盖了从数据进入data preprocessor到model输出loss、predict结果的这一段流程,不影响其余部分。
Runner 调用流程
整体流程构建
Runner 初始化
跟进 from_cfg(cfg) 方法,可以看出,实际是调用了类方法完成 Runner 的初始化,此处有必要贴一下具体代码,方便对配置文件 cfg 建立一个全局的认知
@classmethod
def from_cfg(cls, cfg: ConfigType) -> 'Runner':
"""Build a runner from config.
Args:
cfg (ConfigType): A config used for building runner. Keys of
``cfg`` can see :meth:`__init__`.
Returns:
Runner: A runner build from ``cfg``.
"""
cfg = copy.deepcopy(cfg)
runner = cls(
model=cfg['model'],
work_dir=cfg['work_dir'],
train_dataloader=cfg.get('train_dataloader'),
val_dataloader=cfg.get('val_dataloader'),
test_dataloader=cfg.get('test_dataloader'),
train_cfg=cfg.get('train_cfg'),
val_cfg=cfg.get('val_cfg'),
test_cfg=cfg.get('test_cfg'),
auto_scale_lr=cfg.get('auto_scale_lr'),
optim_wrapper=cfg.get('optim_wrapper'),
param_scheduler=cfg.get('param_scheduler'),
val_evaluator=cfg.get('val_evaluator'),
test_evaluator=cfg.get('test_evaluator'),
default_hooks=cfg.get('default_hooks'),
custom_hooks=cfg.get('custom_hooks'),
data_preprocessor=cfg.get('data_preprocessor'),
load_from=cfg.get('load_from'),
resume=cfg.get('resume', False),
launcher=cfg.get('launcher', 'none'),
env_cfg=cfg.get('env_cfg', dict(dist_cfg=dict(backend='nccl'))),
log_processor=cfg.get('log_processor'),
log_level=cfg.get('log_level', 'INFO'),
visualizer=cfg.get('visualizer'),
default_scope=cfg.get('default_scope', 'mmengine'),
randomness=cfg.get('randomness', dict(seed=None)),
experiment_name=cfg.get('experiment_name'),
cfg=cfg,
)
return runner从上述代码可以很清楚地看出一个完整的 cfg 可配置的选项具体包括哪些,如 model、train_dataloader、optim_wrapper 等。
接下来,进入 Runner 初始化部分,主要的操作有(已省略相关细节,下同)
# 类初始化
class Runner:
def __init__(...)
self.setup_env(env_cfg)
self.set_randomness(**randomness)
self.default_scope = DefaultScope.get_instance(self._experiment_name, scope_name=default_scope)
self.log_processor = self.build_log_processor(log_processor)
self.logger = self.build_logger(log_level=log_level)
self._log_env(env_cfg)
self.message_hub = self.build_message_hub()
self.visualizer = self.build_visualizer(visualizer)
self.model = self.build_model(model)
self.model = self.wrap_model(self.cfg.get('model_wrapper_cfg'), self.model)
self.register_hooks(default_hooks, custom_hooks)
self.dump_config()初始化相关代码主要试下以下功能:
- 基础环境配置:
setup_env, - 设置随机种子
set_randomness, - 获取
default_scope(如mmdet、mmcls等); - 实例化
log_processor、logger、message_hub、visualizer、model等模块; - 注册各类钩子
hooks(默认自带的default_hooks以及用户自定义的custom_hooks); - 模块延迟初始化
Lazy Initialization(此处未展示相关代码),如不同的dataloader,仅当对应流程真正启动时,才需要完整实例化;
训练/验证/测试流程
这里直接贴出相关流程关键代码:
# 训练流程
def train(self) -> nn.Module:
self._train_loop = self.build_train_loop(self._train_loop)
