Transformer的KV Caching机制详解
KV Caching概述
生成式Transformer模型中的键(Key)和值(Value)状态缓存技术已存在一段时间,但您可能需要确切理解它的原理及其带来的显著推理加速效果。
键值状态用于计算缩放点积注意力(scaled dot-product attention),如下图所示:
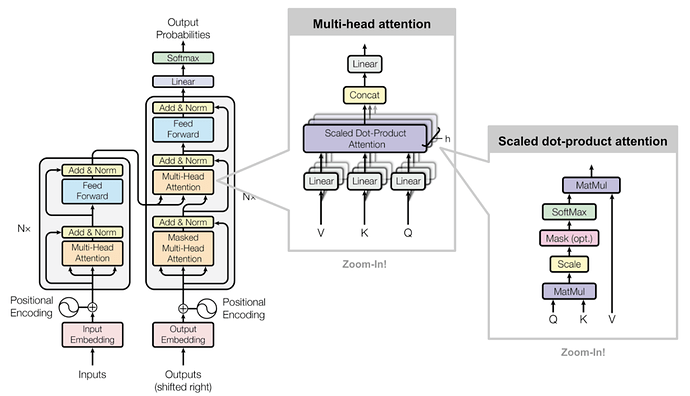
KV Caching发生在多token生成步骤中,仅存在于解码器部分 (例如GPT等纯解码器模型,或T5等编码器-解码器模型的解码器部分)。像BERT这样的非生成式模型不使用KV Caching。
自回归解码机制
解码器以自回归方式工作,如下面GPT-2文本生成示例所示:
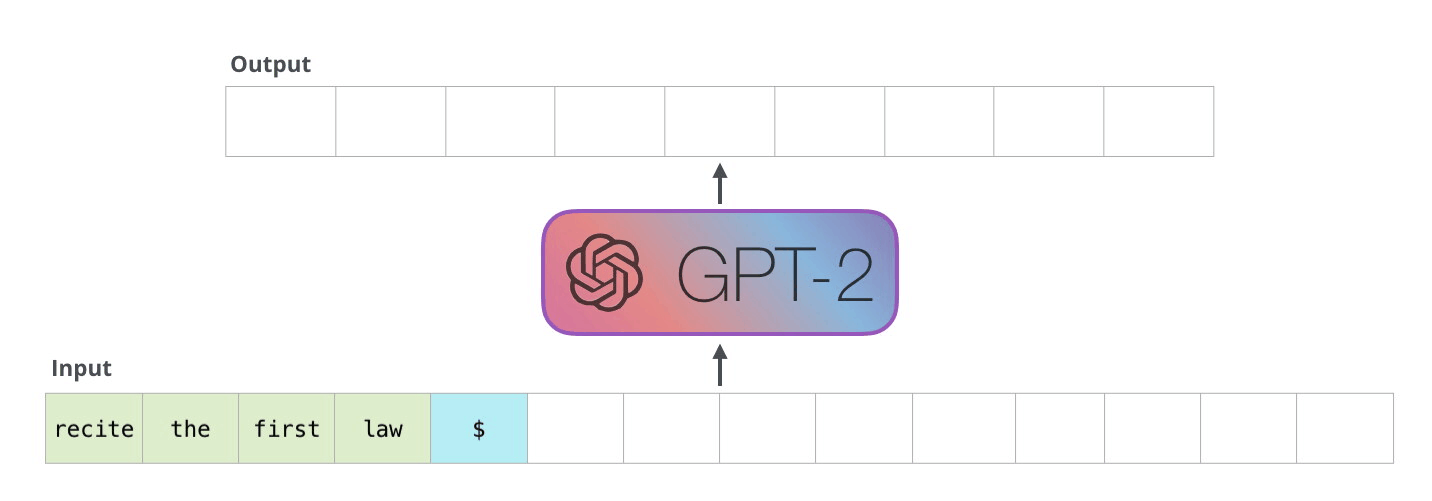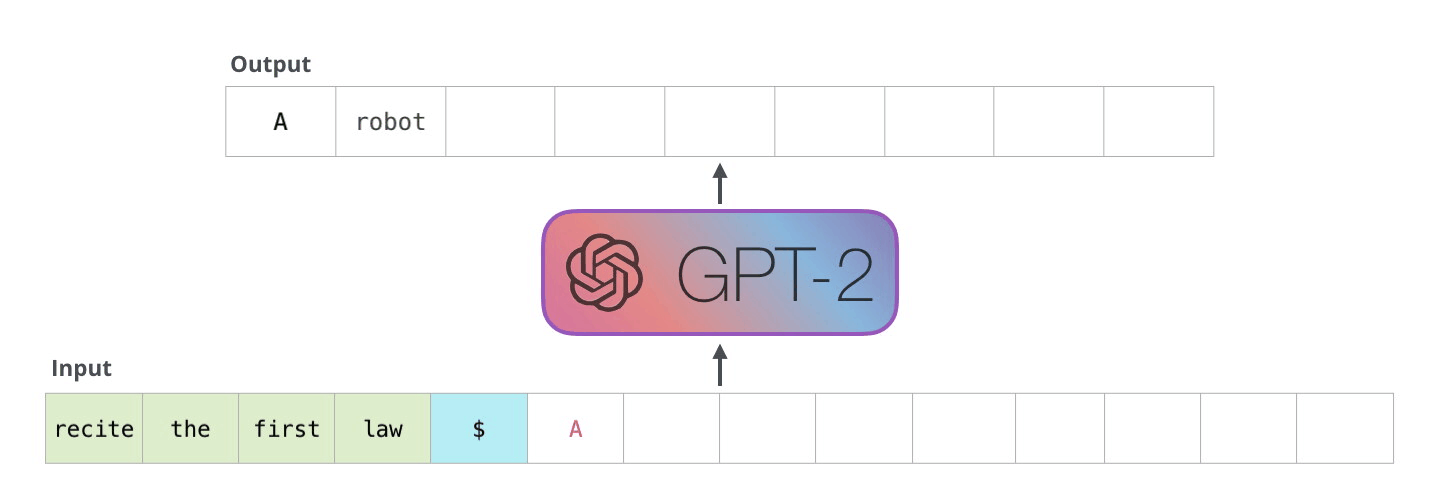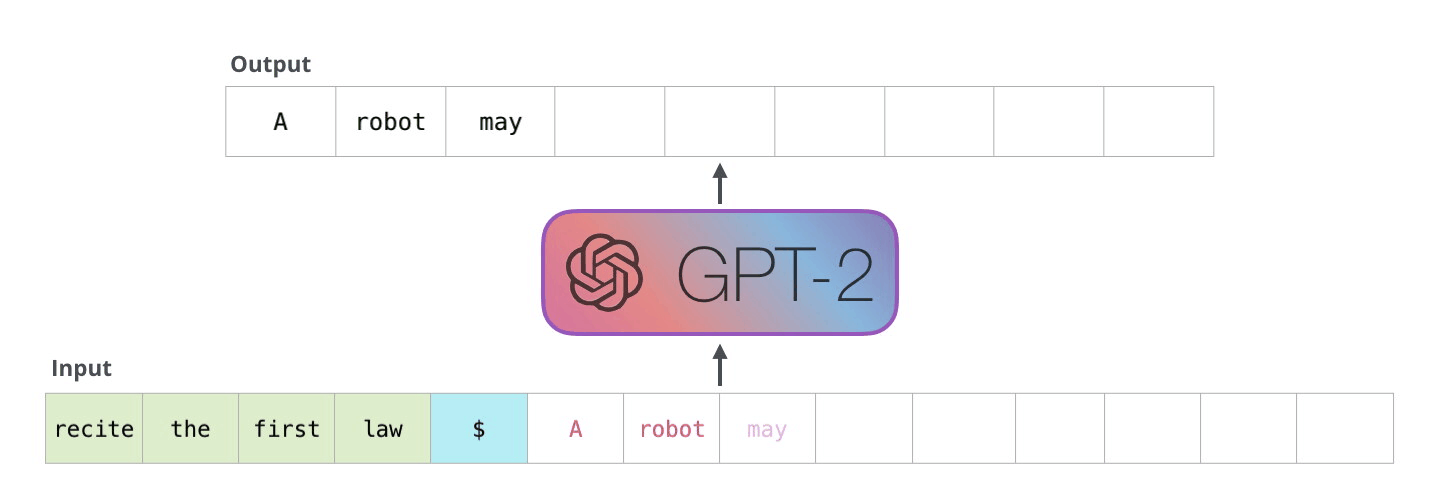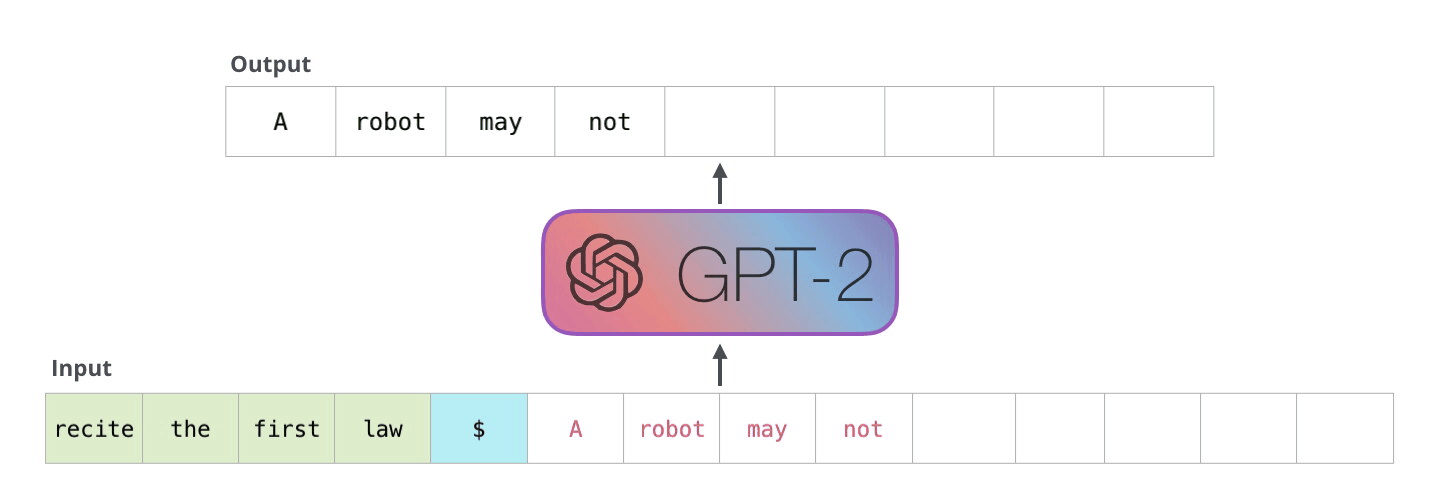
在解码器的自回归生成中,模型根据输入预测下一个token,然后将组合输入用于下一步预测。
这种自回归行为会重复某些计算操作。通过放大观察解码器中的掩码缩放点积注意力计算,我们可以更清楚地理解这一点:
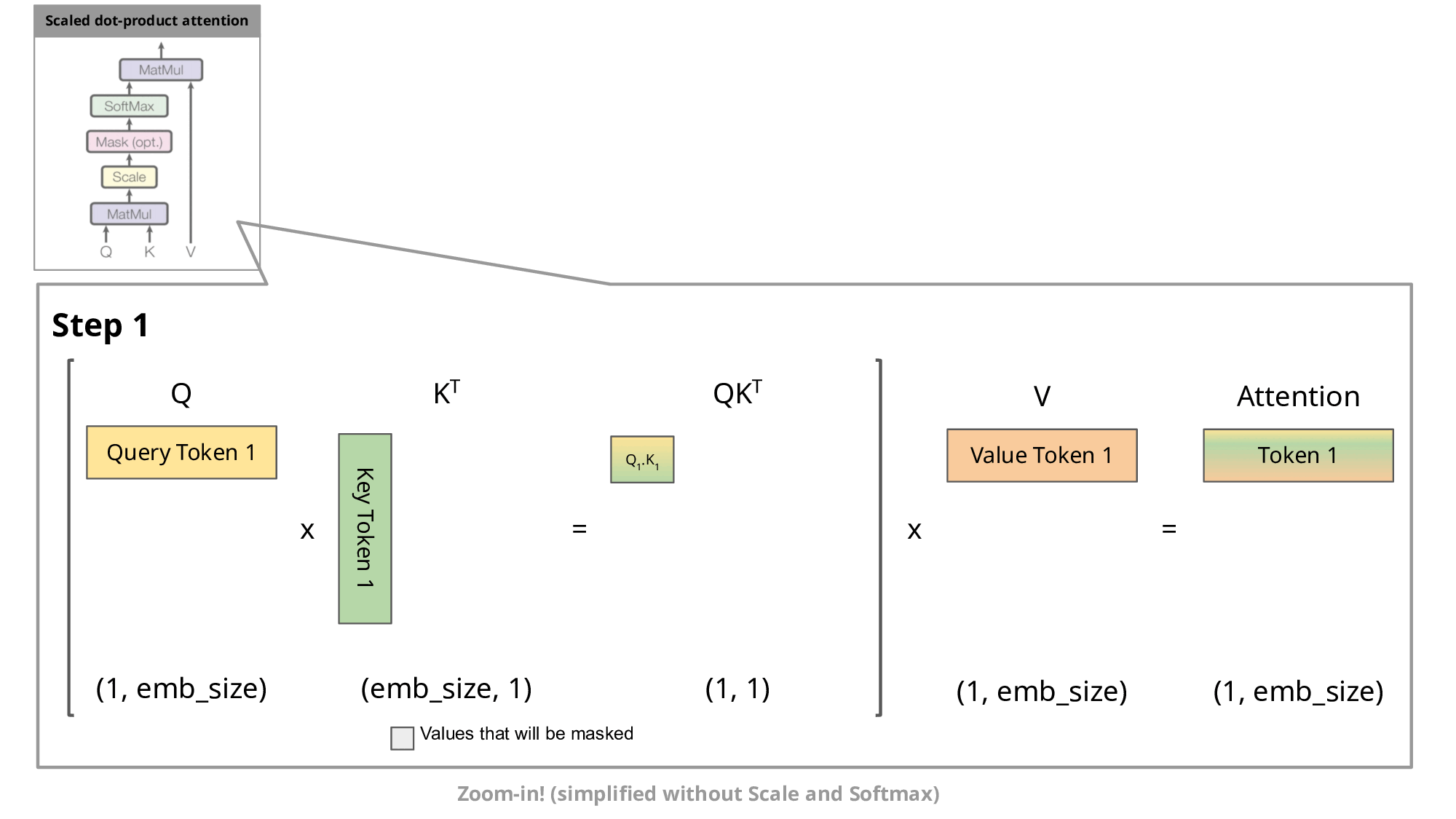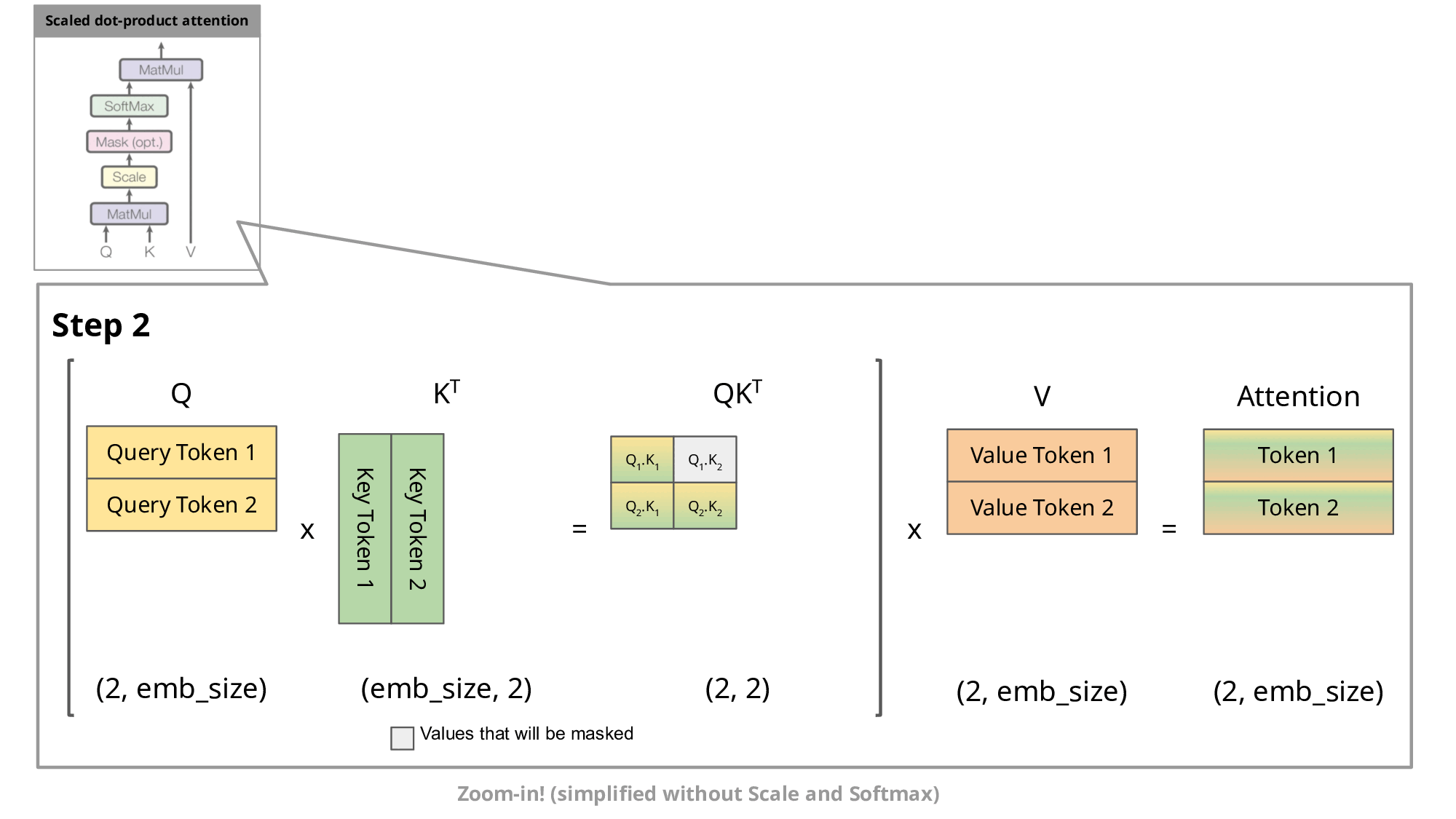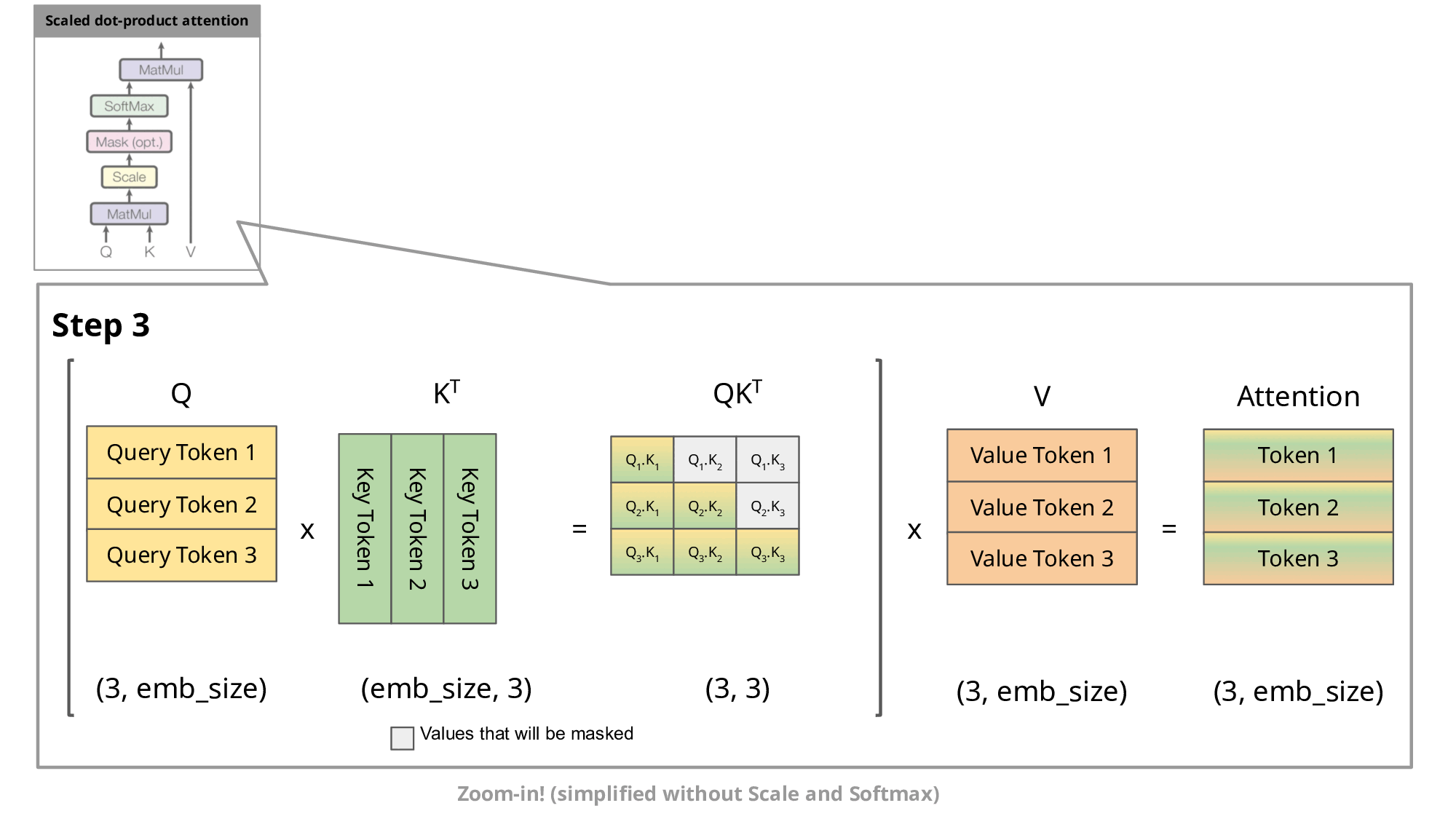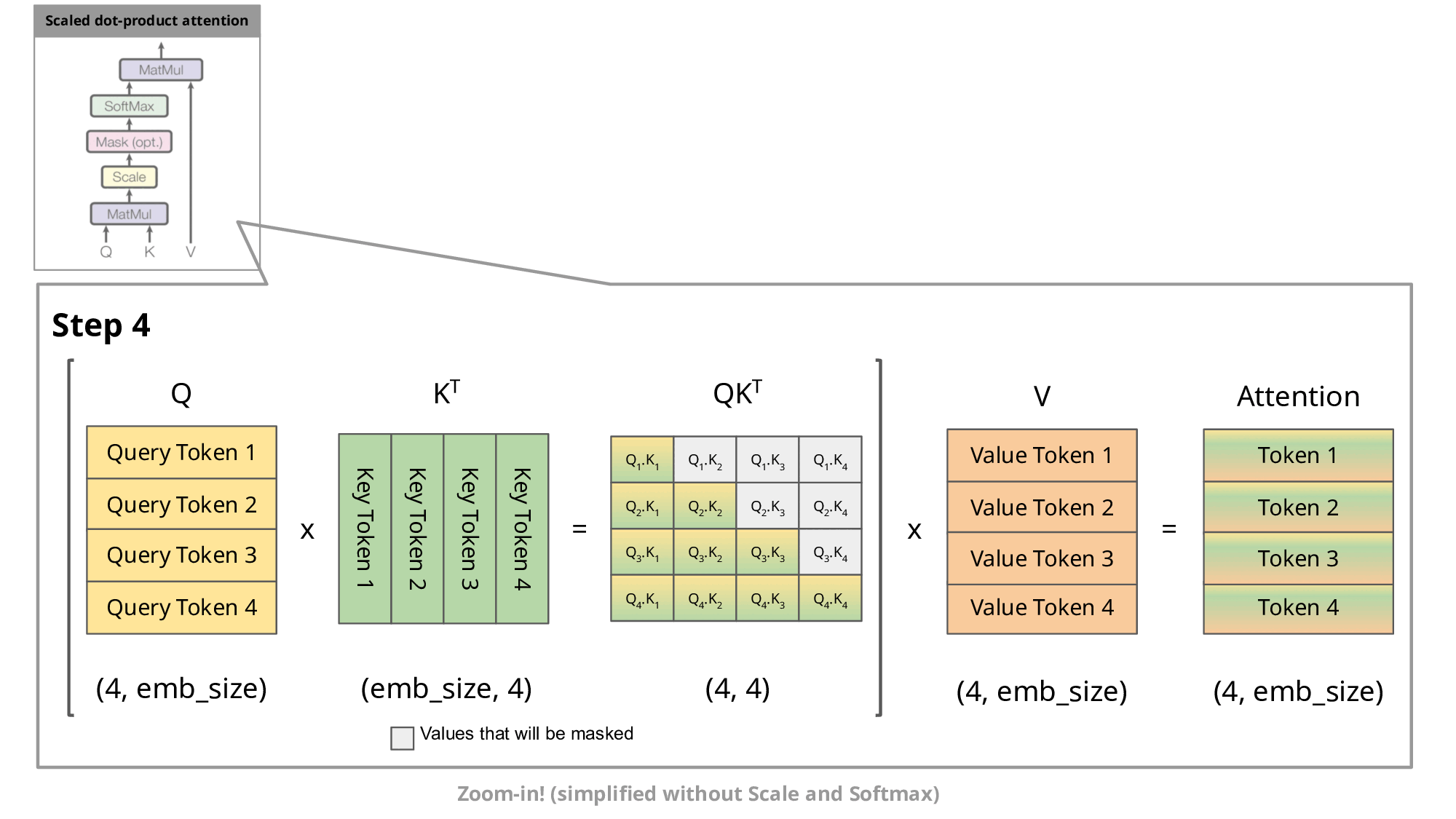
由于解码器是因果的(即token的注意力仅取决于其前面的token),在每个生成步骤中我们都在重复计算相同的前置token注意力,而实际上我们只需要计算新token的注意力。
自回归解码代码示例
import torch
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
# torch.manual_seed(0)
class Sampler:
def __init__(self , model_name : str ='gpt2-medium') -> None:
self.device = 'cuda' if torch.cuda.is_available() else 'cpu'
self.tokenizer = AutoTokenizer.from_pretrained(model_name)
self.model = AutoModelForCausalLM.from_pretrained(model_name).to("cpu").to(self.device)
def encode(self, text):
return self.tokenizer.encode(text, return_tensors='pt').to(self.device)
def decode(self, ids):
return self.tokenizer.decode(ids)
def get_next_token_prob(self, input_ids: torch.Tensor):
with torch.no_grad():
