基于分数的生成建模
本文翻译自 Yang Song (宋飏) 的博客: https://yang-song.net/blog/2021/score/
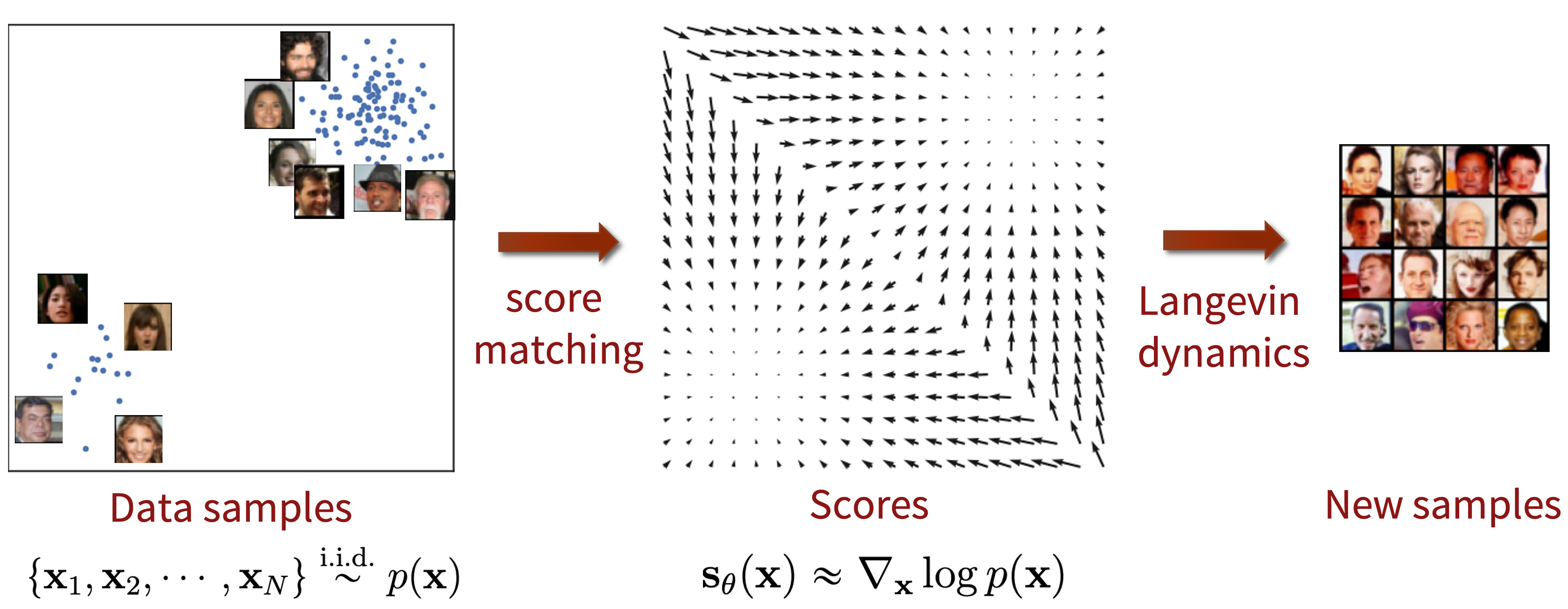
这篇博文重点介绍了一个很有前途的生成模型新方向。我们可以在大量噪声扰动的数据分布上学习得分函数(对数概率密度函数的梯度),然后使用 Langevin 采样生成样本。由此产生的生成模型,通常称为基于分数的生成模型,与现有模型相比具有几个重要优势:
- 无需对抗训练即可实现 GAN 水平的样本质量
- 灵活的模型架构
- 精确的对数似然计算
- 无需重新训练模型的逆向问题求解.
在这篇博文中,我们将更详细地向您展示基于分数的生成模型的直觉、基本概念和潜在应用。
介绍
现有的生成模型技术可以根据它们表示概率分布的方式大致分为两类。
- 基于似然的模型
通过(近似)最大似然直接学习分布的概率密度(或质量)函数。典型的基于似然的模型包括自回归模型[1, 2, 3], 归一化流模型[4, 5], 基于能量的模型 (EBM)[6, 7]和变分自编码器 (VAE)[8,9]。
- 隐式生成模型
其中概率分布由其采样过程的模型隐式表示。最突出的例子是生成对抗网络(GAN[11],其中通过使用神经网络变换随机高斯向量来合成来自数据分布的新样本。
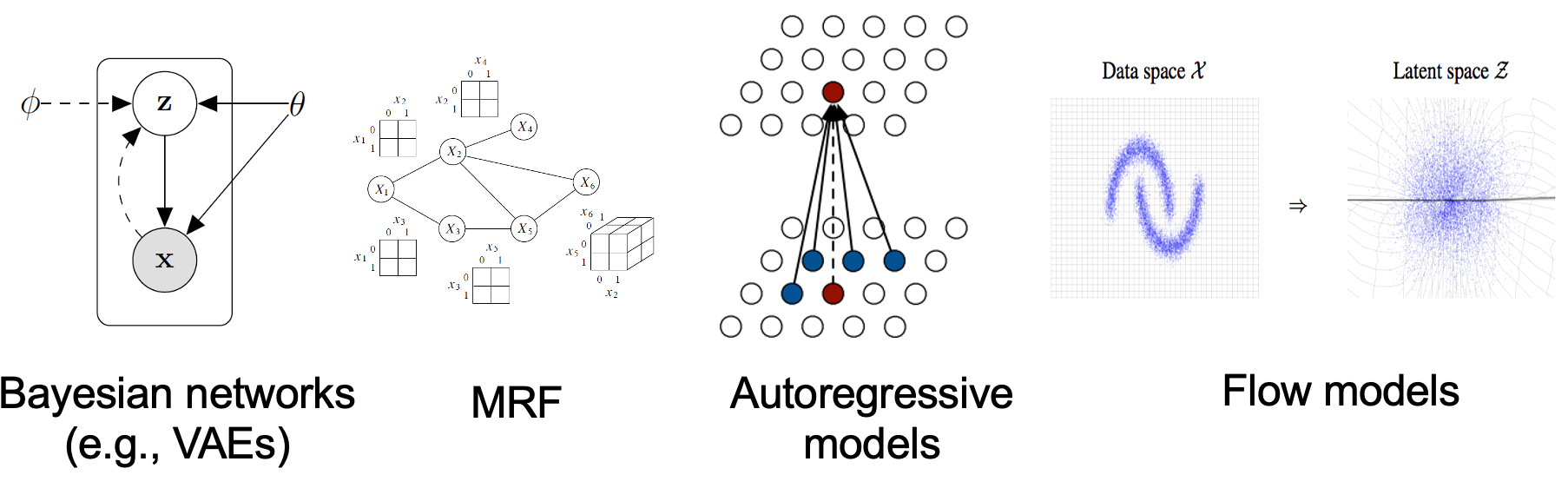
贝叶斯网络、马尔可夫随机场 (MRF)、自回归模型和归一化流模型都是基于似然模型的示例。所有这些模型都表示分布的概率密度或质量函数。
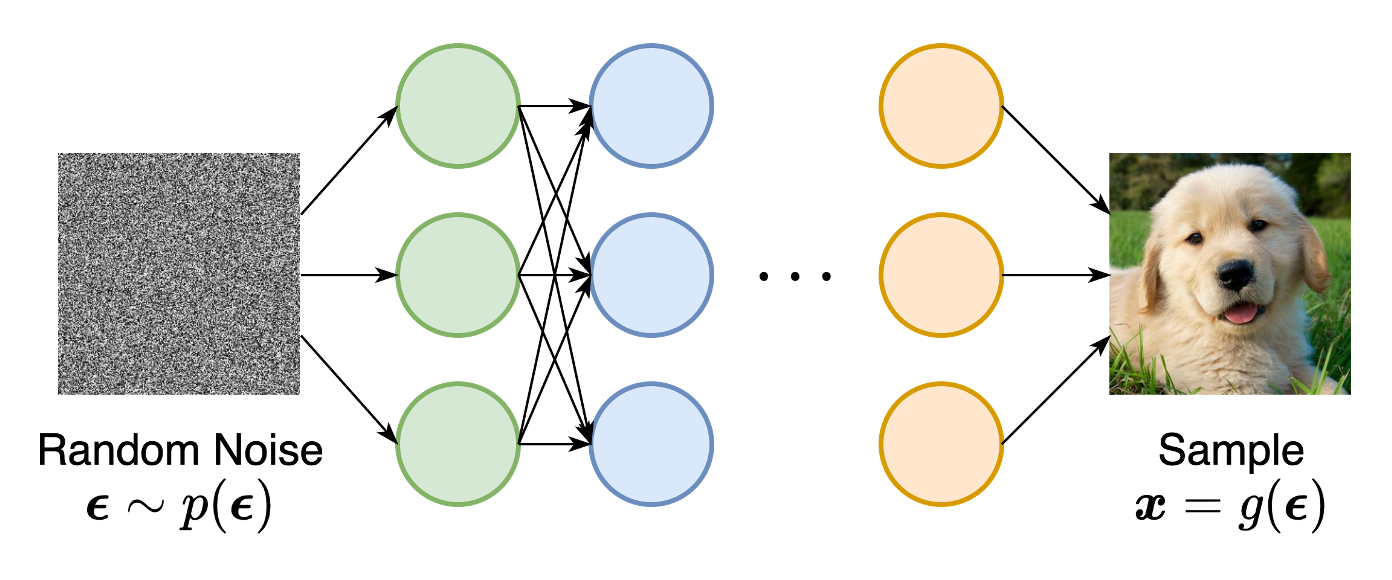
GAN 是隐式模型的一个例子。它隐式地表示了生成器网络可以生成的所有对象的分布。
然而,基于似然的模型和隐式生成模型都有很大的局限性。基于似然的模型要么需要对模型架构进行严格限制,以确保为似然计算提供易于处理的归一化常数,要么必须依赖代理目标函数来近似最大似然训练。另一方面,隐式生成模型通常需要对抗训练,这是出了名的不稳定[12],并可能导致模式崩塌[13]。
在这篇博文中,我将介绍另一种表示概率分布的方法,这种方法可以规避其中的一些限制。关键思想是对对数概率密度函数的梯度进行建模,该函数通常被称为 (Stein)得分函数 [14,15]. 这种基于分数的模型不需要具有易于处理的归一化常数,并且可以直接通过分数匹配来学习 [16, 17]。
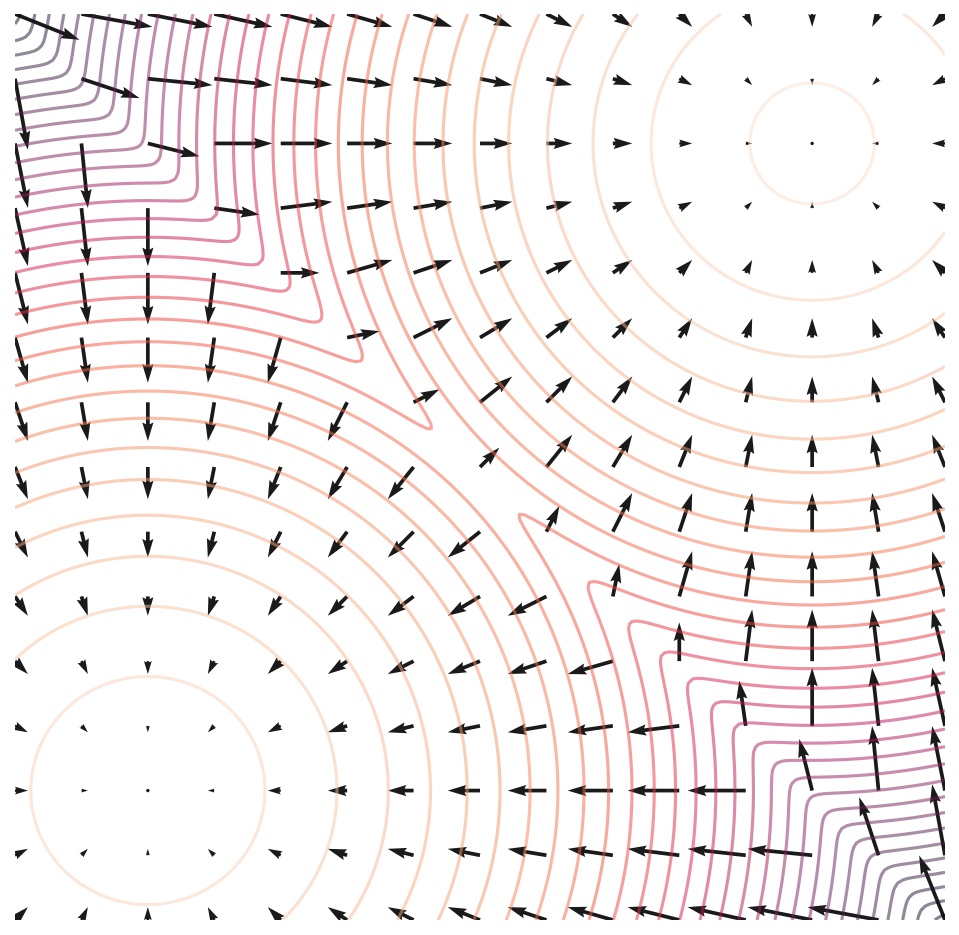
两个高斯混合的得分函数(向量场)和密度函数(等高线)。
基于分数的模型在许多下游任务和应用程序上取得了最好的性能。这些任务包括图像生成等[18, 19, 20, 21, 22,23](比 GAN 更好!),音频合成[24, 25,26], 形状生成[27], 和音乐合成[28]. 此外,基于分数的模型与规一化流模型有内在关联,允许精确的似然计算和表示学习。此外,建模和估计分数有助于[逆向问题](https://en.wikipedia.org/wiki/Inverse_problem#:~:text=An inverse problem in science,measurements of its gravity field)求解,应用场景包括图像修复[18, 21], 图像着色[21]、压缩传感和医学图像重建等(例如 CT、MRI)[29].

从基于分数的模型生成的 1024 x 1024 分辨率的样本[21]
这篇文章旨在向您展示基于分数的生成模型的动机和直觉,以及它的基本概念、属性和应用。
评分函数、基于评分的模型和评分匹配
假设我们有一个数据集${\mathbf{x}_1, \mathbf{x}_2, \cdots, \mathbf{x}N}$,其中每个点都是独立同分布的样本,从潜在的数据分布 $p{\text {data } }(\mathbf{x})$ 中采样得到 。给定这个数据集,生成模型的目标是用模型拟合数据分布,这样我们就可以通过从分布中随意采样来合成新的数据点。
为了构建这样的生成模型,我们首先需要一种表示概率分布的方法。与基于似然的模型一样,其中一种方法是直接对概率密度函数(pdf) 或概率质量函数(pmf) 建模。假设 $f_\theta(\mathbf{x}) \in \mathbb{R}$是由可学习参数 $\theta$ 参数化的实值函数. 我们可以通过下面的公式定义一个pdf : $$ \begin{align} p_\theta(\mathbf{x}) = \frac{e^{-f_\theta(\mathbf{x})} }{Z_\theta}, \end{align} $$ 其中$Z_\theta > 0$ 是依赖于$\theta$ 的归一化常数, $\int p_\theta(\mathbf{x}) \textrm{d} \mathbf{x} = 1 $. 这里的$f_\theta(\mathbf{x})$通常称为非标准化概率模型或基于能量的模型[7].
我们可以通过最大化数据的对数似然来训练 $p_\theta(\mathbf{x})$. $$ \begin{align} \max_\theta \sum_{i=1}^N \log p_\theta(\mathbf{x}i). \end{align} $$ 然而,等式(2)需要$p\theta(\mathbf{x})$为归一化概率密度函数。这是不可取的,因为为了计算$p_\theta(\mathbf{x})$,我们必须评估归一化常数$Z_\theta$, 对于任何一般 $f_\theta(\mathbf{x}) $ ,$Z_\theta$都是一个典型的难以处理的量. 因此,为了使最大似然训练可行,基于似然的模型必须限制它们的模型架构(例如,自回归模型中的因果卷积,归一化流模型中的可逆网络)以使$Z_\theta$易于处理,或近似归一化常数(例如,VAE 中的变分推理,或对比发散中使用的 MCMC 采样[29]) 这可能在计算上很昂贵。
