多模态和多模态模型
ChatGPT再次让世界惊叹。通过GPT4的最新升级,ChatGPT 将其功能从文本扩展到图像和语音。借助 ChatGPT 的新功能,您可以让您的孩子在不发脾气的情况下完成作业,或者帮助他们轻松地将“超级向日葵刺猬”的想象力转化为富有表现力的图形。ChatGPT的新功能不仅使AI多模态系统的行业应用实现了飞跃,也引发了围绕多模态模型未来的新一波讨论。
从LLM到LMM
生成式人工智能中的多模态系统或多模态性表示模型产生各种输出的能力,包括文本、图像、音频、视频甚至基于输入的其他模态。这些模型根据特定数据进行训练,学习潜在模态以生成类似的新数据,从而丰富人工智能应用。
并非所有多模态系统都是大型多模态模型 (LMM)。例如,像 Midjourney、Stable Diffusion 和 Dall-E这样的文本到图像模型是多模态的,但不是 LMM,因为它们没有大型语言模型组件。多模态味着以下特点中的一个或多个:
- 输入和输出属于不同的模态(例如文本到图像,图像到文本)
- 输入是多模态的(例如,一个能够同时处理文本和图像的系统)
- 输出是多模态的(例如,一个能够生成文本和图像的系统)
LMM 是通过将额外的模态合并到大型语言模型(LLM)中而构成的, 例如 Open AI 新推出的DALL.E-3 。虽然 LMM 的表现高度依赖于其基础 LLM 的表现,但随着每种模态的添加,它也增强了其基础 LLM 的表现。
与仅生成文本的 LMM 相比,LMM 更接近人类的自然智能。我们通过多种方式感知世界,尤其是通过视觉。使用图像作为Prompt可以让用户更轻松地查询和使用模型,而不是在文本中起草出完美的Prompt。
事实上,整合多模态模型扩展并丰富了LMM对世界的理解。不同信息格式的融合可以使人工智能系统模仿人类的认知模型,使它们能够通过多种感官而不是单纯的语言来理解世界,从而减少幻觉,提高推理能力和持续学习能力。
科技巨头引领LMM 发展
多模态 ChatGPT 让 OpenAI 更接近通用人工智能 (AGI) 时代,这是 OpenAI 在其网站上提出的终极愿景,也是数十年来 AI 社区的圣杯。正如OpenAI在他们的 GPT-4V system card 中指出,“将额外的模态(例如图像输入)融入到LLMs中被视为人工智能研究和发展的关键前沿。”
OpenAI 并不是唯一一家在多模态人工智能领域占据领先地位的公司。在过去的一年里,每周都有一个主要的研究实验室推出了一个新的LMM,例如DeepMind的Flamingo,Salesforce的BLIP,微软的KOSMOS-1,谷歌的PaLM-E和腾讯的Macaw-LLM。
OpenAI推出GPT-4V系统后,谷歌也顶着压力发布了Gemini,号称是一个从头开始创建的多模态系统。据说Gemini 接受训练的Token数量是 GPT4 两倍,在从大量专有数据中获得的见解和推论的复杂性方面具有明显的优势。同样,Meta 最近推出的SeamlessM4T、AudioCraft和CM3leon系列都表明了其在多模态 AI 进步方面与 OpenAI 和 Google 竞争的决心。
LLM 内容总览
这篇文章涵盖了一般的多模态系统,包括LMMs。它分为3个部分:
- 第1部分介绍多模态的背景,包括为什么需要多模态,不同的数据模态以及多模态任务的类型。
- 第2部分讨论了多模态系统的基础知识,以CLIP为例,它为多模态系统奠定了基础,以及Flamingo,它的出色性能催生了LMMs。
- 第3部分讨论了LMMs的一些活跃研究领域,包括生成多模态输出和更高效多模态训练的适配器,涵盖了新的多模态系统,例如BLIP-2,LLaVA,LLaMA-Adapter V2,LAVIN等。
这篇文章很长,请随时跳到您最感兴趣的部分。
第1部分:了解多模态
为什么需要多模态
许多用例在没有多模态的情况下是不可能实现的,尤其是那些涉及多种数据模态的行业,如医疗保健、机器人技术、电子商务、零售、游戏等。
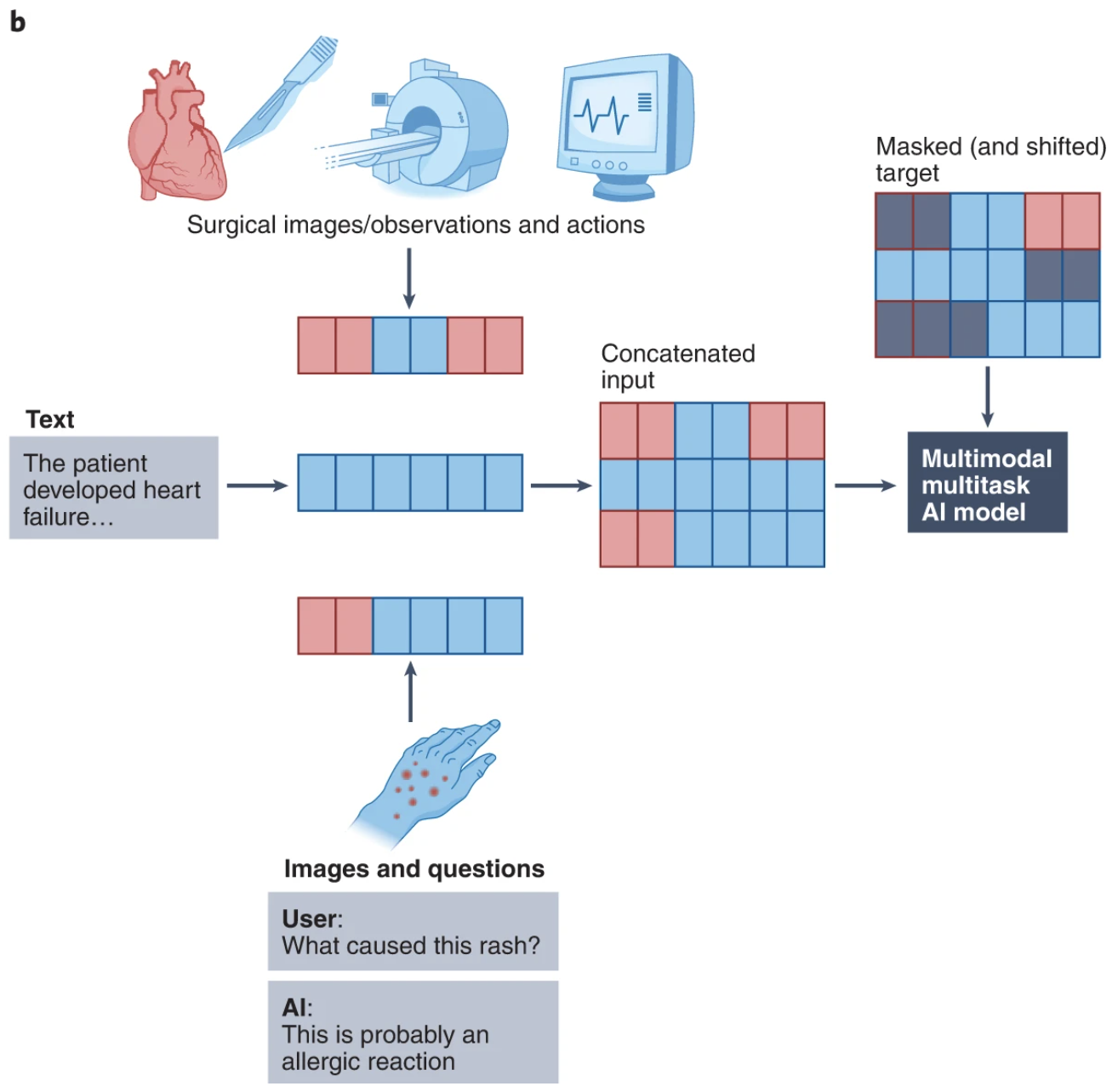
多模态在医疗保健领域的应用示例。图片来自Multimodal biomedical AI (Acosta等,自然医学 2022)
不仅如此,整合来自其他模态的数据可以帮助提高模型性能。一个既能从文本学习又能从图像学习的模型,应该比只能从文本或图像学习的模型性能更好。
多模态系统可以提供更灵活的界面,允许您以在特定时刻以最适合您的方式与它们交互。想象一下,您可以通过打字、说话或者只需将摄像头对准某物来提问。
我特别期待的一个用例是,多模态可以让视障人士能够浏览互联网并在现实世界中导航。

GPT-4V提供的一些酷炫的多模态用例
数据模态
不同的数据模态包括文本、图像、音频、表格数据等。一个数据模态可以被另一个数据模态所表示或近似。例如:
- 音频可以被表示为图像(梅尔频谱图)。
- 语音可以被转录成文本,尽管它的纯文本表示会丢失音量、语调、停顿等信息。
- 图像可以被表示为向量,然后可以被压平并表示为一系列文本标记。
- 视频是图像和音频的序列。目前的机器学习模型主要将视频视为图像的序列。这是一个严重的限制,因为声音对于视频和视觉同样重要。88%的TikTok用户表示声音对他们的TikTok体验非常重要。
- 文本可以被表示为图像,如果你只是简单地进行拍照。
- 数据表可以转换为图表,即图像。
那其他的数据模态呢?