logits = self.model(input_ids=input_ids).logits
logits = logits[0, -1, :]
return logits
class GreedySampler(Sampler):
def __call__(self, prompt, max_new_tokens=10):
predictions = []
result = prompt
# generate until max_len
for i in range(max_new_tokens):
print(f"step {i} input: {result}")
input_ids = self.encode(result)
next_token_probs = self.get_next_token_prob(input_ids=input_ids)
# choose the token with the highest probability
id = torch.argmax(next_token_probs, dim=-1).item()
# convert to token and add new token to text
result += self.decode(id)
predictions.append(next_token_probs[id].item())
return resultgs = GreedySampler()
gs(prompt="Large language models are recent advances in deep learning", max_new_tokens=10)
step 0 input: Large language models are recent advances in deep learning
step 1 input: Large language models are recent advances in deep learning,
step 2 input: Large language models are recent advances in deep learning, which
step 3 input: Large language models are recent advances in deep learning, which uses
step 4 input: Large language models are recent advances in deep learning, which uses deep
step 5 input: Large language models are recent advances in deep learning, which uses deep neural
step 6 input: Large language models are recent advances in deep learning, which uses deep neural networks
step 7 input: Large language models are recent advances in deep learning, which uses deep neural networks to
step 8 input: Large language models are recent advances in deep learning, which uses deep neural networks to learn
step 9 input: Large language models are recent advances in deep learning, which uses deep neural networks to learn to可以看到,随着每次推理的输入token变长,推理FLOPs(浮点运算)会增加。KV Caching通过存储先前计算的键值对的隐藏表示来解决这个问题。
例如在第4步生成"deep"时,我们只需将"uses"输入模型,并从缓存中获取"Large language models are recent advances in deep learning, which"的表示。
KV Caching 基础原理
在Transformer架构中,键值(Key-Value,KV)向量是注意力机制的核心计算单元,用于生成Query-Key点积注意力分数。以GPT为代表的自回归语言模型采用逐token生成策略,其计算过程具有严格的前向依赖性——每个新token的预测都需要基于完整的先前上下文重新计算注意力权重。这种机制导致历史token的KV向量在每次推理迭代时都被重复计算,产生显著的算力冗余。
KV缓存技术通过持久化存储历史token的KV向量状态,有效解决了这一性能瓶颈。其技术优势主要体现在:
- 计算复用:避免重复计算已生成token的KV向量
- 延迟优化:将端到端推理延迟降低30-70%(实测数据)
- 精度无损:保持原始模型输出的数学等价性
- 内存-计算权衡:通过牺牲部分内存开销换取计算效率提升
KV Caching的工作原理
在推理过程中,Transformer模型一次生成一个token。当我们提示模型开始生成时(例如输入"She"),它将产生一个词(如"poured")。然后我们可以将"She poured"传递给模型,它会生成"coffee"。接着我们传入"She poured coffee"并获得序列结束token,表示生成完成。
这意味着我们运行了三次前向传播,每次都将查询(queries)与键(keys)相乘以获得注意力分数(同样适用于后续与值(values)的乘法)。
计算冗余分析
- 第一次前向传播只有单个输入token("She"),产生单个键向量和查询向量,相乘得到q1k1注意力分数。

- 传入"She poured"后,模型看到两个输入token,注意力模块计算如下:

我们计算了三个项,但q1k1是不必要的重复计算——因为:
- q1是输入("She")的嵌入乘以Wq矩阵
- k1是输入("She")的嵌入乘以Wk矩阵
- 嵌入和权重矩阵在推理时都是恒定的
- 第三次前向传播的查询-键计算:

我们计算了六个值,其中一半是已知且不需要重新计算的!
KV Caching机制
KV Caching的原理是:在推理时,当我们计算键(K)和值(V)矩阵时,将其元素存储在缓存中。缓存是一个辅助内存,支持高速检索。在生成后续token时,我们只计算新token的键和值。
例如,使用缓存时第三次前向传播如下:

处理第三个token时,我们不需要重新计算前两个token的注意力分数,可以从缓存中检索它们的键和值,从而节省计算时间。
