CoCa: Contrastive Captioners are Image-Text Foundation Models
机器学习的发展导致了基础模型的发展,基础模型是一类根据大量数据预先训练的模型,可作为无数应用程序的通用基础。这些模型以自然语言处理 (NLP) 中的 GPT 和 BERT 等为代表,在零样本和少样本学习等任务中展示了前所未有的能力。
在本文中,我们深入研究图像文本基础模型领域,探索创新的Contrastive Captioner (CoCa) (CoCa)模型。我们将剖析其架构,了解其结合对比目标和生成目标的独特方法,看看它是如何将CLIP和SIMVLM等模型的能力嵌入到一个统一的、连贯的模型中的。
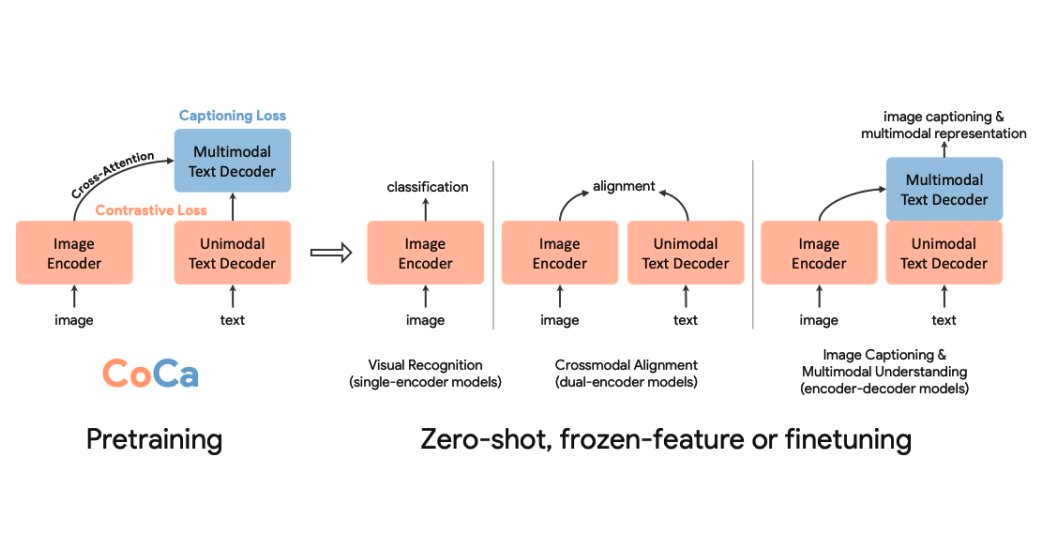
图 1 - 对比字幕 (CoCa)
基础模型的兴起
基础模型的想法在机器学习中并不是什么新鲜事。在深度学习中,能够训练这些模型的技术使我们能够在未来针对下游任务调整模型。在 NLP 领域, GPT和 BERT等基础模型蓬勃发展,这些模型在嘈杂的互联网规模数据上进行训练,展示了卓越的零样本和少样本能力。
构建视觉和视觉语言基础模型的研究尝试探索了三种主要路径:单编码器模型、具有对比损失的图像文本双编码器模型以及具有生成目标的编码器-解码器模型。在探索 CoCa 模型之前,让我们先看一下构建基础模型的这些研究路线及其缺点。