self.optim_wrapper = self.build_optim_wrapper(self.optim_wrapper)
self.scale_lr(self.optim_wrapper, self.auto_scale_lr)
if self.param_schedulers is not None:
self.param_schedulers = self.build_param_scheduler(self.param_schedulers)
if self._val_loop is not None:
self._val_loop = self.build_val_loop(self._val_loop)
self.call_hook('before_run')
self._init_model_weights()
self.load_or_resume()
self.optim_wrapper.initialize_count_status(self.model, self._train_loop.iter, self._train_loop.max_iters)
model = self.train_loop.run()
self.call_hook('after_run')
return model
# 验证流程
def val(self) -> dict:
self._val_loop = self.build_val_loop(self._val_loop)
self.call_hook('before_run')
self.load_or_resume()
metrics = self.val_loop.run()
self.call_hook('after_run')
return metrics
# 测试流程
def test(self) -> dict:
self._test_loop = self.build_test_loop(self._test_loop)
self.call_hook('before_run')
self.load_or_resume()
metrics = self.test_loop.run()
self.call_hook('after_run')
return metrics根据上述代码绘制的流程图如下
对照上述流程图,这里重点讨论以下(粗方框)几部分:
- train 流程构建:
build_train_loop - val 流程构建:
build_val_loop - train 流程调用:
train_loop.run() - val 流程调用:
val_loop.run()
Train 流程构建与调用
def build_train_loop(self, loop: Union[BaseLoop, Dict]) -> BaseLoop:
if 'type' in loop_cfg:
loop = LOOPS.build(
loop_cfg,
default_args=dict(runner=self, dataloader=self._train_dataloader))
else:
by_epoch = loop_cfg.pop('by_epoch')
if by_epoch:
loop = EpochBasedTrainLoop(**loop_cfg, runner=self, dataloader=self._train_dataloader)
else:
loop = IterBasedTrainLoop(**loop_cfg, runner=self, dataloader=self._train_dataloader)
return loop从上述代码片段可以看出,训练流程的构建主要涉及 EpochBasedTrainLoop 与 IterBasedTrainLoop 两种循环结构,分别对应按照 epoch 与 iteration 两种训练方式。
以 EpochBasedTrainLoop 类为例,其主要功能位于初始化 __init__ 与 run 方法部分,以下为整理后的核心代码(精简)片段:
class EpochBasedTrainLoop(BaseLoop):
def __init__(self, runner, dataloader, max_epochs, val_begin, val_interval, dynamic_intervals):
super().__init__(runner, dataloader)
self._max_iters = self._max_epochs * len(self.dataloader)
def run(self) -> torch.nn.Module:
"""Launch training."""
self.runner.call_hook('before_train')
while self._epoch < self._max_epochs and not self.stop_training:
self.run_epoch()
self._decide_current_val_interval()
if (self.runner.val_loop is not None
and self._epoch >= self.val_begin
and self._epoch % self.val_interval == 0):
self.runner.val_loop.run()
self.runner.call_hook('after_train')
return self.runner.model从上述代码可以看出, EpochBasedTrainLoop 类实际上是继承了基类 BaseLoop,进一步跟进去,
class BaseLoop(metaclass=ABCMeta):
def __init__(self, runner, dataloader: Union[DataLoader, Dict]) -> None:
self._runner = runner
if isinstance(dataloader, dict):
