AlphaZero:从零开始掌握围棋、国际象棋和将棋
之前章节介绍的强化学习方法都是无模型的强化学习 (model-free), 包括价值学习 (value-based)和策略学习 (policy-based)。本章介绍的蒙特卡洛树搜索 (Monte Carlo Tree Search, 缩写 MCTS) 是一种基于模型的强化学习方法 (model-based)。MCTS 比价值学习和策略学习更难理解, 所以本章结合 AlphaGo 讲解 MCTS。
AlphaGo 的字面意思是“围棋王”, 俗称“阿尔法狗”, 它是世界上第一个打败人类围棋 冠军的
AlphaGo 依靠 MCTS 做决策, 而决策的过程中需要策略网络和价值网络的辅助。第
1. 动作、状态、策略网络、价值网络
1.1 状态
围棋的棋盘是
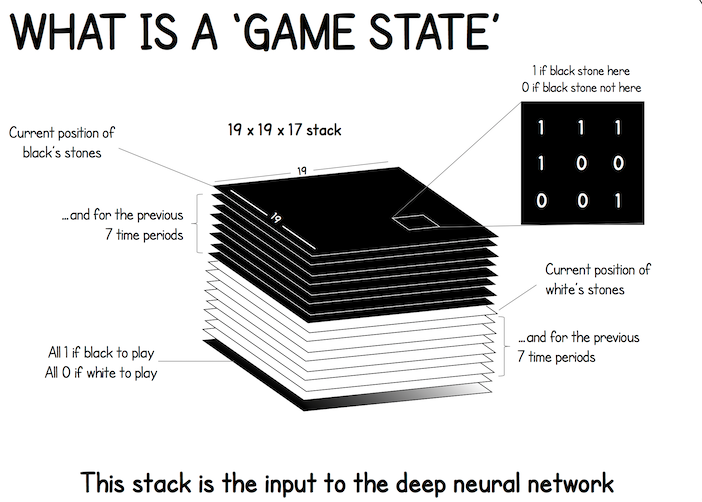
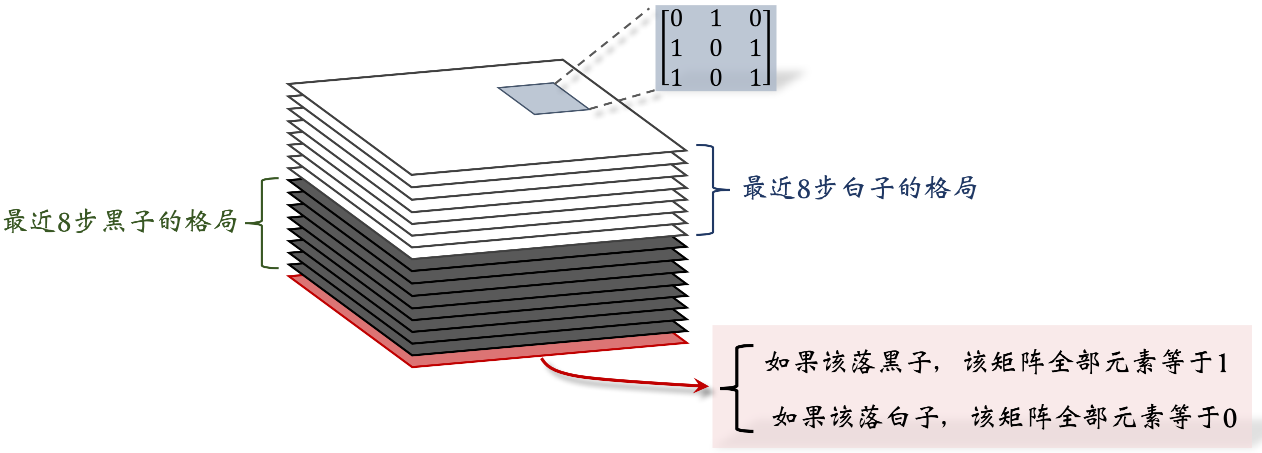
图 1: 状态可以表示为
的张量。
AlphaGo 2016 版本使用
张量每个切片 (slice) 是
的矩阵, 对应 的棋盘。一个 的矩阵可以表示棋盘上所有黑子的位置。如果一个位置上有黑子, 矩阵对应的元素就是 1, 否则就是 0。同样的道理, 用一个 的矩阵来表示当前棋盘上所有白子的位置。 张量中一共有 17 个这样的矩阵;17 是这样得来的。记录最近 8 步棋盘上黑子的位置, 需要 8 个矩阵。同理, 还需要 8 个矩阵记录白子的位置。还另外需要一个矩阵表示该哪一方下棋; 如果该下黑子, 那么该矩阵元素全部等于 1 ; 如果该下白子, 那么该矩阵的元素全都等于 0。
1.2 策略网络
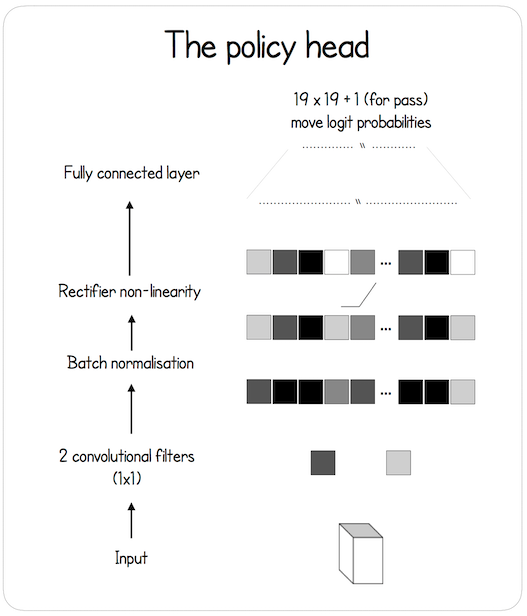
