LLM Generate Parameter
温度 (temperature)、top_p 与 top_k 如何控制大语言模型输出.
背景
基于Transformer架构的LLM通过注意力机制基于输入Token,预测下一个Token。该生成过程会循环执行,直到满足停止条件。
模型首先根据输入序列的上下文计算所有可能 Token的logits(原始预测值),随后通过softmax函数将这些 logits 转换为总和为1的概率分布。根据概率分布,模型通过随机或确定性策略采样下一个Token。
temperature
定义:控制输出随机性的参数,范围通常为0到1或更高。
工作原理:
- 低温度(接近0):模型更倾向于选择概率最高的token,输出更确定性和保守
- 高温度(>1):平滑概率分布,增加随机性,输出更多样化但可能不连贯
1. 标准 Softmax 公式
$$ P(y_i) = \frac{e^{z_i} }{\sum_{j=1}^{K} e^{z_j} } $$ 其中:
- $ z_i $ 是第 $ i $ 个 token 的 logit 值
- $ K $ 是词汇表大小
- $ P(y_i) $ 是第 $ i $ 个 token 的预测概率
2. 带温度的 Softmax 公式
$$ P(y_i | \tau) = \frac{e^{z_i / \tau} }{\sum_{j=1}^{K} e^{z_j / \tau} } $$ 其中温度参数 $ \tau $ (tau) 的作用:
- $ \tau \to 0 $:趋向贪婪采样(仅选择最大 logit)
- $ \tau = 1 $:标准 Softmax
- $ \tau \to \infty $:趋向均匀分布
3. 温度对概率分布的调节效果
$$ \text{当 } \tau < 1 \text{ 时:} \quad \frac{z_i}{\tau} > z_i \Rightarrow \text{放大高概率token的优势} $$ $$ \text{当 } \tau > 1 \text{ 时:} \quad \frac{z_i}{\tau} < z_i \Rightarrow \text{压缩概率差异} $$
4. 温度与熵的关系
模型输出的熵随温度变化: $$ H(P) = -\sum_{i=1}^{K} P(y_i | \tau) \log P(y_i | \tau) $$
- 低温 → 低熵(确定性输出)
- 高温 → 高熵(多样性输出)
5. 代码实现
def softmax_with_temperature(logits, temperature=1.0):
scaled_logits = logits / temperature
exp_logits = np.exp(scaled_logits - np.max(scaled_logits)) # 数值稳定处理
return exp_logits / np.sum(exp_logits)6. Temperature 设置
| 温度(t) | 输出分布特点 | 示例场景 |
|---|---|---|
| 0.1 | 尖锐峰值,低多样性 | 事实问答、代码补全 |
| 0.5 | 适度平滑,平衡确定性与多样性 | 通用对话 |
| 1.0 | 原始模型分布 | 默认配置 |
| 2.0 | 平坦分布,高多样性 | 创意写作、故事生成 |
DeepSeek 推进的Temperature 设置
temperature 参数默认为 1.0。
- 我们建议您根据如下表格,按使用场景设置
temperature。
| 场景 | 温度 |
|---|---|
| 代码生成/数学解题 | 0.0 |
| 数据抽取/分析 | 1.0 |
| 通用对话 | 1.3 |
| 翻译 | 1.3 |
| 创意类写作/诗歌创作 | 1.5 |
7. 温度缩放对梯度的影响:
$$ \frac{\partial P(y_i \mid \tau)}{\partial z_i} = \frac{P(y_i \mid \tau) \cdot (1 - P(y_i \mid \tau))}{\tau} $$