所有数字数据格式都可以用位串(由0和1组成的字符串)或字节串表示。一个能够有效学习位串或字节串的模型将非常强大,它可以从任何数据模态中学习。
还有其他我们没有涉及的数据模态,比如图表和三D图。我们也没有涉及用于表示气味和触觉(触觉)的格式。
在当前的机器学习中,音频仍然主要被视为文本的语音替代品。音频的最常见用例仍然是语音识别(语音转文本)和语音合成(文本转语音)。非语音音频用例,例如音乐生成,仍然相对较为小众。可以参考HuggingFace上的Drake&Weeknd歌曲和MusicGen model on HuggingFace。
图像可能是模型输入最通用的格式,因为它可用于表示文本、表格数据、音频,在某种程度上还可以表示视频。视觉数据也比文本数据多得多。现今我们有手机/网络摄像头可以不断地拍照和录制视频。
文本是模型输出的一个更强大的模态。一个能够生成图像的模型只能用于图像生成,而一个能够生成文本的模型可以用于许多任务:摘要、翻译、推理、回答问题等。
为简单起见,我们将主要关注两种模态:图像和文本。这些知识可以在某种程度上推广到其他模态。
多模态任务
要了解多模态系统,了解它们旨在解决的任务会很有帮助。在文献中,我通常看到将视觉语言任务分为两组:生成和视觉语言理解(VLU)(这是一个涵盖所有不需要生成的任务的总称)。这两组之间的界限是模糊的,因为能够生成答案也需要理解。
生成任务
对于生成任务,输出可以是单模态的(例如文本、图像、3D渲染)或多模态的。虽然单模态输出在今天很常见,但多模态输出仍在不断发展中。我们将在本文末尾讨论多模态输出。
图像生成(Text2Image)
这个任务类别很直接。例如:Dall-E,Stable Diffusion和Midjourney。
文本生成 ( Text Generation)
一个常见的文本生成任务是视觉问答。与其只依赖文本进行上下文,你可以同时给模型提供文本和图像。想象一下你可以用相机对准任何东西并问问题,比如:“我的车无法启动。出了什么问题?”,“怎么制作这道菜?”,或者“这个梗是什么意思?”。
另一个常见的用例是图像描述,它可以作为基于文本的图像检索系统的一部分。一个组织可能有数百万甚至数十亿张图片:产品图片、图表、设计、团队照片、宣传材料等。AI可以自动生成这些图片的描述和元数据,使得更容易找到你想要的确切图片。
视觉语言理解
我们将关注两种任务类型:分类和基于文本的图像检索(TBIR)。
分类
分类模型只能生成属于预定义类别列表的输出。当你只关心有限数量的结果时,这种方法是可行的。例如,一个OCR系统只需要预测一个视觉元素是否为已知字符(例如数字或字母)。
侧面说明:一个OCR系统在字符级别处理数据。当与一个能够理解更广泛上下文的系统结合使用时,它可以改善用例,比如允许你“与”任何教科书、合同、装配说明等进行交流。

使用GPT-4V进行文档处理使用GPT-4V进行文档处理。模型的错误被标记为红色。
与分类相关的一个任务是图像到文本的检索:给定一张图片和一组预定义的文本,找到最有可能与该图片配对的文本。这对于产品图片搜索很有帮助,即从图片中检索产品评论。
基于文本的图像检索(图像搜索)
图像搜索不仅对搜索引擎很重要,对于企业能够搜索其所有内部图片和文档也至关重要。有些人将基于文本的图像检索称为“文本到图像检索”。
基于文本的图像检索有几种方法。其中两种方法是:
为每张图片生成标题和元数据,可以手动或自动完成(请参见文本生成中的图像描述)。给定一个文本查询,找到其标题/元数据与该文本查询最接近的图像。
为图像和文本训练一个联合嵌入空间。给定一个文本查询,为该查询生成一个嵌入,然后找到所有与该嵌入最接近的图像的嵌入。
第二种方法更加灵活,我相信它将被更广泛地使用。这种方法需要在视觉和语言之间建立强大的联合嵌入空间,就像OpenAI的 CLIP 所开发的那种空间。
第2部分:多模态训练的基础
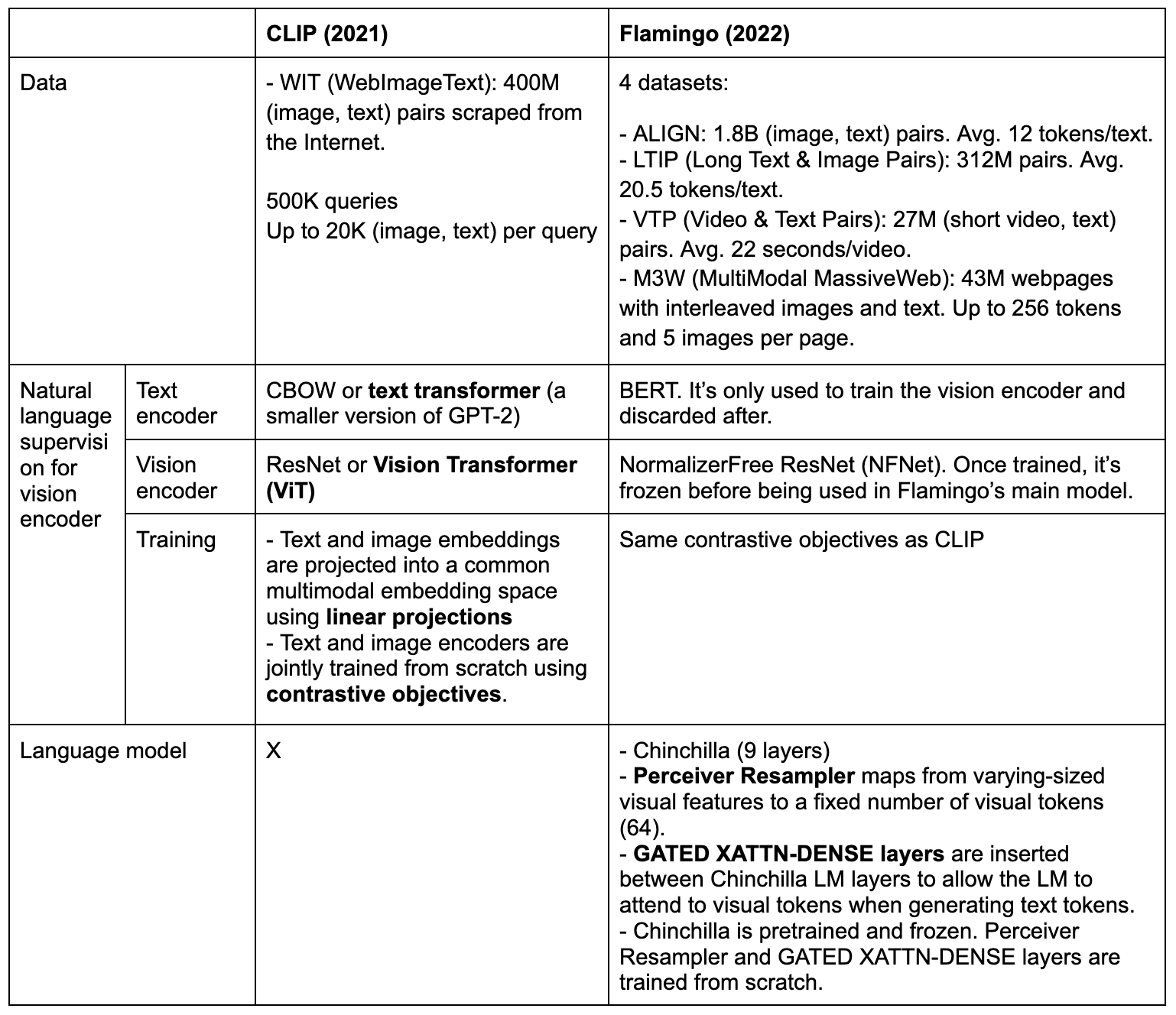
鉴于存在如此多令人惊叹的多模态系统,编写这篇文章的挑战之一是选择专注于哪些系统。最终,我决定专注于两个模型:CLIP (2021年)和 Flamingo (2022),这两个模型因其重要性以及公开细节的可用性和清晰度而备受关注。
CLIP是第一个能够通过零样本和少样本学习泛化到多个图像分类任务的模型。
Flamingo虽然不是第一个能够生成开放性回答的大型多模态模型(Salesforce’s BLIP 在它之前的3个月就发布了)。然而,Flamingo的出色性能使一些人认为它是多模态领域的GPT-3时刻。
尽管这两个模型较老,但它们使用的许多技术在今天仍然适用。我希望它们为理解更新的模型奠定基础。多模态领域正在迅速发展,许多新想法不断涌现。我们将在第3部分介绍这些新模型。
从高层次来看,一个多模态系统包括以下组件:
- 编码器:为每个数据模态构建编码器,以生成该模态数据的嵌入。
- 模态对齐: 一种将不同模态的嵌入对齐到相同多模态嵌入空间的方法
- [仅用于生成模型] 一个语言模型,用于生成文本回应。因为输入可能同时包含文本和图像,需要开发新技术,使语言模型不仅可以根据文本,还可以根据图像来生成回应。
理想情况下,尽可能多的这些组件应该是可以进行预训练的和可重复使用的。