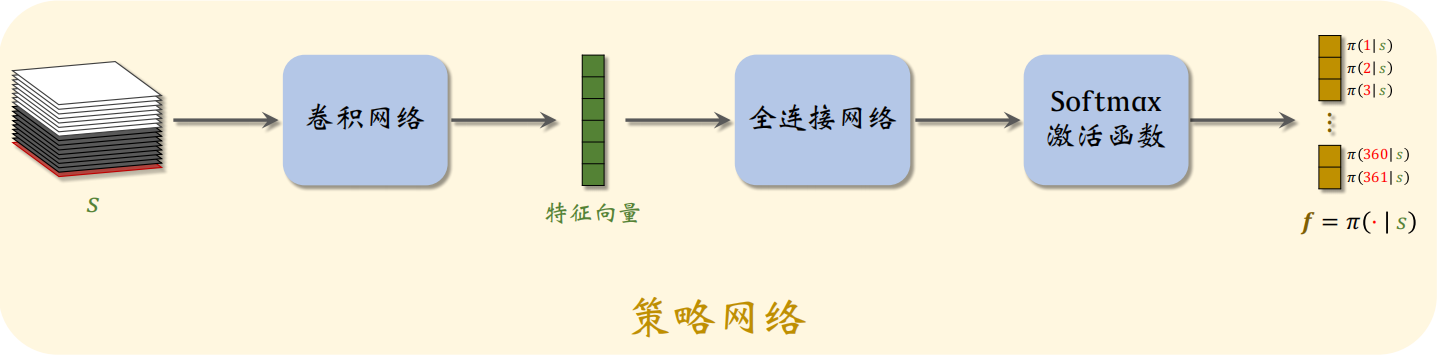
图 2: 策略网络的示意图。
1.3 策略网络与价值网络
策略网络
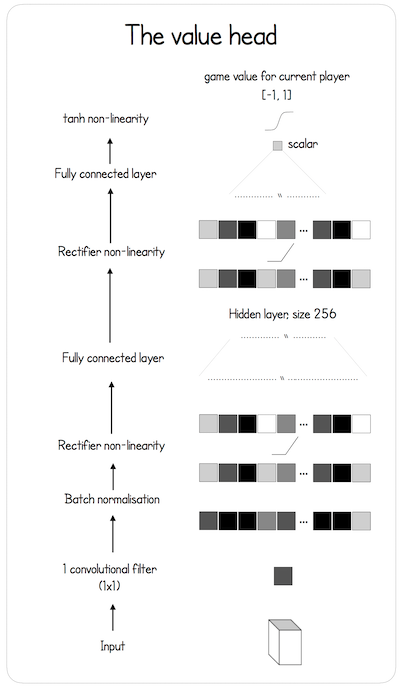
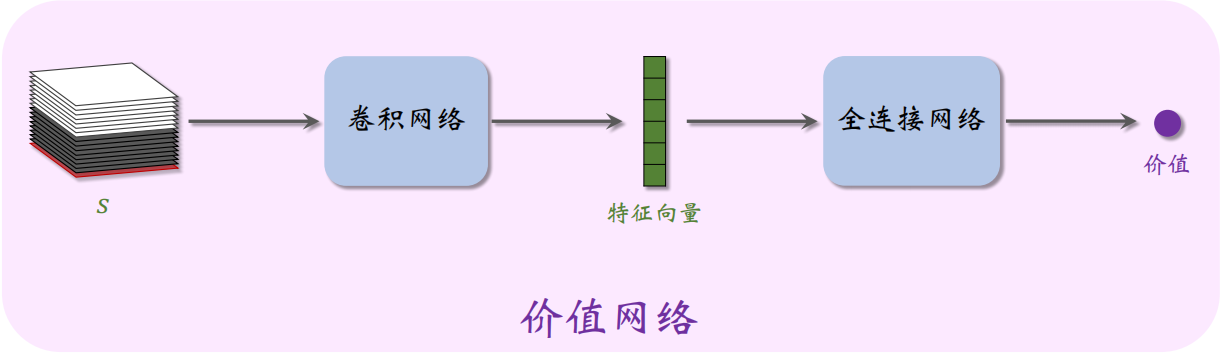
图 3: 价值网络的示意图。
AlphaGo 还有一个价值网络
策略网络和价值的输入相同, 都是状态
2. 蒙特卡洛树搜索 (MCTS)
假设此时已经训练好了策略网络
2.1 MCTS 的基本思想
思考一个问题:人类玩家是怎么下围棋、象棋、五子棋的?
人类玩家通常都会向前看几步; 越是高手, 看得越远。假如现在该我放棋子了, 我应该思考这样的问题:当前有几个貌似可行的走法, 假如我的动作是
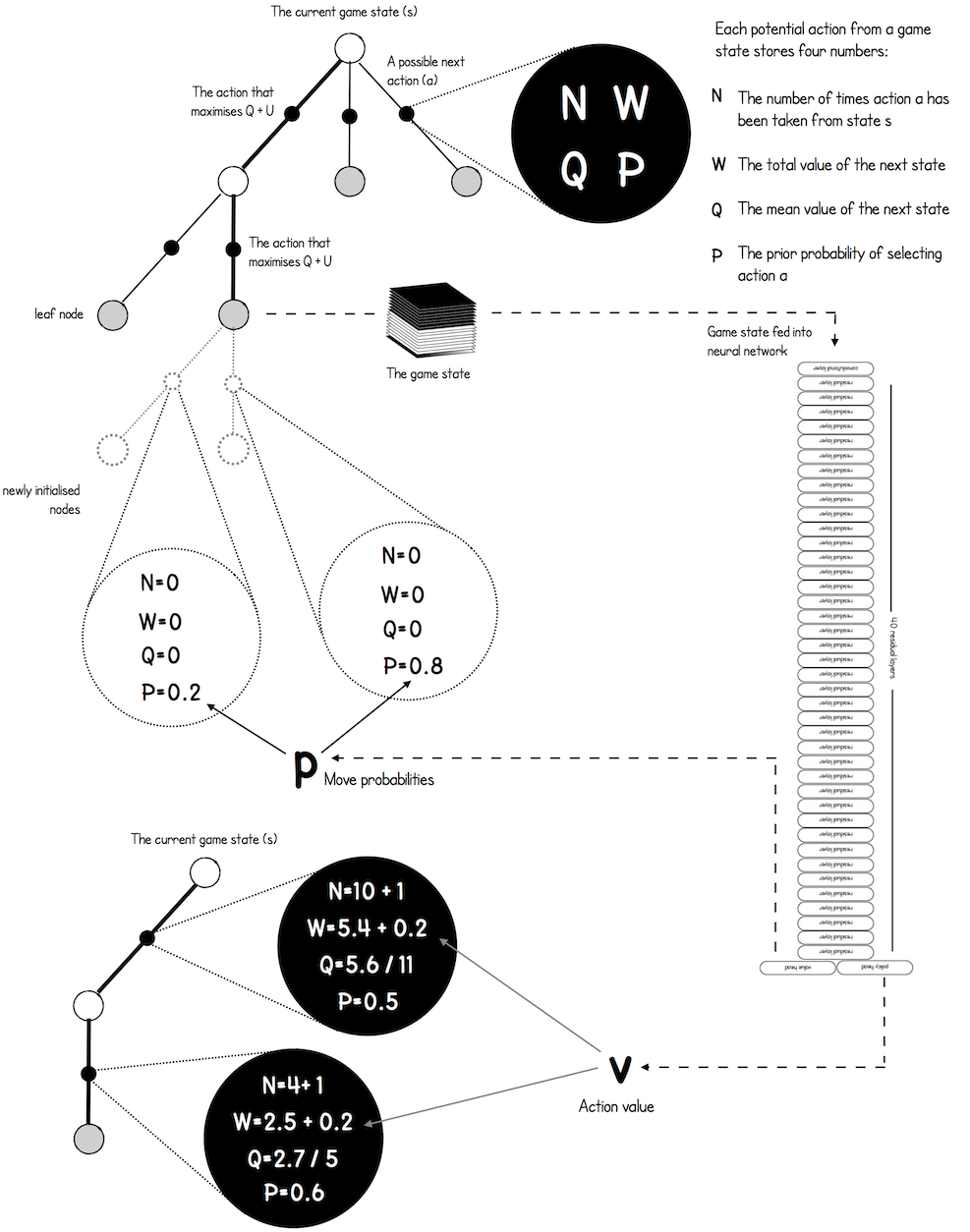
如上图所示,搜索树中的边表示从一个状态转移到另一个状态的动作
2.2 MCTS 的四个步骤
2.2.1 第一步:选择 (Selection)
观测棋盘上当前的格局, 找出所有空位, 然后判断其中哪些位置符合围棋规则 ; 每个符合规则的位置对应一个可行的动作。每一步至少有几 十、甚至上百个可行的动作; 假如挨个搜索和评估所有可行动作, 计算量会大到无法承受。虽然有几十、上百个可行动作, 好在只有少数几个动作有较高的胜算。第一步选择的目的就是找出胜算较高的动作, 只搜索这些好的动作, 忽略掉其他的动作。
如何判断动作
此处的
是动作 已经被访问过的次数。初始的时候, 对于所有的 , 令 。动作 每被选中一次, 我们就把 加一: 。 是之前 次模拟算出来的动作价值, 主要由胜率和价值函数决定。 的初始值是 0 ; 动作 每被选中一次, 就会更新一次 ; 后面会详解。