通过对得分函数而不是密度函数进行建模,我们可以避开难以处理的归一化常数的困难。分布的得分函数$p(\mathbf{x})$定义为 $\nabla_\mathbf{x} \log p(\mathbf{x})$, 得分函数的模型称为基于分数的模型 [18],我们表示为 $\mathbf{s}\theta(\mathbf{x})$. 基于分数的模型是通过$\mathbf{s}\theta(\mathbf{x}) \approx \nabla_\mathbf{x} \log p(\mathbf{x})$ 学习的,并且模型可以参数化,不用担心归一化常数。例如,我们可以使用等式(1)中定义的基于能量的模型轻松地对基于分数的模型进行参数化, 通过 $$ \begin{equation} \mathbf{s}\theta (\mathbf{x}) = \nabla{\mathbf{x} } \log p_\theta (\mathbf{x} ) = -\nabla_{\mathbf{x} } f_\theta (\mathbf{x}) - \underbrace{\nabla_\mathbf{x} \log Z_\theta}{=0} = -\nabla\mathbf{x} f_\theta(\mathbf{x}). \end{equation} $$ 注意,基于分数的模型$\mathbf{s}\theta(\mathbf{x})$与归一化常数$Z\theta$无关!这显着扩展了我们可以轻松使用的模型系列,因为我们不需要任何特殊的架构来使标准化常数变得易于处理。
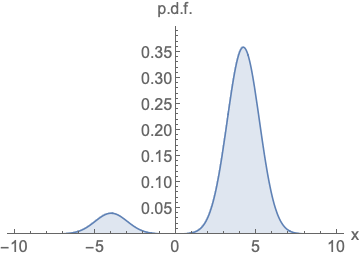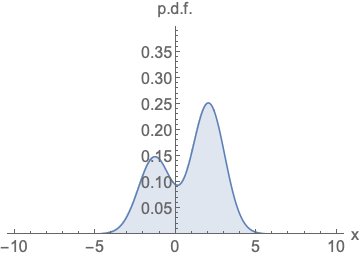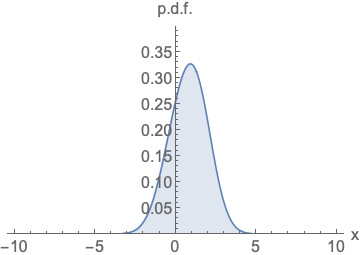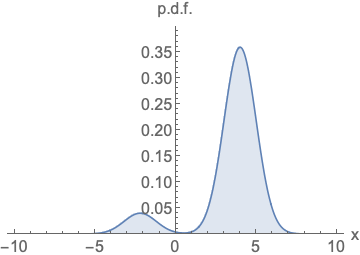
参数化概率密度函数。无论您如何更改模型族和参数,都必须对其进行归一化(曲线下面积必须积分为一)。
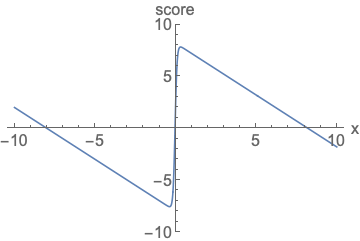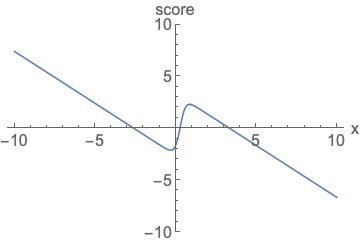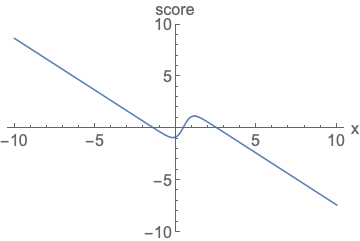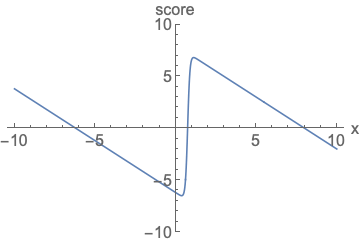
参数化评分函数。无需担心标准化。
与基于似然的模型类似,我们可以通过最小化模型和数据分布之间的 Fisher 散度来训练基于分数的模型, 定义为: $$ \begin{equation} \mathbb{E}{p(\mathbf{x})}[| \nabla\mathbf{x} \log p(\mathbf{x}) - \mathbf{s}_\theta(\mathbf{x}) |2^2] \end{equation} $$ 直观地来看, Fisher 散度比较了Groud Truth 与基于分数的模型之间的 $\ell_2$ 距离。然而,直接计算这种差异是不可行的,因为它需要访问未知的数据分数 $\nabla\mathbf{x} \log p(\mathbf{x})$. 幸运的是,存在一系列称为分数匹配的方法 [ 16, 17,31], 可以在不知道真实数据得分的情况下最小化 Fisher 散度。得分匹配目标可以直接在数据集上估计并使用随机梯度下降进行优化,类似于训练基于似然的模型(具有已知归一化常数)的对数似然目标。我们可以通过最小化分数匹配目标来训练基于分数的模型,而不需要对抗优化。
此外,使用分数匹配目标为我们提供了相当大的建模灵活性。Fisher 散度本身不需要$\mathbf{s}\theta(\mathbf{x})$是一个真实的归一化分布的实际得分函数——它只是比较 Groud Truth 数据与基于分数的模型之间的$\ell_2$距离,没有对$\mathbf{s}\theta(\mathbf{x})$形式的额外假设. 事实上,对基于分数的模型的唯一要求是它应该是具有相同输入和输出维度的向量值函数,这在实践中很容易满足。
简而言之,我们可以通过对评分函数建模来表示分布,这可以通过训练使用得分匹配为目标的得分函数模型来估计。
Langevin dynamics
一旦我们训练了基于分数的模型 $\mathbf{s}\theta(\mathbf{x}) \approx \nabla\mathbf{x} \log p(\mathbf{x})$,我们可以使用称为Langevin 动力学[32, 33]的迭代过程从中抽取样本。
Langevin dynamics 提供了一个 MCMC 程序,只使用它的评分函数$\nabla_\mathbf{x} \log p(\mathbf{x})$来从分布$p(\mathbf{x})$中采样. 具体来说,它先通过任意先验分布$\mathbf{x}0 \sim \pi(\mathbf{x})$ 初始化链,然后迭代如下 $$ \begin{align} \mathbf{x} \gets \mathbf{x}i + \epsilon \nabla\mathbf{x} \log p(\mathbf{x}) + \sqrt{2\epsilon}~ \mathbf{z}_i, \quad i=0,1,\cdots, K, \end{align} $$ 其中 $\mathbf{z}_i \sim \mathcal{N}(0, I)$. 当 $\epsilon \to 0$ 和 $K \to \infty$ 时, $\mathbf{x}_K$ 在一定的规律性条件下, 从程序中获得收敛到来自 $p(\mathbf{x})$ 的样本. 在实践中,当 $\epsilon $ 足够小并且 $K$ 足够大时,误差可以忽略不计。

使用 Langevin 动力学从两个高斯分布的混合中采样。
请注意,Langevin 动力学只通过$\nabla_\mathbf{x} \log p(\mathbf{x})$访问$p(\mathbf{x})$. 因为$\mathbf{s}\theta(\mathbf{x}) \approx \nabla\mathbf{x} \log p(\mathbf{x})$,我们可以通过将其代入方程式(5),从基于分数的模型中生成样本$\mathbf{s}_\theta(\mathbf{x})$.