词汇表
Foundation Models:在机器学习中作为各种应用的起点的预训练模型,可适应特定任务。
Contrastive Loss.: 一种损失函数,用于训练模型学习相似输入对的相似表示以及不同输入对的不同表示。
Cross-Modal Interaction: 不同类型数据模态(例如图像和文本)之间的交互,用于生成联合表示。
Encoder-Decoder Architecture: 一种神经网络结构,具有用于处理输入数据的编码器和用于生成输出的解码器,用于序列到序列任务。
Causal Masking Transformer: 模型中的一项技术,用于防止在训练期间访问序列中的未来标记。
Attention Mechanism :允许模型在处理信息时对输入的不同部分进行加权和优先排序的组件。
Zero-Shot Learning: 一种学习范例,模型对训练期间未见过的数据类进行预测或分类。
Visual Question Answering (VQA): 模型结合计算机视觉和自然语言处理回答有关图像内容的问题的任务。
Unimodal and Multimodal Representations:单模态表示从一种数据模态中捕获信息,而多模态表示集成了来自多个模态的信息。
Contrastive Language-Image Pre-training (CLIP): 使用对比学习训练的模型,将图像和文本在共享表示空间中对齐。
Single Encoder Models
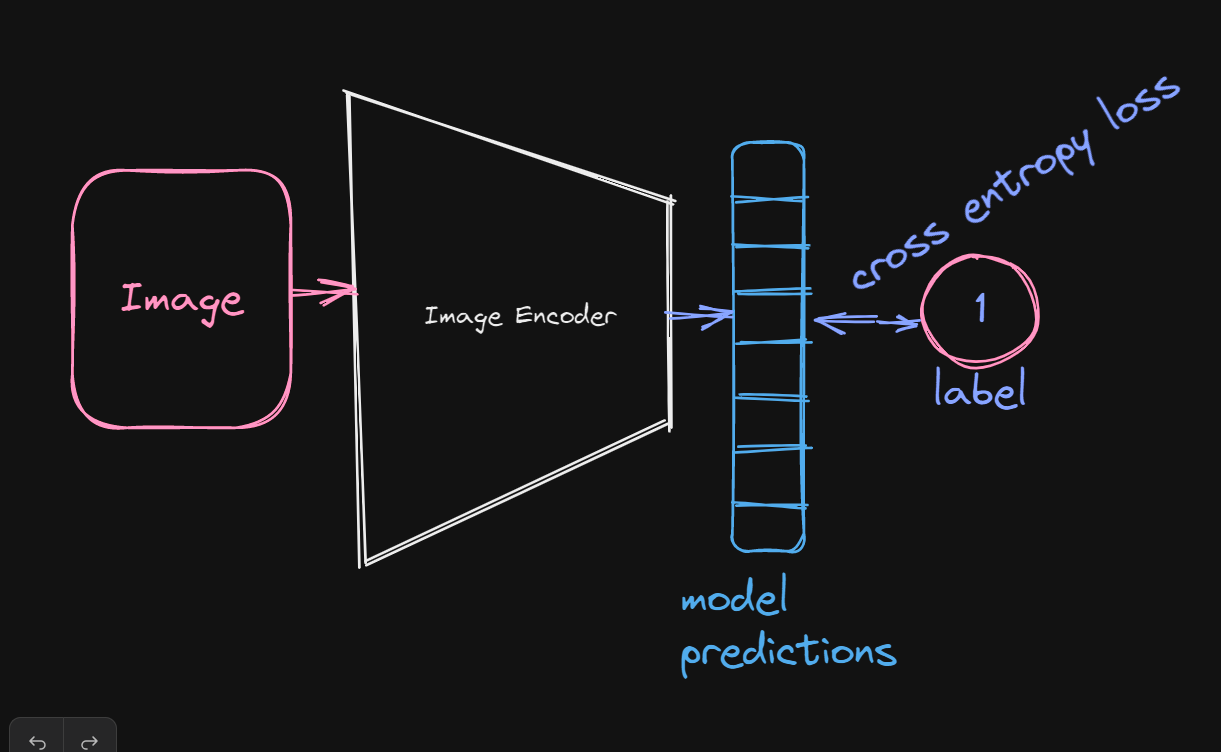
如果您以前涉足过计算机视觉,那么你可能已经接触过这类模型。这些模型学习图像的表示,可以通过在具有交叉熵损失的带注释图像的大型数据集上进行训练来适应下游视觉任务。
经验表明,这些模型在检测等与视觉相关的任务中表现出色,但在涉及视觉语言的任务中表现较差,因为它们严重依赖人类注释,这阻止了将人类自然语言融入到模型中。
图像-文本双编码器模型与对比损失
这类视觉语言基础模型的流行模型包括 CLIP(对比语言图像预训练)和 ALIGN。
在预训练期间,我们通过使用对比损失联合训练图像和语言模型来学习对齐任务。
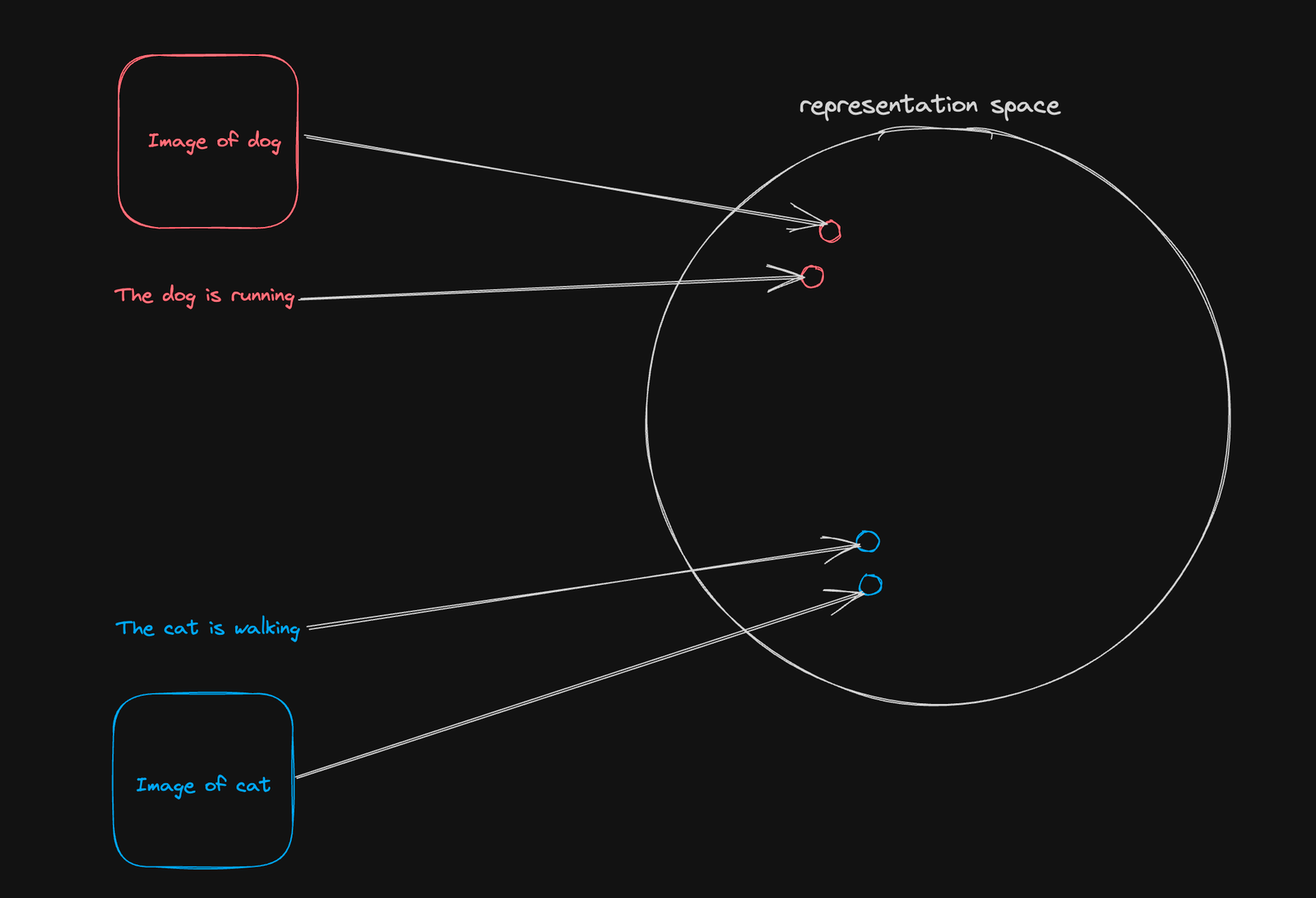
他们的预训练目标背后的想法非常简单:将图像-文本对的表示聚集在一起(它们是相关的),并将同一潜在空间中不相关的图像和文本的表示(对)分开。然后得到的双编码器模型可以用于执行零样本分类任务和图像检索。
