扩散模型的工作原理:从零开始的数学
扩散模型是什么?
扩散模型 (Diffusion Models) 是一类新的最先进的生成模型,可生成各种各样的高分辨率图像。在 OpenAI、英伟达和谷歌成功训练出大规模模型后,它们已经引起了广泛关注。基于扩散模型的示例架构有 GLIDE、DALLE-2、Imagen 和完全开源的 Stable diffusion。
它们背后的主要原理是什么?
在这篇博文中,我们将从基本原理开始挖掘。目前已经有许多不同的基于扩散模型的架构,我们将重点讨论其中最突出的一个,即由 Sohl-Dickstein et al 和 Ho. et al 2020 提出的去噪扩散概率模型 (DDPM, denoising diffusion probabilistic model) 。其它各种方法将不会具体讨论,如 Stable Diffusion 和 Score-based models 。
扩散模型从根本上不同于所有以前的生成方法。直觉上,他们的目标是通过许多小的“去噪”步骤分解图像生成过程(采样)。
扩散模型是生成模型,这意味着它们用于生成与训练数据相似的数据。 从根本上讲,扩散模型的工作原理是通过连续添加高斯噪声来破坏训练数据,然后学习通过逆转该噪声过程来恢复数据。训练后,我们可以使用扩散模型来生成数据,只需将随机采样的噪声传递到学习的去噪过程中即可。

背后的直觉是,模型可以通过这些小步骤进行自我修正并逐渐产生一个好的样本。在某种程度上,这种改进表示的想法已经被用于像alphafold这样的模型中。但是,没有什么是零成本的。这种迭代过程使它们的采样速度变慢,至少与GAN相比。
扩散过程
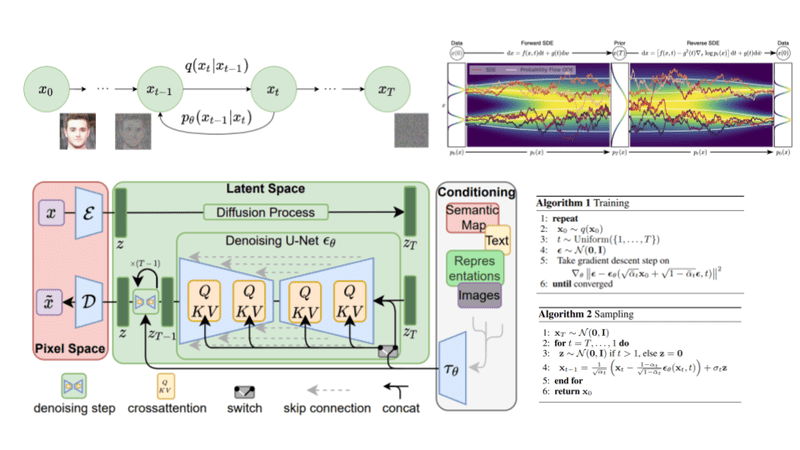
扩散模型背后的基本思想相当简单。输入图像 $x_0$ 并通过一系列 $T$ 步逐渐向其添加高斯噪声,我们将其称为前向过程。值得注意的是,这与神经网络的前向传递无关。但是前向过程对于我们的神经网络生成目标(应用 $t<T$ 噪声步骤后的图像)是必要的。
之后,训练一个神经网络通过逆转噪声过程来恢复原始数据。通过能够对逆向过程建模,我们可以生成新数据。这就是所谓的反向扩散过程,或者通俗地说,就是生成模型的采样过程。
我们深入数学,使之清晰明了。
正向扩散
扩散模型可以看作是隐变量模型。“隐变量” 意味着我们指的是隐藏的连续特征空间。这样,它们可能看起来类似于变分自动编码器 (VAE)。
在实践中,它们是使用马尔可夫链的 $T$ 步来制定的。这里,马尔可夫链意味着每一步只依赖于前一步,这是一个温和的假设。重要的是,与基于流的模型不同,我们并不局限于使用特定类型的神经网络。
给定一个数据点 $\mathbf{x}0$ ,从真实数据分布 $q(\mathbf{x})$ ($\mathbf{x}0 \sim q(\mathbf{x})$) 中采样,我们可以通过添加噪声来定义一个前向扩散过程。具体来说,在马尔科夫链的每一步,我们向 $\mathbf{x}$ 添加方差为 $\beta_t$ 的高斯噪声,产生一个新的隐变量 $\mathbf{x}$ ,其分布为 $q(\mathbf{x}t|\mathbf{x})$ 。这个扩散过程可以表述如下:
$$ q(\mathbf{x}t \vert \mathbf{x}) = \mathcal{N}(\mathbf{x}_t; \boldsymbol{\mu}t=\sqrt{1 - \beta_t} \mathbf{x}, \boldsymbol{\Sigma}_t = \beta_t\mathbf{I}) $$
前向扩散过程 , 图片修改自 Ho et al. 2020
由于我们处于多维情况下, $\textbf{I}$ 是单位矩阵,表明每个维度有相同的标准偏差 $\beta_t$ 。注意到, $q(\mathbf{x}t \vert \mathbf{x})$ 是一个正态分布,其均值是 $\boldsymbol{\mu}t =\sqrt{1 - \beta_t} \mathbf{x}$ ,方差为 $\boldsymbol{\Sigma}_t=\beta_t\mathbf{I}$ ,其中 $\boldsymbol{\Sigma}$ 是一个对角矩阵的方差(这里就是 $\beta_t$ )。 正态分布(也称为高斯分布)由 2 个参数定义:均值 $\mu$ 和方差 $\boldsymbol{\Sigma}$, 基本上,在时间步$t$ 的每个新的(噪音稍大)的图像都可以从条件高斯分布中得出。
因此,我们可以从 $\mathbf{x}_0$ 以一种可操作的方式封闭地转换到到 $\mathbf{x}t$ 。在数学上,这种后验概率定义如下: $$ q(\mathbf{x} \vert \mathbf{x}0) = \prod^T q(\mathbf{x}t \vert \mathbf{x}) $$
其中,$q(\mathbf{x}_{1:T})$ 意味着我们从时间 $1$ 到 $T$ 重复应用 $q$ 。它也被称为轨迹。
到目前为止,看起来还不错?并不!对于时间步长 $t=500<T$ 我们要应用 $q$ 函数 500 次才能采样 $\mathbf{x}_t$ 。难道就没有更好的方式吗?