# Determine whether or not different ranks use different seed.
diff_rank_seed = runner._randomness_cfg.get('diff_rank_seed', False)
self.dataloader = runner.build_dataloader(dataloader, seed=runner.seed, diff_rank_seed=diff_rank_seed)
else:
self.dataloader = dataloader
@property
def runner(self):
return self._runner
@abstractmethod
def run(self) -> Any:
"""Execute loop."""此处,完成了 train_dataloader 的真正实例化操作,并且定义了抽象方法 run() 。
再次回到 EpochBasedTrainLoop 类的 run() 方法,现在总算是进入了真正的训练流程,为了方便理解,建议对照代码,同步参考官方提供的循环控制器相关流程图。
这里再进一步贴出 run() 方法中的训练相关的 run_epoch() 方法:
def run_epoch(self) -> None:
self.runner.call_hook('before_train_epoch')
self.runner.model.train()
for idx, data_batch in enumerate(self.dataloader):
self.run_iter(idx, data_batch)
self.runner.call_hook('after_train_epoch')
self._epoch += 1
def run_iter(self, idx, data_batch: Sequence[dict]) -> None:
self.runner.call_hook('before_train_iter', batch_idx=idx, data_batch=data_batch)
outputs = self.runner.model.train_step(data_batch, optim_wrapper=self.runner.optim_wrapper)
self.runner.call_hook('after_train_iter', batch_idx=idx, data_batch=data_batch, outputs=outputs)
self._iter += 1至此,实际训练环节基本就清晰了,从 run_iter 中可以明显看出,最底层会调用 model.train_step 方法。
Val 流程构建与调用
当然,上述训练部分代码还会涉及到验证环节,可以进一步跟进到 runner.val_loop.run() 方法查看相关细节。
首先,看一下 ValLoop 部分的构建代码:
def build_val_loop(self, loop: Union[BaseLoop, Dict]) -> BaseLoop:
if 'type' in loop_cfg:
loop = LOOPS.build(
loop_cfg,
default_args=dict(runner=self, dataloader=self._val_dataloader, evaluator=self._val_evaluator))
else:
loop = ValLoop(**loop_cfg, runner=self, dataloader=self._val_dataloader, evaluator=self._val_evaluator)
return loop相较于训练构建流程,验证部分主要差异在于只有 ValLoop 一种循环,此外,还多了一个评估 evaluator 模块。
以下是其 run() 方法的相关实现,这里很明显的一个差异在于多了个 evaluator :初始话阶段会实现其实例化操作, run() 方法会调用 evaluator.evaluate() 来计算最终的 metrics,同时在 run_iter() 方法中会调用 evaluator.process() 实现每个 iteration 的数据处理工作。此外,容易看出, ValLoop 底层调用的是 model.val_step 方法。
class ValLoop(BaseLoop):
def __init__(self, runner, dataloader, evaluator, fp16):
super().__init__(runner, dataloader)
if isinstance(evaluator, dict) or isinstance(evaluator, list):
self.evaluator = runner.build_evaluator(evaluator)
if hasattr(self.dataloader.dataset, 'metainfo'):
self.evaluator.dataset_meta = self.dataloader.dataset.metainfo
self.runner.visualizer.dataset_meta = self.dataloader.dataset.metainfo
self.fp16 = fp16
def run(self) -> dict:
self.runner.call_hook('before_val')
self.runner.call_hook('before_val_epoch')
self.runner.model.eval()
for idx, data_batch in enumerate(self.dataloader):
self.run_iter(idx, data_batch)
metrics = self.evaluator.evaluate(len(self.dataloader.dataset))
self.runner.call_hook('after_val_epoch', metrics=metrics)
self.runner.call_hook('after_val')
return metrics
@torch.no_grad()
def run_iter(self, idx, data_batch: Sequence[dict]):
self.runner.call_hook('before_val_iter', batch_idx=idx, data_batch=data_batch)
with autocast(enabled=self.fp16):
outputs = self.runner.model.val_step(data_batch)
self.evaluator.process(data_samples=outputs, data_batch=data_batch)