KV Caching 原理
这正是KV Caching发挥作用的地方。通过缓存先前的Keys和Values,我们可以专注于仅计算新token的注意力:
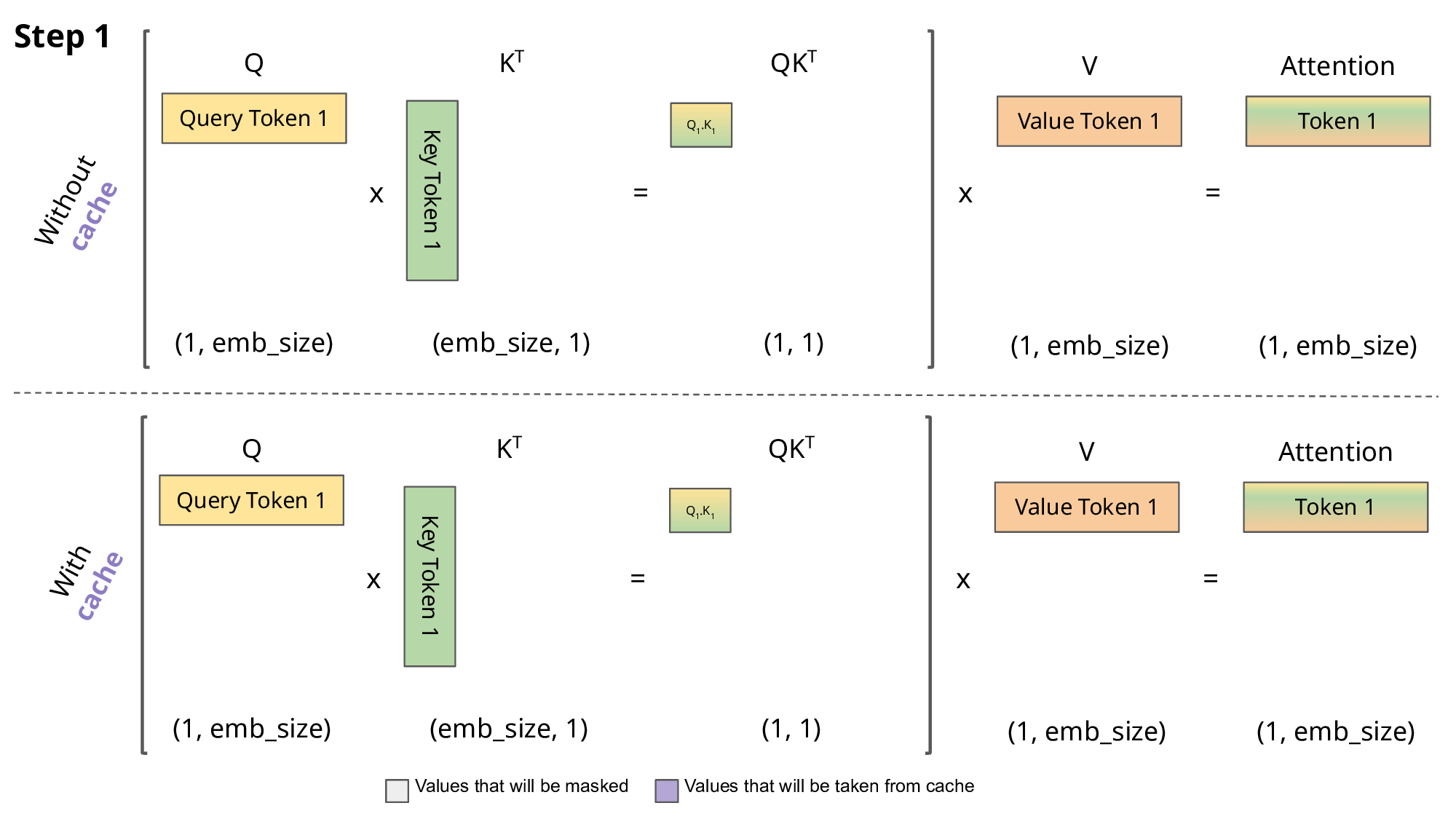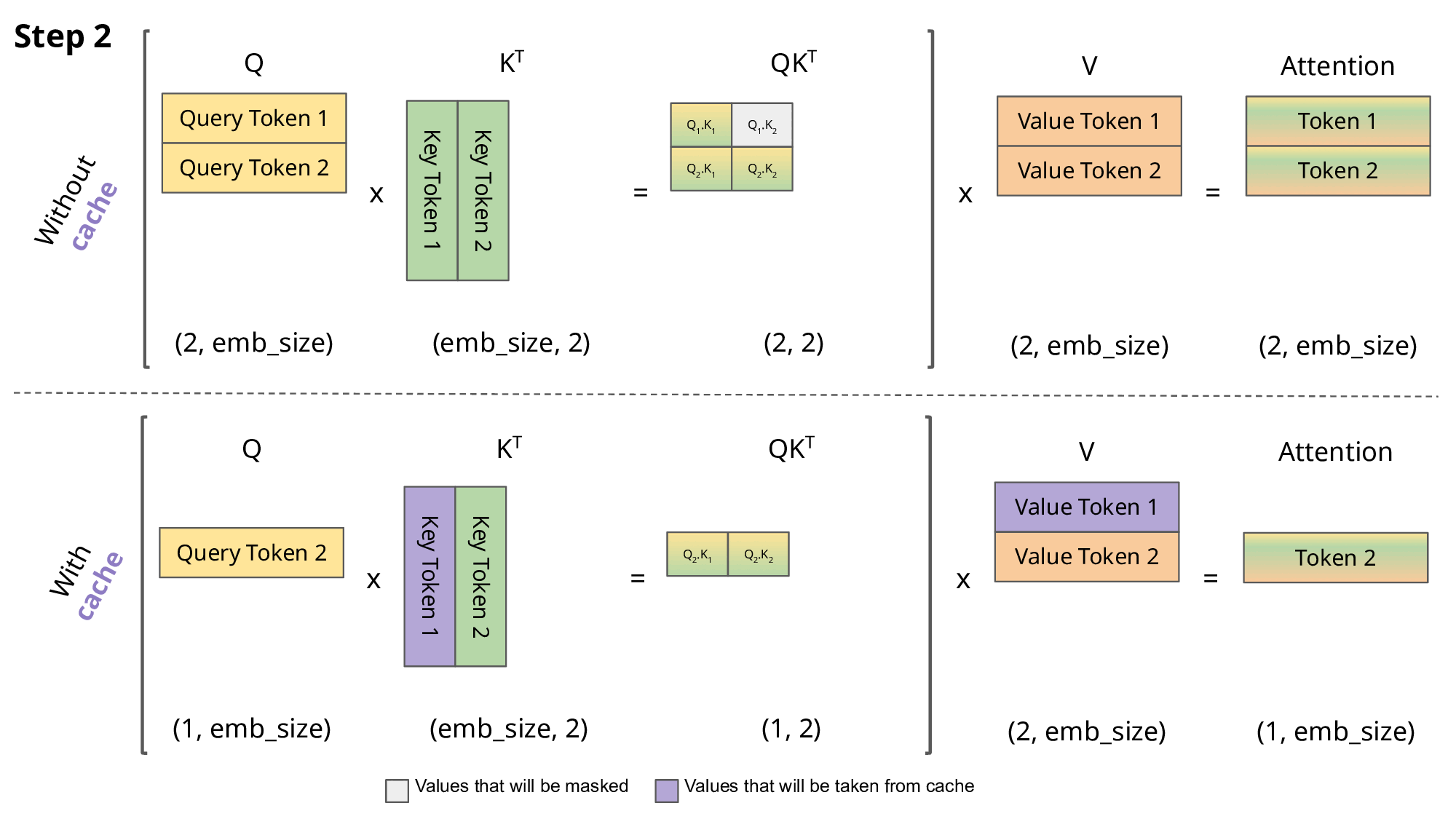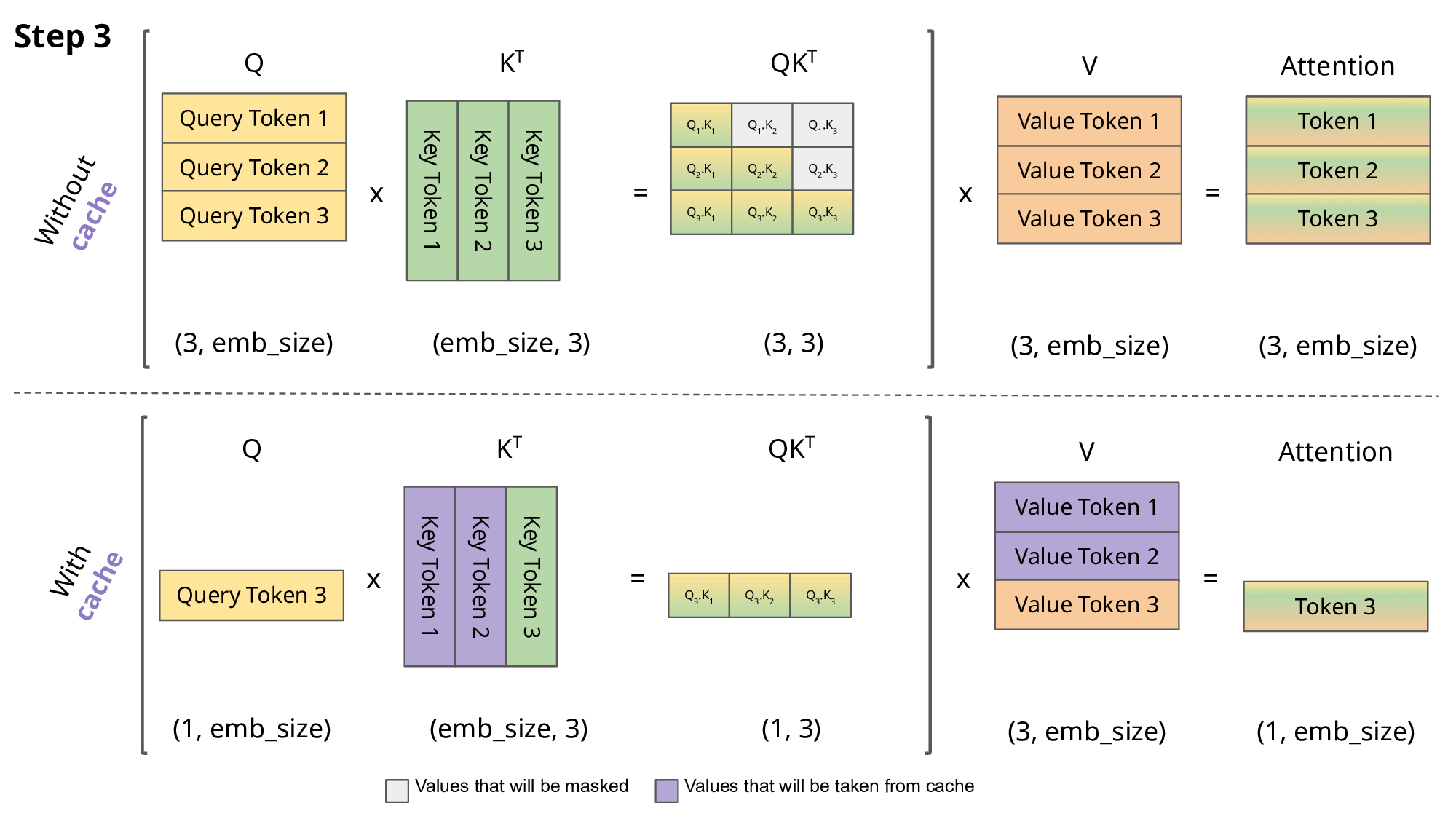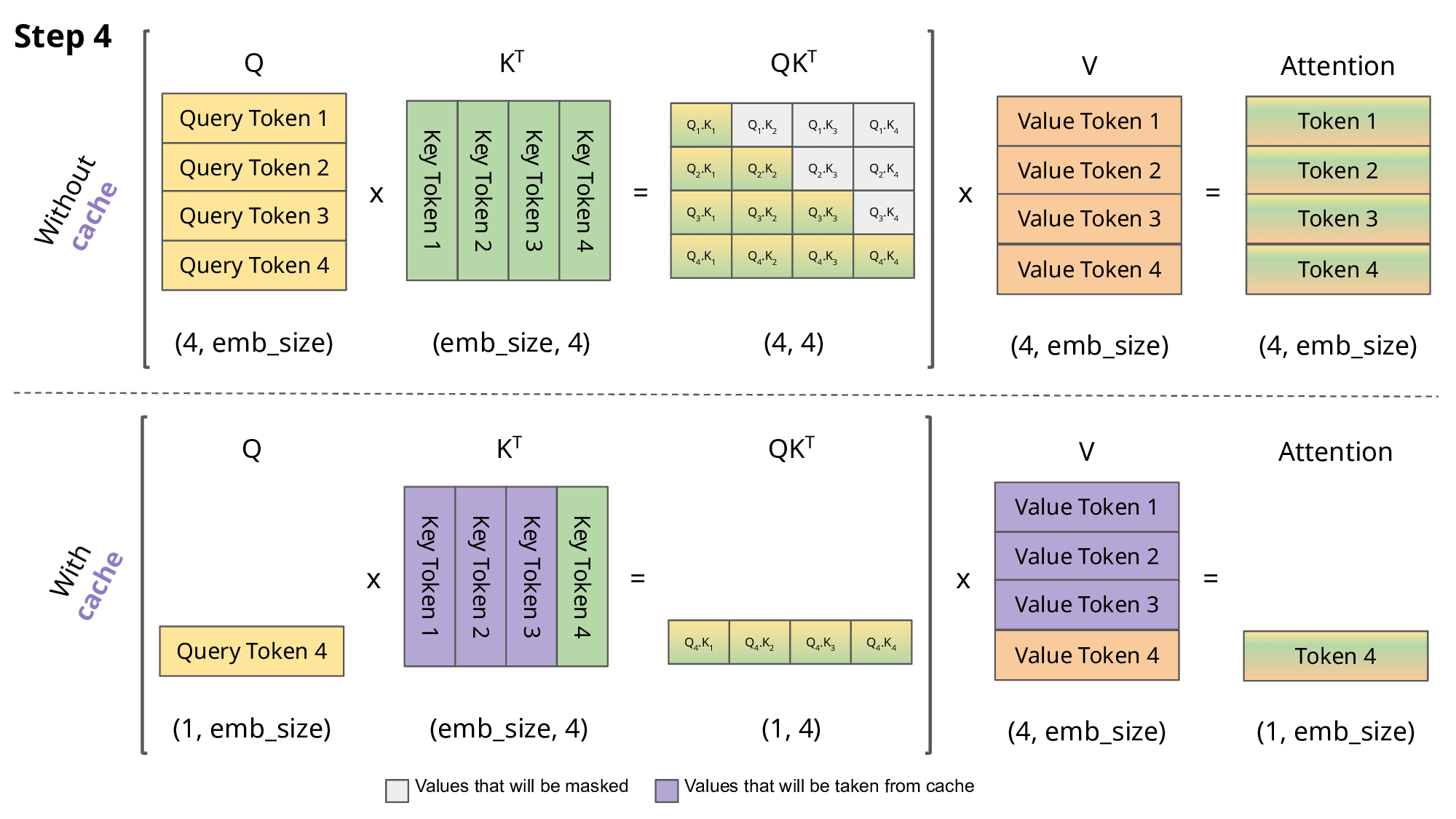
为什么这种优化很重要?如上图所示,使用KV Caching获得的矩阵要小得多,从而实现了更快的矩阵乘法运算。唯一的缺点是它需要更多的GPU显存(如果不使用GPU则需要更多CPU内存)来缓存Key和Value状态。
KV Caching的数学表达
给定生成的第 $t $ 个 token 在 Transformer 层中的表示,记作 $t^i \in \mathbb{R}^{b \times 1 \times h} $,其中:
- $b $ 表示 batch size
- $h $ 表示 hidden dimension
在 Transformer 第 $t $ 层的计算分为两部分:
- KV Caching的更新
- 下一层输入 $t^{i+1} $ 的计算
KV Caching更新公式
$$ \begin{aligned} x_{K}^i &\leftarrow \text{Concat} \left( x_{K}^i, t^i \cdot W_{K}^i \right) \ x_{V}^i &\leftarrow \text{Concat} \left( x_{V}^i, t^i \cdot W_{V}^i \right) \end{aligned} $$
剩余计算步骤
Query 向量计算: $$ t_Q^i = t^i \cdot W_Q^i $$
Attention 输出: $$ t_{\text{out} }^i = \text{softmax} \left( \frac{t_Q^i x_{K}^{i\top} }{\sqrt{h} } \right) \cdot x_V^i \cdot W_O^i + t^i $$
Feed-Forward 计算: $$ t^{i+1} = f_{\text{activation} } \left( t_{\text{out} }^i \cdot W_1 \right) \cdot W_2 + t_{\text{out} }^i $$
KV Caching实现
缓存类实现
当使用Transformers库的Cache类时,自注意力模块会执行几个关键步骤来整合过去和当前的信息:
- 注意力模块将当前的键值对与缓存中存储的历史键值对进行拼接。这会创建形状为
(new_tokens_length, past_kv_length + new_tokens_length)的注意力权重。 当前和历史键值对实质上被组合起来计算注意力分数,确保模型同时感知历史上下文和当前输入 - 当迭代调用
forward方法时,必须确保注意力掩码(attention mask)的形状与历史和当前键值对的组合长度匹配。注意力掩码应具有(batch_size, past_kv_length + new_tokens_length)的形状。这通常在generate()方法内部处理,但如果你想用Cache实现自己的生成循环,请牢记这一点!注意力掩码应包含历史和当前token的值。 - 还需要特别注意