基于分数的朴素生成模型及其陷阱
到目前为止,我们已经讨论了如何使用分数匹配训练基于分数的模型,然后通过 Langevin 动力学生成样本。然而,这种幼稚的方法在实践中取得的成功有限——我们将讨论一些在之前的工作中很少受到关注的分数匹配陷阱[18].
基于分数的生成模型,具有分数匹配 + Langevin 动力学。
关键的挑战是估计的分数函数在低密度区域不准确,其中可用于计算分数匹配目标的数据点很少。这是可预期的,因为分数匹配最小化了 Fisher 散度 $$ \mathbb{E}{p(\mathbf{x})}[| \nabla\mathbf{x} \log p(\mathbf{x}) - \mathbf{s}\theta(\mathbf{x}) |2^2] = \int p(\mathbf{x}) | \nabla\mathbf{x} \log p(\mathbf{x}) - \mathbf{s}\theta(\mathbf{x}) |_2^2 \mathrm{d}\mathbf{x}. $$ 因为真实数据和和基于评分的模型之间的 $\ell_2$ 差异通过 $p(\mathbf{x})$ 加权,当$p(\mathbf{x})$很小的时候,它们在低密度区域中很大程度上被忽略了。这种行为可能导致结果不佳,如下图所示:
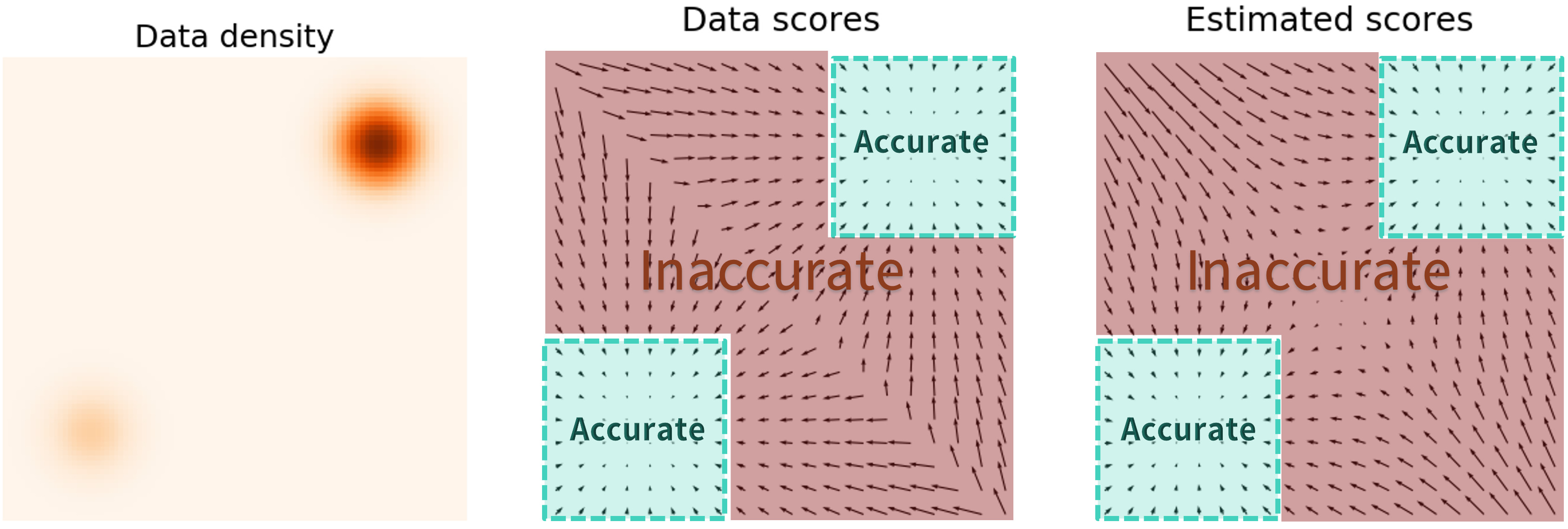
估计分数仅在高密度区域是准确的。
当使用 Langevin 动力学进行采样时,当数据位于高维空间时,我们的初始样本很可能位于低密度区域。因此,不准确的基于分数的模型将从程序的一开始就破坏 Langevin 动力学,阻止它生成可以代表数据的高质量样本。
具有多种噪声扰动的基于分数的生成模型
如何绕过在低数据密度区域进行准确分数估计的困难?我们的求解方案是用噪声扰乱数据点,然后在噪声数据点上训练基于分数的模型。当噪声幅度足够大时,它可以填充低数据密度区域以提高分数估计的准确性。例如,当我们扰动两个受额外高斯噪声扰动的高斯混合体时,会发生以下情况。

由于低数据密度区域的减少,对于受噪声扰动的数据分布,估计分数在任何地方都是准确的。
但是另一个问题仍然存在:我们如何为扰动过程选择合适的噪声尺度?较大的噪声显然可以覆盖更多的低密度区域以获得更好的分数估计,但它会过度破坏数据并显著改变原始分布。另一方面,较小的噪声会导致原始数据分布的损坏较少,但不会像我们希望的那样覆盖低密度区域。
为了实现两全其美,我们同时使用多个尺度的噪声进行扰动[18,19]. 假设我们总是用各向同性高斯噪声扰动数据,总共有$L$个逐渐增加标准偏差 $\sigma_1 < \sigma_2 < \cdots < \sigma_L$. 第一步, 我们以高斯噪声 $\mathcal{N}(0, \sigma_i^2 I), i=1,2,\cdots,L $ 扰乱数据分布 $p(\mathbf{x})$ 以获得噪声扰动分布 $$ p_{\sigma_i}(\mathbf{x}) = \int p(\mathbf{y}) \mathcal{N}(\mathbf{x}; \mathbf{y}, \sigma_i^2 I) \mathrm{d} \mathbf{y}. $$ 注意,我们可以通过$\mathbf{x} \sim p(\mathbf{x})$轻松地从$p_{\sigma_i}(\mathbf{x})$中通过抽取样本, 并根据$\mathbf{z} \sim \mathcal{N}(0, I)$ 计算 $\mathbf{x} + \sigma_i \mathbf{z}$.
接下来,我们通过训练一个基于条件噪声分数的模型(也称为噪声条件评分网络,或 NCSN[17, 18, 20],当用神经网络参数化时)估计每个噪声扰动分布的得分函数,$\nabla_\mathbf{x} \log p_{\sigma_i}(\mathbf{x})$ 与分数匹配,使得对所有$i= 1, 2, \cdots, L$, 有 $\mathbf{s}\theta(\mathbf{x}, i) \approx \nabla\mathbf{x} \log p_{\sigma_i}(\mathbf{x})$ .