可以这样理解公式 (1):
- 如果动作
还没被选中过, 那么 和 都等于零, 因此可得
也就是说完全由策略网络评价动作
- 如果动作
已经被选中过很多次, 那么 就很大, 导致策略网络在 中 的权重降低。当 很大的时候, 有
此时主要基于
- 系数
的另一个作用是鼓励探索, 也就是让被选中次数少的动作有更多的机会被选中。假如两个动作有相近的 分数和 分数, 那么被选中次数少的动作的 score 会更高。
MCTS 根据公式 (1) 算 出所有动作的分数

图 4: 假设有 3 个可行动作, 根据公式 (1) 算出它们 的分数。
2.2.2 第二步:扩展 (Expansion)
把第一步选中的动作记作
此处的状态
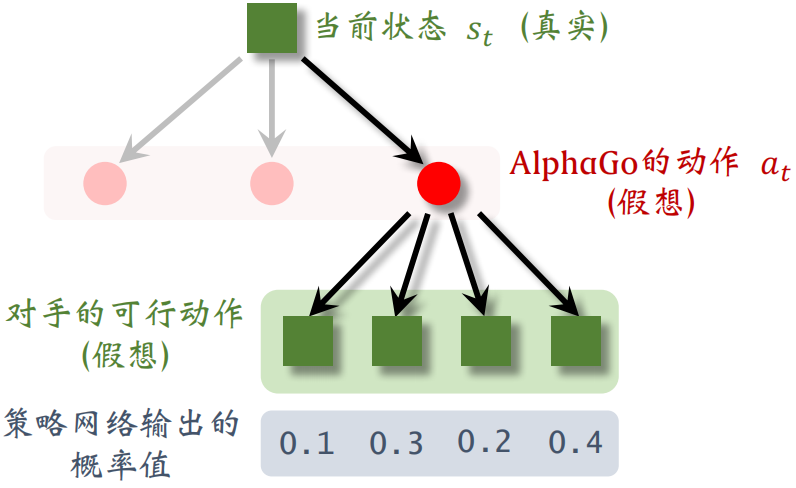
图 5: 假设 AlphaGo 有三种可行的动作,AlphaGo 选中第三个,并在模拟中执行。用策略网络模拟对手,策略网络输出对手可行动作的概率值:0*.1, 0.3, 0.2, 0.*4。
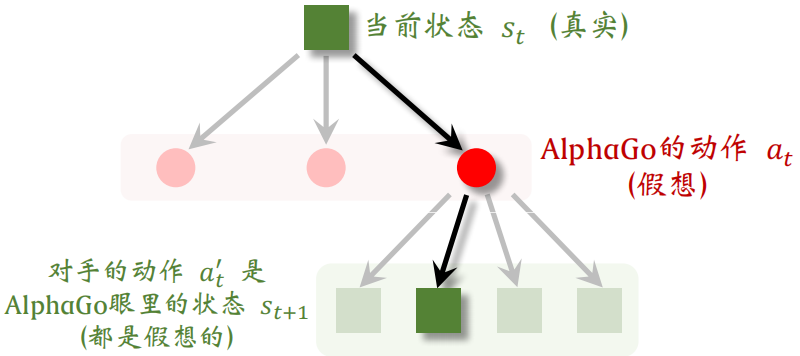
图 6: 假设对手有四种可行的动作,AlphaGo 根据概率值做随机抽样,替对手选中了第二种动作。对手的动作就是 AlphaGo 眼里的新的状态。
AlphaGo 需要在模拟中跟对手将一局游戏进行下去, 所以需要一个模拟器 (即环境)。在模拟器中, AlphaGo 每执行一个动作
AlphaGo 模拟器利用了围棋游戏的对称性:AlphaGo 的策略, 在对手看来是状态转移函数; 对手的策略, 在 AlphaGo 看来是状态转移函数。最理想的情况下, 模拟器的状态转移函数是对手的真实策略;然而 AlphaGo 并不知道对手的真实策略。AlphaGo 退而求其次, 用 AlphaGo 自己训练出的策略网络