cache_position参数。如果你想用forward方法重用预填充的缓存,必须传递有效的cache_position值。它表示序列中的输入位置。cache_position不受填充(padding)影响,总是为每个token增加一个位置。例如,如果KV Caching包含10个token(不考虑填充token),下一个token的缓存位置应该是torch.tensor([10])。
Naive Implemention
假设架构中有n个Transformer层,那么每个注意力头将维护自己独立的KV Caching:
import torch
import torch.nn as nn
import torch.nn.functional as F
# 模拟模型参数结构
class ModelArgs:
def __init__(self, dim=16, n_heads=2, max_seq_len=8, max_batch_size=1):
self.dim = dim
self.n_heads = n_heads
self.head_dim = dim // n_heads
self.max_seq_len = max_seq_len
self.max_batch_size = max_batch_size
class SelfAttention(nn.Module):
def __init__(self, args: ModelArgs):
super().__init__()
self.args = args
self.n_heads = args.n_heads
self.head_dim = args.head_dim
self.dim = args.dim
self.w_q = nn.Linear(self.dim, self.dim, bias=False)
self.w_k = nn.Linear(self.dim, self.dim, bias=False)
self.w_v = nn.Linear(self.dim, self.dim, bias=False)
self.w_o = nn.Linear(self.dim, self.dim, bias=False)
# 缓存初始化
self.register_buffer("cache_k", torch.zeros(
args.max_batch_size, args.max_seq_len, self.n_heads, self.head_dim
))
self.register_buffer("cache_v", torch.zeros(
args.max_batch_size, args.max_seq_len, self.n_heads, self.head_dim
))
def forward(self, x: torch.Tensor, start_pos: int):
# x shape: (B, 1, D)
B, S, D = x.size()
H = self.n_heads
Hd = self.head_dim
# Linear projections
q = self.w_q(x).view(B, S, H, Hd)
k = self.w_k(x).view(B, S, H, Hd)
