PagedAttention
我们发现大语言模型(LLM)推理服务的性能瓶颈在于内存。在自回归解码过程中,所有输入的 token 都会生成注意力机制中的 key 和 value 张量,这些张量被缓存在 GPU 内存中以生成后续 token。这些缓存的 key 和 value 张量通常被称为 KV 缓存(KV cache)。
KV 缓存的挑战
KV 缓存具备如下特点:
- 体积庞大:以 LLaMA-13B 为例,单个序列的 KV 缓存可占用高达 1.7GB 的 GPU 内存。
- 动态变化:其大小取决于序列长度,而序列长度具有高度的可变性和不可预测性。
因此,如何高效地管理 KV 缓存是一项巨大挑战。我们发现,现有系统中由于内存碎片和过度预留导致了 60%–80% 的内存浪费。
PagedAttention 的引入
在论文《Efficient Memory Management for Large Language Model Serving with PagedAttention》中,作者提出了 PagedAttention,一种受虚拟内存分页启发的新型算法。
内存分页技术最早用于操作系统(如 Windows 和 Unix)中,用于管理和分配系统内存中的页帧(Page Frame)。当系统内存不足时,它可以将暂时未被使用的内存区域换出,从而提升整体内存使用效率。PagedAttention 借鉴这一思想,对 LLM 推理中的 KV 缓存空间进行更高效的管理,从而实现动态内存分配,减少资源浪费。

Segmented Memory System (Source)

Paged Memory System (Source)
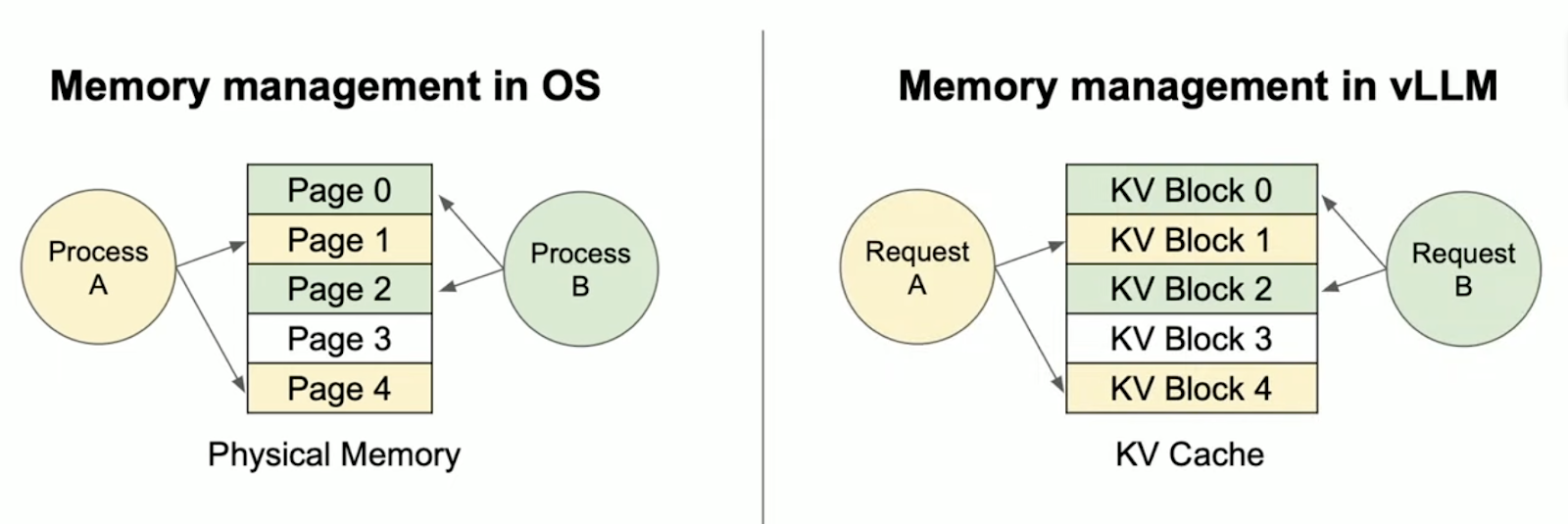
Illustration comparing Memory management within the operating system and in LLM using vLLM (Source).