重参数化技巧 (Reparametrization Trick) 对此提供了一个魔法般的补救办法。
重参数化技巧
如果我们定义 $\alpha_t= 1- \beta_t$, $\bar{\alpha}t = \prod^t \alpha_s$ ,其中 $\boldsymbol{\epsilon}{0},..., \epsilon, \epsilon_{t-1} \sim \mathcal{N}(\textbf{0},\mathbf{I})$ ,那么我们可以使用重参数化技巧证明:
$$ \begin{aligned} \mathbf{x}t &=\sqrt{1 - \beta_t} \mathbf{x} + \sqrt{\beta_t}\boldsymbol{\epsilon}{t-1}\ &= \sqrt{\alpha_t}\mathbf{x} + \sqrt{1 - \alpha_t}\boldsymbol{\epsilon}_{t-1} \ &= \dots \ &= \sqrt{\bar{\alpha}_t}\mathbf{x}_0 + \sqrt{1 - \bar{\alpha}_t}\boldsymbol{\epsilon_0} \end{aligned} $$
由于所有时间段都有相同的高斯噪声,我们从现在开始只使用符号 $ϵ$
因此,为了产生一个样本$x_t$,我们可以使用如下公式:
$$ \mathbf{x}_t \sim q(\mathbf{x}_t \vert \mathbf{x}_0) = \mathcal{N}(\mathbf{x}_t; \sqrt{\bar{\alpha}_t} \mathbf{x}_0, (1 - \bar{\alpha}_t)\mathbf{I}) $$
由于 $\beta_t$ 是一个超参数,我们可以预先计算所有时间步的 $\alpha_t$ 和 $\bar{\alpha}_t$ 。这意味着我们在任何一个时间点 $t$ 对噪声进行采样,并一次性得到 $\mathbf{x}_t$ 。因此,我们可以在任何一个任意的时间段对我们的潜变量 $\mathbf{x}_t$ 进行采样。这将是我们以后计算可操作的目标损失 $L_t$ 的目标。
方差表
方差参数 $\beta_t$ 可以固定为一个常数,也可以选择作为 $T$ 时间段的一个时间表。事实上,我们可以定义一个方差表,它可以是线性的、二次的、余弦的等等。最初的 DDPM 作者利用了一个从 $\beta_1= 10^{-4}$ 到 $\beta_T = 0.02$ 增加的线性时间表。 Nichol et al. 2021 的研究表明,采用余弦时间表效果更好。

Latent samples from linear (top) and cosine (bottom) schedules respectively. Source: Nichol & Dhariwal 2021
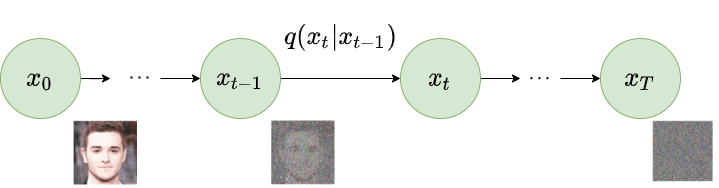
反向扩散
当 $T \to \infty$ 时,隐变量的 $\mathbf{x}T$ 几乎是一个各向同性 (isotropic) 的高斯分布。因此,如果我们知道反向条件分布 $q(\mathbf{x} \vert \mathbf{x}_{t})$ ,然后我们可以反向运行该过程, 通过从随机高斯噪声分布 $\mathcal{N}(\textbf{0},\mathbf{I})$ 中采样一些$\mathbf{x}t$,然后逐渐对其进行“去噪”, 从而生成原始数据分布中的一个新数据点 $x$。
用神经网络近似反向过程
在实际情况中,我们不知道 $q(\mathbf{x}{t-1} \vert \mathbf{x})$ ,由于估计 $q(\mathbf{x}{t-1} \vert \mathbf{x})$ 需要知道所有可能图像的分布才能计算这个条件概率,因此它是不可行的。
相反,我们用一个参数化的模型 $p_{\theta}$ (例如一个神经网络)来近似条件分布 $q(\mathbf{x}{t-1} \vert \mathbf{x})$ 。由于 $q(\mathbf{x}{t-1} \vert \mathbf{x})$ 也将是高斯分布,对于足够小的 $\beta_t$ ,我们可以选择 $p_{\theta}$ 为高斯分布,只需对平均值和方差进行参数化:
$$ p_\theta(\mathbf{x}{t-1} \vert \mathbf{x}t) = \mathcal{N}(\mathbf{x}; \boldsymbol{\mu}\theta(\mathbf{x}t, t), \boldsymbol{\Sigma}\theta(\mathbf{x}_t, t)) $$
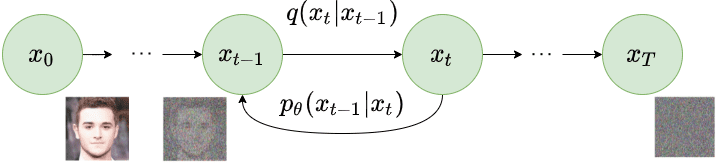
Reverse diffusion process. Image modified by Ho et al. 2020, 其中均值和方差也取决于噪声水平
如果我们对所有的时间步数应用反向公式 $p_\theta(\mathbf{x}_{0:T})$ ,我们可以由 $\mathbf{x}_T$ 得到数据分布:
$$ p_\theta(\mathbf{x}{0:T}) = p{\theta}(\mathbf{x}T) \prod^T p_\theta(\mathbf{x}_{t-1} \vert \mathbf{x}_t) $$
通过在模型上添加时间 $t$ 的条件,该模型将学会预测每个时间段的高斯分布参数(指平均值 $\boldsymbol{\mu}_\theta(\mathbf{x}t, t)$ )和协方差矩阵 $\boldsymbol{\Sigma}\theta(\mathbf{x}_t, t)$。
但我们如何训练这样一个模型呢?