这类模型的最近版本,比如CLIP,已经在各种视觉语言任务中取得了出色的性能,但几乎无法用于需要图像和文本融合表示的任务,比如视觉问答,因为我们只学会了对齐图像和文本表示,而没有生成一个统一的既包含图像又包含文本输入信息的表示。
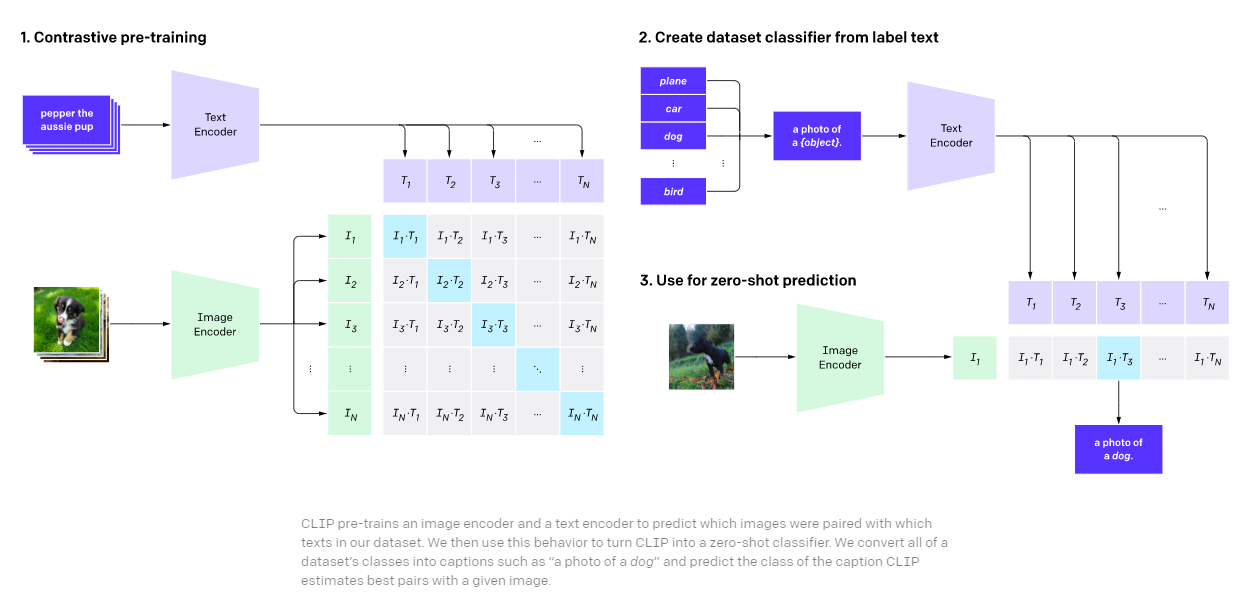
图 3 - 对比语言-图像预训练 (CLIP)
生成式预训练与编码器-解码器架构
这类模型利用图像和文本的隐藏表示之间的跨模态交互来生成联合表示。
在预训练期间,我们通过在隐藏文本表示和图像编码器输出之间的跨模式交互生成图像和文本的统一表示,并对解码器输出应用语言建模损失。
在最近的机器学习体系结构中,跨模态交互主要通过变压器中的交叉注意机制执行,使用图像编码器的输出作为查询,隐藏文本表示作为键和值。
对于下游任务,我们可以使用解码器的输出(图像和文本的联合表示)执行各种多模态图像-文本理解任务,比如视觉问答。最近使用这种范例的一个模型是Simple Visual Language Model(SIMVLM)。
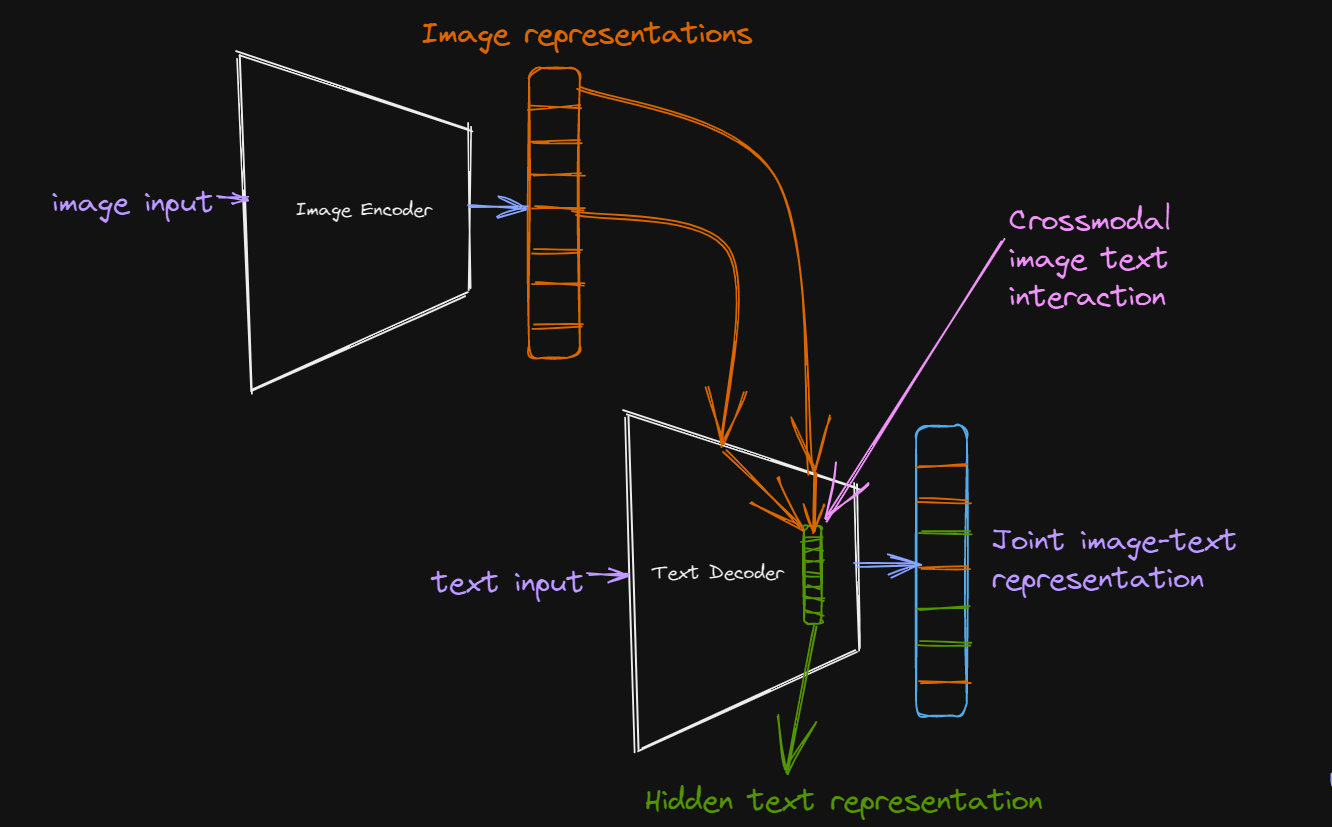
对于下游任务,我们可以获取解码器输出(图像和文本的联合表示),并执行各种多模态图像文本理解任务,例如视觉问答。使用这种范式的最新模型是简单视觉语言模型(SIMVLM)。