为了解决上述问题,我们提出了一种新的注意力算法 —— PagedAttention。该算法受到操作系统中 虚拟内存与分页机制 的启发。
PagedAttention 如何优化 KV 缓存使用效率
PagedAttention 通过动态分配内存块,充分利用先前未被使用的空间,从根本上减少了内存浪费。为了解决这一问题,我们先来了解传统系统如何浪费内存。
以 LLaMA-13B 模型为例,其参数占用约 26GB,在一块 40GB 显存的 NVIDIA A100 GPU 上就占去了 65% 的内存,剩余 30% 用于存放 KV 缓存。但传统系统将 KV 缓存保存在连续的内存空间中,即为每个请求预分配一块固定的、完整的内存区域。由于输入输出长度差异极大,这会导致大量空间无法被充分利用。
vLLM 团队将浪费归纳为三类:
- 内部碎片(Internal Fragmentation):由于系统无法预知最终会生成多少 token,因此会为序列预分配一块较大的内存区域,但最终未被完全使用。
- 保留浪费(Reservation):为了保证请求不中断,系统为整个序列持续预留内存块,即便部分内存未被使用,也不能被其他请求共享。
- 外部碎片(External Fragmentation):内存块固定大小与请求长度不匹配时,会在块之间产生无法复用的“空隙”。

图示:传统系统中三种 KV 缓存内存浪费形式(来源)
与传统的注意力机制不同,PagedAttention 允许将连续的 key 和 value 张量存储在非连续的内存空间中。具体而言,PagedAttention 将每个序列的 KV 缓存划分为若干 块(block),每个块包含固定数量 token 的 key 和 value。在计算注意力时,PagedAttention 内核能够高效地识别并获取这些块。
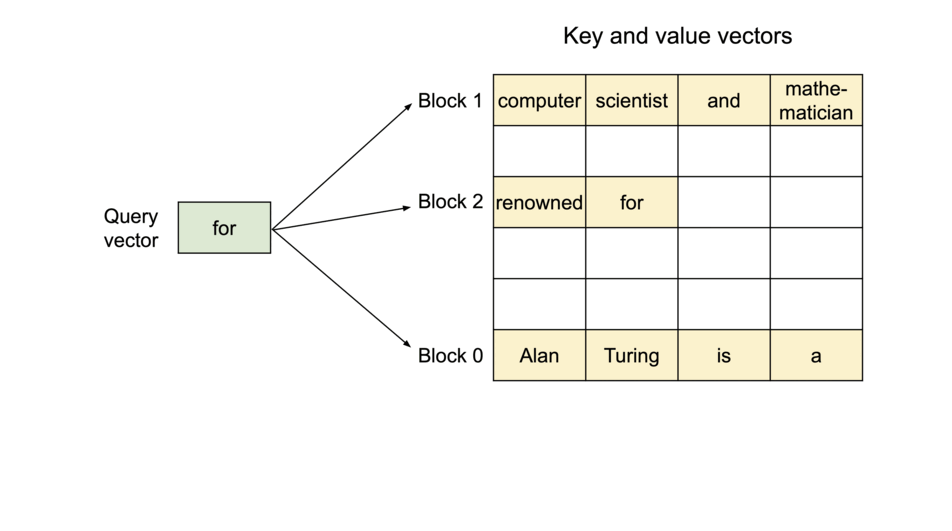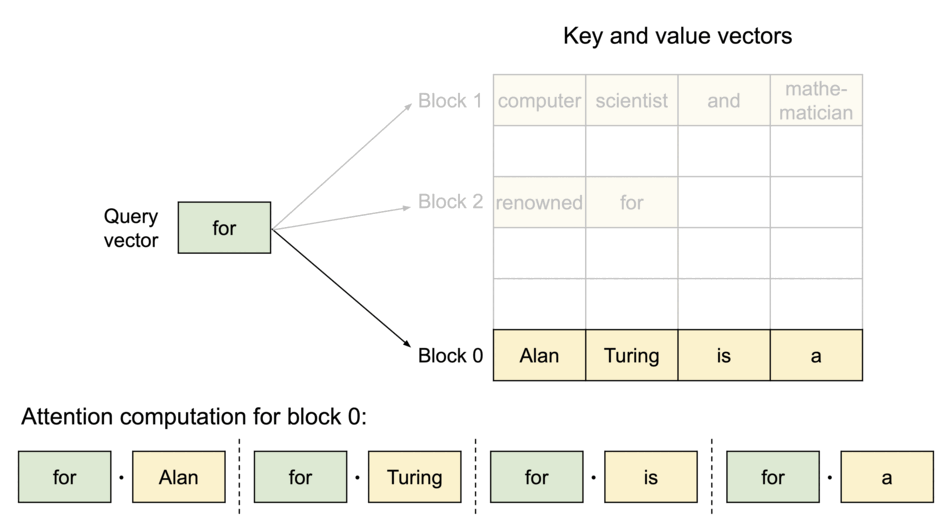