扩散模型训练
定义目标函数
为了推导出逆向扩散过程的目标函数,作者观察到, $q$ 和 $p$ 的组合与变分自编码器 (VAE) (Kingma et al., 2013) 非常相似。因此,我们可以通过优化训练数据的负对数似然来训练它。经过一系列的计算(我们在此不做分析),我们可以把证据下界 (ELBO) 写成如下:
$$ \begin{aligned} \log p(\mathbf{x}) \geq ~ &\mathbb{E}{q(x_1 \vert x_0)} [\log p{\theta} (\mathbf{x}_0 \vert \mathbf{x}1)] - \ &D(q(\mathbf{x}T \vert \mathbf{x}0) \vert\vert p(\mathbf{x}T))- \ &\sum^T \mathbb{E}{q(\mathbf{x}t \vert \mathbf{x}0)} [D(q(\mathbf{x} \vert \mathbf{x}t, \mathbf{x}0) \vert \vert p{\theta}(\mathbf{x} \vert \mathbf{x}t)) ] \ & = L_0 - L_T - \sum^T L \end{aligned} $$
我们来分析一下这些内容:
- $\mathbb{E}{q(x_1 \vert x_0)} [\log p{\theta} (\mathbf{x}_0 \vert \mathbf{x}_1)]$ 可以当作是一个重建项 (reconstruction term) ,类似于变量自动编码器 ELBO 中的项。在 Ho et al 2020 的研究中,这一项是用一个单独的解码器学习的。
- $D_{KL}(q(\mathbf{x}_T \vert \mathbf{x}_0) \vert\vert p(\mathbf{x}_T))$ 显示了 $\mathbf{x}_T$ 与标准高斯有多接近。注意到,整个项都没有可训练的参数,因此,在训练过程这个项会被忽略。
- 最后的第三项 $\sum_{t=2}^T L_{t-1}$ 也表示为 $L_t$ ,描述了期望的去噪步骤 $p_{\theta}(\mathbf{x}_{t-1} \vert \mathbf{x}t)$ 与近似项 $q(\mathbf{x} \vert \mathbf{x}_t, \mathbf{x}_0)$ 之间的差异。
很明显,通过 ELBO ,最大化似然可以归结为学习去噪步骤 $L_t$ 。
尽管 $q(\mathbf{x}{t-1} \vert \mathbf{x})$ 是难以解决的,但 Sohl-Dickstein et al 说明,通过对 $\textbf{x}_0$ 的附加条件,可以使它变得容易解决
直观地说,画家(我们的生成模型)需要一个参考图像 ($\textbf{x}0$) 来慢慢绘制(反向扩散步骤 $q(\mathbf{x} \vert \mathbf{x}_t, \mathbf{x}_0)$ )一个图像。因此,当且仅当我们有 $\mathbf{x}_0$ 作为参考时,我们可以向后退一小步,即从噪声中生成一个图像。换句话说,我们可以在噪声水平 $t$ 的条件下对 $\textbf{x}_t$ 进行采样。由于 $\alpha_t= 1- \beta_t$ 和 $\bar{\alpha}t = \prod^t \alpha_s$ ,我们可以证明:
$$ \begin{aligned} q(\mathbf{x}_{t-1} \vert \mathbf{x}_t, \mathbf{x}0) &= \mathcal{N}(\mathbf{x}; {\tilde{\boldsymbol{\mu} } }(\mathbf{x}_t, \mathbf{x}_0), {\tilde{\beta}_t} \mathbf{I}) \ \tilde{\beta}t &= \frac{1 - \bar{\alpha} }{1 - \bar{\alpha}_t} \cdot \beta_t \ \tilde{\boldsymbol{\mu} }_t (\mathbf{x}_t, \mathbf{x}0) &= \frac{\sqrt{\bar{\alpha} }\beta_t}{1 - \bar{\alpha}t} \mathbf{x_0} + \frac{\sqrt{\alpha_t}(1 - \bar{\alpha})}{1 - \bar{\alpha}_t} \mathbf{x}_t \end{aligned} $$
$\alpha_t$ 和 $\bar{\alpha}_t$ 只取决于 $\beta_t$ ,所以它可以被预先计算出来
这个小技巧为我们提供了一个完全可操作的 ELBO 。上述属性还有一个重要的副作用,正如我们在重参数化技巧中已经看到的,我们可以将 $\mathbf{x}_0$ 表示为:
$$ \mathbf{x}_0 = \frac{1}{\sqrt{\bar{\alpha}_t} }\left(\mathbf{x}_t - \sqrt{1 - \bar{\alpha}_t} \boldsymbol{\epsilon}\right), $$
其中 $\boldsymbol{\epsilon} \sim \mathcal{N}(\textbf{0},\mathbf{I})$
通过合并最后两个方程,现在每个时间步长将有一个仅依赖于$\mathbf{x}_t$均值 $\tilde{\boldsymbol{\mu} }_t$ (我们的目标) :
$$ \tilde{\boldsymbol{\mu} }_t (\mathbf{x}_t) = {\frac{1}{\sqrt{\alpha_t} } \left( \mathbf{x}_t - \frac{\beta_t}{\sqrt{1 - \bar{\alpha}_t} } \boldsymbol{\epsilon} \right)} $$
因此,我们可以使用一个神经网路 $\epsilon_{\theta}(\mathbf{x}_t,t)$ 来近似 $\boldsymbol{\epsilon}$ 并得到如下均值结果:
$$ \tilde{\boldsymbol{\mu}_{\theta} }( \mathbf{x}_t,t) = {\frac{1}{\sqrt{\alpha_t} } \left( \mathbf{x}_t - \frac{\beta_t}{\sqrt{1 - \bar{\alpha}t} } \boldsymbol{\epsilon}{\theta}(\mathbf{x}_t,t) \right)} $$
因此,损失函数(ELBO中的去噪项)可以表示为:
$$ \begin{aligned} L_t &= \mathbb{E}_{\mathbf{x}0,t,\boldsymbol{\epsilon} }\left[\frac{1}{2||\boldsymbol{\Sigma}\theta (x_t,t)||_2^2} ||\tilde{\boldsymbol{\mu} }t - \boldsymbol{\mu}\theta(\mathbf{x}t, t)||2^2 \right] \ &= \mathbb{E}{\mathbf{x}0,t,\boldsymbol{\epsilon} }\left[\frac{\beta_t^2}{2\alpha_t (1 - \bar{\alpha}t) ||\boldsymbol{\Sigma}\theta||^2_2} | \boldsymbol{\epsilon}- \boldsymbol{\epsilon}{\theta}(\sqrt{\bar{a}_t} \mathbf{x}_0 + \sqrt{1-\bar{a}_t}\boldsymbol{\epsilon}, t ) ||^2 \right] \end{aligned} $$
这实际上告诉我们,该模型不是预测分布的平均值,而是预测每个时间点 $t$ 的噪声 $\boldsymbol{\epsilon}$
Ho et.al 2020 对实际损失项做了一些简化,他们忽略了一个加权项。简化后的版本优于完整的目标: $$ L_t^\text{simple} = \mathbb{E}_{\mathbf{x}0, t, \boldsymbol{\epsilon} } \left[|\boldsymbol{\epsilon}- \boldsymbol{\epsilon}{\theta}(\sqrt{\bar{a}_t} \mathbf{x}_0 + \sqrt{1-\bar{a}_t} \boldsymbol{\epsilon}, t ) ||^2 \right] $$
其中,$ x_0 $ 是初始的(真实的、未被破坏的)图像,我们看到由固定的前向过程给出的直接噪声水平 $ t $ 的样本。$ \epsilon $ 是在时间步 $ t $ 采样的纯噪声,而 $ \epsilon_\theta(x_t, t) $ 是我们的神经网络。神经网络是使用真实和预测的高斯噪声之间的简单均方误差(MSE)进行优化的。
作者发现,优化上述目标比优化原始 ELBO 效果更好。这两个方程的证明可以在 Lillian Weng 的这篇优秀文章或 Luo et al. 2022 中找到。
此外,Ho et. al 2020 决定保持方差固定,让网络只学习均值。后来 Nichol et al. 2021 对此进行了改进,他们让网络学习协方差矩阵 $(\boldsymbol{\Sigma})$ (通过修改 $L_t^\text{simple}$ ),取得了更好的结果。

DDPMs 的训练和采样算法 , 图片来自 Ho et al. 2020
训练算法现在看起来如下:
- 首先从真实的未知且可能是复杂的概率分布 $ q(x_0) $ 中随机采样 $ x_0 $;
- 在 1 到 T 之间均匀地采样一个噪声水平 $ t $(即,一个随机的时间步);
- 从高斯分布中采样一些噪声,并通过这个噪声破坏输入;
- 在水平 $ t $(使用重参数技巧)上,神经网络被训练来基于被破坏的图像 $ x_t $ 预测这个噪声(即,基于已知的时间表 $ \beta_t $ 应用于 $ x_0 $ 上的噪声);
扩散模型架构
到目前为止,我们还没有提到的一件事是模型的架构是什么样子的。请注意,模型的输入和输出应该是相同尺寸的。
为此, Ho et al. 采用了一个 U-Net 。如果你对 U-Net 不熟悉,请随时查看我们过去关于 U-Net 架构 的文章。简而言之, U-Net 是一种对称的架构,其输入和输出的空间大小相同,在相应特征维度的编码器和解码器块之间使用 跳层连接 。通常,输入图像首先经过下采样,然后上采样,直到达到其初始尺寸。
在 DDPMs 的原始实现中, U-Net 由 Wide ResNet 块 、 分组归一化 以及 自注意力 块组成。
扩散时间段 $t$ 是通过在每个残差块中加入一个正弦的 位置嵌入 来指定的。欲了解更多细节,请随时访问 官方 GitHub 仓库 。关于扩散模型的详细实现,请查看 Hugging Face 的这篇精彩文章 。
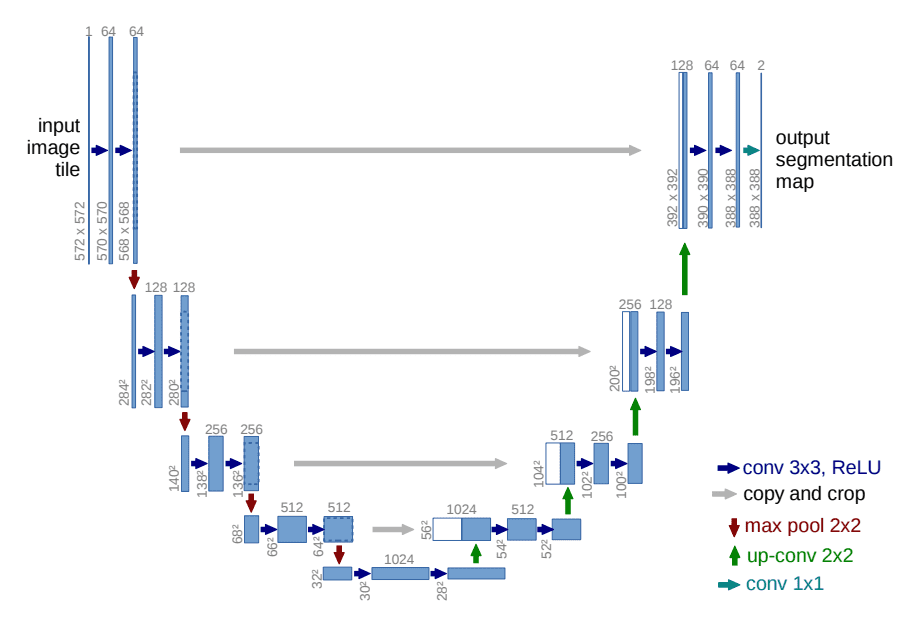
U-Net 的架构 ,图片来自 Ronneberger et al.
条件图像生成:引导扩散
图像生成的一个关键方面是调节采样过程,以操纵生成的样本。在这里,这也被称为引导性扩散。
甚至有一些方法将图像嵌入到扩散中,以便“引导”生成。从数学上讲,引导指的是用一个条件 $y$ ,即类别标签或图像/文本嵌入来调节先验数据分布 $p(\textbf{x})$ ,导致 $p(\textbf{x}|y)$ 。 为了把扩散模型 $p_\theta$ 变成一个条件扩散模型,我们可以在每个扩散步骤中加入条件信息 $y$ :
$$ p_\theta(\mathbf{x}{0:T} \vert y) = p\theta(\mathbf{x}T) \prod^T p_\theta(\mathbf{x}_{t-1} \vert \mathbf{x}_t, y) $$
条件在每个时间步都可见,这可能是文字提示的优秀样本的一个良好证明。
一般来说,引导扩散模型的目的是学习 $\nabla \log p_\theta( \mathbf{x}_t \vert y)$ ,所以使用贝叶斯规则,我们可以写出:
$$ \begin{aligned} \nabla_{\textbf{x}{t} } \log p\theta(\mathbf{x}t \vert y) &= \nabla{\textbf{x}{t} } \log (\frac{p\theta(y \vert \mathbf{x}t) p\theta(\mathbf{x}t) }{p\theta(y)}) \ &= \nabla_{\textbf{x}{t} } \log p\theta(\mathbf{x}t) + \nabla{\textbf{x}{t} } \log (p\theta( y \vert\mathbf{x}_t )) \end{aligned} $$
因为 $p_\theta(y)$ 被移除,梯度算子 $\nabla_{\textbf{x}{t} }$ 仅涉及 $\textbf{x}$, 所以没有 $y$ 的梯度。此外请记住 $\log(a b)= \log(a) + \log(b)$ 。
再加上一个引导标量项 $s$ ,我们就有:
$$ \nabla \log p_\theta(\mathbf{x}t \vert y) = \nabla \log p\theta(\mathbf{x}t) + s \cdot \nabla \log (p\theta( y \vert\mathbf{x}_t )) $$
利用这一表述,让我们对分类器和无分类器的引导进行区分。
分类引导
Sohl-Dickstein et al. 以及后来的 Dhariwal 和 Nichol 表明,我们可以使用第二个模型,即分类器 $f_\phi(y \vert \mathbf{x}_t, t)$ ,在训练过程中引导扩散朝着目标类别 $y$ 。为了达到这个目的,我们可以在噪声图像 $\mathbf{x}t$ 上训练一个分类器 $f\phi(y \vert \mathbf{x}t, t)$ 以预测其类别 $y$ 。然后我们可以使用梯度 $\nabla \log (f\phi( y \vert\mathbf{x}_t ))$ 来引导扩散。具体怎么做呢?