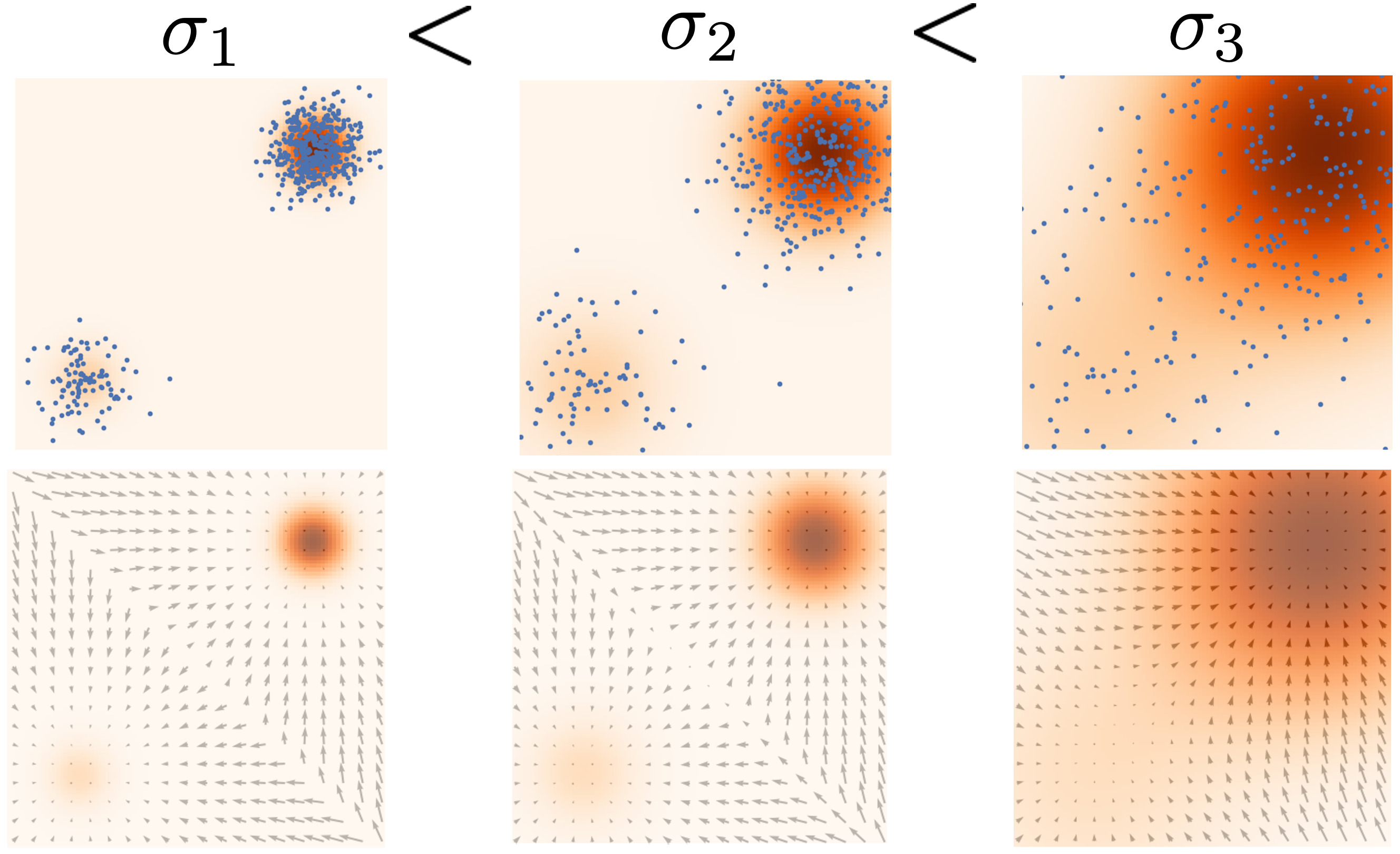
我们应用多尺度高斯噪声来扰乱数据分布(第一行),并联合估计所有数据的得分函数(第二行)。

使用多尺度高斯噪声扰动图像。
训练目标为 $\mathbf{s}\theta(\mathbf{x}, i)$ 是所有噪声尺度的 Fisher 散度的加权和。特别是,我们使用以下目标: $$ \sum^L \lambda(i) \mathbb{E}{p{\sigma_i}(\mathbf{x})}[| \nabla_\mathbf{x} \log p_{\sigma_i}(\mathbf{x}) - \mathbf{s}\theta(\mathbf{x}, i) |2^2] $$ 其中 $\lambda(i) \in \mathbb{R}$是一个正的加权函数,通常选择 $\lambda(i) = \sigma_i^2$. 目标(8)可以通过分数匹配进行优化,就像优化朴素(无条件)的基于分数的模型$\mathbf{s}\theta(\mathbf{x})$一样 。
在训练我们的基于噪声条件分数的模型$\mathbf{s}_\theta(\mathbf{x}, i)$之后,我们可以通过运行 Langevin 动力学按顺序$i = L, L-1, \cdots, 1$ 从中产生样本。这种方法称为退火 Langevin 动力学, 因为噪声尺度$\sigma_i$随着时间的推移逐渐减少(退火)。
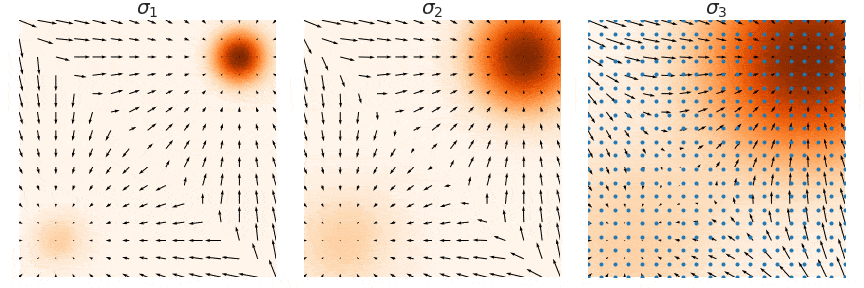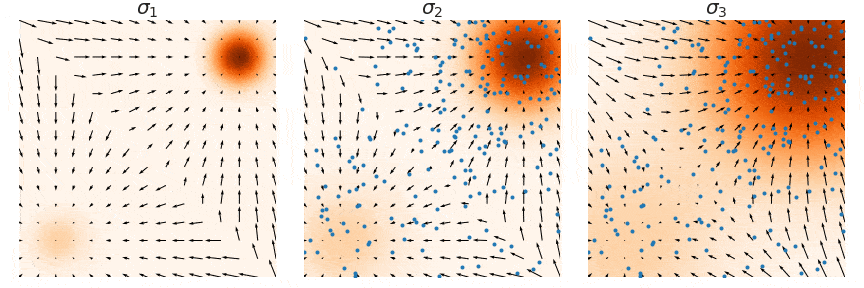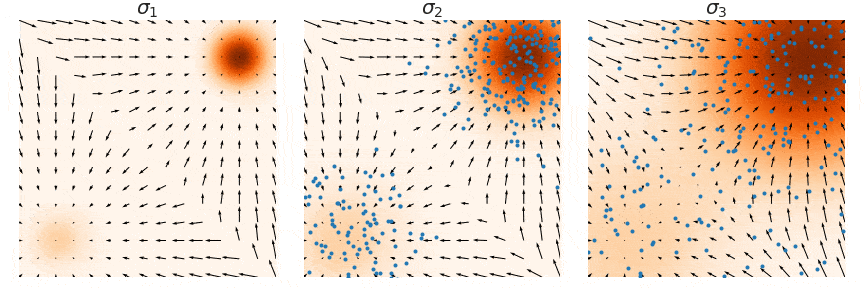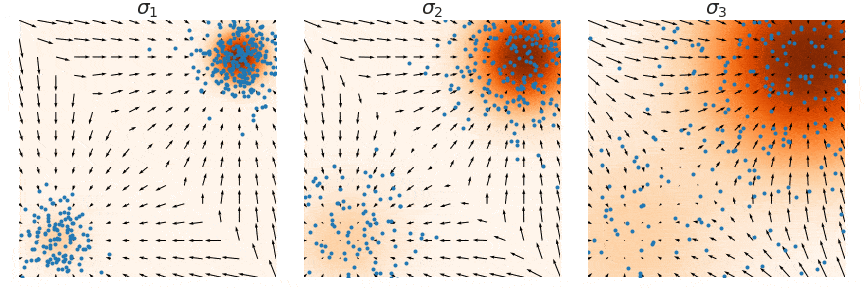
退火 Langevin 动力学将一系列 Langevin 链与逐渐降低的噪声尺度结合起来。


噪声条件评分网络 (NCSN) 模型的退火 Langevin 动力学(来自参考文献。[18]) 在 CelebA(左)和 CIFAR-10(右)上训练。我们可以从非结构化噪声开始,根据分数修改图像,生成好的样本。该方法在当时的 CIFAR-10 上取得了最好的 Inception 分数。
以下是调整具有多个噪声尺度的基于分数的生成模型的一些实用建议:
- 选择$\sigma_1 < \sigma_2 < \cdots < \sigma_L$作为[几何级数](https://en.wikipedia.org/wiki/Geometric_progression#:~:text=In mathematics%2C a geometric progression,number called the common ratio.),$\sigma_1$足够小并且 $\sigma_L$与所有训练数据点之间的最大成对距离相当[19]. $L$通常是数百或数千的数量级。
- 使用 U-Net 跳连[17, 19],参数化基于分数的模型$\mathbf{s}_\theta(\mathbf{x}, i)$.
- 在测试时,对基于分数的模型的权重应用指数移动平均[18, 19].
有了这样的最佳实践,我们能够在各种数据集上生成与 GAN 质量相当的高质量图像样本,如下所示:

Samples from the NCSNv2[18]model. From left to right: FFHQ 256x256, LSUN bedroom 128x128, LSUN tower 128x128, LSUN church_outdoor 96x96, and CelebA 64x64.