CLIP: Contrastive Language-Image Pre-training
CLIP的关键贡献在于其能够将不同模态的数据,即文本和图像,映射到共享的嵌入空间中。这个共享的多模态嵌入空间使得文本到图像和图像到文本的任务变得更加容易。
训练这个多模态嵌入空间还产生了一个强大的图像编码器,使得CLIP在许多图像分类任务上实现了有竞争力的零样本性能。这个强大的图像编码器可以用于许多其他任务:图像生成、视觉问答和基于文本的图像检索。Flamingo和LLaVa使用CLIP作为它们的图像编码器。DALL-E使用CLIP对生成的图像进行重新排序。目前尚不清楚GPT-4V是否使用了CLIP。
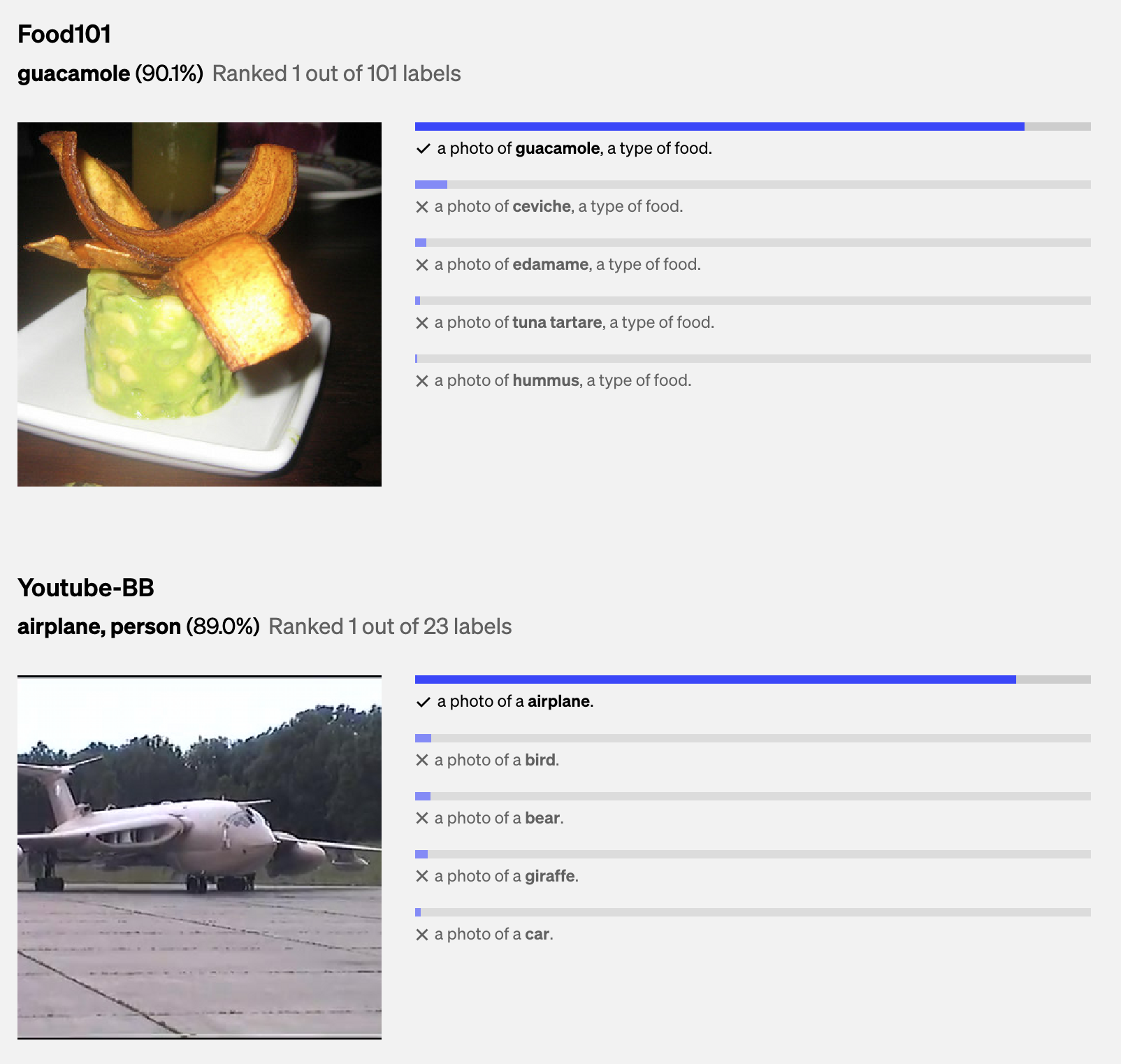
使用CLIP进行零样本图像分类使用CLIP进行零样本图像分类
CLIP利用了自然语言监督和对比学习,这使得CLIP既能够扩大其数据规模,又能够提高训练效率。我们将讨论这两种技术的原因和工作原理。
CLIP的高级架构
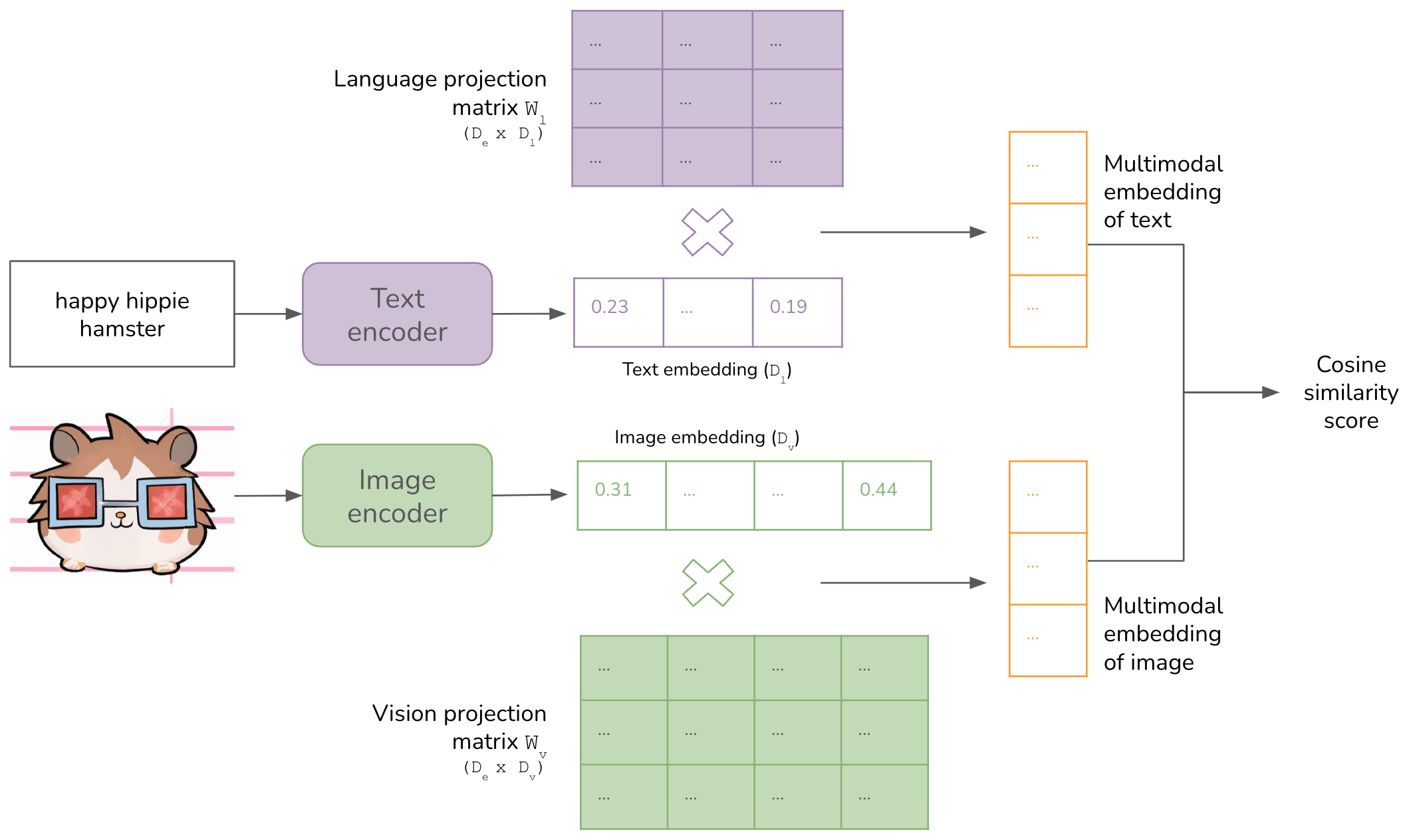
CLIP的架构包括两个主要部分:图像编码器和文本编码器,以及用于将它们投影到相同嵌入空间的两个投影矩阵,这两个部分是从头开始联合训练的。训练的目标是在最大化正确的(图像,文本)配对的相似度分数的同时,最小化错误配对的相似度分数(对比学习)。
对于图像编码器,作者尝试了ResNet和ViT两种架构。最佳性能的模型是ViT-L/14@336px:
- Large vision transformer ViT-L
- on 336x336 pixel input
对于文本编码器,CLIP使用了一个类似于GPT-2但规模较小的Transformer模型。他们的基础模型仅有63M参数和8个注意头。作者发现CLIP的性能对文本编码器的容量不太敏感。
图像编码器和文本编码器生成的嵌入通过使用两个投影矩阵$W_v$和$W_l$被投影到相同的嵌入空间中。
- 给定一个图像嵌入$Vi$,相应的多模态嵌入计算如下:$W_vV_i$。
- 给定一个文本嵌入$Li$,相应的多模态嵌入计算如下:$W_lL_i$。
当人们提到CLIP嵌入时,他们指的是这些多模态嵌入或者是由CLIP的图像编码器生成的嵌入。
自然语言监督
多年来,图像模型是通过手动标注的(图像,文本)数据集(例如ImageNet、MS COCO)进行训练的。但是这种方法不太容易扩展,手动标注非常耗时和昂贵。
CLIP的论文指出,当时可用的(图像,文本)数据集都不够大,质量也不够高。因此,他们创建了自己的数据集,包含了4亿个(图像,文本)配对。具体方法如下:
- 构建一个包含50万个查询的列表。这些查询是常见单词、二元组和热门维基百科文章的标题。
- 找到与这些查询匹配的图像(进行字符串和子字符串匹配)。论文中并未详细说明这个搜索是在哪里进行的,但我猜测由于OpenAI已经为他们的GPT模型抓取了整个互联网,他们可能只是查询了他们的内部数据库。
- 每个图像都与一个文本配对(例如标题、评论等),而不是查询,因为查询太短,无法描述图像。
由于某些查询比其他查询更受欢迎,为了避免数据不平衡,他们每个查询最多使用2万个图像。
对比学习
在CLIP出现之前,大多数视觉-语言模型都是使用分类器或语言模型目标进行训练的。对比学习是一种聪明的技术,使得CLIP能够扩展并泛化到多个任务。
我们将通过一个图像描述的示例任务来说明为什么对比目标更适合CLIP模型:给定一个图像,生成描述它的文本。
分类器目标
分类器预测在预定义类别列表中的正确类别。当输出空间是有限的时,这种方法有效。之前使用(图像,文本)配对数据集的模型都有这个限制。例如,使用ILSVRC-2012数据集的模型限制了自己在1000个类别中进行预测,而使用JFT-300M 数据集的模型则限制在18291个类别中进行预测。
这个目标不仅限制了模型输出有意义的响应的能力,还限制了它进行零样本学习的能力。也就是说,如果模型被训练为在10个类别中进行预测,那么它不适用于有100个类别的任务。
语言模型目标
如果分类器只为每个输入输出一个类别,那么语言模型则输出一个类别序列。生成的每个类别被称为一个标记。每个标记都来自语言模型的预定义词汇表。
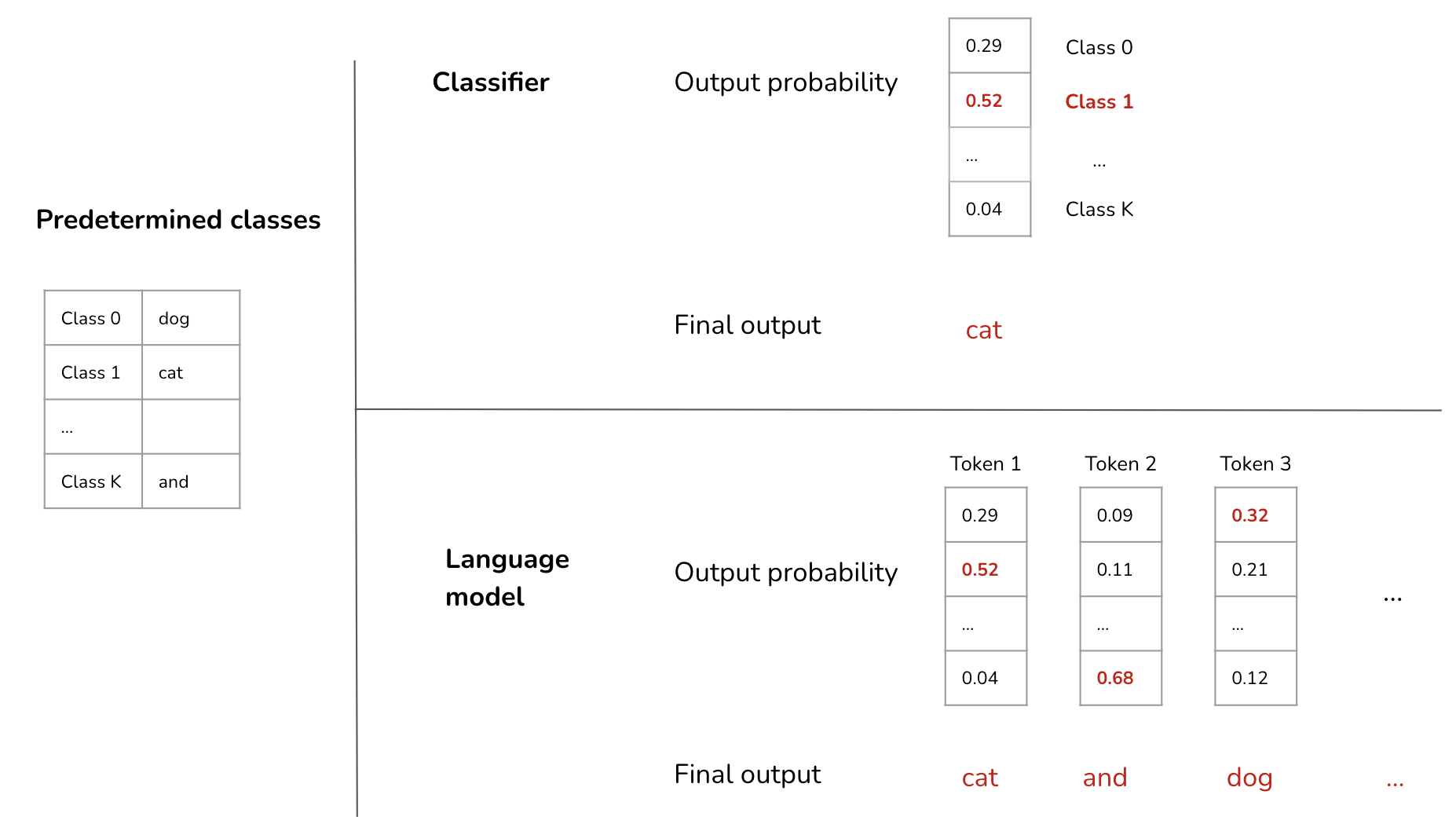
分类器与语言模型目标
对比目标
虽然语言模型目标允许更加灵活的输出,但CLIP的作者指出,这个目标使得训练变得困难。他们的假设是,这是因为模型试图生成与每个图像相伴随的确切文本,而一个图像可能有很多可能的文本伴随:例如 可替代文本、标题、评论等。
例如,在Flickr30K 数据集中,每个图像都有由人类注释者提供的 5 个标题,并且同一图像的标题可能非常不同。

对比学习就是为了克服这一挑战。CLIP 的训练目的不是预测每个图像的确切文本,而是预测文本是否比其他文本更有可能伴随图像。
For each batch of $N$ (image, text) pairs, the model generates $\mathrm{N}$ text embeddings and $\mathrm{N}$ image embeddings.