我们可以建立一个具有均值 $\mu_\theta(\mathbf{x}t|y)$ 和方差 $\boldsymbol{\Sigma}\theta(\mathbf{x}_t |y)$ 的类条件扩散模型。
由于 $p_\theta \sim \mathcal{N}(\mu_{\theta}, \Sigma_{\theta})$ ,我们可以用上一节的引导公式表明,均值受到了 $y$ 类的 $\log f_\phi(y|\mathbf{x}_t)$ 的梯度扰动,结果是:
$$ \hat{\mu}(\mathbf{x}t |y) =\mu\theta(\mathbf{x}t |y) + s \cdot \boldsymbol{\Sigma}\theta(\mathbf{x}t |y) \nabla{\mathbf{x}t} \log f\phi(y \vert \mathbf{x}_t, t) $$
在 Nichol et al. 著名的 GLIDE 论文 中,作者扩展了这个想法,并使用 CLIP 嵌入 来指导扩散。 Saharia et al. 提出的 CLIP 由一个图像编码器 $g$ 和一个文本编码器 $h$ 组成。它分别产生一个图像和文本嵌入 $g(\mathbf{x}_t)$ 和 $h(c)$ ,其中 $c$ 是文本标题。
因此,我们可以用它们的点积来扰动梯度:
$$ \hat{\mu}(\mathbf{x}_t |c) =\mu(\mathbf{x}t |c) + s \cdot \boldsymbol{\Sigma}\theta(\mathbf{x}t |c) \nabla{\mathbf{x}_t} g(\mathbf{x}_t) \cdot h(c) $$
结果,他们能够“引导”生成过程朝着用户定义的文本标题发展。

分类器引导的扩散采样算法,图片来自 Dhariwal & Nichol 2021
无分类器引导
使用与之前相同的表述,我们可以将无分类器的引导扩散模型定义为:
$$ \nabla \log p(\mathbf{x}_t \vert y) =s \cdot \nabla \log(p(\mathbf{x}_t \vert y)) + (1-s) \cdot \nabla \log p(\mathbf{x}_t) $$
正如 Ho & Salimans 所提议的那样,不需要第二个分类器模型就可以实现指导作用。事实上,他们使用的是完全相同的神经网络,而不是训练一个单独的分类器,作者将条件性扩散模型 $\boldsymbol{\epsilon}_\theta (\mathbf{x}t|y)$ 与无条件性模型 $\boldsymbol{\epsilon}\theta (\mathbf{x}_t |0)$ 一起训练。在训练过程中,他们随机地将类 $y$ 设置为 $0$ ,这样模型就同时接触到了有条件和无条件的设置:
$$ \begin{aligned} \hat{\boldsymbol{\epsilon} }_\theta(\mathbf{x}t |y) & = s \cdot \boldsymbol{\epsilon}\theta(\mathbf{x}t |y) + (1-s) \cdot \boldsymbol{\epsilon}\theta(\mathbf{x}t |0) \ &= \boldsymbol{\epsilon}\theta(\mathbf{x}t |0) + s \cdot (\boldsymbol{\epsilon}\theta(\mathbf{x}t |y) -\boldsymbol{\epsilon}\theta(\mathbf{x}_t |0) ) \end{aligned} $$
请注意,这也可以用来“注入”文本嵌入,正如我们在分类器指导中显示的那样
这个无疑“奇怪”的过程有两个主要优点:
- 它只使用一个单一的模型来指导扩散。
- 它简化了在难以用分类器预测的信息(如文本嵌入)的条件下的引导。
Saharia et al. 提出的 Imagen 在很大程度上依赖于无分类器的引导,因为他们发现这是生成具有强图像-文本对齐的样本的关键贡献者。关于 Imagen 方法的更多信息,请看 AI Coffee Break 与 Letitia 的这段 YouTube 视频:
扩展扩散模型
你可能会问这些模型有什么问题。嗯,将这些 U-Nets 扩展到高分辨率图像在计算上非常昂贵。这给我们带来了两种方法,将扩散模型扩展到更高分辨率:级联扩散模型和潜在扩散模型。
级联扩散模型
Ho et al. 2021 引入了级联扩散模型,以产生高保真的图像。级联扩散模型包括一个由许多连续扩散模型组成的$Pipeline$,这些模型生成分辨率逐渐增加的图像。每个模型通过连续上采样图像并添加更高分辨率的细节,生成比前一个更高质量的样本。要生成图像,我们从每个扩散模型顺序采样。
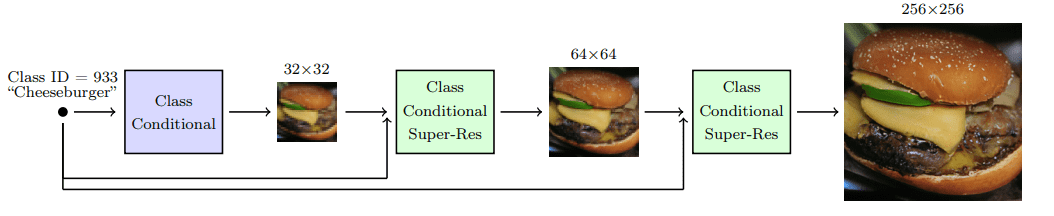
级联扩散模型$Pipeline$,图片来自 Ho & Saharia et al.