想要用 MCTS 做决策, 必须要有模拟器, 而搭建模拟器的关键在于构造正确的状态转移函数
2.2.3 第三步:求值 (Evaluation)
从状态
对手基于状态
当这局游戏结束时, 可以观测到奖励
回顾一下, 棋盘上真实的状态是
如果 AlphaGo 赢得这局模拟
, 则 说明 可能很好; 如果输了 , 则说明 可能不好。因此, 奖励 可 以反映出 的好坏。 此外, 还可以用价值网络
评价状态 的好坏。价值 越大, 则说明状 态 越好。
奖励
把它记录下来, 作为对状态
实际实现的时候, AlphaGo 还训练了一个更小的神经网络, 它做决策更快。MCTS 在第一步和第二步用大的策略网络, 第三步用小的策略网络。读者可能好奇, 为什么在且仅在第三步用小的策略网络呢? 第三步两个策略网络交替落子, 通常要走一两百步, 导致第三步成为 MCTS 的瓶颈。用小的策略网络代替大的策略网络, 可以大幅加速 MCTS。
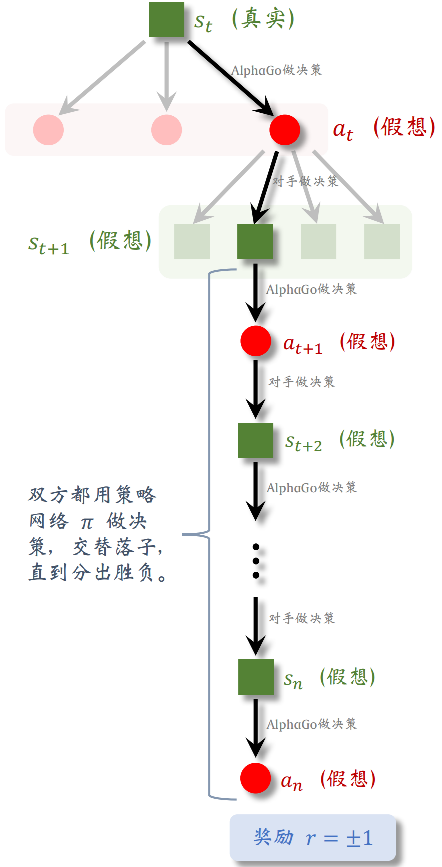
2.2.4 第四步:回溯(Backup)
在第三步求值过程中算出了第
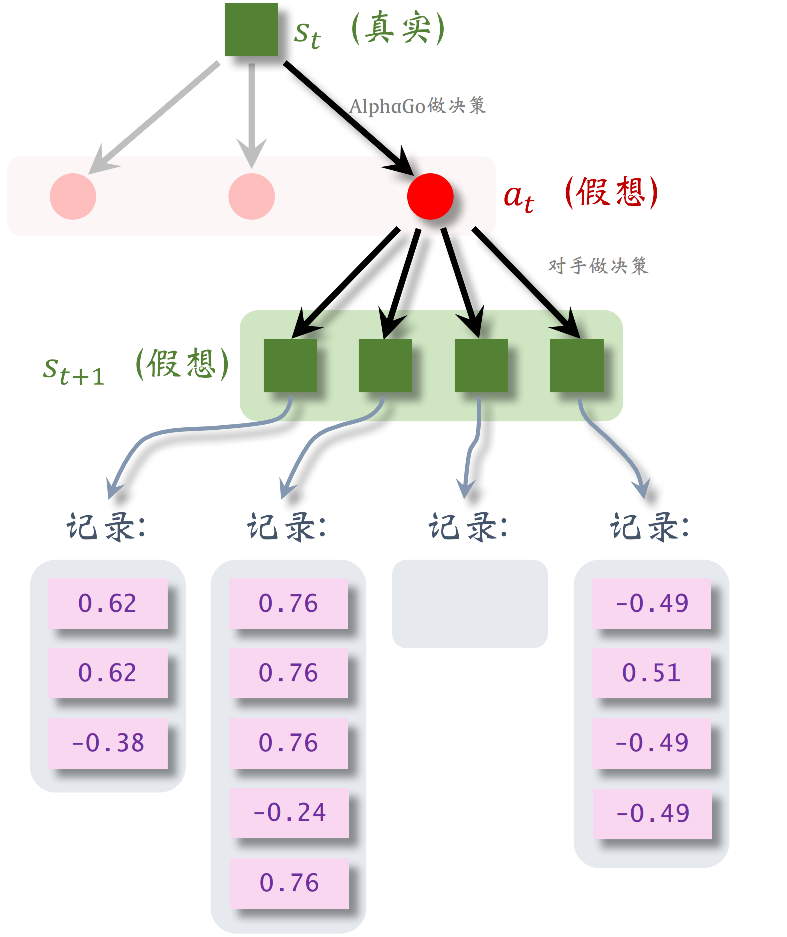
图 8: 每一个状态
下面都有很多条记录, 每一 条记录是一个 。
给定棋盘上的真实状态
回顾第一步一选择 (Selection) : 基于棋盘上真实的状态
然后选择分数最高的
2.3 MCTS 的决策
上一小节讲解了单次模拟的四个步骤, 注意, 这只是单次模拟而已。MCTS 想要真正做出一个决策 (即往真正的棋盘上落一个棋子), 需要做成千上万次模拟。在做了无数次模拟之后, MCTS 做出真正的决策:
此时 AlphaGo 才会真正往棋盘上放一个棋子。