使用随机微分方程 (SDE) 的基于分数的生成模型
正如我们已经讨论过的,添加多个噪声尺度对于基于分数的生成模型的成功至关重要。通过将噪声尺度的数量推广到无穷大[21],我们不仅获得了更高质量的样本,而且还获得了精确的对数似然计算和用于逆问题求解的可控生成。
除了本文介绍之外,我们还有用Google Colab编写的教程,以提供在 MNIST 上训练Demo模型的指南。我们还有更高级的代码库,可为大型应用程序提供成熟的实现。
| Link | Description |
|---|---|
| Tutorial of score-based generative modeling with SDEs in JAX + FLAX | |
| Load our pretrained checkpoints and play with sampling, likelihood computation, and controllable synthesis (JAX + FLAX) | |
| Tutorial of score-based generative modeling with SDEs in PyTorch | |
| Load our pretrained checkpoints and play with sampling, likelihood computation, and controllable synthesis (PyTorch) | |
| Code in JAX | Score SDE codebase in JAX + FLAX |
| Code in PyTorch | Score SDE codebase in PyTorch |
使用 SDE 扰动数据
当噪声尺度的数量接近无穷大时,我们基本上会随着噪声水平的不断增加而扰乱数据分布。在这种情况下,噪声扰动过程是一个连续时间[随机过程](https://en.wikipedia.org/wiki/Stochastic_process#:~:text=A stochastic process is defined,measurable with respect to some),如下所示
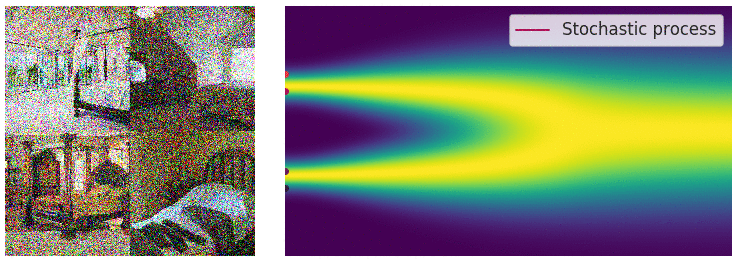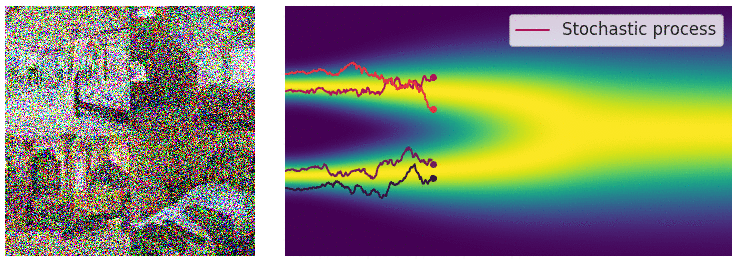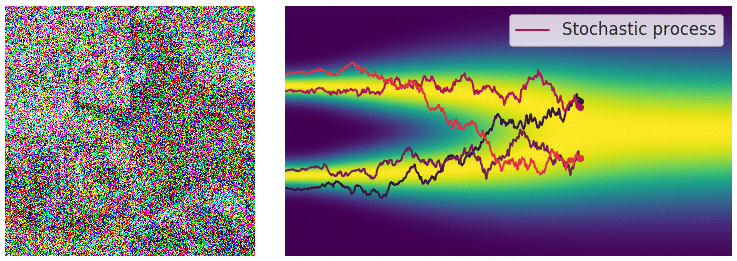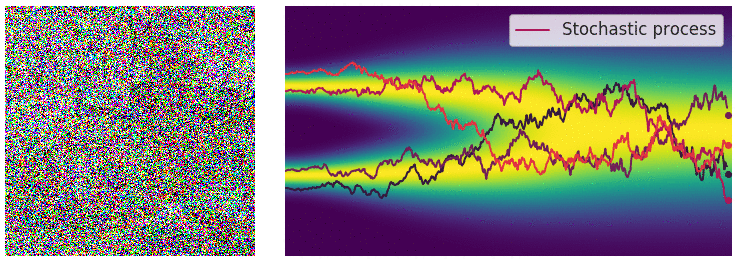
使用连续时间随机过程将数据扰动为噪声。
我们如何以简洁的方式表示随机过程?许多随机过程(尤其是扩散过程)都是随机微分方程 (SDE) 的解。通常,SDE 具有以下形式: $$ \begin{align} \mathrm{d}\mathbf{x} = \mathbf{f}(\mathbf{x}, t) \mathrm{d}t + g(t) \mathrm{d} \mathbf{w}, \end{align} $$ 其中 $\mathbf{f}(\cdot, t): \mathbb{R}^d \to \mathbb{R}^d $是称为漂移系数的向量值函数,$g(t)\in \mathbb{R}$是称为扩散系数的实值函数,$w$ 表示标准布朗运动,并且$\mathrm{d} \mathbf{w}$可以看作无穷小的白噪声。随机微分方程的解是随机变量的连续集合${ \mathbf{x}(t) }_{t\in [0, T]}$. 这些随机变量跟踪随机轨迹作为时间索引$t$从开始时间 $0$开始增长到$T$.
让 $p_t(\mathbf{x})$表示$\mathbf{x}(t)$的(边际)概率密度函数. 这里 $t \in [0, T] $ 类似 $i = 1, 2, \cdots, L$ 当我们有有限数量的噪声尺度时,并且$p_t(\mathbf{x})$类似于$p_{\sigma_i}(\mathbf{x})$ . 清楚地是,$p_0(\mathbf{x}) = p(\mathbf{x})$ 是一个数据分布,因为在 $t=0$ 没有对数据应用扰动. 在的通过随机过程扰动 $p(\mathbf{x})$足够长的时间$T$, $p_T(\mathbf{x})$ 接近易处理的噪声分布 $\pi(\mathbf{x})$, 称为先验分布。我们注意到在有限噪声尺度的情况下, $p_T(\mathbf{x})$类似于$p_{\sigma_L}(\mathbf{x})$,对应于应用最大的噪声 $ \sigma_L$扰动数据。
SDE是手工设计的,类似于在有限噪声尺度的情况下,我们手工设计的$\sigma_1 < \sigma_2 < \cdots < \sigma_L$。添加噪声扰动的方法有很多种,SDE 的选择也不是唯一的。比如下面的SDE $$ \begin{align} \mathrm{d}\mathbf{x} = e^{t} \mathrm{d} \mathbf{w} \end{align} $$ 用均值为零且方差呈指数增长的高斯噪声扰动数据,这类似于通过$\mathcal{N}(0, \sigma_1^2 I), \mathcal{N}(0, \sigma_2^2 I), \cdots, \mathcal{N}(0, \sigma_L^2 I)$⋯ $\sigma_1 < \sigma_2 < \cdots < \sigma_L$是一个[几何级数](https://en.wikipedia.org/wiki/Geometric_progression#:~:text=In mathematics%2C a geometric progression,number called the common ratio.) 来扰动数据 。因此SDE 应该被视为模型的一部分,就像${\sigma_1, \sigma_2, \cdots, \sigma_L}$. 在[21],我们提供了三种通常适用于图像的 SDE:方差爆炸 SDE (VE SDE)、方差保持 SDE (VP SDE) 和 sub- VP SDE。
反转 SDE 以生成样本
回想一下,在有限数量的噪声尺度下,我们可以通过使用退火 Langevin 动力学反转扰动过程来生成样本,即,使用 Langevin 动力学从每个噪声扰动分布中顺序采样。对于无限噪声尺度,我们可以通过使用反向 SDE 类似地反转样本生成的扰动过程。
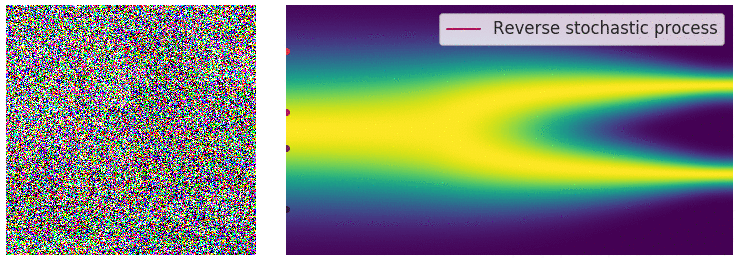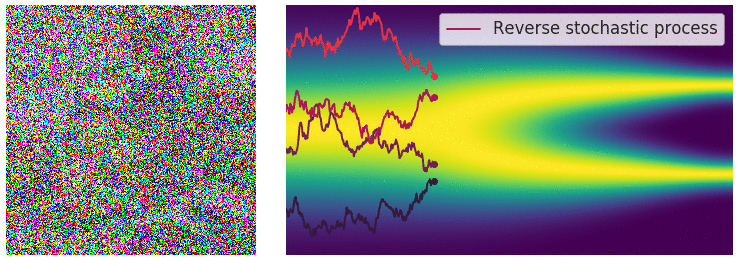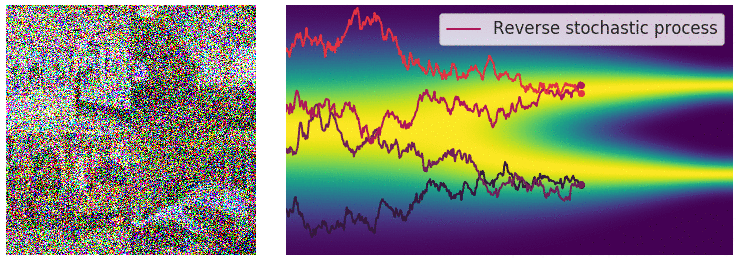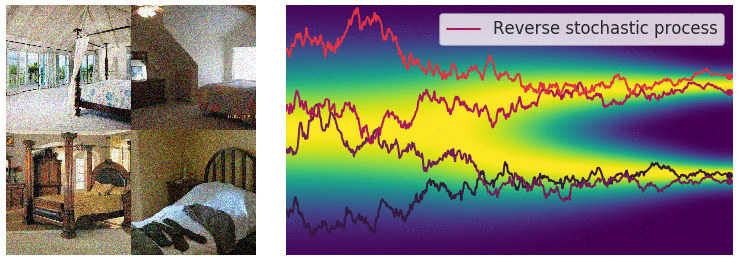
通过反转扰动过程从噪声中生成数据。
重要的是,任何 SDE 都有相应的反向 SDE[35], 其闭合形式为 $$ \begin{equation} \mathrm{d}\mathbf{x} = [\mathbf{f}(\mathbf{x}, t) - g^2(t) \nabla_\mathbf{x} \log p_t(\mathbf{x})]\mathrm{d}t + g(t) \mathrm{d} \mathbf{w}.\end{equation} $$ 这里$\mathrm{d} t$表示负无穷小时间步,因为 SDE(10)需要反向运算(从$t=T$到$t=0$). 为了计算反向 SDE,我们需要估计$\nabla_\mathbf{x} \log p(\mathbf{x})$, 这正是 $p_t(\mathbf{x})$的得分函数.