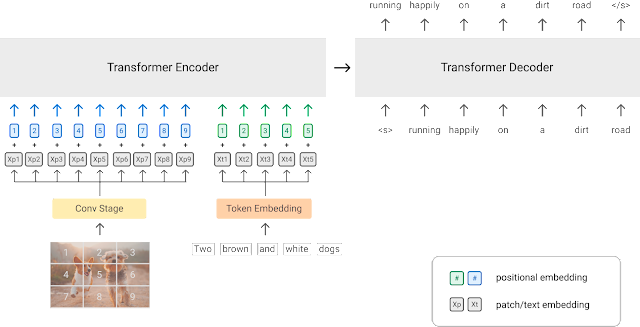
图 5 - 简单视觉语言模型 (SIMVLM)
CoCa模型的动机
CoCa模型的作者试图将构建图像-文本基础模型的不同范式的能力合并到一个简单的模型中。CoCa的设计利用了对比损失来学习在一个向量空间中对齐图像和文本表示,以及一个生成目标(字幕损失)来学习联合图像-文本表示,从而将CLIP和SIMVLM等模型的能力嵌入到一个单一的、连贯的模型中。
模型架构
CoCa采用了标准的编码器-解码器方法,与大多数此类模型一样,使用神经网络(如卷积神经网络或变压器)对图像进行编码。
CoCa 架构的独特性始于其编码器的输出和整个解码器设置。
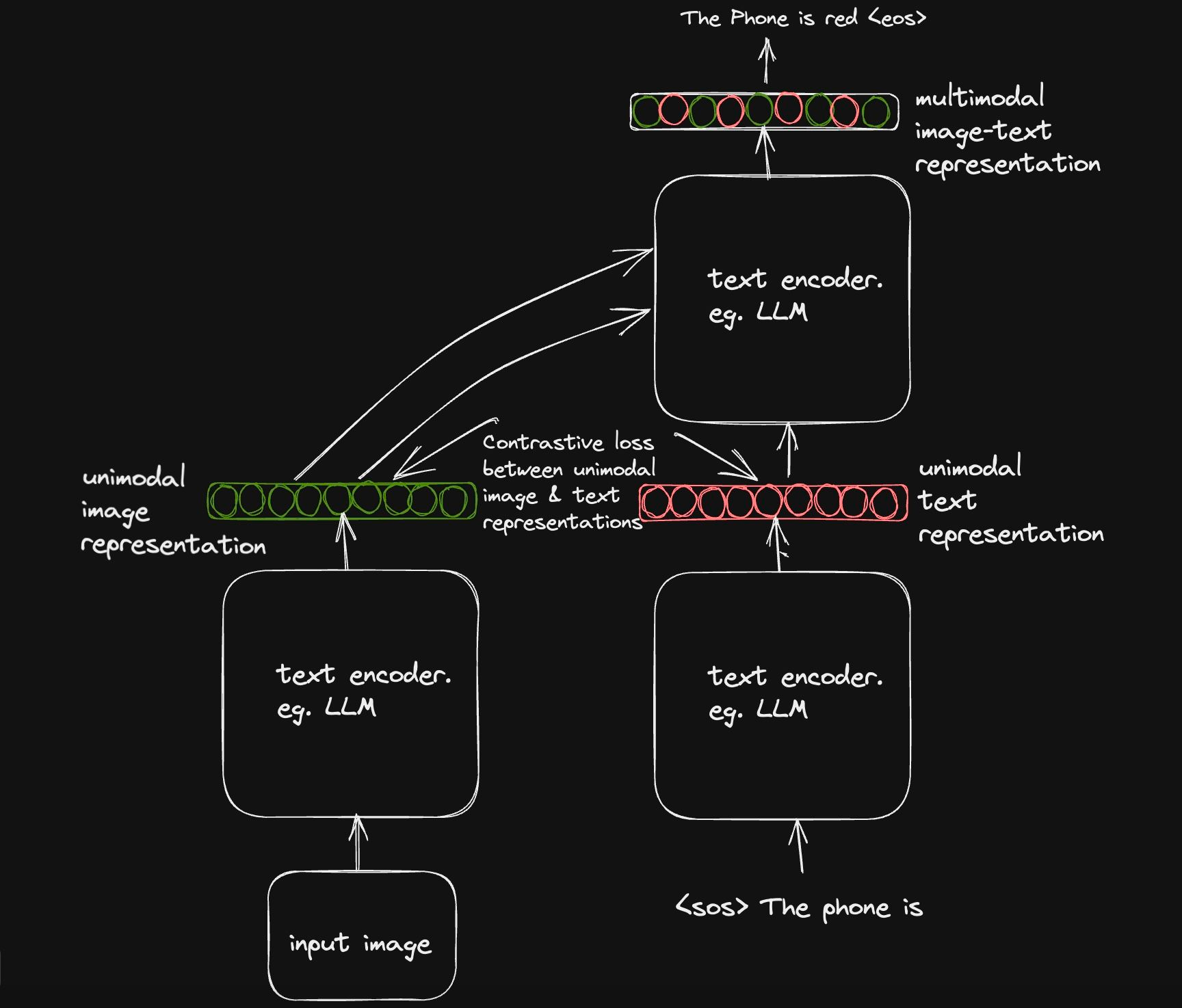
回想一下, CoCa 论文的目的是将两种视觉语言模型范式(对比目标和生成目标)的功能结合到一个模型中。对比目标范式要求我们的文本解码器输出一个单一的文本表示,然后将其投影到与图像表示相似的向量空间中,以学习对齐任务。
另一方面,生成目标允许解码器从编码器获取图像表示,并根据图像表示和文本输入自动回归生成文本。
请注意,两个解码器部分都应用了因果屏蔽,以防止模型提前查看标记。