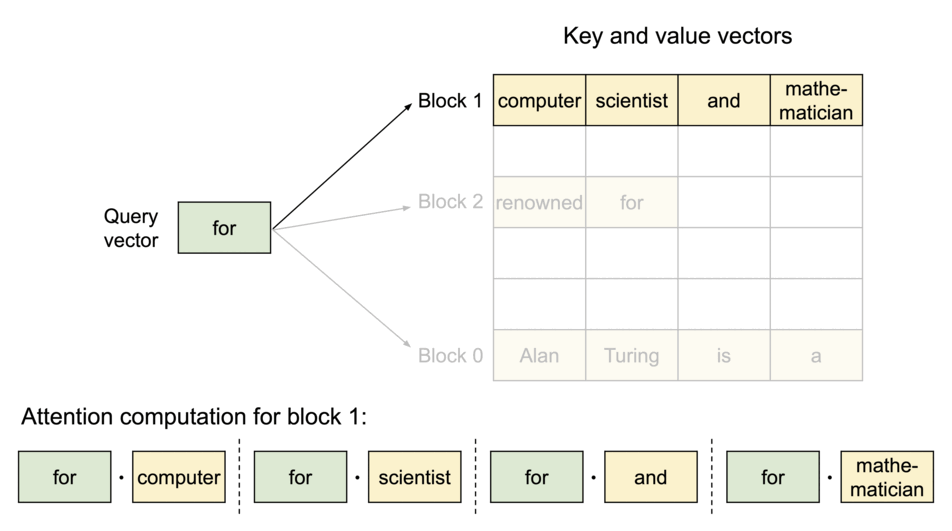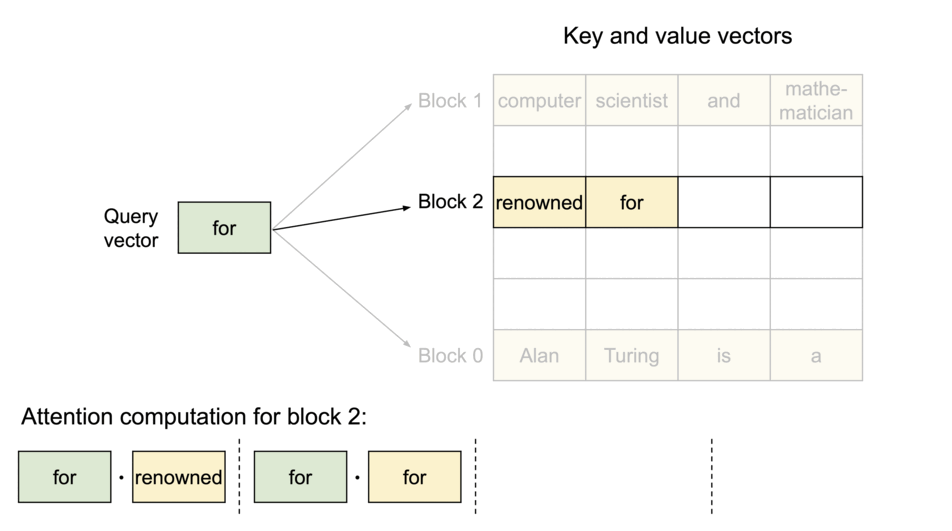
PagedAttention:KV 缓存被划分为多个块,块在内存中不要求连续存储。
由于块不要求在物理内存中连续,我们可以更灵活地管理 KV 数据,这与操作系统的虚拟内存类似。可以将:
- 块类比为 页面(page),
- token 类比为 字节(byte),
- 序列类比为 进程(process)。
序列的连续逻辑块通过一个 块映射表(block table) 映射到物理内存中的非连续块。这些物理块会随着新 token 的生成而按需分配。
PagedAttention 的核心在于引入分页机制,动态分配内存块,不再要求内存连续。每个逻辑 KV 缓存与物理内存块之间的映射关系保存在一个称为“块表(Block Table)”的数据结构中。