求解反向 SDE 会产生一个基于分数的生成模型。可以使用 SDE 将数据转换为简单的噪声分布。如果我们知道每个中间时间步的分布得分,则可以反过来从噪声中生成样本。
使用基于分数的模型和分数匹配估计反向 SDE
求解反向SDE需要我们知道最终分布$p_T(\mathbf{x})$, 和得分函数$\nabla_\mathbf{x} \log p_t(\mathbf{x})$. 通过设计,前者接近于先验分布$\pi(\mathbf{x})$这是很容易处理的。为了估计$\nabla_\mathbf{x} \log p_t(\mathbf{x})$,我们训练一个基于时间依赖分数的模型 $\mathbf{s}\theta(\mathbf{x}, t)$,使得$\mathbf{s}\theta(\mathbf{x}, t)$≈$ \nabla_\mathbf{x} \log p_t(\mathbf{x})$. 这类似于基于噪声条件分数的模型$\mathbf{s}\theta(\mathbf{x}, i)$,用于有限噪声尺度, 经过训练使得 $\mathbf{s}\theta(\mathbf{x}, i)$≈$\nabla_\mathbf{x} \log p_{\sigma_i}(\mathbf{x})$
我们的训练目标是: $\mathbf{s}\theta(\mathbf{x}, t)$ 是 Fisher 散度的连续加权组合,由下式给出 $$ \begin{equation} \mathbb{E}{t \in \mathcal{U}(0, T)}\mathbb{E}{p_t(\mathbf{x})}[\lambda(t) | \nabla\mathbf{x} \log p_t(\mathbf{x}) - \mathbf{s}\theta(\mathbf{x}, t) |2^2], \end{equation} $$ 其中$\mathcal{U}(0, T)$表示时间间隔内的均匀分布$[0, T]$,和$\lambda: \mathbb{R} \to \mathbb{R}$是正加权函数。通常我们使用$\lambda(t) \propto 1/ \mathbb{E}[| \nabla{\mathbf{x}(t)} \log p(\mathbf{x}(t) \mid \mathbf{x}(0))|2^2]$ 来平衡不同分数匹配损失随时间的大小。和以前一样,我们的 Fisher 散度的加权组合可以通过分数匹配方法有效优化,例如去噪分数匹配[16]和切片得分匹配[30]. 一旦我们基于分数的模型$\mathbf{s}\theta(\mathbf{x}, t)$被训练到最优,我们可以将它插入到反向 SDE 的表达式中(11)获得估计的反向 SDE。 $$ \begin{equation} \mathrm{d}\mathbf{x} = [\mathbf{f}(\mathbf{x}, t) - g^2(t) \mathbf{s}\theta(\mathbf{x}, t)]\mathrm{d}t + g(t) \mathrm{d} \mathbf{w}. \end{equation} $$ 我们可以从$\mathbf{x}(T) \sim \pi$ 开始,求解上述反向SDE得到样本$\mathbf{x}(0)$. 让我们表示用$p\theta$表示$\mathbf{x}(0)$的分布. 当基于分数的模型$\mathbf{s}\theta(\mathbf{x}, t)$训练完,我们有$p\theta \approx p_0$, 在这种情况下$\mathbf{x}(0)$是数据分布的$p_0$近似采样
当$\lambda(t) = g^2(t)$,在 Fisher 散度的加权组合与 KL 散度之间有重要联系, $p_0$到$p_\theta$在某些正则条件下[36],有: $$ \operatorname{KL}(p_0(\mathbf{x})|p_\theta(\mathbf{x})) \leq \frac{T}{2}\mathbb{E}{t \in \mathcal{U}(0, T)}\mathbb{E}{p_t(\mathbf{x})}[\lambda(t) | \nabla_\mathbf{x} \log p_t(\mathbf{x}) - \mathbf{s}_\theta(\mathbf{x}, t) |_2^2] + \operatorname{KL}(p_T \mathrel| \pi). $$ 由于与 KL 散度的这种特殊联系以及模型训练的最小化 KL 散度和最大化似然之间的等价性,我们称$\lambda(t) = g(t)^2$ 为似然加权函数。使用这种似然加权函数,我们可以训练基于分数的生成模型来实现非常高的似然,与最好的自回归模型相当甚至更优[35].
如何解决反向SDE
通过用数值 SDE 求解器求解估计的反向 SDE,我们可以模拟样本生成的反向随机过程。也许最简单的数值 SDE 求解器是Euler-Maruyama 方法。当应用于我们估计的反向 SDE 时,它使用有限的步长和小的高斯噪声对 SDE 进行离散化。具体来说,它选择一个小的负时间步长$\Delta t \approx 0$, 初始化$t \gets T$, 并重复以下过程直到$t \approx 0$: $$ \begin{aligned} \Delta \mathbf{x} &\gets [\mathbf{f}(\mathbf{x}, t) - g^2(t) \mathbf{s}_\theta(\mathbf{x}, t)]\Delta t + g(t) \sqrt{\vert \Delta t\vert }\mathbf{z}_t \ \mathbf{x} &\gets \mathbf{x} + \Delta \mathbf{x}\ t &\gets t + \Delta t, \end{aligned} $$ 这里$\mathbf{z}_t \sim \mathcal{N}(0, I)$. Euler-Maruyama 方法在性质上类似于 Langevin 动力学—两者都通过使用被高斯噪声扰动的得分函数更新$\mathbf{x}$。
除了 Euler-Maruyama 方法外,其他数值 SDE 求解器可以直接用于求解反向 SDE 以生成样本,例如包括Milstein 方法和随机 Runge-Kutta 方法。在[20],我们提供了一个类似于 Euler-Maruyama 的反向扩散求解器,但更适合求解逆向SDE。最近,作者在[36]引入了自适应步长 SDE 求解器,可以更快地生成质量更好的样本。
此外,我们的反向 SDE 有两个特殊属性,允许更灵活的采样方法:
- 我们通过我们基于时间的分数模型$\mathbf{s}\theta(\mathbf{x}, t)$估计$\nabla\mathbf{x} \log p_t(\mathbf{x}))$.
- 我们只关心从每个边际分布中抽样$p_t(\mathbf{x})$. 在不同时间步长获得的样本可以具有任意相关性,并且不必形成从反向 SDE 采样的特定轨迹。
由于这两个属性,我们可以应用 MCMC 方法来微调从数值 SDE 求解器获得的轨迹。具体来说,我们提出了 Predictor-Corrector samplers。预测器可以是任何数值 SDE 求解器, 从来自现有样本分布$\mathbf{x}(t) \sim p_t(\mathbf{x})$预测$\mathbf{x}(t + \Delta t) \sim p_{t+\Delta t}(\mathbf{x})$. 校正器可以是任何完全依赖于得分函数的MCMC 程序,例如 Langevin 动力学和哈密顿蒙特卡洛。
在 Predictor-Corrector 采样器的每一步,我们首先使用预测器来选择合适的步长$\Delta t < 0$, 然后基于当前样本$\mathbf{x}(t)$预测$\mathbf{x}(t + \Delta t)$. 接下来,我们运行几个校正步骤, 根据我们基于分数的模型$\mathbf{s}\theta(\mathbf{x}, t + \Delta t)$来改进样本$\mathbf{x}(t + \Delta t)$, 以便$\mathbf{x}(t + \Delta t)$成为更高质量的来自$p{t+\Delta t}(\mathbf{x})$的样本.
通过预测-校正方法和更好的基于分数的模型架构,我们可以在 CIFAR-10 上实现最好的样本质量(在 FID 中测量[37]和初始分数[12]),优于迄今为止最好的 GAN 模型(StyleGAN2 + ADA[38]).
| Method | FID ↓ | Inception score ↑ |
|---|---|---|
| StyleGAN2 + ADA [38] | 2.92 | 9.83 |
| Ours [20] | 2.20 | 9.89 |
采样方法还可以针对极高维数据进行扩展。例如,它可以成功生成高保真分辨率的图像1024×1024.

来自在 FFHQ 数据集上训练的基于分数的模型的, 1024 x 1024 样本。
其他数据集的一些额外(未经整理)示例(取自此GitHub存储库):

LSUN 卧室的 256 x 256 样本。

CelebA-HQ 上的 256 x 256 样本。
概率流常微分方程
尽管能够生成高质量样本,但基于 Langevin MCMC 和 SDE 求解器的采样器并未提供一种方法来计算基于分数的生成模型的精确对数似然。下面,我们介绍一个基于常微分方程 (ODE) 的采样器,它可以进行精确的似然计算。
在[20],我们证明 t 可以在不改变边际分布的情况下将任何 SDE 转换为常微分方程 (ODE)${ p_t(\mathbf{x}) }{t \in [0, T]}$. 因此,通过求解此 ODE,我们可以从与反向 SDE 相同的分布中采样。SDE 对应的 ODE 称为概率流 ODE [20], 由下面公式表示: $$ \begin{equation} \mathrm{d} \mathbf{x} = \bigg[\mathbf{f}(\mathbf{x}, t) - \frac{1}{2}g^2(t) \nabla\mathbf{x} \log p_t(\mathbf{x})\bigg] \mathrm{d}t. \end{equation} $$ 下图描绘了 SDE 和概率流 ODE 的轨迹。尽管 ODE 轨迹明显比 SDE 轨迹更平滑,但它们都能将相同的数据分布转换为相同的先验分布,反之亦然,并且共享同一组边际分布${ p_t(\mathbf{x}) }_{t \in [0, T]}$. 换句话说,通过求解概率流 ODE 得到的轨迹与 SDE 轨迹具有相同的边缘分布。
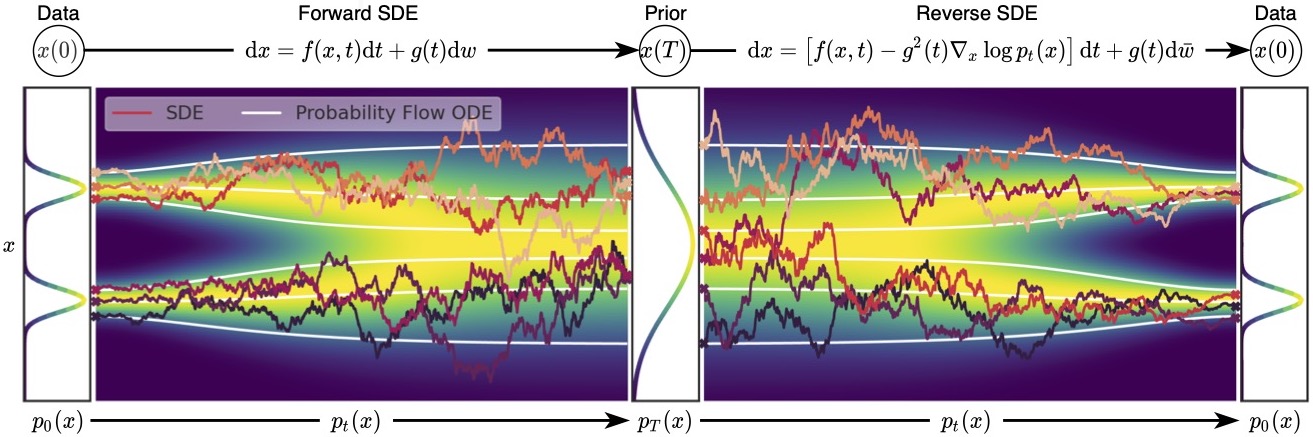
我们可以使用 SDE 将数据映射到噪声分布(先验),并反转此 SDE 以进行生成模型。我们还可以反转关联的概率流 ODE,这会产生一个确定性过程,该过程从与 SDE 相同的分布中采样。逆SDE和概率流ODE都可以通过估计得分函数得到。
这种概率流 ODE 公式具有几个独特的优点。
当$\nabla_\mathbf{x} \log p_t(\mathbf{x})$被它的近似值$\mathbf{s}_\theta(\mathbf{x}, t)$代替,概率流 ODE 成为神经 ODE 的特例[39]. 特别是,它是连续归一化流的示例[40],因为概率流 ODE 转换数据分布$p_0$(X)到先前的噪声分布$p_t(\mathbf{x})$(因为它与 SDE 具有相同的边际分布)并且是完全可逆的。
因此,概率流 ODE 继承了神经 ODE 或连续归一化流的所有属性,包括精确的对数似然计算。具体来说,我们可以利用瞬时变量变化公式(定理 1[39], 等式 (4) 在[40]) 使用数值 ODE 求解器从已知的先验密度$p_T$来计算未知数据密度$p_0$。
事实上,即使没有最大似然训练,我们的模型在均匀去量化的CIFAR-10 图像 [20] 上实现了最先进的对数似然。
| Method | Negative log-likelihood (bits/dim) ↓ |
|---|---|
| RealNVP | 3.49 |
| iResNet | 3.45 |
| Glow | 3.35 |
| FFJORD | 3.40 |
| Flow++ | 3.29 |
| Ours | 2.99 |
当使用我们之前讨论的似然加权训练基于分数的模型,并使用变分反量化来获得离散图像的似然时,我们可以获得与最好的自回归模型相当甚至更好的似然(所有这些都没有任何数据增强)[35].
