PagedAttention 原理详解
大语言模型推理服务的性能瓶颈往往在于内存。在自回归解码过程中,每个输入 Token 都会生成注意力机制中的 Key 与 Value 张量,这些张量被缓存在 GPU 内存中以生成后续 Token,统称为 KV Cache。PagedAttention 借鉴操作系统虚拟内存分页思想,高效管理 KV Cache,显著减少内存浪费。
1. KV Cache 的挑战
KV Cache 具备以下特点:
- 体积庞大:以 LLaMA-13B 为例,单个序列的 KV Cache 可占用高达 1.7 GB GPU 内存。
- 动态变化:其大小取决于序列长度,而序列长度具有高度可变性与不可预测性。
传统系统由于内存碎片与过度预留,导致 60%–80% 的内存浪费。
2. PagedAttention 的引入
在论文 Efficient Memory Management for Large Language Model Serving with PagedAttention 中,作者提出了 PagedAttention,一种受虚拟内存分页启发的算法。
操作系统通过分页管理物理内存页帧(Page Frame),在内存不足时换出暂不使用的页面。PagedAttention 将这一思想应用于 LLM 推理:
- 将连续的逻辑 KV 块映射到非连续的物理内存块。
- 每个块包含固定数量 Token 的 Key 与 Value。
- 通过块表(Block Table)维护逻辑块到物理块的映射。
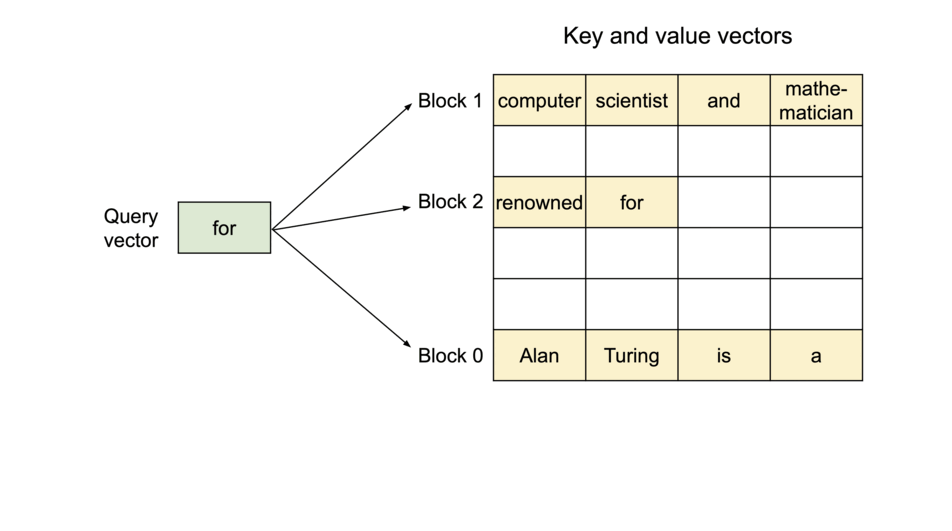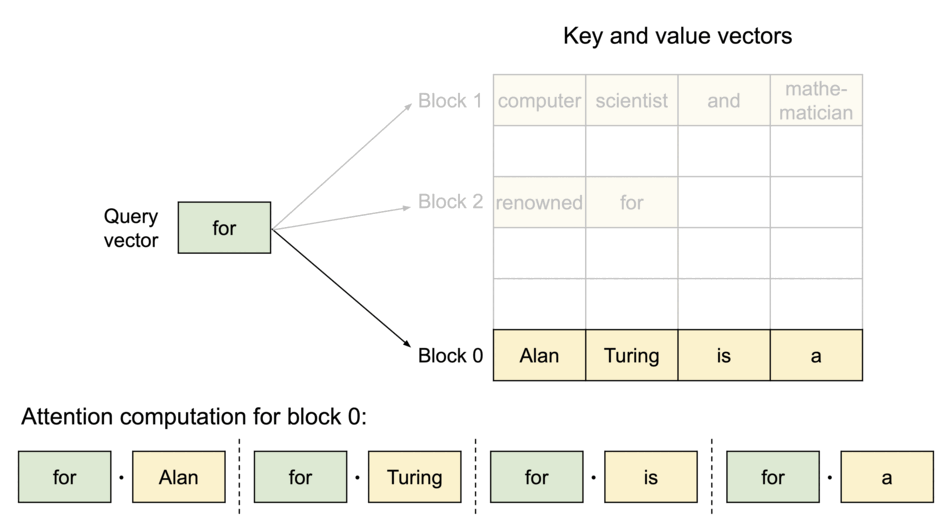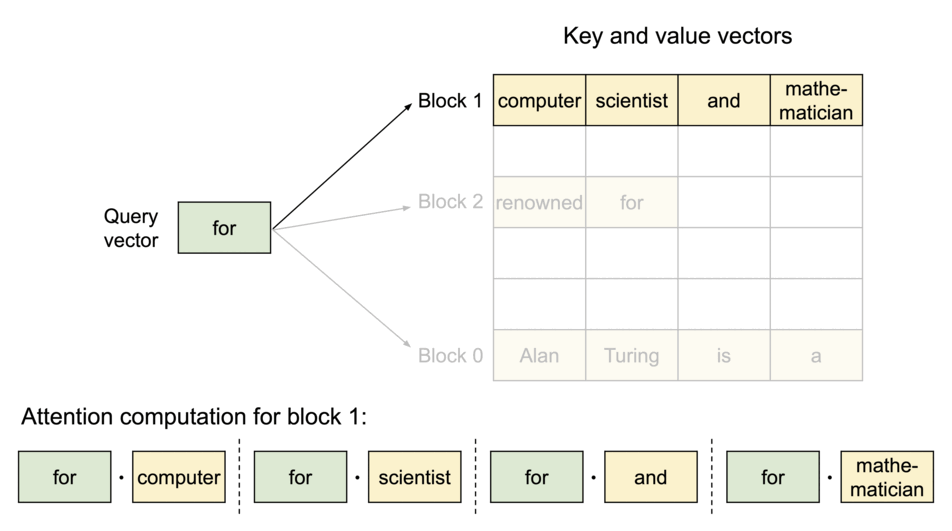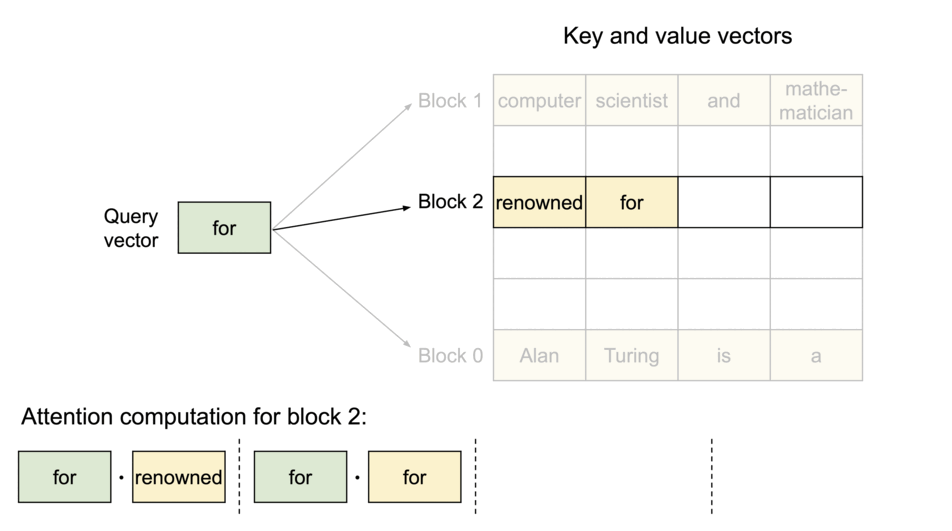
图示:PagedAttention 将 KV Cache 划分为多个块,块在物理内存中不要求连续。
通过类比:
- 块 ↔ 页面(page)
- Token ↔ 字节(byte)
- 序列 ↔ 进程(process)
序列的连续逻辑块通过 Block Table 映射到物理内存中的非连续块,并随新 Token 生成按需分配。
3. 内存浪费的消除
传统系统将 KV Cache 保存在连续内存空间中,为每个请求预分配固定完整区域。由于输入输出长度差异大,导致三类浪费:
- 内部碎片(Internal Fragmentation):预分配较大区域,最终未完全使用。
- 保留浪费(Reservation):为整个序列持续预留内存,即使部分未使用也无法共享。
- 外部碎片(External Fragmentation):块大小与请求长度不匹配,产生无法复用的“空隙”。
PagedAttention 允许将连续的 Key 与 Value 张量存储在非连续内存空间中,通过动态分配内存块:
- 消除外部碎片。
- 最大程度减少内部碎片:内存浪费只发生在序列的最后一个块。
据论文所述,传统实现中仅 20%–40% 的 KV Cache 被有效使用,而 vLLM 的 PagedAttention 将效率提升至接近 96%。
4. 高效的内存共享
PagedAttention 通过 Block Table 天然支持内存共享,类似于操作系统多个进程共享物理页面:
- 追踪每个物理块的引用计数。
- 实施写时复制(Copy-on-Write),在需要修改共享内容时自动创建副本。
以下解码策略均可受益:
4.1 并行采样(Parallel Sampling)
从同一输入生成多个输出样本时,vLLM 可共享输入 Prompt 阶段的计算与内存。
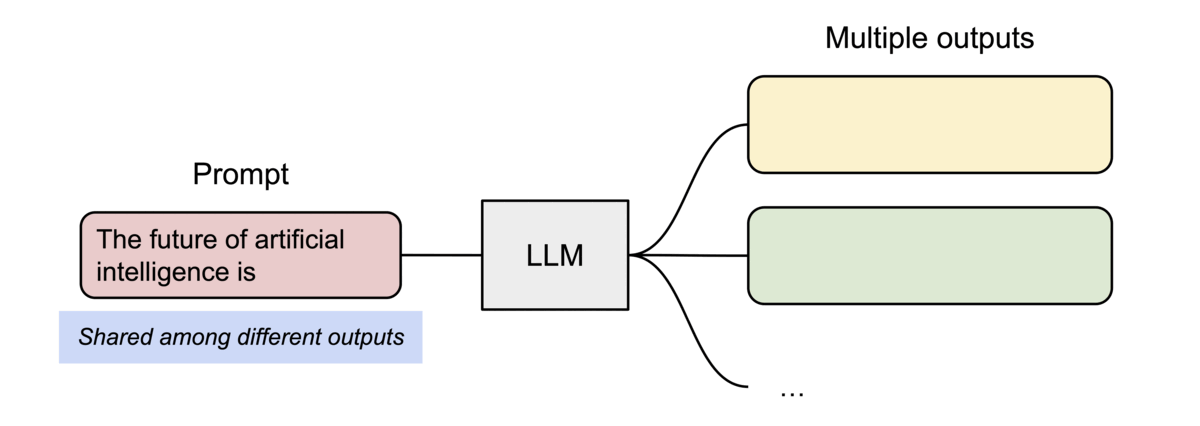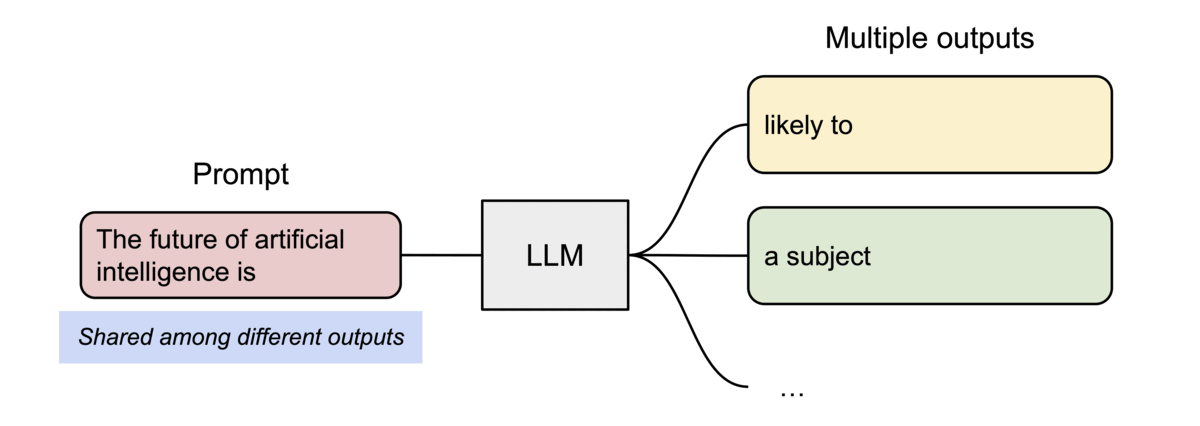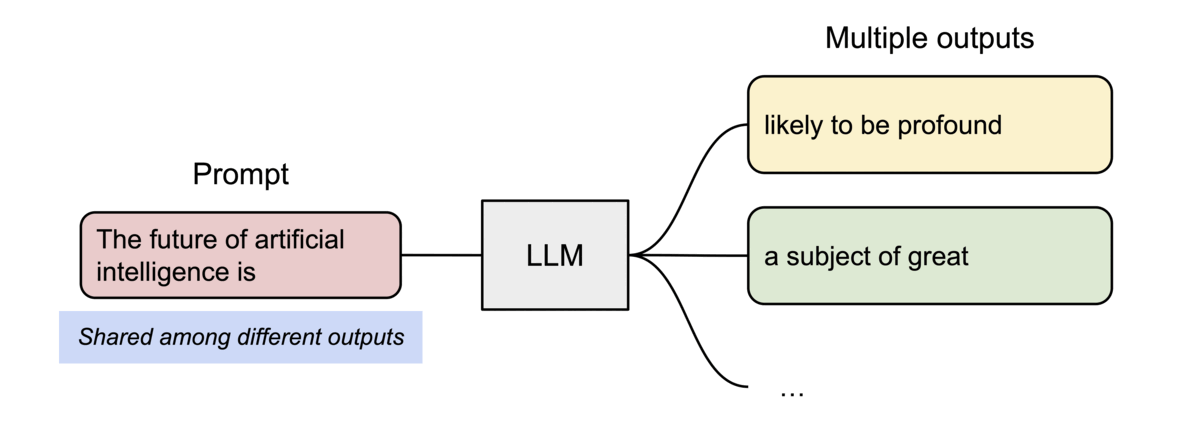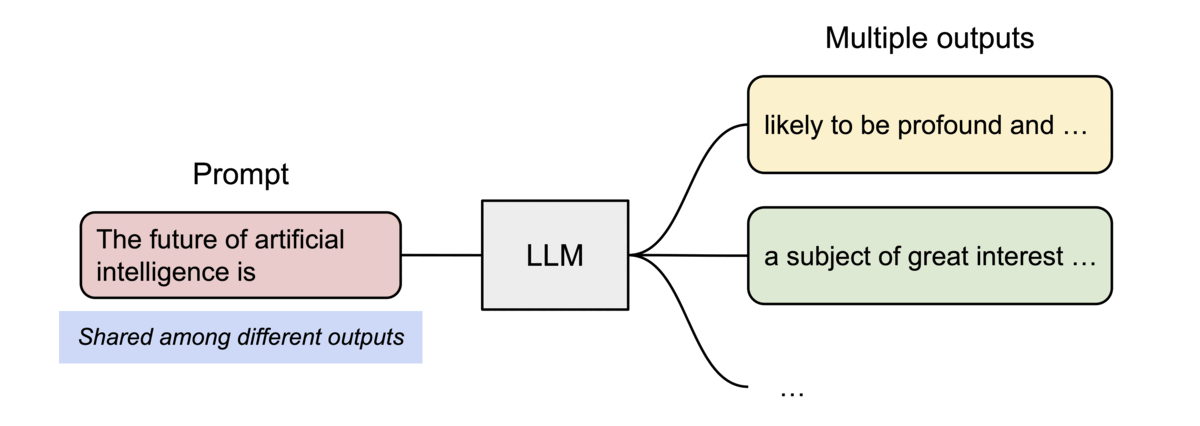
4.2 束搜索(Beam Search)
每步保留最可能的候选路径,vLLM 可在不同 Beam 分支间高效复用共享前缀。
4.3 共享前缀(Shared Prefix)
多个请求使用相同 System Prompt 时,vLLM 会预存并共享该前缀的 KV Cache。
4.4 混合解码策略
贪婪解码、Top-K 采样与束搜索等可并发使用,vLLM 灵活管理不同策略下的缓存共享。
5. 性能收益
PagedAttention 的内存共享机制大幅减少了复杂采样算法的内存开销。据测试结果:
- 并行采样与束搜索等方法内存使用最多可减少 55%。
- 吞吐量提升高达 2.2 倍。
总结
PagedAttention 是 vLLM 的核心技术,通过借鉴操作系统分页机制,将 KV Cache 管理从连续预分配转变为动态块分配,显著提升了内存利用率与推理吞吐量。它支持多种模型与解码策略,是高效 LLM 服务的关键基石。