- 温度越高,梯度越小,模型更新更温和。
8. 可视化效果
温度变化对概率分布的影响:
- 低 $ \tau $:概率分布呈现尖峰
- 高 $ \tau $:概率分布趋于平坦
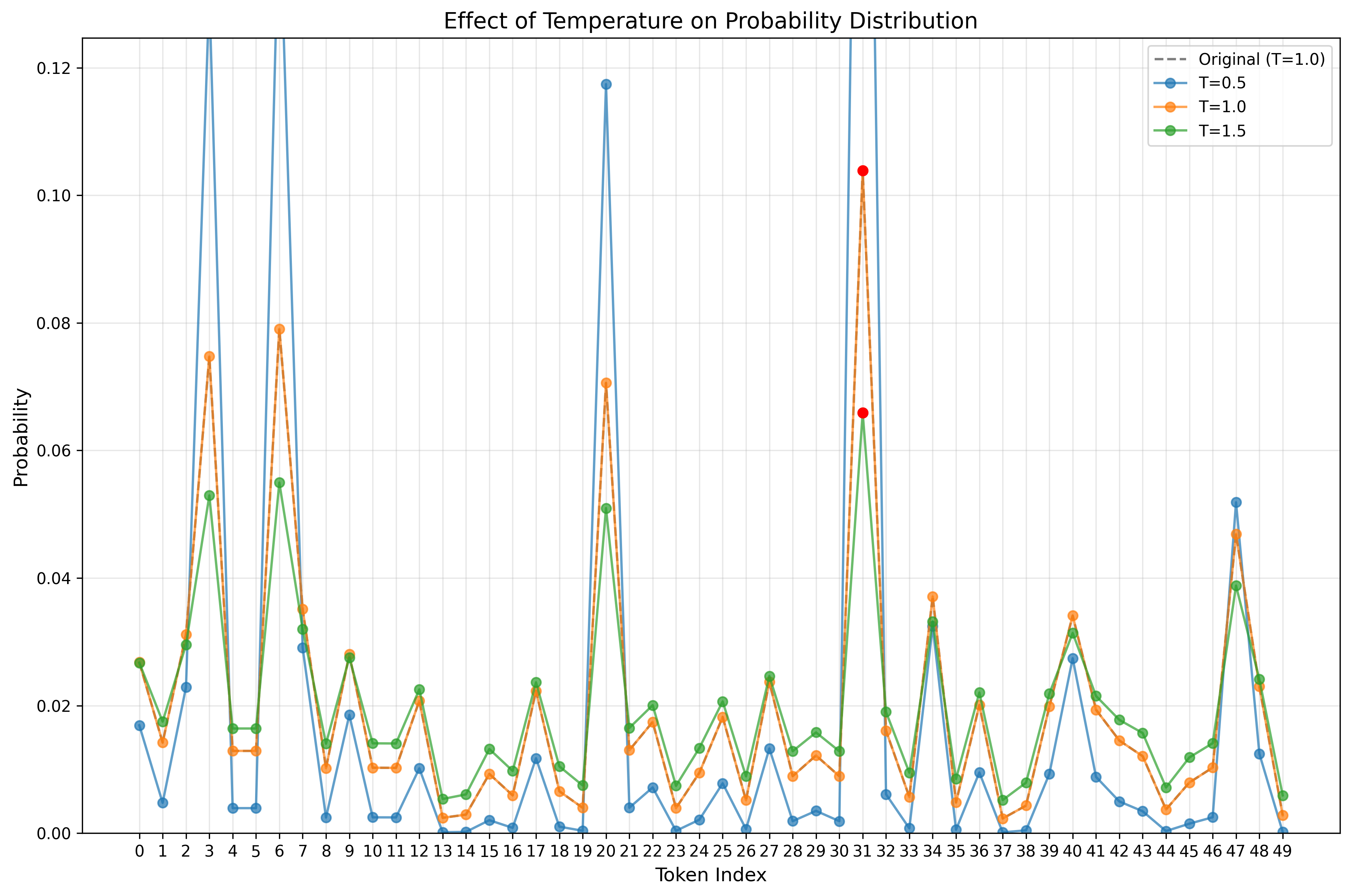
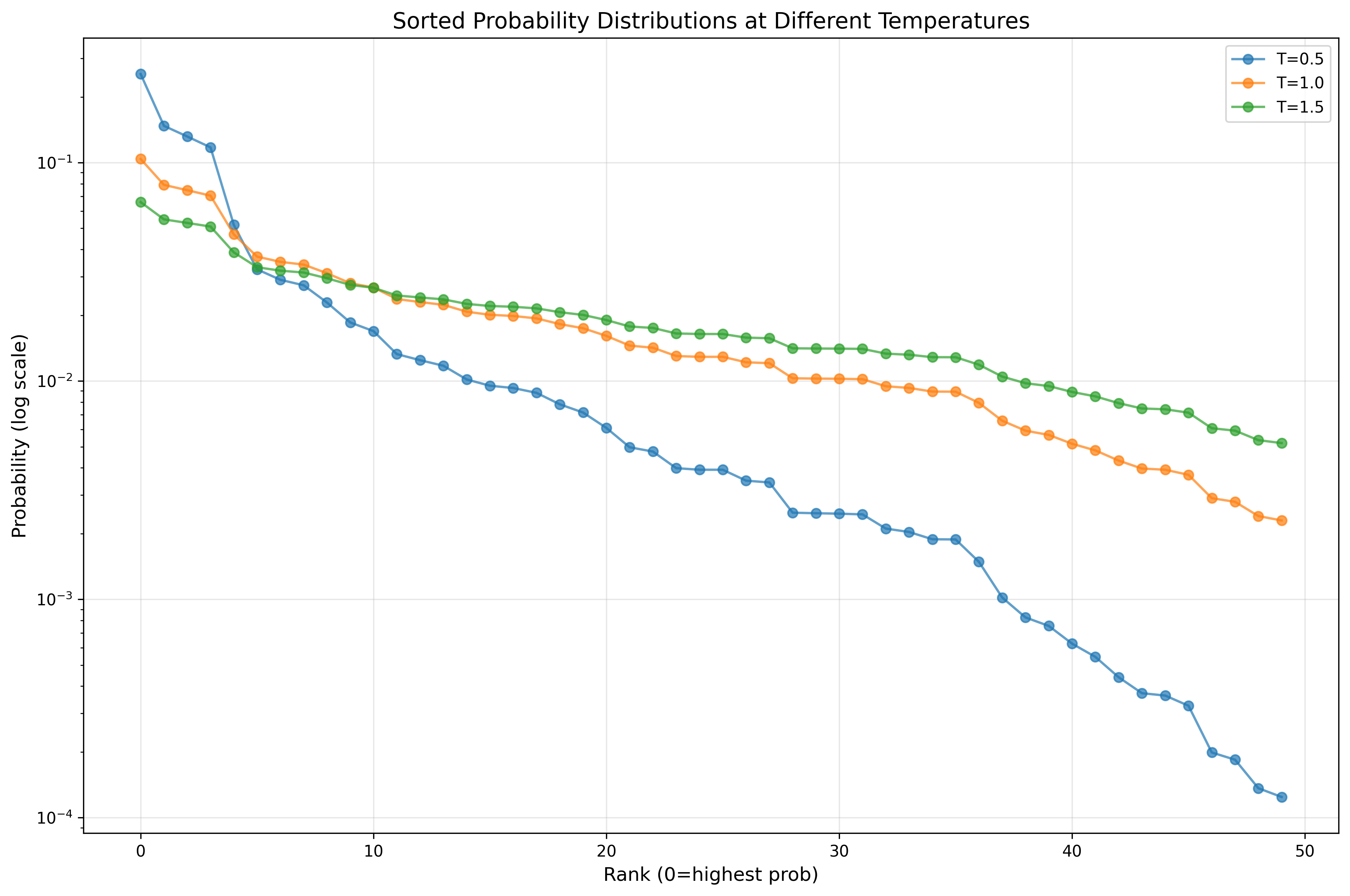
Code to plot the figuer
import numpy as np
import matplotlib.pyplot as plt
from scipy.special import softmax
# 模拟原始logits
np.random.seed(42)
logits = np.random.normal(0, 1, 50) # 50个token的logits
temperatures = [0.5, 1.0, 1.5]
# 创建第一个图形:原始分布视图
plt.figure(figsize=(12, 8))
original_probs = softmax(logits)
plt.plot(original_probs, "k--", alpha=0.5, label="Original (T=1.0)")
for temp in temperatures:
scaled_logits = logits / temp
probs = softmax(scaled_logits)
plt.plot(probs, "o-", label=f"T={temp}", alpha=0.7)
plt.title("Effect of Temperature on Probability Distribution", fontsize=14)
plt.xlabel("Token Index", fontsize=12)
plt.ylabel("Probability", fontsize=12)
plt.legend(fontsize=10)
plt.grid(True, alpha=0.3)
plt.xticks(np.arange(len(logits)))
plt.ylim(0, max(original_probs) * 1.2)
# 高亮最高概率token
max_idx = np.argmax(original_probs)
for temp in temperatures:
scaled_logits = logits / temp
probs = softmax(scaled_logits)
plt.scatter(max_idx, probs[max_idx], color="red", zorder=5)
plt.tight_layout()
plt.savefig("temperature_effect_raw.png", dpi=300, bbox_inches="tight")
plt.close() # 关闭图形以释放内存
# 创建第二个图形:排序视图
plt.figure(figsize=(12, 8))
for temp in temperatures:
scaled_logits = logits / temp
probs = softmax(scaled_logits)
sorted_probs = np.sort(probs)[::-1] # 降序排列
plt.plot(sorted_probs, "o-", label=f"T={temp}", alpha=0.7)
plt.title("Sorted Probability Distributions at Different Temperatures", fontsize=14)
plt.xlabel("Rank (0=highest prob)", fontsize=12)
plt.ylabel("Probability (log scale)", fontsize=12)
plt.legend(fontsize=10)
plt.grid(True, alpha=0.3)
plt.yscale("log")