为了在使用级联架构时获得良好的结果,对每个超分辨率模型的输入进行强数据增强至关重要。为什么?因为它减轻了前面级联模型的复合误差,以及由于训练-测试不匹配造成的误差。
研究发现,发现高斯模糊是实现高保真度的一个关键转换。他们将这种技术称为条件增强。
Stable Diffusion: 隐变量扩散模型
隐变量扩散模型是基于一个相当简单的想法:我们不是直接在高维输入上应用扩散过程,而是将输入投射到一个较小的隐变量空间,并在隐变量空间应用扩散。
更详细地说, Rombach et al. 建议使用编码器网络将输入编码为隐变量表示,即 $\mathbf{z}_t = g(\mathbf{x}_t)$ 。这一决定背后的直觉是通过在低维空间处理输入来降低训练扩散模型的计算需求。之后,一个标准的扩散模型 (U-Net) 应用于生成新的数据,这些数据被一个解码器网络放大。
如果一个典型的扩散模型 (DM) 的损失被表述为:
$$ L {DM} = \mathbb{E}{\mathbf{x}, t, \boldsymbol{\epsilon} } \left[| \boldsymbol{\epsilon}- \boldsymbol{\epsilon}_{\theta}( \mathbf{x}_t, t ) ||^2 \right] $$
然后,给定编码器 $\mathcal{E}$ 和一个隐变量表示 $z$ ,那么一个隐变量扩散模型 (LDM) 的损失函数可以表示为:
$$ L {LDM} = \mathbb{E}{ \mathcal{E}(\mathbf{x}), t, \boldsymbol{\epsilon} } \left[| \boldsymbol{\epsilon}- \boldsymbol{\epsilon}_{\theta}( \mathbf{z}_t, t ) ||^2 \right] $$
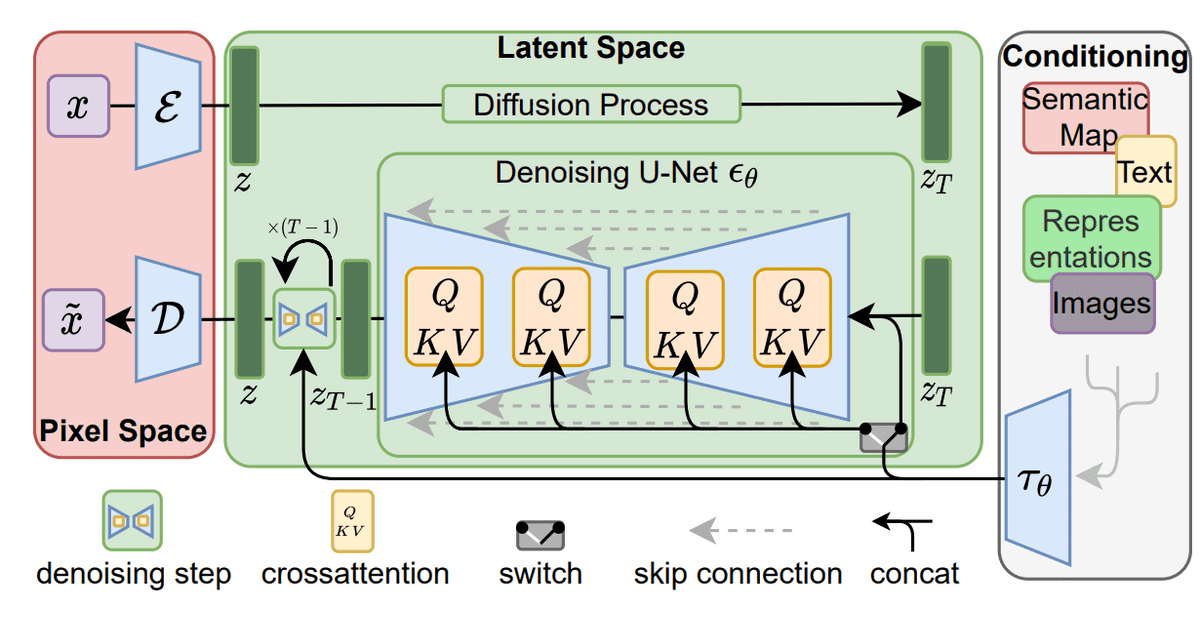
隐变量的扩散模型,图片来自 Rombach et al
欲了解更多信息,请看这个 YouTube 视频:
基于分数的生成模型
在 DDPM 论文发表的同时, Song and Ermon 提出了一种不同类型的生成模型,似乎与扩散模型有许多相似之处。基于分数的模型利用分数匹配和 Langevin 动力学来解决生成式学习。
- 分数匹配 (Score-matching) 指的是对数概率密度函数梯度的建模过程,也被称为分数函数。
- Langevin 动力学 (Langevin dynamics) 是一个迭代过程,它可以使用仅其分数函数从分布中绘制样本。
$$ \mathbf{x}t=\mathbf{x}+\frac{\delta}{2} \nabla_{\mathbf{x} } \log p\left(\mathbf{x}_{t-1}\right)+\sqrt{\delta} \boldsymbol{\epsilon}, \quad \text { where } \boldsymbol{\epsilon} \sim \mathcal{N}(\mathbf{0}, \mathbf{I}) $$
其中 $\delta$ 是步长大小。
假设我们有一个概率密度 $p(x)$ ,并且我们定义分数函数为 $\nabla_x \log p(x)$ 。然后我们可以训练一个神经网络 $s_{\theta}$ 来估计 $\nabla_x \log p(x)$ ,而不用先估计 $p(x)$ 。训练目标可以表述如下:
$$ \mathbb{E}{p(\mathbf{x})}[| \nabla\mathbf{x} \log p(\mathbf{x}) - \mathbf{s}\theta(\mathbf{x}) |2^2] = \int p(\mathbf{x}) | \nabla\mathbf{x} \log p(\mathbf{x}) - \mathbf{s}\theta(\mathbf{x}) |_2^2 \mathrm{d}\mathbf{x} $$
然后通过使用 Langevin 动力学,我们可以使用近似的分数函数直接从 $p(x)$ 中采样。
引导式扩散模型使用这种基于分数的模型的表述,因为它直接学习 $\nabla_x \log p(x)$ 。当然,它并不依赖 Langevin 动力学
为基于分数的模型添加噪音:噪声条件得分网络 (NCSN)
到目前为止的问题是:在低密度地区,估计的分数函数通常是不准确的,因为那里的数据点很少。因此,使用 Langevin 动力学采样的数据质量并不好.