请注意,两个解码器部分都应用了因果屏蔽,以防止模型提前查看标记。
为了实现这一目标,作者巧妙地采用了一种解耦的解码器设置,第一部分学习为对比目标生成单模态文本表示,第二部分学习生成多模态图像-文本表示。
对比目标
对比目标背后的思想,正如在CLIP和ALIGN等多个模型中所使用的,相当简单。其思想是学习不同模态(如图像和文本)的表示,使得相似的对在表示空间中更接近,而不相似的对则更远离彼此。
在每个训练步骤中,我们从数据集中抽取图像-文本对的样本,并驱使我们的编码器的权重,使其将样本对聚类在一起,并将非对应的样本推开。
正如前面提到的,对比目标要求图像和文本模态的单模态表示。为了在文本编码器方面实现这一点,我们采用了BERT语言模型中使用的经典技术。
作为输入序列的一部分,我们在输入序列的末尾引入了一个可学习的分类标记[CLS],希望映射到该标记的输出向量将捕捉整个输入序列的语义含义。
由于我们的解码器对其注意力图进行因果屏蔽,将分类标记添加到序列的末尾可以确保分类标记与输入序列中的所有其他标记之间存在注意力连接,从而捕捉整个句子的语义含义。
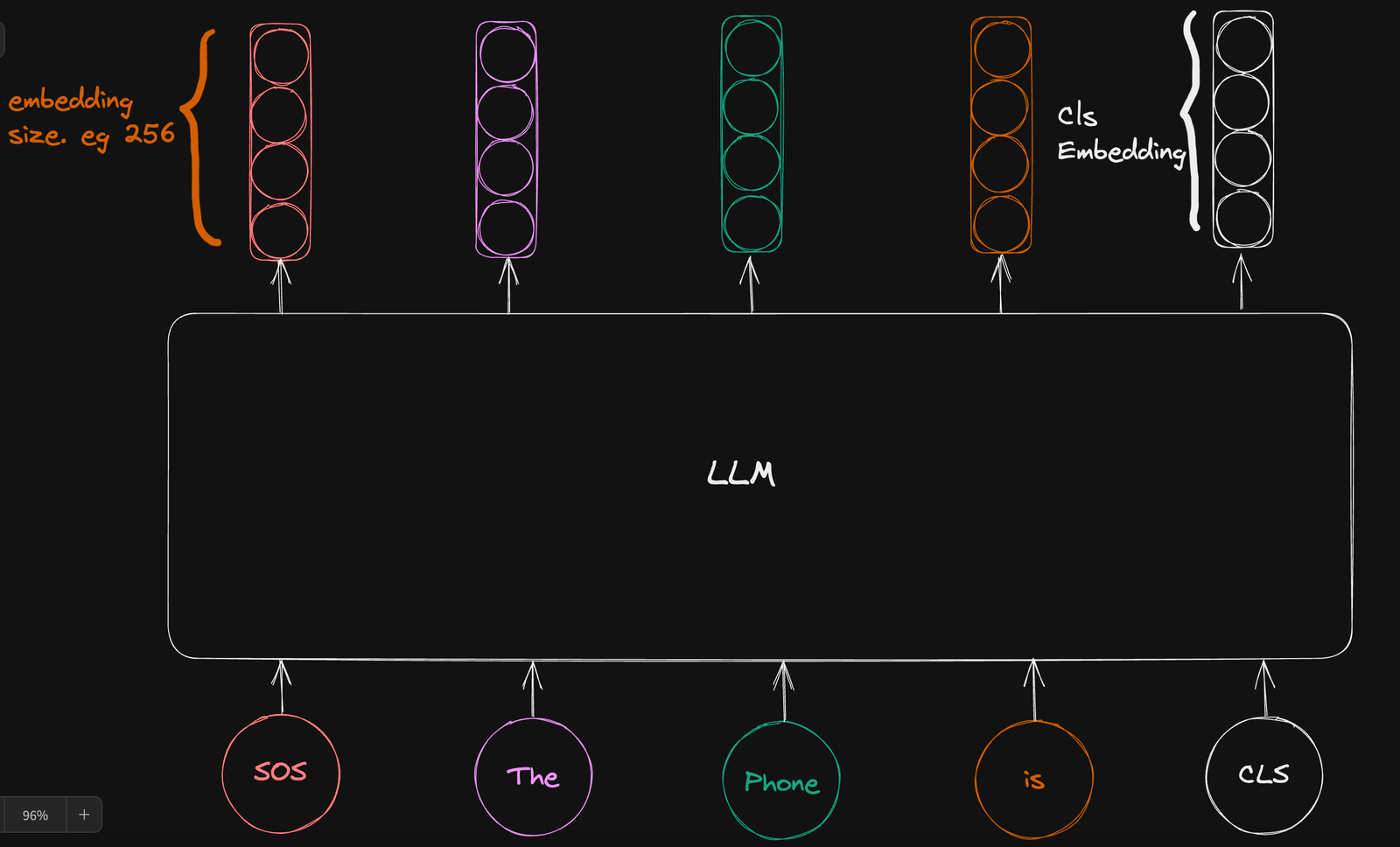
我们忽略其他输入标记的向量表示,并使用分类标记的向量表示来估计对比损失。