plt.tight_layout()
plt.savefig("temperature_effect_sorted.png", dpi=300, bbox_inches="tight")
plt.close()top_k
定义:限制采样池只包含概率最高的 k 个token。
工作原理:
- 对词汇表按概率排序
- 只保留前k个token
- 在这些token中重新分配概率 (同样需要重新计算softmax概率)
影响:
- k值小:输出更可预测但缺乏多样性
- k值大:更多样化但可能包含不相关token
- 典型值:5-100
top_p
定义:动态选择累积概率超过p的最小 token集合。
工作原理:
- 按概率降序排列token
- 累加概率直到和 ≥p
- 仅从这些token中采样(需要在缩小的词汇表上重新计算 softmax)
优势:
- 自适应token集大小
- 避免低质量token同时保持多样性
示例:
- 接近1的值(如0.95):考虑大部分词汇表,输出更随机。因为即使低概率Token也会被纳入采样池
- 接近0的值(如0.1):仅考虑最高概率的极少数Token,输出更确定
min_p (最小概率阈值)
定义:排除概率低于指定阈值的 token。
工作原理:
- 只考虑概率 > min_p × 最高概率 token 的token
- 是top_p的补充方法
使用场景:
- 需要排除极低概率但不想固定token数量时
- 与temperature结合可精细控制多样性
示例:
- min_p=0.1: 排除概率不到最高概率token10%的所有选项
参数协同工作机制
配置 Temperature=0.8, Top-K=50, Top-P=0.9 min_p=0.01 的执行流程:
- 根据温度
Temperature=0.8缩放调整原始 logits - 保留
Top-K=50个候选词 - 从中筛选累计概率 ≥90%, (同时排除概率 < min_p * 最高概率的Token),剩余约45个词
- 重新归一化(应用softmax将它们转换为适当的概率)
- 最终采样
Temperature=1.0, Top-K=-1, Top-P=1.0 min_p=None
参考
https://huggingface.co/docs/transformers/main_classes/text_generation
https://aviralrma.medium.com/understanding-llm-parameters-c2db4b07f0ee
参数详解
控制输出长度的参数
max_length (int, 可选, 默认20): 生成的token的最大长度。对应于输入提示长度+max_new_tokens。如果同时设置了max_new_tokens,则会被后者覆盖。
max_new_tokens (int, 可选): 要生成的最大token数量,忽略提示中的token数量。
min_length (int, 可选, 默认0): 生成序列的最小长度。对应于输入提示长度+min_new_tokens。如果同时设置了min_new_tokens,则会被后者覆盖。
min_new_tokens (int, 可选): 要生成的最小token数量,忽略提示中的token数量。
early_stopping (bool或str, 可选, 默认False): 控制基于束的方法(如束搜索)的停止条件。可接受以下值:
True: 一旦有num_beams个完整候选就停止生成False: 应用启发式方法,当不太可能找到更好候选时停止生成"never": 仅当不可能有更好候选时才停止束搜索过程(经典束搜索算法)
max_time (float, 可选): 允许计算运行的最大时间(秒)。分配时间过后,生成仍会完成当前轮次。
stop_strings (str或List[str], 可选): 如果模型输出这些字符串中的任何一个,将终止生成的字符串或字符串列表。
控制生成策略的参数
do_sample (bool, 可选, 默认False): 是否使用采样;否则使用贪婪解码。