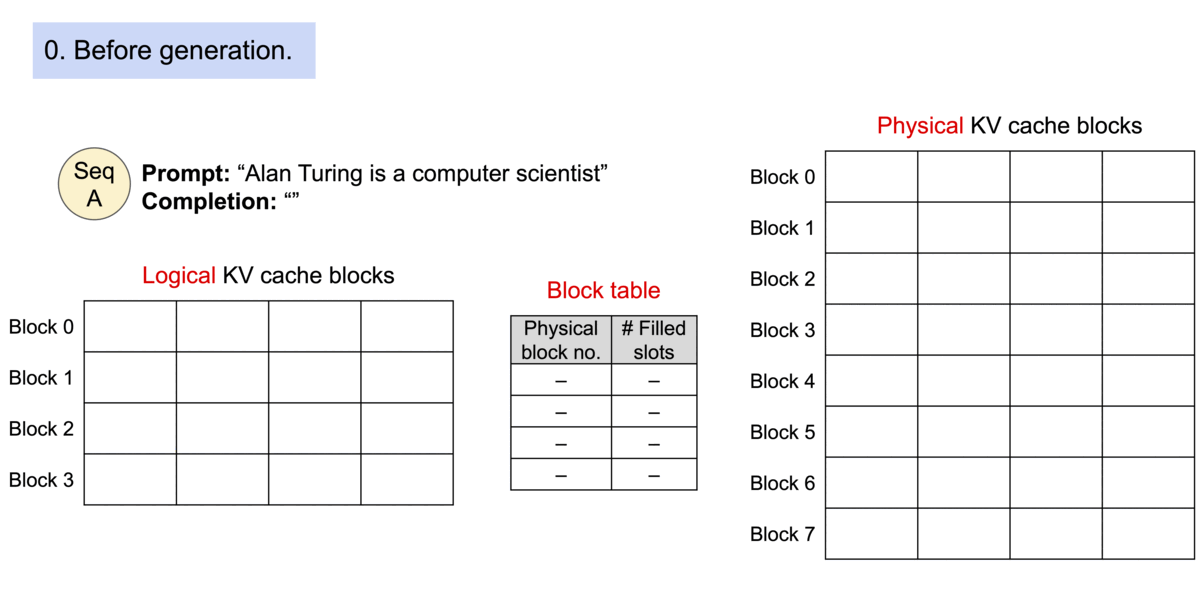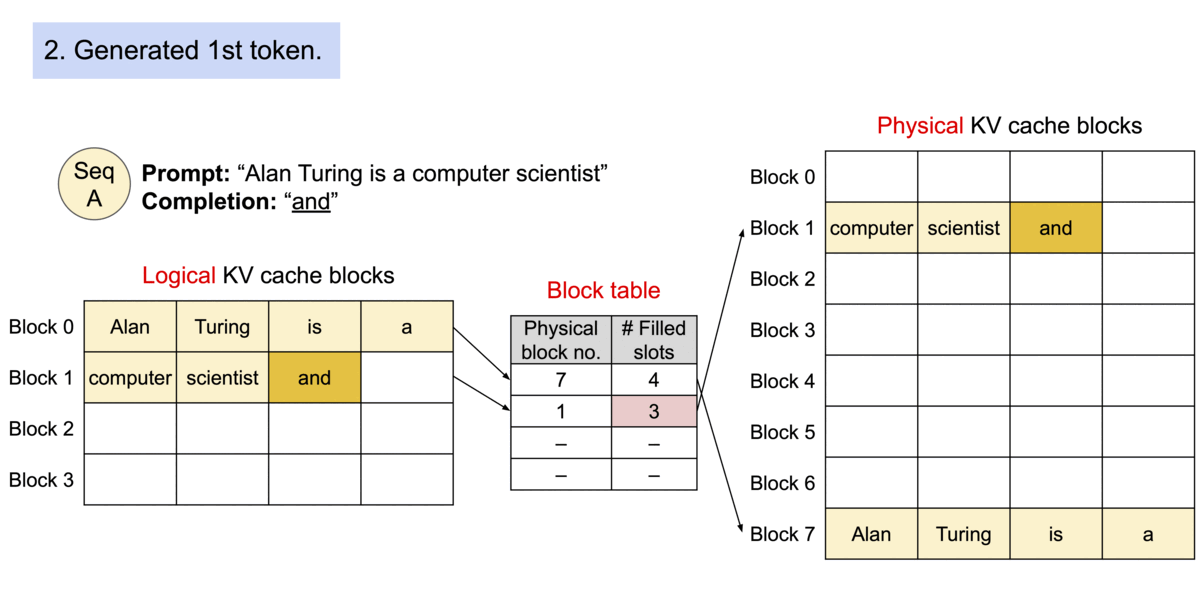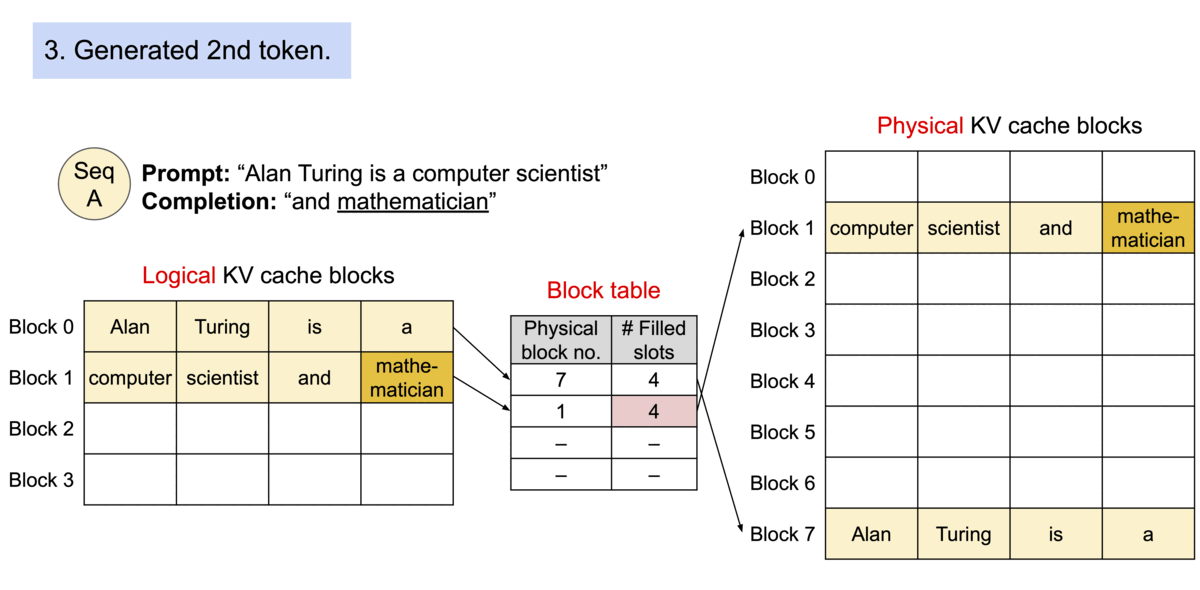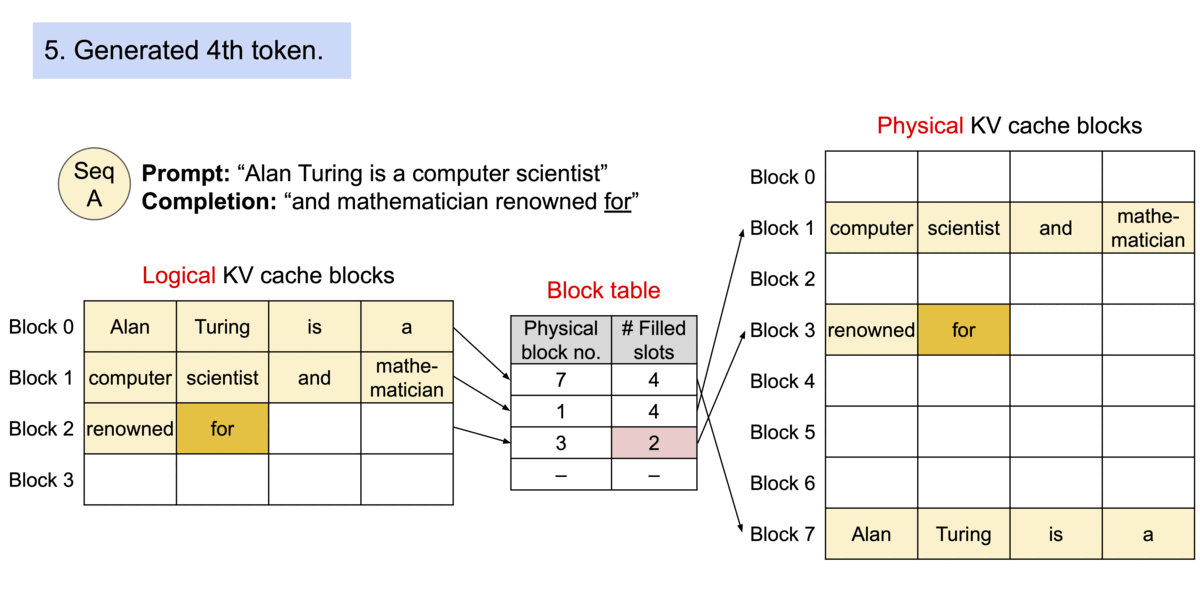
图示:PagedAttention 分页管理 KV 缓存的示意图(来源)
PagedAttention 不仅消除了外部碎片,还最大程度减少了内部碎片,实现了近乎完美的内存使用效率。在 PagedAttention 中,内存浪费只发生在序列的最后一个块。据论文所述,传统实现中仅 20%–40% 的 KV 缓存被有效使用,而 vLLM 的 PagedAttention 将这一效率提升至接近 96%。
这种提升带来了显著的性能收益:
- 可以批处理更多序列,
- 提高 GPU 利用率,
- 从而显著提升吞吐量(如上图性能结果所示)。
