静态,动态和连续批处理
GPU 专为高度并行计算工作负载而设计,每秒可执行数万亿甚至数千万亿次浮点运算(FLOPs)。然而,LLMs 通常无法充分利用这些 GPU,因为芯片的大部分内存带宽都消耗在加载模型参数上。
批处理有助于缓解这一瓶颈。在生产环境中,您的服务可能会同时收到大量请求。通过将多个请求批量处理而非单独处理每个请求,可以跨多个请求复用已加载的模型参数,从而显著提升吞吐量。
静态批处理
最简单的批处理形式是静态批处理 。这种方式下,服务器会等待固定数量的请求到达后,将它们作为一个批次统一处理。

以下是LLM推理中静态批处理的示意图:
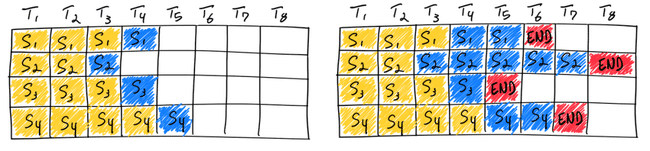
如上图所示,在第一遍迭代(左)中,每个序列从提示词(黄)中生成一个标记(蓝色)。经过几轮迭代(右)后,完成的序列具有不同的尺寸,因为每个序列在不同的迭代结束时产生不同的结束序列标记(红色)。尽管序列3在两次迭代后完成,但静态批处理意味着 GPU 将在批处理中的最后一个序列完成。
与传统深度学习模型不同,LLM 的批处理方法比较复杂,因为其推理是迭代性的。直观上,这是因为请求可能提前完成,但是释放其资源并添加可能处于不同完成状态的新请求是棘手的。这意味着,随着 GPU 在批次中不同序列的生成长度与最大生成长度不同而未充分利用。在上面的右图,这通过序列1、3和4的序列末标记后的白色方块来说明。
虽然静态批处理易于实现,但存在明显缺陷。
- 批次中的首个请求被迫等待最后一个请求到达,造成不必要延迟。这就像打印机必须累积指定数量的文档后才开始工作,无论最后一份文档需要多久才能送达。
- 批次中的请求并非完全均质。在 LLM 推理过程中,有些请求可能生成极短的响应,而其他请求则涉及冗长的逐步推理。由于批次内所有请求必须等待最慢的请求完成,这会导致计算资源浪费和延迟增加。
动态批处理