- Let $V_1, V_2, \ldots, V_n$ be the embeddings for the $N$ images.
- Let $L_1, L_2, \ldots, L_n$ be the embeddings for the $N$ texts.
CLIP computes the cosine similarity scores of the $N^2$ possible $\left(V_i, L_j\right)$ pairings. The model is trained to maximize the similarity scores of the $N$ correct pairings while minimizing the scores of the $N^2-N$ incorrect pairings. For CLIP, $N=32,768$.
另一种看待这个问题的方法是,CLIP 的每个训练批次都是两个分类任务。
- 每张图像都可以与 N 个可能的文本配对,模型会尝试预测正确的文本。这与图像到文本检索的设置相同。
$$ L_{\text {contrastive:txt2im } }=-\frac{1}{N} \sum_i^N \log \left(\frac{\exp \left(L_i^T V_i \beta\right)}{\sum_j^N \exp \left(L_i^T V_j \beta\right)}\right) $$ 2. 每个文本可以与 N 个可能的图像配对,并且模型尝试预测正确的图像。这与文本到图像检索的设置相同。
$$ L_{\text {contrastive:im2txt } }=-\frac{1}{N} \sum_i^N \log \left(\frac{\exp \left(V_i^T L_i \beta\right)}{\sum_j^N \exp \left(V_i^T L_j \beta\right)}\right) $$
这两个损失的总和被最小化。$\beta$ 是可训练的逆温度参数。
这就是伪代码的样子。

CLIP 作者发现,与语言模型目标基线相比,对比目标的效率提高了 12 倍,同时产生了更高质量的图像嵌入。
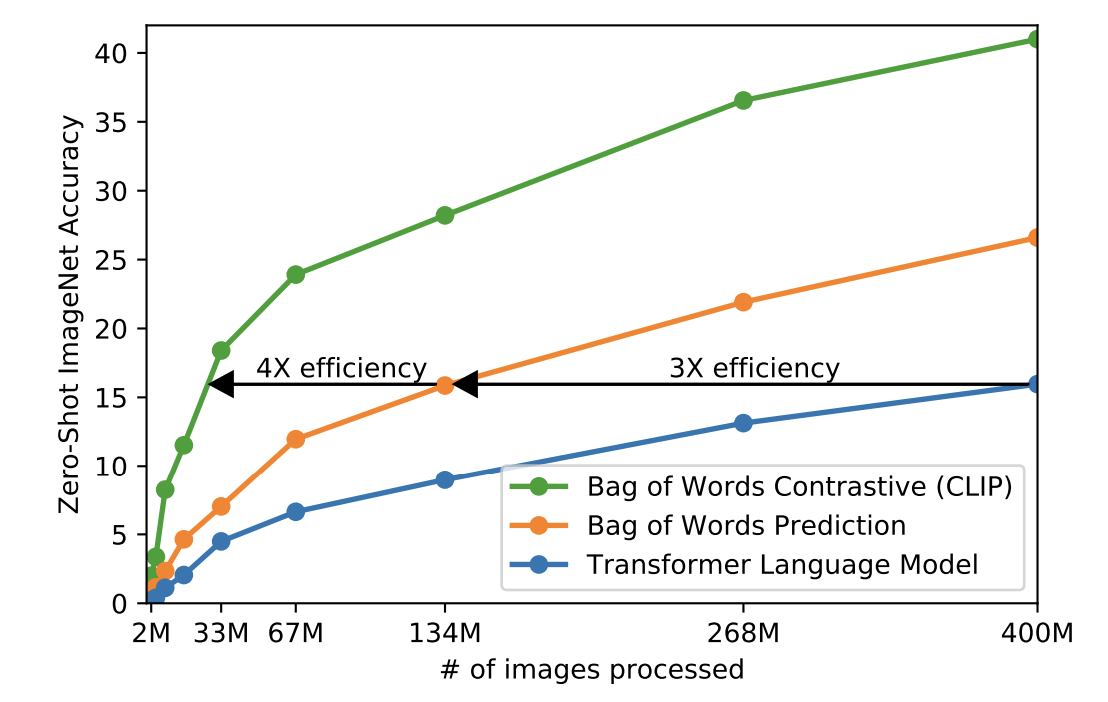
CLIP 模型的应用
分类
如今,对于许多图像分类任务,CLIP 仍然是一个强大的开箱即用基线,可以按原样使用或进行微调。
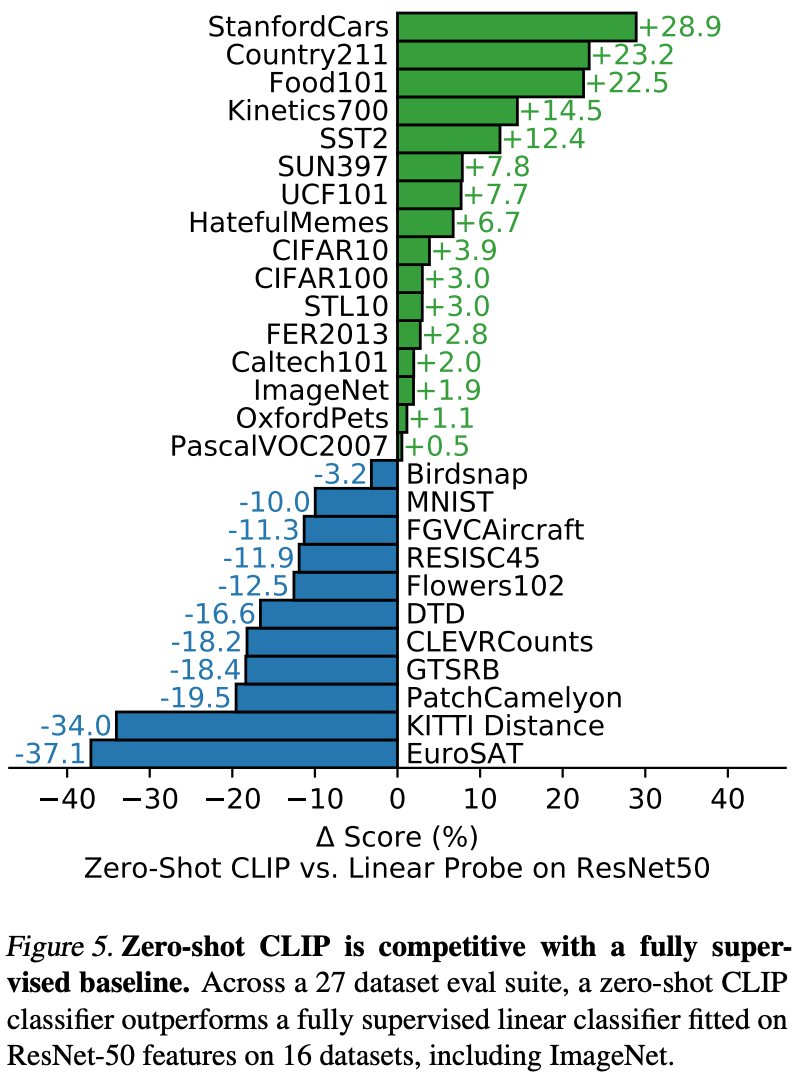
基于文本的图像检索
由于 CLIP 的训练过程在概念上类似于图像到文本检索和文本到图像检索,因此 CLIP“为图像检索或搜索等广泛应用的任务展现了巨大的前景。” 然而,“在图像检索方面,CLIP 的性能相对于整体现有技术水平明显较低。”
有人尝试使用 CLIP 进行图像检索。例如, clip-retrieval 的工作原理如下:
- 为所有图像生成 CLIP 嵌入并将它们存储在矢量数据库中。
- 对于每个文本查询,生成该文本的 CLIP 嵌入。
- 在向量数据库中查询嵌入与该文本查询嵌入接近的所有图像。
图像生成
CLIP 的联合图像文本嵌入对于图像生成非常有用。给定文本提示,DALL-E (2021) 会生成许多不同的视觉效果,并使用 CLIP 对这些视觉效果重新排名,然后再向用户显示顶级视觉效果。
2022 年,OpenAI 推出了unCLIP,这是一种以 CLIP 潜在特征为条件的文本到图像合成模型。它由两个主要部分组成:
- CLIP 经过训练并冻结。预训练的 CLIP 模型可以在同一嵌入空间中生成文本和图像的嵌入。
- 图像生成时发生两件事:
- 使用 CLIP 生成此文本的嵌入。
- 使用扩散解码器生成以此嵌入为条件的图像。
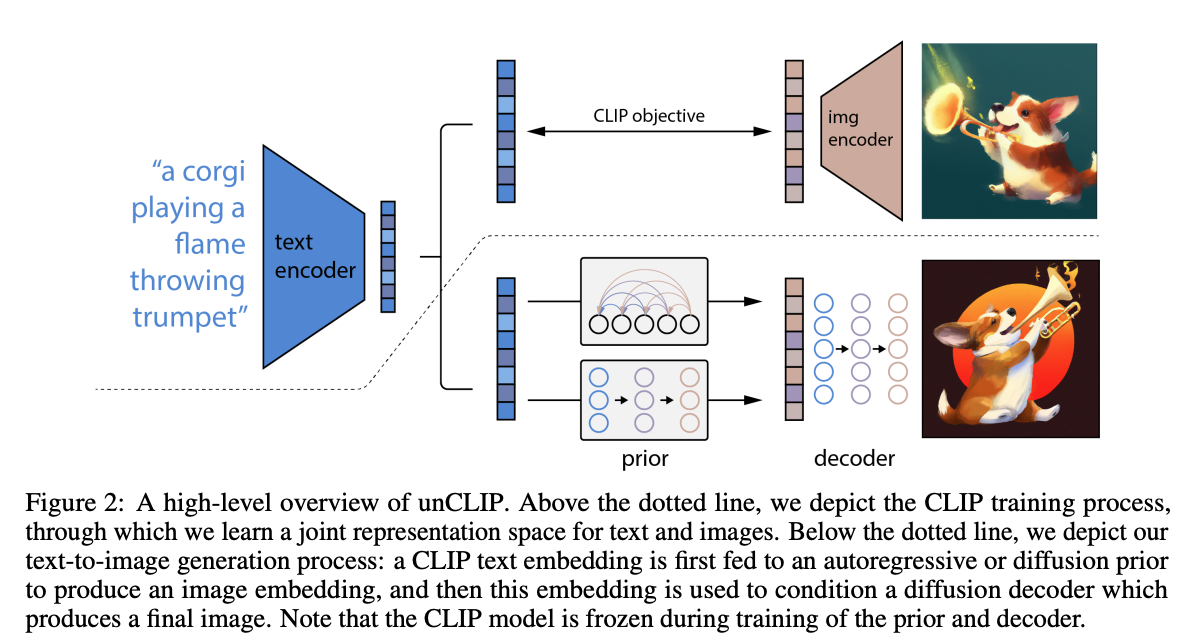
文本生成:视觉问答、图像摘要
CLIP 作者确实尝试创建一个文本生成模型。他们试验的一个版本称为 LM RN50。尽管该模型可以生成文本响应,但在 CLIP 评估的所有视觉语言理解任务上,其性能始终比 CLIP 的最佳性能模型低 10% 左右。
虽然现在 CLIP 不直接用于文本生成,但其图像编码器通常是可生成文本的 LMM 的骨干。
Flamingo:LMM 的黎明
与 CLIP 不同,Flamingo 可以生成文本响应。从简化的角度来看,Flamingo 是 CLIP + 语言模型,添加了一些技术,使语言模型能够根据视觉和文本输入生成文本标记。

Flamingo 可以根据文本和图像生成文本响应
Flamingo的高层架构
从高层次来看,Flamingo 由两部分组成:
- 视觉编码器:使用对比学习来训练类似 CLIP 的模型。然后丢弃该模型的文本编码器。视觉编码器被冻结以在主模型中使用。
- 语言模型:Flamingo 微调 Chinchilla 以生成文本标记,以视觉效果和文本为条件,使用语言模型损失,以及两个附加组件 Perceiver Resampler 和 GATED XATTN-DENSE 层。我们稍后将在本博客中讨论它们。
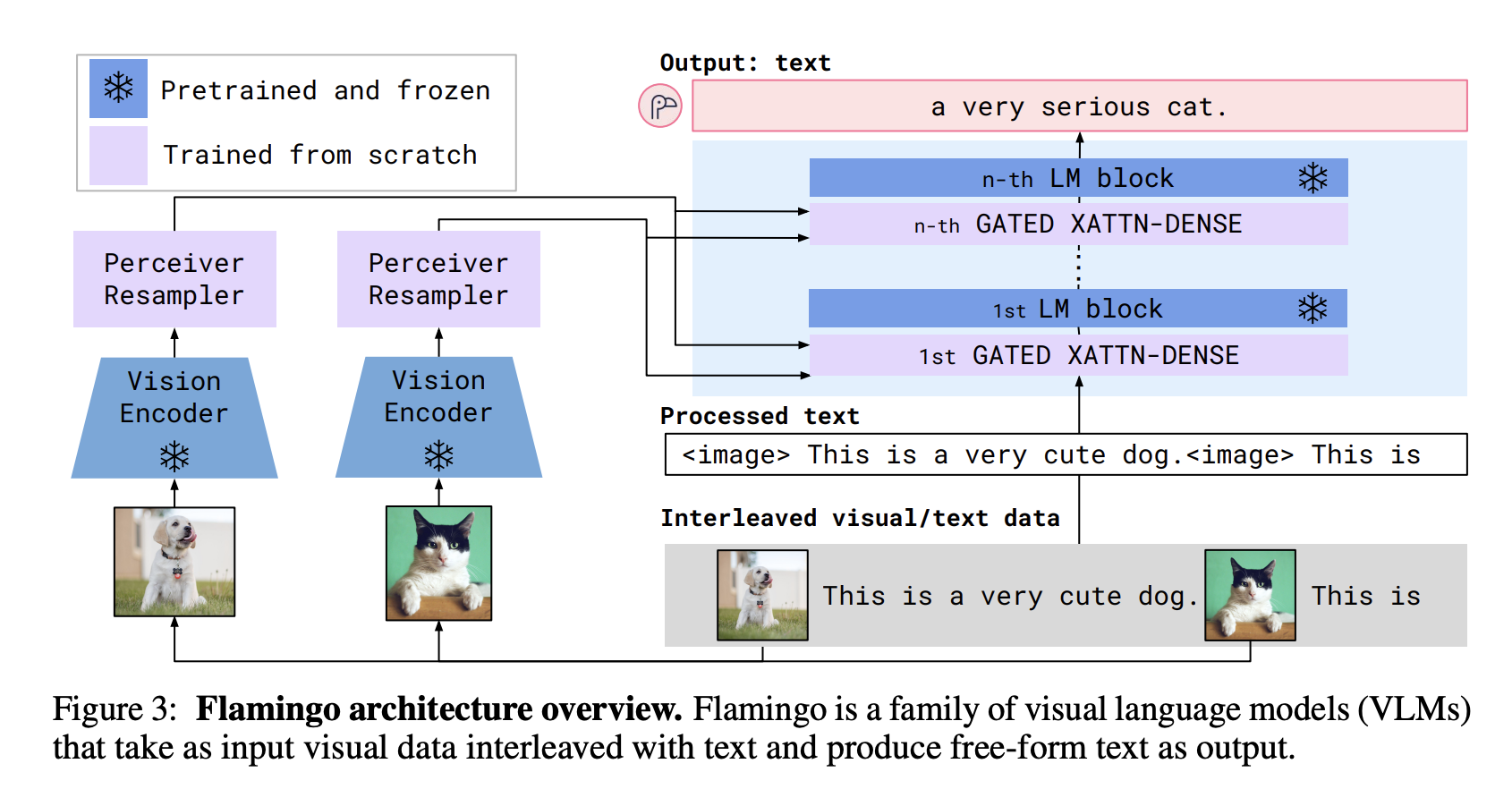
数据
Flamingo 使用了 4 个数据集:2 个(图像、文本)对数据集、1 个(视频、文本)对数据集和 1 个交错的图像和文本数据集。

Overview of the datasets
| Dataset | Type | Size | How | Training weight |
|---|---|---|---|---|
| M3W | Interleaved image and text dataset | 43M webpages | For each webpage, they sample a random subsequence of 256 tokens and take up to the first 5 images included in the sampled sequence. | 1.0 |
| ALIGN | (Image, text) pairs | 1.8B pairs | Texts are alt-texts, averaging 12 tokens/text. | 0.2 |
| LTIP | (Image, text) pairs | 312M pairs | Texts are long descriptions, averaging 20.5 tokens/text. | 0.2 |
| VTP | (Video, text) pairs | 27M short videos | ~22 seconds/video on average | 0.03 |
Flamingo 的视觉编码器
Flamingo 首先使用对比学习从头开始训练类似 CLIP 的模型。该组件仅使用 2 个(图像、文本)对数据集:ALIGN 和 LTIP,总共 2.1 M万个(图像、文本)对。这比 CLIP 训练的数据集大 5 倍。