为什么要依据
观测到棋盘上当前状态
AlphaGo 下棋非常“暴力”: 每走一步棋之前, 它先在“脑海里”模拟几千、几万局, 它可以预知它每一种动作带来的后果, 对手最有可能做出的反应都在 AlphaGo 的算计之内。由于计算量差距悬殊, 人类面对 AlphaGo 时不太可能有胜算。这样的比赛对人来说是不公平的; 假如李世石下每一颗棋子之前, 先跟柯洁模拟一千局, 或许李世石的胜算会大于 AlphaGo。
3. 训练策略网络和价值网络
上一节假设策略网络和价值网络已经训练好, 并且用策略网络和价值网络辅助 MCTS。本节具体讲解如何训练两个神经网络。AlphaGo 有多个版本, 其中最著名的是 2016、2017 年发表在 Nature 期刊的两个版本, 本篇称之为 2016 版和 AlphaGo Zero 版。AlphaGo Zero 实力更强:DeepMind 做了实验, 让两个版本博弈 100 次, 比分是
3.1 AlphaGo 2016 版本的训练
AlphaGo 2016 版的训练分为三步:第一, 随机初始化策略网络
3.1.1 第一步:行为克隆
一开始的时候, 策略网络的参数都是随机初始化的。假如此时直接让两个策略网络自我博弈, 它们会做出纯随机的动作。它们得随机摸索很多很多次, 才能做出合理的动作。假如一上来就用 REINFORCE 学习策略网络, 最初随机摸索的过程要花很久。这就是为什么 AlphaGo 2016 版基于人类专家的知识初步训练一个策略网络。
有一个叫 KGS 的在线围棋游戏程序, 它在 2000 年的时候上线, 让玩家在线比赛。KGS 会把每一局游戏都记录下来。KGS 有 16 万局是六段以上的高级玩家的记录。每一局游戏有很多步, 每一步棋盘上的格局作为一个状态
AlphaGo 用行为克隆训练策略网络