为解决静态批处理的问题,多数系统采用动态批处理 。这种方法仍会将到达的请求收集成批,但不强制要求固定批次规模。取而代之的是设置时间窗口,处理该时间段内到达的所有请求。若批次提前达到规模上限,则立即启动处理。这类似于按固定时刻表发车的公交车,或在满员时立即出发的机制。
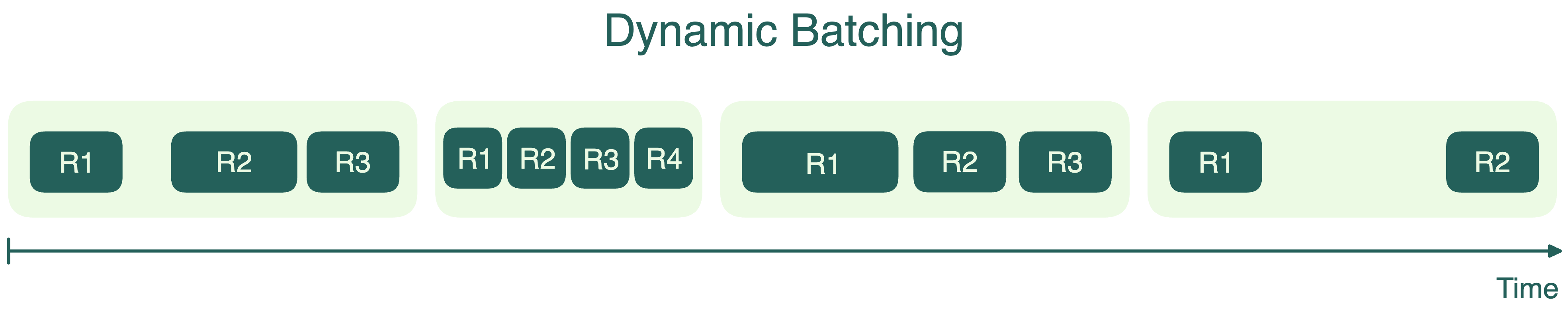
动态批处理有助于平衡吞吐量与延迟。它确保先到达的请求不会被后续请求无限期延迟。但由于某些批次在启动时可能未完全满载,这种方法并不总能实现 GPU 效率最大化。另一个缺点是,与静态批处理类似,批次中最长的请求仍决定整个批次的完成时间,导致短请求产生不必要等待。
连续批处理
在 LLM 推理中,输出序列长度差异显著。有些用户可能提出简单问题,而其他用户则需要详细解释。静态和动态批处理会强制短请求等待最长请求,导致 GPU 资源利用率不足。
连续批处理(亦称在途批处理)正是为了解决这些效率问题。连续批处理不要求整个批次完成后再返回结果,而是允许批次中的每个序列独立完成,并立即用新请求替换已完成序列。这就像流水线作业:每当一个产品完成(无论耗时长短),立即补充新产品以保持生产线全负荷运转。
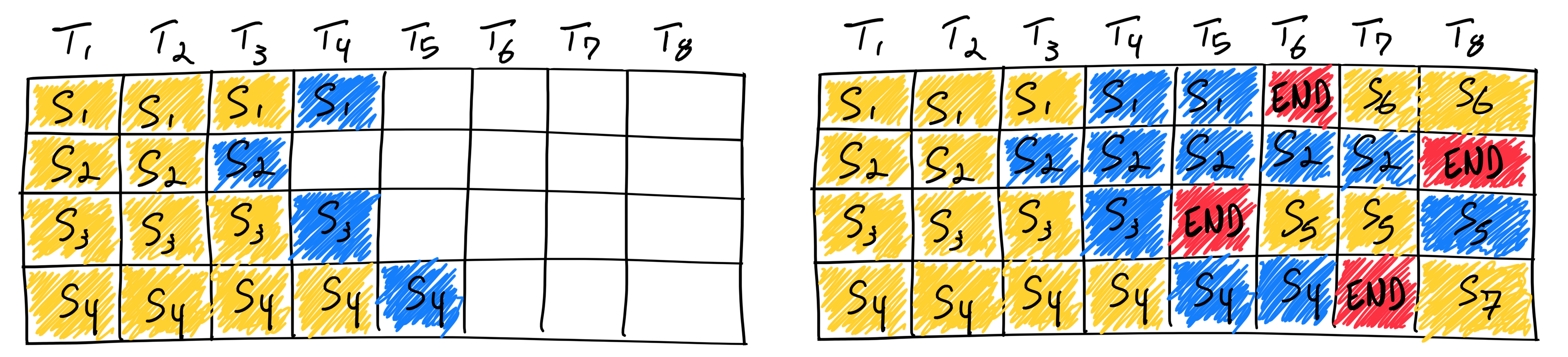
采用连续批处理生成七个序列的示意图, 图片来源. 在首次迭代时(左图),每个序列根据其提示词生成首个令牌。左图显示了单个迭代后的Batch,随时间推移(右图),右图显示了多次迭代后的Batch。一旦某个序列产生结束序列标记,我们在其位置插入新的序列(即序列S5、S6和S7)。这实现了更高的 GPU 利用率,因为 GPU 不需要等待所有序列完成才开始新的一个。
该技术采用迭代级调度策略,意味着批次组成会在每个解码迭代周期动态变化。当批次中某个序列完成令牌生成后,服务器会立即在其位置插入新请求。这种方式通过避免因等待批次中最慢序列而产生的空闲时间,最大化 GPU 占用率并保持计算资源持续忙碌。
主流 推理框架 如 vLLM、SGLang、TensorRT-LLM、LMDeploy(持久批处理)和 Hugging Face TGI 均支持连续批处理或类似机制。