v = self.w_v(x).view(B, S, H, Hd)
# 更新缓存
self.cache_k[:B, start_pos:start_pos+S] = k
self.cache_v[:B, start_pos:start_pos+S] = v
# 获取当前全部 key/value(从0到当前位置)
keys = self.cache_k[:B, :start_pos+S] # (B, Seq_KV, H, Hd)
values = self.cache_v[:B, :start_pos+S]
# Attention计算
q = q.transpose(1, 2) # (B, H, 1, Hd)
k = keys.transpose(1, 2) # (B, H, Seq_KV, Hd)
v = values.transpose(1, 2) # (B, H, Seq_KV, Hd)
attn_scores = torch.matmul(q, k.transpose(-2, -1)) / (Hd ** 0.5) # (B, H, 1, Seq_KV)
attn_weights = F.softmax(attn_scores, dim=-1)
attn_output = torch.matmul(attn_weights, v) # (B, H, 1, Hd)
attn_output = attn_output.transpose(1, 2).contiguous().view(B, S, D) # (B, 1, D)
out = self.w_o(attn_output)
return out
# ====== 测试示例 ======
torch.manual_seed(42)
args = ModelArgs()
attn = SelfAttention(args)
# 模拟一个序列分步生成,每步输入一个 token
sequence = torch.randn(1, args.max_seq_len, args.dim)
outputs = []
for i in range(args.max_seq_len):
x = sequence[:, i:i+1, :] # 当前时间步的 token
y = attn(x, start_pos=i) # KV Caching 自动生效
outputs.append(y)
# 拼接结果
final_out = torch.cat(outputs, dim=1)
print("🧾 最终输出 shape:", final_out.shape)
print(final_out)Transformers 中的实现
以下示例演示了如何使用DynamicCache创建生成循环。如前所述,注意力掩码是历史和当前token值的拼接,并且为下一个token将缓存位置加1。
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, DynamicCache
model_id = "meta-llama/Llama-2-7b-chat-hf"
model = AutoModelForCausalLM.from_pretrained(model_id, torch_dtype=torch.bfloat16, device_map="cuda:0")
tokenizer = AutoTokenizer.from_pretrained(model_id)