是策略网络的输出, 设
可以用随机梯度下降 (SGD) 求解这个优化问题。每次随机从
此处的
KGS 中的 16 万局游戏都是六段以上的高手的博弈。行为克隆得到的策略网络模仿高手的动作, 可以做出比较合理的决策。它在实战中可以打败业余玩家, 但是打不过职业玩家。第
3.1.2 第二步:用 REINFORCE 训练策略网络
AlphaGo 让策略网络做自我博弈, 用胜负作为奖励, 更新策略网络。博弈的双方是两个策略网络, 一个叫做“玩家”,用最新的参数, 记作
让“玩家”和“对手”博弈, 将一局游戏进行到底, 假设走了
游戏结束的时候, 如果“玩家”赢了, 奖励是
如果“玩家”输了, 奖励是
所有
REINFORCE 是一种策略梯度方法, 它用观测到的回报
此处的
3.1.3 第三步:训练价值网络
价值网络
让训练好的策略网络做自我博弈, 记录状态一回报二元组
我们希望价值网络
回报的定义是
, 折扣率是 。
可以用随机梯度下降 (SGD) 求解这个回归问题。设当前价值网络参数为
此处的
3.2 AlphaGo Zero 版本的训练
AlphaGo Zero 与 2016 版本的最大区别在于训练策略网络
3.2.1 自我博弈
用 MCTS 控制两个玩家对弈。每走一步棋, MCTS 需要做成千上万次模拟, 并记录下每个动作被选中的次数
对这些
设这局游戏走了
用这些数据更新策略网络
3.2.2 更新策略网络
上一节讨论过, MCTS 做出的决策优于策略网络
尽量接近
设
此处的
3.2.3 更新价值网络
训练价值网络的方法与 AlphaGo 2016 版本基本一样,都是让
设价值网络
训练流程 : 随机初始化策略网络参数
- 让
自我博弈, 完成一局游戏, 收集到 个三元组: 。 - 按照公式 (2) 做一次梯度下降, 更新策略网络参数