在图像编码器方面,情况略有不同。
在图-6中,你可以看到图像编码器的输出的一部分与分类标记嵌入一起用于估计对比损失,而另一部分则发送到解耦设置的上部,用于估计联合表示。
事实上,只需要图像的单个嵌入输出来估计对比目标,而整个图像编码器的嵌入输出序列用于估计生成目标。
作者认为,他们能够经验性地确定,单个池化嵌入输出有助于捕捉图像的全局表示(这正是我们希望实现的对比目标),而嵌入输出序列有助于需要图像的更细粒度表示的任务。
为了实现这一目标,引入了一个注意池化层,它是一个单一的多头注意层,通过一个可学习的查询参数将图像编码器输出定制为不同目标的嵌入序列。通过将查询参数设置为特定的整数值,我们可以使得整个编码器设置输出一个嵌入序列,其长度是查询参数。
在对比目标的情况下,我们将查询参数设置为 1 以获得单个嵌入来计算对比损失,在我们的生成目标情况下,我们将其设置为任意值,理想情况下等于我们的序列长度文本。在 CoCa 论文中,作者选择了 256 作为生成目标。
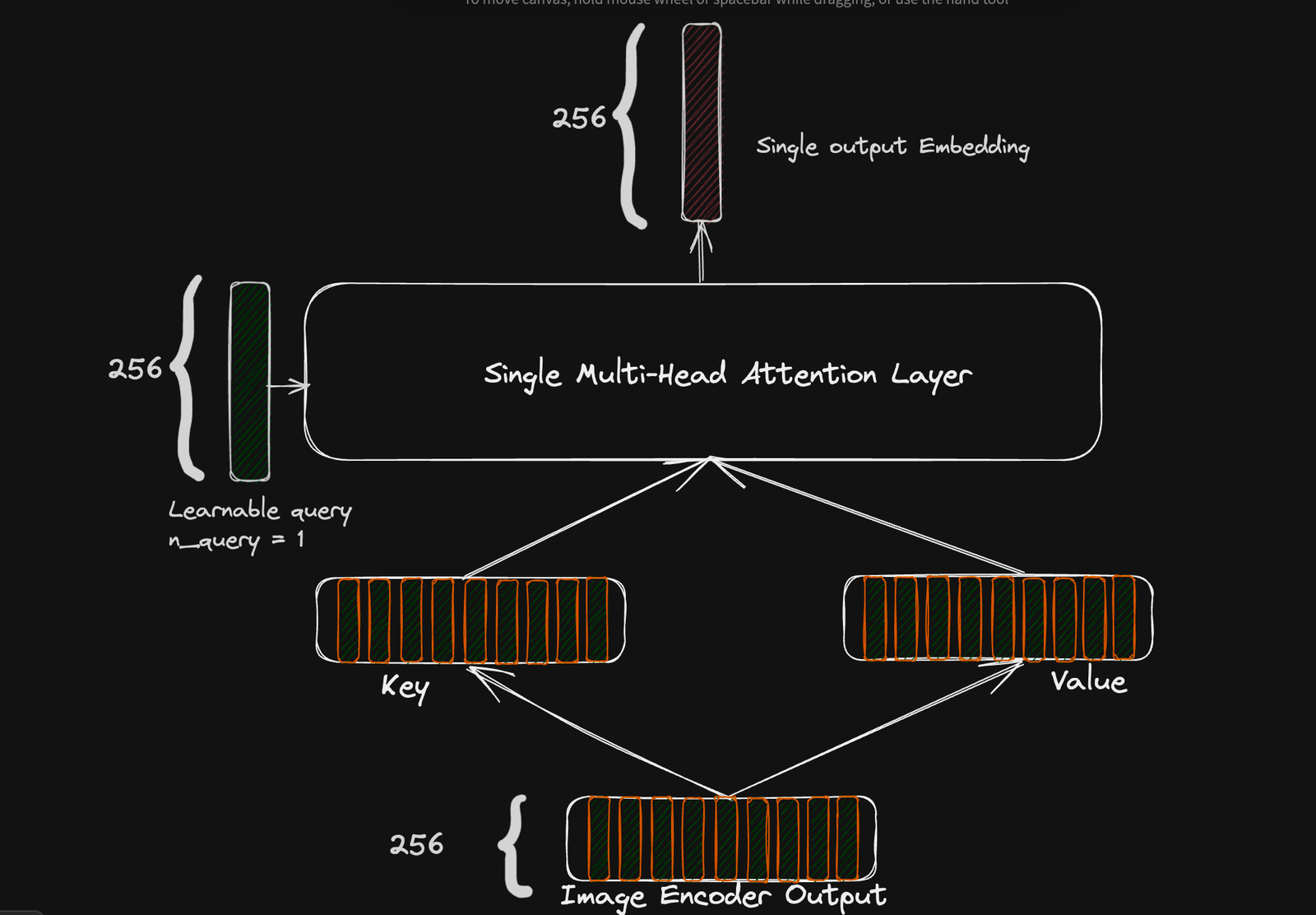
用于对比损失的注意力池设置。注意力层的输出是单个 256 维嵌入。
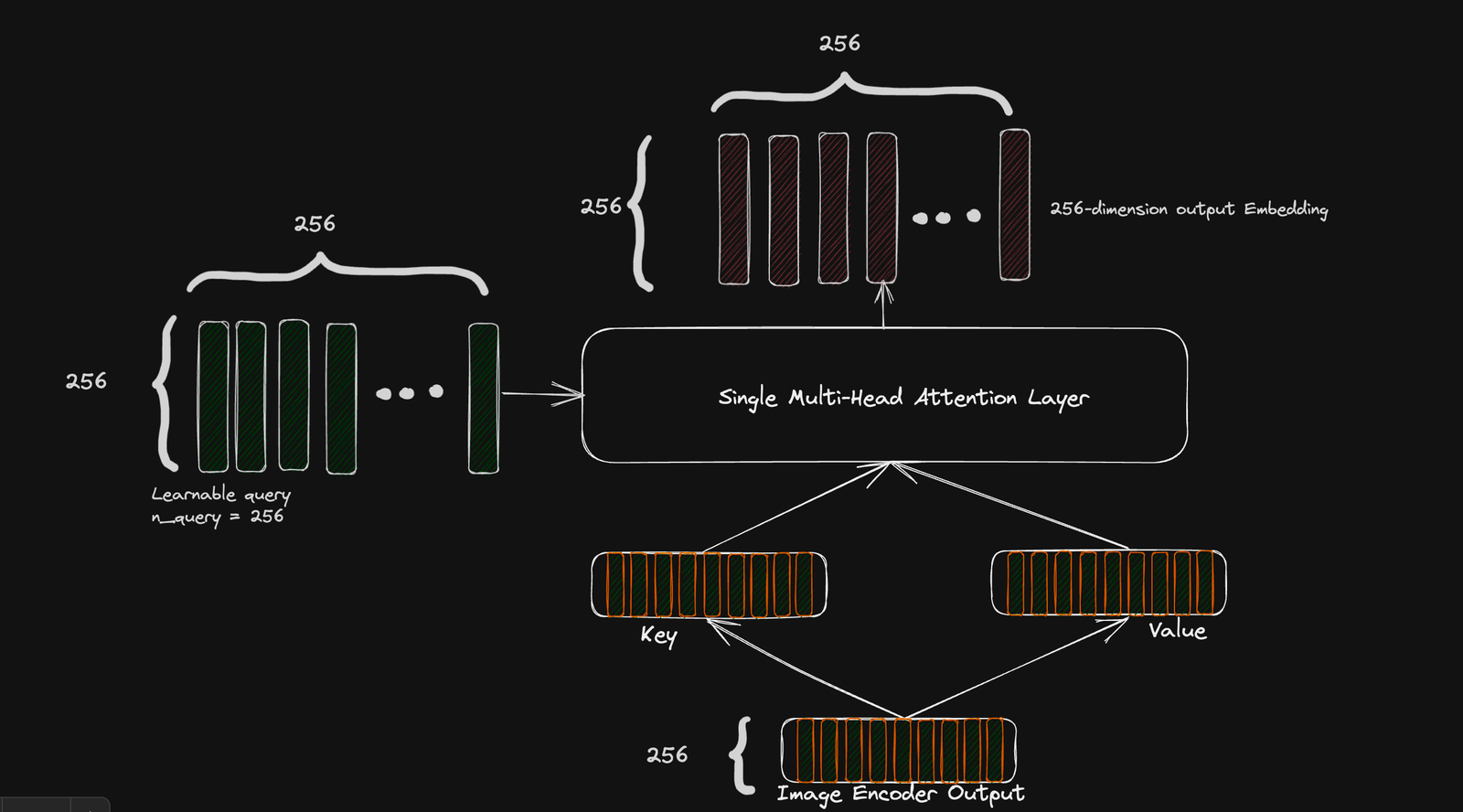
生成目标