num_beams (int, 可选, 默认1): 束搜索的束数量。1表示不进行束搜索。
num_beam_groups (int, 可选, 默认1): 将num_beams分成的组数,以确保不同束组之间的多样性。详见此论文。
penalty_alpha (float, 可选): 在对比搜索解码中平衡模型置信度和退化惩罚的值。
dola_layers (str或List[int], 可选): 用于DoLa解码的层。如果为None,则不使用DoLa解码。如果是字符串,必须是"low"或"high"之一,分别表示使用模型层的下半部分或上半部分。"low"表示前20层的前半部分,"high"表示后20层的后半部分。如果是整数列表,则必须包含用于DoLa候选早期层的层索引(0层是模型的词嵌入层)。设置为'low'可改进长答案推理任务,'high'可改进短答案任务。详见文档或论文。
控制缓存的参数
use_cache (bool, 可选, 默认True): 模型是否应使用过去的键/值注意力(如果适用于模型)来加速解码。
cache_implementation (str, 可选, 默认None): 将在generate中实例化的缓存类名称,用于更快解码。可能值包括:
"dynamic": [DynamicCache]"static": [StaticCache]"offloaded_static": [OffloadedStaticCache]"sliding_window": [SlidingWindowCache]"hybrid": [HybridCache]"mamba": [MambaCache]"quantized": [QuantizedCache] 如果未指定,将使用模型的默认缓存(通常是[DynamicCache])。详见缓存文档。
cache_config (CacheConfig或dict, 可选, 默认None): 可以在cache_config中传递键值缓存类使用的参数。可以作为Dict传递,内部会转换为相应的CacheConfig;或者作为与指定cache_implementation匹配的CacheConfig类传递。
return_legacy_cache (bool, 可选, 默认True): 当默认使用DynamicCache时,是否返回旧格式或新格式的缓存。
控制模型输出logits的参数
temperature (float, 可选, 默认1.0): 用于调节下一个token概率的值。此值设置在模型的generation_config.json文件中。如果未设置,默认值为1.0。
top_k (int, 可选, 默认50): 保留用于top-k过滤的最高概率词汇token数量。此值设置在模型的generation_config.json文件中。如果未设置,默认值为50。
top_p (float, 可选, 默认1.0): 如果设置为小于1的浮点数,仅保留概率加起来达到top_p或更高的最小最可能token集合用于生成。此值设置在模型的generation_config.json文件中。如果未设置,默认值为1.0。
min_p (float, 可选): 最小token概率,将由最可能token的概率进行缩放。必须是0到1之间的值。典型值在0.01-0.2范围内,与设置top_p在0.99-0.8范围内相当(使用与正常top_p值相反的值)。
typical_p (float, 可选, 默认1.0): 局部典型性衡量预测下一个目标token的条件概率与预测下一个随机token的预期条件概率的相似程度。如果设置为小于1的浮点数,仅保留概率加起来达到typical_p或更高的最小最局部典型token集合用于生成。详见此论文。
epsilon_cutoff (float, 可选, 默认0.0): 如果设置为严格介于0和1之间的浮点数,仅采样条件概率大于epsilon_cutoff的token。在论文中,建议值范围从3e-4到9e-4,取决于模型大小。详见截断采样作为语言模型去平滑。