。 - 按照公式 (3) 做一次梯度下降, 更新价值网络参数
。
4. 相关思考
4.1 为什么 AlphaGoZero 更好
蒙特卡洛搜索树为训练提供了稳定的梯度
策略网络和价值网络共享参数,使用 Multi-task 的方式学习,防止了过拟合
4.2 使用哪个模型来生成 self-play 数据?
在 AlphaGo Zero 版本中,我们需要同时保存当前最新的模型和通过评估得到的历史最优的模型,self-play 数据始终由最优模型生成,用于不断训练更新当前最新的模型,然后每隔一段时间评估当前最新模型和最优模型的优劣,决定是否更新历史最优模型。而到了 AlphaZero 版本中,这一过程得到简化,我们只保存当前最新模型,self-play 数据直接由当前最新模型生成,并用于训练更新自身。直观上我们可能会感觉使用当前最优模型生成的 self-play 数据可能质量更高,收敛更好,但是在尝试过两种方案之后,我们发现,在 6*6 棋盘上下 4 子棋这种情况下,直接使用最新模型生成 self-play 数据训练的话大约 500 局之后就能得到比较好的模型了,而不断维护最优模型并由最优模型生成 self-play 数据的话大约需要 1500 局之后才能达到类似的效果,这和 AlphaZero 论文中训练 34 小时的 AlphaZero 胜过训练 72 小时的 AlphaGo Zero 的结果也是吻合的。个人猜测,不断使用最新模型来生成 self-play 数据可能也是一个比较有效的 exploration 手段,首先当前最新模型相比于历史最优模型一般不会差很多,所以对局数据的质量其实也是比较有保证的,同时模型的不断变化使得我们能覆盖到更多典型的数据,从而加快收敛。
4.3 如何保证 self-play 生成的数据具有多样性?