past_key_values = DynamicCache()
messages = [{"role": "user", "content": "Hello, what's your name."}]
inputs = tokenizer.apply_chat_template(messages, add_generation_prompt=True, return_tensors="pt", return_dict=True).to("cuda:0")
generated_ids = inputs.input_ids
cache_position = torch.arange(inputs.input_ids.shape[1], dtype=torch.int64, device="cuda:0")
max_new_tokens = 10
for _ in range(max_new_tokens):
outputs = model(**inputs, cache_position=cache_position, past_key_values=past_key_values, use_cache=True)
# 贪婪采样下一个token
next_token_ids = outputs.logits[:, -1:].argmax(-1)
generated_ids = torch.cat([generated_ids, next_token_ids], dim=-1)
# 通过保留未处理的token(本例中只有一个新token)来准备下一个生成步骤的输入
# 并按照上述说明扩展注意力掩码
attention_mask = inputs["attention_mask"]
attention_mask = torch.cat([attention_mask, attention_mask.new_ones((attention_mask.shape[0], 1))], dim=-1)
inputs = {"input_ids": next_token_ids, "attention_mask": attention_mask}
cache_position = cache_position[-1:] + 1 # 为下一个token增加一个位置
print(tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0])
# 输出: "[INST] Hello, what's your name. [/INST] Hello! My name is LLaMA,"传统缓存格式
在Cache类出现之前,缓存是以张量元组的元组形式存储的。这种格式是动态的,会随着文本生成而增长,类似于DynamicCache。
如果你的项目依赖这种传统格式,可以使用from_legacy_cache()和DynamicCache.to_legacy_cache()函数在DynamicCache和元组元组之间进行转换。这对于需要以特定格式操作缓存的自定义逻辑很有帮助。
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, DynamicCache
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-2-7b-chat-hf")