- 对于文本编码器,Flamingo 使用 BERT 而不是 GPT-2。
- 对于视觉编码器,Flamingo 使用 NormalizerFree ResNet (NFNet) F6 模型。
- 文本和视觉嵌入在投影到联合嵌入空间之前进行均值池化。
Flamingo的语言模型
Flamingo 使用 Chinchilla 作为它们的语言模型。更具体地说,他们冻结了 9 个预训练的 Chinchilla LM 层。传统的语言模型根据前面的文本标记来预测下一个文本标记。Flamingo 根据前面的文本和视觉标记预测下一个文本标记。
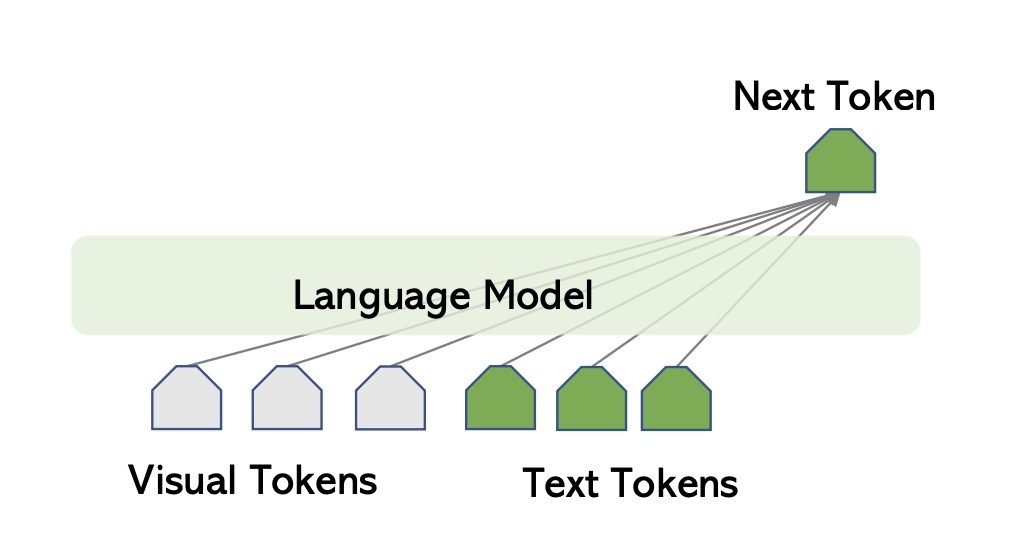
下一个Token的生成以文本和视觉Token为条件。插图取自 Chunyuan Li 的 CVPR 2023 教程:大型多模态模型。
为了能够根据文本和视觉输入生成文本,Flamingo 依赖于 Perceiver Resampler 和 GATED XATTN-DENSE 层。
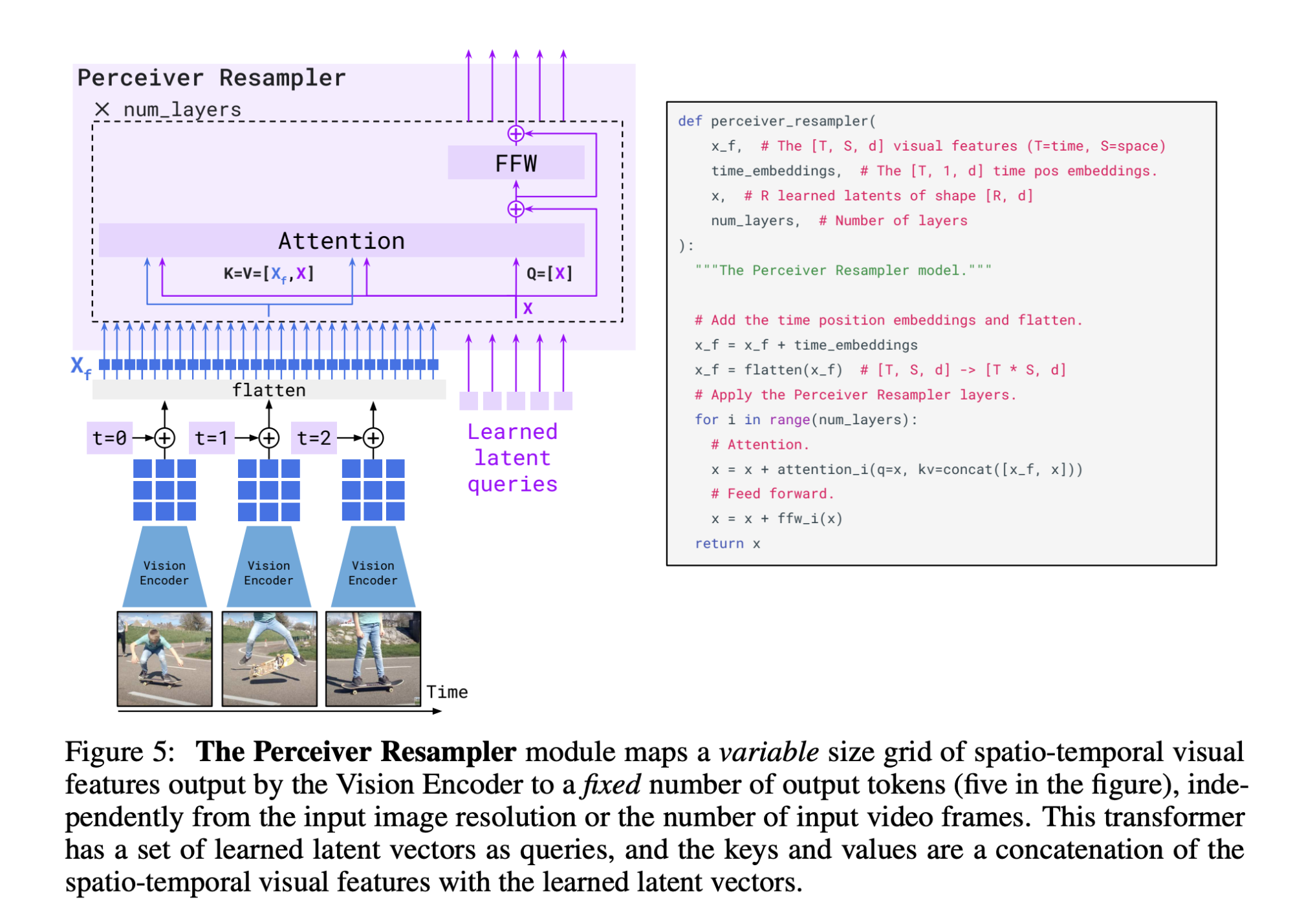
Perceiver Resampler
由于视觉输入可以是图像和视频,因此视觉编码器可以产生可变数量的图像或视频特征。Perceiver Resampler 将这些可变特征转换为一致的 64 个视觉输出。
有趣的是,在训练视觉编码器时,使用的分辨率为 288 x 288。然而,在此阶段,视觉输入大小调整为 320 × 320。事实证明,使用 CNN 时,更高的测试时分辨率可以提高性能。
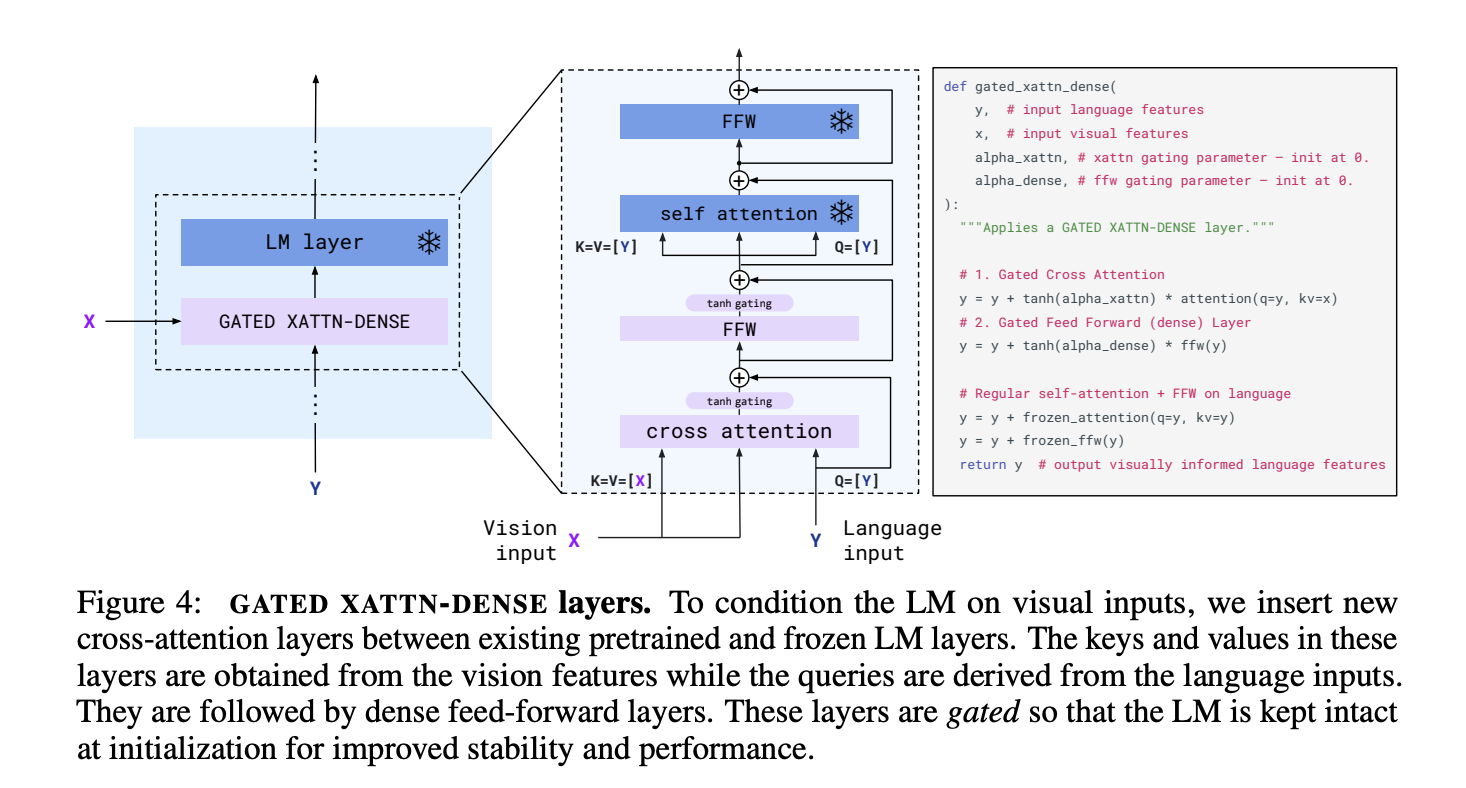
门控 XATTN-DENSE 层
门控 XATTN-DENSE 层插入现有的和冻结的 LM 层之间,以允许语言模型在生成文本标记时更有效地处理视觉标记。如果没有这些层,Flamingo 作者指出总体得分下降了 4.2%。
损失函数
Flamingo 计算以交错的图像和视频$x$为条件的文本$y$ 的似然函数 。
$$p(y|x) = \prod_{l=1}^N p(y_l|y_{<l}, x_{\leq l})$$
训练损失函数是所有 4 个数据集生成文本的预期负对数似然的加权和,其中$\lambda_m$是数据集$m$的训练权重。
$$\sum_{m=1}^M \lambda_m E_{(x, y)\sim D_m} [ -\sum_{l=1}^L \log p(y|x)]$$
训练
虽然 Chinchilla LM 层经过微调和冻结,但附加组件是使用所有 4 个具有不同权重的 Flamingo 数据集从头开始训练的。找到正确的每个数据集权重是性能的关键。每个数据集的权重位于上面数据集表的“训练权重”列中。
VTP 的权重比其他数据集小得多(0.03 与 0.2 和 1 相比),因此它对训练的贡献应该很小。然而,作者指出,删除该数据集会对所有视频任务的性能产生负面影响。
虽然 Flamingo 不是开源的,但有许多 Flamingo 的开源复制品。
CLIP 与 Flamingo
第 3 部分. LMM 的研究方向
CLIP 已经 3 岁了,Flamingo 也快 2 岁了。虽然他们的架构为我们理解 LMM 的构建方式奠定了良好的基础,但该领域已经取得了许多新的进展。
以下是一些令我兴奋的方向。这远不是一个详尽的列表,既因为这篇文章很长,又因为我仍在了解这个领域。如果您有任何指示或建议,请告诉我!