| Method | Negative log-likelihood (bits/dim) ↓ on CIFAR-10 | Negative log-likelihood (bits/dim) ↓ on ImageNet 32x32 |
|---|---|---|
| Sparse Transformer | 2.80 | - |
| Image Transformer | 2.90 | 3.77 |
| Ours | 2.83 | 3.76 |
逆问题求解的可控生成
基于分数的生成模型特别适合求解反问题。从本质上讲,逆问题与贝叶斯推理问题相同。$x$和$y$是是两个随机变量,假设我们知道生成的正向过程是从$x$ 到 $y$, 由$ p(\mathbf{y} \mid \mathbf{x})$表示转移概率分布。 逆问题是计算$p(\mathbf{x} \mid \mathbf{y})$. 根据贝叶斯定理,我们有$p(\mathbf{x} \mid \mathbf{y}) = p(\mathbf{x}) p(\mathbf{y} \mid \mathbf{x}) / \int p(\mathbf{x}) p(\mathbf{y} \mid \mathbf{x}) \mathrm{d} \mathbf{x}$. 这个表达式可以通过对 $x$在两侧求导得到极大简化,导出以下贝叶斯规则评分函数: $$ \begin{equation} \nabla_\mathbf{x} \log p(\mathbf{x} \mid \mathbf{y}) = \nabla_\mathbf{x} \log p(\mathbf{x}) + \nabla_\mathbf{x} \log p(\mathbf{y} \mid \mathbf{x}).\end{equation} $$ 通过分数匹配,我们可以训练一个模型来估计无条件数据分布的分数函数,即$\mathbf{s}\theta(\mathbf{x}) \approx \nabla\mathbf{x} \log p(\mathbf{x})$ 这将使我们能够通过等式(15),从已知的前向过程 $p(\mathbf{y} \mid \mathbf{x})$轻松计算后验得分函数 $\nabla_\mathbf{x} \log p(\mathbf{x} \mid \mathbf{y})$, 并使用 Langevin-type sampling 从中采样[20].
UT Austin 的最新工作[28]已经证明基于分数的生成模型可以应用于求解医学成像中的逆问题,例如加速磁共振成像(MRI)。同时在[41],我们不仅在加速 MRI ,而且在稀疏视图计算机断层扫描 (CT) 上展示了基于分数的生成模型的卓越性能。我们能够实现与监督或展开的深度学习方法相当甚至更好的性能,同时在测试时对不同的测量过程更加稳健。
下面我们展示了一些求解计算机视觉逆问题的例子。

类条件生成,无条件的基于分数的模型,以及 CIFAR-10 上的预训练噪声条件图像分类器。

使用在 LSUN 卧室上训练的基于分数的模型进行图像修复。最左边的列是基本事实。第二列显示蒙版图像(在我们的框架中为 y)。其余列显示不同的修复图像,通过求解条件逆时 SDE 生成。

使用在 LSUN church_outdoor 和 bedroom 上训练的基于时间的基于分数的模型进行图像着色。最左边的列是基本事实。第二列显示灰度图像(在我们的框架中为 y)。其余列显示不同的彩色图像,通过求解条件逆时 SDE 生成。

我们甚至可以使用在 FFHQ 上训练的基于分数的模型为历史名人(亚伯拉罕林肯)的灰度肖像着色。图像分辨率为 1024 x 1024。
与扩散模型和其他模型的连接
我从 2019 年开始从事基于分数的生成模型,当时我努力使分数匹配具有可扩展性,以便在高维数据集上训练基于深度能量的模型。我在这方面的第一次尝试导致了切片分数匹配的方法[30]. 尽管用于训练基于能量的模型的切片分数匹配具有可扩展性,但我惊讶地发现,即使在 MNIST 数据集上,从这些模型中抽取的 Langevin 样本也无法产生合理的样本。我开始研究这个问题,并发现了三个可以产生极好的样本的关键改进:
(1) 用多个噪声尺度扰动数据,并为每个噪声尺度训练基于分数的模型;
(2) 对基于分数的模型使用 U-Net 架构(我们使用 RefineNet,因为它是 U-Net 的现代版本);
(3) 将 Langevin MCMC 应用于每个噪声尺度并将它们链接在一起。
通过这些方法,我能够在 CIFAR-10 上获得最好的 Inception Score[17](甚至比最好的 GAN 还要好!),并生成高分辨率的图像 256×256[18].
不过,用多尺度噪声扰动数据的想法绝不是基于分数的生成模型所独有的。它以前曾用于,例如,模拟退火,退火重要性采样[42], 扩散概率模型[43], infusion training [44], 和变分回溯[45]生成随机网络[46]. 在所有这些工作中,扩散概率建模可能是最接近基于分数的生成模型的。扩散概率模型是由Jascha和他的同事在 2015 年首先提出的分层潜变量模型[43],它通过学习变分解码器来生成样本,以逆转将数据扰动为噪声的离散扩散过程。在没有意识到这项工作的情况下,基于分数的生成模型被提出并从一个非常不同的角度独立地被激发。尽管都具有多尺度噪声的扰动数据,但当时基于分数的生成模型和扩散概率建模之间的联系似乎很肤浅,因为前者通过分数匹配训练并通过 Langevin 动力学采样,而后者通过证据训练下界 (ELBO) 并使用学习解码器进行采样。
2020 年,Jonathan Ho及其同事[19]显著提高了扩散概率模型的经验性能,并首次揭示了与基于分数的生成模型的更深层次联系。他们表明,用于训练扩散概率模型的 ELBO 本质上等同于基于分数的生成模型中使用的分数匹配目标的加权组合。此外,通过将解码器参数化为一系列具有 U-Net 架构的基于分数的模型,他们首次证明了扩散概率模型也可以生成与 GAN 相当或优于 GAN 的高质量图像样本。
受他们工作的启发,我们在 ICLR 2021 论文中进一步研究了扩散模型和基于分数的生成模型之间的关系[20]. 我们发现扩散概率模型的采样方法可以与基于分数的模型的退火 Langevin 动力学相结合,以创建统一且更强大的采样器(预测校正采样器)。通过将噪声尺度的数量推广到无穷大,我们进一步证明了基于分数的生成模型和扩散概率模型都可以看作是对由分数函数确定的随机微分方程的离散化。这项工作将基于分数的生成模型和扩散概率建模连接到一个统一的框架中。
总的来说,这些最新进展似乎表明,基于分数的多噪声扰动生成模型和扩散概率模型都是同一模型族的不同视角,就像波力学和矩阵力学是量子力学历史上的等效公式一样。 分数匹配和基于分数的模型的角度可以精确计算对数似然,自然地求解反问题,并直接连接到基于能量的模型、薛定谔桥和最优传输[47]. 扩散模型的观点自然与 VAE、有损压缩相关,并且可以直接与变分概率推理相结合。这篇博文侧重于第一种观点,但我强烈建议感兴趣的读者也了解扩散模型的另一种观点(参见Lilian Weng 的精彩博客)。
许多最近关于基于分数的生成模型或扩散概率模型的工作深受双方研究知识的影响(参见牛津大学研究人员策划的网站)。尽管基于分数的生成模型和扩散模型之间存在着这种深厚的联系,但很难为它们的模型家族提出一个总称。DeepMind 的一些同事建议称它们为“生成扩散过程”。这在未来是否会被社区采纳还有待观察。
结束语
这篇博文详细介绍了基于分数的生成模型。我们证明了这种新的生成模型范例能够生成高质量样本,计算精确的对数似然,并执行可控生成以求解逆向问题。它是我们过去几年发表的几篇论文的汇编。如果您对更多详细信息感兴趣,请访问他们:
- Yang Song, Sahaj Garg, Jiaxin Shi, and Stefano Ermon. Sliced Score Matching: A Scalable Approach to Density and Score Estimation. UAI 2019 (Oral)
- Yang Song, and Stefano Ermon. Generative Modeling by Estimating Gradients of the Data Distribution. NeurIPS 2019 (Oral)
- Yang Song, and Stefano Ermon. Improved Techniques for Training Score-Based Generative Models. NeurIPS 2020
- Yang Song, Jascha Sohl-Dickstein, Diederik P. Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-Based Generative Modeling through Stochastic Differential Equations. ICLR 2021 (Outstanding Paper Award)
- Yang Song, Conor Durkan, Iain Murray, and Stefano Ermon. Maximum Likelihood Training of Score-Based Diffusion Models. NeurIPS 2021 (Spotlight)
- Yang Song, Liyue Shen, Lei Xing, and Stefano Ermon. Solving Inverse Problems in Medical Imaging with Score-Based Generative Models. ICLR 2022
对于受基于分数的生成模型影响的作品列表,牛津大学的研究人员建立了一个非常有用(但不一定完整)的网站:https 😕/scorebasedgenerativemodeling.github.io/ 。
基于分数的生成模型有两个主要挑战。首先,采样速度慢,因为它涉及大量的 Langevin 型迭代。其次,使用离散数据分布不方便,因为分数仅在连续分布上定义。
第一个挑战可以通过对精度较低的概率流 ODE 使用数值 ODE 求解器来部分求解(一种类似的方法,去噪扩散隐式建模,已经在[48]解决). 也可以学习从概率流 ODE 的潜在空间到图像空间的直接映射,如[49]. 然而,迄今为止所有这些方法都会导致样品质量变差。
第二个挑战可以通过在离散数据上学习自动编码器并在其连续潜在空间上执行基于分数的生成模型来求解[27,50]. Jascha 关于扩散模型的原创工作43]也为离散数据分布提供了离散扩散过程,但其大规模应用的潜力还有待证明。
我坚信,在研究界的共同努力下,这些挑战将很快得到求解,基于分数的生成模型/基于扩散的模型将成为数据生成、密度估计、反问题求解、以及机器学习中的许多其他下游任务。
References
- The neural autoregressive distribution estimator Larochelle, H. and Murray, I., 2011. International Conference on Artificial Intelligence and Statistics, pp. 29--37.
