Align before Fuse (ALBEF):通过对比学习促进视觉语言理解
TL; DR:我们提出了一种新的视觉语言表示学习框架,该框架通过在融合之前首先对齐单模态表示来实现最先进的性能。
背景
视觉和语言是人类感知世界的两个最基本的渠道。构建能够共同理解视觉数据(图像)和语言数据(文本)的智能机器一直是人工智能领域的长期目标。视觉和语言预训练(VLP)已成为解决这一问题的有效方法。然而,现有方法具有三个主要局限性。
- 限制1:以CLIP[2]和ALIGN[3]为代表的方法学习单模态图像编码器和文本编码器,并在表示学习任务上取得了令人印象深刻的性能。然而,它们缺乏对图像和文本之间复杂交互进行建模的能力,因此它们不擅长需要细粒度图像文本理解的任务。
- 限制2:UNITER[4]代表的方法采用多模态编码器对图像和文本进行联合建模。然而,多模态转换器的输入包含未对齐的基于区域的图像特征和单词标记嵌入。由于视觉特征和文本特征驻留在各自的空间中,因此多模态编码器学习对它们的交互进行建模具有挑战性。此外,大多数方法使用预先训练的目标检测器进行图像特征提取,这既昂贵又计算昂贵。
- 限制 3:用于预训练的数据集主要由从网络收集的噪声图像文本对组成。广泛使用的预训练目标,例如掩码语言模型(MLM),很容易过度拟合噪声文本,从而损害表示学习。
为了解决这些限制,我们提出了 ALign BEfore Fuse ( ALBEF ),一种新的视觉语言表示学习框架。ALBEF 在图像文本检索、视觉问答 (VQA) 和自然语言视觉推理 (NLVR) 等多种视觉语言下游任务上实现了最先进的性能。接下来,我们将解释 ALBEF 的工作原理。
将单模态表示与图像文本对比学习结合起来
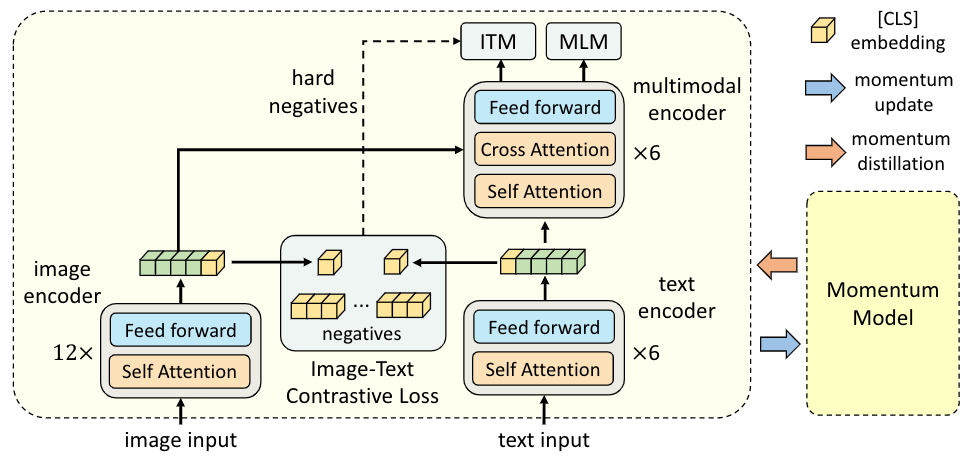 ALBEF框架
ALBEF框架
如上图所示,ALBEF 包含图像编码器(ViT-B/16)、文本编码器(BERT 的前 6 层)和多模态编码器(BERT 的后 6 层,带有额外的交叉注意力层)。我们通过联合优化以下三个目标来预训练 ALBEF:
- 目标 1:图像-文本对比学习应用于单模态图像编码器和文本编码器。它将图像特征和文本特征对齐,并训练单模态编码器以更好地理解图像和文本的语义。
- 目标2:应用于多模态编码器的图像文本匹配,预测一对图像和文本是正(匹配)还是负(不匹配)。我们提出了对比 hard negative mining ,它选择具有更高对比相似性的信息负例。
- 目标 3:应用于多模态编码器的掩码语言建模。我们随机屏蔽文本标记,并训练模型使用图像和屏蔽文本来预测它们。
从嘈杂的图像文本对中学习的动量蒸馏
从网络收集的图像文本对通常是弱相关的:文本可能包含与图像无关的单词,或者图像可能包含文本中未描述的实体。为了从噪声数据中学习,我们提出了动量蒸馏,其中我们使用动量模型来生成图像文本对比学习和掩蔽语言建模的伪目标。下图显示了图像的伪正文本示例,它产生了“年轻女子”和“树”等新概念。我们还从互信息最大化的角度提供了理论解释,表明动量蒸馏可以解释为为每个图像-文本对生成视图。

图像的伪正文本
期待
ALBEF 是一个简单、端到端且功能强大的视觉语言表示学习框架。我们已经发布了pre-trained model and code 以促进对这一重要主题的更多研究。如果您有兴趣了解更多信息,请查看我们的论文。
References
- Align before Fuse: Vision and Language Representation Learning with Momentum Distillation. arXiv preprint arXiv: 2107.07651, 2021.
- Learning transferable visual models from natural language supervision. arXiv preprint arXiv:2103.00020, 2021.
- Scaling up visual and vision-language representation learning with noisy text supervision. arXiv preprint arXiv:2102.05918, 2021.
- UNITER: universal image-text representation learning. In ECCV, 2020.