eta_cutoff (float, 可选, 默认0.0): Eta采样是局部典型采样和epsilon采样的混合。如果设置为严格介于0和1之间的浮点数,仅考虑大于eta_cutoff或sqrt(eta_cutoff)*exp(-entropy(softmax(next_token_logits)))的token。后者直观上是预期的下一个token概率,按sqrt(eta_cutoff)缩放。在论文中,建议值范围从3e-4到2e-3,取决于模型大小。详见截断采样作为语言模型去平滑。
diversity_penalty (float, 可选, 默认0.0): 如果束在特定时间生成与其他组中任何束相同的token,则从该束的分数中减去此值。注意diversity_penalty仅在启用组束搜索时有效。
repetition_penalty (float, 可选, 默认1.0): 重复惩罚参数。1.0表示无惩罚。详见此论文。
encoder_repetition_penalty (float, 可选, 默认1.0): 编码器重复惩罚参数。对不在原始输入中的序列的指数惩罚。1.0表示无惩罚。
length_penalty (float, 可选, 默认1.0): 用于基于束的生成的序列长度指数惩罚。作为指数应用于序列长度,然后用于除以序列的分数。由于分数是序列的对数似然(即负数),length_penalty>0.0促进更长序列,而length_penalty<0.0鼓励更短序列。
no_repeat_ngram_size (int, 可选, 默认0): 如果设置为大于0的整数,该大小的所有ngram只能出现一次。
bad_words_ids (List[List[int]], 可选): 不允许生成的token id列表的列表。详见[~generation.NoBadWordsLogitsProcessor]文档和示例。
force_words_ids (List[List[int]]或List[List[List[int]]], 可选): 必须生成的token id列表。如果给定List[List[int]],则视为必须包含的简单单词列表,与bad_words_ids相反。如果给定List[List[List[int]]],则触发析取约束,其中可以允许每个单词的不同形式。
renormalize_logits (bool, 可选, 默认False): 在应用所有logits处理器(包括自定义处理器)后是否重新归一化logits。强烈建议将此标志设置为True,因为搜索算法假设分数logits已归一化,但一些logits处理器会破坏归一化。
constraints (List[Constraint], *可选): 可以添加到生成中的自定义约束,以确保输出将以最合理的方式包含Constraint`对象定义的某些token的使用。
forced_bos_token_id (int, 可选, 默认model.config.forced_bos_token_id): 在decoder_start_token_id之后强制作为第一个生成token的token id。对于像mBART这样的多语言模型很有用,其中第一个生成token需要是目标语言token。
forced_eos_token_id (int或List[int], 可选, 默认model.config.forced_eos_token_id): 当达到max_length时强制作为最后一个生成token的token id。可选地,使用列表设置多个序列结束token。
remove_invalid_values (bool, 可选, 默认model.config.remove_invalid_values): 是否移除模型可能的nan和inf输出以防止生成方法崩溃。注意使用remove_invalid_values可能会减慢生成速度。
exponential_decay_length_penalty (tuple(int, float), 可选): 此元组添加一个指数增长的长度惩罚,在生成一定数量的token后开始。元组应包含:(start_index, decay_factor),其中start_index表示惩罚开始的位置,decay_factor表示指数衰减因子。