纳入更多数据模态
如今,大多数多模态系统都使用文本和图像。我们需要能够整合视频、音乐和 3D 等其他模态的系统只是时间问题。为所有数据模态提供一个共享嵌入空间,这不是一件令人惊奇的事情吗?
在这个领域的研究包括:
- ULIP: Learning a Unified Representation of Language, Images, and Point Clouds for 3D Understanding (Xue et al., Dec 2022)
- ImageBind: One Embedding Space To Bind Them All (Girdhar et al., May 2023)
- NExT-GPT: Any-to-Any Multimodal Large Language Model (Wu et al., Sep 2023)
- Jeff Dean 雄心勃勃的Pathways项目(2021 年):其愿景是“实现同时包含视觉、听觉和语言理解的多模态模型。”

用于遵循指令的多模态系统
Flamingo 接受了补全任务的训练,但没有接受对话或遵循指令的训练。(如果您不熟悉完成与对话,请查看我在RLHF上的帖子)。许多人正在致力于构建可以遵循指令并进行对话的 LMM,例如:
- MultiInstruct: Improving Multi-Modal Zero-Shot Learning via Instruction Tuning (Xu et al., Dec 2022)
- LLaVA: Visual Instruction Tuning (Liu et al., Apr 28, 2023)
- InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning (Salesforce, May 11, 2023)
- LaVIN: Cheap and Quick: Efficient Vision-Language Instruction Tuning for Large Language Models (Luo et al., May 24, 2023)

LaVIN 的输出示例与其他 LMM 相比,如 LaVIN 的论文所示
更高效的多模态训练适配器
虽然 Flamingo 使用了 Chinchilla 的 9 个预训练和冻结层,但它必须从头开始预训练其视觉编码器、Perceiver Resampler和GATED XATTN-DENSE层。这些从头开始训练的模块可能需要大量计算资源。许多研究侧重于使用更少的从头开始训练来启动多模态系统的更高效方法。
在这个领域的一些研究非常有前途。例如,BLIP-2在零样本VQA-v2上的性能比Flamingo-80B高出了8.7%,并且可训练参数少了54倍。
在这个领域的研究包括:
- BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models
- [LAVIN] Cheap and Quick: Efficient Vision-Language Instruction Tuning for Large Language Models
- LLaMA-Adapter V2: Parameter-Efficient Visual Instruction Model
下面的两张图片来自 Chunyuan Li在 CVPR 2023 上的 Large Multimodal Models ,顺便说一句,这是一个很棒的教程。
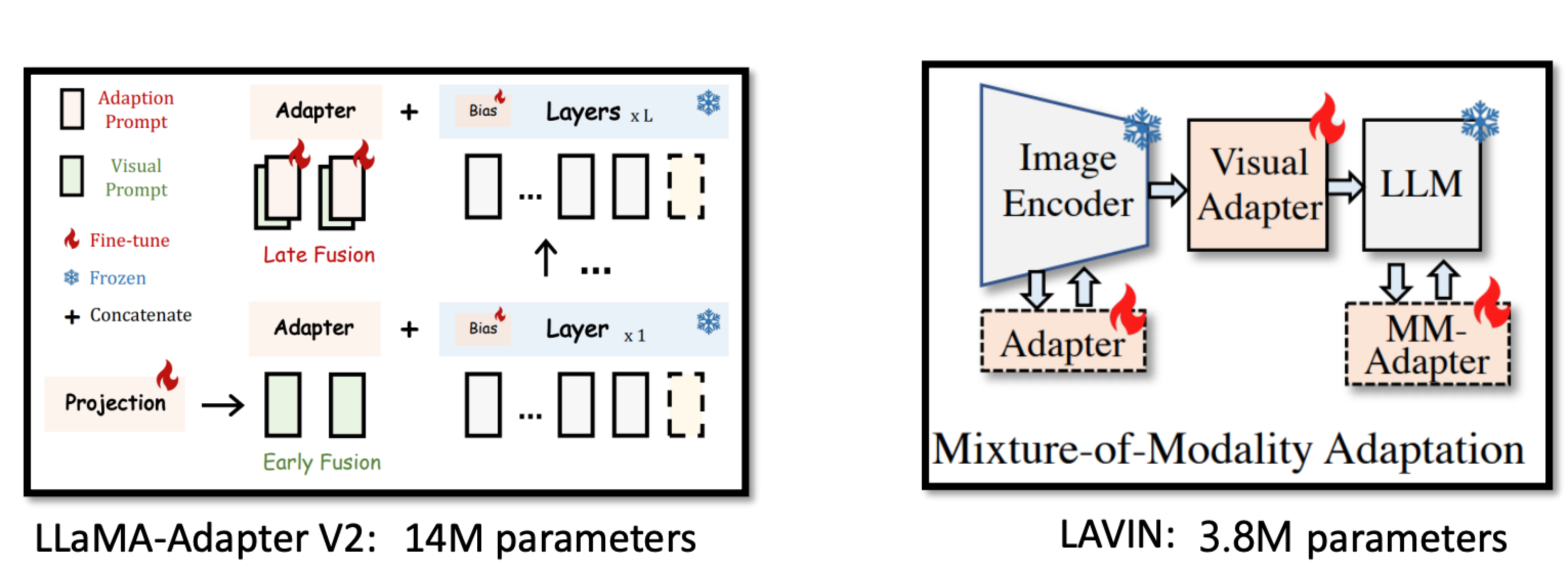
生成多模态输出
虽然能够处理多模态输入的模型正变得普遍,但多模态输出仍然滞后。许多应用场景需要多模态输出。例如,如果我们要求ChatGPT解释RLHF,一个有效的解释可能需要图表、方程式,甚至简单的动画。
为了生成多模态输出,模型首先需要生成一个共享的中间输出。一个关键问题是中间输出应该是什么样子的。
一个中间输出的选择是文本,然后将其用于生成/合成其他操作。
例如,CM3(Aghajanyan 等人,2022)输出 HTML 标记,该标记可以编译成不仅包含文本还包含格式、链接和图像的网页。GPT-4V 生成 Latex 代码,然后可以将其重建为数据表。

CM3 的采样输出
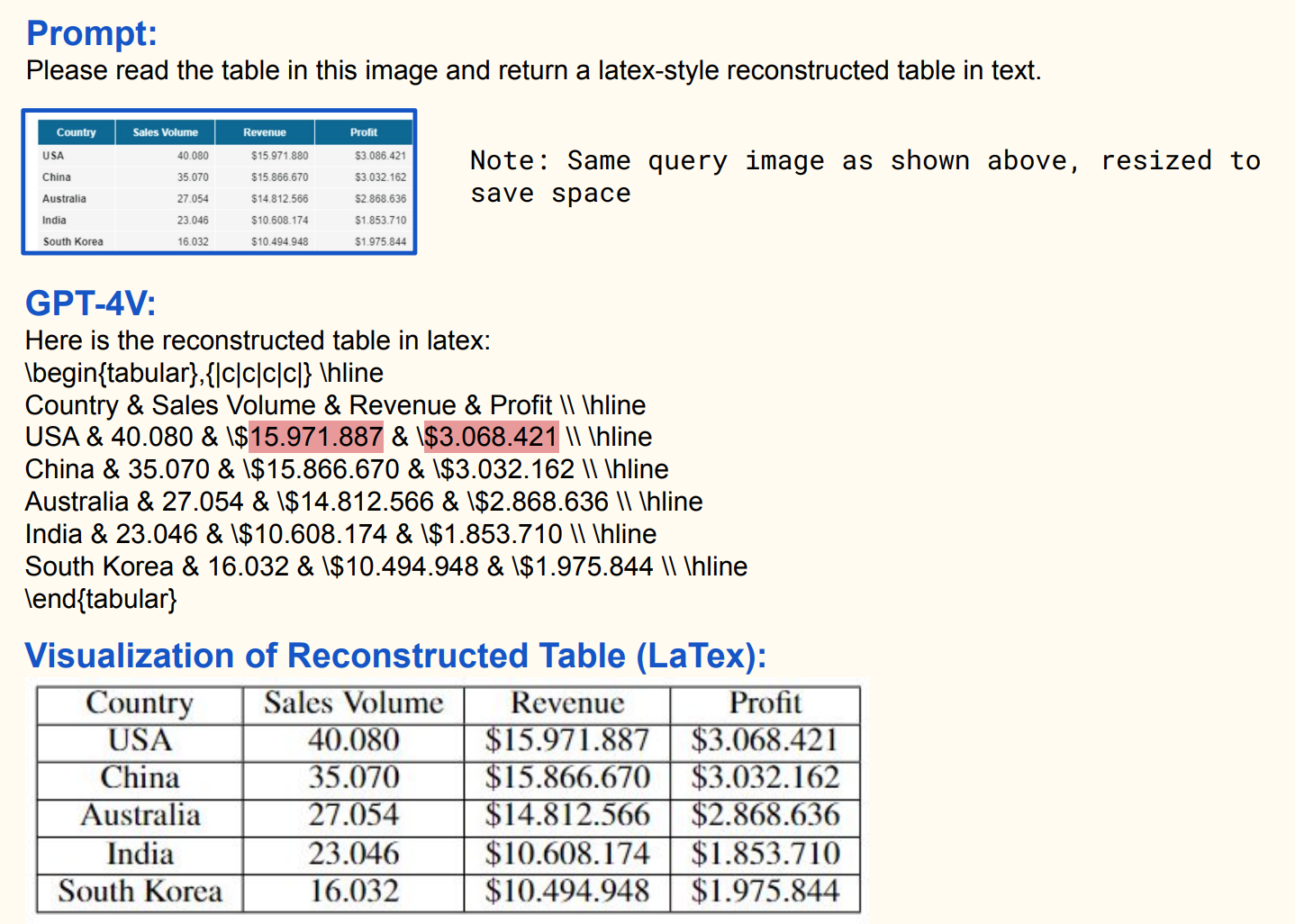
GPT-4V生成Latex代码,然后可以将其重建为数据表
另一个中间输出的选择是多模态标记。这是Salesforce团队的Caiming Xiong告诉我的选择。他的 Salesforce 团队在多模态方面做了很多出色的工作。每个标记将有一个标签,表示它是文本标记还是图像标记。然后,图像标记将被输入到像Diffusion这样的图像模型中,以生成图像。文本标记将被输入到语言模型中。
使用多模态语言模型生成图像(Koh 等人,2023 年 6 月)是一篇很棒的论文,展示了 LMM 如何在生成文本的同时生成和检索图像。见下文。
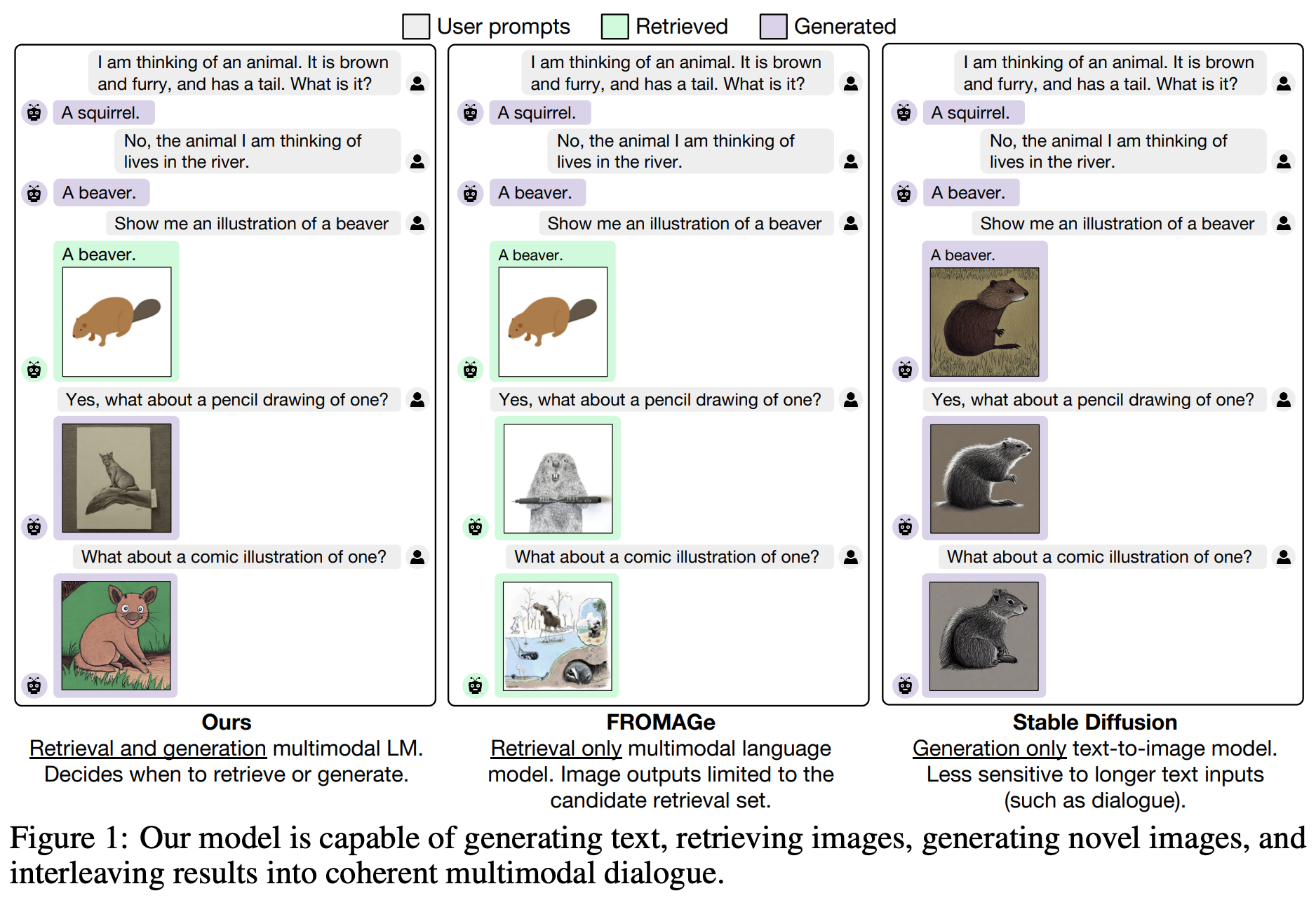
结论
总的来说,在这篇博文中,我回顾了很多多模态论文,并与正在进行出色工作的人们交流,试图在一篇博文中总结关键要点。多模态系统还处于早期阶段(早到一个朋友告诉我他不确定LMM缩写是否会流行起来的阶段)。是的,在我大部分的对话中,人们普遍认为多模态系统总体上,尤其是大型多模态模型,将比大型语言模型更具影响力。但请记住,LMMs并不会使LLMs过时。由于LMMs在LLMs的基础上进行了扩展,LMM的性能依赖于其基础LLM的性能。许多实验室同时致力于多模态系统和大型语言模型的研究。
Resources
Awesome Paper with code










Models