self.runner.call_hook('after_val_iter', batch_idx=idx, data_batch=data_batch, outputs=outputs)跟到这里,差不多完整的 EpochBasedTrainLoop 与 ValLoop 流程就就很清晰了。
IterBasedTrainLoop 以及 TestLoop 与上述两者逻辑类似,不再赘述。
与 MMCV Runner 的对比
关于新版 MMEngine 中 Runner 与旧版 MMCV Runner 的差异,官方在 迁移 MMCV 执行器到 MMEngine 文档 中已经给出了比较详细的说明,这里仅选取几处个人感觉变化比较明显的点加以探讨。
优化器封装 OptimWrapper
在新版 MMEngine 中,官方对优化器做了一层封装:OptimWrapper,按照文档描述,这层封装主要的目的在于:
MMEngine 实现了优化器封装,为用户提供了统一的优化器访问接口。优化器封装支持不同的训练策略,包括混合精度训练、梯度累加和梯度截断。用户可以根据需求选择合适的训练策略。优化器封装还定义了一套标准的参数更新流程,用户可以基于这一套流程,实现同一套代码,不同训练策略的切换。
OptimWrapper 的源码实现位于 mmengine/optim/optimizer/optimizer_wrapper.py,从代码可以看出,除了封装 backward()、step()、zero_grad() 等基本操作外,OptimWrapper 还集成了如下功能:
get_lr(),get_momentum()用于统一获取学习率/动量;state_dict()与load_state_dict()方法批量导出/加载状态字典,这一点在管理多个优化器的时候会非常方便;optim_context()、should_update()、_clip_grad()等方法可实现混合精度训练、梯度累加/剪裁等高级功能;
在优化器的统一处理方面,由于涉及到的类型众多,笔者之前还没有看到过一套完整统一且便捷的解决方案,MMEngine 目前提供了一种很好的解决思路,尤其是在涉及多个优化器的应用场景,相比其他框架会有明显优势;
评估模块 Evaluator
在前面分析 ValLoop 时,简单提及了 evaluator 的构建与迭代流程:
- 验证循环中
run_iter()调用的是evaluator.process()方法; - 验证循环结束时调用的是
evaluator.evaluate()方法来计算metrics;
这里再跟进源码看下评估模块的实现细节,相关文件位于 mmengine/evaluator/evaluator.py,其核心代码如下:
class Evaluator:
def __init__(self, metrics: Union[dict, BaseMetric, Sequence]):
self._dataset_meta: Optional[dict] = None
if not isinstance(metrics, Sequence):
metrics = [metrics]
self.metrics: List[BaseMetric] = []
for metric in metrics:
if isinstance(metric, dict):
self.metrics.append(METRICS.build(metric))
else:
self.metrics.append(metric)
def process(self,
data_samples: Sequence[BaseDataElement],
data_batch: Optional[Any] = None):
_data_samples = []
for data_sample in data_samples:
if isinstance(data_sample, BaseDataElement):
_data_samples.append(data_sample.to_dict())
else:
_data_samples.append(data_sample)
for metric in self.metrics:
metric.process(data_batch, _data_samples)
def evaluate(self, size: int) -> dict:
metrics = {}
for metric in self.metrics:
_results = metric.evaluate(size)
metrics.update(_results)
return metrics从上述片段可以看出,
evaluator.process()实际会去调用metric.process()方法,其输入参数为dataloader返回的data_batch、包含了模型预测结果predictions与验证集ground truth数据的_data_samples;- evaluator.evaluate()
会去调用metric.evaluate()` 方法;
再进入 mmengine/evaluator/metric.py 看一下 metric 的相关实现:
class BaseMetric(metaclass=ABCMeta):
@abstractmethod
def process(self, data_batch: Any, data_samples: Sequence[dict]) -> None:
@abstractmethod
def compute_metrics(self, results: list) -> dict:
def evaluate(self, size: int) -> dict:
results = collect_results(self.results, size, self.collect_device)
if is_main_process():
results = _to_cpu(results)
_metrics = self.compute_metrics(results)
metrics = [_metrics]
else:
metrics = [None]
broadcast_object_list(metrics)
self.results.clear()
return metrics[0]该类包含了2个抽象方法,为了便于理解,可以参考 mmdet/evaluation/metrics/coco_metric.py 中的子类 CocoMetric 进一步分析:
metric.process()会处理一个Batch的数据以及对应的预测结果、标签等,并将其处理结果保存至metric.results中;metric.evaluate()则会收集所有(分布式rank上的)处理结果,并调用metric.compute_metrics()计算最终指标;
至此,MMEngine 中的评估模块基本分析完毕,简单来说,虽然不同的 Metric 可能千差万别,但是可以将其封装成统一的类与接口,再使用 Evaluator 间接去调用这些接口,从而用统一方法实现不同的指标计算。
对比旧版 MMCV 基于 EvalHook 的实现方式,新版实现抽象程度更高,也相对更加灵活,这里采用的思想可以说与前述的 OptimWrapper 有异曲同工之妙。