model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-2-7b-chat-hf", torch_dtype=torch.float16, device_map="auto")
inputs = tokenizer("Hello, my name is", return_tensors="pt").to(model.device)
# `return_dict_in_generate=True`是返回缓存所必需的,而`return_legacy_cache`强制返回传统格式的缓存
generation_outputs = model.generate(**inputs, return_dict_in_generate=True, return_legacy_cache=True, max_new_tokens=5)
cache = DynamicCache.from_legacy_cache(generation_outputs.past_key_values)
legacy_format_cache = cache.to_legacy_cache()KV Caching性能影响评估
KV Caching可能对推理时间产生重大影响。影响程度取决于模型架构。可缓存的计算越多,减少推理时间的潜力就越大。
我们使用transformers🤗库比较GPT-2在使用和不使用KV Caching时的生成速度:
import numpy as np
import time
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
device = "cuda" if torch.cuda.is_available() else "cpu"
tokenizer = AutoTokenizer.from_pretrained("gpt2")
model = AutoModelForCausalLM.from_pretrained("gpt2").to(device)
for use_cache in (True, False):
times = []
for _ in range(10): # 测量10次生成
start = time.time()
model.generate(**tokenizer("What is KV caching?", return_tensors="pt").to(device), use_cache=use_cache, max_new_tokens=1000)
times.append(time.time() - start)
print(f"{'with' if use_cache else 'without'} KV caching: {round(np.mean(times), 3)} +- {round(np.std(times), 3)} seconds")在Google Colab笔记本上使用Tesla T4 GPU,生成1000个新token的平均时间和标准差如下:
使用KV Caching: 11.885 ± 0.272秒 不使用KV Caching: 56.197 ± 1.855秒
推理速度差异巨大,而GPU显存使用量变化可以忽略不计。因此请确保在您的Transformer模型中使用KV Caching!