他们的解决方案是对数据点进行噪声扰动,然后在噪声数据点上训练基于分数的模型。事实上,他们使用了多种规模的高斯噪声扰动。
因此,添加噪声是使 DDPM 和基于分数的模型都起作用的关键。
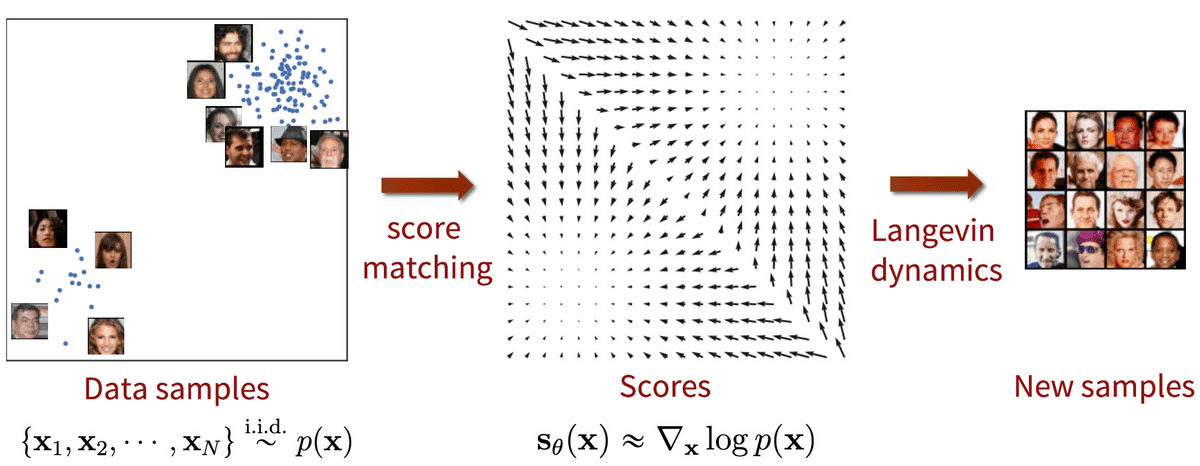
基于分数的生成模型与分数匹配以及 Langevin 动力学,图片来自 Generative Modeling by Estimating Gradients of the Data Distribution
在数学上,给定数据分布 $p(x)$ ,我们用高斯噪声进行扰动 $\mathcal{N}(\textbf{0}, \sigma_i^2 I)$ 其中 $i=1,2,\cdots,L$ 得到一个噪声扰动的分布:
$$ p_{\sigma_i}(\mathbf{x}) = \int p(\mathbf{y}) \mathcal{N}(\mathbf{x}; \mathbf{y}, \sigma_i^2 I) \mathrm{d} \mathbf{y} $$
然后我们训练一个网络 $s_\theta(\mathbf{x},i)$ ,称为基于噪声条件的分数网络 (NCSN) 来估计分数函数 $\nabla_\mathbf{x} \log d_{\sigma_i}(\mathbf{x})$ 。训练目标是所有噪声尺度的 Fisher 散度 的加权和:
$$ \sum_{i=1}^L \lambda(i) \mathbb{E}{p{\sigma_i}(\mathbf{x})}[| \nabla_\mathbf{x} \log p_{\sigma_i}(\mathbf{x}) - \mathbf{s}_\theta(\mathbf{x}, i) |_2^2] $$
通过随机微分方程 (SDE) 进行基于分数的生成性建模
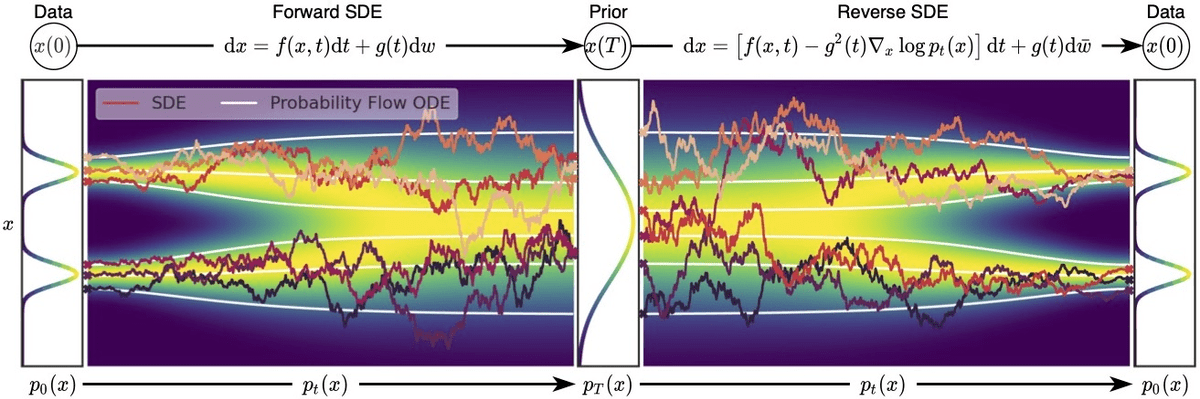
Song et al. 2021 探讨了基于分数的模型与扩散模型的联系。为了将 NSCNs 和 DDPMs 都囊括在同一伞下,他们提出了以下建议。
我们不使用有限数量的噪声分布来扰动数据,而是使用连续的分布,这些分布根据扩散过程随时间演变。这个过程由一个规定的随机微分方程 (SDE) 来模拟,它不依赖于数据,也没有可训练的参数。通过逆转这个过程,我们可以生成新的样本。

通过随机微分方程 (SDE) 进行基于分数的生成性建模, 图片来自 Song et al. 2021
我们可以把扩散过程 ${ \mathbf{x}(t) }_{t\in [0, T]}$ 定义为以下形式的 SDE:
$$ \mathrm{d}\mathbf{x} = \mathbf{f}(\mathbf{x}, t) \mathrm{d}t + g(t) \mathrm{d} \mathbf{w} $$
其中,$\mathbf{w}$ 是维纳过程(又称布朗运动)。 $\mathbf{f}(\cdot, t)$ 是一个矢量值函数,称为 $\mathbf{x}(t)$ 的漂移系数, $g(\cdot)$ 是一个标度函数,称为 $\mathbf{x}(t)$ 的扩散系数。请注意, SDE 通常有一个唯一的强解。
为了理解我们为什么使用 SDE ,这里有一个提示: SDE 的灵感来自于布朗运动,在布朗运动中,一些粒子在介质内随机移动。粒子运动的这种随机性模拟了数据上的连续噪声扰动
在对原始数据分布进行足够长时间的扰动后,被扰动的分布会变得接近于一个可操作的噪声分布。
为了产生新的样本,我们需要逆转扩散过程。该 SDE 被选择为有一个相应的封闭形式的反向 SDE:
$$ \mathrm{d}\mathbf{x} = [\mathbf{f}(\mathbf{x}, t) - g^2(t) \nabla_\mathbf{x} \log p_t(\mathbf{x})]\mathrm{d}t + g(t) \mathrm{d} \mathbf{w} $$
为了计算反向 SDE ,我们需要估计分数函数 $\nabla_\mathbf{x} \log p_t(\mathbf{x})$ 。这是用基于分数的模型 $s_\theta(\mathbf{x},i)$ 和 Langevin 动力学完成的。训练目标是 Fisher 分歧的连续组合:
$$ \mathbb{E}{t \in \mathcal{U}(0, T)}\mathbb{E}{p_t(\mathbf{x})}[\lambda(t) | \nabla_\mathbf{x} \log p_t(\mathbf{x}) - \mathbf{s}_\theta(\mathbf{x}, t) |_2^2] $$
其中 $\mathcal{U}(0, T)$ 表示时间间隔上的均匀分布, $\lambda$ 是一个正的加权函数。一旦我们有了分数函数,我们就可以把它放入反向 SDE 并求解,以便从原始数据分布 $p_0(\mathbf{x})$ 中采样 $\mathbf{x}(0)$ 。
有许多解决反向 SDE 的方案,我们在此不作分析。请务必查看原始论文或作者的 这篇优秀博文
通过 SDEs 进行基于分数的生成性建模的概述, 图片来自 Song et al. 2021
总结
让我们对这篇博文中所学到的主要内容做一个简单的总结。
- 扩散模型的工作原理是通过一系列的 T 步骤将高斯噪声逐渐添加到原始图像中,这个过程被称为扩散。
- 为了对新数据进行采样,我们使用神经网络对反向扩散过程进行近似。
- 模型的训练是基于证据下界 (ELBO) 的最大化。
- 我们可以将扩散模型置于图像标签或文本嵌入的条件下,以便“指导”扩散过程。
- 级联扩散和隐变量扩散是两种将模型扩展到高分辨率的方法。
- 级联扩散模型是连续的扩散模型,可以生成分辨率越来越高的图像。
- 隐变量扩散模型(像 Stable Diffusion )在较小的隐变量空间上应用扩散过程,以提高计算效率,使用变分自编码器进行向上和向下取样。