suppress_tokens (List[int], 可选): 生成时将抑制的token列表。SupressTokens logit处理器将其对数概率设置为-inf,使其不被采样。
begin_suppress_tokens (List[int], 可选): 生成开始时将抑制的token列表。SupressBeginTokens logit处理器将其对数概率设置为-inf,使其不被采样。
forced_decoder_ids (List[List[int]], 可选): 整数对的列表,指示从生成索引到token索引的映射,这些token将在采样前被强制使用。例如,[[1, 123]]表示第二个生成token将始终是索引123的token。
sequence_bias (Dict[Tuple[int], float], 可选): 将token序列映射到其偏差项的字典。正偏差增加序列被选择的几率,负偏差则相反。详见[~generation.SequenceBiasLogitsProcessor]文档和示例。
token_healing (bool, 可选, 默认False): 通过将提示的尾部token替换为适当的扩展来修复它们。这提高了受贪婪token化偏差影响的提示的完成质量。
guidance_scale (float, 可选): 分类器自由引导(CFG)的引导比例。通过设置guidance_scale > 1启用CFG。更高的引导比例鼓励模型生成与输入提示更紧密相关的样本,通常以质量下降为代价。
low_memory (bool, 可选): 切换到顺序束搜索和顺序topk进行对比搜索以减少峰值内存。与束搜索和对比搜索一起使用。
watermarking_config (BaseWatermarkingConfig或dict, 可选): 用于通过向随机选择的"绿色"token集合添加小偏差来为模型输出添加水印的参数。详见[SynthIDTextWatermarkingConfig]和[WatermarkingConfig]文档。如果作为Dict传递,将在内部转换为WatermarkingConfig。
定义生成输出变量的参数
num_return_sequences (int, 可选, 默认1): 批次中每个元素独立计算的返回序列数量。
output_attentions (bool, 可选, 默认False): 是否返回所有注意力层的注意力张量。详见返回张量中的attentions。
output_hidden_states (bool, 可选, 默认False): 是否返回所有层的隐藏状态。详见返回张量中的hidden_states。
output_scores (bool, 可选, 默认False): 是否返回预测分数。详见返回张量中的scores。
output_logits (bool, 可选): 是否返回未处理的预测logit分数。详见返回张量中的logits。
return_dict_in_generate (bool, 可选, 默认False): 是否返回[~utils.ModelOutput],而不是仅返回生成的序列。此标志必须设置为True才能返回生成缓存(当use_cache为True时)或可选输出(见以output_开头的标志)。
生成时可使用的特殊token
pad_token_id (int, 可选): 填充token的id。
bos_token_id (int, 可选): 序列开始token的id。
eos_token_id (Union[int, List[int]], 可选): 序列结束token的id。可选地,使用列表设置多个序列结束token。
编码器-解码器模型特有的生成参数
encoder_no_repeat_ngram_size (int, 可选, 默认0): 如果设置为大于0的整数,encoder_input_ids中出现的该大小的所有ngram不能在decoder_input_ids中出现。