与仅需要图像的全局表示的对比目标不同,当我们生成图像的更细粒度的表示时,生成目标会更有效。
正如前面已经解释的,我们通过将查询参数设置为一个任意数字(在CoCa论文中为256),从而生成一个256 x 256的丰富图像表示,以获取精细的图像表示。
该表示被传递到解耦解码器设置的上部,并通过与单模态文本表示的跨模态交互(忽略 CLS 表示),我们获得了统一的图像文本表示,该表示通过自回归分解用于预测词汇的概率分布。
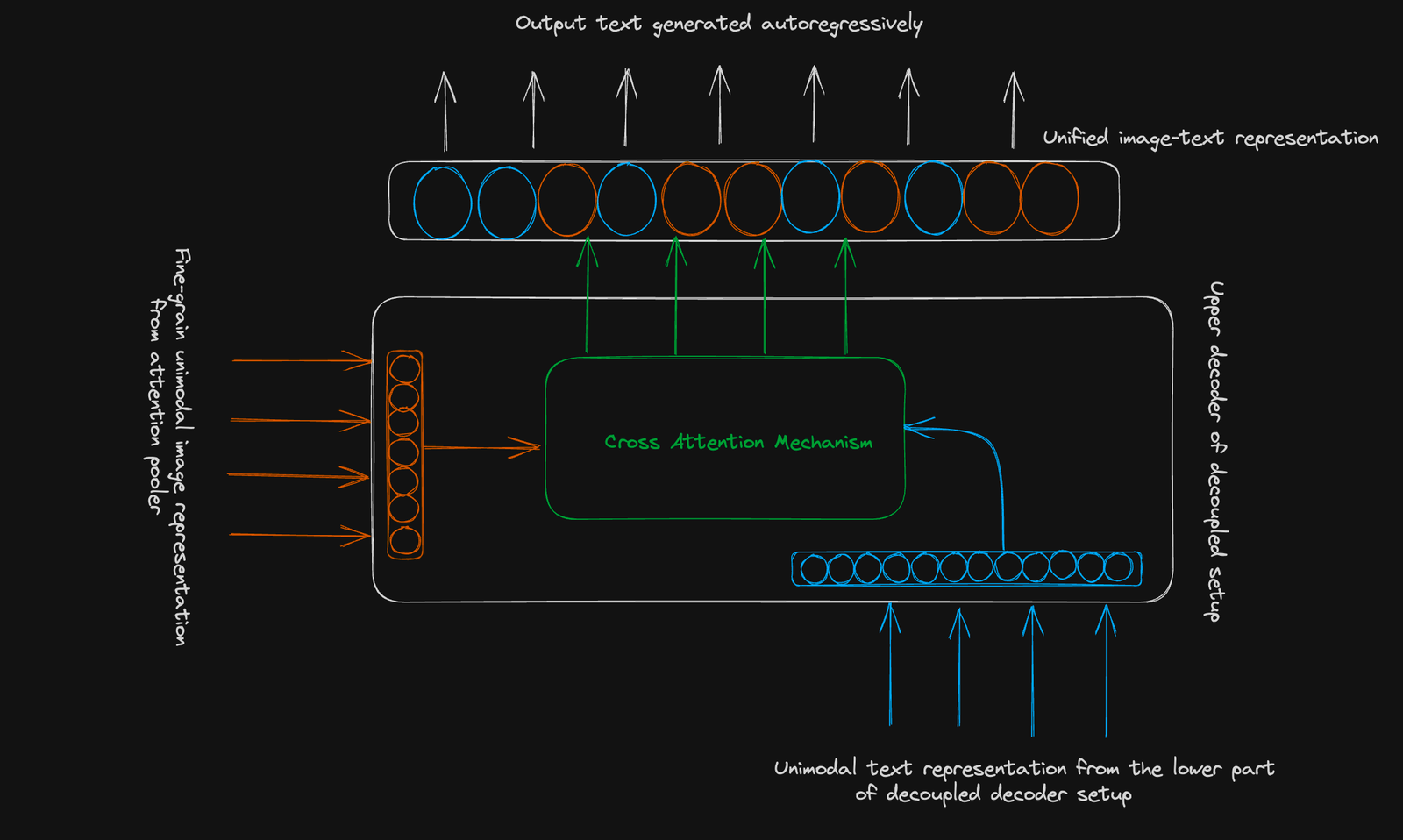
正如本文的前两节所示,CoCa模型的架构设置允许吸收一类在零-shot学习任务(如图像分类和跨模态检索)方面表现出色的模型的能力,以及在VQA和图像字幕方面表现出色的另一类模型的能力。CoCa模型还可以在几个下游视觉和语言任务上进行微调。
最后的思考
像CoCa这样的基础模型的出现标志着机器学习领域的重大进展。CoCa将各种范式的优势融合在一起,提供了一个能够对齐图像和文本表示并生成联合图像-文本表示的统一模型。
该模型证明了整合对比目标和生成目标的潜力,为增强视觉问答和图像字幕等任务的性能铺平了道路。它包含了擅长零样本学习任务的模型和精通多模态图像文本理解任务的模型的能力,为众多下游视觉和语言任务提供了多功能工具。