- 基于分数的模型也将一连串的噪声扰动应用到原始图像上。但它是用分数匹配和 Langevin 动力学来训练的。尽管如此,它最终的目标是相似的。
- 扩散过程可以被表述为一个 SDE 。解决反向 SDE 使我们能够生成新的样本。
最后,有关扩散模型和VAE或AE之间联系的更多信息,请查看 这些很棒的文章 。
本文翻译自 AI Summer 的工作人员 Sergios Karagiannakos, Nikolas Adaloglou 等几人发布的一篇文章,原文是 How diffusion models work: the math from scratch | AI Summer (theaisummer.com)
References
[1] Sohl-Dickstein, Jascha, et al. Deep Unsupervised Learning Using Nonequilibrium Thermodynamics. arXiv:1503.03585, arXiv, 18 Nov. 2015
[2] Ho, Jonathan, et al. Denoising Diffusion Probabilistic Models. arXiv:2006.11239, arXiv, 16 Dec. 2020
[3] Nichol, Alex, and Prafulla Dhariwal. Improved Denoising Diffusion Probabilistic Models. arXiv:2102.09672, arXiv, 18 Feb. 2021
[4] Dhariwal, Prafulla, and Alex Nichol. Diffusion Models Beat GANs on Image Synthesis. arXiv:2105.05233, arXiv, 1 June 2021
[5] Nichol, Alex, et al. GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models. arXiv:2112.10741, arXiv, 8 Mar. 2022
[6] Ho, Jonathan, and Tim Salimans. Classifier-Free Diffusion Guidance. 2021. openreview.net
[7] Ramesh, Aditya, et al. Hierarchical Text-Conditional Image Generation with CLIP Latents. arXiv:2204.06125, arXiv, 12 Apr. 2022
[8] Saharia, Chitwan, et al. Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding. arXiv:2205.11487, arXiv, 23 May 2022
[9] Rombach, Robin, et al. High-Resolution Image Synthesis with Latent Diffusion Models. arXiv:2112.10752, arXiv, 13 Apr. 2022
[10] Ho, Jonathan, et al. Cascaded Diffusion Models for High Fidelity Image Generation. arXiv:2106.15282, arXiv, 17 Dec. 2021
[11] Weng, Lilian. What Are Diffusion Models? 11 July 2021
[12] O'Connor, Ryan. Introduction to Diffusion Models for Machine Learning AssemblyAI Blog, 12 May 2022
[13] Rogge, Niels and Rasul, Kashif. The Annotated Diffusion Model . Hugging Face Blog, 7 June 2022
[14] Das, Ayan. “An Introduction to Diffusion Probabilistic Models.” Ayan Das, 4 Dec. 2021
[15] Song, Yang, and Stefano Ermon. Generative Modeling by Estimating Gradients of the Data Distribution. arXiv:1907.05600, arXiv, 10 Oct. 2020
[16] Song, Yang, and Stefano Ermon. Improved Techniques for Training Score-Based Generative Models. arXiv:2006.09011, arXiv, 23 Oct. 2020
[17] Song, Yang, et al. Score-Based Generative Modeling through Stochastic Differential Equations. arXiv:2011.13456, arXiv, 10 Feb. 2021
[18] Song, Yang. Generative Modeling by Estimating Gradients of the Data Distribution, 5 May 2021
[19] Luo, Calvin. Understanding Diffusion Models: A Unified Perspective. 25 Aug. 2022