PagedAttention 的另一个优势:高效的内存共享
PagedAttention 通过其 块映射表(block table) 天然实现了内存共享。类似于操作系统中多个进程共享物理页面,PagedAttention 中的不同序列也可以通过将其逻辑块映射到同一个物理块,实现 块级别的共享。
为了确保共享的安全性,PagedAttention 会:
- 追踪每个物理块的 引用计数(reference count);
- 实施 写时复制(Copy-on-Write)机制,在需要修改共享内容时自动创建副本,避免数据冲突。
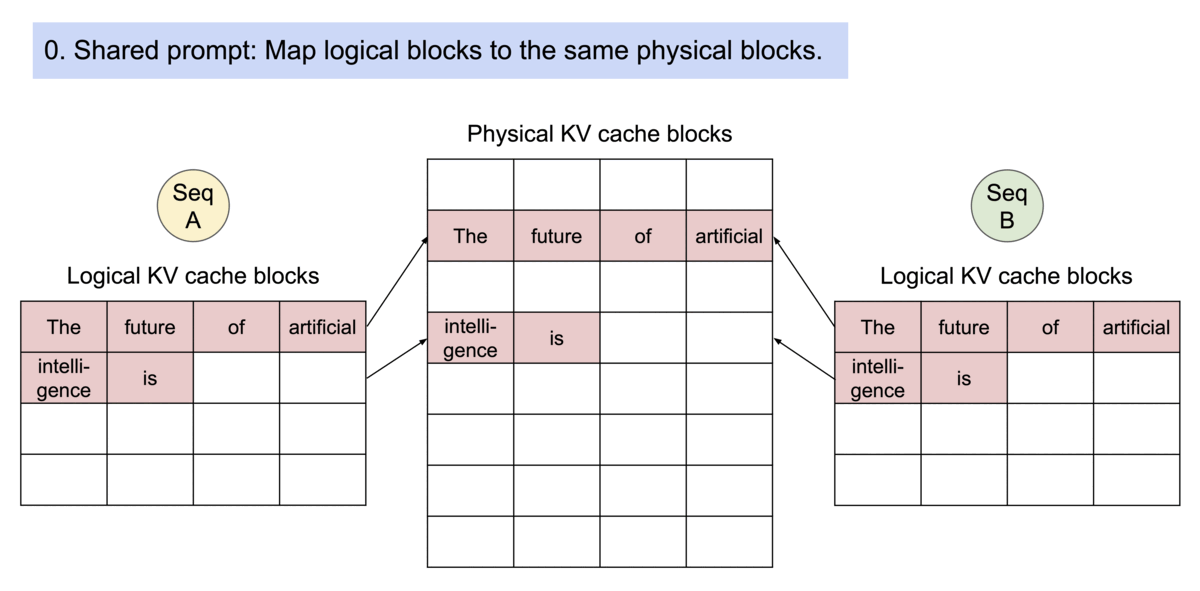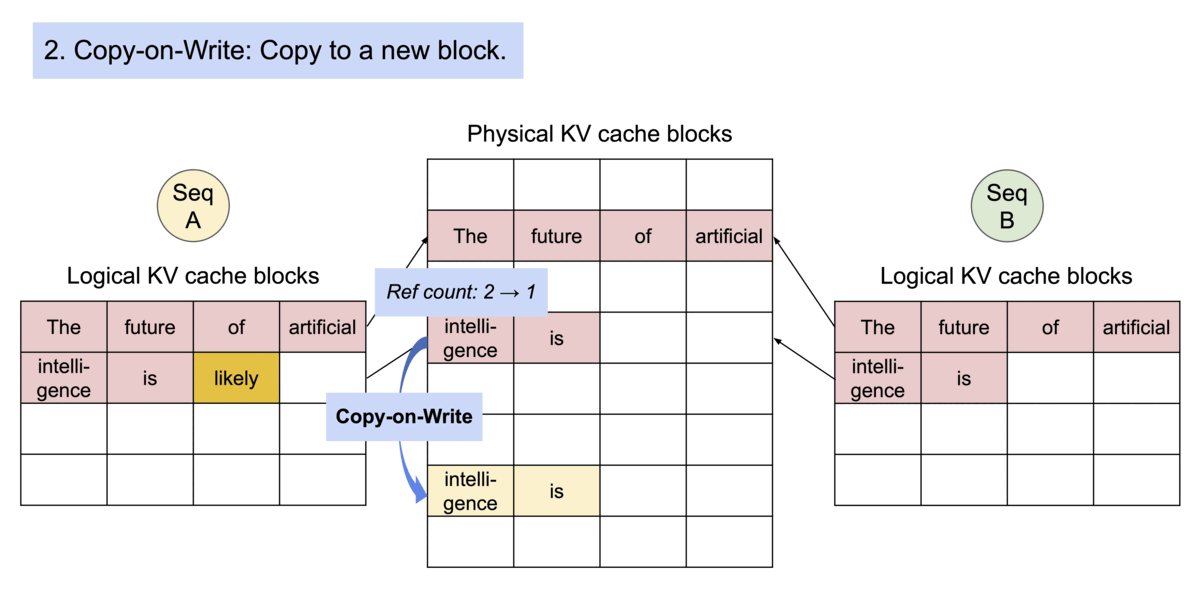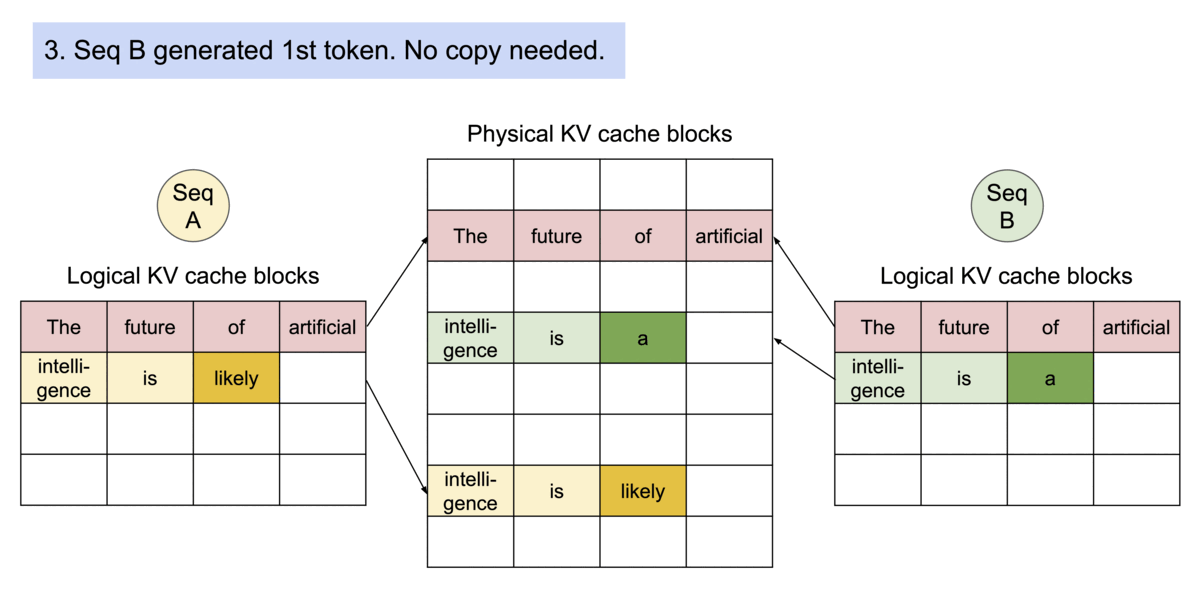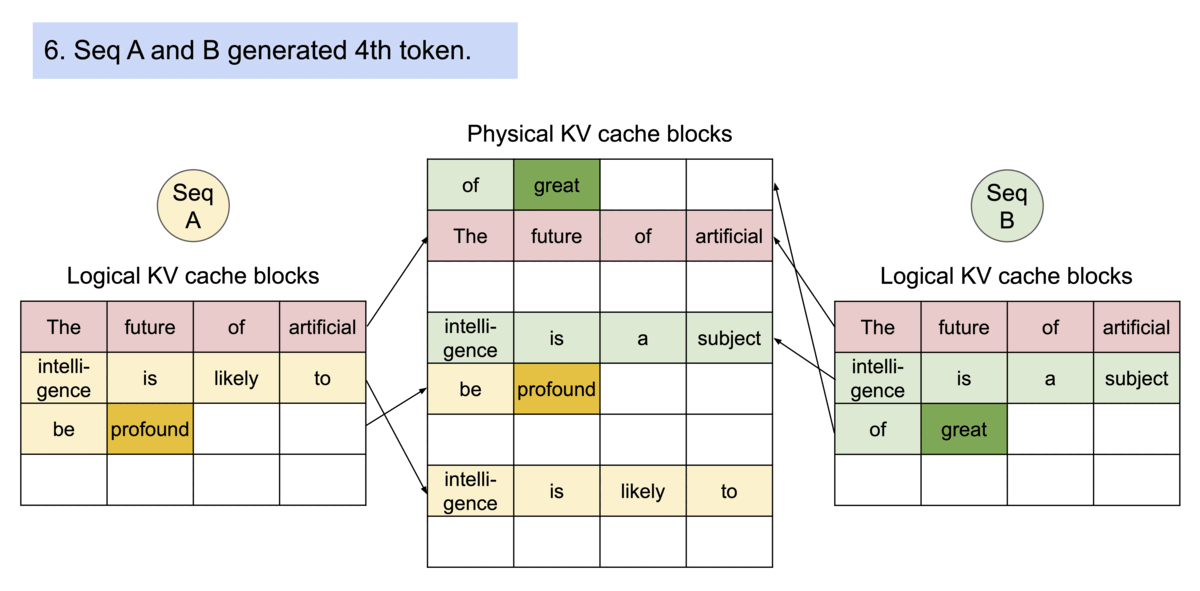
示例:并行采样下的生成过程