一个有效的策略价值模型,需要在各种局面下都能比较准确的评估当前局面的优劣以及当前局面下各个 action 的相对优劣,要训练出这样的策略价值模型,就需要在 self-play 的过程中尽可能的覆盖到各种各样的局面。前面提到,不断使用最新的模型来生成 self-play 数据可能在一定程度上有助于覆盖到更多的局面,但仅靠这么一点模型的差异是不够的,所以在强化学习算法中,一般都会有特意设计的 exploration 的手段,这是至关重要的。在 AlphaGo Zero 论文中,每一个 self-play 对局的前 30 步,action 是根据正比于 MCTS 根节点处每个分支的访问次数的概率采样得到的,而之后的 exploration 则是通过直接加上 Dirichlet noise 的方式实现的。
4.4 self-play 数据的扩充
围棋具有旋转和镜像翻转等价的性质,其实五子棋也具有同样的性质。在 AlphaGo Zero 中,这一性质被充分的利用来扩充 self-play 数据,以及在 MCTS 评估叶子节点的时候提高局面评估的可靠性。但是在 AlphaZero 中,因为要同时考虑国际象棋和将棋这两种不满足旋转等价性质的棋类,所以对于围棋也没有利用这个性质。而在我们的实现中,因为生成 self-play 数据本身就是计算的瓶颈,为了能够在算力非常弱的情况下尽快的收集数据训练模型,每一局 self-play 结束后,我们会把这一局的数据进行旋转和镜像翻转,将 8 种等价情况的数据全部存入 self-play 的 data buffer 中。这种旋转和翻转的数据扩充在一定程度上也能提高 self-play 数据的多样性和均衡性。
4.5 训练好的 Alpha Zero 如何进行对弈?
评估器的落子过程即最终对弈时的落子过程(自对弈中的落子就是真实最终对局时的落子方式):使用神经网络的输出 p 作为先验概率进行 MCTS 搜索,每步 1600 次(最后应用的版本可能和每一步的给的时间有关)模拟,前 30 步采样落子,剩下棋局使用最多访问次数来落子,得到 π,然后选择落子策略中最大的一个位置落子。
5. 相关文献
早在很多年前,
AlphaGo 的论文首先发表在 Nature 2016
蒙特卡洛树搜索 (MCTS) 的名字最早在 2006 年发表的论文
6. 知识点
AlphaGo 2016 版本的训练分三步。首先做行为克隆, 用人类高手的棋谱训练策略网 络。然后让两个策略网络自我博弈, 用 REINFORCE 算法进一步训练策略网络。最 后做回归训练价值网络, 价值网络可以根据棋盘上的格局预估胜算。
新版的 AlphaGo Zero 用蒙特卡洛树搜索(MCTS)控制两个玩家博弈。每完成一 局, 对策略网络和价值网络做一次更新。用行为克隆训练策略网络, 模仿的对象是 MCTS 的决策。用回归训练价值网络, 让价值网络拟合胜负关系。
训练好策略网络和价值网络之后, AlphaGo 可以与人类高手对决。AlphaGo 使用 MCTS 做决策, MCTS 需要策略网络和价值网络的辅助。策略网络扮演模拟器中的 玩家和对手。价值网络的作用是给棋盘上的格局打分,从而估算动作的好坏。
MCTS 分四步:选择、扩展、求值、回溯。在模拟器中执行这四步, 可以计算出一个动作的一个分数。需要重复这四步成千上万次, 可以从动作的分数中看出动作的 好坏。实际执行最好的动作, 在棋盘上落一颗棋子。每在棋盘上落一颗子, 都需要 从头开始做 MCTS, 重复成千上万次模拟。
7. 习题
AlphaGo 用 MCTS 来判断动作的好坏。通过计算, MCTS 发现动作
的分数 很高, 这说明 A. 动作 好 B. 动作 不好 AlphaGo 中的价值网络
是对 的近似。 A. 动作价值函数 B. 最优动作价值函数 C. 状态价值函数 D. 最优状态价值函数