decoder_start_token_id (int或List[int], 可选): 如果编码器-解码器模型使用不同于bos的token开始解码,则该token的id或长度为batch_size的列表。指示列表可以为批次中的每个元素启用不同的起始id(例如,一个批次中包含不同目标语言的多语言模型)。
辅助生成特有的参数
is_assistant (bool, 可选, 默认False): 模型是否是辅助(草稿)模型。
num_assistant_tokens (int, 可选, 默认20): 定义每次迭代时由辅助模型生成并在目标模型检查前的_推测token_数量。num_assistant_tokens的较高值使生成更_推测性_:如果辅助模型性能良好,可以达到更大的加速;如果辅助模型需要大量修正,则加速较低。
num_assistant_tokens_schedule (str, 可选, 默认"constant"): 定义在推理期间更改最大辅助token的计划:
"heuristic": 当所有推测token都正确时,将num_assistant_tokens增加2,否则减少1。num_assistant_tokens值在多次使用相同辅助模型的生成调用中保持不变。"heuristic_transient": 与"heuristic"相同,但num_assistant_tokens在每次生成调用后重置为其初始值。"constant":num_assistant_tokens在生成期间保持不变。
assistant_confidence_threshold (float, 可选, 默认0.4): 辅助模型的置信度阈值。如果辅助模型对当前token预测的置信度低于此阈值,即使尚未达到_推测token_数量(由num_assistant_tokens定义),辅助模型也会停止当前token生成迭代。辅助的置信度阈值在整个推测迭代过程中进行调整,以减少不必要的草稿和目标前向传递次数,偏向于避免假阴性。assistant_confidence_threshold值在多次使用相同辅助模型的生成调用中保持不变。这是Dynamic Speculation Lookahead Accelerates Speculative Decoding of Large Language Models https://arxiv.org/abs/2405.04304中动态推测前瞻的无监督版本。
prompt_lookup_num_tokens (int, 可选): 要输出为候选token的token数量。
max_matching_ngram_size (int, 可选): 要考虑在提示中匹配的最大ngram大小。如果未提供,默认为2。
assistant_early_exit (int, 可选): 如果设置为正整数,将使用模型的早期退出作为辅助。只能与支持早期退出的模型一起使用(即LM头可以解释中间层logits的模型)。
assistant_lookbehind (int, 可选, 默认10): 如果设置为正整数,重新编码过程将额外考虑最后assistant_lookbehind个辅助token以正确对齐token。只能在推测解码中使用不同的tokenizer。详见此博客。
target_lookbehind (int, 可选, 默认10): 如果设置为正整数,重新编码过程将额外考虑最后target_lookbehind个目标token以正确对齐token。只能在推测解码中使用不同的tokenizer。详见此博客。
与性能和编译相关的参数
compile_config (CompileConfig, 可选): 如果使用静态缓存,这控制generate如何编译前向传递以获得性能提升。
disable_compile (bool, 可选): 是否禁用前向传递的自动编译。当满足特定条件(包括使用可编译缓存)时,会自动进行编译。如果您发现需要使用此标志,请提出问题。
通配符
generation_kwargs: 额外的生成kwargs将转发到模型的generate函数。不在generate签名中的kwargs将用于模型前向传递。