An incomplete list of multimodal systems by time to give you a sense of how fast the space is moving!
- Microsoft COCO Captions: Data Collection and Evaluation Server (Apr 2015)
- VQA: Visual Question Answering (May 2015)
- VideoBERT: A Joint Model for Video and Language Representation Learning (Google, Apr 3, 2019)
- LXMERT: Learning Cross-Modality Encoder Representations from Transformers (UNC Chapel Hill, Aug 20, 2019)
- CLIP: Learning Transferable Visual Models From Natural Language Supervision (OpenAI, 2021)
- Unifying Vision-and-Language Tasks via Text Generation (UNC Chapel Hill, May 2021)
- BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation (Salesforce, Jan 28, 2022)
- Flamingo: a Visual Language Model for Few-Shot Learning (DeepMind, April 29, 2022)=
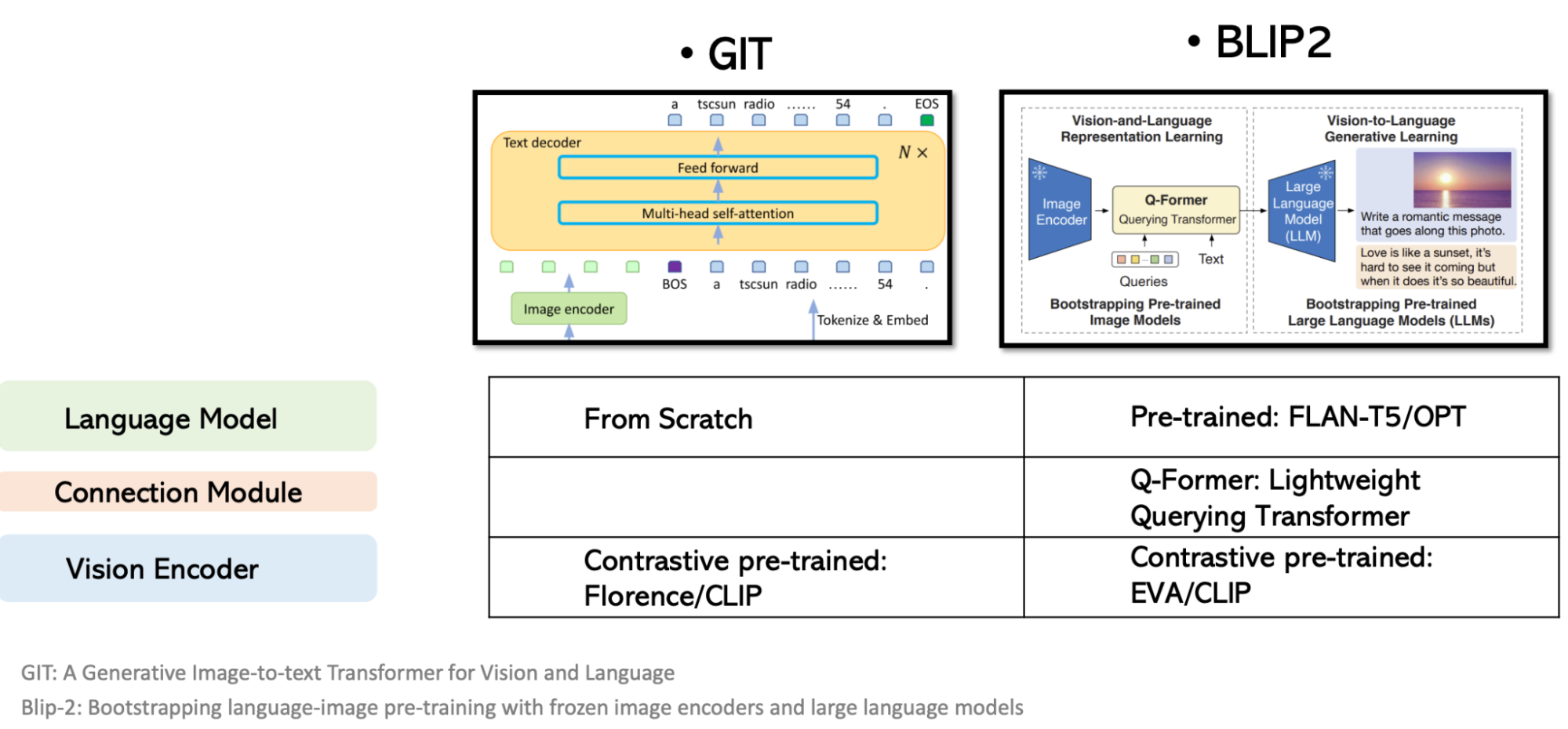
- GIT: A Generative Image-to-text Transformer for Vision and Language (Microsoft, May 2, 2022)
- MultiInstruct: Improving Multi-Modal Zero-Shot Learning via Instruction Tuning (Xu et al., Dec 2022)
- BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models (Salesforce, Jan 30, 2023)
- Cross-Modal Fine-Tuning: Align then Refine (Shen et al., Feb 11, 2023)
- KOSMOS-1: Language Is Not All You Need: Aligning Perception with Language Models (Microsoft, Feb 27, 2023)
- PaLM-E: An Embodied Multimodal Language Model (Google, Mar 10, 2023)
- LLaMA-Adapter: Efficient Fine-tuning of Language Models with Zero-init Attention (Zhang et al., Mar 28, 2023)
- mPLUG-Owl: Modularization Empowers Large Language Models with Multimodality (Ye et al., Apr 2, 2023)
- LLaMA-Adapter V2: Parameter-Efficient Visual Instruction Model (Gao et al., Apr 28, 2023)
- LLaVA: Visual Instruction Tuning (Liu et al., Apr 28, 2023)
- X-LLM: Bootstrapping Advanced Large Language Models by Treating Multi-Modalities as Foreign Languages (Chen et al., May 7, 2023)
- InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning (Salesforce, May 11, 2023)
- Towards Expert-Level Medical Question Answering with Large Language Models (Singhal et al., May 16, 2023)
- Cheap and Quick: Efficient Vision-Language Instruction Tuning for Large Language Models (Luo et al., May 24, 2023)
- Shikra: Unleashing Multimodal LLM’s Referential Dialogue Magic (SenseTime, Jun 3, 2023)
- Macaw-LLM: Multi-Modal Language Modeling with Image, Audio, Video, and Text Integration (Tencent, Jun 15, 2023)
Other resources
[CVPR2023 Tutorial Talk]
Large Multimodal Models: Towards Building and Surpassing Multimodal GPT-4
- Slides: Large Multimodal Models
[CMU course] 11-777 MMML
[Open source] Salesforce’s LAVIS