- Made: Masked autoencoder for distribution estimation Germain, M., Gregor, K., Murray, I. and Larochelle, H., 2015. International Conference on Machine Learning, pp. 881--889.
- Pixel recurrent neural networks Van Oord, A., Kalchbrenner, N. and Kavukcuoglu, K., 2016. International Conference on Machine Learning, pp. 1747--1756.
- NICE: Non-linear independent components estimation Dinh, L., Krueger, D. and Bengio, Y., 2014. arXiv preprint arXiv:1410.8516.
- Density estimation using Real NVP Dinh, L., Sohl-Dickstein, J. and Bengio, S., 2017. International Conference on Learning Representations.
- A tutorial on energy-based learning LeCun, Y., Chopra, S., Hadsell, R., Ranzato, M. and Huang, F., 2006. Predicting structured data, Vol 1(0).
- How to Train Your Energy-Based Models Song, Y. and Kingma, D.P., 2021. arXiv preprint arXiv:2101.03288.
- Auto-encoding variational bayes Kingma, D.P. and Welling, M., 2014. International Conference on Learning Representations.
- Stochastic backpropagation and approximate inference in deep generative models Rezende, D.J., Mohamed, S. and Wierstra, D., 2014. International conference on machine learning, pp. 1278--1286.
- Learning in implicit generative models Mohamed, S. and Lakshminarayanan, B., 2016. arXiv preprint arXiv:1610.03483.
- Generative adversarial nets Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A. and Bengio, Y., 2014. Advances in neural information processing systems, pp. 2672--2680.
- Improved techniques for training gans Salimans, T., Goodfellow, I., Zaremba, W., Cheung, V., Radford, A. and Chen, X., 2016. Advances in Neural Information Processing Systems, pp. 2226--2234.
- Unrolled Generative Adversarial Networks [link] Metz, L., Poole, B., Pfau, D. and Sohl-Dickstein, J., 2017. 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, April 24-26, 2017, Conference Track Proceedings. OpenReview.net.
- A kernelized Stein discrepancy for goodness-of-fit tests Liu, Q., Lee, J. and Jordan, M., 2016. International conference on machine learning, pp. 276--284.
- Estimation of non-normalized statistical models by score matching Hyvarinen, A., 2005. Journal of Machine Learning Research, Vol 6(Apr), pp. 695--709.
- A connection between score matching and denoising autoencoders Vincent, P., 2011. Neural computation, Vol 23(7), pp. 1661--1674. MIT Press.
- Generative Modeling by Estimating Gradients of the Data Distribution [PDF] Song, Y. and Ermon, S., 2019. Advances in Neural Information Processing Systems, pp. 11895--11907.
- Improved Techniques for Training Score-Based Generative Models [PDF] Song, Y. and Ermon, S., 2020. Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, virtual.
- Denoising diffusion probabilistic models Ho, J., Jain, A. and Abbeel, P., 2020. arXiv preprint arXiv:2006.11239.
- Score-Based Generative Modeling through Stochastic Differential Equations [link] Song, Y., Sohl-Dickstein, J., Kingma, D.P., Kumar, A., Ermon, S. and Poole, B., 2021. International Conference on Learning Representations.
- Diffusion models beat gans on image synthesis Dhariwal, P. and Nichol, A., 2021. arXiv preprint arXiv:2105.05233.
- Cascaded Diffusion Models for High Fidelity Image Generation Ho, J., Saharia, C., Chan, W., Fleet, D.J., Norouzi, M. and Salimans, T., 2021.
- WaveGrad: Estimating Gradients for Waveform Generation [link] Chen, N., Zhang, Y., Zen, H., Weiss, R.J., Norouzi, M. and Chan, W., 2021. International Conference on Learning Representations.
- DiffWave: A Versatile Diffusion Model for Audio Synthesis [link] Kong, Z., Ping, W., Huang, J., Zhao, K. and Catanzaro, B., 2021. International Conference on Learning Representations.
- Grad-tts: A diffusion probabilistic model for text-to-speech Popov, V., Vovk, I., Gogoryan, V., Sadekova, T. and Kudinov, M., 2021. arXiv preprint arXiv:2105.06337.
- Learning Gradient Fields for Shape Generation Cai, R., Yang, G., Averbuch-Elor, H., Hao, Z., Belongie, S., Snavely, N. and Hariharan, B., 2020. Proceedings of the European Conference on Computer Vision (ECCV).
- Symbolic Music Generation with Diffusion Models Mittal, G., Engel, J., Hawthorne, C. and Simon, I., 2021. arXiv preprint arXiv:2103.16091.
- Robust Compressed Sensing MRI with Deep Generative Priors Jalal, A., Arvinte, M., Daras, G., Price, E., Dimakis, A.G. and Tamir, J.I., 2021. Advances in neural information processing systems.
- Training products of experts by minimizing contrastive divergence Hinton, G.E., 2002. Neural computation, Vol 14(8), pp. 1771--1800. MIT Press.
- Sliced score matching: A scalable approach to density and score estimation [PDF] Song, Y., Garg, S., Shi, J. and Ermon, S., 2020. Uncertainty in Artificial Intelligence, pp. 574--584.
- Correlation functions and computer simulations Parisi, G., 1981. Nuclear Physics B, Vol 180(3), pp. 378--384. Elsevier.
- Representations of knowledge in complex systems Grenander, U. and Miller, M.I., 1994. Journal of the Royal Statistical Society: Series B (Methodological), Vol 56(4), pp. 549--581. Wiley Online Library.
- Adversarial score matching and improved sampling for image generation [link] Jolicoeur-Martineau, A., Piche-Taillefer, R., Mitliagkas, I. and Combes, R.T.d., 2021. International Conference on Learning Representations.
- Reverse-time diffusion equation models Anderson, B.D., 1982. Stochastic Processes and their Applications, Vol 12(3), pp. 313--326. Elsevier.
- Maximum Likelihood Training of Score-Based Diffusion Models Song, Y., Durkan, C., Murray, I. and Ermon, S., 2021. Advances in Neural Information Processing Systems (NeurIPS).
- Gotta Go Fast When Generating Data with Score-Based Models Jolicoeur-Martineau, A., Li, K., Piche-Taillefer, R., Kachman, T. and Mitliagkas, I., 2021. arXiv preprint arXiv:2105.14080.
- GANs Trained by a Two Time-Scale Update Rule Converge to a Local Nash Equilibrium Heusel, M., Ramsauer, H., Unterthiner, T., Nessler, B. and Hochreiter, S., 2017. Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, December 4-9, 2017, Long Beach, CA, {USA}, pp. 6626--6637.
- Training Generative Adversarial Networks with Limited Data Karras, T., Aittala, M., Hellsten, J., Laine, S., Lehtinen, J. and Aila, T., 2020. Proc. NeurIPS.
- Neural Ordinary Differential Equations Chen, T.Q., Rubanova, Y., Bettencourt, J. and Duvenaud, D., 2018. Advances in Neural Information Processing Systems 31: Annual Conference on Neural Information Processing Systems 2018, NeurIPS 2018, December 3-8, 2018, Montr{'{e} }al, Canada, pp. 6572--6583.
- Scalable Reversible Generative Models with Free-form Continuous Dynamics [link] Grathwohl, W., Chen, R.T.Q., Bettencourt, J. and Duvenaud, D., 2019. International Conference on Learning Representations.
- Solving Inverse Problems in Medical Imaging with Score-Based Generative Models [PDF] Song, Y., Shen, L., Xing, L. and Ermon, S., 2022. International Conference on Learning Representations.
- Annealed importance sampling Neal, R.M., 2001. Statistics and computing, Vol 11(2), pp. 125--139. Springer.
- Deep unsupervised learning using nonequilibrium thermodynamics Sohl-Dickstein, J., Weiss, E., Maheswaranathan, N. and Ganguli, S., 2015. International Conference on Machine Learning, pp. 2256--2265.
- Learning to generate samples from noise through infusion training Bordes, F., Honari, S. and Vincent, P., 2017. arXiv preprint arXiv:1703.06975.
- Variational walkback: Learning a transition operator as a stochastic recurrent net Goyal, A., Ke, N.R., Ganguli, S. and Bengio, Y., 2017. arXiv preprint arXiv:1711.02282.
- GSNs: generative stochastic networks Alain, G., Bengio, Y., Yao, L., Yosinski, J., Thibodeau-Laufer, E., Zhang, S. and Vincent, P., 2016. Information and Inference: A Journal of the IMA, Vol 5(2), pp. 210--249. Oxford University Press.
- Diffusion Schrödinger Bridge with Applications to Score-Based Generative Modeling De Bortoli, V., Thornton, J., Heng, J. and Doucet, A., 2021. Advances in Neural Information Processing Systems (NeurIPS).
- Denoising Diffusion Implicit Models [link] Song, J., Meng, C. and Ermon, S., 2021. International Conference on Learning Representations.
- Knowledge Distillation in Iterative Generative Models for Improved Sampling Speed Luhman, E. and Luhman, T., 2021. arXiv e-prints, pp. arXiv--2101.
- Score-based Generative Modeling in Latent Space Vahdat, A., Kreis, K. and Kautz, J., 2021. Advances in Neural Information Processing Systems (NeurIPS).