PagedAttention 的内存共享机制极大地减少了复杂采样算法的内存开销,比如并行采样和 beam search。根据测试结果,这些方法的内存使用最多可减少 55%,从而带来高达 2.2 倍 的吞吐量提升,使得这些采样方法在 LLM 服务中变得更加实用和高效。
PagedAttention 支持多个请求之间共享 KV 缓存内存,这是其动态映射设计的又一优势。以下几种推理解码策略都可以受益于此:
1. 并行采样(parallel sampling)
在 并行采样(parallel sampling) 中,从同一输入生成多个输出样本,例如生成多个候选答案供用户选择,在这种情况下,vLLM 可共享输入提示阶段的计算与内存。
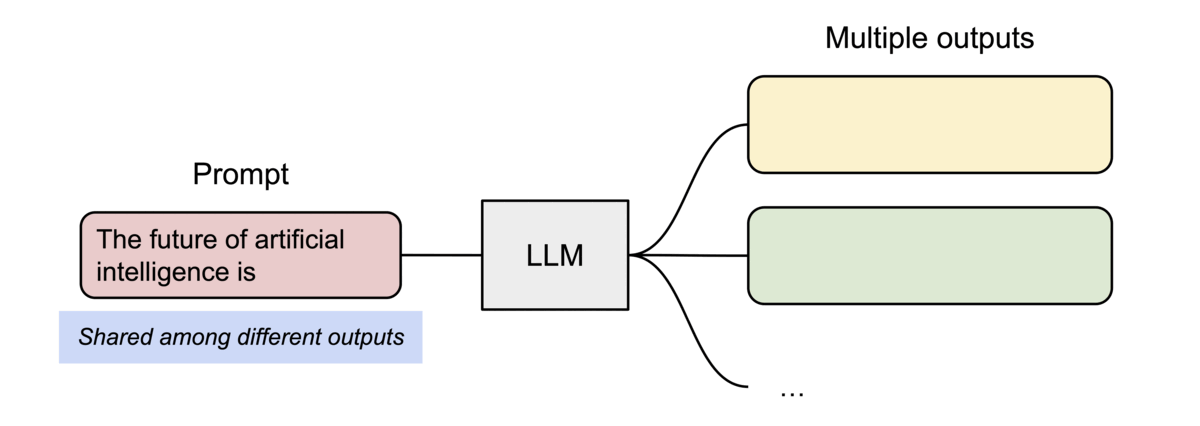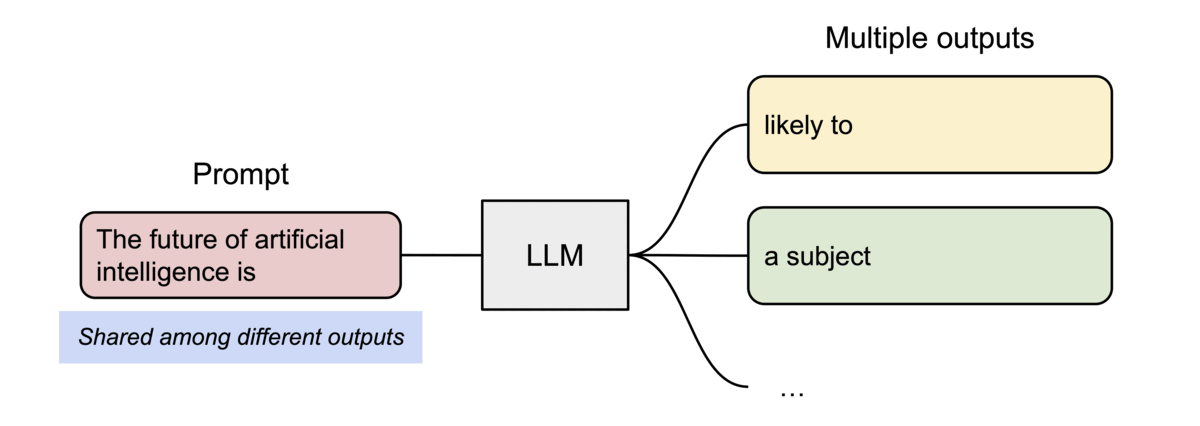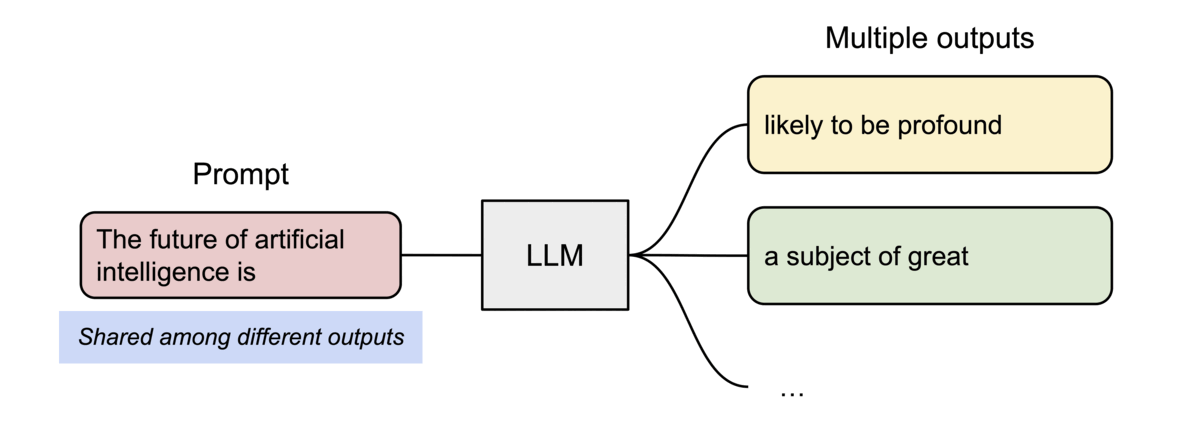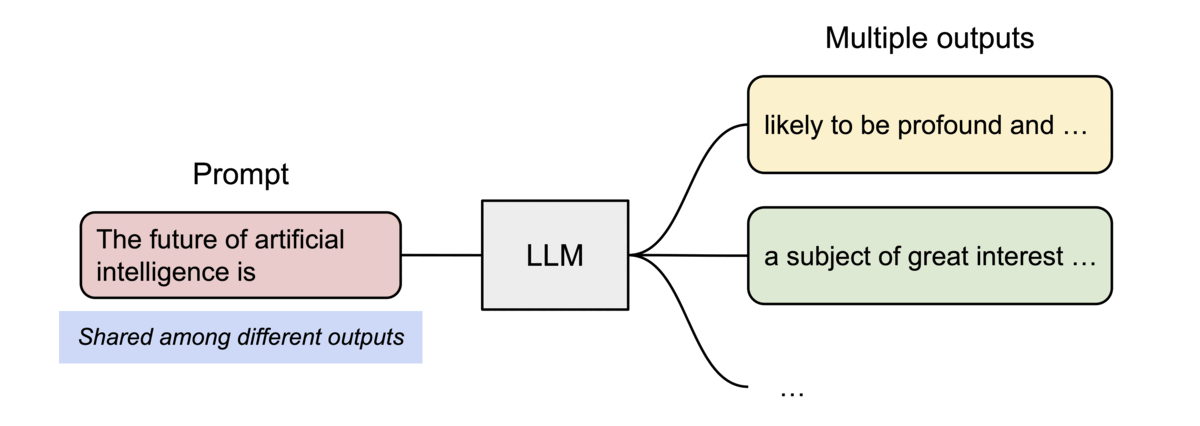
图示:vLLM 在并行采样中共享 KV 缓存(来源)
2. 束搜索(Beam Search)
用于机器翻译等任务,每步保留最可能的几个候选路径,逐步扩展。vLLM 能够在不同 beam 分支间高效复用共享的前缀缓存。
3. 共享前缀(Shared Prefix)
多个请求使用相同系统提示词(system prompt)时,vLLM 会将其预存缓存共享,从而减少重复计算,提高效率。
4. 混合解码策略(Mixed Decoding)
如贪婪解码、Top-K 采样与 Beam Search 等混合并发使用,vLLM 可灵活管理不同策略下的缓存共享,无需强制统一解码方式,从而提升系统吞吐量与灵活性。
总结
PagedAttention 是 vLLM 的核心技术 —— 一个高性能、易用的大语言模型推理与服务引擎。它支持多种模型,显著提升内存利用率和推理吞吐量。